多线程
多线程安全隐患的原因:当多条语句在操作同一个线程共享语句时,一个线程对多条语句只执行了一部分,还没执行完,另一个线程参与执行,导致共享数据错误。解决办法:对多条操作共享数据的语句,只能让一个线程执行完,在执行过程中,其他线程不能执行。
Synchronized(对象){ 需要被同步的代码 }
sleep只释放cpu执行权,不释放锁。
同步函数使用的锁:this
静态同步函数使用的锁:函数所在类的class对象
ThreadLocal不继承Thread,也不实现Runnable接口,ThreadLocal为每个线程都维护了自己独有的变量拷贝。每个线程都有自己独立的变量,其作用在于数据独立。
ThreadLocal采用hash表的方式来为每个线程提供一个变量的副本。
多个静态变量或静态代码块,按顺序加载。
Object的wait方法要使用try,不然就会抛出interrupted Exception
Concurrenthashmap
采用了二次hash的方法,第一次哈希将key映射到segment中,而第二次哈希则是映射到segment的不同桶中。
主要实现类为Concurrenthashmap整个hash表、segment(桶)、HashEntry(每个hash链中的一个节点)
HashEntry中除了value,其余3个key、hash、next都是final的。这意味着不能从中间或者尾部添加或删除节点,因为这需要改变next引用值,所有节点修改只能从头部开始,对于put操作,可以一律添加到hash链的头部,对于remove操作,可能需要从中间删除一个节点,这就需要将删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除节点的下一个节点。
Segment类中,count用来统计该段数据的个数,每次修改操作做了结构上的改变,比如增加或删除(修改节点的值不算结构上的改变)都要写count值,每次读取操作开始都要读count的值。
put操作也是委托给段的put方法。remove操作也是委托给段的remove方法,get操作也是委托给段的get方法。都是在持有短锁的情况下进行,lock和unlock。
由于所有修改操作,在进行结构修改时都会在最后一步写count变量,通过这种机制保证get操作,能够得到几乎最新的结构更新。count是volatile的,对hash链进行遍历不需要加锁的原有在于next指针是final的。读的时候,若value不为空,直接返回,若为空,则加锁重读。
Segment是一种可重入锁
Segments数组的长度size通过Concurrencylevel计算得出。16
Segment数组长度必须为2的n次(一个ConcurrentHashMap有一个Segments数组,每Segment相当于一个hashtable)
ConcurrentHashMap的get操作如何做到不加锁的呢?
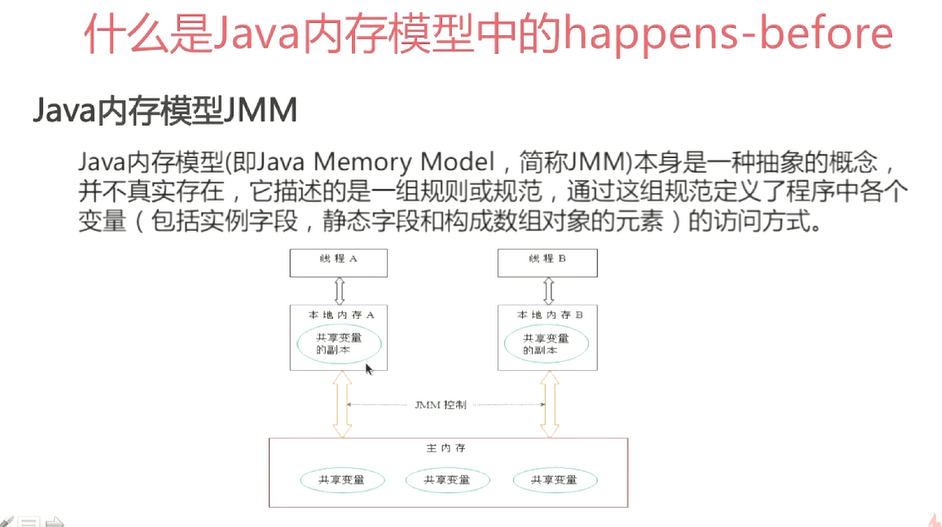
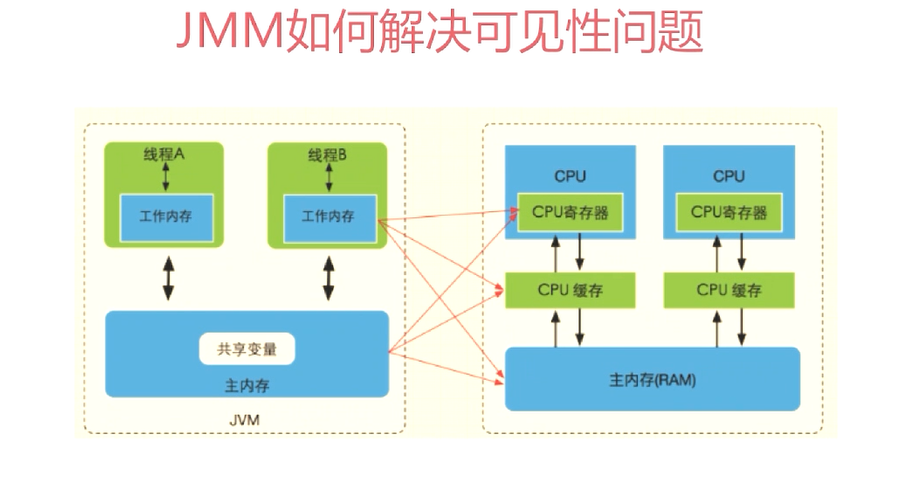
因为get方法里将需要使用的共享变量都定义为volatile(定义为volatile的变量可以在线程之间保证可见性,可以被多线程同时读,但只能被单线程写)Get 中只需要读,不需要写,所以不用加锁。之所以不会读到过期的值,这是因为Java内存模型的happen before原则,对volatile字段写入操作会先于读操作,即使两个线程同时修改volatile变量,get也能拿到最新的值。
Resize时,只对Segment扩容,不对整个ConcurrentHash Map扩容,先判断是否需要扩容,再put,传统hashmap 是先put再判断。
Size求大小,最安全的做法是统计size时将所有Segment的put remove clean方法全部锁住,效率低。所以ConcurrentHashMap 的做法是:先尝试两次不锁柱Segment的方法来统计各个Segment大小。若统计的过程中,容器的count发生了变化,则采用加锁的方式来统计。使用modcount变量来判断统计过程中,count是否变化。
在put、remove、clean方法操作元素前modcount要加1,那么在统计size前后比较modcount是否发生变化,从而得知容器大小是否变化。
CAS:Compare and swap
CAS有3种操作数:内存值V,旧的预期值A和要修改的新值B
当且仅当,预期值A和内存值V相同时,将内存V改为B,返回V
CAS通过调用JNI的代码实现
Hashmap 不是线程安全的,所以如果在使用迭代器的过程中有其他线程修改了 map, 则会抛出 ConcurrentModificationException,这就是所谓的 fast-fail 策略,是通过 modcount 实现,对 Hashmap 内容的修改都将增加这个值,那么在迭代器初始化时会将这个值赋给迭 代器的 exceptedmodcount。在迭代过程中,判断 modcount 和 exceptedmodcount 是否相等, 若不相等,则说明其他线程修改了 map。Modcount 是 volatile 的。 Hashtable 继承 Dictionary 类,实现 map、cloneable、serializable 接口。 Hashtable 键为 null,则抛出 NullPointException。他的 clear 方法就是把数组元素都设为 null。
事务隔离级别就是对事物并发控制的等级。串行化:所有事务一个接一个的串行执行。 可重复读:所有被 select 获取的数据都不能被修改,这样就可以避免一个事务前后读取数据 不一致的情况。读已提交:被读取的数据可以被其他事务修改。读未提交:允许其他事务看 到没提交的数据。脏读:事务没提交,提前读取,就是当一个事务正在访问数据,并且对数 据进行了修改,而这种修改还没提交到数据库,这时,另外一个事务也访问这个数据,然后 使用了这个数据。
怎么判断一个 mysql 中 select 语句是否使用了索引,可以在 select 语句前加上 explain, 比如 explain select * from tablename;返回的一列中,若列名为 key 的那列为 null,则没有使 用索引,若不为 null,则返回实际使用的索引名。让 select 强制使用索引的语法:select * from tablename from index(index_name);
Hashmap,两次哈希,第一次直接调用 key 的 hashcode 方法,第二次再调用一个函数 即 hash(key.hashcode()),此方法加入高位计算,防止低位不变高位变化时造成的冲突。
乐观锁适用于写较少的情况,即冲突真的很少发生,这样可以省去了锁的开销,加大了 系统的吞吐量。





