Java基础知识_ConcurrentHashMap
一、ConCurrentHashMap剖析
1.1 初识ConCurrentHashMap
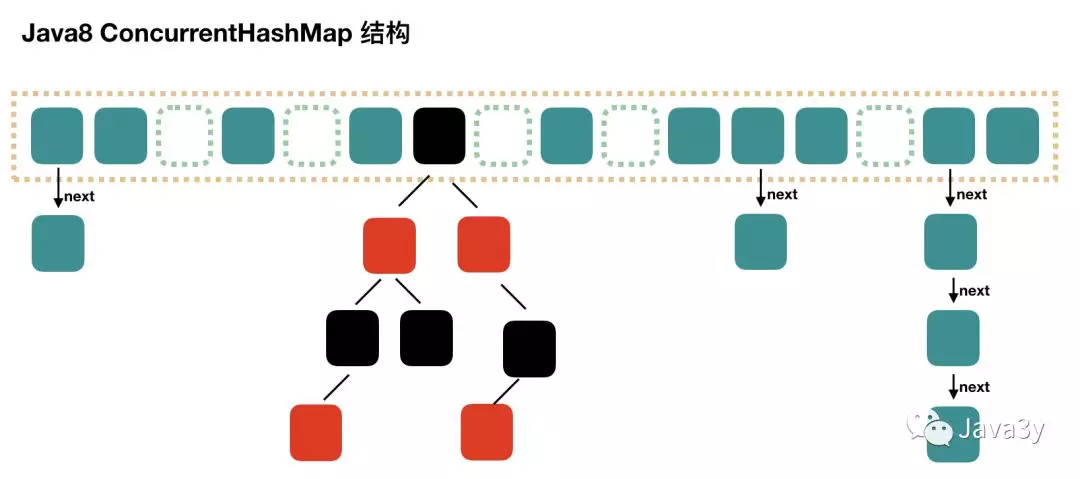
ConCurrentHashMap的底层是散列表+红黑树,与HashMap是一样的。
从前面的章节可以发现,最快了解一个类是干嘛的,我们看源码的顶部注释就可以了。
1 /** 2 * A hash table supporting full concurrency of retrievals and 3 * high expected concurrency for updates. This class obeys the 4 * same functional specification as {@link java.util.Hashtable}, and 5 * includes versions of methods corresponding to each method of 6 * {@code Hashtable}. However, even though all operations are 7 * thread-safe, retrieval operations do <em>not</em> entail locking, 8 * and there is <em>not</em> any support for locking the entire table 9 * in a way that prevents all access. This class is fully 10 * interoperable with {@code Hashtable} in programs that rely on its 11 * thread safety but not on its synchronization details. 12 * 13 * <p>Retrieval operations (including {@code get}) generally do not 14 * block, so may overlap with update operations (including {@code put} 15 * and {@code remove}). Retrievals reflect the results of the most 16 * recently <em>completed</em> update operations holding upon their 17 * onset. (More formally, an update operation for a given key bears a 18 * <em>happens-before</em> relation with any (non-null) retrieval for 19 * that key reporting the updated value.) For aggregate operations 20 * such as {@code putAll} and {@code clear}, concurrent retrievals may 21 * reflect insertion or removal of only some entries. Similarly, 22 * Iterators, Spliterators and Enumerations return elements reflecting the 23 * state of the hash table at some point at or since the creation of the 24 * iterator/enumeration. They do <em>not</em> throw {@link 25 * java.util.ConcurrentModificationException ConcurrentModificationException}. 26 * However, iterators are designed to be used by only one thread at a time. 27 * Bear in mind that the results of aggregate status methods including 28 * {@code size}, {@code isEmpty}, and {@code containsValue} are typically 29 * useful only when a map is not undergoing concurrent updates in other threads. 30 * Otherwise the results of these methods reflect transient states 31 * that may be adequate for monitoring or estimation purposes, but not 32 * for program control. 33 * 34 * <p>The table is dynamically expanded when there are too many 35 * collisions (i.e., keys that have distinct hash codes but fall into 36 * the same slot modulo the table size), with the expected average 37 * effect of maintaining roughly two bins per mapping (corresponding 38 * to a 0.75 load factor threshold for resizing). There may be much 39 * variance around this average as mappings are added and removed, but 40 * overall, this maintains a commonly accepted time/space tradeoff for 41 * hash tables. However, resizing this or any other kind of hash 42 * table may be a relatively slow operation. When possible, it is a 43 * good idea to provide a size estimate as an optional {@code 44 * initialCapacity} constructor argument. An additional optional 45 * {@code loadFactor} constructor argument provides a further means of 46 * customizing initial table capacity by specifying the table density 47 * to be used in calculating the amount of space to allocate for the 48 * given number of elements. Also, for compatibility with previous 49 * versions of this class, constructors may optionally specify an 50 * expected {@code concurrencyLevel} as an additional hint for 51 * internal sizing. Note that using many keys with exactly the same 52 * {@code hashCode()} is a sure way to slow down performance of any 53 * hash table. To ameliorate impact, when keys are {@link Comparable}, 54 * this class may use comparison order among keys to help break ties. 55 * 56 * <p>A {@link Set} projection of a ConcurrentHashMap may be created 57 * (using {@link #newKeySet()} or {@link #newKeySet(int)}), or viewed 58 * (using {@link #keySet(Object)} when only keys are of interest, and the 59 * mapped values are (perhaps transiently) not used or all take the 60 * same mapping value. 