

写操作系统之开发加载器
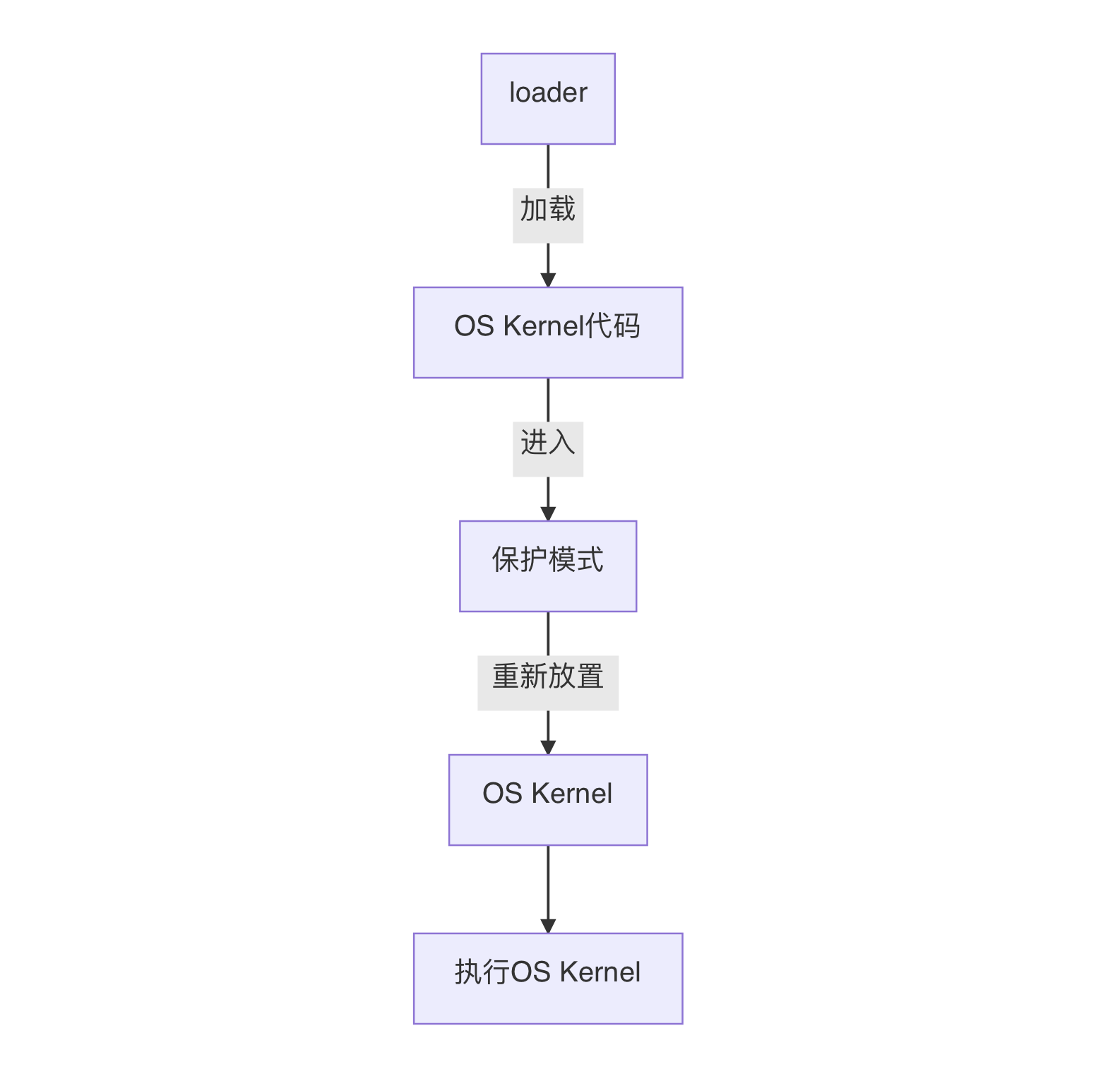
loader功能
功能
loader的功能是:
- 从软盘中把操作系统内核读取到内存中。
- 进入保护模式。
- 把内存中的操作系统内核重新放置到内存中。
- 执行操作系统内核。
如果理解不了上面的部分语句,先搁置,后面会详细说明。
流程图
先看loader的流程图。
不必全部看懂。我觉得可能对读者理解后面的内容有帮助,所以先给出这张图。
Kernel
代码
在加载kernel到内存中之前,先要有一个内核。我们马上写一个。下面的代码在文件kernel.asm中。
[section .text]
global _start
_start:
mov ah, 0Fh
mov al, 'C'
mov [gs:(80 * 20 + 40) * 2], ax
mov [gs:(80 * 21 + 40) * 2], ax
mov [gs:(80 * 22 + 80) * 2], ax
jmp $
jmp $
上面的代码是展示了一个汇编函数的模板,但又不是典型的汇编函数模板。
[section .text]是伪指令,不会被CPU执行,仅仅只是告知程序员下面的代码是可执行代码,提高代码的可读性。
global _start让函数_start成为全局函数。
func_name:
; some code
ret
这才是汇编函数的标准模板。func_name是函数名,;some code和ret都是函数体。ret可以理解为C语言中的return。
在kernel.asm中,函数名是_start,这固定的,只能是这个名字,由编译器或链接机制决定(我也不是特别清楚)。
mov [gs:(80 * 20 + 40) * 2], ax,把字符C打印在屏幕的第20行、第40列。
jmp $,可以理解成C代码while(1){}。
编译
# 把kernel.asm编译成elf格式的目标文件kernel.o。
nasm -o kernel.o -f elf kernel.asm
# 使用连接器ld把目标文件kernel.o连接成32位的可执行文件kernel.bin,并且使用0x30400作为文本段的起始点。
ld -s -Ttext 0x30400 -o kernel.bin kernel.o -m elf_i386
放入软盘
# 把boot.bin写入软盘a.img
dd if=boot.bin of=a.img bs=512 count=1 conv=notrunc
# 挂载软盘a.img,以便在下面把loader.bin、kernel.bin写入软盘。
sudo mount -o loop a.img /mnt/floppy/
sudo cp loader.bin /mnt/floppy/ -v
sudo cp kernel.bin /mnt/floppy/ -v
# 卸载软盘
sudo umount /mnt/floppy
经过上面的一系列步骤,就得到了一个可执行的内核文件kernel.bin。虽然简单,但我们写的这个操作系统无论变得多复杂,都是在这个简单的内核文件上慢慢添加功能变成的。
加载内核
内核代码在kernel.bin文件中。kernel.bin是kernel.asm经过编译后的二进制文件。加载内核,就是把kernel.bin从软盘中读取到内存中。
从软盘中读取数据的思路是:
- 根据文件名在软盘的根目录中找到目标文件的第一个FAT项的编号,同时也是在数据区的第一个扇区的编号。
- 由于文件的所有FAT项构成一个单链表,变量这个单链表,读取每个FAT项对应的扇区的数据复制到内存中。
和读取引导扇区到内存中的方法高度相似,在代码上只有很小的差异。在后面不能理解加载内核的代码时,请回头看看《开发引导扇区》。
CPU模式
es:bx
在boot.asm中,使用int 13h会把从软盘中读取到的数据存储到es:bx指向的内存中。就从es:bx这条指令(称呼它为指令不严谨,我没见过在汇编代码中直接使用这样的指令)开始讲述本节的内容。
es:bx的的值是多少?这个值有什么意义?
先回答第二个问题,它的值表示一个内存地址,物理内存地址,不是在高级编程语言例如C语言编写的程序中出现的内存地址。后者是虚拟内存地址。
什么叫物理内存地址?先解释什么是物理地址。拿软盘来说。在软盘的引导扇区的最后两个字节存储0x55AA,那么,在软盘中偏移量是510个字节的存储空间中,能看到0x55AA。如果510是虚拟地址,在软盘中偏移量是510个字节的存储空间中,可能看不到0x55AA。
所以,对“物理地址”和“虚拟地址”的理解是:前者和存储空间一一对应,如果0x55AA存储在软盘的引导扇区中地址为510的存储空间中,就能在这个地址的存储空间中找到0x55AA中这两个字节的数据。后者和存储空间不是一一对应的,0x55AA存储在虚拟地址510的存储空间中,在软盘中地址为510的存储空间找不到0x55AA这两个字节的数据。
理解了“物理地址”,再把"软盘"换成"内存",想必非常容易理解“物理内存地址”的含义。
用一句什么话过渡到CPU模式呢?
那么,es:bx的值究竟应该如何计算呢?计算方法取决于CPU所处的模式。先介绍一下“实模式”。
实模式
实际上,我们已经体验过“实模式"了。引导扇区程序就运行在实模式下。
我认为,对这种古老的历史知识,不必深究。实模式对我而言,有用的知识点是:
- 在这种模式下,物理内存地址的计算方法,也就是计算
es:bx的值的方法。 - 寄存器中的数据最大是16位的,不能是32位的。
卖了不少关子,其实,计算方法只用一句话就能讲清楚:
$$
实模式下的物理内存地址 = es * 16 + bx。
$$
例如,要把内核读取到物理内存地址是0x91000的存储空间中,只需把es的值设置成0x9000,把bx的值设置成0x1000。
为什么这样做就能表示物理内存地址
0x91000呢?这涉及到"选择子"、“地址总线”等知识。我认为,不知道这些古老的概念,暂时并不妨碍我们继续开发自己的操作系统内核。就算花点时间弄明白了,过段时间又忘记了,不忘记,作用似乎也不大,仅仅满足了自己的好奇心。不如先跳过这种细枝末节、不影响大局的知识点,降低自己的学习难度。以后有时间再弄清楚这种细节。
实模式下,最多能使用多大的内存?
