
ClickHouse在做SQL查询时要尽量遵循的原则
1.大表在左,小表在右,否则会造成右表加载数据量太大,大量消耗内存资源;
2.如果join的右表为大表,则需要将右表写成子查询,在子查询中将右表的条件都加上,并进行列裁剪,这样可以有效减少数据加载;
3.where条件中只放左表的条件,如果放右表的条件将在下推阶段右表条件不会生效,将右表条件放到join的子查询中去。
select ... from t_all join ( -- 右表本身直接走本地表 select ... from t_local where t_local.filter = xxx -- 尽可能手动将条件放在子查询中 ) where t_local.f = xxx -- 当前版本不支持自动下推到JOIN查询中,需要手动修改 and t_all.f in ( select ... from xxx -- 若能将子查询作为筛选条件更佳 )
ClickHouse执行计划分析
此执行计划分析是在多分片单副本的ClickHouse环境中执行的。
准备数据
-- 建表语句 CREATE TABLE dw_local.t_a on cluster cluster_name ( `aid` Int64, `score` Int64, `shard` String, `_sign` Int8, `_version` UInt64 ) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/table/{shard}/t_a', '{replica}') ORDER BY (aid); CREATE TABLE dw_dist.t_a on cluster cluster_name as dw_local.t_a ENGINE = Distributed('cluster_name', 'dw_local', 't_a', sipHash64(shard)); CREATE VIEW dw.t_a on cluster cluster_name as select * from dw_dist.t_a final where _sign = 1; CREATE TABLE dw_local.t_b on cluster cluster_name ( `bid` Int64, `aid` Int64, `shard` String, `_sign` Int8, `_version` UInt64 ) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/table/{shard}/t_b', '{replica}') ORDER BY (bid); CREATE TABLE dw_dist.t_b