61 * 62 * <p>A ConcurrentHashMap can be used as scalable frequency map (a 63 * form of histogram or multiset) by using {@link 64 * java.util.concurrent.atomic.LongAdder} values and initializing via 65 * {@link #computeIfAbsent computeIfAbsent}. For example, to add a count 66 * to a {@code ConcurrentHashMap<String,LongAdder> freqs}, you can use 67 * {@code freqs.computeIfAbsent(k -> new LongAdder()).increment();} 68 * 69 * <p>This class and its views and iterators implement all of the 70 * <em>optional</em> methods of the {@link Map} and {@link Iterator} 71 * interfaces. 72 * 73 * <p>Like {@link Hashtable} but unlike {@link HashMap}, this class 74 * does <em>not</em> allow {@code null} to be used as a key or value. 75 * 76 * <p>ConcurrentHashMaps support a set of sequential and parallel bulk 77 * operations that, unlike most {@link Stream} methods, are designed 78 * to be safely, and often sensibly, applied even with maps that are 79 * being concurrently updated by other threads; for example, when 80 * computing a snapshot summary of the values in a shared registry. 81 * There are three kinds of operation, each with four forms, accepting 82 * functions with Keys, Values, Entries, and (Key, Value) arguments 83 * and/or return values. Because the elements of a ConcurrentHashMap 84 * are not ordered in any particular way, and may be processed in 85 * different orders in different parallel executions, the correctness 86 * of supplied functions should not depend on any ordering, or on any 87 * other objects or values that may transiently change while 88 * computation is in progress; and except for forEach actions, should 89 * ideally be side-effect-free. Bulk operations on {@link java.util.Map.Entry} 90 * objects do not support method {@code setValue}. 91 * 92 * <ul> 93 * <li> forEach: Perform a given action on each element. 94 * A variant form applies a given transformation on each element 95 * before performing the action.</li> 96 * 97 * <li> search: Return the first available non-null result of 98 * applying a given function on each element; skipping further 99 * search when a result is found.</li> 100 * 101 * <li> reduce: Accumulate each element. The supplied reduction 102 * function cannot rely on ordering (more formally, it should be 103 * both associative and commutative). There are five variants: 104 * 105 * <ul> 106 * 107 * <li> Plain reductions. (There is not a form of this method for 108 * (key, value) function arguments since there is no corresponding 109 * return type.)</li> 110 * 111 * <li> Mapped reductions that accumulate the results of a given 112 * function applied to each element.</li> 113 * 114 * <li> Reductions to scalar doubles, longs, and ints, using a 115 * given basis value.