内存条可以随意增加空间,能使用的最大内存就取决于计算机能寻址多大的内存地址。计算机的内存寻址又受制于寄存器能提供的内存地址值和地址总线能传递的内存地址值。
不可避免地要介绍一下地址总线。我也只是稍微了解一点够用的知识。
CPU和内存之间通过地址总线交流,可以这么简单粗暴地理解。CPU把内存地址,例如0x9000:0x1000通过地址总线告知内存,要读取0x9000:0x1000处的数据。
- 首先,
0x9000、0x1000这两个数值,能存储在16位寄存器es、ax中。如果超过16位寄存器的数值存储范围,CPU就不能读取0x9000:0x1000处的数据。 - 地址总线接收到的内存地址是
0x9000:0x1000计算出来的数值0x91000。如果0x91000超出地址总线的存储范围,CPU也不能读取到目标数据。
实模式下,地址总线是20位的,能表示的最大数值是$2^{20}-1$。
计算机寻址的最小单位是“字节”,而不是“bit”。所以,实模式下,计算机能使用的内存最大是$2^{20} - 1 + 1$字节,即1M。
为什么是$2{20}-1+1$?因为内存地址的初始值是0。从0到最大值$2-$1,总计有$2^{20}-1+1$个字节。
各位的电脑内存是多大?远远大于1M。实模式很快就不能满足需求,所以就出现了“保护模式”。
保护模式
和实模式对比
保护模式下,
- CPU通过寄存器能提供的最大内存地址是$2^{32}-1$。
- 地址总线是32位的,能传输的最大内存地址也是$2^{32}-1$。
- 因此,计算机能使用的最大内存是
4GB。
在实模式下,任何指令能使用任何合法的内存地址指向的内存空间。想象一下,A地址存储小明的代码XM,B地址存储小王的代码XW。小明和小王约定好,执行完XM后,跳转到XW;执行XW后,跳转到XM。可是,小王和小明吵了一架,偷偷地在XW中把A地址处的代码全部擦除,执行完XW后,小明的代码就再也不会执行了。
再举个例子,你一边用编辑器写代码,一边用某个音乐播放器听音乐,音乐播放器偷偷修改了正在运行中的编辑器所占用的内存中的数据,导致你运行自己的代码时总是出错。当然,你肯定没有遇到过这种奇怪的事情。因为你的电脑的CPU不是运行在实模式下。
通过两个例子,应该能够知道实模式的弊端。保护模式中的“保护”二字,集中体现在:对指令能使用的内存空间做了限制,不能像在实模式下那样能随心所欲地使用任何合法的内存地址指向的内存空间。
用最简单的语言描述保护模式:
- 计算机能使用的最大内存是
4GB。 - 指令只能使用特定的内存空间。
- 内存寻址方式不同。
保护模式下,仍然用es:bx这种格式的数据表示内存地址,可计算es:bx的值的方法和实模式下大为不同。
先了解几组概念。
GDT
GDT的全称是"Global Description Table",对应的中文术语是“全局描述符表"。在后面,还会遇到LDT。
全局描述符表,顾名思义,这个表中的每个项都是一个全局描述符。
全局描述符是一段8个字节的数据。这8个字节包含三项内容:段界限、段基址、段属性。
全是陌生概念。不要慌。让我们一个一个来弄清楚。
在前面,我讲过,保护模式下,指令不能访问任意内存空间的指令,能访问的内存空间是被限制的。怎么实现这种限制呢?
划定一段内存空间,规定这段内存空间只有具有某种属性的指令才能访问。怎么划定一段内存空间?非常自然地想到在:指定一个初始值,再指定一个界限值,就能确定一段内存空间。然后再用“段属性”规定访问这段内存空间需要具备的条件。
“初始值”就是“段基址”,“界限值”就是“段界限”。段属性是什么?有点难说清楚,后面再说。
在逻辑上,全局描述符的结构很清晰,可它的实际结构却非常不规则。先看看全局描述符的结构示意图。

怎么解读这张图?
- 图中的数据使用“小端法”存储。
- 全局描述符占用8个字节,即64个bit。
- 示意图中把描述符分为“代码段”描述符和“数据段”描述符。是哪种描述符,由段属性决定。
- 段属性依然很复杂。咱们再搁置一会儿。
介绍描述符结构的终极目的是用代码表示描述符,而且是用汇编代码表示。
描述符的本质是64个bit,要把一段内存空间的"信息"(初始地址--段基址、这段内存空间的长度减去1--段界限、这段内存空间的属性--段属性)按描述符的结构存储到这64个bit中。
所谓“结构”,可以理解为:按某种规则解读一段数据。例如,桌子上按顺序放着10支铅笔,每支红色铅笔表示1年,2支红色铅笔表示2年,3支红色铅笔表示3年,按照这个规定,10支红色铅笔表示10年。再规定,前四支铅笔表示小明的年龄,后六支铅笔表示小王的年龄。给你10支持按顺序排列的铅笔,你能从中查询到小明和小王的年龄吗?这一定是一件非常容易的事。分别看看前4支、后6支铅笔中红色铅笔的数量即可。
不知道这个例子是否恰当。我想表达的意思是:"结构"是一种规定好的规则,例如,前4支铅笔表示小明的年龄;读数据,要按这种规则去读,存数据也要按这种规则去存。小明的年龄只能从前4支铅笔读取,也只能用前4支铅笔存储。
先给出用C语言表示的描述符结构。
typedef struct{
// 对应描述符结构图中的BYTE0、BYTE1。
unsigned short seg_limit_below;
// 对应描述符结构图中的BYTE2、BYTE3。
unsigned short seg_base_below;
// 对应描述符结构图中的BYTE4。
unsigned char seg_base_middle;
// 对应描述符结构图中的BYTE5。
unsigned char seg_attr1;
// 对应描述符结构图中的BYTE6。
unsigned char seg_limit_high_and_attr2;
// 对应描述符结构图中的BYTE7。
unsigned char seg_base_high;
}Descriptor;
我当初怎么都理解不了汇编代码表示的描述符结构,直到看到用C语言表示的描述符结构后才豁然开朗,所以先给出C代码,希望跟我有同样困惑的人能和我一样顿悟。
因为我只是普通的人,当初理解“结构”和代码的对应关系着实花了不少时间,所以在这里写得比较啰嗦,实际上是把我当时的理解过程全部写了出来。聪明人请快速跳过这段。
用汇编语言怎么表示描述符结构?我决定先不照搬之前已经写好的代码,而是和读者朋友一起现场徒手再写一次描述符结构的汇编代码A。请对照前面的描述符结构图写代码。过程如下:
- 使用汇编代码中的宏来实现描述符结构。
- 这个宏有三个参数,分别是段界限、段基址、段属性,命名为seg_limit、seg_base、seg_attr。每个参数的长度都是4个字节。
- 段界限1是seg_limit的低16位,代码是:
seg_limit & 0xFFFF。 - 段基址1是seg_base的低24位,代码是:
seg_base & 0xFFFFFF。 - 属性是seg_attr的低8位 + seg_limit的高4位 + seg_attr的高4位,代码是:
(seg_attr & 0xFF) |(( (seg_attr >>8) <<12) | (seg_limit >> 16)<<8)。 - 段基值2是seg_base的高8位,代码是:
seg_base>>24。
和我以前写的描述符结构的汇编代码B比较一下。
; 三个参数分别是段基址、段界限、段属性
; 分别用 %1、%2、%3表示上面的三个参数,分别等价于A代码中的seg_base、seg_limit、seg_attr。
%macro Descriptor 3
dw %2 & 0ffffh
dw %1 & 0ffffh
db (%1 >> 16) & 0ffh
db %3 & 0ffh
db ((%2 >> 16) & 0fh) | (((%3 >> 8) & 0fh) << 4)
db (%1 >> 24) & 0ffh
%endmacro
