数据库
------------恢复内容开始------------

如何设计一个关系型数据库
mysql索引使用的是B+树的数据结构
索引:用于提高数据访问速度的数据库对象。
优点:
1、索引可以避免全表扫描
2、对于非聚集索引,有些查询甚至可以不访问数据项。
3、聚集索引可以避免数据插入操作集中于表的最后一个数据页。
4、一些情况下,索引还可以避免排序。
虽然索引可以提高查询速度,但是他们也会导致数据库更新数据的性能下降,因为大部分数据更新的时候都需要同时更新索引。
聚集索引:数据按索引顺序存储,叶子节点存储真实的数据行,不再有单独的数据页,一张表上只能创建一个聚集索引。
因为真实数据的物理顺序只能有一种,若一张表没有聚集索引,则它被称为堆集。这样表的数据行没有特定的顺序,所有新行被添加到表的末尾。
非聚集索引与聚集索引的区别
1、叶子节点并非数据节点。
2、叶子节点为每个真正的数据行存储了一个键指针对。
3、叶子节点还存储了一个指针偏移量,根据页指针以及指针偏移量可以定位到具体的数据行。
4、在除叶子节点外的其他索引节点,存储的是类似内容,只不过是指向下一级索引页。
索引
一般来说应该在这些列上加上索引:
1、经常需要搜索的列,加快搜索搜索速度
2、作为主键的列,强制该列的唯一性。
3、在经常用在连接的列上,这些列主要是外键,可以加快连接速度
4、在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,指定的范围是连续的
5、在经常需要排序的列上。
唯一索引:不允许其中任何两行有相同的值
主键索引:为表定义主键自动创建主键索引,是唯一索引的特定类型
下列事件索引会失效
1、条件中有or,即使其中有条件但索引也不会使用,
2、like查询以%开头
3、若列类型为字符串,则一定要在条件中将数据用引用引起来,否则不使用引擎
4、若mysql估计使用全表扫描要比索引快,则不使用索引
5、对索引进行运算导致索引列失效
6、使用内部函数导致索引失效,这样应该创建基于函数的索引
7B树 is null不会用,is not null也不会用
索引:
1、可以避免全表扫描
2、若一个表没有聚集索引,则这样的数据没有特定的顺序,所有新行被添加到表的末尾
3、聚集索引是一种稀疏索引,数据页上一页的索引页存储的是页指针,不是行指针
对于非聚集索引则是密集索引,数据页的上一级索引为每一个每一个数据行存储的一条索引记录



