

antlr4 入门
antlr4
本文包括:
- antlr4基本操作:下载、安装、测试
- Listener模式和Visitor模式比较
- 通过增加操作修饰文法
- antlr4 优先级、左递归及相关性
- antlr4 实现的简单计算器(java版)
基本操作
- 下载安装antlr
sudo curl -O http://www.antlr.org/download/antlr-4.7-complete.jar
alias antlr4='java -jar /usr/local/lib/antlr-4.7-complete.jar'
alias grun='java org.antlr.v4.gui.TestRig'
设置antlr4和grun别名的两句:直接写在命令行,重启就会被抹去,失去效果;推荐写在用户配置文件中(Mac OS 下
vi ~/.bash_profile,写在文件末尾即可)
- 编写一个文法,保存为hello.g4
grammar hello;
//tokens
s: 'hello' + ID;
ID: [a-z]+;
WS: [ \t\n\r]+ -> skip;
- 利用antlr生成这个文法的识别器(默认生成的识别器由java编写)
//进入hello.g4所在文件夹后执行
antlr4 hello.g4
测试字符串是否属于这个文法
在使用生成的识别器前要先编译,因为我们生成的识别器是用默认的java语言编写的,所以我们用javac来编译:
javac -g *.java。如果不编译就使用这个识别器,会发生
Can't load hello as lexer or parser的错误,原因显而易见,不再赘述
以下方式都可以用来识别字符串是否能够被这个文法识别,敲入下列命令,回车,输入要识别的字符串,以 EOF(UNIX/Mac OS下Ctrl+D,windows下Ctrl+Z)结尾
grun [文法名] [标识符] [TestRig参数]
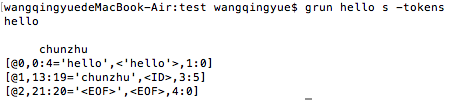
grun hello s -tokens

-
grun hello s -tree![]()
-
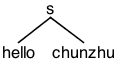
grun hello s -gui![]()
-
上面列出了常见TestRig参数,其他参数可见antlr官方文档
Listener & Visitor
- Visitor和Listener是antlr提供的两种树遍历机制。Listener是默认的机制,可以被antlr提供的遍历器对象调用;如果要用Visitor机制,在生成识别器时就需要显式说明
antlr4 -no-listener -visitor Calc.g4,并且必须显示的调用visitor方法遍历它们的子节点,在一个节点的子节点上如果忘记调用visit方法,就意味着那些子数没有得到访问
Listener
文件结构
hello.tokens
helloBaseListener.java
helloLexer.java
helloLexer.tokens
helloListener.java
helloParser.java
ParserTreeWalker类是ANTLR运行时提供的用于遍历语法分析树和触发Listener中回调方法的树遍历器。ANTLR工具根据hello.g4文法自动生成ParserTreeListener接口的子接口helloListener和默认实现helloBaseListener,其中含有针对语法中每个规则的enter和exit方法。
helloListener是语法和Listener对象之间的关键接口 public interface helloListener extends ParserTreeListener
helloBaseListener是ANTLR生成的一组空的默认实现。ANTLR内建的树遍历器会去触发在Listener中像enterProg()和exitProg()这样的一串回调方法
Visitor
文件结构
执行antlr4 -no-listener -visiter hello.g4后,生成以下文件
hello.tokens
helloBaseVisitor.java
helloLexer.java
helloLexer.tokens
helloParser.java
helloVisitor.java
增加操作
@parser
grammer Rows;
@parser::members {
int col;
public RowsParser(TokenStream input, int col){
this(input);
this.col = col;
}
}
file: (row NL)+;
row
locals [int i=0]
: ( STUFF
{
$i++;
if ($i == col) System.out.println($STUFF.text);
}
)+
;
TAB : '\t' -> skip;
NL : '\r'? '\n';
STUFF: ~[\t\r\n]+;
- 操作时被花括号括起来的代码段
- 上例中members操作的代码将会被注入到生成的语法分析器类中的成员区;
- 规则row中的操作访问\(i是由locals子句定义的局部变量,该操作也用\)STUFF.text获取最近匹配的STUFF记号的文本内容
public class Rows{
public static void main(String[] args) throws Exception {
ANTLRInputStream input = new ANTLRInputStream(System.in);
RowsLexer lexer = new RowsLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
int col = Integer.valueOf(args[0]);
RowsParser parser = new RowsParser(tokens, col);
parser.setBuildParserTree(false);
parser.file();
}
}
语义谓词
grammer IData;
file : group+;
group : INT sequence[$INT.int];
sequence[int n]
locals [int i = 1]
: ({$i <= $n}? INT {$i++})*
;
INT :[0-9]+;
WS :[ \t\n\r]+ -> skip;
被称为语义谓词的布尔值操作:{$i <= $n},当谓词计算结果为true时,语法分析器匹配整数直到超过序列规则参数n要求的数量;当谓词计算结果为false时,谓词让相关的选项从生成的语法分析器中“消失”。在这里,值为false的谓词让(...)*循环从规则序列里终止而退出。
注意:一定不能写成以下的语法,语义偏差很大,因为\(INT总是返回最近匹配的INT,在下面的错误代码中,匹配sequence时的第一个\)INT确实是sequence之前的INT,但之后都将变成上一个sequence操作中匹配的INT
grammer IData;
file : group+;
group : INT sequence;
sequence
locals [int i = 1]
