设计模式、设计原则、重构与编码规范(设计模式之美笔记)
设计模式要干的事情就是对复杂解耦。利用更好的代码结构将一大坨代码拆分成职责更单一的小类,让其满足高内聚低耦合等特性。
创建型模式是将创建和使用代码解耦,结构型模式是将不同的功能代码解耦,行为型模式是将不同的行为代码解耦。
而解耦的主要目的是应对代码的复杂性。设计模式就是为了解决复杂代码问题而产生的。

为什么设计模式?
- 面试会问
- 提高复杂代码的设计和开发能力。避免只是框架用的溜。
- 如何分层、分模块、分类
- 每个类应该有哪些属性和方法
- 怎么设计类之间的交互,用继承还是组合
- 使用接口还是抽象类,怎么做到解耦、高内聚和低耦合
- 该用单例模式还是静态方法
- 用工厂模式创建对象还是直接new出来
- 如何避免使用了设计模式提高扩展性的同时降低了可读性
- 告别写被人吐槽的烂代码,团队里面的代码标杆,不经意间写出来的代码,都能作为同事学习、临摹的范例。
- 读源码的时候根据设计模式推测作者的思路,做到事半功倍。
如何评价代码质量的好坏?
即使一段代码的可扩展性很好,但可读性很差,那我们也不能说这段代码质量高。常见的评价指标:
- 可维护性:分层清晰、模块化好、高内聚低耦合、遵从基于接口而非实现编程的设计原则,比较好的遵循了开闭原则等等。还和代码量的多少、业务的复杂程度、利用到的技术的复杂程度、文档是否全面、团队成员的开发水平等诸多因素有关。
- 可读性:需要看命名是否达意,注释是否详尽,函数长短是否合适,模块划分是否清晰
- 可扩展性:代码应对未来需求变化的能力,开闭原则
- 灵活性:一般粒度越小的方法,通用性灵活性越好。
- 简洁性:思从深而行从简,Keep it simple, stupid
- 可复用性:减少重复code编写
如何写出好的代码?
就等同于在问,如何写出易维护、易读、易扩展、灵活、简洁、可复用、可测试的代码。
基于面向对象,借助一些设计原则和设计模式,编写的时候遵循代码规范并且不断开发的过程中不断重构,就可以写出。
- 面向对象设计思想:****是很多设计原则、设计模式等编码实现的基础。
- 设计原则:SOLID 原则,DRY 原则、KISS 原则、YAGNI 原则、LOD 法则。掌握它的设计初衷,能解决哪些编程问题,有哪些应用场景。
- 设计模式:相对于设计原则来说,没有那么抽象。应用设计模式的主要目的是提高代码的可扩展性。
- 编码规范:偏向于记忆,只要照着做可以。不像设计原则需要融入很多个人的理解和思考。一般的持续的小重构就是改写到符合编码规范:命名注释函数长度等等。
- 重构技巧:前面说的都是重构的工具,不要过度设计,重构应该融入到日常的开发当中。大重构除非无可救药。
如何评价编程能力?
一个编程能力强的人,能熟练使用编程语言、开发类库等工具,思路清晰,面对复杂的逻辑,能够编写出 bug free 的代码,能够合理地利用数据结构和算法编写高效的代码,能够灵活地使用设计思想、原则和模式,编写易读、易扩展、易维护、可复 用的高质量代码。
一个编程能力差的人,往往逻辑思维能力比较差,面对复杂的逻辑,编写代码的速度很慢,而且容易考虑不周,写出来的代码 bug 很多,更没有性能意识,不懂得如何分析代码的时间复杂度、空间复杂度,更不懂得如何借助现成的数据结构和算法来优化代码性能。除此之外,写代码的时候,几乎不考虑代码的可读性、可扩展性等质量问题,只追求能运行就可以。
满嘴“架构、高可用、 高并发、分布式”,往往代码写得惨不忍睹。一般来讲,编程语言都可以快速掌握,只是顺带着考察一下就可以了。重点是:数据结构和算法,设计思想、原则和模式。不依赖很强的算法背景和特殊的解题技巧的题目,比较适合用来面试。“写一个函数将 IPv4 地址字符串(仅包含数字、点、空格) 转化成 32 位整数。另外,数字和点之间的空格是合法的,其他情况均为非法地址,要求输出合法地址的 32 位整型结果。”
算法与设计模式的侧重点分别是什么?
算法是写出高性能代码,设计思想和模式是编写易读、易扩展、易维护的高质量代码。共同奠定了一个人的编程能力。
刷题不仅仅能加强你对数据结构和算法的掌握,还能锻炼你的逻辑思维能力、写出 bug free 代码的能力、快速实现复杂逻辑的能力,也能锻炼你的性能意识。
设计思想、原则和模式需要在平时的开发中进行练习。拿到一个功能需求的时候,先去思考一下如何设计,而不是上来就写代码。写代码时,时刻思考代码是否遵循了经典的设计思想、设计原则。做 Code Review 的时候,思考哪些值得借鉴的地方。
接手项目如何熟悉?
在读代码的过程中,读懂的业务写到文档中。对于复杂的业务流程,画一些流程图。方便新人和自己。
面向对象设计思想
面向对象和面向过程的区别?
使用面向对象语言写出来的也可能是面向过程的代码。
面向过程在代码量大的时候可维护性是比较低的,是按照事情执行的顺序编写的。
面向对象在代码量大的时候为代码提供了高扩展性和可维护性的可能。采用实体和现实世界对应的编程方式,让代码更加符合现实世界的组织关系。
OOA、OOD、OOP是什么?
- 面向对象分析(OOA)其实就是需求分析,产出就是PRD以及线框图
- 面向对象设计(OOD)其实就是类设计,产出就是UML类图
- 首先将需求划分职责,识别出类。之后定义类中的属性和方法。然后定义类之间的交互关系,画出UML图,最后将类组装起来提供统一入口供外部调用
- 面向对象编程(OOP)就是将类转换为代码。
面向对象四大特性?
- 封装:暴露有限的接口授权外部使用。需要语言支持:private、public 等关键字就是 Java 语言中的访问权限控制支持
- 数据隐藏与保护,提高类的易用性。
- 抽象:让调用者只需要关心方法提供了哪些功能,并不需要知道这些功能是如何实现的。使用java中的 abstract 和 interface 实现
- 隐藏方法的具体实现,减少代码的改动范围。
- 继承:is a 关系。多用组合少用继承。否则代码难以维护
- 表示 is-a 关系,支持多态特性,代码复用。
- 多态:子类可以替换父类。父类要可以引用子类对象,语言要支持继承,子类可以重写父类中的方法。
- 提高代码的可扩展性和复用性。
常见违反面向对象的设计?
- 滥用 getter、setter 方法:除非真的需要,尽量不要给属性定义 setter 方法。除此之外,如果返回的是集合容器,那也要防范集合内部数据被修改的风险,明确是否需要返回不可变的集合。
- Constants 类、Utils 类的设计:尽量能做到职责单一,定义一些细化的小类,比如 RedisConstants、FileUtils,而不是定义一个大而全的 Constants 类、Utils 类。
- 基于贫血模型的开发模式:是彻彻底底的面向过程编程风格的。数据和操作是分开定义在 VO/BO/Entity 和 Controler/Service/Repository 中的。
接口与抽象类的区别?
抽象类表示一种 is-a 关系,继承来实现,表示属于某一类。用来复用重复的代码。
接口表示一种 has-a 关系,表示具有某些功能。用来解耦。
为什么要面向接口而非实现编程?
封装不稳定的实现,实现代码的解耦。如果某个功能只有一种实现方式,未来也不会有其他的实现方式,就没有必要为其设计接口,直接使用实现类就可以了。
接口的函数的命名不能暴露任何实现细节。改为更加抽象的命名方式。
为什么多用组合少用继承?
继承是反模式的,继承层次过深、继承关系过于复杂会影响到代码的可读性和可维护性。想要给某个类增加功能会影响所有子类,要么就新建一个类导致类数量爆炸。
继承主要有三个作用:表示 is-a 关系,支持多态特性,代码复用。而这三个作用都可以通过其他技术手段来达成。
- is-a 关系,我们可以通过组合和接口的 has-a 关系来替代;
- 多态特性我们可以利用接口来实现;
- 代码复用我们可以通过组合和委托来实现。
如果类的继承关系清晰,继承层次比较浅,关系不复杂,就可以大胆使用继承。
MVC三层架构贫血模型与DDD的充血模型的区别是什么?
- 基于贫血模型的传统开发模式:数据和对应的业务逻辑被封装到不同类中。Entity 和 Repository 组成了数据访问层,Bo 和 Service 组成了业务逻辑层,Vo 和 Controller 在这里属于接口层。像 Bo 这样, 只包含数据,不包含业务逻辑的类,就叫作贫血模型(Anemic Domain Model)。同理,Entity、Vo 都是基于贫血模型设计的。这种贫血模型将数据与操作分离,破坏了面向对象的封装特性,是一种典型的面向过程的编程风格。
- 在基于贫血模型的传统开发模式中,Service 层包含 Service 类和 BO 类两部分,BO 是贫血模型,只包含数据,不包含具体的业务逻辑。业务逻辑集中在 Service 类中。
- 重 Service 轻 BO
- 基于充血模型的DDD开发模式:数据和对应的业务逻辑被封装到同一个类中。这种充血模型是典型的面向对象编程风格。领域驱动设计主要是用来指导如何解耦业务系统,划分业务模块,定义业务领域模型及其交互。恰好就是用来指导划分服务的,微服务盛行,所以领域驱动设计开始盛行。实际上,基于充血模型的 DDD 开发模式实现的代码,也是按照 MVC 三层架构分层的。它跟基于贫血模型的传统开发模式的区别主要在 Service 层。
- 在基于充血 模型的 DDD 开发模式中,Service 层包含 Service 类和 Domain 类两部分。Domain 就相当于贫血模型中的 BO。不过,Domain 与 BO 的区别在于它是基于充血模型开发的,既包含数据,也包含业务逻辑。Service 更多是对 Domain 的组合。
- 轻 Service 重 Domain
- 抉择:
- 项目业务比较简单,没有必要精心设计充血模型。贫血就可以很好完成CRUD。重点在SQL上,往往Service的逻辑没那么重要
- 基于充血模型的 DDD 开发模式,更适合业务复杂的系统开发。比如,包含各种利息计算模型、还款模型等复杂业务的金融系统。前期需要在设计上投入更多时间和精力,来提高代码的复用性和可维护性。往往Domain的逻辑是重要和可复用的。
设计原则
SOLID原则
SRP 单一职责原则
一个类或者模块只负责完成一个职责(或者功能)。这里的类不是说Service这种,而是主要说在设计领域对象的时候。
不同的应用场景、不同阶段的需求背景下,对同一个类职责是否单一的判定,可能都是不一样的。可以先写一个粗粒度的类,满足业务需求。随着业务的发展,如果粗粒度的类越来越庞大,代码越来越多,这个时候,我们就可以将这个粗粒度的类,拆分成几个更细粒度的类。这就是所谓的持续重构。如果拆分得过细,实际上会适得其反,反倒会降低内聚性,也会影响代码的可维护性****。
判断类的职责是否足够单一:
- 类中的代码行数、函数或属性过多,会影响代码的可读性和可维护性
- 类依赖的其他类过多,或者依赖类的其他类过多,不符合高内聚、低耦合的设计思想
- 私有方法过多,我们就要考虑能否将私有方法独立到新的类中,设置为 public 方法,供更多的类使用,从而提高代码的复用性;
- 比较难给类起一个合适名字,很难用一个业务名词概括,或者只能用一些笼统的 Manager、Context 之类的词语来命名,这就说明类的职责定义得可能不够清晰;
- 类中大量的方法都是集中操作类中的某几个属性,比如,在 UserInfo 例子中,如果一半的方法都是在操作 address 信息,那就可以考虑将这几个属性和对应的方法拆分出来。
OCP 对扩展开放、修改关闭原则
添加一个新的功能,在已有代码基础上扩展代码(新增模块、类、方法等),而非修改已有代码(修改模块、类、方法 等)。
如何实现:
- 多态、依赖注入、基于接口而非实现编程。
- 23 种经典设计模式,大部分(比如,装饰、策略、模板、职责链、状态)都是为了解决代码的扩展性问题而总结出来的,都是以开闭原则为指导原则的。
LSP 里氏替换原则和多态的区别
子类对象能够替换程序中父类对象出现的任何地方,并且保证原来程序的逻辑行为不变及正确性不被破坏。
如何实现:子类在重写父类的方法的时候,不能改变父类原本的逻辑、功能、输入输出以及异常
ISP接口隔离原则
客户端不应该强迫依赖它不需要的接口。其中的“客户端”,可以理解为接口的调用者或者使用者。
如何实现:
- 如果部分接口只被部分调用者使用,那我们就需要将这部分接口隔离出来,单独给对应的调用者使用,而不是强迫其他调用者也依赖这部分不会被用到的接口。
- 函数的设计要功能单一,不要将多个不同的功能逻辑在一个函数中实现。
- 接口最好为了一个具体的功能定义,而不是通用的,否则会导致实现类需要实现一些自己不使用的类
接口隔离原则提供了一种判断接口的职责是否单一的标准。如果调用者只使用部分接口或接口的部分功能,那接口的设计就不够职责单一。
DIP依赖反转/倒置
其实就是面向接口编程。
- IOC控制反转,“控制”指的是对程序执行流程的控制,而“反转”指的是在没有使用框架之前,程序员自己控制整个程序的执行。在使用框架之后,整个程序的执行流程可以通过框架来控制。流程的控制权从程序员“反转”到了框架。控制反转,是一种框架设计思想,可以用模板方法实现(测试框架),也可以使用依赖注入来实现,是编码技巧。