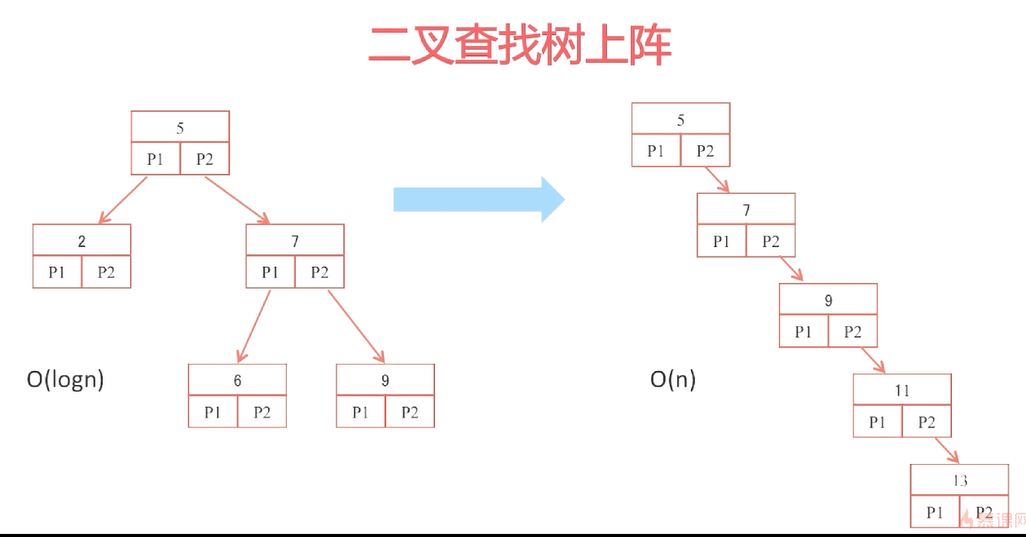
想让树变的小一点
就是矮一点,然后减少io次数
通常不止3个
B 树索引可以使用< <= = >= >或者between运算符的列比较
如果like的参数是一个没有通配符起始的常量字符串也可以使用这种索引
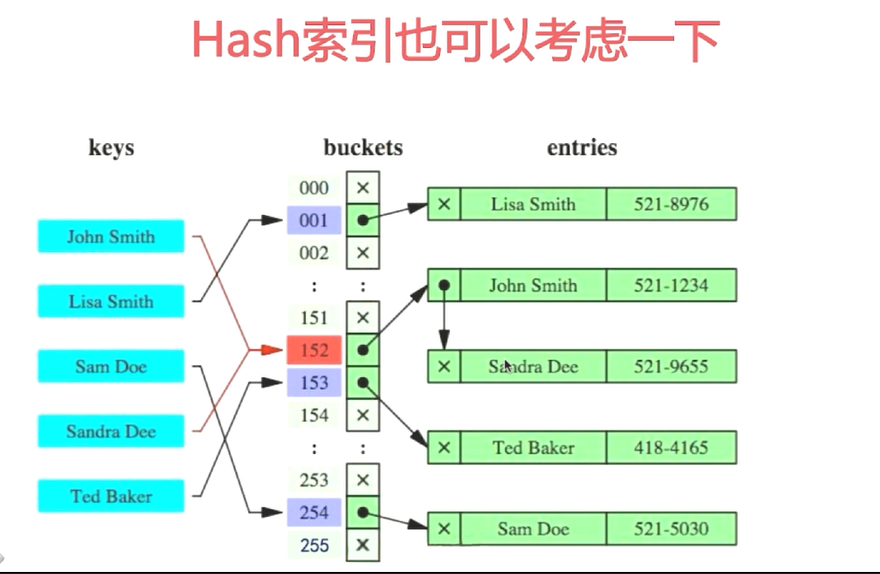
Hash索引
只能使用=,不能用于有范围的运算符,因为键经过hash以后的值没有意义
优化器不能使用hash索引来加速order by操作。
这种类型的索引不能够用于按照顺序查找下一个条目
mysql无法使用hash索引来估计两个值之间有多少行。
查找某行记录必须全键匹配,而且B 树索引,任何改键的左前缀都可以查找记录。
若将一张myisam或innodb表换成hash索引的内存表,一些查询可能受影响。