on cluster cluster_name as dw_local.t_b ENGINE = Distributed('cluster_name', 'dw_local', 't_b', sipHash64(shard)); CREATE VIEW dw.t_b on cluster cluster_name as select * from dw_dist.t_b final where _sign = 1; -- 插入数据 insert into dw_dist.t_a (aid, score, shard, _sign, _version) values(1, 1, 's1', 1, 1); insert into dw_dist.t_a (aid, score, shard, _sign, _version) values(2, 1, 's2', 1, 2); insert into dw_dist.t_b (bid, aid, shard, _sign, _version) values(1, 1, 's1', 1, 1); insert into dw_dist.t_b (bid, aid, shard, _sign, _version) values(2, 2, 's2', 1, 2); insert into dw_dist.t_b (bid, aid, shard, _sign, _version) values(3, 0, 's1', 1, 3); insert into dw_dist.t_b (bid, aid, shard, _sign, _version) values(4, 1, 's2', 1, 4);
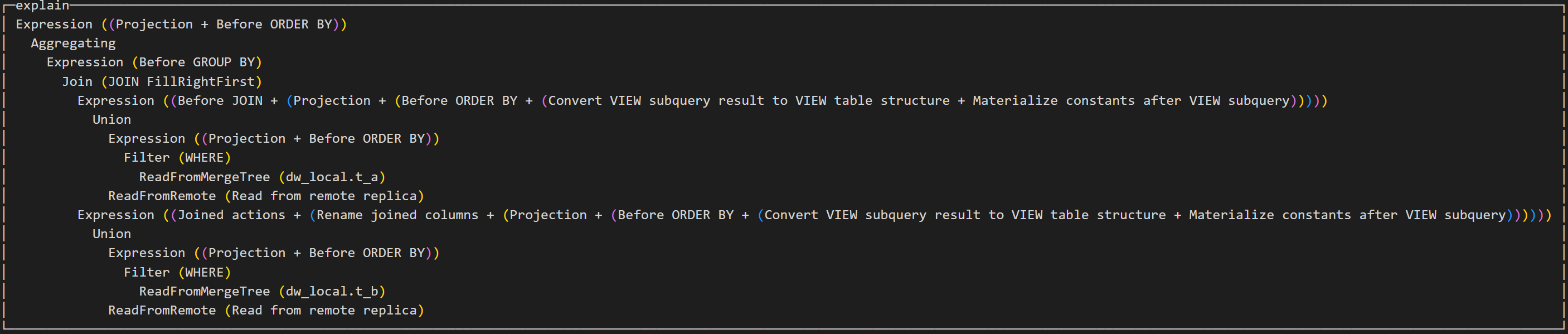
案例1
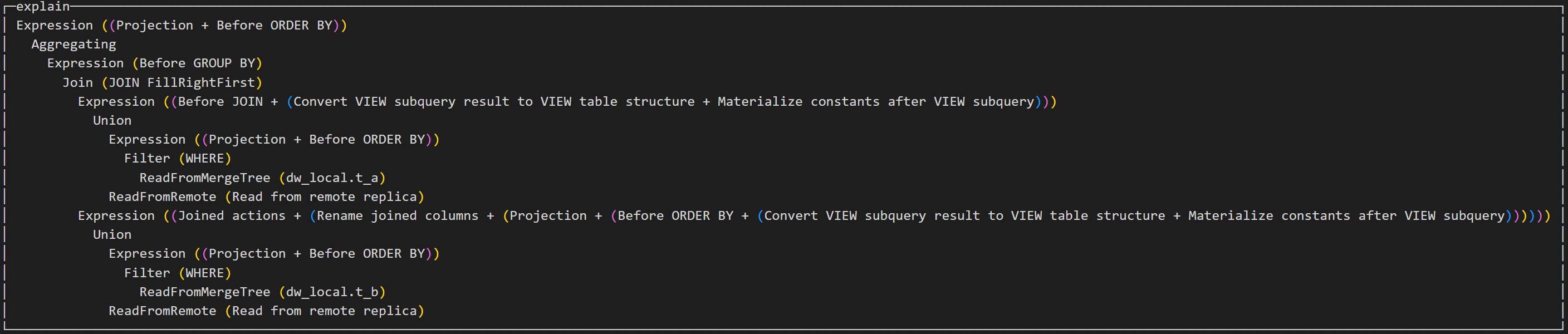
explain select a.aid as aid, b.bid as bid, count(*) as ct from dw.t_a as a join dw.t_b as b on a.aid = b.aid group by aid, bid;
通过执行计划可以看到,左表和右表的执行计划基本一样,先将远程节点上的表数据拉取到本地,然后和本地表的数据进行union操作,然后左表和右表进行join操作,最后进行group by操作。
案例2
explain select a.aid as aid, b.bid as bid, count(*) as ct from dw.t_b as b join dw.t_a as a on a.aid = b.aid group by aid, bid;
此SQL和案例1SQL相比只是将左右表的顺序调换,此次表的执行顺序只是调换了一下,从左到右执行。