- DI 依赖注入:不通过 new() 的方式在类内部创建依赖类对象,而是将依赖的类对象在外部创建好之后,通过构造函数、函数参数等方式传递 (或注入)给类使用。
- DIP 依赖反转原则:依赖倒置原则。这条原则跟控制反转有点类似,主要用来指导框架层面的设计。高层模块不依赖低层模块,它们共同依赖同一个抽象。抽象不要依赖具体实现细节,具体实现细节依赖抽象。Tomcat 是运行 Java Web 应用程序的容器。我们编写的 Web 应用程序代码只需要部署在 Tomcat 容器下,便可以被 Tomcat 容器调用执行。按照之前的划分原则,Tomcat 就是高 层模块,我们编写的 Web 应用程序代码就是低层模块。Tomcat 和应用程序代码之间并没 有直接的依赖关系,两者都依赖同一个“抽象”,也就是 Sevlet 规范。Servlet 规范不依 赖具体的 Tomcat 容器和应用程序的实现细节,而 Tomcat 容器和应用程序依赖 Servlet 规范。
LOD 迪米特法则
“高内聚”用来指导类本身的设计,相近的功能应该放到同一个类中,不相近的功能不要放到同一类中。“松耦合”用来指导类与类之间依赖关系的设计。
最小知识原则,英文翻译为:The Least Knowledge Principle。不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口(也就是定义中的“有限知识”)。让类越独立越好。每个类都应该少了解系统的其他部分。一旦发生变化,需要了解这一变化的类就会比较少。
KISS、YAGNI 原则
- Keep It Simple and Stupid 尽量保持简单。保持代码可读和可维护的重要手段。
- 不要使用同事可能不懂的技术来实现代码。比如前面例子中的正则表达式,还有一些编 程语言中过于高级的语法等。
- 不要重复造轮子,要善于使用已经有的工具类库。
- 不要过度优化。不要过度使用一些奇技淫巧(比如,位运算代替算术运算、复杂的条件 语句代替 if-else、使用一些过于底层的函数等)
- YAGNI 原则的英文全称是:You Ain’t Gonna Need It。直译就是:你不会需要它。不要做过度设计。
DRY原则
Don’t Repeat Yourself。实现逻辑重复、功能语义重复和代码执行重复。
易混点:
- 实现逻辑重复,但功能语义不重复的代码,并不违反 DRY 原则。
- 实现逻辑不重复,但功能语义重复的代码,也算是违反 DRY 原则。
- 代码执行重复也算是违反 DRY 原则。
如何实现:满足单一职责原则、模块化、业务与非业务逻辑分离、通用代码下沉、继承、多态、抽象、封装、应用模板等设计模式。
编码规范与重构
重构目的(why)
- 在保持功能不变的前提下,利用设计思想、原则、模式、编程规范等理论来优化代码,修改设计上的不足,提高代码质量。
- 重构是避免过度设计的有效手段。在我们维护代码的过程中,真正遇到问题的时候, 再对代码进行重构,能有效避免前期投入太多时间做过度的设计。
重构对象(what)
大型重构:包括:系统、模块、代码结构、类与类之间的关系等的重构,重构的手段有:分层、模块化、解耦、抽象可复用组件等等。用到设计模式
小型重构:对代码细节的重构,主要是针对类、函数、变量等代码级别的重构,比如规范命名、规范注释、消除超大类或函数、提取重复代码等等。用到编码规范
重构时机(when)
寄希望于在代码烂到一定程度之后,集中重构解决所有问题是不现实的,我们必须探索一条可持续、可演进的方式。
提倡的重构策略是持续重构。代码总会存在不完美,重构就会持续在进行。时刻具有持续重构意识,才能避免开发初期就过度设计,避免代码维护的过程中质量的下降。而那些看到别人代码有点瑕疵就一顿乱骂,或者花尽心思去构思一个完美设计的人,往往都是因为没有树立正确的代码质量观,没有持续重构意识。
重构方法(how)
大规模高层次的重构一定是有组织、有计划,并且非常谨慎的,需要有经验、熟悉业务的资深同事来主导。
小规模低层次的重构,因为影响范围小,改动耗时短,所以,只要你愿意并且有时间,随时都可以去做。
代码解耦方法
- 封装、抽象:隐藏实现的复杂性,隔离实现的 易变性,给依赖的模块提供稳定且易用的抽象接口。
- 模块化:分而治之
- 中间层:中间层能简化模块或类之间的依赖关系。引入一个中间层,包裹老的接口,提供新的接口定义。新开发的代码依赖中间层提供的新接口。将依赖老接口的代码改为调用新接口。确保所有的代码都调用新接口之后,删除掉老的接口。
- 设计思想与原则,比如:单一职责原则、基于接口而非实现编程、依赖注入、多用组合少用继承、迪米特法则等。当然,还有一些设计模式,比如观察者。
编码规范
命名与注释(Naming and Comments)
- 对于一些默认的、大家都比较熟知的词,推荐用缩写。比如,sec 表示 second、str 表示 string、num 表示 number、 doc 表示 document。
- 利用上下文简化命名,User 的名字叫 name 而不是 userName
- 命名要可读、可搜索
- 代码注释:做什么、为什么、怎么做、怎么用
代码风格(Code Style)
- 函数完整地显示在 IDE 中,那最大代码行数不能超过 50。
- 在类的成员变量与函数之间、静态成员变量与普通成员变量之间、各函数之间、 甚至各成员变量之间,添加空行
编程技巧(Coding Tips)
- 把代码分割成更小的单元块,这样理解代码的时候先看整体再看细节。
- 避免函数参数过多,是否职责单一,封装为对象
- 函数参数来控制逻辑的时候,具体逻辑最好作为单独的函数
- 移除不必要的else,调整执行顺序,减少嵌套
- 常量替代魔法数字
设计模式
借助设计模式,我们利用更好的代码结构,将一大坨代码拆分成职责更单一的小类,让其满足开闭原则、高内聚松耦合等特性,以此来控制和应对代码的复杂性,提高代码的可扩展性。
设计模式之间的主要区别还是在于设计意图,也就是应用场景。单纯地看设计思路或者代码实现,有些模式确实很相似,比如策略模式和工厂模式。
创建型
主要解决对象的创建问题,封装复杂的创建过程,解耦对象的创建代码和使用代码。
- 单例模式用来创建全局唯一的对象。
- 工厂模式用来创建不同但是相关类型的对象(继 承同一父类或者接口的一组子类),由给定的参数来决定创建哪种类型的对象。
- 建造者模式是用来创建复杂对象,可以通过设置不同的可选参数,“定制化”地创建不同的对象。
- 原型模式针对创建成本比较大的对象,利用对已有对象进行复制的方式进行创建,以达到节省创建时间的目的。
单例模式
为什么要使用单例?
- 解决资源访问冲突导致的覆写问题。不能解决多线程并发问题,但是保证了不同线程里的对象锁可以生效,因为所有调用者用的是同一个对象,这样简单的 synchronized 就可以实现串行,就不用使用类锁了。
- 全局唯一的配置类,唯一ID生成器
单例的实现方式
- 饿汉式:类加载的时候初始化好,JVM保证唯一和线程安全,不支持延迟加载
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static final IdGenerator instance = new IdGenerator();
private IdGenerator() {}
public static IdGenerator getInstance() { return instance; }
public long getId() {
return id.incrementAndGet();
}
}
- 懒汉式
// 并发度低
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private static IdGenerator instance = new IdGenerator();
private IdGenerator() {}
public static synchronized IdGenerator getInstance() {
if (instance == null) {
instance = new IdGenerator();
}
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
// 并发读高
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
// 禁止new 的时候指令重排序
private volatile static IdGenerator instance = new IdGenerator();
private IdGenerator() {}
public static IdGenerator getInstance() {
if (instance == null) {
synchronized(IdGenerator.class) {
if (instance == null) {
instance = new IdGenerator();
}
}
}
return instance;
}
public long getId() {
return id.incrementAndGet();
}
}
- 静态内部类(类似饿汉的延迟加载),JVM 保证延迟,保证唯一和线程安全
public class IdGenerator {
private AtomicLong id = new AtomicLong(0);
private IdGenerator() {}
private static class SingletonHolder {
private static final IdGenerator instance = new IdGenerator();
}
public static IdGenerator getInstance() {
return SingletonHolder.instance;
}
public long getId() {
return id.incrementAndGet();
}
}
- 枚举,枚举特性保证唯一和线程安全
public enum IdGenerator {
INSTANCE;
private AtomicLong id = new AtomicLong(0);
public long getId() {
return id.incrementAndGet();
}
}
单例存在哪些问题?
- 违背了面向接口而非实现编程,一个ID生成器要对不同场景分别生成的时候改动就很大。
- 隐藏类之间的依赖关系,一般都使用无参构造器,想要有参数需要自己封装
public class Config {
public static final int PARAM_A = 123;
public static fianl int PARAM_B = 245;
}
public class Singleton {
private static Singleton instance = null;
private final int paramA;
private final int paramB;
private Singleton() {
this.paramA = Config.PARAM_A;
this.paramB = Config.PARAM_B;
}
public synchronized static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
有何替代的解决方案?
- 静态方法
- 工厂模式、IOC 容器(比如 Spring IOC 容器)
如何理解单例模式中的唯一性?
单例模式创建的对象是进程唯一的
如何实现线程唯一的单例?
- 通过一个 ConcurrentHashMap 来存储对象,其中 Long key 是线程 ID,value 是对象。
- Java 提供了 ThreadLocal 工具类,可以更加轻松地实现线程唯一单例。
如何实现集群环境下的单例?
需要把这个单例对象序列化并存储到外部共享存储区(比如文件)。使用这个单例对象的时候,需要先从外部共享存储区中将它读取到内存,并反序列化成对象,然后再使用,使用完成之后还需要再存储回外部共享存储区。一个进程在获取到对象之后,需要对对象加锁,避免其他进程再将其获取。在进程使用完这个对象之后,还需要显式地将对象从内存中删除,并且释放对对象的加锁。
如何实现一个多例模式?
一个类只可以创建有限个。
public class Logger {
private static final ConcurrentHashMap<String, Logger> instances
= new ConcurrentHashMap<>();
private Logger() {}
public static Logger getInstance(String loggerName) {
instances.putIfAbsent(loggerName, new Logger());
return instances.get(loggerName);
}
public void log() {
//...