B树就是B-树,是一种多路索引树,任意非叶子节点最多只有m个儿子且m>2
根节点的儿子数最多为[2,m]
除了根节点以外的非叶子节点的儿子数为[m/2,m]
每个节点至少存放m/2-1和最多m-1个关键字
非叶子节点的关键字个数=儿子数-1
所有叶子节点在同一层
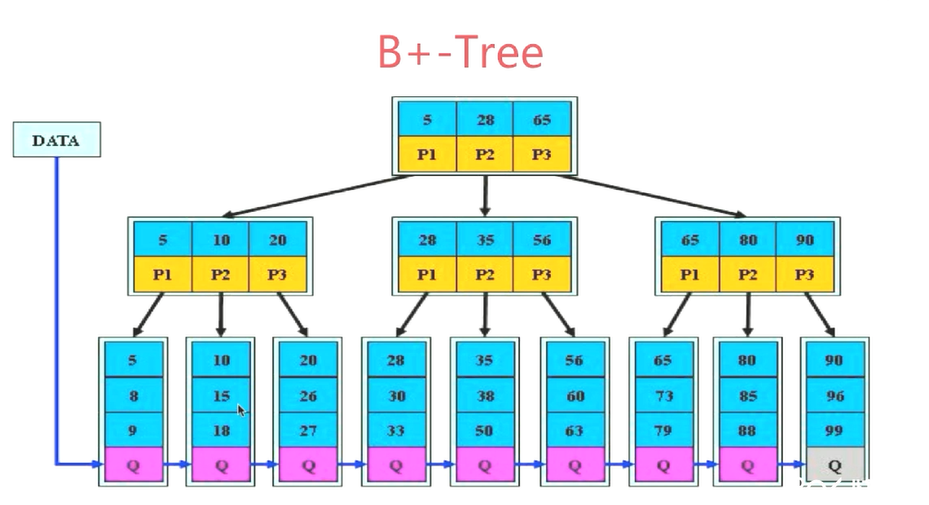
B+树
适合文件系统索引
1、其基本定义和B树相同
2、非叶子节点的儿子数=关键字个数
3、所有叶子节点增加一个键指针
4、所有关键字都在叶子节点出现,且叶子节点本身依赖关键字大小排序
查找某个关键字时,B树可能在非叶子节点命中,B+树只有到达叶子节点才命中。
B*树是B+树的变种,B*树中非根和非叶子节点增加指向兄弟的指针。
B*树中的非叶子节点增加指向兄弟的指针,B*树种非叶子节点关键字个数>2m/3,即块的最低利用率为2/3,B+树为1/2
B+树比B-树更适合OS文件索引和数据库索引


