数据血缘图在数据错误追溯中的应用指南
当终端用户发现数据报告或仪表板中存在错误数据时,架构师可以利用数据血缘图进行系统化的“逆向工程”,快速定位故障的系统、转换过程和时间点。
1. 架构师追溯错误的三维定位模型
数据血缘图通过结构化的方式连接了数据流动的三个关键维度,实现了对错误根源的快速定位:
|
维度 |
对应血缘图要素 |
解决的问题 |
|---|---|---|
|
系统 (System) |
节点 (Nodes) |
数据从哪个应用程序或数据库流出? |
|
转换 (Transformation) |
边 (Edges) 上的元数据 |
哪个 ETL/ELT 逻辑或业务规则引入了错误? |
|
时间 (Time) |
转换作业时间戳 / 版本控制 |
错误数据是在哪个批次或时间窗口首次出现的? |
2. 故障追溯的系统化步骤
架构师应从下游(用户可见的错误点)开始,沿着血缘图进行逆向追溯,直到找到第一个引入错误的环节。
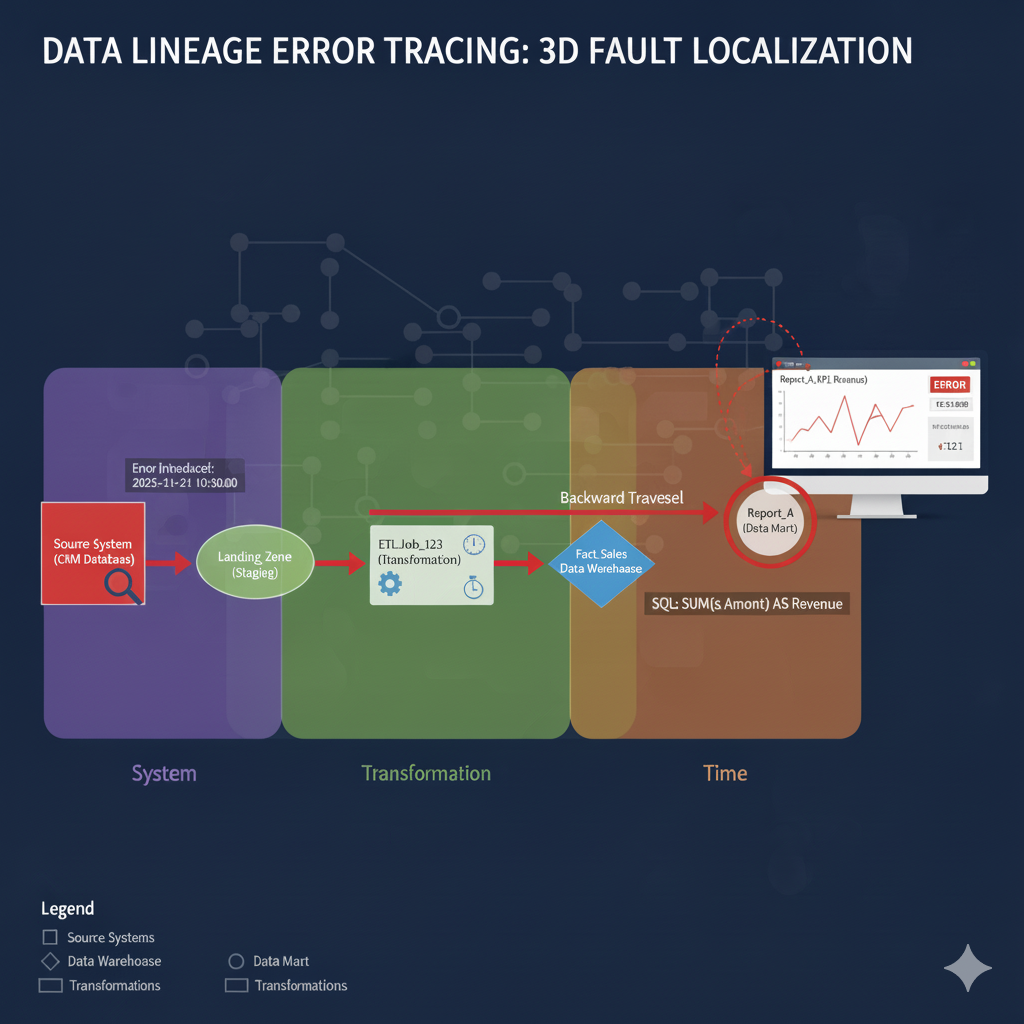
步骤 1: 确定错误的起点和终点
-
确定起点 (Downstream): 从用户报告的最终指标或字段(例如:
Report_A.KPI_Revenue字段值错误)作为追溯的起点。 -
定位血缘图中的目标节点: 在血缘图中定位到该目标字段所在的表(Node)。
步骤 2: 逆向遍历血缘路径 (Backward Traversal)
-
反向追溯: 从目标字段开始,沿着血缘图的反向路径(即从下游到上游)一步步回溯。
-
检查相邻转换: 追溯到上一个转换(Edge)。该转换的元数据会记录**哪个作业(Job ID)**执行了数据移动或计算。
步骤 3: 隔离故障系统和转换逻辑
-
系统定位: 检查该转换的上游节点,即可确定数据来源的上一个系统(System)(例如:从数据仓库 (DW) 到数据集市 (Mart) 的 ETL 过程)。
-
转换逻辑审查:
-
错误的转换过程 (Transformation): 调取该作业(Edge)对应的具体转换代码(如 SQL 脚本、存储过程或自定义 Python 脚本)。
-
分析: 重点审查
JOIN条件、WHERE过滤逻辑、聚合函数 (SUM,AVG) 或复杂的业务规则实现。如果发现逻辑缺陷,则该转换即为根源。
-
步骤 4: 利用时间戳进行精确时间点定位
如果转换逻辑没有问题,说明错误可能来源于上游的原始数据。此时需要利用血缘元数据中的时间信息。
-
数据生成时间: 查看当前出错数据所依赖的上游输入数据的生成时间或加载时间。
-
版本对比: 如果血缘系统支持,可以对比错误发生时间前后的数据版本,确定错误数据是**在哪个时间点(Time Point)**首次进入数据湖或数据仓库的。
-
锁定时间窗口: 例如,如果追溯到原始事务表,发现错误值是在 2025 年 11 月 21 日 10:30 的批次中引入的,那么故障根源就锁定在这个时间点的源系统操作。
步骤 5: 最终定位根源
持续逆向追溯,直到找到以下任一环节:
-
源系统 (Source System): 发现原始数据本身就存在问题(例如,应用程序的 Bug 导致写入错误值)。
-
首次摄取/清洗 (Initial Ingestion/Cleaning): 发现第一次将数据从源系统导入数据平台的作业中存在错误配置或初级转换逻辑错误。
3. 血缘系统必备的技术能力
为了高效地执行上述追溯过程,数据血缘图工具必须具备以下关键技术能力:
-
字段级别血缘 (Column-Level Lineage): 必须能够显示字段到字段的精确映射,而不仅仅是表到表的映射。例如,展示
Source.Amount字段如何被转换为Target.Revenue。 -
时间旅行与版本控制 (Time Travel & Versioning): 能够查看特定历史时间点的血缘关系和转换逻辑。这对于对比“正确状态”和“错误状态”至关重要。
-