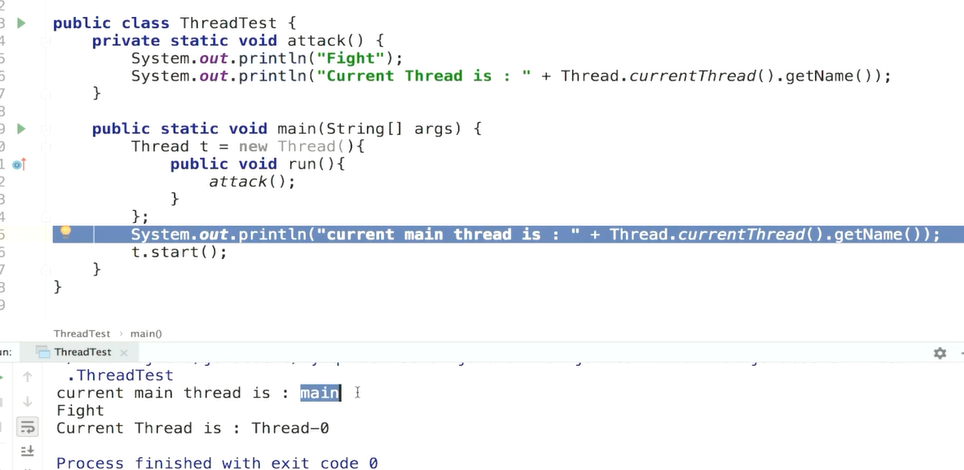

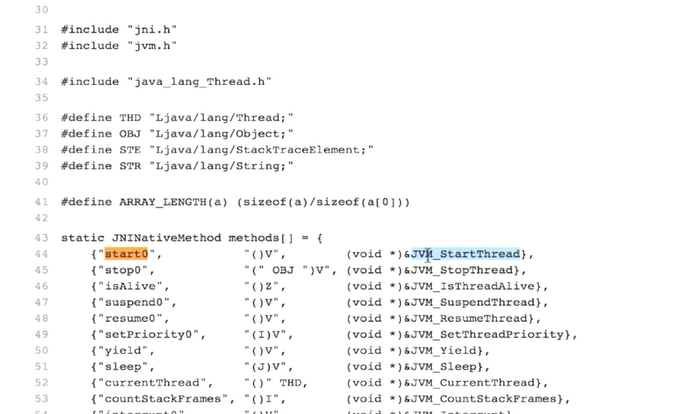
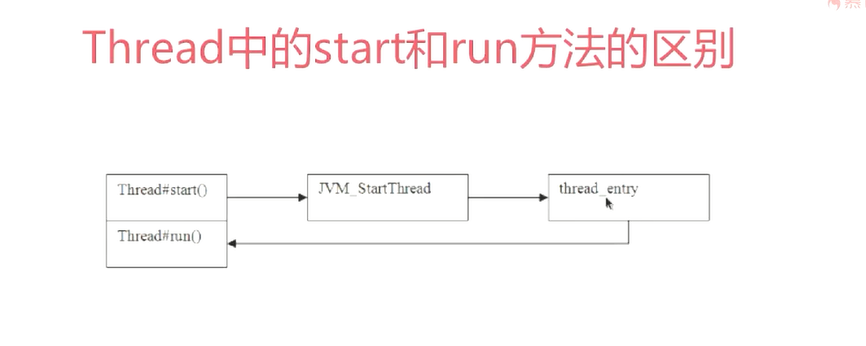
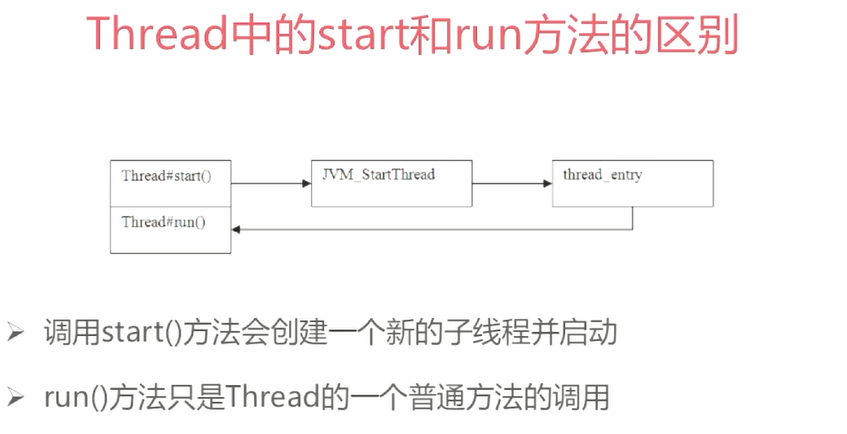