查询效率一样高效





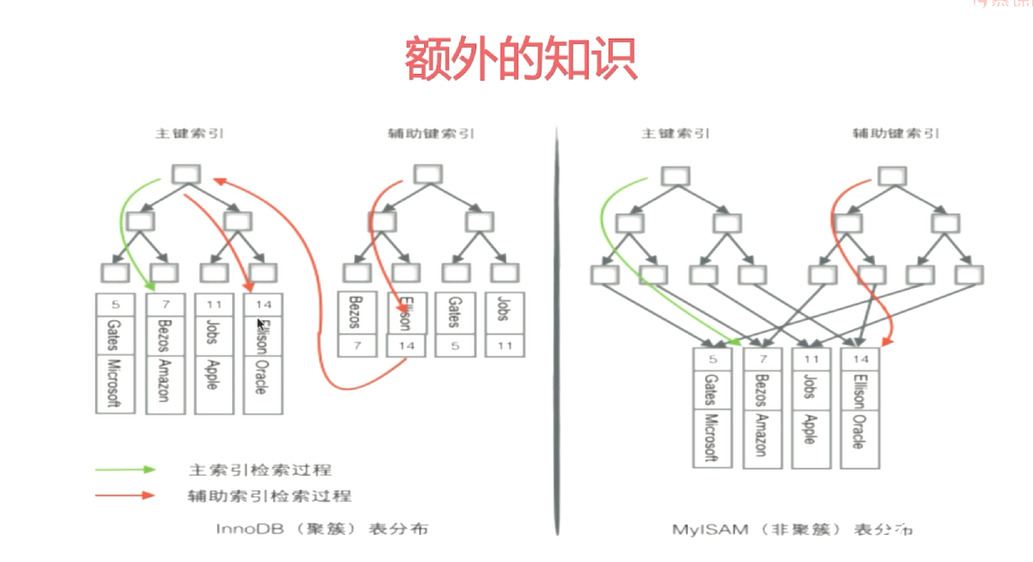
innodb索引和数据存在一起,isam索引和数据分开存储



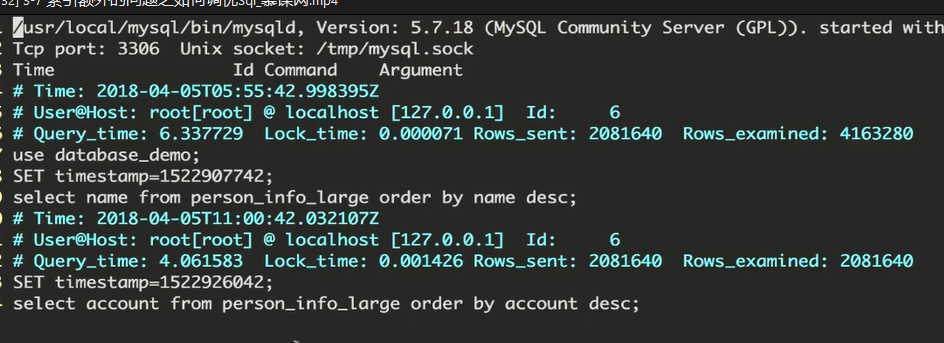
有时候改sql无法满足业务就需要加索引了。


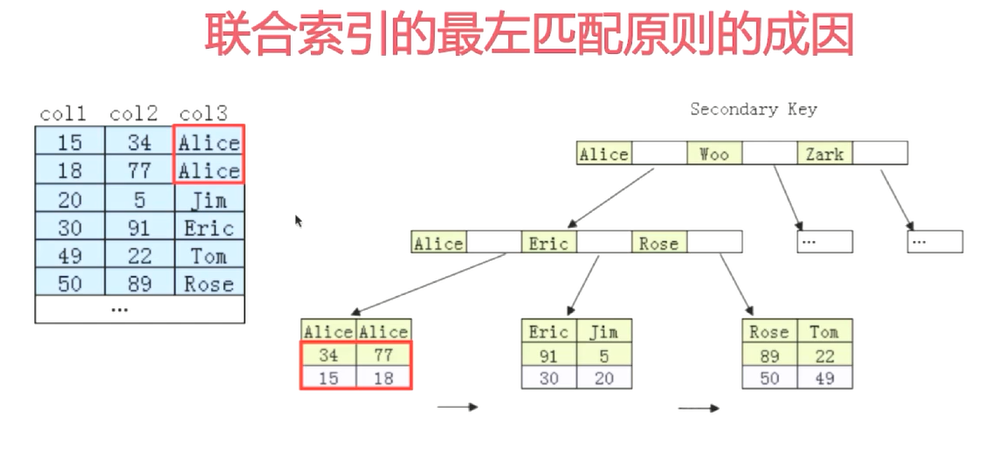
第一个有序第二个就无序了鸭
单单依靠col2无法去走索引啊。


isam会对select加读锁,其他加写锁
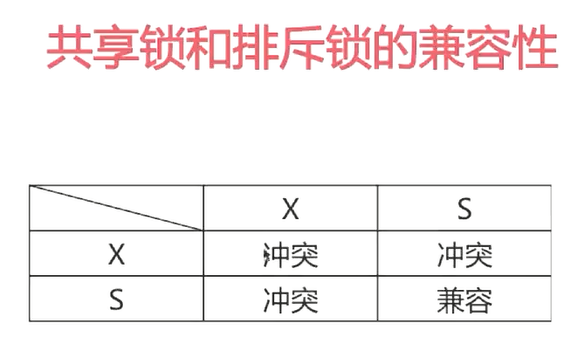
读锁又称共享锁
写锁又是排他锁
上了共享锁之后依然支持上共享锁,但不支持上排他锁。
上了排他锁,其他都不允许。
select 语句也可以上排他锁,在末尾加上for update就行。
下面看看innodb情况

innodb默认没加读锁

默认是行锁。
当不走索引默认是表锁
锁的粒度越细代价越高,innodb的开销更大
1、MyIsam不支持事务,适用于查询频繁,增删改少的场景。mysql默认的引擎。
2、innodb使用于增删查改都很频繁的,可靠性要求比较高的,支持事务,自动灾难恢复,行级锁。
3、memory出发点是速度,采用的存储介质是内存。
4、merge一组myisam表的组合。
Myisam:不支持事务行级锁和外键约束。所以当执行 insert 和 update 时,执行写操作 时,要锁定整个表,所以效率低。但是它保存了表的行数,执行 select count(*) from table 时,不需要全表扫描,而是直接读取保存的值。所以若读操作远远多于写操作,并且不需要 事务,myisam 是首选。 Innodb:支持事务、行级锁和外键,mysql 运行时,Innodb 会在内存中建立缓冲池,用 于缓冲数据和索引。不保存表的行数,执行 select count(*) from table 时要全表扫描。写不锁 定全表,高效并发时效率高。