}
}
//l1==l2, l1!=l3
Logger l1 = Logger.getInstance("User.class");
Logger l2 = Logger.getInstance("User.class");
Logger l3 = Logger.getInstance("Order.class");
工厂模式
简单工厂:工厂方法的特例
- 实现方式:如果唯一的话一般和单例模式结合(HashMap)使用
- 使用场景:根据输入进行不同类型的简单对象的创建,但是有多个类型的时候。可以使用HashMap消除一些 if 的逻辑。
/**
* 简单工厂的第一种实现方法
*/
public class RuleConfigParserFactoryA {
public static IRuleConfigParser createParser(String configFormat) {
IRuleConfigParser parser = null;
if ("json".equalsIgnoreCase(configFormat)) {
parser = new JsonRuleConfigParser();
} else if ("xml".equalsIgnoreCase(configFormat)) {
parser = new XmlRuleConfigParser();
} else if ("yaml".equalsIgnoreCase(configFormat)) {
parser = new YamlRuleConfigParser();
} else if ("properties".equalsIgnoreCase(configFormat)) {
parser = new PropertiesRuleConfigParser();
}
return parser;
}
}
/**
* 简单工厂的第二种实现方法. A版本每次都要创建一个新的对象,实际上,如果 parser 可以复用,为了节省内存和对象创建的时间,
* 我们可以将 parser 事先创建好缓存起来。当调用 createParser() 函数的时候,我们从缓存中取出 parser 对象直接使用。
*/
public class RuleConfigParserFactoryB {
private static final Map<String, IRuleConfigParser> cachedParsers = new HashMap<>();
static {
cachedParsers.put("json", new JsonRuleConfigParser());
cachedParsers.put("xml", new XmlRuleConfigParser());
cachedParsers.put("yaml", new YamlRuleConfigParser());
cachedParsers.put("properties", new PropertiesRuleConfigParser());
}
public static IRuleConfigParser createParser(String configFormat) {
if (configFormat == null || configFormat.isEmpty()) {
return null;
}
return cachedParsers.get(configFormat.toLowerCase());
}
}
工厂方法:更加符合开闭原则
比起简单工厂消除了 if ,更加符合开闭原则。
- 实现方式:每一个类都对应单独的工厂,最后有一个工厂的工厂来决定使用哪一个工厂。可以使用HashMap消除一些 if 的逻辑。
- 使用场景:根据输入进行不同类型的复杂对象的创建,这些逻辑拆分到多个工厂类中,让每个工厂类都不至于过于复杂。复杂对象不只是简单的 new 一下就可以,而是要组合其他类对象,做各种初始化操作的时候。
/**
* 为工厂类再创建一个简单工厂,也就是工厂的工厂,用来创建工厂类对象。
* 因为工厂类只包含方法,不包含成员变量,完全可以复用,
* 不需要每次都创建新的工厂类对象,所以,简单工厂模式实现思路更加合适。
*/
public class RuleConfigParserFactoryMap {
private static final Map<String, IRuleConfigParserFactory> cachedFactories = new HashMap<>();
static {
cachedFactories.put("json", new JsonRuleConfigParserFactory());
cachedFactories.put("xml", new XmlRuleConfigParserFactory());
cachedFactories.put("yaml", new YamlRuleConfigParserFactory());
cachedFactories.put("properties", new PropertiesRuleConfigParserFactory());
}
public static IRuleConfigParserFactory getParserFactory(String type) {
if (StringUtils.isEmpty(type)) {
return null;
}
return cachedFactories.get(type.toLowerCase());
}
}
public interface IRuleConfigParserFactory {
IRuleConfigParser createParser(String configFormat);
}
public class JsonRuleConfigParserFactory implements IRuleConfigParserFactory {
@Override
public IRuleConfigParser createParser(String configFormat) {
return new JsonRuleConfigParser();
}
}
抽象工厂:实际项目中不常用
- 实现方式:可以让一个工厂负责创建多个不同类型的对象,而不是只创建一种 parser 对象。这样就可以有效地减少工厂类的个数。
- 使用场景:根据输入的多个维度的分类进行不同类型的对象的创建,否则使用上面的工厂方法会导致工厂类组合炸裂。
工厂的编码规范
大部分工厂类都是以“Factory”这个单词结尾的,但也不是必须的,比如 Java 中的 DateFormat、Calender。
创建对象的方法一般都是 create 开头,但有的也命名为 getInstance()、createInstance()、 newInstance(),有的甚至命名为 valueOf()。
工厂模式和 DI 容器有何区别?
DI 容器底层最基本的设计思路就是基于工厂模式的。
DI 容器的核心功能有哪些?或者说实现一个DI的思路?
配置解析、对象创建和对象生命周期管理。
- Spring 容器读取配置文件,解析出要创建的两个对象:rateLimiter 和 redisCounter,并且得到两者的依赖关系:rateLimiter 依赖 redisCounter。
- 在 DI 容器中,给每个类都对应创建一个工厂类,不如将所有类对象的创建都放到 一个工厂类中完成就可以了,比如 BeansFactory。借助反射,使得创建对象的代码变为可复用的,而不需要为每一个类单独写创建逻辑。
- scope=prototype 可以每次返回新对象,lazy-init=true 是对象被使用的时候才会创建。init-method 和 destroy-method 方法可以设置初始化属性方法以及摧毁之前的清理工作。
建造者模式/Builder 模式
建造者模式的必要性
使用set的话,对于必填的字段是无法保证的,还是要写在构造函数里。
对于 private 字段,不能使用 set,只能在构造函数中传入。
构造函数的参数列表长的时候,在可读性和易用性上都会变差。
实现方式
创建建造者,并且通过 set() 方法设置建造者的变量值,然后在使用 build() 方法真正创建对象之前,做集中的校验,校验通过之后才会创建对象。
构造函数改为 private 私有权限。 这样就只能通过建造者来创建类对象。
/**
* 建造者模式
* 优点:避免构造函数的参数列表过长,影响代码的可读性和易用性;参数的必填项能够很好支持;能对参数与参数之间的依赖、约束做成判断;能创建不可变对象,创建后不能再更改对象的内部属性。
* 缺点:代码重复,属性在类和Builder类中都要定义一遍。
*/
public class ResourcePoolConfigC {
private String name;
private int maxTotal;
private int maxIdle;
private int minIdle;
//注意,这里的赋值是用builder的值
private ResourcePoolConfigC(Builder builder) {
this.name = builder.name;
this.maxTotal = builder.maxTotal;
this.maxIdle = builder.maxIdle;
this.minIdle = builder.minIdle;
}
//...省略getter方法...
//我们将Builder类设计成了ResourcePoolConfig的内部类。
//我们也可以将Builder类设计成独立的非内部类ResourcePoolConfigBuilder。
public static class Builder {
private static final int DEFAULT_MAX_TOTAL = 8;
private static final int DEFAULT_MAX_IDLE = 8;
private static final int DEFAULT_MIN_IDLE = 0;
private String name;
private int maxTotal = DEFAULT_MAX_TOTAL;
private int maxIdle = DEFAULT_MAX_IDLE;
private int minIdle = DEFAULT_MIN_IDLE;
public ResourcePoolConfigC build() {
// 校验逻辑放到这里来做,包括必填项校验、依赖关系校验、约束条件校验等
if (StringUtils.isBlank(name)) {
throw new IllegalArgumentException("...");
}
if (maxIdle > maxTotal) {
throw new IllegalArgumentException("...");
}
if (minIdle > maxTotal || minIdle > maxIdle) {
throw new IllegalArgumentException("...");
}
return new ResourcePoolConfigC(this);
}
public Builder setName(String name) {
if (StringUtils.isBlank(name)) {
throw new IllegalArgumentException("...");
}
this.name = name;
return this;
}
public Builder setMaxTotal(int maxTotal) {
if (maxTotal <= 0) {
throw new IllegalArgumentException("...");
}
this.maxTotal = maxTotal;
return this;
}
public Builder setMaxIdle(int maxIdle) {
if (maxIdle < 0) {
throw new IllegalArgumentException("...");
}
this.maxIdle = maxIdle;
return this;
}
public Builder setMinIdle(int minIdle) {
if (minIdle < 0) {
throw new IllegalArgumentException("...");
}
this.minIdle = minIdle;
return this;
}
}
public static void main(String args[]) {
// 这段代码会抛出IllegalArgumentException,因为minIdle>maxIdle
ResourcePoolConfigC config = new ResourcePoolConfigC.Builder()
.setName("dbconnectionpool")
.setMaxTotal(16)
.setMaxIdle(10)
.setMinIdle(12)
.build();
}
}
原型模式
使用场景
如果对象的创建成本比较大,比如需要经过复杂的计算才能得到(比如排序、计算哈希值),或者需要从 RPC、网络、数据库、文件系统等非常慢速的 IO 中读取而同一个类的不同对象之间差别不大(大部分字段都相同), 在这种情况下,我们可以利用对已有对象(原型)进行复制(或者叫拷贝)的方式来创建新对象,以达到节省创建时间的目的。
实现方法
浅拷贝: Java 的 Object 类的 clone() 方法只会拷贝对象中的基本数据类型的数据(比如,int、long),以及引用对象的内存地址,不会递归地拷贝引用对象本身。
/**
* 浅拷贝
* 使用浅拷贝来代替重新从数据库中查询数据出来,这样过程就不会太过耗时。
* 缺点:拷贝出来的HashMap的value和原HashMap的value指向都是同一个对象,这样一个value做出更改,另一个也会跟着变动,所以我们需要深拷贝来拷贝完全独立的HashMap。
*/
public class DemoC {
private HashMap<String, SearchWord> currentKeywords = new HashMap<>();
private long lastUpdateTime = -1;
public void refresh() {
// 原型模式就这么简单,拷贝已有对象的数据,更新少量差值
HashMap<String, SearchWord> newKeywords = (HashMap<String, SearchWord>) currentKeywords.clone();
// 从数据库中取出更新时间>lastUpdateTime的数据,放入到newKeywords中
List<SearchWord> toBeUpdatedSearchWords = getSearchWords(lastUpdateTime);
long maxNewUpdatedTime = lastUpdateTime;
for (SearchWord searchWord : toBeUpdatedSearchWords) {
if (searchWord.getLastUpdateTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = searchWord.getLastUpdateTime();
}
if (newKeywords.containsKey(searchWord.getKeyword())) {