二者的差异在对段基址1、属性的处理。
汇编代码B中对段基址1的处理是:
dw %1 & 0ffffh
db (%1 >> 16) & 0ffh
汇编代码A中对段基值1的处理是seg_base & 0xFFFFFF。把A中的6个字节拆分成4个字节和2个字节,原因是在nasm汇编中,只存在dw、db这样的伪指令,而不存在能表示6个字节的伪指令。二者都能把段基址1存储到正确的内存空间,只是受限于汇编语法把6个字节拆分成两部分来处理。
dw、db都是伪指令。
伪指令是指不被处理器直接支持的指令,最终会被翻译成机器指令被处理器处理。
dw:一个字,两个字节。
db:一个字节。
再比较二者对属性的处理。
; A代码
(seg_attr & 0xFF) |(( (seg_attr >>8) <<12) | (seg_limit >> 16)<<8)
; B代码
db seg_attr & 0ffh
db ((seg_limit >> 16) & 0fh) | (((seg_attr >> 8) & 0fh) << 4)
A代码和B代码对属性的处理结果是一致的,都符合nasm汇编语法。B代码很容易理解。A代码有点难懂,展开分析一下。
- 在描述符结构图中,BYTE5、BYTE6中存储的数据混合了段界限的高4位和全部属性。
- 这个混合体的低8位是属性的低8位,用
seg_attr & 0xFF来获取,这不应该有疑问。 - 混合体的高4位是属性的高4位。属性的高4位是
seg_attr >>8。混合体总计12位,高4位的前面是低12位,所以,必须把获取到的属性的高4位左移12位,因此,最终结果是:(seg_attr >>8) <<12。 - 混合体的高4位、低8位都已经填充数据,剩余中间4位用来存储段界限的高4位。段界限的高4位是
seg_limit >> 16。要把这4位存储在混合体的中间4位,需要跳过混合体的低8位,使用(seg_limit >> 16)<<8实现。 - 最后,把混合体的三部分用
|运算符拼接起来,就是这样的:(seg_attr & 0xFF) |(( (seg_attr >>8) <<12) | (seg_limit >> 16)<<8)。
gdtptr
GDT存储在内存的一段空间内。CPU要想正确读取GDT中的描述符,需要先把这段空间的初始地址和空间界限存储在专门的寄存器gdtptr中。
gdtptr的结构图如下。

在前面介绍保护模式时,我提到过,要确定一段内存空间,至少需要两个值:这段内存空间的初始值和这段内存空间的长度。
GDT也存储在一段内存空间中,只需提供空间初始值和空间长度就能找出存储GDT的这段内存空间。gdtptr的设计正是如此:低16位存储界限,高32位存储基地址。16位界限 = 空间长度(L) - 1,因为内存地址的初始值是0。内存的第1个字节,内存地址是0x0;内存的第2个字节,内存地址是0x1。GDT的第1个字节,内存地址是基地址+0;GDT的第2个字节,内存地址是基地址+1;GDT的第3个字节,内存地址是基地址+2;GDT的第L个字节,内存地址是基地址+L-1。这就是“16位界限 = 空间长度(L) - 1”的由来。
那么,要填充到gdtptr中的值怎么用代码表示呢?请看下面。
; 三个参数分别是段基址、段界限、段属性
; 分别用 %1、%2、%3表示上面的三个参数
%macro Descriptor 3
dw %2 & 0ffffh
dw %1 & 0ffffh
db (%1 >> 16) & 0ffh
db %3 & 0ffh
db ((%2 >> 16) & 0fh) | (((%3 >> 8) & 0fh) << 4)
db (%1 >> 24) & 0ffh
%endmacro
LABEL_GDT: Descriptor 0, 0, 0
LABLE_GDT_FLAT_X: Descriptor 0, 0ffffffh, 0c9ah
LABLE_GDT_FLAT_X_16: Descriptor 0, 0ffffffh, 98h
LABLE_GDT_FLAT_X_162: Descriptor 0, 0ffffffh, 98h
;LABLE_GDT_FLAT_X: Descriptor 0, 0FFFFFh, 0c9ah
;LABLE_GDT_FLAT_WR:Descriptor 0, 0fffffh, 293h
LABLE_GDT_FLAT_WR_TEST:Descriptor 5242880, 0fffffh, 0c92h
LABLE_GDT_FLAT_WR_16:Descriptor 0, 0fffffh, 0892h
LABLE_GDT_FLAT_WR:Descriptor 0, 0fffffh, 0c92h
LABLE_GDT_VIDEO: Descriptor 0b8000h, 0ffffh, 0f2h
GdtLen equ $ - LABEL_GDT
GdtPtr dw GdtLen - 1
dd 0
这段代码中的GdtPtr存储的值就是要填充到寄存器gdtptr中的值。
GdtLen equ $ - LABEL_GDT中的$表示当前位置,即GdtLen之前的位置。LABEL_GDT表示从存储当前二进制文件(当前源文件编译之后得到的二进制文件)的内存的初始地址到LABEL_GDT这个位置的字节偏移量。汇编代码中的变量名称都能理解成这个变量相对于存储当前二进制文件的内存空间的初始位置的字节偏移量。从LABEL_GDT到GdtLen,是GDT表的长度。
GdtPtr dw GdtLen - 1
dd 0
GdtPtr的前16位存储GDT的长度减去1(就是GDT的界限),后32位存储0(就是GDT的基地址)。这和gdtptr需要的数据结构正好一致。事实上,往gdtptr中存储的值就是GdtPtr中的数据。完成这个操作的指令是:
[GdtPtr]表示内存地址GdtPtr指向的内存空间中存储的数据,而不是指内存地址这个值本身。可以把[GdtPtr]理解成指针。
lgdt [GdtPtr]
关于GDT的理论知识,只剩下全局描述符的指针和选择子还没有讲解。让我们看看全局描述符的代码,顺便理解一下全局描述符中的段属性。
LABEL_GDT: Descriptor 0, 0, 0
LABLE_GDT_FLAT_X: Descriptor 0, 0ffffffh, 0c9ah
LABLE_GDT_FLAT_X_16: Descriptor 0, 0ffffffh, 98h
LABLE_GDT_FLAT_WR_16:Descriptor 0, 0fffffh, 0892h
LABLE_GDT_FLAT_WR:Descriptor 0, 0fffffh, 0c92h
LABLE_GDT_VIDEO: Descriptor 0b8000h, 0ffffh, 0f2h
现在开始解读这段代码。
Descriptor是创建描述符的宏。汇编函数中的宏和C语言中的宏的作用相同。- 注意,我没有说
Descriptor是创建“全局”描述符的宏。因为,用这个宏既能创建全局描述符,又能创建局部描述符。 LABEL_GDT。使用宏Descriptor,三个参数都是0。意思是,这个描述符的描述的内存空间的段基址、段界限、段属性都是0。这是一个空描述符,是GDT的初始位置。把GDT中的第一个描述符设计成空描述符,是为了定位其他描述符时有一个参照系。LABLE_GDT_FLAT_WR_16。段基址是0,段界限是0fffffh,段属性是0892h。
段界限是0fffffh字节还是0fffffhG?这由段属性中的一个属性决定。下面详细介绍段属性。
描述符LABLE_GDT_FLAT_WR_16的属性值是0892h。这个段属性是怎么确定的?又应该怎么解读?
首先,属性值0892h的二进制形式是:1000 1001 0010。这个二进制值的存储方式是“小端法”。把它填入下面的表格中。怎么填写?