乐观锁一般是增加时间标识
版本时间一样就提交更新否则错误


数据库事务是ACID
聚集索引的叶节点是数据节点,而非聚集索引的叶节点依然是索引节点,只不过有一个指针指向对应的数据块。
有索引不一定快的。


悲观锁大多数情况下,依赖数据库的锁机制。乐观锁大多数情况基于数据版本,记录机制实现。
数据版本,为数据增加一个版本标识,比如增加一个version字段,读数据时,将版本号一并独出,之后更新时,版本号加1,将提交数据的版本号与数据表对应记录版本号对比。若提交的大于数据库里面的,则可以更新,否则认为是过期数据。将乐观锁策略在存储过程中实现,对外只放开基于此存储过程的数据更新途径,而不是将数据表直接对外公开。
解决超卖的方法
1、乐观锁
2、队列
建立一条队列,每个请求加入队列中,然后异步获取队列数据进行处理,把多线程变成单线程,处理完一个就从队列中移除一个,因为高并发,可能一下子内存爆满。
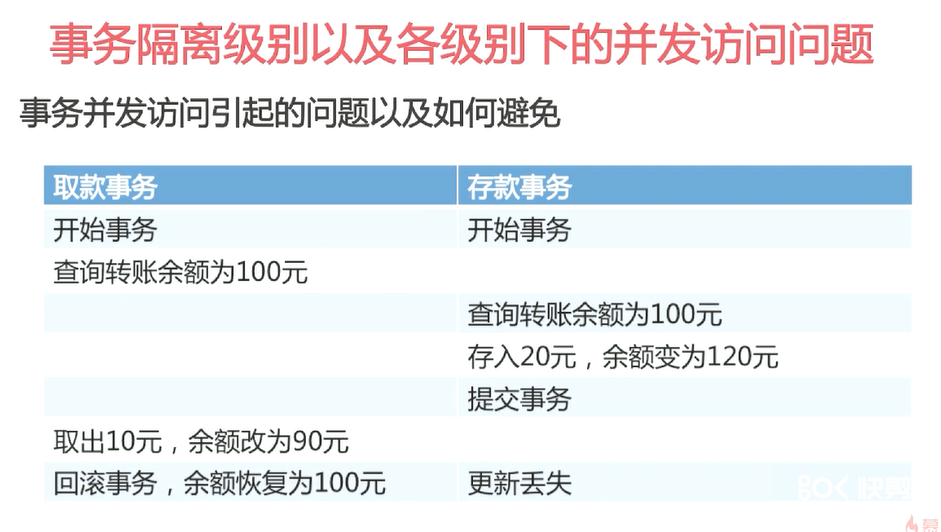
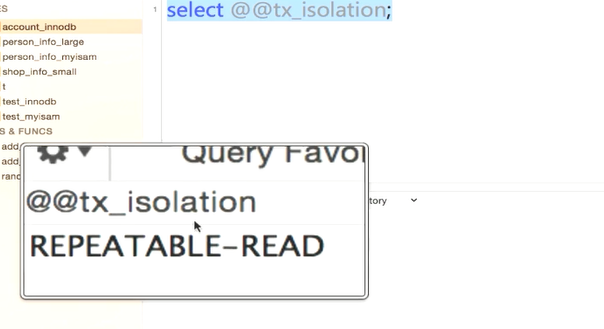
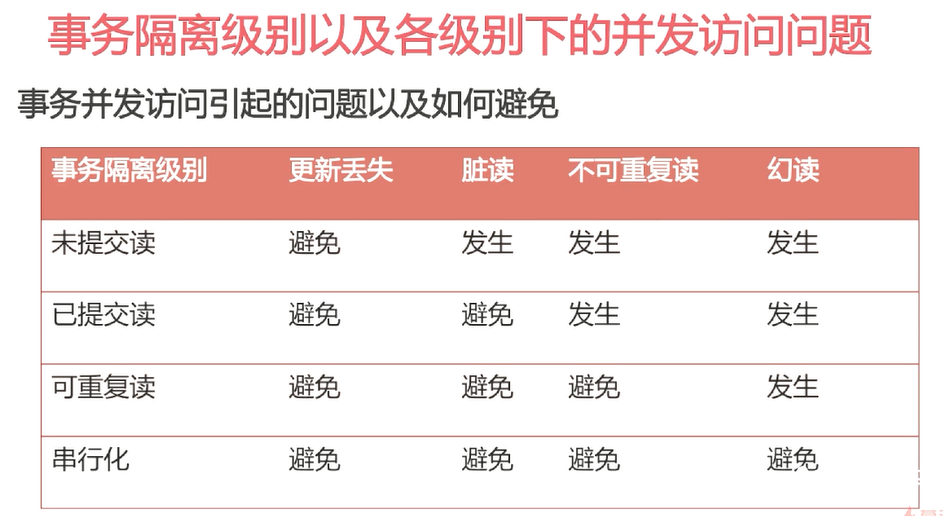
默认隔离级别