SearchWord oldSearchWord = newKeywords.get(searchWord.getKeyword());
oldSearchWord.setCount(searchWord.getCount());
oldSearchWord.setLastUpdateTime(searchWord.getLastUpdateTime());
} else {
newKeywords.put(searchWord.getKeyword(), searchWord);
}
}
lastUpdateTime = maxNewUpdatedTime;
currentKeywords = newKeywords;
}
private List<SearchWord> getSearchWords(long lastUpdateTime) {
// TODO: 从数据库中取出更新时间>lastUpdateTime的数据
return null;
}
深拷贝:可以使用序列化来实现,也可以使用递归拷贝来实现
/**
* 可以先采用浅拷贝的方式创建 newKeywords。对于需要更新的 SearchWord 对象,我们再使用深度拷贝的方式创建一份新的对象,替换 newKeywords 中的老对象。
* 毕竟需要更新的数据是很少的。这种方式即利用了浅拷贝节省时间、空间的优点,又能保证 currentKeywords 中的中数据都是老版本的数据。
*/
public class DemoF {
private HashMap<String, SearchWord> currentKeywords = new HashMap<>();
private long lastUpdateTime = -1;
public void refresh() {
// Shallow copy
HashMap<String, SearchWord> newKeywords = (HashMap<String, SearchWord>) currentKeywords.clone();
// 从数据库中取出更新时间>lastUpdateTime的数据,放入到newKeywords中
List<SearchWord> toBeUpdatedSearchWords = getSearchWords(lastUpdateTime);
long maxNewUpdatedTime = lastUpdateTime;
for (SearchWord searchWord : toBeUpdatedSearchWords) {
if (searchWord.getLastUpdateTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = searchWord.getLastUpdateTime();
}
if (newKeywords.containsKey(searchWord.getKeyword())) {
newKeywords.remove(searchWord.getKeyword());
}
newKeywords.put(searchWord.getKeyword(), searchWord);
}
lastUpdateTime = maxNewUpdatedTime;
currentKeywords = newKeywords;
}
private List<SearchWord> getSearchWords(long lastUpdateTime) {
// TODO: 从数据库中取出更新时间>lastUpdateTime的数据
return null;
}
}
结构型
结构型模式主要总结了一些类或对象组合在一起的经典结构,这些经典的结构可以解决特定应用场景的问题。
代理模式
静态代理
- 方法一:实现类和代理类实现相同的业务接口,在代理类中引用实现类,之后实现相同的方法,使用的时候多态面向接口编程即可。代理类构造器入参传递实现类的对象。
- 方法二:继承实现类,重写对应的业务方法内部调用父类的方法。使用的时候多态面向接口编程即可。
动态代理
静态代理的问题:
- 需要在代理类中,将原始类中的所有的方法,都重新实现一遍,并且为每个方法都附加相似的代码逻辑。
- 如果要添加的附加功能的类有不止一个,我们需要针对每个类都创建一个代理类。
JAVA 的动态代理底层依赖的依旧是反射
/**
* 所谓动态代理(Dynamic Proxy),就是我们不事先为每个原始类编写代理类,而是在运行的时候,动态地创建原始类对应的代理类,然后在系统中用代理类替换掉原始类。
* 可以看到这里没有跟业务相关的类
*/
public class MetricsCollectorProxy {
public static void main(String[] args) {
MetricsCollectorProxy proxy = new MetricsCollectorProxy();
// UserController userController = (UserController) proxy.createProxy(new UserController());
//jdk动态代理的原始类必须要实现一个接口
IUserController userController = (IUserController) proxy.createProxy(new UserController());
userController.login("13607841111", "123456");
}
private MetricsCollector metricsCollector;
public MetricsCollectorProxy() {
this.metricsCollector = new MetricsCollector();
}
public Object createProxy(Object proxiedObject) {
Class<?>[] interfaces = proxiedObject.getClass().getInterfaces();
DynamicProxyHandler handler = new DynamicProxyHandler(proxiedObject);
return Proxy.newProxyInstance(proxiedObject.getClass().getClassLoader(), interfaces, handler);
}
private class DynamicProxyHandler implements InvocationHandler {
private Object proxiedObject;
public DynamicProxyHandler(Object proxiedObject) {
this.proxiedObject = proxiedObject;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
long startTimestamp = System.currentTimeMillis();
Object result = method.invoke(proxiedObject, args);
long endTimeStamp = System.currentTimeMillis();
long responseTime = endTimeStamp - startTimestamp;
String apiName = proxiedObject.getClass().getName() + ":" + method.getName();
RequestInfo requestInfo = new RequestInfo(apiName, responseTime, startTimestamp);
metricsCollector.recordRequest(requestInfo);
return result;
}
}
}
使用场景
- 非功能性需求,比如:监控、统计、鉴权、限流、事务、幂等、日志这些附加功能与业务功能解耦,放到代理类中统一处理,让程序员只需要关注业务方面的开发。
- 上面的代理同步记录响应时间,对原本的业务有影响,所以这里可以使用guava的异步方式来记录存储相关信息。
import com.google.common.eventbus.AsyncEventBus;
import com.google.common.eventbus.EventBus;
import com.google.common.eventbus.Subscribe;
import org.apache.commons.lang3.StringUtils;
import java.util.concurrent.Executors;
/**
* 数据采集接口
* 对于性能这一点,落实到具体的代码层面,需要解决两个问题,也是我们之前提到过的,一个是采集和存储要异步来执行,因为存储基于外部存储(比如 Redis),会比较慢,异步存储可以降低对
* 接口响应时间的影响。引入 Google Guava EventBus 来解决。实际上,我们可以把 EventBus 看作一个“生产者 - 消费者”模型或者“发布 - 订阅”模型,采集的数据先放入内存共享队列中,
* 另一个线程读取共享队列中的数据,写入到外部存储(比如 Redis)中。
*/
public class MetricsCollector {
private static final int DEFAULT_STORAGE_THREAD_POOL_SIZE = 20;
//基于接口而非实现编程
private IMetricsStorage metricsStorage;
private EventBus eventBus;
// 兼顾代码的易用性,新增一个封装了默认依赖的构造函
public MetricsCollector() {
this(new RedisMetricsStorage(), DEFAULT_STORAGE_THREAD_POOL_SIZE);
}
// 兼顾灵活性和代码的可测试性,这个构造函数继续保留
public MetricsCollector(IMetricsStorage metricsStorage, int threadNumToSaveData) {
this.metricsStorage = metricsStorage;
this.eventBus = new AsyncEventBus(Executors.newFixedThreadPool(threadNumToSaveData));
this.eventBus.register(new EventListener());
}
public void recordRequest(RequestInfo requestInfo) {
if (requestInfo == null || StringUtils.isBlank(requestInfo.getApiName())) {
return;
}
eventBus.post(requestInfo);
}
public class EventListener {
@Subscribe
public void saveRequestInfo(RequestInfo requestInfo) {
metricsStorage.saveRequestInfo(requestInfo);
}
}
}
桥接模式
一个类存在两个(或多个)独立变化的维度,我们通过组合的方式, 让这两个(或多个)维度可以独立进行扩展。将抽象和实现解耦,让它们可以独立变化。
例子:一个消息,从重要程度来看有 正常、重要、紧急;从发送渠道来看有微信、短信、电话。现在要实现的最灵活的,要实现某一类型的消息可以通过特定的渠道发送,并且有的渠道可能会发多种类型。
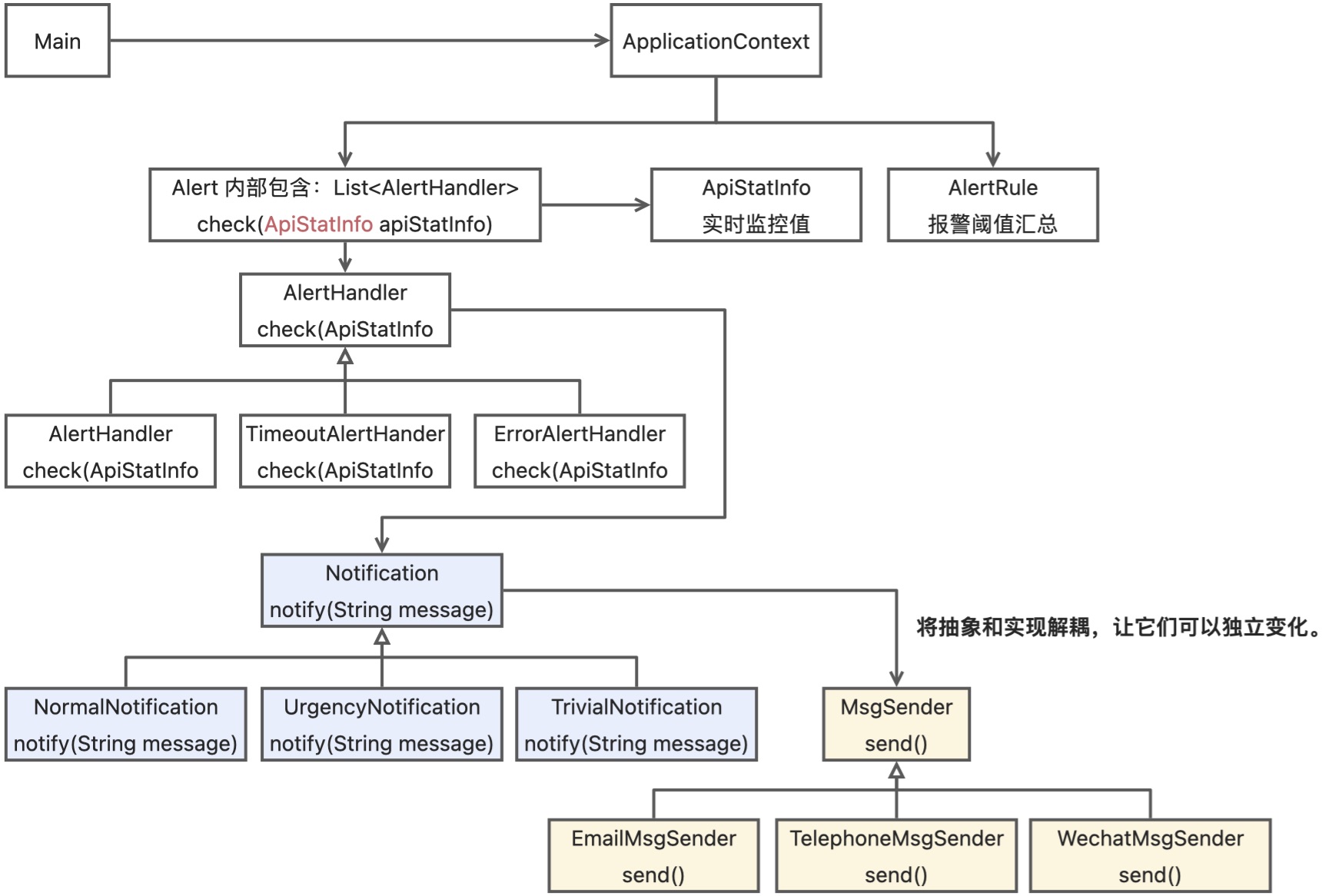
“组合优于继承”设计原则,通过组合关系来替代继承关系,避免继承层次的指数级爆炸。
装饰器模式
装饰器对比继承的好处
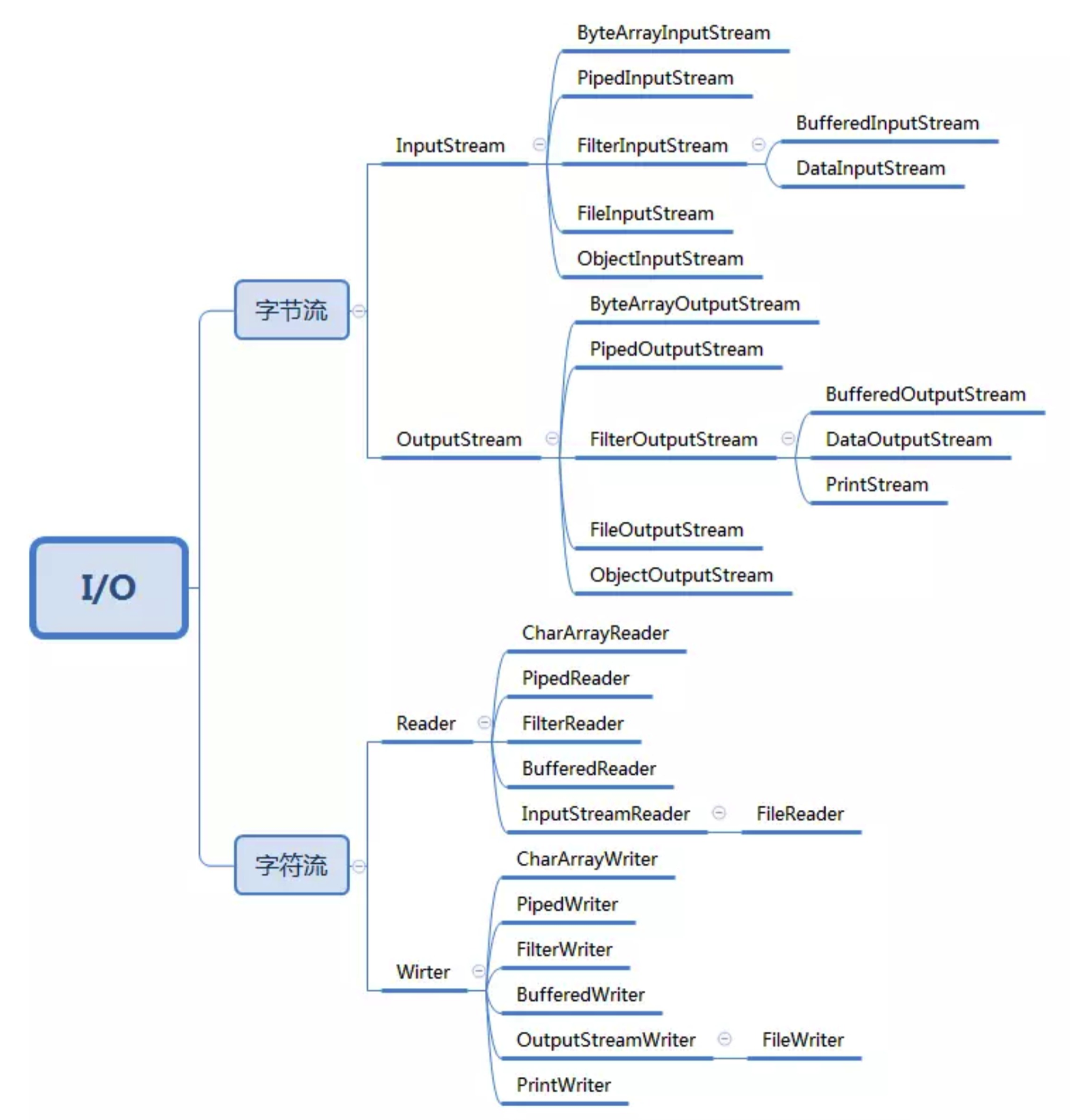
上面的 InputStream 有很多子类,如果BufferedXxxInputStream是基于继承实现的,那么所有的子类都需要有一个对应的子类,除了支持缓存读取之外,如果我们还需要对功能进行其他方面的增强,比如 DataInputStream 类,支持按照基本数据类型(int、boolean、long 等)来读取数据。继续按照继承的方式来实现的话,就需要再继续派生出 DataFileInputStream、DataPipedInputStream 等类。既支持缓存、又支持按照基本类型读取数据的类,那就要再继续派生出 BufferedDataFileInputStream、 BufferedDataPipedInputStream 等 n 多类。类继承结构变得无比复杂,代码既不好扩展,也不好维护。
装饰器和组合的区别
装饰器类和原始类实现同样的父类,这样我们可以对原始类“嵌套”多个装饰器类。
装饰器和代理模式的区别
代理模式中,代理类附加的是跟原始类无关的功能,而在装饰器模式中,装饰器类附加的是跟原始类相关的增强功能。
需要注意,调用被包装类的对应方法。是通过委托的方式,而不是直接调用父类的方法,一般装饰器都会持有原始对象的引用。
增加所有装饰器父类的必要性
直接实现抽象类的方式导致即使没有需要增加的逻辑也要简单调用一下被装饰类的方法。我们可以加个中间层,也就是所有装饰器的父类,这样具体的装饰器类只需要实现它需要增强的方法就可以了,其他方法继承装饰器父类的默认实现。下面的FilterXxx就是一个中间层的角色。

适配器模式
让原本由于接口不兼容而不能一起工作的类可以一起工作。就是 USB 转接头充当适配器,把两种不兼容的接口,通过转接变得可以一起工作。
实现方式
类适配器和对象适配器,类适配器使用继承关系来实现,对象适配器使用组合关系来实现。
类适配器:基于继承
ITarget 表示要转化成的接口定义。Adaptee 是一组不兼容 ITarget 接口定义的接口,Adaptor 将 Adaptee 转化成一组符合 ITarget 接口定义的接口。
/**
* ITarget 表示要转化成的接口定义
*/
public interface ITarget {
void f1();
void f2();
void fc();
}
/**
* Adaptee 是一组不兼容 ITarget 接口定义的接口
*/
public class Adaptee {
public void fa() {}
public void fb() {}
public void fc() {}
}
/**
* Adaptor 将 Adaptee 转化成一组符合 ITarget 接口定义的接口。
* // 类适配器: 基于继承
*/
public class Adaptor extends Adaptee implements ITarget {
@Override
public void f1() {
super.fa();
}
@Override
public void f2() {
super.fb();
}
// 这里fc()不需要实现,直接继承自Adaptee,这是跟对象适配器最大的不同点
}
对象适配器:基于组合
/**
* ITarget 表示要转化成的接口定义
*/
public interface ITarget {
void f1();
void f2();
void fc();
}
/**
* Adaptee 是一组不兼容 ITarget 接口定义的接口
*/
public class Adaptee {
public void fa() {
//...