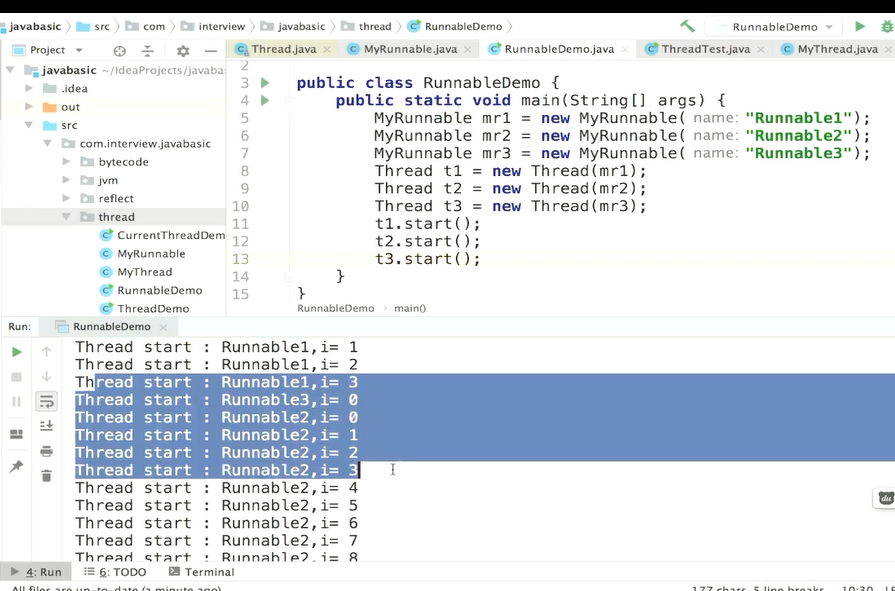


返回值怎么来呢
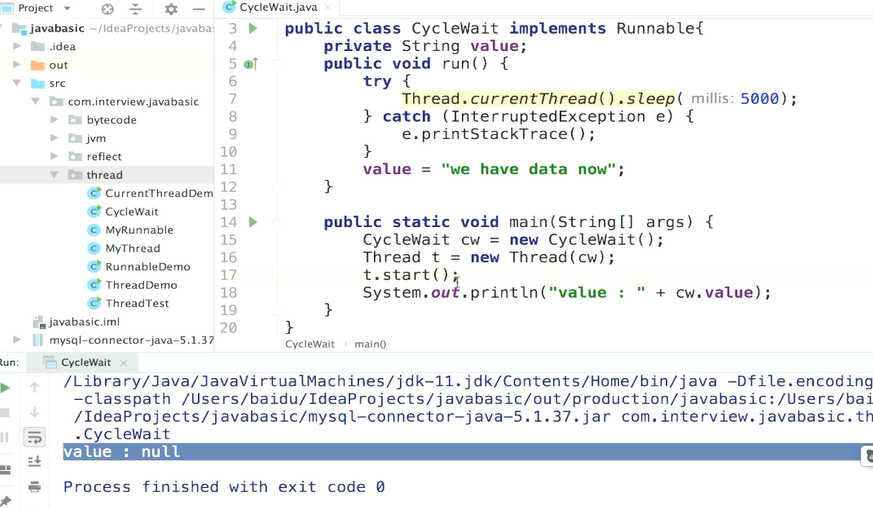
这是null

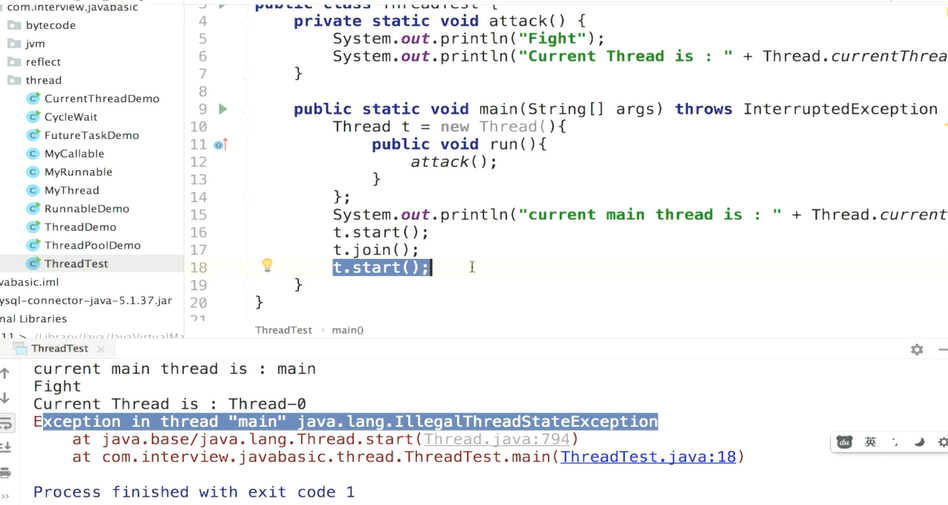
这就是主线程等待法
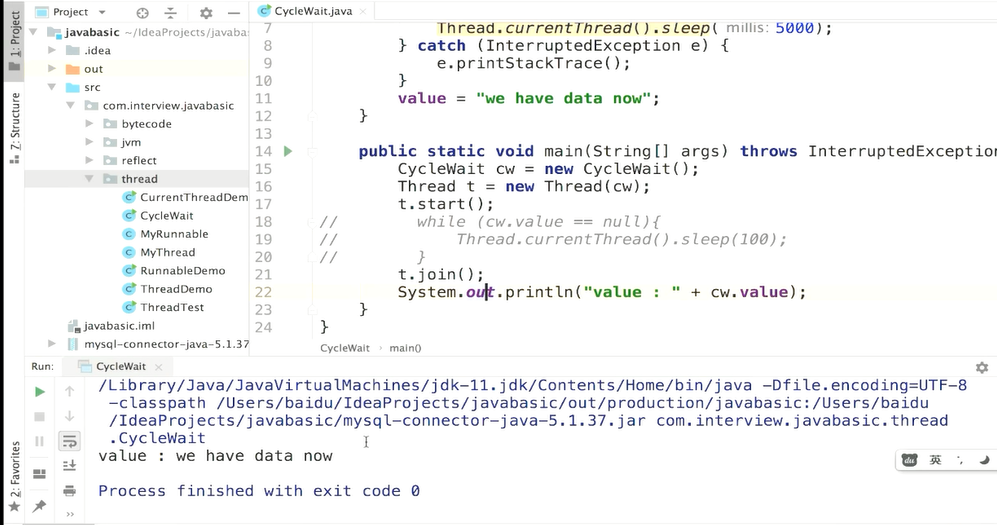
A线程中调用了B线程的join()方法时,表示只有当B线程执行完毕时,A线程才能继续执行
但是粒度不够细

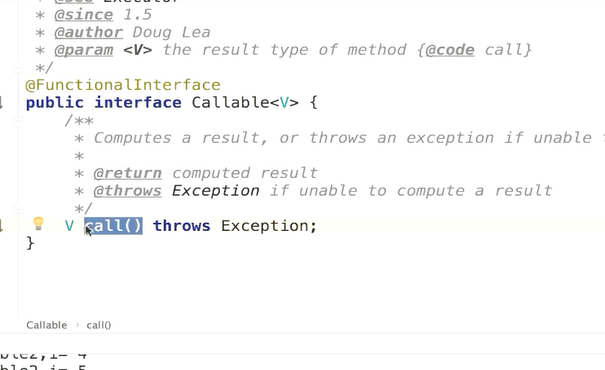


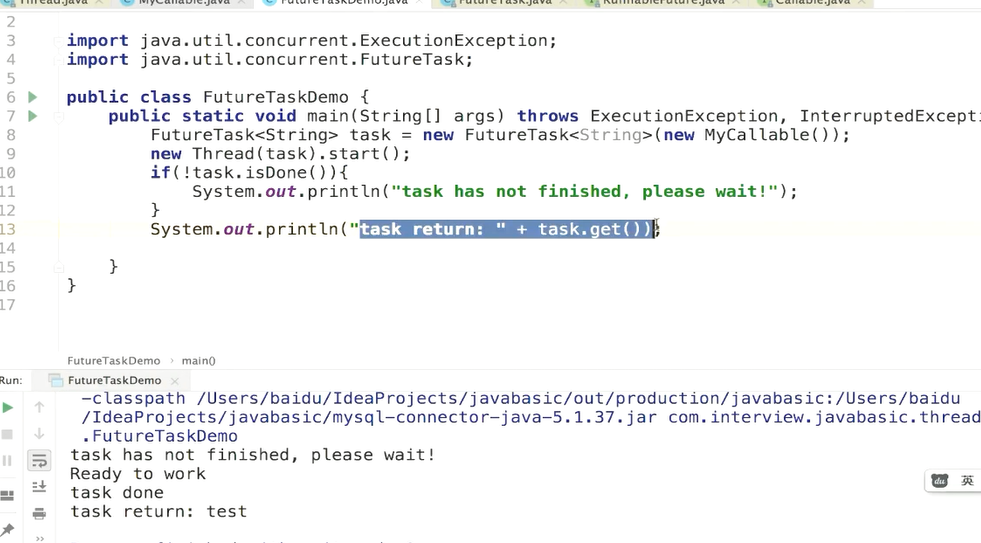
tast.get是等待有了返回值之后再返回的







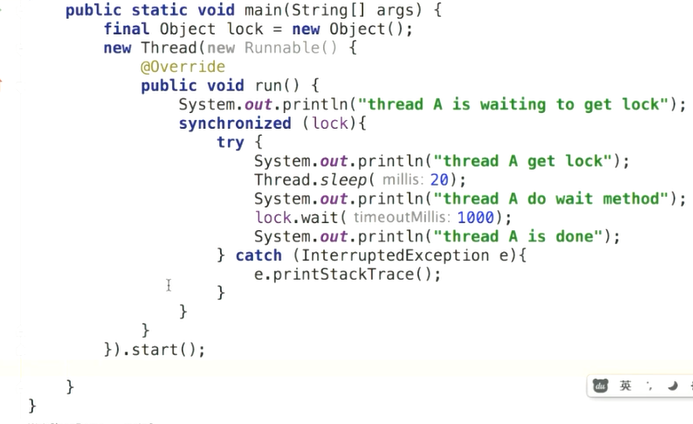
sleep是没有释放锁的功能的
wait必须写在synchronized里,可以释放锁