从1000 1001 0010的最右边开始,依次把值填入两个表格的第0列、第1列、第2列直至填充到第11列。
表格一
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | R | C | X | S | DPL | DPL | P | AVL | L | D/B | G |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
表格二
| A | W | E | X | S | DPL | DPL | P | AVL | L | D/B | G |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
这两个表格是段属性的12个bit拼接在一起形成的,仅仅只有表格的第1列、第2列所存储的数据的含义不同。
第1列、第2列是R、C的那个表格是代码段的段属性表格;R、C分别表示是否可读、是否依从。最关键的是X列,表示是否可执行。表格一中的X位上的值是0,这表示这个描述符所描述的内存空间中存储的是“数据”,所以,这种描述符叫“代码段”描述符。
两个表格的第0列到第3列对应描述符结构图中的TYPE。每个位的含义请看下面的两张图。
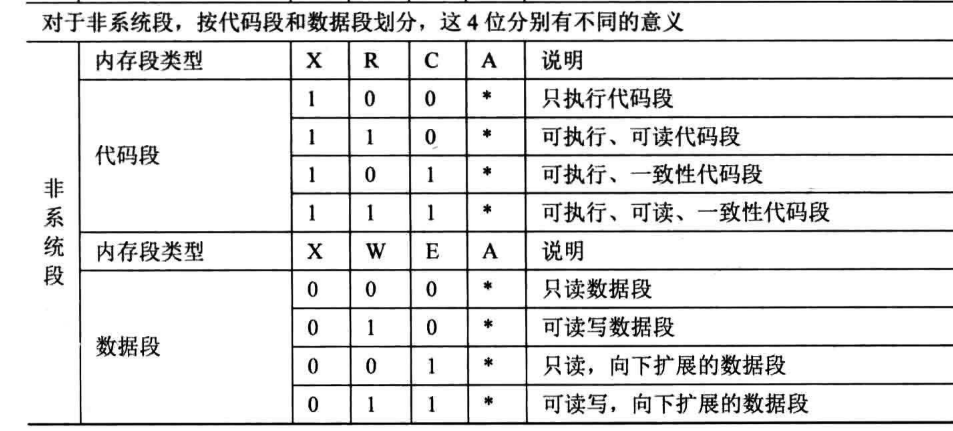
代码段一定是不可写的,所以代码段属性中没有“写”属性。
数据段一定是可读的,所以数据段属性中不必设计一个“读”属性。
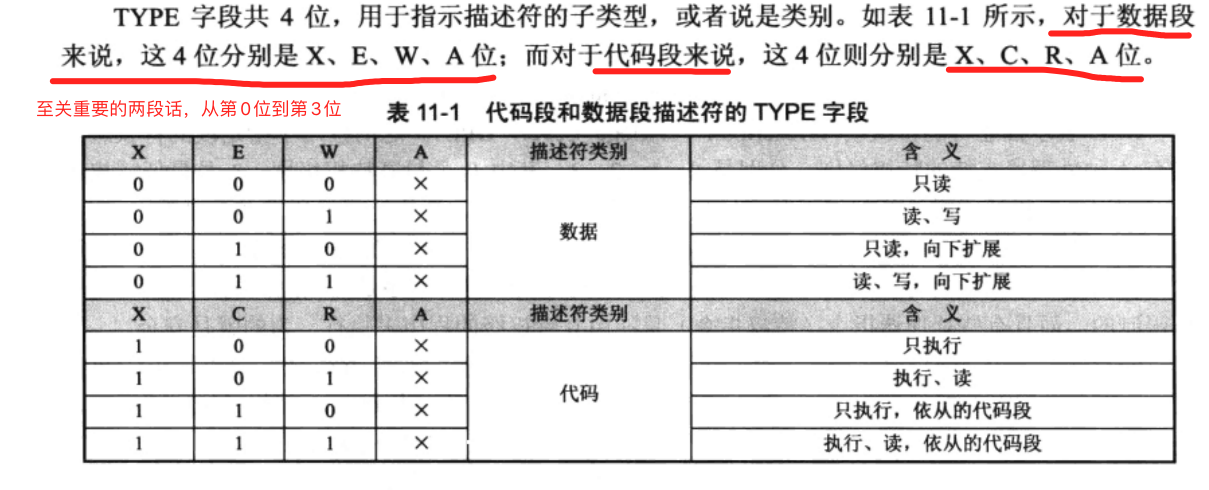
上面是对描述符结构图中TYPE的介绍。下面介绍除TYPE外的其他属性。
S。S是0时,描述符是系统段/门描述符。S是1时,描述符是代码段/数据段描述符。DPL。描述符的特权级,值可以是0或1或2。数字越小,特权级越高。P。P是0时,描述符指向的段在内存中不存在。P是1时,描述符指向的段在内存中存在。AVL。保留位。我没用到过。暂时不用关注。D/B。比较复杂。太琐碎了。只需知道,它决定段使用的操作数、内存地址的位数;或者决定堆栈扩展的方向。用到这一位时,查资料即可。毕竟,记住这种细节,用处不大,成本不小。G。在前面,我提过,段界限除了具体数值,还有一个数值单位。这个单位由G决定。G是granularity,意思是“粒度”。当G的值是0时,段界限粒度是字节;当G的粒度是1时,段界限粒度是4kB。
描述符LABLE_GDT_FLAT_WR_16的段属性的G位是1,段界限是``0fffffh * 4kb = 4GB`。
再分析一个描述符LABLE_GDT_FLAT_WR。它的段属性是0c92h。我想把这个描述符设置成:段界限粒度为4kB,数据段,可读写,32位。
把属性0c92h换算成二进制形式110010010010,然后填入数据段属性的表格。
| A | W | E | X | S | DPL | DPL | P | AVL | L | D/B | G |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
W位是1,表示描述符指向的段是可读可写的。S是1,表示描述符是代码段或数据段描述符。D/B是1,表示描述符指向的段是32位的。G是1,表示描述符指向的段的段界限的粒度是4kB。和我前面的设想吻合。
对GDT的介绍终于可以结束了。
选择子
现在可以进一步解释es:bx了。
在保护模式下,es:bx中的es中存储的数据叫做“选择子”。GDT中包含多个描述符,选择子的作用是从GDT中指定目标选择子。
可以近似地把GDT理解成C语言中的数组,数组的元素的数据类型是描述符,选择子是数组的索引。像这样简化地理解选择子,只是为了帮助我们体会选择子的作用。它的作用是什么?从GDT或LDT中找出目标描述符。
在前面,我提过,描述符分为全局描述符和局部描述符。由全局描述符组成的描述符表叫GDT,由局部描述符表组成的描述符表叫LDT。
给出一个选择子,是从GDT还是LDT中挑选目标描述符呢?这是由选择子中的某些数据决定的。来了解一下选择子的结构。

选择子的前2个bit存储RPL,对应的中文术语是“请求特权级”。RPL和DPL一样,有三个取值:00、01、11。
选择子的第2个bi存储TI。TI是0时,是GDT的选择子。TI是1时,是LDT的选择子。
选择子的剩余13位存储描述符索引。这才是目标描述符在描述符表中的索引。描述符索引,本质是目标描述符在描述符表中的字节偏移量。每个描述符的长度是8个字节。描述符表能容纳的描述符的最大数量是$2^{13}$即8192。
gdtptr的低16位存储GDT的段界限,也就是说,GDT的最大长度是$2{16}$字节。GDT中描述符的最大数量是$2$,每个描述符的长度是8个字节,那么,GDT中所有描述符的长度之和也就是GDT的长度是$2^{13} * 8 = 2^{16}$个字节。二者是吻合的。
看一看选择子的汇编代码。
SelectFlatX equ LABLE_GDT_FLAT_X - LABEL_GDT
SelectFlatX_16 equ LABLE_GDT_FLAT_X_16 - LABEL_GDT
SelectFlatX_162 equ LABLE_GDT_FLAT_X_162 - LABEL_GDT
SelectFlatWR equ LABLE_GDT_FLAT_WR - LABEL_GDT
SelectFlatWR_TEST equ LABLE_GDT_FLAT_WR_TEST - LABEL_GDT
SelectFlatWR_16 equ LABLE_GDT_FLAT_WR_16 - LABEL_GDT
SelectVideo equ LABLE_GDT_VIDEO - LABEL_GDT + 3
代码中的第0列(初始值规定为0)是选择子,例如SelectFlatX。表面上看,选择子是对应描述符的内存地址相对于空描述符的内存地址的偏移量。这个偏移量一定是8个字节的整数倍。
选择子的前三位分别是CPL和TI,后13位是描述符在描述符表中的索引。代码中的选择子是描述符之间的偏移量,理解偏移量和选择子结构如何吻合,是一个难点。
描述符相对于描述符表的初始地址及空描述符表的地址的偏移量,必定是8个字节的整数倍。若觉得不能透彻理解,可以举例子看看。
丢弃偏移量的低3位,相当于把偏移量左移3位(等价于除以8),结果是描述符的数量。也就是说,偏移量的高13位是选择子对应的描述符相对于描述符数组的初始位置的偏移量,但这个偏移量的单位不再是字节,而是描述符。简单说,偏移量的高13位是描述符在描述符表中的描述符偏移量。描述符偏移量不就是描述符索引么?