}
public void fb() {
//...
}
public void fc() {
//...
}
}
public class Adaptor implements ITarget {
private Adaptee adaptee;
@Override
public void f1() {
adaptee.fa();
}
@Override
public void f2() {
adaptee.fb();
}
@Override
public void fc() {
adaptee.fc();
}
}
实现方式选择标准
- 如果 Adaptee 接口并不多,那两种实现方式都可以。
- 如果 Adaptee 接口很多,而且** Adaptee 和 ITarget 接口定义大部分都相同,那我们推荐使用类适配器,也就是直接继承**,因为 Adaptor 复用父类 Adaptee 的接口,比起对象适配器的实现方式,Adaptor 的代码量要少一些。
- 如果 Adaptee 接口很多,而且 Adaptee 和 ITarget 接口定义大部分都不相同,那我们推荐使用对象适配器,也就是组合,因为组合结构相对于继承更加灵活。
应用场景
一般是用来补救设计上的缺陷,是无奈之举,设计之初就可以规避这种不兼容问题,就没有使用这个模式的机会了。
封装有缺陷的接口设计,屏蔽不需要的接口,避免测试麻烦
依赖的外部系统在接口设计方面有缺陷(比如包含大量静态方法),引入之后会影响到我们自身代码的可测试性。为了隔离设计上的缺陷,我们希望对外部系统提供的接口进行二次封装,抽象出更好的接口设计,这个时候就可以使用适配器模式了。
统一多个类的接口设计
某个功能的实现依赖多个外部系统(或者说类)。通过适配器将它们的接口适配为统一的接口定义,使用多态的来复用代码逻辑。
假设我们的系统要对用户输入的文本内容做敏感词过滤,为了提高过滤的召回率,我们引入了多款第三方敏感词过滤系统,依次对用户输入的内容进行过滤,过滤掉尽可能多的敏感词。但是,每个系统提供的过滤接口都是不同的。这就意味着我们没法复用一套逻辑来调用各个系统。这个时候,我们就可以使用适配器模式,将所有系统的接口适配为统一的接口定义,这样我们可以复用调用敏感词过滤的代码。
// 未使用适配器模式之前的代码:代码的可测试性、扩展性不好
public class RiskManagement {
private ASensitiveWordsFilter aFilter = new ASensitiveWordsFilter();
private BSensitiveWordsFilter bFilter = new BSensitiveWordsFilter();
private CSensitiveWordsFilter cFilter = new CSensitiveWordsFilter();
public String filterSensitiveWords(String text) {
String maskedText = aFilter.filterSexyWords(text);
// 使用每一个过滤器对文本进行操作
maskedText = aFilter.filterPoliticalWords(maskedText);
maskedText = bFilter.filter(maskedText);
maskedText = cFilter.filter(maskedText, "***");
return maskedText;
}
}
// 使用适配器模式进行改造
public interface ISensitiveWordsFilter { // 统一接口定义
String filter(String text);
}
public class ASensitiveWordsFilterAdaptor implements ISensitiveWordsFilter {
private ASensitiveWordsFilter filter;
@Override
public String filter(String text) {
String maskedText = filter.filterSexyWords(text);
maskedText = filter.filterPoliticalWords(maskedText);
return maskedText;
}
}
// 扩展性更好,更加符合开闭原则,如果添加一个新的敏感词过滤系统,
// 这个类完全不需要改动;而且基于接口而非实现编程,代码的可测试性更好。
public class RiskManagement {
private List<ISensitiveWordsFilter> filters = new ArrayList<>();
public void addSensitiveWordsFilter(ISensitiveWordsFilter filter) {
filters.add(filter);
}
public String filterSensitiveWords(String text) {
String maskedText = text;
for (ISensitiveWordsFilter filter : filters) {
maskedText = filter.filter(maskedText);
}
return maskedText;
}
}
替换依赖的外部系统
当我们把项目中依赖的一个外部系统替换为另一个外部系统的时候,利用适配器模式,可以减少对代码的改动。为新的代码实现一个旧的外部系统接口的适配器类,这样只需要替换调用者的实现类即可。
兼容老版本的接口
JDK2 在保留 Enumeration 类的同时,将其实现替换为直接调用 Itertor,保证了旧代码的正常运行。
public class Collections {
public static Emueration emumeration(final Collection c) {
return new Emueration() {
Iterator i = c.iterator();
public boolean hasMoreElments() {
return i.hasNext();
}
public Object nextElement() {
return i.next();
}
};
}
}
适配不同格式的数据
Java 中的 Arrays.asList() 也可以看作一种数据适配器,将数组类型的数据转化为集合容器类型。
内部操作的数据其实是同一份。
日志门面框架中的适配器原理
不像 JDBC 那样,一开始就制定了数据库操作的接口规范。日志有不同的接口实现。
项目中的不同组件如果使用不同的日志框架,引入多个组件,每个组件使用的日志框架都不一样,那日志本身的管理工作就变得非常复杂。Slf4j 不仅仅提供了统一的接口定义,还提供了针对不同日志框架的适配器。对不同日志框架的接口进行二次封装,适配成统一的 Slf4j 接口定义。
Log4jLoggerAdapter实现了LocationAwareLogger接口,其中LocationAwareLogger继承自Logger接口。
如果一些老的项目没有使用 Slf4j,而是直接使用比如 JCL 来打印日 志,那如果想要替换成其他日志框架,比如 log4j,该怎么办呢?
Slf4j 不仅仅提供了从其他日志框架到 Slf4j 的适配器,还提供了反向适配器,也就是从 Slf4j 到其他日志框架的适配。我们可以先将 JCL 切换为 Slf4j,然后再将 Slf4j 切换为 log4j。经过两次适配 器的转换,我们能就成功将 JCL 切换为了 log4j。
代理、桥接、装饰器、适配器 4 种设计模式的区别
都可以称为 Wrapper 模式,也就是通过 Wrapper 类二次封装原始类。
- 代理模式:代理模式在不改变原始类接口的条件下,为原始类定义一个代理类,主要目的是控制访问,而非加强功能,这是它跟装饰器模式最大的不同。
- 桥接模式:桥接模式的目的是将接口部分和实现部分分离,从而让不同接口的实现相对独立地改变。
- 装饰器模式:装饰者模式在不改变原始类接口的情况下,对原始类功能进行增强,并且支持 多个装饰器的嵌套使用。
- 适配器模式:适配器模式是一种事后的补救策略。适配器提供跟原始类不同的接口,而代理模式、装饰器模式提供的都是跟原始类相同的接口。
门面模式
如果接口的粒度过小,会导致需要调用 n 多细粒度的接口才能完成。如果接口粒度设计得太大,就会导致接口不够通用、可复用性不好。门面模式为子系统提供一组统一的接口,定义一组高层接口让子系统更易用。假设有一个系统 A,提供了 a、b、c、d 四个接口。系统 B 完成某个业务功能,需要调用 A 系统的 a、b、d 接口。利用门面模式,我们提供一个包裹 a、b、d 接口调用的门面接口 x,给系统 B 直接使用。
使用场景
解决性能问题
例如:App 和服务器之间是通过移动网络通信的,网络通信耗时比较多,为了提高 App 的响应速度,我们要尽量减少 App 与服务器之间的网络通信次数。完成某个业务功能(比如显示某个页面信息)需要“依次”调用 a、b、d 三个接口,因自身业务的特点,不支持并发调用这三个接口。门面模式包装之后App 客户端调用一次接口 x,来获取到所有想要的数 据,将网络通信的次数从 3 次减少到 1 次,也就提高了 App 的响应速度。
解决易用性问题
Linux 的 Shell 命令和系统调用都是封装系统的底层实现,隐藏系统的复杂性,提供一组更加简单易用、更高层的接口。
门面模式有点类似之前讲到的迪米特法则(最少知识原则)和接口隔离原则:两个有交互的系统,只暴露有限的必要的接口。
解决分布式事务问题
借鉴门面模式的思想,再设计一个包裹这两个操作的新接口,让新接口在一个事务中执行两个 SQL 操作。
组合模式
与其说是一种设计模式,倒不如说是对业务场景的一种数据结构和算法的抽象。一组对象满足树形结构。以表示一种“部分 - 整 体”的层次结构。让代码的使用者可以统一单个对象和组合对象的处理逻辑。业务需求可以通过在树上的递归遍历算法来实现。
使用场景
文件系统
设计一个类来表示文件系统中的目录:动态地添加、删除某个目录下的子目录或文件;统计指定目录下的文件个数;统计指定目录下的文件总大小。
// 不好的实现
public class FileSystemNode {
private String path;
private boolean isFile;
private List<FileSystemNode> subNodes = new ArrayList<>();
public FileSystemNode(String path, boolean isFile) {
this.path = path;
this.isFile = isFile;
}
//统计指定目录下的文件个数;
public int countNumOfFiles() {
if (isFile) {
return 1;
}
int num = 0;
for (FileSystemNode fileSystemNode : subNodes) {
num += countNumOfFiles();
}
return num;
}
//统计指定目录下的文件总大小。
public long countSizeOfFiles() {
if (isFile) {
//计算文件大小
File file = new File(path);
if (!file.exists()) return 0;
return file.length();
}
long sizeofFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
sizeofFiles += fileOrDir.countSizeOfFiles();
}
return sizeofFiles;
}
public String getPath() {
return path;
}
public void addSubNode(FileSystemNode fileOrDir) {
subNodes.add(fileOrDir);
}
public void removeSubNode(FileSystemNode fileOrDir) {
int size = subNodes.size();
int i = 0;
for (; i < size; ++i) {
if (subNodes.get(i).getPath().equalsIgnoreCase(fileOrDir.getPath())) {
break;
}
}
if (i < size) {
subNodes.remove(i);
}
}
}
// 好的实现
public abstract class FileSystemNode {
protected String path;
public FileSystemNode(String path) {
this.path = path;
}
public abstract int countNumOfFiles();
public abstract long countSizeOfFiles();
public String getPath() {
return path;
}
}
public class File extends FileSystemNode {
public File(String path) {
super(path);
}
@Override
public int countNumOfFiles() {
return 1;
}
@Override
public long countSizeOfFiles() {
java.io.File file = new java.io.File(path);
if (!file.exists()) return 0;
return file.length();
}
}
public class Directory extends FileSystemNode {
private List<FileSystemNode> subNodes = new ArrayList<>();
public Directory(String path) {
super(path);
}
@Override
public int countNumOfFiles() {
int numOfFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
numOfFiles += fileOrDir.countNumOfFiles();
}
return numOfFiles;
}
@Override
public long countSizeOfFiles() {
long sizeofFiles = 0;
for (FileSystemNode fileOrDir : subNodes) {
sizeofFiles += fileOrDir.countSizeOfFiles();
}
return sizeofFiles;
}
public void addSubNode(FileSystemNode fileOrDir) {
subNodes.add(fileOrDir);
}
public void removeSubNode(FileSystemNode fileOrDir) {
int size = subNodes.size();
int i = 0;
for (; i < size; ++i) {
if (subNodes.get(i).getPath().equalsIgnoreCase(fileOrDir.getPath())) {
break;
}
}
if (i < size) {
subNodes.remove(i);
}
}
}
公司人员架构图
/**
* HumanResource 是部门类(Department)和员工类(Employee)抽象出来的父类,为的是能统一薪资的处理逻辑。
*/
public abstract class HumanResource {
protected long id;
protected double salary;
public HumanResource(long id) {
this.id = id;
}
public long getId() {
return id;
}
public abstract double calculateSalary();
}
public class Department extends HumanResource {
private List<HumanResource> subNodes = new ArrayList<>();
public Department(long id) {
super(id);
}
@Override
public double calculateSalary() {
double totalSalary = 0;
for (HumanResource hr : subNodes) {
totalSalary += hr.calculateSalary();
}
this.salary = totalSalary;
return totalSalary;
}
public void addSubNode(HumanResource hr) {
subNodes.add(hr);
}
}
public class Employee extends HumanResource {