改成最低的隔离级别
避免脏读只要将隔离级别提升到read commited

再提高一个级别可以避免不可重复读
也就是可重复读级别

幻读就是突然多了一条数据
事务隔离级别到最高就可以避免
串行化事务隔离级别
默认所有都加上锁
mysql默认是可重复读
Oracle默认是rc


当前读就是加了锁的增删查改语句



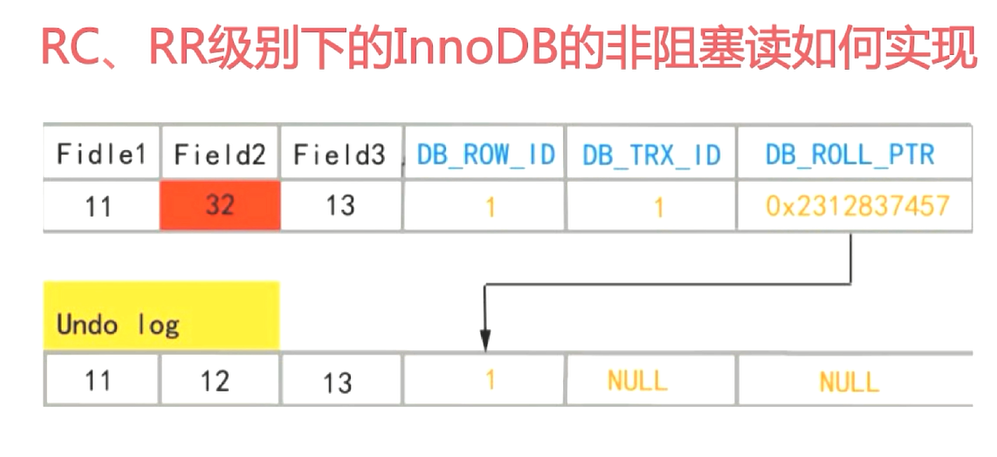
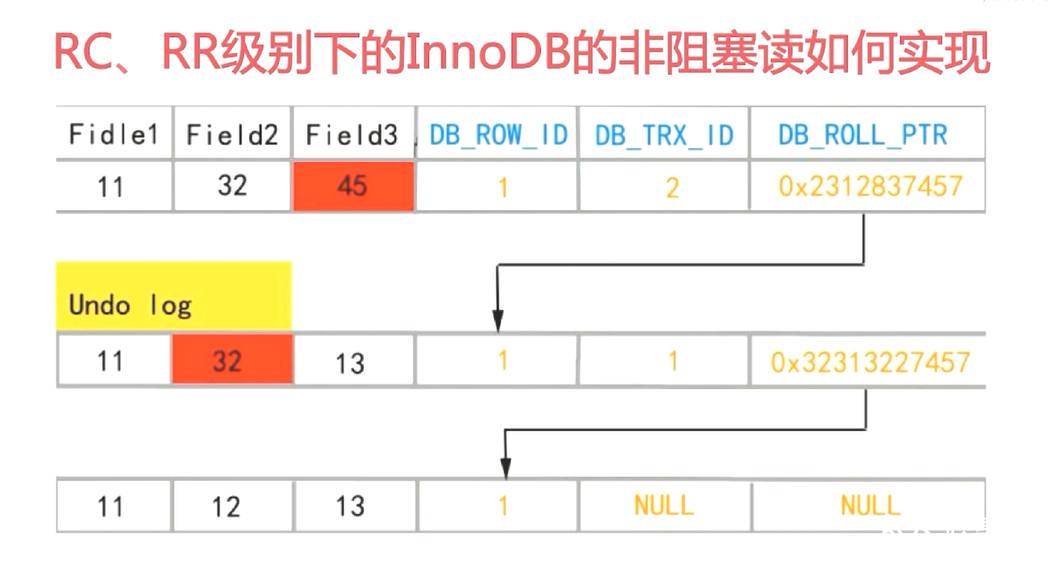