</li> 116 * 117 * </ul> 118 * </li> 119 * </ul> 120 * 121 * <p>These bulk operations accept a {@code parallelismThreshold} 122 * argument. Methods proceed sequentially if the current map size is 123 * estimated to be less than the given threshold. Using a value of 124 * {@code Long.MAX_VALUE} suppresses all parallelism. Using a value 125 * of {@code 1} results in maximal parallelism by partitioning into 126 * enough subtasks to fully utilize the {@link 127 * ForkJoinPool#commonPool()} that is used for all parallel 128 * computations. Normally, you would initially choose one of these 129 * extreme values, and then measure performance of using in-between 130 * values that trade off overhead versus throughput. 131 * 132 * <p>The concurrency properties of bulk operations follow 133 * from those of ConcurrentHashMap: Any non-null result returned 134 * from {@code get(key)} and related access methods bears a 135 * happens-before relation with the associated insertion or 136 * update. The result of any bulk operation reflects the 137 * composition of these per-element relations (but is not 138 * necessarily atomic with respect to the map as a whole unless it 139 * is somehow known to be quiescent). Conversely, because keys 140 * and values in the map are never null, null serves as a reliable 141 * atomic indicator of the current lack of any result. To 142 * maintain this property, null serves as an implicit basis for 143 * all non-scalar reduction operations. For the double, long, and 144 * int versions, the basis should be one that, when combined with 145 * any other value, returns that other value (more formally, it 146 * should be the identity element for the reduction). Most common 147 * reductions have these properties; for example, computing a sum 148 * with basis 0 or a minimum with basis MAX_VALUE. 149 * 150 * <p>Search and transformation functions provided as arguments 151 * should similarly return null to indicate the lack of any result 152 * (in which case it is not used). In the case of mapped 153 * reductions, this also enables transformations to serve as 154 * filters, returning null (or, in the case of primitive 155 * specializations, the identity basis) if the element should not 156 * be combined. You can create compound transformations and 157 * filterings by composing them yourself under this "null means 158 * there is nothing there now" rule before using them in search or 159 * reduce operations. 160 * 161 * <p>Methods accepting and/or returning Entry arguments maintain 162 * key-value associations. They may be useful for example when 163 * finding the key for the greatest value. Note that "plain" Entry 164 * arguments can be supplied using {@code new 165 * AbstractMap.SimpleEntry(k,v)}. 166 * 167 * <p>Bulk operations may complete abruptly, throwing an 168 * exception encountered in the application of a supplied 169 * function. Bear in mind when handling such exceptions that other 170 * concurrently executing functions could also have thrown 171 * exceptions, or would have done so if the first exception had 172 * not occurred. 173 * 174 * <p>Speedups for parallel compared to sequential forms are common 175 * but not guaranteed. Parallel operations involving brief functions 176 * on small maps may execute more slowly than sequential forms if the 177 * underlying work to parallelize the computation is more expensive 178 * than the computation itself. Similarly, parallelization may not 179 * lead to much actual parallelism if all processors are busy 180 * performing unrelated tasks. 181 * 182 * <p>All arguments to all task methods must be non-null. 183 * 184 * <p>This class is a member of the 185 * <a href="{@docRoot}/../technotes/guides/collections/index.html"> 186 * Java Collections Framework</a>. 187 * 188 * @since 1.5 189 * @author Doug Lea 190 * @param <K> the type of keys maintained by this map 191 * @param <V> the type of mapped values 192 */