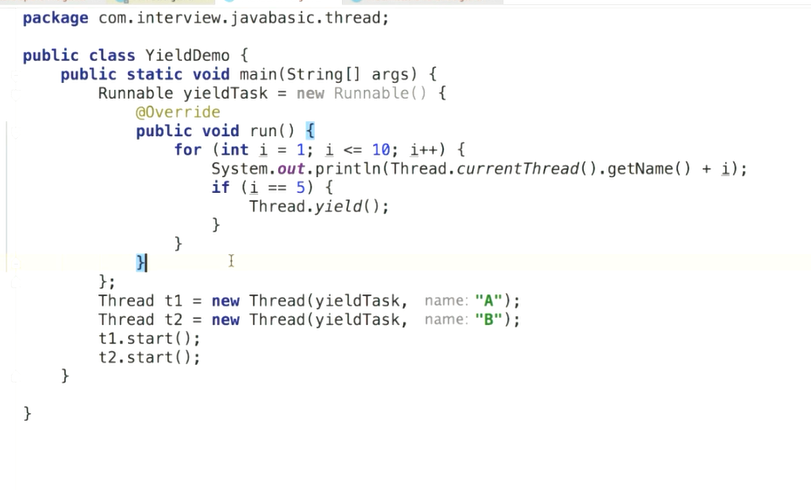
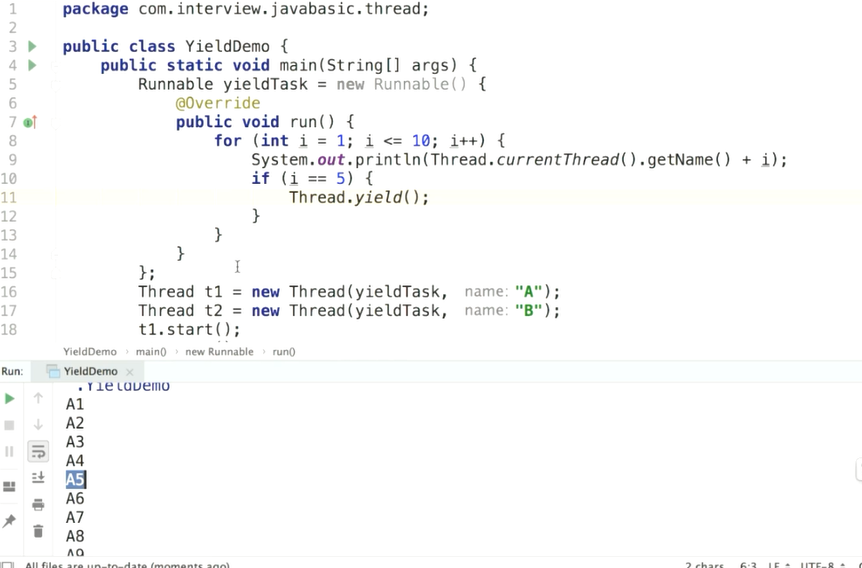
yield对锁没有影响