偏移量的高13位是描述符在描述符表中的索引,理由在上面说了。偏移量的低3位是0,正好对应选择子的低3位。把选择子的低3位即CPL、TI设置成0,从结构和数据的对应看,当然没问题。可是,选择子的低3位不会总是0,需要存储具有特定意义的数据。怎么办实现这个目的?对描述符内存地址的偏移量进行修改就能实现这个目的。
正如上面的代码中的SelectVideo。它的选择子的计算方式是:LABLE_GDT_VIDEO - LABEL_GDT + 3。
SelectVideo的TI是0,CPL是3。这表示,SelectVideo是GDT的选择子,当前特权级是3。
代码中的其他选择子,都是描述符内存地址相对于GDT初始地址的原始偏移量,没有修改低3位存储的TI和CPL。
寻址方式
保护模式下,内存地址的寻址方式如下图所示。
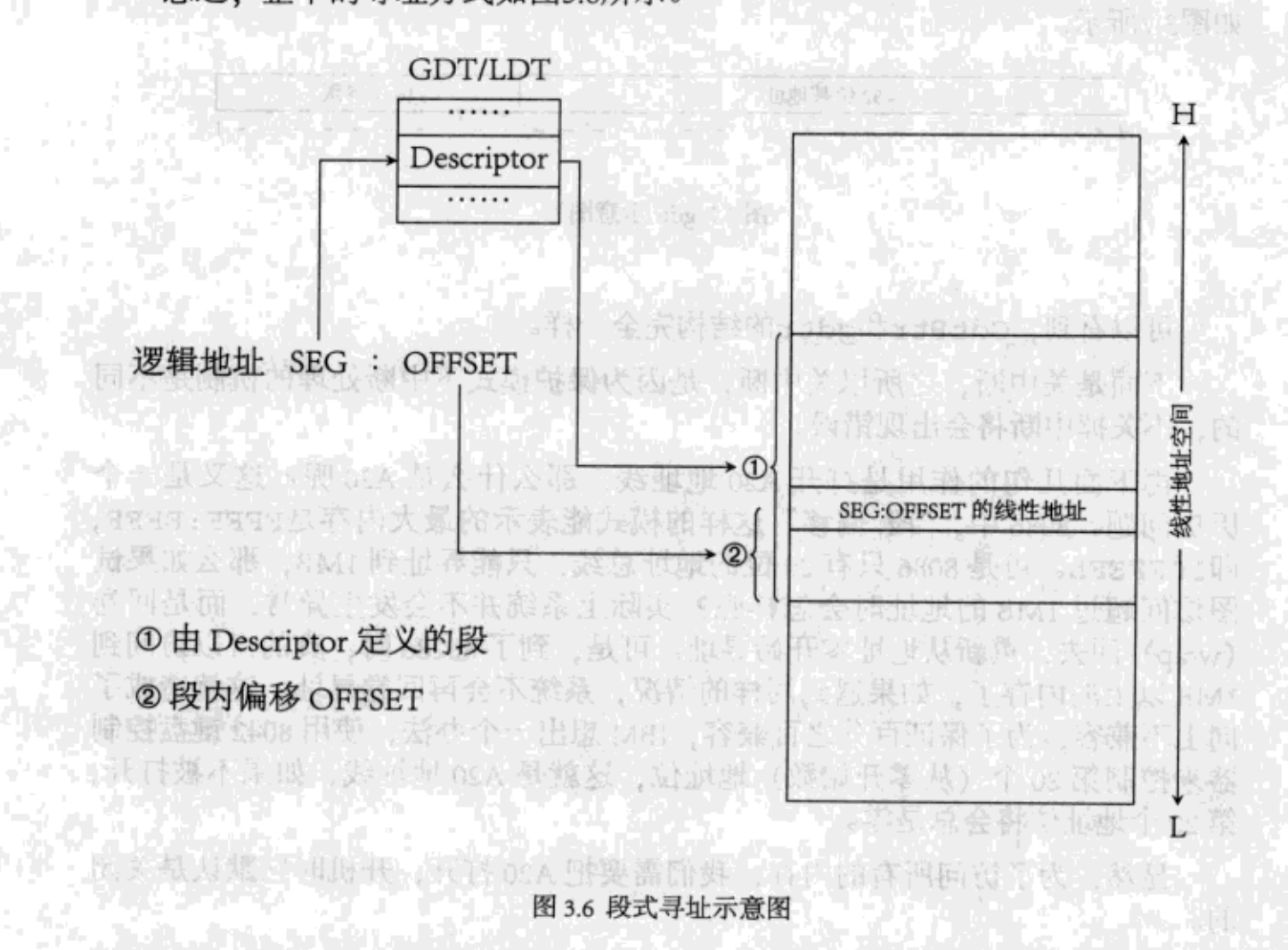
es:bx这种形式的内存地址叫“逻辑地址”。es中的值是描述符表的选择子。根据选择子在描述符表中选择它对应的描述符。- 从描述符中获取这个描述符指向的内存空间(根据描述符中包含的段基址和段界限就能划定一段内存空间)。
bx就是在这段内存空间中的地址偏移量。而es就是上图中的SEG。
进入保护模式
进入保护模式的代码如下。
; 把GdtPtr加载到寄存器gdtptr中。
mov dword [GdtPtr + 2], BaseOfLoaderPhyAddr + LABEL_GDT
lgdt [GdtPtr]
; 关闭中断。
; 关闭中断的目的是,让进入保护模式的所有操作具有原子性。
; 假如打开了A20地址线,却还处在实模式下,此时会错误处理超过了2的20次方的地址。
cli
; 打开A20地址线。
in al, 92h
or al, 10b
out 92h, al
; 准备切换到保护模式
mov eax, cr0
or eax, 1
mov cr0, eax
; 真正进入保护模式。这句把cs设置为SelectFlatX
jmp dword SelectFlatX:(BaseOfLoaderPhyAddr + LABEL_PM_START)
从实模式进入保护模式,使用这几行代码就可以了。要理解每行代码的含义,又涉及到一些古老的细节知识。我以为,这些东西作用不大,在后续功能开发中不会用到第二次。所以,对进入保护模式的方法,掌握到这个程度就足够了。
重新放置内核
内核文件kernel.bin已经从软盘中读入内存了,为什么还要重新放置内核呢?因为,这个内核文件是elf格式的。这种格式的可执行文件,不仅包含可执行的指令,还包括一些额外数据。
下面,一起来了解ELF文件。
这种起“过渡”作用的废话真的需要吗?不写这句话,直接介绍elf,又显得太突兀。
ELF
elf的全称是excutable load format。linux系统上的目标文件、可执行文件都是elf文件。elf文件包含elf头、section头表、segment、program header table。
一图胜千言。让我们看看ELF文件的结构示意图。
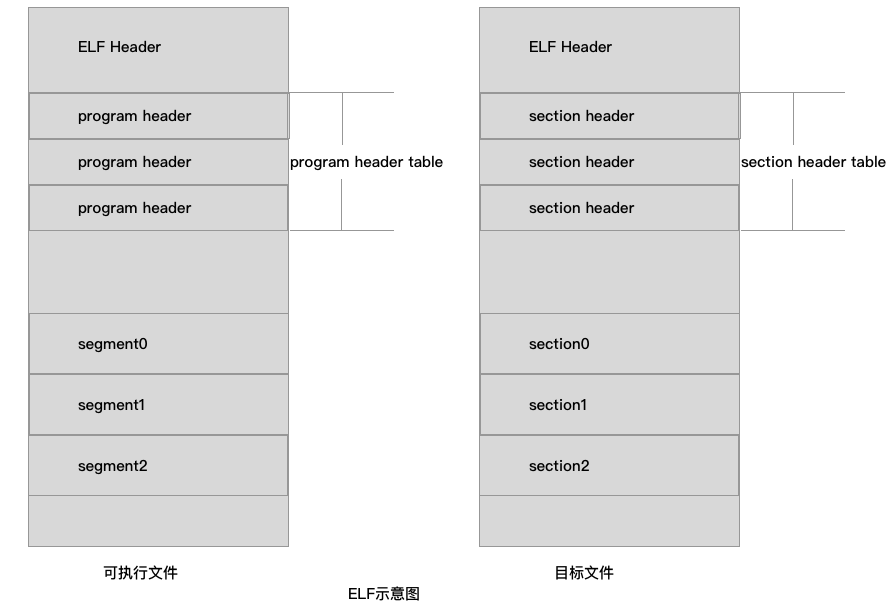
ELF的知识远远不止上面这么一点,但了解上面的知识,足以让我们理解"重新放置内核"这个操作。好奇心强烈的读者朋友可以看看下面的补充知识。不看也不会妨碍我们继续开发自己的操作系统。
复制段
流程
重新放置内核,处理的是kernel.bin。它是ELF格式的可执行文件。所谓重新放置,就是把segment0、segment1、segment2等复制到内存中的某些位置。具体流程如下:
- 从
ELF Header中查询出program header table在文件中的偏移量e_phoff和program header table中的program header的数量e_phnum。 - 每个
program header对应一个segment。program header中记录着segment在文件中的偏移量p_offset、应该在内存中的地址p_vaddr和它的大小p_filesz。 - 遍历
program header table,把对应的segment复制到p_vaddr 内存地址处。
伪代码
重新放置内核的伪代码如下。
// kernel.bin在内存中的位置。
address_of_kernel;
for(int i = 0; i < ELF_Header.e_phnum; i++ ){
// 每个program_header的大小是32字节。
program_header = program_header_table + i * 32;
// 复制program_header对应的段。
Memcpy(program_header.p_vaddr, program_header.p_offset + address_of_kernel, program_header.p_filesz);
}
汇编代码
汇编代码如下。
BaseOfKernelPhyAddr equ 80000h ; Kernel.BIN 被加载到的位置
; 重新放置内核
InitKernel:
push eax
push ecx
push esi
;程序段的个数,e_phnum
mov cx, [BaseOfKernelPhyAddr + 2CH]
movzx ecx, cx
;程序头表的内存地址
xor esi, esi
; 对应伪代码中的program_header_table,也是ELF头的e_phoff。
mov esi, [BaseOfKernelPhyAddr + 1CH]
add esi, BaseOfKernelPhyAddr
.Begin:
; program_header的p_filesz。
mov eax, [esi + 10H]
push eax
mov eax, BaseOfKernelPhyAddr
; [esi + 4H] 是program_header的 p_offset,eax的最终结果是段的内存地址。
add eax, [esi + 4H]
push eax
; [esi + 8H] 是program_header的 p_vaddr,eax的最终结果是段应该被重新放置到的内存地址。
mov eax, [esi + 8H]
push eax
; 调用复制函数。
call Memcpy
; 三个参数(每个占用32位,4个字节,2个字),占用6个字,12个字节
add esp, 12
; ecx是e_phnum。重新复制一个段后,ecx的值应该减去1。
dec ecx
; 当ecx的值是0时,所有的段已经处理完毕。
cmp ecx, 0
jz .NoAction
; 一个program_header的大小是20H,处理完一个program_header后,
; 应该处理下一个program_header。
add esi, 20H
jmp .Begin
.NoAction:
pop esi
pop ecx
pop eax
ret
验证
重新放置内核后,怎么知道有没有把内核中的代码段放置到了正确的内存位置呢?