支持高并发的检索和更新,线程是安全的,并且检索操作是不再加锁的。get方法非阻塞,检索出来结果是最新设置的值,一些关于统计的方法,最好在单线程的环境下使用,不然它只满足监控或估算的目的,在项目中使用它是无法准确返回的,当有太多散列碰撞的时候,这表会动态增加,再散列(扩容)是一件非常消耗资源的事情,最好是提取计算放入容器中有多少元素来手动初始化装载因子和初始容量,这样会好很多。
能够用来频繁改变的Map,通过LongAdder,实现了Map和Iterator的所有方法,ConCurrentHashMap不允许key或value为null,ConCurrentHashMap提供方法支持批量操作
简单总结
jdk1.8的底层是散列表+红黑树
ConCurrentHashMap支持高并发的访问和更新,它是线程安全的
检索操作不用加锁,get方法是非阻塞的
key和value都不允许为null
1.2 JDK1.7底层实现
上面指明的是jdk1.8底层是:散列表+红黑树,也就意味着jdk1.7的底层根jdk1.8是不同的~
jdk1.7的底层是:segments+HashEntry数组:
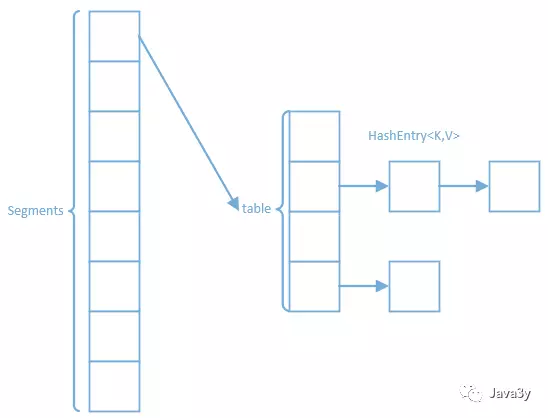
Segment继承了ReentrantLock,每个片段都有了一个锁,叫做锁分段
1.3 有了Hashtable为啥需要ConCurrentHashMap
Hashtable是在每个方法上都加上了Synchronized完成同步,效率低下
ConCurrentHashMap通过部分加锁和利用CAS算法来实现同步
1.4CAS算法和volatile简单介绍
在看ConCurrentHashMap源码之前,我们来简单讲讲CAS算法和volatile关键字
CAS(比较与交换,Compare and swap)是一种有名的无锁算法
CAS有3个操作数
内存值V
旧的预期值A
要修改的新值B
当前仅当预期值A和内存值V相同的时候,将内存值V修改成B,否则什么都不做
当多个线程尝试使用CAS同时更新同一个变量的时候,只有一个线程能更新变量的值(A和内存值V相同时,将内存值V修改为B),而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并且可以再次尝试(否则什么都不做)
看了上面的描述应该很容易理解了,先比较是否相等,如果相等则替换(CAS算法)
接下来我们来看看volatile关键字
volatile经典总结:volatile仅仅用来保证该变量对所有的线程的可见性,但不保证原子性。
我们将其拆开来解释一下:
保证该变量对所有线程的可见性
在多线程的环境下:当这个变量修改时,所有线程都会知道该变量被修改了,也就是所谓的可见性
不保证原子性
修改变量实质上在JVM分为好几步,它是不安全的。
1.5 ConCurrentHashMap
域对象有这么几个:
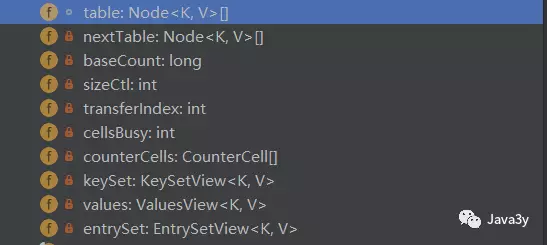
我们来简单看看他们是啥玩意
1 /* ---------------- Fields -------------- */ 2 3 /** 4 * The array of bins. Lazily initialized upon first insertion. 5 * Size is always a power of two. Accessed directly by iterators. 6 */ 7 transient volatile Node<K,V>[] table; 8 9 /** 10 * The next table to use; non-null only while resizing. 11 */ 12 private transient volatile Node<K,V>[] nextTable; 13 14 /** 15 * Base counter value, used mainly when there is no contention, 16 * but also as a fallback during table initialization 17 * races. Updated via CAS. 18 */ 19 private transient volatile long baseCount; 20 21 /** 22 * Table initialization and resizing control. When negative, the 23 * table is being initialized or resized: -1 for initialization, 24 * else -(1 + the number of active resizing threads). Otherwise, 25 * when table is null, holds the initial table size to use upon 26 * creation, or 0 for default. After initialization, holds the 27 * next element count value upon which to resize the table. 28 */ 29 private transient volatile int sizeCtl; 30 31 /** 32 * The next table index (plus one) to split while resizing. 33 */ 34 private transient volatile int transferIndex; 35 36 /** 37 * Spinlock (locked via CAS) used when resizing and/or creating CounterCells. 38 */ 39 private transient volatile int cellsBusy; 40 41 /** 42 * Table of counter cells. When non-null, size is a power of 2. 43 */ 44 private transient volatile CounterCell[] counterCells; 45 46 // views 47 private transient KeySetView<K,V> keySet; 48 private transient ValuesView<K,V> values; 49 private transient EntrySetView<K,V> entrySet;
table是散列表,迭代器迭代的就是它了。
1.6 ConCurrentHashMap构造方法
ConcurrentHashMap的构造方法有五个
默认初始容量是16,可以直接指定初始容量,这样可以不用过度依赖动态扩容了,也可以指定估计的并发线程数量。