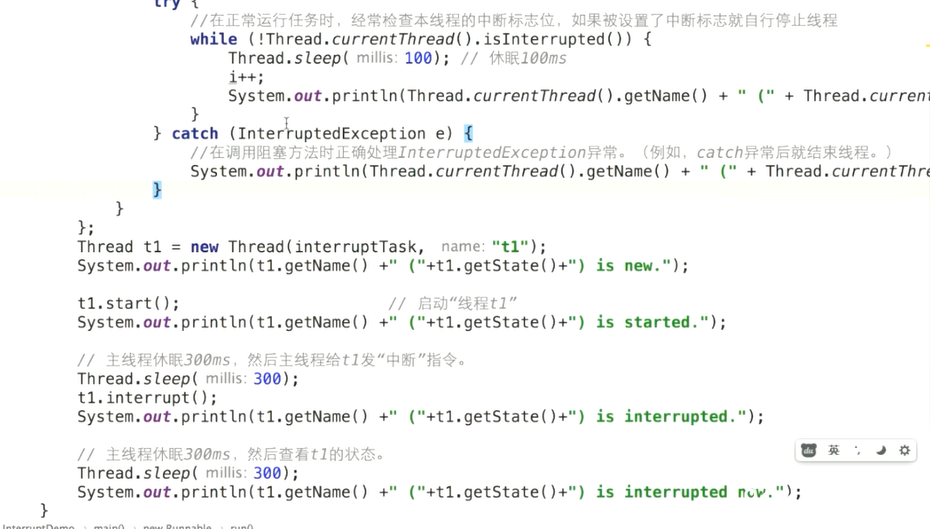
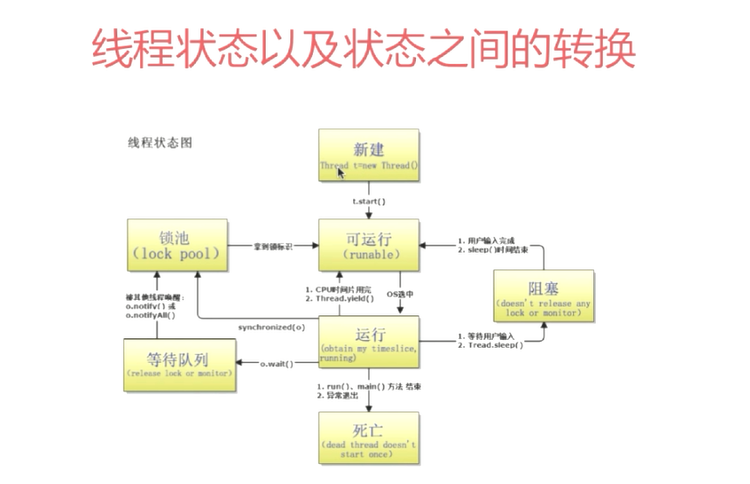
同步:多个线程并发访问共享数据时,保证共享数据在同一个时刻,只被一个线程使用,而互斥是实现同步的一种手段
临界区、互斥量、信号量都是主要的互斥实现手段。
互斥是因,同步是果,互斥是方法,同步是目的。
公平锁:(先申请先得到)多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获取,而公平锁则不保证这一点。
Synchronized不是公平锁,reentrantlock默认下是非公平的,但是在构造函数中,可以设置为公平的。
互斥同步对性能最大的影响是阻塞的实现,挂起线程和恢复线程的需要转入内核态完成。
若物理机器上有一个以上的处理器,能让2个或2个以上的线程同时并行执行,我们就可以让后面请求锁的那个线程稍等一下,但不放弃处理器的执行时间,看看持有锁的线程是否会很快的释放锁,为了让线程等待,我们只需要让他执行一个忙循环(自旋),这项技术就是所谓的自旋锁。
自适应自旋锁的自旋时间不再固定,而是由前一次在同一个锁上自旋时间以及锁拥有的状态决定。
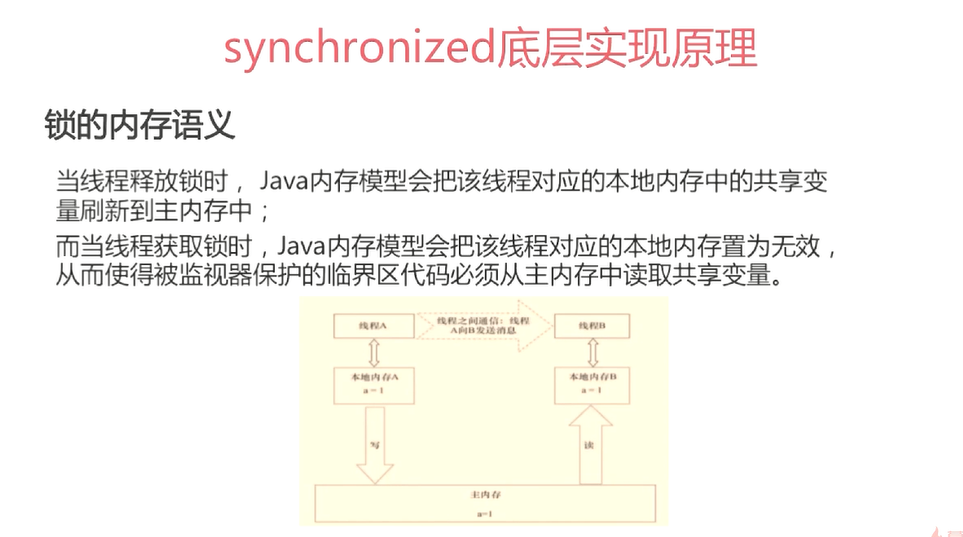
Synchronized
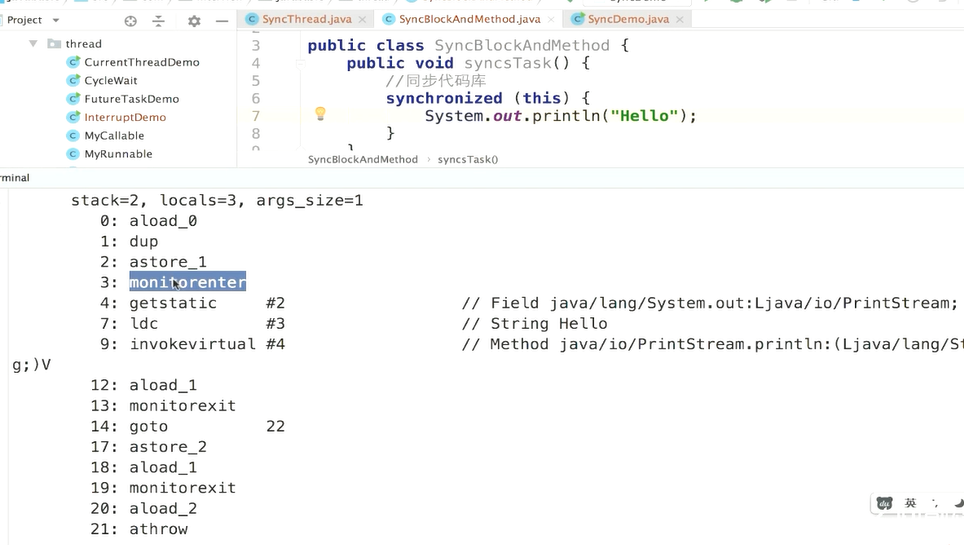
1、同步代码块 使用monitor enter和monitor exit指令实现,monitor enter指令插入到同步代码块的开始位置,monitor exit指令插入到同步代码块结束位置,jvm需要保证每个monitor enter都有一个monitor exit与之对应。任何对象都有一个monitor与之相关联,并且一个monitor被持有之后,他将处于锁定的状态,线程执行到monitor指令前,将会尝试获取对象所对应的monitor所有权,即尝试获取对象的锁。
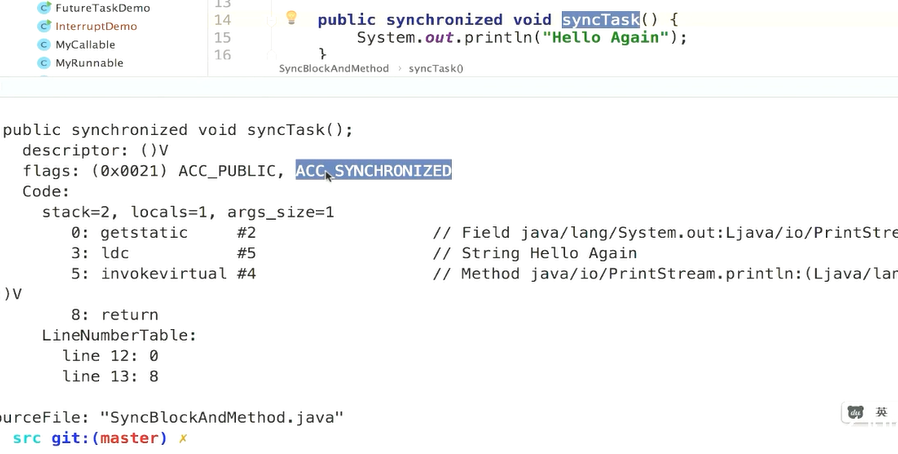
2、同步方法:依靠的是方法修饰符上的ACC_SYNCHRONIZED实现。Synchronized方法则会被翻译为普通的方法调用和返回指令,比如invoke virtual指令,在jvm字节码层面并没有任何特别的指令来实现synchronized修饰方法,而是在class文件的方法表中将该方法的access_flags字段中的synchronized标志位置为1,表示该方法为synchronized方法,且使用调用该方法的对象或者该方法所属的class在jvm内部对象表示作为锁对象。
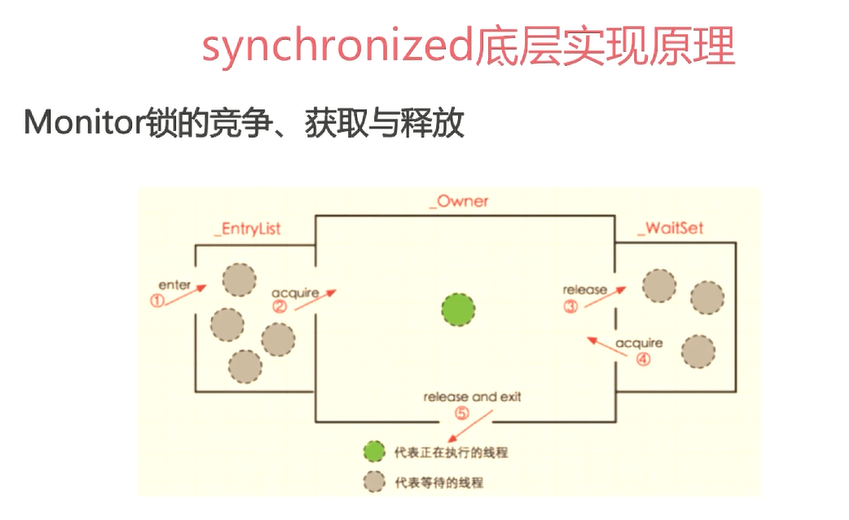
在Java设计中。每个对象自打娘胎里出来就带了一把看不见的锁,即monitor锁。Monitor是线程私有的数据结构,每个线程都有一个可用的monitor record列表,同时还有一个全局可用列表。每一个被锁住对象都会和一个monitor关联。Monitor中有一个owner字段存放拥有该对象的线程的唯一标识,表示该锁这个线程占有。
Owner初始时为null,表示当前没有任何线程拥有该monitor record,当线程成功拥有该锁后保存线程唯一标识,当锁被释放时,又设为null。
Entry Q:关联一个系统互斥锁,阻塞所有试图锁住monitor entry失败的线程。
Next:用来实现重入锁的计数。
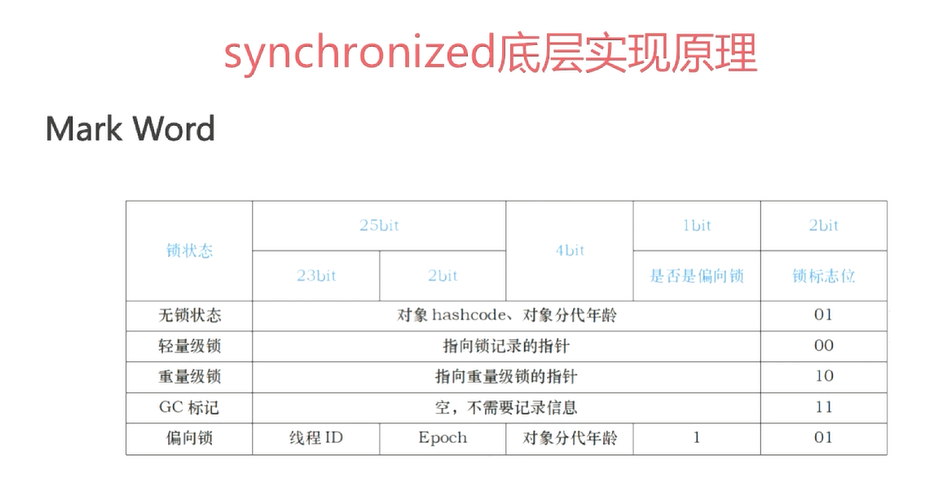
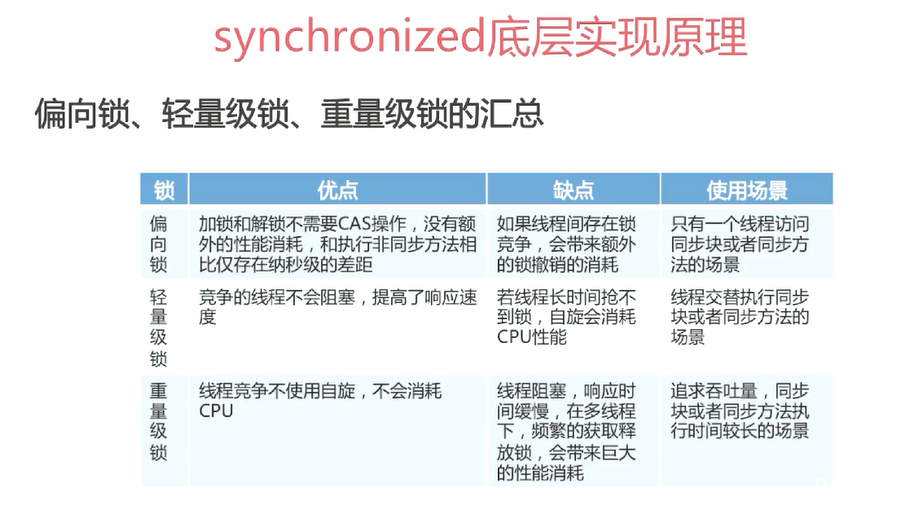
