疯狂Java讲义读书笔记08 Java集合-01Set
Java集合是一种特别有用的工具类,可用于存储数量不等的对象,并可以实现常用的数据结构,如栈队列等。除此之外,Java集合还可以保存具有映射关系的关联数组。
Java集合大致分为四类Set、List、Queue和Map四种体系
Java集合就像一种容器,可以把多个对象(实际上是对象的引用)丢进该容器中。在Java5之前,Java集合会丢失容器中所有对象的数据类型,把所有对象都当成Object类型处理。从Java5增加了泛型之后,家集合可以记住容器中的数据类型了。
集合类和数组不一样,数组元素即可以是基本类型的值,也可以是对象,而集合只能保存对象(实际上是保存对象的引用变量,但通常习惯上认为是保存对象)
Java集合类主要由两个接口派生而出:Collection和Map
Collection接口是List、Set和Queue接口的父接口,该接口里定义的方法即可以用于操作Set集合,也可以用于操作List和Queue集合。
Collection接口里定义了如下操作集合元素的方法。
add--addAll--clear--contains--containsAll--isEmpty--iterator--remove--removeAll--retainAll--size--toArray
所有的Collection实现类都重写了toString方法,该方法可以一次性的输出集合中所有的元素。
如果想要依次访问集合的每一个元素,则需要使用某种方式来遍历集合元素,下面介绍遍历集合元素的两种方法。
1、使用Lambda表达式遍历集合
Java8为Iterable接口新增了一个foreach方法,该方法所需要的参数是一个函数式接口,而Iterable接口是Collection接口的父接口,因此Collection集合也可以直接调用这个方法。
当程序调用Iterable的foreach(Consumer action)遍历集合元素时,程序会依次将集合元素传递给Consumer的accept(T t)方法(该接口中唯一的抽象方法)。正因为Consumer是函数式接口,因此可以使用Lambda表达式来遍历集合元素。

2、使用Java8增强的Iterator遍历集合元素。
Iterator接口也是Java集合框架的成员,但它与Collection系列、Map系列的集合不一样
属于迭代器
Iterator接口隐藏了各种Collection实现类的底层细节,向应用程序提供了遍历Collection集合元素的统一编程接口


从上面代码中可以看出,Iterator仅用于遍历集合,Iterator本身并不提供盛装对象的能力,如果需要创建Iterator对象,则必须有一个被迭代的集合。没有集合的Iterator如无本之木,没有存在的价值。
当使用Iterator迭代访问Collection集合元素时,Collection集合里的元素不能被改变,只有通过Iterator的remove方法删除上依次next方法返回的集合元素才可以。否则会引发java.util.ConcurrentModificationException异常。
Iterator采用的是快速失败机制(fail-fast),一旦在迭代过程中检测到集合已经被修改,程序会立即引发ConcurrentModificationException异常,而不是显示修改后的结果,这样可以避免共享资源引发的潜在问题。
3、使用lambda表达式遍历iterator

4、使用foreach遍历集合
5、使用Java8新增的Predicate操作集合
该方法会批量删除所有符合filter条件的所有元素。

使用Java8新增的Stream操作集合
Java8里面还新增了Stream、IntStream、LongStream等流式API。这些API支持串行和并行聚集操作的元素。
Stream是一个通用接口,而IntStream则代表元素类型为int的流
Java8还为上面的每个流式API提供了对应的Builder,例如Stream.Builder、IntStream.Builder,开发者可以通过这些Builder来创建对应的流。
1、使用Stream或XxxStream的builer()类方法创建该Stream对应的Builder
2、重复调用Builder的add方法向该流中添加多个元素
3、调用Builder的build方法获取对应的Stream
4、调用Stream的聚集方法