有人说,执行一次呗。如果能看到内核运行的效果,就说明是正确的。
我试过,这样不能验证内核被正确地重新放置了。内核也就是kernel.bin是一个ELF文件,除了包含代码段,还包含很多CPU不能识别的数据。直接运行kernel.bin,CPU遇到不能识别的数据就不处理,遇到了代码段就执行,所以,即使没有正确地放置内核,也能看到内核运行效果。也许是因为我们目前的内核太简单。
验证内核有没有被正确放置到内存中的方法是,使用bochs查看内存中的数据。让我们一起来验证一下。
实例分析ELF文件
用xxd查看kernel.bin的数据data。
[root@localhost v4]# xxd -u -a -g 1 -c 16 kernel.bin
00000000: 7F 45 4C 46 01 01 01 00 00 00 00 00 00 00 00 00 .ELF............
00000010: 02 00 03 00 01 00 00 00 00 04 03 00 34 00 00 00 ............4...
00000020: 30 04 00 00 00 00 00 00 34 00 20 00 01 00 28 00 0.......4. ...(.
00000030: 03 00 02 00 01 00 00 00 00 00 00 00 00 00 03 00 ................
00000040: 00 00 03 00 1D 04 00 00 1D 04 00 00 05 00 00 00 ................
00000050: 00 10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000060: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
*
00000400: B4 0F B0 43 65 66 A3 D0 0C 00 00 65 66 A3 70 0D ...Cef.....ef.p.
00000410: 00 00 65 66 A3 60 0E 00 00 EB FE EB FE 00 2E 73 ..ef.`.........s
00000420: 68 73 74 72 74 61 62 00 2E 74 65 78 74 00 00 00 hstrtab..text...
00000430: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000440: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000450: 00 00 00 00 00 00 00 00 0B 00 00 00 01 00 00 00 ................
00000460: 06 00 00 00 00 04 03 00 00 04 00 00 1D 00 00 00 ................
00000470: 00 00 00 00 00 00 00 00 10 00 00 00 00 00 00 00 ................
00000480: 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 ................
00000490: 1D 04 00 00 11 00 00 00 00 00 00 00 00 00 00 00 ................
000004a0: 01 00 00 00 00 00 00 00 ........
从上面的数据中找出:program header table在文件中的偏移量e_phoff、第一个代码段在段中的偏移量p_offset、第一个代码段被重新放置到内存中后的初始地址p_vaddr、程序在内存中的入口地址e_entry。
e_phoff。在文件中的偏移量是1CH,长度是4个字节。- program header table在文件中的地址就是
e_phoff。 - 在data中找到
e_phoff,是34 00 00 00。这是十六进制数。 34 00 00 00是十六进制数,左边是低内存地址,右边是高内存地址。- 把它写成我们平时的读写顺序,这个数字应该是
0x34。
- program header table在文件中的地址就是
e_entry。在文件中的偏移量是18H,长度是4个字节,值是00 04 03 00,换算成0x030400。p_offset。在program header中的偏移量是4H,在文件中的偏移量是0x34+0x4,长度是4个字节。- 代码段在文件中的地址就是
p_offset。 p_offset是00 00 00 00,和前面转换34 00 00 00的方法一样,00 00 00 00是0x0。
- 代码段在文件中的地址就是
p_vaddr。在段中的偏移量是8H,在文件中的偏移量是0x34+0x8,长度是4个字节。- 值是
00 00 03 00,换算成0x030000。
- 值是
- 程序的入口在文件中的偏移量是什么?
- ELF文件没有直接提供这个数据,但我们可以计算出来。
- 先计算程序的入口在段中的偏移量。
- 程序的入口在内存中的地址是
e_entry,段在内存中的地址是p_vaddr。 - 程序的入口是段中的一条指令。这一句非常关键。
e_entry - p_vaddr就是程序的入口在段中的偏移量offset。段在文件中的偏移量 + 程序的入口在段中的偏移量就是程序的入口在段中的偏移量。- 这个值是:
0 + 0x030400 - 0x030000 = 0x400。
还需要知道代码段的长度p_filesz。它在program header中的偏移量是10H,在文件中的偏移量是0x34 + 0x10 = 0x44,因而,值是1D 04 00 00,换算成0x041D。
在上面写了这么多,就是为了得出下列结论:
- 第一个代码段在文件中的偏移量是
0x0,应该被重新放置到内存地址p_vaddr即0x30000。 - 程序的入口的内存地址
e_entry即0x30400,在文件内的偏移量是0x400。 - 第一个代码段的长度是
p_filesz即0x041D。
我们继续进行分析ELF文件。
代码段的数据是:
00000000: 7F 45 4C 46 01 01 01 00 00 00 00 00 00 00 00 00 .ELF............
00000010: 02 00 03 00 01 00 00 00 00 04 03 00 34 00 00 00 ............4...
00000020: 30 04 00 00 00 00 00 00 34 00 20 00 01 00 28 00 0.......4. ...(.
00000030: 03 00 02 00 01 00 00 00 00 00 00 00 00 00 03 00 ................
00000040: 00 00 03 00 1D 04 00 00 1D 04 00 00 05 00 00 00 ................
00000050: 00 10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000060: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
*
00000400: B4 0F B0 43 65 66 A3 D0 0C 00 00 65 66 A3 70 0D ...Cef.....ef.p.
00000410: 00 00 65 66 A3 60 0E 00 00 EB FE EB FE 00 2E 73 ..ef.`.........s
这是第一个代码段中的数据?没有搞错吗?怎么这个代码段包含了ELF Header和program header table?
分析ELF文件后,我发现,第一个代码段的确包含了ELF Header和program header table。可我在《一个操作系统的实现》、《程序员的自我修改---链接、装载与库》、维基百科中看到的ELF文件结构示意图都把segment和ELF画成互不包含的两个部分。怎么理解两类矛盾的现象?是这些书写错了吗?
它们没有错。正确的理解应该是,这些资料中的图是第二个、第三个代码段(反正不是第一个代码段)和ELF Header、program header table的结构示意图。
回到“验证内核中的指令是否正确''这个主题上来。
在data中,从0x400到0x41C都是代码段中的指令,就是下面这块数据。
00000400: B4 0F B0 43 65 66 A3 D0 0C 00 00 65 66 A3 70 0D ...Cef.....ef.p.
00000410: 00 00 65 66 A3 60 0E 00 00 EB FE EB FE -- -- -- ..ef.`.........s
程序在内存中的初始地址是0x30400。我们只需对比内存0x30400到0x3041C中的数据是否和上面文件中0x400到0x41C`数据一一相等,就能判断内核是否被正确地放置到了内存中。
请看下面的表格。
表格中的"地址偏移量"是指文件地址偏移量和内存地址偏移量。两个偏移量相等,只不过地址的基址不同。
文件地址的基址是0x0,内存地址的基址是0x30000。
启动bochs,查看内存地址0x30400、0x30401、0x30402中的数据,并填入下面的表格。
(0) Magic breakpoint
Next at t=14812083
(0) [0x000000090312] 0008:0000000000090312 (unk. ctxt): jmpf 0x0008:00030400 ; ea000403000800
<bochs:2> xp /1wx 0x30400
[bochs]:
0x0000000000030400 <bogus+ 0>: 0x43b00fb4
<bochs:3> xp /1bx 0x30400
[bochs]:
0x0000000000030400 <bogus+ 0>: 0xb4
<bochs:4> xp /1bx 0x30401
[bochs]:
0x0000000000030401 <bogus+ 0>: 0x0f
<bochs:5> xp /1bx 0x30402
[bochs]:
0x0000000000030402 <bogus+ 0>: 0xb0
<bochs:6> xp /1bx 0x3041D
[bochs]:
0x000000000003041d <bogus+ 0>: 0x00
<bochs:7> XP /bx 0x3041C
:7: syntax error at 'XP'
<bochs:8> xp /1bx 0x3041C
[bochs]:
0x000000000003041c <bogus+ 0>: 0xfe
| 地址偏移量 | 0x400 | 0x401 | 0x402 | 0x41C |
|---|---|---|---|---|
| 文件中的数据 | B4 | 0F | B0 | FE |
| 内存中的数据 | b4 | 0f | b0 | fe |
表格中的数据都是十六进制数据,无论是否有没有0x前缀。十六进制数据中的字母大小写不敏感。比较下面几个地址处的数据是否相等。一眼就能看出,文件中的数据和内存中对应位置的数据相等。我只对比了几个地址的数据。读者朋友如果不相信这个结果,可以继续看看其他地址处的数据是否相同。
如果你经过对比后发现内存中的第一个段的数据和文件中的段的数据完全相同,就可以做出判断了:内核被正确地重新放置到了内存中。
留一个疑问。我们对比的是内存中的第一个段的数据和文件中的段的数据,然而,重新放置内核并不是直接从软盘中的文件中读取数据再放置,而是从内存的一个位置把内核数据重新放置到另一个位置。我的问题是:对比内存中的数据和软盘中的文件中的数据,效果等同于对比内存中的数据和另一段内存中的数据。为什么二者的效果是等同的?