锁主要有4种状态:无锁状态、偏向状态、轻量级状态、重量级状态。他们会随着竞争的激烈而逐渐升级,锁可以升级但不可以降级。
自旋锁、自适应自旋锁、锁消除。锁消除的依据是逃逸分析的数据支持。锁粗化:将多个连续加锁解锁操作连接起来扩展成一个范围更大的锁。
轻量级锁:传统的锁是重量级锁,他是用系统的互斥量来实现。轻量级锁的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。
偏向锁:目的是消除数据在无竞争情况下的同步原语。如果说轻量级锁是在无竞争的情况下使用CAS操作去消除同步使用的互斥量,那么偏向锁就是在无竞争的情况下把整个同步消除掉。
Synchronized用的锁时存在Java对象头。对象头包含标记字段和类型指针。类型指针是对象指向它类元数据的指针,虚拟机通过这个指针确定这个对象是哪个类的实例。标记字段用于存储对象自身运行时数据,他是实现轻量级锁和偏向锁的关键。
JVM可以通过对象的元数据信息确定对象的大小,但是无法从数据的元数据来确定数组的大小。
乐观锁VS悲观锁
1、悲观锁:就是很悲观,每次去拿数据的时候都会认为别人会修改。所以每次在拿数据的时候都会上锁。这样别人想拿这个数据就会block直到拿到锁。传统的关系型数据库就用到了很多这种机制。比如行锁、写锁,都在操作之前上锁。
2、乐观锁:就是乐观,每次拿数据的时候都会认为别人不会修改,所以不会上锁,但是会判断一下在此期间别人有没有更新这个数据。适用于多读,比如weiter_condition。
这两种锁各有优缺点,不能认为一种比一种好。
JVM中,一个字节以下的整形数据byte,-128到127会在jvm启动时加载入内存,除非用new Integer()显示的创建对象,否则都是同一个对象。Integer的value方法返回一个对象,先判断传入的参数是否在-128到127之间,则直接返回引用,否则返回new Interger(n);
Hashmap的resize在多线程的情况下可能产生条件竞争。因为如果两个线程都发现hashmap需要resize了,他们会同时试着调整大小的大小。在调整大小的过程中。存储在链表中的元素的次序会反过来。因为移动到了新的位置时,hashmap并不会将元素放在链表的尾部,而是放在链表的头部,这是为了避免尾部遍历。如果条件竞争发生了可能出现环形链表,之后当我们调用get(key)操作时就可能发生死循环。
ConcurrentHashMap:初始化时除了initialCapacity,loadfactor参数。还有一个重要参数concurrency level,他决定了segment数组的长度,默认16.每次get和put操作都会通过hash算法定位到一个segment,然后再通过hash算法定位到具体某个entry
Get操作时是不需要加锁的。因为get方法里将要使用的共享变量都定义为volatile。定义为volatile的变量, 能够在线程之间保存可见性,能够被多个线程同时读。并且保证不会读到过期的值。但是只能被单线程写。
Put必须加锁
ReenTrantLock 可重入,单线程可以重复进入,弹药重复退出。synchronized也是可重入锁
可中断,可响应中断
可限时,超时不能获得锁就返回false
公平锁:线程先来,先得到锁,可以在构造函数中设置。
Condition的await和single与Object的wait和notify相似
对于锁来说,它是互斥的排他的,意思是只要我获得了锁,没人再能获得,而对于somaphore来说,它允许多个线程同时进入临界区,可以认为它是一个共享锁,但是共享的额度是有限的,额度用完了,其他没有额度的线程还是要阻塞在临界区外,当额度是1时,相当lock