: ({$i <= $INT.int}? INT {$i++})*
;
INT :[0-9]+;
WS :[ \t\n\r]+ -> skip;
词法模型
同一文件的不同格式
基本思路:当词法分析器看到特殊的哨兵字符序列时,让它在不同模式之间切换
lexer grammar XMLLexer;
//默认模式
OPEN : '<' -> pushMode(INSIDE);
COMMEND : '<!--' .* '-->' -> skip;
EntityRef : '&' [a-z] ';';
TEXT : ~('<'|'&')+;
//INSIDE模式
mode INSIDE;
CLOSE : '>' -> popMode;
SLASH_CLOSE : '/>' -> popMode;
EQUALS : '=' ;
STRING : '"' .* '"';
SlashName : '/' Name;
Name : ALPHA (ALPHA|DIGIT)*;
S : [ \t\r\n] -> skip;
fragment
ALPHA : [a-zA-Z];
fragment
DIGIT : [0-9];
重写输入流
import org.antlr.v4.runtime.TokenStream;
import org.antlr.v4.runtime.TokenStreamRewriter;
public class RewriteListener extends IDataBaseListener{
TokenStreamRewrite rewriter;
public RewriteListener(TokenStream tokens) {
rewriter = new TokentreamRewriter(tokens);
}
@Override
public void enterGroup(IDataParser.GroupContext ctx){
rewriter.insertAfter(ctx.stop, '\n');
}
}
以上代码实现在捕获到group的时候把换行符插到它末尾。
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.*;
import java.io.FileInputStream;
import java.io.InputStream;
public class IData {
InputStream is = args.length > 0 ? new FileInputStream(args[0]):System.in;
ANTLRInputStream input = new ANTLRInputStream(is); //CharStream
IDataLexer lexer = new IDataLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
IDataParser parser = new IDataParser(tokens);
ParserTree tree = parser.file();
RewriterListener listener = new RewriteListener(tokens);
System.out.println("Before Rewriting");
System.out.println(listener.reewriter.getText());
ParserTreeWalker walker = new ParserTreeWalker();
walker.walk(listener, tree);
System.out.println("After rewriting");
System.out.println(listener.rewriter.getText());
}
发送记号到不同的通道
COMMENT
: '/*' .*? '*/' -> channel(HIDDEN)
;
WS : [ \r\n\t]+ -> channel(HIDDEN)
;
优先级,左递归以及相关性
相关性
默认情况下,ANTLR从左到右结合运算符。使用assoc手动指定运算符记号上的相关性。
expr : <assoc=right>expr '^' expr
| INT
;
//指数表达式选项放在其他表达式选项之前,因为它的运算符比乘法和加法都有更高的优先级
expr : <assco=right>expr '^' expr
| expr '*' expr
| expr '+' expr
| INT
;
左递归
左递归规则是指直接或者间接调用在选项左边缘的自身的规则。
ANTLR可以处理直接左递归,不能处理间接左递归
优先级
ANTLR词法分析器通过偏爱首先指定的规则来解决词法规则间的二义性,这意味着ID规则应该定义在所有的关键词规则之后。
比如,乘除比加减优先级高,写在加减的前面
expr: expr op=(MUL|DIV) expr # md_expr
| expr op=(ADD|SUB) expr # as_expr
| sign=(ADD|SUB)? NUM # number
| ID # id
| '(' expr ')' # parens
;
ANTLR把隐式的为字面量生成的词法规则放在显式的词法规则之前,因此它们总是具有更高的优先级。
简单计算器案例
- 用 visitor 模式实现的简单计算器
- 实现支持加、减、乘、除、取余、幂运算的浮点数计算器,其中规定取余只能对有整数意义的对象操作,优先级及结合律的实现无误
- 支持print语句、行注释、块注释
grammar Calc;
prog: stat+;
stat: expr ';' # cal_stat
| ID '=' expr ';' # assign
| 'print' '(' expr ')' ';' # print
;
expr: <assco=right>expr POW expr # pow_expr
| expr op=(MUL|DIV|MOD) expr # md_expr
| expr op=(ADD|SUB) expr # as_expr
| sign=(ADD|SUB)? NUM # number
| ID # id
| '(' expr ')' # parens
;
NUM: INT
| FLOAT
;
MUL: '*';
DIV: '/';
ADD: '+';
SUB: '-';
POW: '^';
MOD: '%';
ID: [a-zA-Z]+[0-9a-zA-Z]*;
ZERO: '0';
INT: [1-9][0-9]*
| ZERO
;
FLOAT: INT '.' [0-9]+
;
COMMENT_LINE: '//' .*? '\r'? '\n' -> skip;
COMMENT_BLOCK: '/*' .*? '*/' -> skip;
WS: [ \t\r\n] -> skip;
具体实现
- 浮点型的比较用BigDecimal提高精确度
- 浮点型格式化输出用DecimalFormat实现
- 对除零、浮点数取余做了错误检查
import java.math.BigDecimal;
import java.text.DecimalFormat;
import java.util.HashMap;
import java.util.Map;
/**
* Created by wangqingyue on 2017/9/21.