read view有一个事务活跃算法
可见性算法
当前可见最稳定的版本
第一次select快照读会创建一个readview
rc下每次都会创建一个新的快照


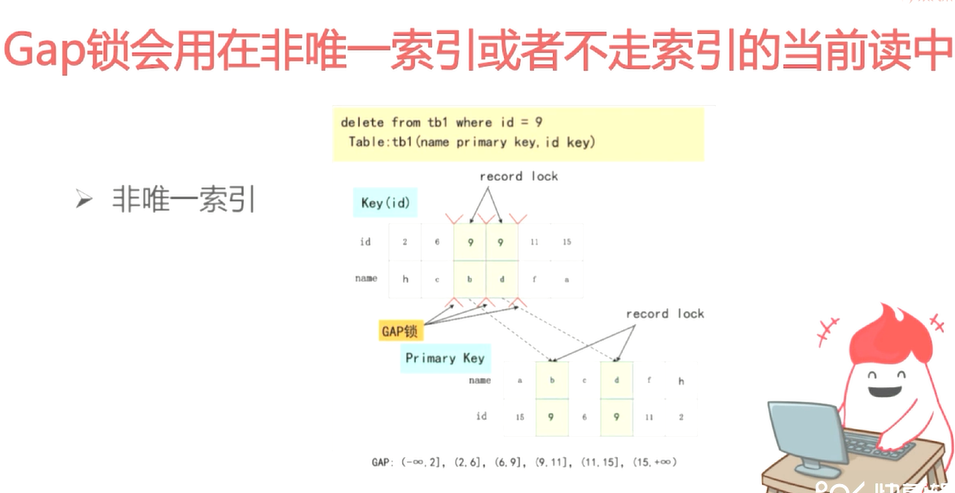
gap锁是防止插入的
防止幻读
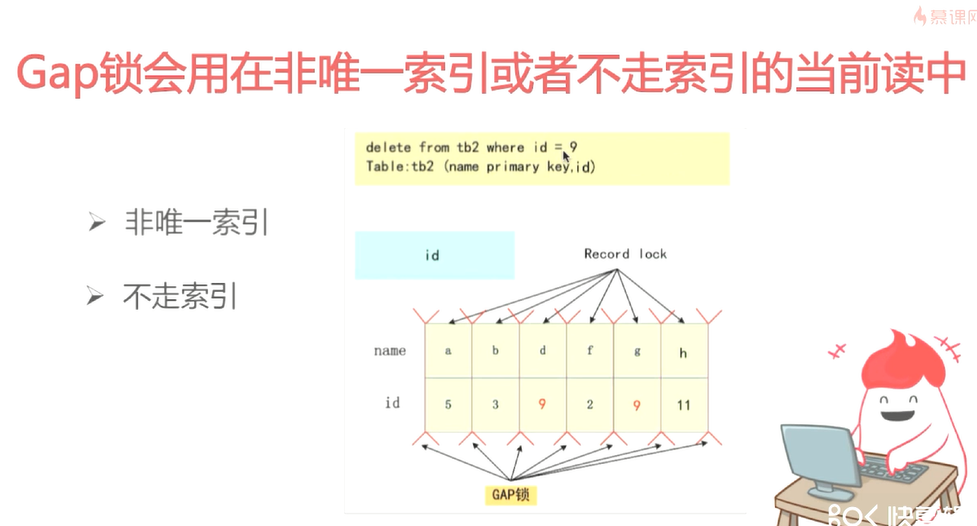
课后了解一下
redolog
undolog
binlog
关键语法
select * from tablename order by liename limit m,n(从m+1条开始,取n条数据)
mysql分页查询:客户端通过传递start(页码),limit(每页显示的条数)两个参数去分页查询数据库中的数据。
Limit m,n从m+1条开始,取n条数据
1)查询第一条到第十条 的是:select * from table limit 0,10;对应的就是第一页的数据。2)查询第 10 条到第 20 条的 是:select * from table limit 10,10;对应的就是第二页的数据。3)查询第 20 条到第 30 条的是: select * from table limit 20,10;对应的就是第三页的数据。总结:select * from table limit (页 数-1)*每页条数, 每页条数;