自动解析 (Automated Parsing): 能够自动解析 ETL 工具、SQL 查询、存储过程和代码中的转换逻辑,并将其映射到血缘图的边上,确保血缘图的准确性和实时性。
-
可视化与搜索 (Visualization & Search): 提供直观的图形界面,支持快速搜索数据资产,并能动态过滤和高亮显示特定路径,避免在复杂的图中迷失。
4. 如何选择血缘系统工具
目前市场上数据血缘图(Data Lineage Graph)工具种类繁多,大致可以分为以下几类,它们在功能、部署和侧重点上有所不同:
1. 独立/专业数据治理平台 (Dedicated Data Governance/Lineage Platforms)
这类工具专注于元数据管理、数据质量和血缘分析,功能强大且深入。
| 工具名称 | 侧重功能 | 特点 |
| Informatica Enterprise Data Catalog | 全面的数据目录、字段级血缘 | 市场领导者,支持复杂 ETL 工具和系统,自动化解析能力强。 |
| Collibra Data Governance Center | 数据治理、数据目录、业务血缘 | 强调业务上下文和数据所有权,血缘图与业务术语高度集成。 |
| MANTA Automated Data Lineage | 深度、自动化血缘解析 | 专注于解析各种复杂的代码和脚本(SQL、存储过程、ETL工具),提供高精度血缘。 |
| Atlan | 现代数据目录、数据协作 | 结合数据血缘、数据质量和数据发现的平台,用户体验友好,面向数据团队协作。 |
2. 云服务提供商的内置工具 (Cloud Provider Built-in Tools)
主流云服务商在其数据生态系统内提供了强大的血缘和元数据管理能力,特别适合使用其原生数据服务的用户。
| 平台 | 工具名称 | 侧重功能 |
| Google Cloud | Dataplex (Data Lineage) | 自动捕获 BigQuery、Cloud Storage 和 Dataproc 等服务的数据移动和转换。 |
| AWS | AWS Glue Data Catalog | 提供了元数据和基本血缘信息,与 Glue ETL 集成。 |
| Microsoft Azure | Azure Purview (现为 Microsoft Purview) | 统一的数据治理解决方案,提供跨云和本地环境的血缘分析。 |
3. 开源和轻量级工具 (Open Source and Lightweight Tools)
这类工具适合预算有限或追求高度定制化的团队。
| 工具名称 | 侧重功能 | 特点 |
| Apache Atlas | 元数据和血缘管理框架 | 强大的开源解决方案,常与 Hadoop 生态系统(如 Hive、Spark)集成,提供 API 驱动的血缘。 |
| OpenLineage | 开放标准、血缘采集 | 作为一个 API 标准和规范,帮助数据平台和 ETL 工具标准化地发送血缘事件,实现血缘的互操作性。 |
| Amundsen | 数据发现和目录 | 由 Lyft 开源,虽然主要功能是数据目录,但通常会集成血缘展示能力。 |
选择工具时,架构师应该根据以下因素来评估:
-
数据环境复杂性: 您的数据管道有多少种技术(SQL Server, Spark, Kafka, Python, ETL tools)?工具对这些技术的解析能力如何?
-
血缘精度要求: 您需要表级血缘(粗粒度)还是字段级血缘(细粒度)?(追溯错误通常需要字段级)。
-
云策略: 如果您主要依赖某一云平台,使用其原生工具(如 Dataplex, Purview)通常集成度最高,成本效益最佳。
-
自动化程度: 工具是否能自动从您的代码和查询日志中解析血缘,还是需要手动维护?(自动化是高效追溯的关键)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号