public Employee(long id, double salary) {
super(id);
this.salary = salary;
}
@Override
public double calculateSalary() {
return salary;
}
}
public class DepartmentRepo {
public List<Long> getSubDepartmentIds(Long ID) {
return null;
}
}
public class EmployeeRepo {
public List<Long> getDepartmentEmployeeIds(Long id) {
return null;
}
public double getEmployeeSalary(Long id) {
return 0l;
}
}
public class Demo {
private static final long ORGANIZATION_ROOT_ID = 1001;
// 依赖注入
private EmployeeRepo employeeRepo;
// 依赖注入
public void buildOrganization() {
Department rootDepartment = new Department(ORGANIZATION_ROOT_ID);
buildOrganization(rootDepartment);
}
private DepartmentRepo departmentRepo;
private void buildOrganization(Department department) {
List<Long> subDepartmentIds = departmentRepo.getSubDepartmentIds(department.getId());
for (Long subDepartmentId : subDepartmentIds) {
Department subDepartment = new Department(subDepartmentId);
department.addSubNode(subDepartment);
buildOrganization(subDepartment);
}
List<Long> employeeIds = employeeRepo.getDepartmentEmployeeIds(department.getId());
for (Long employeeId : employeeIds) {
double salary = employeeRepo.getEmployeeSalary(employeeId);
department.addSubNode(new Employee(employeeId, salary));
}
}
}
享元模式
被共享的单元。复用对象,节省内存,前提是享元对象是不可变对象。当一个系统中存在大量重复对象的时候,如果这些重复的对象是不可变对象,我们就可以利用享元模式将对象设计成享元,在内存中只保留一份实例。注意整个生命周期都是对所有的线程共享的。
大量相似对象中不变的属性拆分为独立的类,共用
一个棋牌游戏(比如象棋)。一个游戏厅中有成千上万个“房间”,每个房 间对应一个棋局。棋局要保存每个棋子的数据。ChessPiece 类表示棋子,ChessBoard 类表示一 个棋局,里面保存了象棋中 30 个棋子的信息。
public class ChessBoard {
private Map<Integer, ChessPiece> chessPieces = new HashMap<>();
public ChessBoard() {
init();
}
private void init() {
chessPieces.put(1, new ChessPiece(1, "車", ChessPiece.Color.BLACK, 0, 0));
chessPieces.put(2, new ChessPiece(2, "馬", ChessPiece.Color.BLACK, 0, 1));
//...省略摆放其他棋子的代码...
}
public void move(int chessPieceId, int toPositionX, int toPositionY) {
//...省略...
}
}
public class ChessPiece {
private int id;
private String text;
private Color color;
private int positionX;
private int positionY;
public ChessPiece(int id, String text, Color color, int positionX, int positionY) {
this.id = id;
this.text = text;
this.color = color;
this.positionX = positionX;
this.positionY = positionX;
}
public static enum Color {RED, BLACK} // ...省略其他属性和getter/setter方法...
}
利用工厂类来缓存 ChessPieceUnit 信息(也就是 id、text、 color)。通过工厂类获取到的 ChessPieceUnit 就是享元。所有的 ChessBoard 对象共享 这 30 个 ChessPieceUnit 对象(因为象棋中只有 30 个棋子)。在使用享元模式之前,记录 1 万个棋局,我们要创建 30 万(30*1 万)个棋子的 ChessPieceUnit 对象。利用享元模式,我们只需要创建 30 个享元对象供所有棋局共享使用即可,大大节省了内存。
public class ChessPieceUnit {
private int id;
private String text;
private Color color;
public ChessPieceUnit(int id, String text, Color color) {
this.id = id;
this.text = text;
this.color = color;
}
public static enum Color {RED, BLACK}
// ...省略其他属性和getter方法...
}
/**
* 利用工厂类来缓存 ChessPieceUnit 信息(也就是 id、text、color)。通过工厂类获取到的 ChessPieceUnit 就是享元。
*/
public class ChessPieceUnitFactory {
private static final Map<Integer, ChessPieceUnit> pieces = new HashMap<>();
static {
pieces.put(1, new ChessPieceUnit(1, "車", ChessPieceUnit.Color.BLACK));
pieces.put(2, new ChessPieceUnit(2, "馬", ChessPieceUnit.Color.BLACK)); //...省略摆放其他棋子的代码...
}
public static ChessPieceUnit getChessPiece(int chessPieceId) {
return pieces.get(chessPieceId);
}
}
public class ChessPiece {
private ChessPieceUnit chessPieceUnit;
private int positionX;
private int positionY;
public ChessPiece(ChessPieceUnit unit, int positionX, int positionY) {
this.chessPieceUnit = unit;
this.positionX = positionX;
this.positionY = positionY;
} // 省略getter、setter方法
}
public class ChessBoard {
private Map chessPieces = new HashMap<>();
public ChessBoard() {
init();
}
private void init() {
chessPieces.put(1, new ChessPiece(ChessPieceUnitFactory.getChessPiece(1), 0, 0));
chessPieces.put(1, new ChessPiece(ChessPieceUnitFactory.getChessPiece(2), 1, 0));
//...省略摆放其他棋子的代码...
}
public void move(int chessPieceId, int toPositionX, int toPositionY) {
//...省略...
}
}
文本编辑器的优化
内存中表示一个文本文件,只需要记录文字和格式两部分信息就可以了,其中,格式又包括文字的字体、大小、颜色等信息。
public class Character {
private char c;
private Font font;
private int size;
private int colorRGB;
public Character(char c, Font font, int size, int colorRGB) {
this.c = c;
this.font = font;
this.size = size;
this.colorRGB = colorRGB;
}
}
public class Editor {
private List<Character> chars = new ArrayList<>();
public void appendCharacter(char c, Font font, int size, int colorRGB) {
Character character = new Character(c, font, size, colorRGB);
chars.add(character);
}
}
对于字体格式,我们可以将它设计成享元,让不同的文字共享使用。
public class Character {
private char c;
private CharacterStyle style;
public Character(char c, CharacterStyle style) {
this.c = c;
this.style = style;
}
}
public class CharacterStyle {
private Font font;
private int size;
private int colorRGB;
public CharacterStyle(Font font, int size, int colorRGB) {
this.font = font;
this.size = size;
this.colorRGB = colorRGB;
}
@Override
public boolean equals(Object o) {
CharacterStyle otherStyle = (CharacterStyle) o;
return font.equals(otherStyle.font) &&
size == otherStyle.size && colorRGB == otherStyle.colorRGB;
}
}
public class CharacterStyleFactory {
private static final List<CharacterStyle> styles = new ArrayList<>();
public static CharacterStyle getStyle(Font font, int size, int colorRGB) {
CharacterStyle newStyle = new CharacterStyle(font, size, colorRGB);
for (CharacterStyle style : styles) {
if (style.equals(newStyle)) {
return style;
}
}
styles.add(newStyle);
return newStyle;
}
}
public class Editor {
private List<Character> chars = new ArrayList<>();
public void appendCharacter(char c, Font font, int size, int colorRGB) {
Character character = new Character(c, CharacterStyleFactory.getStyle(font, size, colorRGB));
chars.add(character);
}
}
享元模式 vs 单例、缓存、对象池
- 在单例模式中,一个类只能创建一个对象,而在享元模式中,一个类可以创建多个对象,每个对象被多处代码引用共享。
- 平时所讲的缓存,主要是为了提高访问效率,而非复用。
- 对象池也是为了复用,但是一个线程用的时候其余线程不能用,享元由于是不可变的,整个生命周期都是可以被共用的。
Java Integer、String 中的应用
IntegerCache 只缓存 -128 到 127 之间的整型值,加载的时候,缓存的享元对象会被集中一次性创建好。也就是一个字节的大小(-128 到 127 之间的数 据)。
// 不会使用到 IntegerCache
Integer a = new Integer(123);
// 会使用到 IntegerCache
Integer a = 123;
// 会使用到 IntegerCache
Integer a = Integer.valueOf(123);
在 Java String 类的实现中,JVM 开辟一块存储区专门存储字符串常量,这块存储区叫作 字符串常量池,类似于 Integer 中的 IntegerCache。不过,跟 IntegerCache 不同的是, 它并非事先创建好需要共享的对象,而是在程序的运行期间,根据需要来创建和缓存字符串 常量。
不可滥用享元模式
享元模式对 JVM 的垃圾回收并不友好。因为享元工厂类一直保存了对享元对象的 引用,这就导致享元对象在没有任何代码使用的情况下,也并不会被 JVM 垃圾回收机制自动回收掉。因此,在某些情况下,如果对象的生命周期很短,也不会被密集使用,利用享元 模式反倒可能会浪费更多的内存。所以,除非经过线上验证,利用享元模式真的可以大大节省内存,否则,就不要过度使用这个模式,为了一点点内存的节省而引入一个复杂的设计模式,得不偿失啊。
行为型
观察者模式、发布订阅模式
有同步阻塞的实现方式,也有异步非阻塞的实现方式;有进程内的实现方式,也有跨进程的实现方式。
- 同步阻塞是最经典的实现方式,主要是为了代码解耦;
- 异步非阻塞除了能实现代码解耦之外,还能提高代码的执行效率;
- 进程间的观察者模式解耦更加彻底,一般是基于消息队列来实现,用来实现不同进程间的被观察者和观察者之间的交互。
同步阻塞的模板代码
当一个对象状态改变的时候,所有依赖的对象都会自动收到通知。被依赖的对象叫作被观察者(Observable),依赖的对象叫作观察者 (Observer)。
// 被观察者
public interface Subject {
void registerObserver(Observer observer);
void removeObserver(Observer observer);
void notifyObservers(Message message);
}
public class ConcreteSubject implements Subject {
private List<Observer> observers = new ArrayList();
@Override
public void registerObserver(Observer observer) {
observers.add(observer);
}
@Override
public void removeObserver(Observer observer) {
observers.remove(observer);
}
@Override
public void notifyObservers(Message message) {
for (Observer observer : observers) {
observer.update(message);
}
}
}
// 观察者
public interface Observer {
void update(Message message);
}
public class ConcreteObserverOne implements Observer {
@Override
public void update(Message message) {
//TODO: 获取消息通知,执行自己的逻辑...