补充知识
.text是代码段,.bss 段保存未初始化的变量,.rodata段保存字符串或只读变量,.data段保存已经初始化了的全局或局部静态变量。它们都是section或segment。
在可执行文件中,它们是segment。在目标文件等非执行文件中,它们是section。
在”kernel"这个小节,编译kernel.asm产生的kernel.o是目标文件,kernel.bin是可执行文件。使用file命令查看这两个文件。
[root@localhost v4]# file kernel.o
kernel.o: ELF 32-bit LSB relocatable, Intel 80386, version 1 (SYSV), not stripped
[root@localhost v4]# file kernel.bin
kernel.bin: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), statically linked, stripped
kernel.o 是ELF 32-bit LSB relocatable,kernel.bin是 ELF 32-bit LSB executable。二者都是ELF文件,但前者是relocatable,后者是executable。
只有ELF Header的位置在ELF文件中是固定的,在开头。其他元素例如program header table的位置不固定,在ELF Header中记录了它们的位置、大小等信息。
想了解更多关于ELF的知识,请去看《一个操作系统的实现》的5.3节和《程序员的自我修改》的第3章。
《一个操作系统的实现》中的elf文件的结构和《程序员的自我修改》中的elf文件的结构不同。另外,像.rodata、.bss、.text这些,在《一个操作系统的实现》中没有出现。我不清楚,像.rodata、.bss、.text这些和section头表、segment头表、program header table的关系。
section头等都挨在一起组成一个表,是这样吗?
program header描述一个segment 还是一个segment header?二者是一一对应的关系吗?
segment 只存在于可执行文件中吗?
参考资料
《一个操作系统的实现》
《程序员的自我修养---链接、装载与库》
代码注释
我不知道怎么用更好的方式写剩下的内容,就直接送上添加了详细注释的loader.asm吧。
; 暂时不必理会这句的意思。
org 0100h
jmp LABEL_START
nop
; 下面是 FAT12 磁盘的头
BS_OEMName DB 'YOUR--OS' ; OEM String, 必须 8 个字节
BPB_BytsPerSec DW 512 ; 每扇区字节数
BPB_SecPerClus DB 1 ; 每簇多少扇区
BPB_RsvdSecCnt DW 1 ; Boot 记录占用多少扇区
BPB_NumFATs DB 2 ; 共有多少 FAT 表
BPB_RootEntCnt DW 224 ; 根目录文件数最大值
BPB_TotSec16 DW 2880 ; 逻辑扇区总数
BPB_Media DB 0xF0 ; 媒体描述符
BPB_FATSz16 DW 9 ; 每FAT扇区数
BPB_SecPerTrk DW 18 ; 每磁道扇区数
BPB_NumHeads DW 2 ; 磁头数(面数)
BPB_HiddSec DD 0 ; 隐藏扇区数
BPB_TotSec32 DD 0 ; wTotalSectorCount为0时这个值记录扇区数
BS_DrvNum DB 0 ; 中断 13 的驱动器号
BS_Reserved1 DB 0 ; 未使用
BS_BootSig DB 29h ; 扩展引导标记 (29h)
BS_VolID DD 0 ; 卷序列号
BS_VolLab DB 'YOUR--OS.02'; 卷标, 必须 11 个字节
BS_FileSysType DB 'FAT12 ' ; 文件系统类型, 必须 8个字节
; 三个参数分别是段基址、段界限、段属性
; 分别用 %1、%2、%3表示上面的三个参数
%macro Descriptor 3
dw %2 & 0ffffh
dw %1 & 0ffffh
db (%1 >> 16) & 0ffh
db %3 & 0ffh
db ((%2 >> 16) & 0fh) | (((%3 >> 8) & 0fh) << 4)
db (%1 >> 24) & 0ffh
%endmacro
; 描述符和选择子的详细讲解请看本问的”GDT”、"选择子"小节。
; 空描述符,也是GDT的地址。
LABEL_GDT: Descriptor 0, 0, 0
; 代码段描述符
LABLE_GDT_FLAT_X: Descriptor 0, 0ffffffh, 0c9ah
; 数据段描述符
LABLE_GDT_FLAT_WR:Descriptor 0, 0fffffh, 0c92h
; 显存段描述符
LABLE_GDT_VIDEO: Descriptor 0b8000h, 0ffffh, 0f2h
; GDT地址,在下面加载到gdtptr寄存器。
; GDT的长度。
GdtLen equ $ - LABEL_GDT
GdtPtr dw GdtLen - 1
dd BaseOfLoaderPhyAddr + LABEL_GDT
; 代码段的选择子
SelectFlatX equ LABLE_GDT_FLAT_X - LABEL_GDT
; 数据段的选择子
SelectFlatWR equ LABLE_GDT_FLAT_WR - LABEL_GDT
; 显存段的选择子
SelectVideo equ LABLE_GDT_VIDEO - LABEL_GDT + 3
LABEL_START:
; 打印X
mov ax, 0B800h
mov gs, ax
mov ah, 0Ch
mov al, 'X'
mov [gs:(80 * 16 + 20)*2], ax
; 下面的代码把kernel.bin从软盘中加载到内存中,和从软盘中读取loader.bin相似,
; 请看上一篇文章《开发引导扇区》中的代码注释。
mov ax, BaseOfKernel
mov es, ax
mov ax, 0x9000
mov ds, ax
; 复位软驱
mov ah, 00h
mov dl, 0
int 13h
mov ax, FirstSectorOfRootDirectory
mov cl, 1
mov bx, OffSetOfLoader
call ReadSector
mov cx, 4
mov bx, (80 * 18 + 40) * 2
mov di, OffSetOfLoader
SEARCH_FILE_IN_ROOT_DIRECTORY:
cmp cx, 0
jz FILE_NOT_FOUND
push cx
mov si, LoaderBinFileName
mov cx, LoaderBinFileNameLength
mov dx, 0
COMPARE_FILENAME:
;cmp [es:si], [ds:di]
;cmp [si], [di]
lodsb
cmp al, byte [es:di]
jnz FILENAME_DIFFIERENT
dec cx
inc di
inc dx
cmp dx, LoaderBinFileNameLength
jz FILE_FOUND
jmp COMPARE_FILENAME
FILENAME_DIFFIERENT:
mov al, 'E'
mov ah, 0Ch
mov [gs:bx], ax
add bx, 160
pop cx ; 在循环中,cx会自动减少吗?
cmp cx, 0
dec cx
jz FILE_NOT_FOUND
;;;;;xchg bx, bx
and di, 0xFFE0 ; 低5位设置为0,其余位数保持原状。回到正在遍历的根目录项的初始位置
add di, 32 ; 增加一个根目录项的大小
jmp SEARCH_FILE_IN_ROOT_DIRECTORY
FILE_FOUND:
mov al, 'S'
mov ah, 0Ah
mov [gs:(80 * 23 + 35) *2], ax
;;;;xchg bx, bx
; 修改段地址和偏移量后,获取的第一个簇号错了
; 获取文件的第一个簇的簇号
and di, 0xFFE0 ; 低5位设置为0,其余位数保持原状。回到正在遍历的根目录项的初始位置; 获取文件的第一个簇的簇号
add di, 0x1A
mov si, di
mov ax, BaseOfKernel
push ds
mov ds, ax
;;;;xchg bx, bx
lodsw
pop ds
push ax
;;;;xchg bx, bx
; call GetFATEntry
mov bx, OffSetOfLoader
; 获取到文件的第一个簇号后,开始读取文件
READ_FILE:
;;;;xchg bx, bx
push bx
; push ax
; 簇号就是FAT项的编号,把FAT项的编号换算成字节数
;;push bx
;mov dx, 0
;mov bx, 3
;mul bx
;mov bx, 2
;div bx ; 商在ax中,余数在dx中
;mov [FATEntryIsInt], dx
;
;; 用字节数计算出FAT项在软盘中的扇区号
;mov dx, 0
;mov bx, 512
;div bx ; 商在ax中,余数在dx中。商是扇区偏移量,余数是在扇区内的字节偏移量
; 簇号就是FAT项的编号,同时也是文件块在数据区的扇区号。
; 用簇号计算出目标扇区在软盘中的的扇区号。
add ax, 19
add ax, 14
sub ax, 2
; 读取一个扇区的数据 start
; add ax, SectorNumberOfFAT1
mov cl, 1
pop bx
call ReadSector
;;;;xchg bx, bx
add bx, 512
; 读取一个扇区的数据 end
;jmp READ_FILE_OVER
pop ax
push bx
call GetFATEntry
pop bx
push ax
cmp ax, 0xFF8
; 注意了,ax >= 0xFF8 时跳转,使用jc 而不是jz。昨天,一定是在这里弄错了,导致浪费几个小时调试。
;jz READ_FILE_OVER
;jc READ_FILE_OVER
jnb READ_FILE_OVER
;mov al, 'A'
;inc al
;mov ah, 0Ah
;mov [gs:(80 * 23 + 36) *2], ax
;;;;;xchg bx, bx
jmp READ_FILE
FILE_NOT_FOUND:
mov al, 'N'
mov ah, 0Ah
mov [gs:(80 * 23 + 36) *2], ax
jmp OVER
READ_FILE_OVER:
;xchg bx, bx
;mov al, 'O'
;mov ah, 0Dh
;mov [gs:(80 * 23 + 33) * 2], ax
; 开启保护模式 start
;cli
;mov dx, BaseOfLoaderPhyAddr + LABEL_PM_START ;;xchg bx, bx
lgdt [GdtPtr]
cli
in al, 92h
or al, 10b
out 92h, al
mov eax, cr0
or eax, 1
mov cr0, eax
;xchg bx, bx
; 真正进入保护模式。这句把cs设置为SelectFlatX
;jmp dword SelectFlatX:(BaseOfLoaderPhyAddr + 100h + LABEL_PM_START)
;jmp dword SelectFlatX:dx
jmp dword SelectFlatX:(BaseOfLoaderPhyAddr + LABEL_PM_START)
; 开启保护模式 end
; 在内存中重新放置内核
;call InitKernel
;;;xchg bx, bx
;jmp BaseOfKernel:73h
;jmp BaseOfKernel:61h
;jmp BaseOfKernel2:400h
;jmp BaseOfKernel:60h
;jmp BaseOfKernel:0
;jmp BaseOfKernel:OffSetOfLoader
;jmp BaseOfKernel2:0x30400
;jmp BaseOfKernel:OffSetOfLoader
;jmp BaseOfKernel:40h
;jmp OVER
OVER:
jmp $
BootMessage: db "Hello,World OS!"