1 public ConcurrentHashMap() { 2 } 3 4 /** 5 * Creates a new, empty map with an initial table size 6 * accommodating the specified number of elements without the need 7 * to dynamically resize. 8 * 9 * @param initialCapacity The implementation performs internal 10 * sizing to accommodate this many elements. 11 * @throws IllegalArgumentException if the initial capacity of 12 * elements is negative 13 */ 14 public ConcurrentHashMap(int initialCapacity) { 15 if (initialCapacity < 0) 16 throw new IllegalArgumentException(); 17 int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ? 18 MAXIMUM_CAPACITY : 19 tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)); 20 this.sizeCtl = cap; 21 } 22 23 /** 24 * Creates a new map with the same mappings as the given map. 25 * 26 * @param m the map 27 */ 28 public ConcurrentHashMap(Map<? extends K, ? extends V> m) { 29 this.sizeCtl = DEFAULT_CAPACITY; 30 putAll(m); 31 } 32 33 /** 34 * Creates a new, empty map with an initial table size based on 35 * the given number of elements ({@code initialCapacity}) and 36 * initial table density ({@code loadFactor}). 37 * 38 * @param initialCapacity the initial capacity. The implementation 39 * performs internal sizing to accommodate this many elements, 40 * given the specified load factor. 41 * @param loadFactor the load factor (table density) for 42 * establishing the initial table size 43 * @throws IllegalArgumentException if the initial capacity of 44 * elements is negative or the load factor is nonpositive 45 * 46 * @since 1.6 47 */ 48 public ConcurrentHashMap(int initialCapacity, float loadFactor) { 49 this(initialCapacity, loadFactor, 1); 50 } 51 52 /** 53 * Creates a new, empty map with an initial table size based on 54 * the given number of elements ({@code initialCapacity}), table 55 * density ({@code loadFactor}), and number of concurrently 56 * updating threads ({@code concurrencyLevel}). 57 * 58 * @param initialCapacity the initial capacity. The implementation 59 * performs internal sizing to accommodate this many elements, 60 * given the specified load factor. 61 * @param loadFactor the load factor (table density) for 62 * establishing the initial table size 63 * @param concurrencyLevel the estimated number of concurrently 64 * updating threads. The implementation may use this value as 65 * a sizing hint. 66 * @throws IllegalArgumentException if the initial capacity is 67 * negative or the load factor or concurrencyLevel are 68 * nonpositive 69 */ 70 public ConcurrentHashMap(int initialCapacity, 71 float loadFactor, int concurrencyLevel) { 72 if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) 73 throw new IllegalArgumentException(); 74 if (initialCapacity < concurrencyLevel) // Use at least as many bins 75 initialCapacity = concurrencyLevel; // as estimated threads 76 long size = (long)(1.0 + (long)initialCapacity / loadFactor); 77 int cap = (size >= (long)MAXIMUM_CAPACITY) ? 78 MAXIMUM_CAPACITY : tableSizeFor((int)size); 79 this.sizeCtl = cap; 80 }
可以发现在构造方法中有几处都调用了tableSizeFor(),我们来看一下他是干什么的;
点进去之后,啊,原来我看过这个方法,在HashMap的时候。
1 private static final int tableSizeFor(int c) { 2 int n = c - 1; 3 n |= n >>> 1; 4 n |= n >>> 2; 5 n |= n >>> 4; 6 n |= n >>> 8; 7 n |= n >>> 16; 8 return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; 9 }
它就是用来获取大于参数且最接近2的整次幂的数...
赋值给sizeCtl属性也就说明了:这是下次扩容的大小
1.7 put方法
终于来到了最核心的方法之一了:put方法啦~~~~
我们先来整体看一下put方法干了什么事;
1 final V putVal(K key, V value, boolean onlyIfAbsent) { 2 if (key == null || value == null) throw new NullPointerException(); 3 int hash = spread(key.hashCode()); 4 int binCount = 0; 5 for (Node<K,V>[] tab = table;;) { 6 Node<K,V> f; int n, i, fh; 7 if (tab == null || (n = tab.length) == 0) 8 tab = initTable(); 9 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { 10 if (casTabAt(tab, i, null, 11 new Node<K,V>(hash, key, value, null))) 12 break; // no lock when adding to empty bin 13 } 14 else if ((fh = f.hash) == MOVED) 15 tab = helpTransfer(tab, f); 16 else { 17 V oldVal = null; 18 synchronized (f) { 19 if (tabAt(tab, i) == f) { 20 if (fh >= 0) { 21 binCount = 1; 22 for (Node<K,V> e = f;; ++binCount) { 23 K ek; 24 if (e.hash == hash && 25 ((ek = e.key) == key || 26 (ek != null && key.equals(ek)))) { 27 oldVal = e.val; 28 if (!onlyIfAbsent) 29 e.val = value; 30 break; 31 } 32 Node<K,V> pred = e; 33 if ((e = e.next) == null) { 34 pred.next = new Node<K,V>(hash, key, 35 value, null); 36 break; 37 } 38 } 39 } 40 else if (f instanceof TreeBin) { 41 Node<K,V> p; 42 binCount = 2; 43 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, 44 value)) != null) { 45 oldVal = p.val; 46 if (!onlyIfAbsent) 47 p.val = value; 48 } 49 } 50 } 51 } 52 if (binCount != 0) { 53 if (binCount >= TREEIFY_THRESHOLD) 54 treeifyBin(tab, i); 55 if (oldVal != null) 56 return oldVal; 57 break; 58 } 59 } 60 } 61 addCount(1L, binCount); 62 return null; 63 }
对key进行散列,获取哈希值,当表为null时,进行初始化。如果这个哈希值直接可以存到数组,就直接插入进去,插入的位置是表的连接点时,那就表明在扩容,帮助当前线程扩容,链表长度大于8,链表结构转化成树形结构。
接下来我们看看初始化散列表的时候干了什么事:initTable()
1 private final Node<K,V>[] initTable() { 2 Node<K,V>[] tab; int sc; 3 while ((tab = table) == null || tab.length == 0) { 4 if ((sc = sizeCtl) < 0) 5 Thread.yield(); // lost initialization race; just spin 6 else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { 7 try { 8 if ((tab = table) == null || tab.length == 0) { 9 int n = (sc > 0) ? sc : DEFAULT_CAPACITY; 10 @SuppressWarnings("unchecked") 11 Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; 12 table = tab = nt; 13 sc = n - (n >>> 2); 14 } 15 } finally { 16 sizeCtl = sc; 17 } 18 break; 19 } 20 } 21 return tab; 22 }
有线程正在初始化,告诉其他线程不要进来了。设置为-1,说明本线程正在初始化。相当于设置一个0.75*n设置一个扩容的阈值
只让一个线程对散列表进行初始化!
1.8 get方法
从顶部注释我们可以读到,get方法是不用加锁的,是非阻塞的。
我们可以发现,Node节点是重写的设置了volatile关键字,致使它每次获取的都是最新的值
1 static class Node<K,V> implements Map.Entry<K,V> { 2 final int hash; 3 final K key; 4 volatile V val; 5 volatile Node<K,V> next; 6 7 Node(int hash, K key, V val, Node<K,V> next) { 8 this.hash = hash; 9 this.key = key; 10 this.val = val; 11 this.next = next; 12 } 13 14 public final K getKey() { return key; } 15 public final V getValue() { return val; } 16 public final int hashCode() { return key.hashCode() ^ val.hashCode(); } 17 public final String toString(){ return key + "=" + val; } 18 public final V setValue(V value) { 19 throw new UnsupportedOperationException(); 20 } 21 22 public final boolean equals(Object o) { 23 Object k, v, u; Map.Entry<?,?> e; 24 return ((o instanceof Map.Entry) && 25 (k = (e = (Map.Entry<?,?>)o).getKey()) != null && 26 (v = e.getValue()) != null && 27 (k == key || k.equals(key)) && 28 (v == (u = val) || v.equals(u))); 29 }
在桶子上就直接获取,和在树形结构上以及在链表上
1 public V get(Object key) { 2 Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; 3 int h = spread(key.hashCode()); 4 if ((tab = table) != null && (n = tab.length) > 0 && 5 (e = tabAt(tab, (n - 1) & h)) != null) { 6 if ((eh = e.hash) == h) { 7 if ((ek = e.key) == key || (ek != null && key.equals(ek))) 8 return e.val; 9 } 10 else if (eh < 0) 11 return (p = e.find(h, key)) != null ? p.val : null; 12 while ((e = e.next) != null) { 13 if (e.hash == h && 14 ((ek = e.key) == key || (ek != null && key.equals(ek)))) 15 return e.val; 16 } 17 } 18 return null; 19 }
二、总结
上面简单介绍了ConcurrentHashMap的核心知识,还有很多知识点都没提到
下面简单总结一下
1、底层结构是散列表(数组+链表)+红黑树,这一点是和HashMap是一样的
2、Hashtable是将所有方法实现同步,效率低下。而ConcurrentHashMap作为一个高并发容器,它是通过部分锁定+CAS算法来实现线程安全的。CAS算法也可以认为是乐观锁的一种。
3、在高并发的环境下,统计数据(计算size)其实是无意义的,因为下一时刻size值就变化了。
4、get方法是非阻塞,无锁的。重写Node类,通过volatile修饰next来实现每次获取的都是最新设置的值
5、ConcurrentHashMap的key和value都不能为null

 浙公网安备 33010602011771号
浙公网安备 33010602011771号