System.out.println("ConcreteObserverOne is notified.");
}
}
public class ConcreteObserverTwo implements Observer {
@Override
public void update(Message message) {
//TODO: 获取消息通知,执行自己的逻辑...
System.out.println("ConcreteObserverTwo is notified.");
}
}
public class Message {
}
public class Demo {
public static void main(String[] args) {
ConcreteSubject subject = new ConcreteSubject();
subject.registerObserver(new ConcreteObserverOne());
subject.registerObserver(new ConcreteObserverTwo());
subject.notifyObservers(new Message());
}
}
异步非阻塞的模板代码
如果注册接口是一个调用比较频繁的接口,对性能非常敏感,希望接口的响应时间尽可能短,那我们可以将同步阻塞的实现方式改为异步非阻塞的实现方式,以此来减少响应时间。
- 使用一个新的线程执行代码。
- 使用eventBus来实现
- 使用消息队列实现,但是系统需要添加新中间件
新建线程来实现
// 同步
public class UserController {
private UserService userService; // 依赖注入
private List<RegObserver> regObservers = new ArrayList<>();
// 一次性设置好,之后也不可能动态的修改
public void setRegObservers(List observers) {
regObservers.addAll(observers);
}
public Long register(String telephone, String password) {
//省略输入参数的校验代码
// 省略userService.register()异常的try-catch代码
long userId = userService.register(telephone, password);
for (RegObserver observer : regObservers) {
observer.handleRegSuccess(userId);
}
return userId;
}
}
/**
* 异步非阻塞观察者模式的简易实现
*/
// 使用线程处理异步函数
public class RegPromotionObserver implements RegObserver {
private PromotionService promotionService; // 依赖注入
@Override
public void handleRegSuccess(long userId) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
promotionService.issueNewUserExperienceCash(userId);
}
});
thread.start();
}
}
// 使用线程池处理异步函数
public class UserController {
private UserService userService; // 依赖注入
private List<RegObserver> regObservers = new ArrayList<>();
private Executor executor;
public UserController(Executor executor) {
this.executor = executor;
}
// 一次性设置好,之后也不可能动态的修改
public void setRegObservers(List observers) {
regObservers.addAll(observers);
}
public Long register(String telephone, String password) {
long userId = userService.register(telephone, password);
for (RegObserver observer : regObservers) {
// 使用线程池来处理函数,而不是新建线程
executor.execute(new Runnable() {
@Override
public void run() {
observer.handleRegSuccess(userId);
}
});
}
return userId;
}
}
使用eventBus来实现
/**
* EventBus 翻译为“事件总线”,它提供了实现观察者模式的骨架代码。
* 其中,Google Guava EventBus 就是一个比较著名的 EventBus 框架,它不仅仅支持异步非阻塞模式,同时也支持同步阻塞模式
*/
public class UserController {
private UserService userService; // 依赖注入
private EventBus eventBus;
private static final int DEFAULT_EVENTBUS_THREAD_POOL_SIZE = 20;
public UserController() {
//eventBus = new EventBus(); // 同步阻塞模式
eventBus = new AsyncEventBus(Executors.newFixedThreadPool(DEFAULT_EVENTBUS_THREAD_POOL_SIZE)); // 异步非阻塞模式
}
public void setRegObservers(List<Object> observers) {
for (Object observer : observers) {
eventBus.register(observer);
}
}
public Long register(String telephone, String password) {
//省略输入参数的校验代码 //省略userService.register()异常的try-catch代码
long userId = userService.register(telephone, password);
// 发消息
eventBus.post(userId);
return userId;
}
}
// 观察者
// 这个接口其实是没有必要的
public interface RegObserver {
void handleRegSuccess(long userId);
}
import com.google.common.eventbus.Subscribe;
public class RegNotificationObserver implements RegObserver {
private NotificationService notificationService;
@Override
@Subscribe
public void handleRegSuccess(long userId) {
notificationService.sendInboxMessage(userId, "Welcome...");
}
}
public class RegPromotionObserver implements RegObserver {
private PromotionService promotionService; // 依赖注入
@Override
@Subscribe
public void handleRegSuccess(long userId) {
promotionService.issueNewUserExperienceCash(userId);
}
}
其实不需要定义 Observer 接口, 任意类型的对象都可以注册到 EventBus 中,通过 @Subscribe 注解来标明类中哪个函数可以接收被观察者发送的消息。
自实现 eventBus
Guava EventBus 对外暴露的所有可调用接口,都封装在 EventBus 类中。其中, EventBus 实现了同步阻塞的观察者模式,AsyncEventBus 继承自 EventBus,提供了异步 非阻塞的观察者模式。
- register() 函数用来注册观察者。具体的函数定义如下所示。它可以接受任何类型(Object)的观察者。而在经典的观察者模式的实现中,register() 函数必须接 受实现了同一 Observer 接口的类对象。
- 相对于 register() 函数,unregister() 函数用来从 EventBus 中删除某个观察者。
- EventBus 类提供了 post() 函数,用来给观察者发送消息。
观察者而言:
- EventBus 通过方法上的 @Subscribe 注解来标明,某个函数能接收哪种类型的消息。方法的参数决定了监听什么类型的消息
内部关键数据结构:
- 最关键的一个数据结构是 Observer 注册表,记录了消息类型和可接收消息函数的对应关系。当调用 register() 函数注册观察者的时候,EventBus 通过解析 @Subscribe 注解,生成 Observer 注册表。当调用 post() 函数发送消息的时候, EventBus 通过注册表找到相应的可接收消息的函数,然后通过 Java 的反射语法来动态地创建对象、执行函数。对于同步阻塞模式,
- EventBus 在一个线程内依次执行相应的函数。 对于异步非阻塞模式,EventBus 通过一个线程池来执行相应的函数。
/**
* EventBus 实现的是阻塞同步的观察者模式。看代码你可能会有些疑问,这明明就用到了线程池 Executor 啊。实际上,MoreExecutors.directExecutor() 是 Google Guava
* 提供的工具类,看似是多线程,实际上是单线程。之所以要这么实现,主要还是为了跟 AsyncEventBus 统一代码逻辑,做到代码复用。
*/
public class EventBus {
private Executor executor;
private ObserverRegistry registry = new ObserverRegistry();
public EventBus() {
this(MoreExecutors.directExecutor());
}
protected EventBus(Executor executor) {
this.executor = executor;
}
public void register(Object object) {
registry.register(object);
}
public void post(Object event) {
List<ObserverAction> observerActions = registry.getMatchedObserverActions(event);
for (ObserverAction observerAction : observerActions) {
executor.execute(new Runnable() {
@Override
public void run() {
observerAction.execute(event);
}
});
}
}
}
/**
* 有了 EventBus,AsyncEventBus 的实现就非常简单了。
* 为了实现异步非阻塞的观察者模式,它就不能再继续使用 MoreExecutors.directExecutor() 了,而是需要在构造函数中,由调用者注入线程池。
*/
public class AsyncEventBus extends EventBus {
public AsyncEventBus(Executor executor) {
super(executor);
}
}
/**
* Subscribe 是一个注解,用于标明观察者中的哪个函数可以接收消息。
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Beta
public @interface Subscribe {
}
/**
* ObserverAction 类用来表示 @Subscribe 注解的方法,其中,target 表示观察者类,method 表示方法。
它主要用在 ObserverRegistry 观察者注册表中。
*/
public class ObserverAction {
private Object target;
private Method method;
public ObserverAction(Object target, Method method) {
this.target = Preconditions.checkNotNull(target);
this.method = method;
this.method.setAccessible(true);
}
public void execute(Object event) { // event是method方法的参数
try {
method.invoke(target, event);
} catch (InvocationTargetException | IllegalAccessException e) {
e.printStackTrace();
}
}
}
/**
* ObserverRegistry 类就是前面讲到的 Observer 注册表,是最复杂的一个类,
框架中几乎所有的核心逻辑都在这个类中。这个类大量使用了 Java 的反射语法,不过代码整体来说都不难理解,
* 其中,一个比较有技巧的地方是 CopyOnWriteArraySet 的使用。
*/
public class ObserverRegistry {
private ConcurrentMap<Class<?>, CopyOnWriteArraySet<ObserverAction>> registry = new ConcurrentHashMap<>();
/**
* 将观察者类的加有@Subscribe注解的方法的参数类型的class类找到,作为注册表的key,value则为对应的类与类的函数的一个集合
*
* @param observer
*/
public void register(Object observer) {
Map<Class<?>, Collection<ObserverAction>> observerActions = findAllObserverActions(observer);
for (Map.Entry<Class<?>, Collection<ObserverAction>> entry : observerActions.entrySet()) {
Class<?> eventType = entry.getKey();
Collection<ObserverAction> eventActions = entry.getValue();
CopyOnWriteArraySet<ObserverAction> registeredEventActions = registry.get(eventType);
if (registeredEventActions == null) {
registry.putIfAbsent(eventType, new CopyOnWriteArraySet<>());
registeredEventActions = registry.get(eventType);
}
registeredEventActions.addAll(eventActions);
}
}
/**
* 根据参数event的类型找到已注册的同一参数类型的 类及方法(载体是ObserverAction)
*
* @param event
* @return
*/
public List<ObserverAction> getMatchedObserverActions(Object event) {
List<ObserverAction> matchedObservers = new ArrayList<>();
Class<?> postedEventType = event.getClass();
for (Map.Entry<Class<?>, CopyOnWriteArraySet<ObserverAction>> entry : registry.entrySet()) {
Class<?> eventType = entry.getKey();
Collection<ObserverAction> eventActions = entry.getValue();
// 类是不是另一个类的子类
if (eventType.isAssignableFrom(postedEventType)) {
matchedObservers.addAll(eventActions);
}
}
return matchedObservers;
}
/**
* 将当前observer观察者类与加有@Subscribe注解的方法 添加到observerActions Map里
*
* @param observer
* @return
*/
private Map<Class<?>, Collection<ObserverAction>> findAllObserverActions(Object observer) {
Map<Class<?>, Collection<ObserverAction>> observerActions = new HashMap<>();
Class<?> clazz = observer.getClass();
//将观察者类 有打上@Subscribe注解 的方法全部找出来
for (Method method : getAnnotatedMethods(clazz)) {
Class<?>[] parameterTypes = method.getParameterTypes();
Class<?> eventType = parameterTypes[0];
if (!observerActions.containsKey(eventType)) {
observerActions.put(eventType, new ArrayList<>());
}
observerActions.get(eventType).add(new ObserverAction(observer, method));
}
return observerActions;
}
/**
* 将观察者类 有打上@Subscribe注解的方法全部找出来
* 打上@Subscribe注解的方法只能有一个参数,否则会直接抛错(google的EventBus也是只能有一个参数而已吗?)
*
* @param clazz
* @return
*/
private List<Method> getAnnotatedMethods(Class<?> clazz) {
List<Method> annotatedMethods = new ArrayList<>();
for (Method method : clazz.getDeclaredMethods()) {
if (method.isAnnotationPresent(Subscribe.class)) {
Class<?>[] parameterTypes = method.getParameterTypes();
Preconditions.checkArgument(parameterTypes.length == 1,
"Method %s has @Subscribe annotation but has %s parameters."
+ "Subscriber methods must have exactly 1 parameter.",
method, parameterTypes.length);
annotatedMethods.add(method);
}
}
return annotatedMethods;
}
}
模板模式
模板模式主要是用来解决复用和扩展两个问题。定义骨架,具体实现在子类进行。
经典代码
- 模板方法定义为 final,可以避免被子类重写。
- 需要子类重写的方法定义为 abstract,可以强迫子类去实现。
public abstract class AbstractClass {
// 模板方法定义为 final,可以避免被子类重写。
public final void templateMethod() {
//...
method1();
// ...
method2();
// ...