案例3
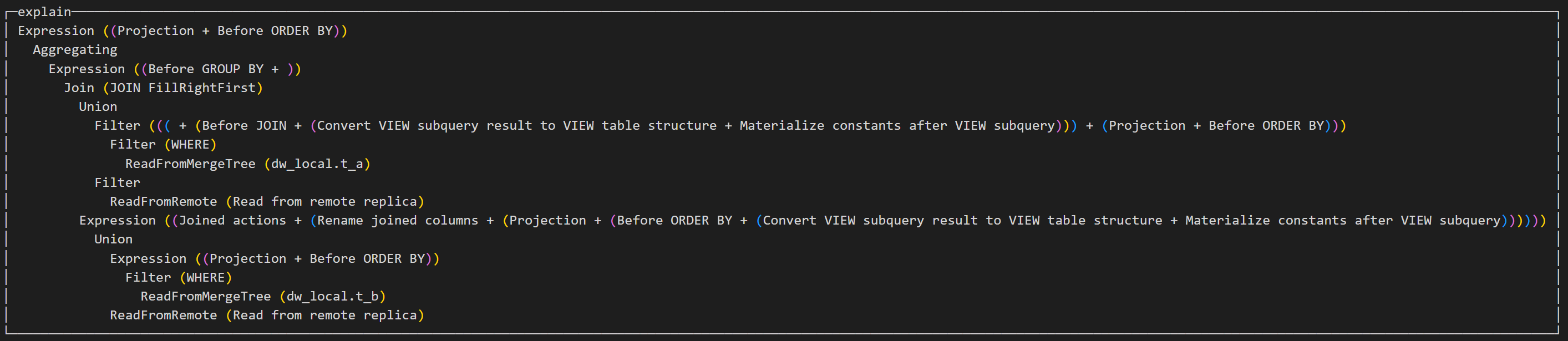
explain select a.aid as aid, b.bid as bid, count(*) as ct from dw.t_a as a join dw.t_b as b on a.aid = b.aid where a.aid=1 group by aid, bid;
此SQL和案例1SQL相比添加了左表的where条件,执行计划中将条件放在了左表进行数据加载。
案例4
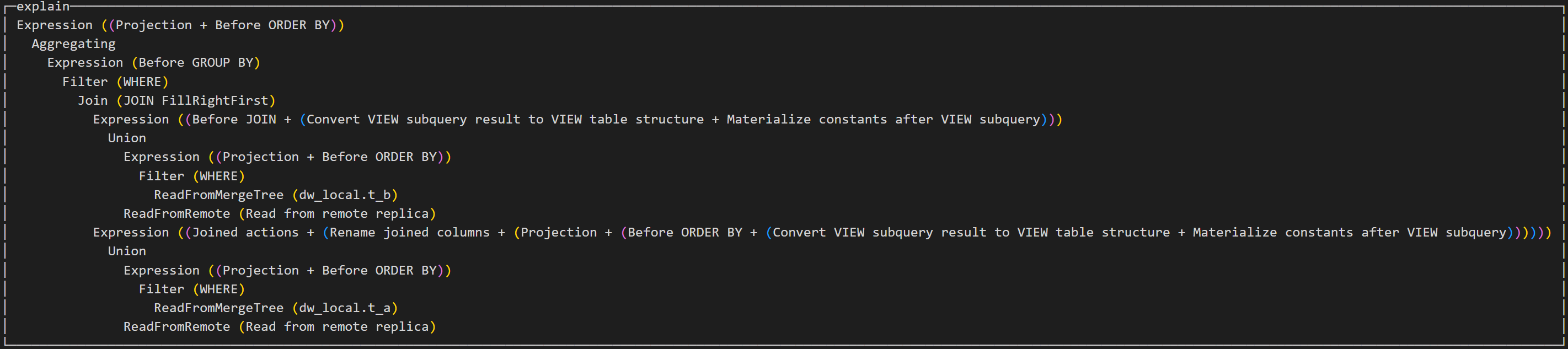
explain select a.aid as aid, b.bid as bid, count(*) as ct from dw.t_b as b join dw.t_a as a on a.aid = b.aid where a.aid=1 group by aid, bid;
此SQL中的左表表无过滤条件,右表存在过滤条件,执行计划并不会将右表的条件放到拉取数据的阶段。
案例5
explain select a.aid as aid, b.bid as bid, count(*) as ct from dw_local.t_a as a join dw_local.t_b as b on a.aid = b.aid where a.aid=1 group by aid, bid;
如果所有表都采用本地表,而不是分布式表,则在数据加载阶段不会拉取远程节点的数据。

案例6
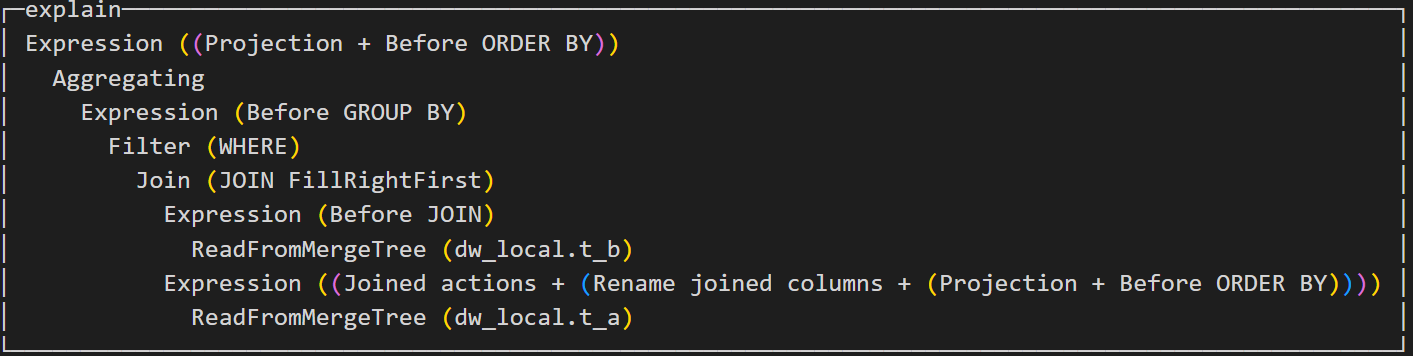
explain select a.aid as aid, b.bid as bid, count(*) as ct from dw_local.t_b as b join dw_local.t_a as a on a.aid = b.aid where a.aid=1 group by aid, bid;
调换左右表顺序,同案例5结果相同。
案例7
explain select a.aid as aid, b.bid as bid, count(*) as ct from ( select * from dw.t_a ) as a join dw.t_b as b on a.aid = b.aid group by aid, bid;
左表为子查询时,左表也会走分布式表查询方式拉取数据,有文章说左表为子查询的情况下会导致左表走本地查询策略,不走分布式查询策略,可能是版本原因,我们测试过程中没有出现类似情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号