ReadWriteLock:读读不互斥,读写互斥,写写互斥,并发性提高。
CountDownLatch
倒数计时器,一种典型的场景就是火箭发射,在火箭发射前,往往还要进行各项设备仪器的检查,只能等所有检查完成之后,引擎才能点火,这种场景都非常适合使用CountDownLatch,它可以使点火线程使得所有检查线程全部完工后,再执行。
cyclicBarrier模拟高并发
可重入锁:同一线程,外层函数获得锁所之后,内层递归函数仍有获得该锁的机会但不 受影响。Synchronized 和 reentrantlock 都是可重入锁。
Hashmap 的实现用 hash 表,tree-map 采用红黑树。
Collections 类中提供了一个方法,返回一个同步版本的 hashmap,该方法返回的是一个 synchronized Map 的实例,synchronized Map 类是定义在 Collections 中的一个静态内部类。 它实现 map 接口,并对其中的每一个方法通过 synchronized 关键字进行了同步控制。但 synchronized Map 在使用过程中不一定线程安全。
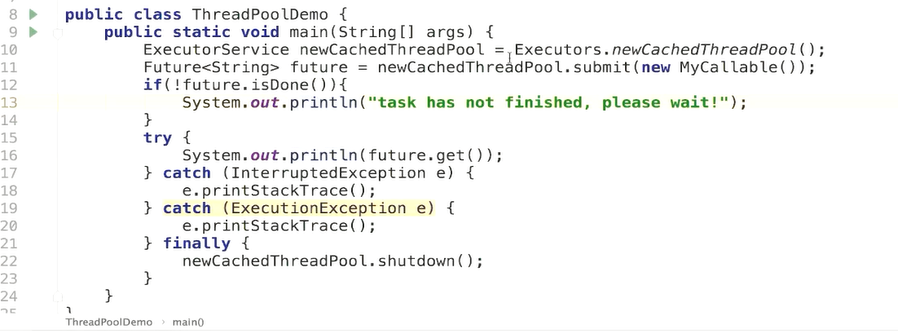
一、Runnable 的 run 方法没有返回值,并且不可以抛出异常;callable 的 call 方法有返 回值,并且可以抛出异常,且返回值可以被 future 接收。 Callable c=new Callable(){ Public Integer call() throws Exception{ Return new Random().nextInt(100); }} Future 是一个接口。Futuretask 是他的一个实现类,可通过 futuretask 的 get 方法得到 返回值。 Futuretask future =new Futuretask< Integer >( callable); New Thread(future).start(); 二、使用 ExecutorService 的 submit 方法执行 callable; ExecutorService threadpoll=Executors.new SingleThreadExecutor(); Futuretask future= threadpoll.submit(new callable(){ Public Integer call() throws Exception{ Return new Random().nextInt(100); } })
Future 对象表示异步计算的结果,他提供了检查计算是否完成的方法,以等待计算的完 成,并获取计算的结果。计算完成后只能使用 get 方法来获取结果,若没有执行完,get 方 法可能会阻塞,直到线程执行完。取消由 cancel 方法执行。isDone 确定任务是正常执行还 是被取消。一旦计算完成,就不能再取消了。
共享锁 VS 排他锁:1)共享锁,又称读锁,若事务 T 对数据对象 A 加了 S 锁,则是事 务 T 可以读 A 但不能修改 A,其它事务只能再对他加 S 锁,而不能加 X 锁,直到 T 释放 A 上 的 S 锁。这保证了其他事务可以读 A,但在事务 T 释放 S 锁之前,不能对 A 做任何操作。2) 排他锁,又称写锁,若事务 T 对数据对象加 X 锁,事务 T 可以读 A 也可以修改 A,其他事务 不能对 A 加任何锁,直到 T 释放 A 上的锁。这保证了,其他事务在 T 释放 A 上的锁之前不 能再读取和修改 A。
a 发送给 b 一个信息,但是 a 不承认他发送了,防止这个可用数字签名

