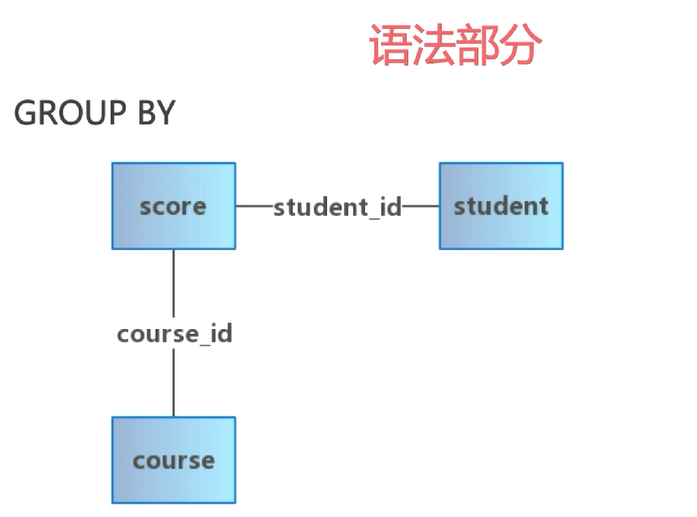
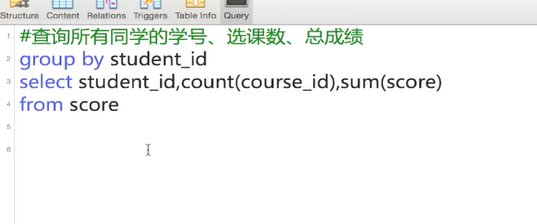
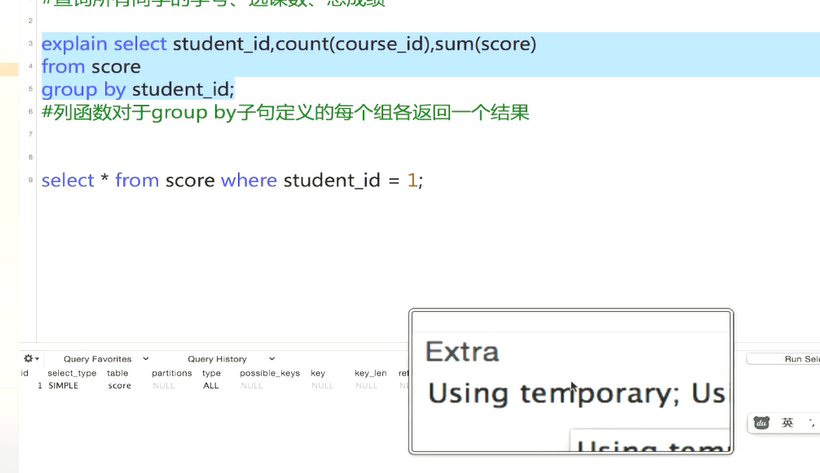
会先缓存一个表然后统计
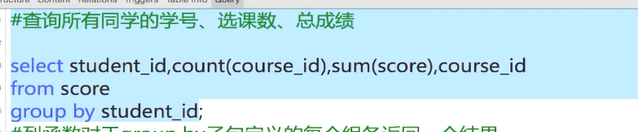
这样就会报错
不能有除了group by列里的列
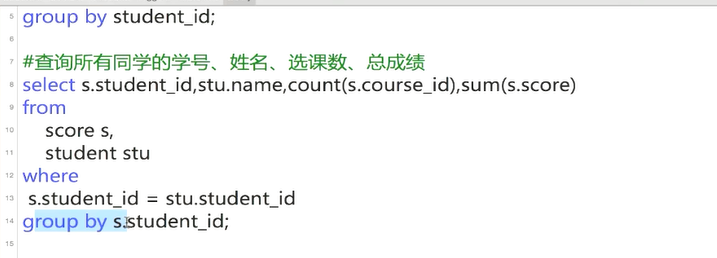
多表却可以是别的表的列

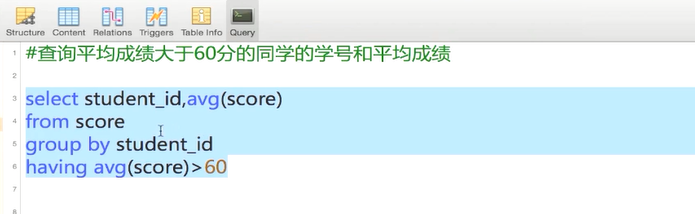
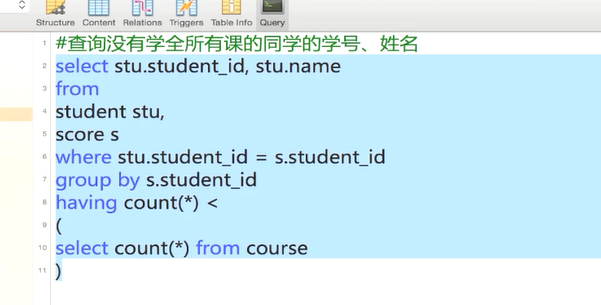
先分组再选出组中大于60 的同学
------------恢复内容结束------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号