程序只要调用Collection的stream方法即可返回该集合对应的Stream,接下来就可以通过Stream编程带来的优势。
上面程序中最后一段粗体字代码先调用Collection对象的stream方法将集合转换为Stream对象,然后调用Stream对象的mapToInt方法将其转换成IntSream。
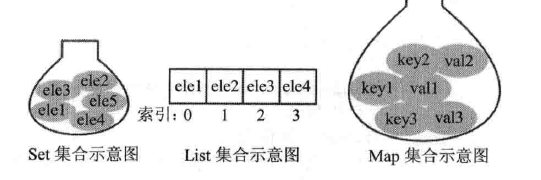
Set集合
这个集合类似于一个罐子,程序可以依次将多个对象丢进去,也记不住元素的顺序。
Set集合与Collection集合基本相同,没有提供任何额外的方法。实际上Set就是Collection,只有行为略有不同(Set不允许包含重复元素)
set集合不允许包含相同的元素,如果试图把两个相同的元素加入同一个set集合中,则增加操作失败,add方法返回false。且新元素不会被加入。
上面介绍的是Set集合的通用知识,因此完全适合后面介绍的HashSet、TreeSet、EnumSet三个实现类,只是三个实现类还各有特色。
HashSet是set接口的典型实现,大多数时候,使用set集合就是使用这个实现类。HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。
HashSet具有以下特点
不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也可能发生变化。
HashSet不是同步的,如果多个线程同时访问一个HashSet,假设有两个或两个以上的 线程同时修改了HashSet集合时,则必须通过代码来保证其同步
集合的值可以是null
当向hashset中存入一个元素时,hashset会调用该对象的hashCode方法来得到该对象的hashCode值,然后根据该hashCode值决定该对象在HashSet中的存储位置。 如果有两个元素equal相等,但是hashcode不等,hashset会将它们存储在不同位置,依然可以添加成功。
也就是说hashset判断两个元素相等的标准是两个对象通过equals相等并且两个对象通过hashcode返回值也相等。
如果两个对象的hashcode方法返回的hashcode值相同,但它们通过equals方法比较返回false时会更麻烦,因为实际上会在这个位置用链式结构保存多个对象;而HashSet访问集合元素时也是根据元素的hashCode值来快速定位的,如果HashSet中两个以上的元素具有相同的hashCode值,将会导致性能下降。
HashSet中每个能存储元素的槽位,通常称为桶。如果有多个元素的hashcode相等,但是equals方法返回false就需要在桶里放多个元素,这样会导致性能下降。
下面给出重写hashcode方法的基本规则
1、在程序运行过程中,同一个对象多次调用hashcode方法应该返回相同的值。
2、当两个对象通过equals方法比较返回true时,这两个对象的hashcode方法应该返回相等的值。
3、对象中用作equals方法比较标准的实例变量都应该用于计算hashCode中。
下面给出重写hashCode方法的一般步骤
1、把对象内每个有意义的实例变量计算出一个int类型的hashcode值。
2、用第一步计算出来的多个hashcode值组合计算出一个hashcode值返回。
当向hashset中添加可变对象时,必须十分小心,如果修改hashset集合中的对象,有可能导致该对象与集合中其他对象相等,从而导致hashset无法准确访问该对象。
LinkedHashSet类
HashSet还有一个子类LinkedHashSet。LinkedHashSet集合也是根据元素的hashcode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入顺序来保存的。
也就是说,当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素
LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
虽然LinkedHashSet使用了链表记录集合元素的添加顺序,但是LinkedHashSet依然是HashSet,因此它依然不允许集合元素重复。
TreeSet类
TreeSet是SortedSet接口的实现类,正如SortedSet名字所暗示的,TreeSet可以确保集合元素处于排序状态。
与HashSet集合相比,TreeSet还提供了如下几个额外的方法。
Comparator comparator() 如果TreeSet采用了定制顺序,则该方法返回定制排序所用的comparator,如果TreeSet采用了自然排序,则返回null。
first()返回第一个元素
last()返回最后一个元素
lower(Object e)返回集合中位于指定元素之前的元素
higher(Object e)返回集合中位于指定元素之后的元素
SortedSet subSet(Object fromElement,Object toElement)返回此Set的子集合,范围从fromElement到toElement
SortedSet headSet(Object toElement)返回此Set的子集,由小于toElement的元素组成
SortedSet tailSet(Object fromElement)返回此Set的子集,由大于或等于fromElement的元素组成
表面上看起来这些方法很多,其实它们很简单,因为TreeSet中的元素是有序的,所以增加了访问第一个,前一个,后一个,最后一个元素的方法,并提供了三个从TreeSet中截取子set的方法。
treeset采用红黑树的数据结构来存储集合元素。那么TreeSet进行排序的规则是怎么样的呢?TreeSet支持两种排序方法:自然排序和定制排序。在默认情况下,TreeSet采用自然排序。
1、自然排序
TreeSet会调用集合元素的compareTo方法来比较元素之间的大小关系,然后将集合按升序排列,这种方式就是自然排序。
Java提供了一个Comparator接口,该接口里面定义了一个compareTo方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类就可以比较大小。当一个对象调用该方法与另一个对象进行比较是,例如obj1.compareTo(obj2),如果该方法返回0,则表面这两个对象相等,如果返回一个正整数则表面obj1大于obj2,如果返回一个负整数,则表面obj1小于obj2
Java的一些常用类已经实现了Comparable接口,并提供了比较大小的标准。下面是实现了Comparable接口的常用类

试图将一个对象添加到TreeSet时,该对象必须实现Comparable接口,否则程序就会抛出异常。
如果希望TreeSet正常运作,只能添加同一种类型的对象。
如果需要实现定制排序,则需要在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联。由该Comparator对象负责排序逻辑,因为是一个函数式接口,所以可以用lambda表达式来代替Comparator对象。
上面程序中粗体字是Comparator的lambda表达式,它负责ts集合的排序。所以当把M对象添加到ts集合中时,无须M类实现Comparator接口,因为此时TreeSet无需通过M对象本身来比较大小,而是由与TreeSet关联的Lambda表达式来负责集合元素的排序
EnumSet类
EnumSet是一个专门为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式或隐式地指定。EnumSet的集合也是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序。
EnumSet在内部以位向量的形式存储,这种存储形式非常紧凑高效。因此EnumSet对象占用的内存很小,而且运行效率很好,尤其是进行批量操作的时候(如调用containsAll和retainAll方法)如果其参数也是EnumSet集合,则该批量操作的执行速度也非常快。
不允许插入null元素,如果试图插入null元素,EnumSet将抛出NullPointerException

各Set实现类的性能分析
HashSet和TreeSet是Set的两个典型实现,到底如何选择HashSet和TreeSet呢》HashSet的性能就是比TreeSet好,特别是最常用的添加、查询元素等操作,因为TreeSet需要额外的红黑树算法来维护集合元素的次序。只有当需要一个保持排序的Set时才应该使用TreeSet,否则都应该使用HashSet
HashSet还有一个子类,LinkedHashSet,对于普通插入删除,LinkedHashSet比HashSet慢一点,这是由于维护链表所带来的额外开销造成的,但是遍历LinkedHashSet会更好
EnumSet是性能最好的,但是只能保存同一个枚举类的枚举值作为集合元素
必须指出的是,Set的三个实现类,都不是线程安全的,可以通过Collections工具类的synchronizedSortedSet方法来包装集合类,此操作最好在创建时进行。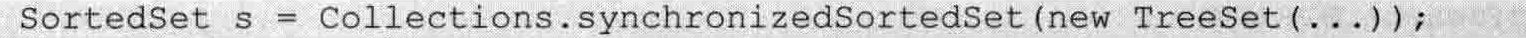

 浙公网安备 33010602011771号
浙公网安备 33010602011771号