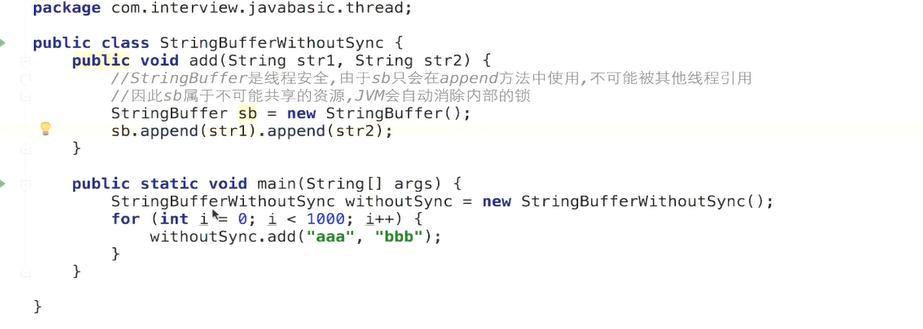

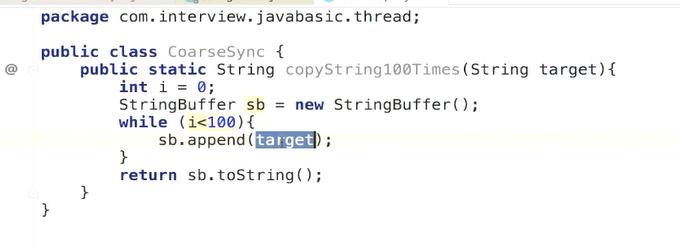
















++不具备原子性














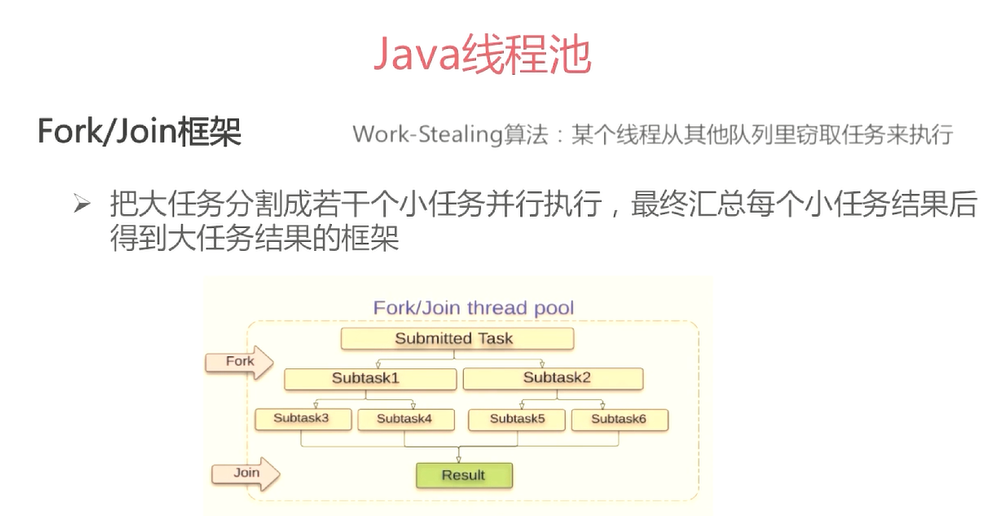

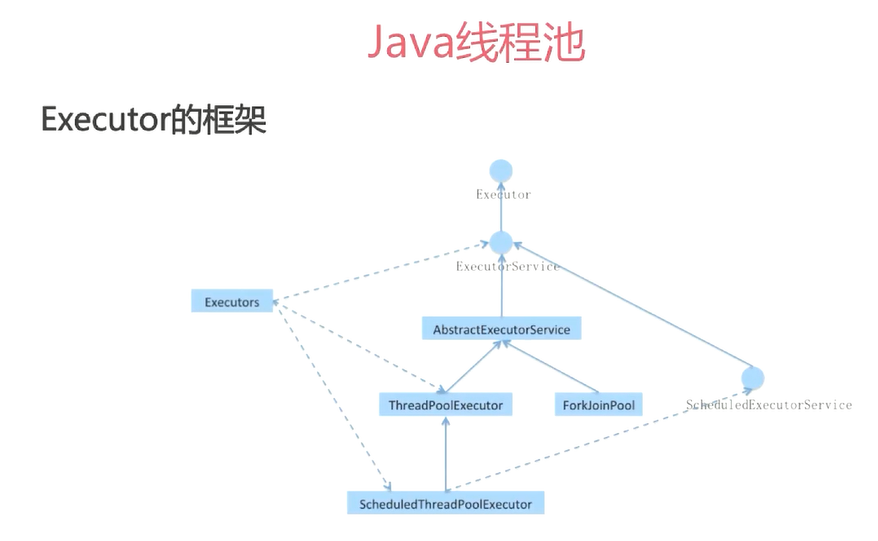
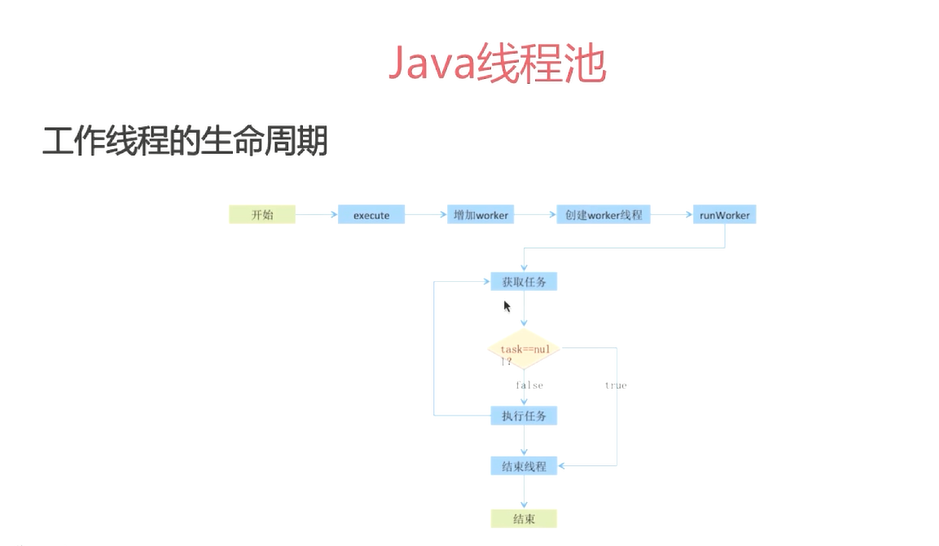
线程池ThreadPoolExecutor
corepoolsize:核心池大小,默认情况下,在创建了线程池之后,线程池中的线程数位0,当有任务来之后,就会创建一个线程去执行任务,当线程池中线程数到达corepoolsize后,就把任务放到任务缓存队列中。
maximumpoolsize:线程池中最多创建多少个线程
keeplivetime:线程没有任务执行时,最多保存多少时间会终止,默认情况下,当线程池中线程数>corepoolsize时,keeplivetime才起作用,直到线程数不大于corepoolsize。
workqueue:阻塞队列,用来存放等待被执行的任务。
threadFactory:线程工厂,用来创建线程。

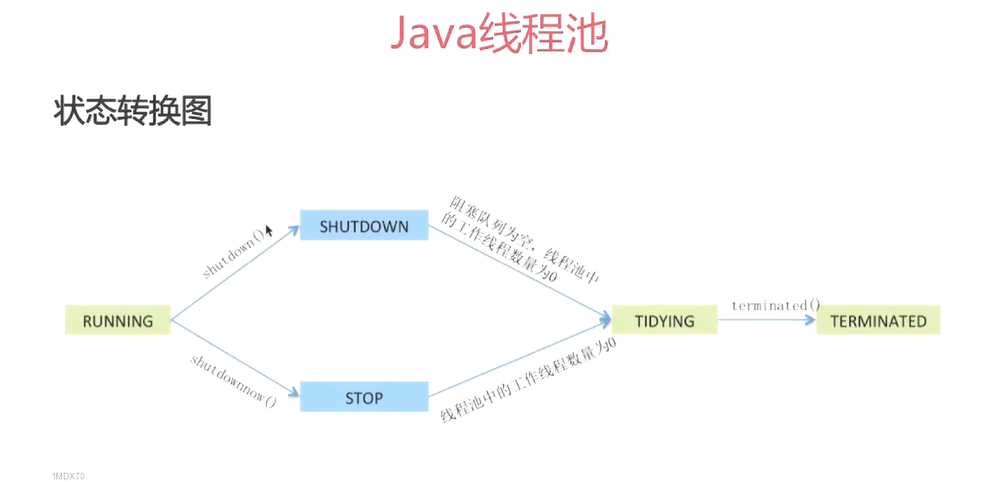
线程池状态:
1、当线程池创建后,初始为running状态。
2、调用shutdown方法后,处shutdown状态,此时不再接受新的任务,等待已有的任务执行完毕。
3、调用shutdownnow方法后,进入stop状态,不再接受新的任务,并且会尝试终止正在执行的任务。
4、当处于shutdown或stop状态,并且所有工作线程已经销毁,任务缓存队列已清空,线程池被设为terminated状态。
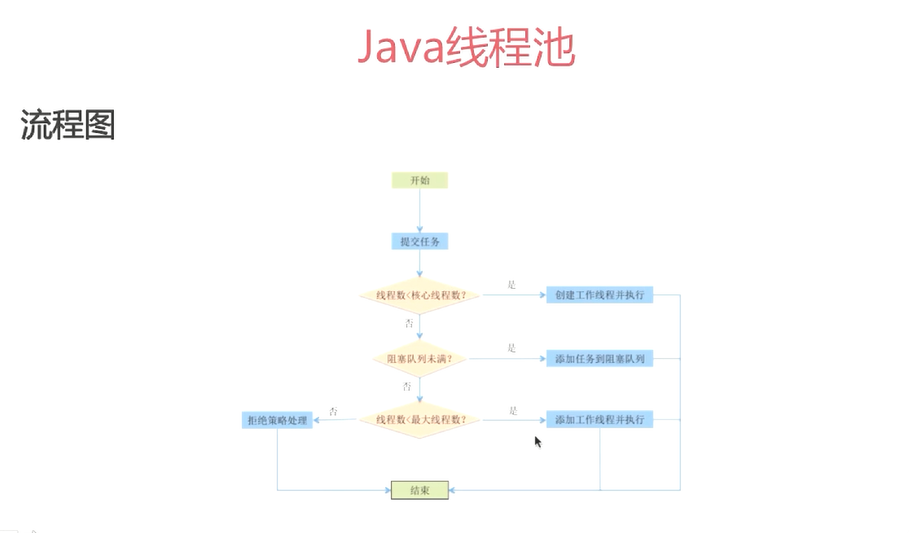
当有任务提交到线程池后的一些操作。
1、若当前线程池中的线程数<corepoolsize,则每来一个任务就创建一个线程去执行。
2、若当前线程池中线程数>=corepoolsize,会尝试将任务添加到任务缓存队列中去,若添加成功则任务会等待空闲线程将其取出,若添加失败,则尝试创建线程去执行这个任务。
3、若当线程池中线程数>=maximumpoolsize,则采取拒绝策略,有4种。
1、abortpolicy 丢弃任务,抛出RejectedExecutionException
2、dicardpolicy拒绝执行,不抛异常。
3、discardoldestpolicy丢弃任务缓存队列中最老的任务并且尝试重新提交新的任务。
4、callerrunspolicy有反馈机制,使任务提交的速度变慢。
使用线程池。我们只需要运行Executors类给我们提供的静态方法,就可以创建相应的线程池。
public static ExecutorService newSingleThreadExecutor()
public static ExecutorService newFixedThreadPool()
public static ExecutorService newCachedThreadPool()
newSingleThreadExecutor返回包含一个单线程的Executor,将多个任务交给这个Executor时,这个线程处理完一个任务交给这个Executor时,这个线程处理完一个任务之后接着处理下一个任务,若该线程出现异常,将会有一个新线程来代替。
newFixedThreadPool返回一个包含指定数目线程的线程池,若任务多于线程数目,则没有执行的任务必须等待,直到有任务完成为止。
newCachedThreadPool根据用户的任务数创建相应的线程数来处理,该线程池不会对线程数加以限制,完全依赖于jvm能创建线程的数量,可能引起内存不足。
我们只需要将待执行的方法放入run方法中,将Runnable接口的实现类交给线程池的execute方法,作为它的一个参数。
1 Executor e=Executors.newSingleThreadExecutor(); 2 e.execute(new Runnable(){ //匿名内部类 3 public void run(){ 4 //需要执行的任务 5 } 6 });













 浙公网安备 33010602011771号
浙公网安备 33010602011771号