*/
public class Calc extends CalcBaseVisitor<Double>{
Map<String, Double> memory = new HashMap<String, Double>();
// ID '=' expr ';'
@Override
public Double visitAssign(CalcParser.AssignContext ctx){
String id = ctx.ID().getText();
Double value = visit(ctx.expr());
memory.put(id, value);
return value;
}
// expr ';'
@Override
public Double visitCal_stat(CalcParser.Cal_statContext ctx){
Double value = visit(ctx.expr());
return value;
}
// 'print' '(' expr ')' ';'
@Override
public Double visitPrint(CalcParser.PrintContext ctx){
Double value = visit(ctx.expr());
DecimalFormat df = new DecimalFormat("#.###");
System.out.println(df.format(value));
return value;
}
// <assco=right>expr POW expr
@Override
public Double visitPow_expr(CalcParser.Pow_exprContext ctx){
Double truth = visit(ctx.expr(0));
Double power = visit(ctx.expr(1));
return Math.pow(truth, power);
}
// expr op=(MUL|DIV) expr
@Override
public Double visitMd_expr(CalcParser.Md_exprContext ctx){
Double left = visit(ctx.expr(0));
Double right = visit(ctx.expr(1));
if (ctx.op.getType() == CalcParser.MUL) return left * right;
else if (ctx.op.getType() == CalcParser.DIV){
if (new BigDecimal(right).compareTo(new BigDecimal(0.0)) == 0){
return 0.0;
}
return left / right;
}
else {
int left_int = (new Double(left)).intValue();
int right_int = (new Double(right).intValue());
if (new BigDecimal(right_int).compareTo(new BigDecimal(right)) == 0
&& new BigDecimal(left_int).compareTo(new BigDecimal(left_int)) == 0){
return Double.valueOf(left_int % right_int);
}
System.out.println("Mod\'%\' operations should be integer.");
return 0.0;
}
}
// expr op=(ADD|SUB) expr
@Override
public Double visitAs_expr(CalcParser.As_exprContext ctx){
Double left = visit(ctx.expr(0));
Double right = visit(ctx.expr(1));
if (ctx.op.getType() == CalcParser.ADD) return left + right;
else return left - right;
}
// sign=(ADD|SUB)? NUM
@Override
public Double visitNumber(CalcParser.NumberContext ctx){
int child = ctx.getChildCount();
Double value = Double.valueOf(ctx.NUM().getText());
if (child == 2 && ctx.sign.getType() == CalcParser.SUB){
return 0 - value;
}
return value;
}
// ID
@Override
public Double visitId(CalcParser.IdContext ctx){
String id = ctx.ID().getText();
if (memory.containsKey(id)) {
return memory.get(id);
}
System.out.println("undefined identifier \"" + id + "\".");
return 0.0;
}
//'(' expr ')'
@Override
public Double visitParens(CalcParser.ParensContext ctx){
Double value = visit(ctx.expr());
return value;
}
}
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
/**
* Created by wangqingyue on 2017/9/21.
*/
public class Main {
public static void main(String[] args) throws Exception{
CharStream input = args.length > 0? CharStreams.fromFileName(args[0]): CharStreams.fromStream(System.in);
CalcLexer lexer = new CalcLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CalcParser parser = new CalcParser(tokens);
ParseTree tree = parser.prog();
Calc calculator = new Calc();
calculator.visit(tree);
}
}
update at 2017/9/22
by 一颗球

 浙公网安备 33010602011771号
浙公网安备 33010602011771号