;BootMessageLength: db $ - BootMessage
; 长度,需要使用 equ
BootMessageLength equ $ - BootMessage
FirstSectorOfRootDirectory equ 19
SectorNumberOfTrack equ 18
SectorNumberOfFAT1 equ 1
;LoaderBinFileName: db "KERNEL BIN"
LoaderBinFileName: db "KERNEL BIN"
LoaderBinFileNameLength equ $ - LoaderBinFileName ; 中间两个空格
FATEntryIsInt equ 0 ; FAT项的字节偏移量是不是整数个字节:0,不是;1,是。
BytesOfSector equ 512 ; 每个扇区包含的字节数量
; 根据FAT项的编号获取这个FAT项的值
GetFATEntry:
; 用FAT项的编号计算出这个FAT项的字节偏移量 start
; mov cx, 3
; mul cx
; mov cx, 2
;div cx ; 商在al中,余数在ah中 ;
push ax
MOV ah, 00h
mov dl, 0
int 13h
pop ax
mov dx, 0
mov bx, 3
mul bx
mov bx, 2
div bx
; 用FAT项的编号计算出这个FAT项的字节偏移量 end
mov [FATEntryIsInt], dx
; 用字节偏移量计算出扇区偏移量 start
mov dx, 0
; and ax, 0000000011111111b ; 不知道这句的意图是啥,忘记得太快了!
; mov dword ax, al ; 错误用法
; mov cx, [BytesOfSector]
mov cx, 512
div cx
; push dx
add ax, SectorNumberOfFAT1 ; ax 是在FAT1区域的偏移。要把它转化为在软盘中的扇区号,需加上FAT1对软盘的偏移量。
; mov ah, 00h
; mov dl, 0
; int 13h
; 用字节偏移量计算出扇区偏移量 end
; mov dword ax, al
; add ax,1
mov cl, 2
mov bx, 0
push es
push dx
push ax
mov ax, BaseOfFATEntry
mov es, ax
pop ax
; 用扇区偏移量计算出在某柱面某磁道的扇区偏移量,可以直接调用ReadSector
call ReadSector
;pop es
;;;;;;xchg bx, bx
;pop ax
;mov ax, [es:bx]
pop dx
add bx, dx
mov ax, [es:bx]
pop es
; 根据FAT项偏移量是否占用整数个字节来计算FAT项的值
cmp byte [FATEntryIsInt], 0
jz FATEntry_Is_Int
shr ax, 4
FATEntry_Is_Int:
and ax, 0x0FFF
ret
; 读取扇区
ReadSector:
push ax
push bp
push bx
mov bp, sp
sub sp, 2
mov byte [bp-2], cl
; push al ; error: invalid combination of opcode and operands
;push cx
; mov bx, SectorNumberOfTrack
; ax 存储在软盘中的扇区号
mov bl, SectorNumberOfTrack ; 一个磁道包含的扇区数
div bl ; 商在al中,余数在ah中
mov ch, al
shr ch, 1 ; ch 是柱面号
mov dh, al
and dh, 1 ; dh 是磁头号
mov dl, 0 ; 驱动器号,0表示A盘
inc ah
mov cl, ah
;add cl, 1 ; cl 是起始扇区号
; pop al ; al 是要读的扇区数量
mov al, [bp-2]
add sp, 2
mov ah, 02h ; 读软盘
pop bx
;mov bx, BaseOfKernel ; 让es:bx指向BaseOfKernel
;mov ax, cs
;mov es, ax
;;;;;;xchg bx, bx
int 13h
;pop cx
;;;;;;xchg bx, bx
; pop bx
pop bp
pop ax
ret
;
; mov ch, 0
; mov cl, 1
; mov dh, 0
; mov dl, 0
; mov al, 1 ; 要读的扇区数量
; mov ah, 02h ; 读软盘
; mov bx, BaseOfKernel ; 让es:bx指向BaseOfKernel
; int 13h ; int 13h 中断
; ret
; 读取扇区
ReadSector2:
mov ch, 0
mov cl, 2
mov dh, 1
mov dl, 0
mov al, 1 ; 要读的扇区数量
mov ah, 02h ; 读软盘
mov bx, BaseOfKernel ; 让es:bx指向BaseOfKernel
int 13h ; int 13h 中断
ret
BaseOfKernel equ 0x8000
BaseOfKernel2 equ 0x6000
BaseOfKernel3 equ 0x0
OffSetOfLoader equ 0x0
BaseOfFATEntry equ 0x1000
BaseOfLoader equ 0x9000
BaseOfLoaderPhyAddr equ BaseOfLoader * 10h ; LOADER.BIN 被加载到的位置 ---- 物理地址 (= BaseOfLoader * 10h)
[SECTION .s32]
ALIGN 32
[BITS 32]
LABEL_PM_START:
; 初始化一些寄存器
mov ax, SelectFlatWR
mov ds, ax
mov es, ax
mov fs, ax
mov ss, ax
mov ax, SelectVideo
mov gs, ax
mov gs, ax
mov al, 'K'
mov ah, 0Ah
mov [gs:(80 * 19 + 25) * 2], ax
; 重新放置内核
call InitKernel
;xchg bx, bx
;mov gs, ax
mov al, 'G'
mov ah, 0Ah
mov [gs:(80 * 19 + 20) * 2], ax
xchg bx, bx
;jmp 0x30400
; 开始执行内核代码。
jmp SelectFlatX:0x30400
; 等同于while(1){}
jmp $
jmp $
jmp $
jmp $
; 重新放置内核
InitKernel:
push eax
push ecx
push esi
;xchg bx, bx
;程序段的个数
;mov cx, word ptr ds:0x802c
mov cx, [BaseOfKernelPhyAddr + 2CH]
movzx ecx, cx
;程序头表的内存地址
xor esi, esi
mov esi, [BaseOfKernelPhyAddr + 1CH]
add esi, BaseOfKernelPhyAddr
;xchg bx, bx
.Begin:
mov eax, [esi + 10H]
push eax
mov eax, BaseOfKernelPhyAddr
add eax, [esi + 4H]
push eax
mov eax, [esi + 8H]
push eax
call Memcpy
;xchg bx, bx
; 三个参数(每个占用32位,4个字节,2个字),占用6个字,12个字节
add esp, 12
dec ecx
cmp ecx, 0
jz .NoAction
add esi, 20H
jmp .Begin
.NoAction:
;xchg bx, bx
pop esi
pop ecx
pop eax
ret
; Memcpy(p_vaddr, p_off, p_size)
Memcpy:
push ebp
mov ebp, esp
push eax
push ecx
push esi
push edi
;mov bp, sp
;mov di, [bp + 4] ; p_vaddr,即 dst
;mov si, [bp + 8] ; p_off,即 src
;mov cx, [bp + 12] ; 程序头的个数,即p_size
;mov di, [bp + 8] ; p_vaddr,即 dst
;mov si, [bp + 12] ; p_off,即 src
;mov cx, [bp + 16] ; 程序头的个数,即p_size
mov edi, [ebp + 8] ; p_vaddr,即 dst
mov esi, [ebp + 12] ; p_off,即 src
mov ecx, [ebp + 16] ; 程序头的个数,即p_size
push es
; 在32位模式下,这两步操作不需要。而且,我没有找到把大操作数赋值给小存储单元的指令。
; mov es, edi
; mov edi, 0
.1:
mov byte al, [ds:esi]
mov [es:edi], al
inc esi
inc edi
dec ecx
cmp ecx, 0
jz .2
jmp .1
.2:
pop es
mov eax, [ebp + 8]
pop edi
pop esi
pop ecx
pop eax
pop ebp
ret
BaseOfKernelPhyAddr equ 80000h ; Kernel.BIN 被加载到的位置 ---- 物理地址 中的段基址部分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号