}
protected abstract void method1();
protected abstract void method2();
}
public class ConcreteClass1 extends AbstractClass {
@Override
protected void method1() {
}
@Override
protected void method2() {
}
}
public class ConcreteClass2 extends AbstractClass {
@Override
protected void method1() {
}
@Override
protected void method2() {
}
}
使用场景:复用
所有的子类都可以复用父类中模板方法定义的流程代码。
- InputStream 中 read() 函数是一个模板方法,定义了读取数据的整个流程,并且暴露了一个可以由子类来定制的抽象方法。不过这个方法也被命名为了 read(),只是参数跟模板方法不同。
使用场景:扩展
框架通过模板模式提供功能扩展点,让框架用户可以在不修改框架源码的情况下,基于扩展点定制化框架的功能。
- 抛开高级框架来开发 Web 项目,必然会用到 Servlet。使用比较底层的 Servlet 来开发 Web 项目也不难。我们只需要定义一个继承 HttpServlet 的类,并且重写其中的 doGet() 或 doPost() 方法,来分别处理 get 和 post 请求。HttpServlet 的 service() 方法就是一个模板方法,它实现了整个 HTTP 请求的执行流程,doGet()、doPost() 是模板中可以由子类来定制的部分。 实际上,这就相当于 Servlet 框架提供了一个扩展点(doGet()、doPost() 方法),让框架用户在不用修改 Servlet 框架源码的情况下,将业务代码通过扩展点镶嵌到框架中执行。
回调
回调可以分为同步回调和异步回调(或者延迟回调)。同步回调指在函数返回之前执行回调函数;异步回调指的是在函数返回之后执行回调函数。
同步回调
public class Main {
public static void main(String[] args) {
BClass b = new BClass();
b.process(new ICallback() { //回调对象
@Override
public void methodToCallback() {
System.out.println("Call back me.");
}
});
}
}
public class BClass {
public void process(ICallback callback) {
//...
callback.methodToCallback();
//...
}
}
public interface ICallback {
void methodToCallback();
}
异步回调
通过三方支付系统来实现支付功能,用户在发起支付请求之后,一般不会一直阻塞到支付结果返回,而是注册回调接口(类似回调函数,一般是一个回调用的 URL)给三方支付系统, 等三方支付系统执行完成之后,将结果通过回调接口返回给用户。
同步回调看起来更像模板模式,异步回调看起来更像观察者模式。
应用举例一:JdbcTemplate
Spring 提供了很多 Template 类,比如,JdbcTemplate、RedisTemplate、 RestTemplate。尽管都叫作 xxxTemplate,但它们并非基于模板模式来实现的,而是基于 回调来实现的,确切地说应该是同步回调。而同步回调从应用场景上很像模板模式,所以, 在命名上,这些类使用 Template(模板)这个单词作为后缀。
JdbcTemplate 通过回调的机制,将不变的执行流程抽离出来,放到模板方法 execute() 中,将可变的部分设计成回调 StatementCallback,由用户来定制。query() 函数是对 execute() 函数的二次封装,让接口用起来更加方便。
应用举例二:addShutdownHook()
Hook 比较经典的应用场景是 Tomcat 和 JVM 的 shutdown hook。接下来,我们拿 JVM 来举例说明一下。JVM 提供了 Runtime.addShutdownHook(Thread hook) 方法,可以 注册一个 JVM 关闭的 Hook。当应用程序关闭的时候,JVM 会自动调用 Hook 代码。
模板模式 VS 回调
回调基于组合关系来实现,把一个对象传递给另一个对象,是一种对象之间的关系;模板模式基于继承关系来实现,子类重写父类的抽象方法,是一种类之间的关系。
组合优于继承。实际上,这里也不例外。在代码实现上,回调相对于模板模式会更加灵活
策略模式
利用它来避免冗长的 if-else 或 switch 分支判断,提供框架的扩展点等等。
定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用算法的客户端。
解耦定义、创建、使用
工厂模式是解耦对象的创建和使用,观察者模式是解耦观察者和被观察者,策略模式解耦的是策略的定义、创建、使用。
// 定义
public interface Strategy {
void algorithmInterface();
}
public class ConcreteStrategyA implements Strategy {
@Override
public void algorithmInterface() {}
}
public class ConcreteStrategyB implements Strategy {
@Override
public void algorithmInterface() {}
}
// 创建:
// 如果策略类是无状态的,缓存到工厂类中,用的时候直接返回。
public class StatelessStrategyFactory {
private static final Map<String, Strategy> strategies = new HashMap<>();
static {
strategies.put("A", new ConcreteStrategyA());
strategies.put("B", new ConcreteStrategyB());
}
public static Strategy getStrategy(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
return strategies.get(type);
}
}
// 如果策略类是有状态的,用的时候都要返回新的
public class StrategyFactory {
public static Strategy getStrategy(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
if (type.equals("A")) {
return new ConcreteStrategyA();
} else if (type.equals("B")) {
return new ConcreteStrategyB();
}
return null;
}
}
// 使用
// 在程序运行期间, 根据配置、用户输入、计算结果等这些不确定因素,动态决定使用哪种策略。
使用策略避免分支判断
public class OrderService {
public double discount(Order order) {
double discount = 0.0;
OrderType type = order.getType();
if (type.equals(OrderType.NORMAL)) { // 普通订单
//...省略折扣计算算法代码
} else if (type.equals(OrderType.GROUPON)) { // 团购订单
//...省略折扣计算算法代码
} else if (type.equals(OrderType.PROMOTION)) { // 促销订单
//...省略折扣计算算法代码
}
return discount;
}
}
将不同类型订单的打折策略设计成策略类,并由工厂类来负责创建策略对象。
借助“查表法”,根据 type 查表替换分支判断。
public class OrderService {
public double discount(Order order) {
double discount = 0.0;
OrderType type = order.getType();
DiscountStrategy discountStrategy = DiscountStrategyFactory.getDiscountStrategy(type);
discount = discountStrategy.calDiscount(order);
return discount;
}
}
/**
* 无状态的策略工厂类
*/
public class DiscountStrategyFactory {
private static final Map<OrderType, DiscountStrategy> strategies = new HashMap<>();
static {
strategies.put(OrderType.NORMAL, new NormalDiscountStrategy());
strategies.put(OrderType.GROUPON, new GrouponDiscountStrategy());
strategies.put(OrderType.PROMOTION, new PromotionDiscountStrategy());
}
public static DiscountStrategy getDiscountStrategy(OrderType type) {
return strategies.get(type);
}
}
/**
* 如果业务场景需要每次都创建不同的策略对象,我们就要用另外一种工厂类的实现方式了。
*/
public class DiscountStrategyFactoryB {
public static DiscountStrategy getDiscountStrategy(OrderType type) {
if (type == null) {
throw new IllegalArgumentException("Type should not be null.");
}
if (type.equals(OrderType.NORMAL)) {
return new NormalDiscountStrategy();
} else if (type.equals(OrderType.GROUPON)) {
return new GrouponDiscountStrategy();
} else if (type.equals(OrderType.PROMOTION)) {
return new PromotionDiscountStrategy();
}
return null;
}
}
但是如果策略是有状态的,还是会需要if-else 分支逻辑,从 OrderService 类中转移到了工厂类
面试题:对文件内的数字排序
只需要将文件中的内容读取出来,并且通过逗号分割成一个一个的数字,放到内存数组中,然后编写某种排序算法(比如快排),或者直接使用编程语 言提供的排序函数,对数组进行排序,最后再将数组中的数据写入文件就可以了。
如果文件很大呢?比如有 10GB 大小,因为内存有限(比如只有 8GB 大小),我们没办法一次性加载文件中的所有数据到内存中。如果文件更大,比如有 100GB 大小,我们为了利用 CPU 多核的优势,可以在外部排序的 基础之上进行优化,加入多线程并发排序的功能,这就有点类似“单机版”的 MapReduce。如果文件非常大,比如有 1TB 大小,即便是单机多线程排序,这也算很慢了。这个时候, 我们可以使用真正的 MapReduce 框架,利用多机的处理能力,提高排序的效率。
// 排序入口
public class Sorter {
private static final long GB = 1000 * 1000 * 1000;
private static final List<AlgRange> algs = new ArrayList<>();
static {
algs.add(new AlgRange(0, 6 * GB, SortAlgFactory.getSortAlg("QuickSort")));
algs.add(new AlgRange(6 * GB, 10 * GB, SortAlgFactory.getSortAlg("ExternalSort")));
algs.add(new AlgRange(10 * GB, 100 * GB, SortAlgFactory.getSortAlg("ConcurrentExternalSort")));
algs.add(new AlgRange(100 * GB, Long.MAX_VALUE, SortAlgFactory.getSortAlg("MapReduceSort")));
}
public void sortFile(String filePath) {
// 省略校验逻辑
File file = new File(filePath);
long fileSize = file.length();
ISortAlg sortAlg = null;
for (AlgRange algRange : algs) {
if (algRange.inRange(fileSize)) {
sortAlg = algRange.getAlg();
break;
}
}
sortAlg.sort(filePath);
}
}
// 消除比较范围的 if else
public class AlgRange {
private long start;
private long end;
private ISortAlg alg;
public AlgRange(long start, long end, ISortAlg alg) {
this.start = start;
this.end = end;
this.alg = alg;
}
public ISortAlg getAlg() {
return alg;
}
public boolean inRange(long size) {
return size >= start && size < end;
}
}
// 策略工厂
public class SortAlgFactory {
private static final Map<String, ISortAlg> algs = new HashMap<>();
static {
algs.put("QuickSort", new QuickSort());
algs.put("ExternalSort", new ExternalSort());
algs.put("ConcurrentExternalSort", new ConcurrentExternalSort());
algs.put("MapReduceSort", new MapReduceSort());
}
public static ISortAlg getSortAlg(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
return algs.get(type);
}
}
责任链模式
将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求,沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。
通过配置文件配置需要的处理器,客户端代码也可以不改,通过反射动态加载,但是一般不会这样,代码易读性不好。
经典代码
使用链表
/**
* HandlerChain 是处理器链,从数据结构的角度来看,它就是一个记录了链头、链尾的链表。其中,记录链尾是为了方便添加处理器。
*/
public class HandlerChain {
private Handler head = null;
private Handler tail = null;
public void addHandler(Handler handler) {
handler.setSuccessor(null);
if (head == null) {
head = handler;
tail = handler;
return;
}
tail.setSuccessor(handler);
tail = handler;
}
public void handle() {
if (head != null) {
head.handle();
}
}
}
/**
* 利用模板模式,将调用 successor.handle() 的逻辑从具体的处理器类中剥离出来,放到抽象父类中。这样具体的处理器类只需要实现自己的业务逻辑就可以了。
*/
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public final void handle() {
boolean handled = doHandler();
if (successor != null && !handled) {
successor.handle();
}
}
public abstract boolean doHandler();
}
使用数组
/**
* HandlerChain 类用数组而非链表来保存所有的处理器,并且需要在 HandlerChain 的 handle() 函数中,依次调用每个处理器的 handle() 函数。
*/
public class HandlerChain {
private List<IHandler> handlers = new ArrayList<>();
public void addHandler(IHandler handler) {
this.handlers.add(handler);
}
public void handle() {
for (IHandler handler : handlers) {
boolean handled = handler.handle();
if (handled) {
break;
}
}
}
}
public class HandlerA implements IHandler {
@Override
public boolean handle() {
//false 表示不处理,继续向下传递请求
boolean handled = false;
System.out.println("传递到HandlerA了");
//...
return handled;
}
}
应用场景
Servlet Filter:双向拦截
添加过滤器非常方便,不需要修改任何代码,定义一个实现 javax.servlet.Filter 的类,再改改配置就搞定了,完全符合开闭原则。
javax.servlet.Filter 就是处理器接口,FilterChain 就是处理器链。Servlet 中的 FilterChain 只是一个接口定义。具体的实现类由遵从 Servlet 规范的Web 容器来提供。
上面的拦截器只支持单向拦截,想实现双向拦截,类似AOP的,可以使用递归调用。
@Override
public void doFilter(ServletRequest request, ServletResponse response) {
if (pos < n) {
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
// 递归调用
filter.doFilter(request, response, this);
} else {
// filter都处理完毕后,执行servlet
servlet.service(request, response);
}
}
//把filter.doFilter的代码实现展开替换
@Override
public void doFilter(ServletRequest request, ServletResponse response) {
if (pos < n) {
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
// 递归调用
//filter.doFilter(request, response, this);
//把filter.doFilter的代码实现展开替换到这里
System.out.println("拦截客户端发送来的请求.");
chain.doFilter(request, response); // chain就是this
System.out.println("拦截发送给客户端的响应.")
} else {
// filter都处理完毕后,执行servlet
servlet.service(request, response);
}
}
Spring Interceptor
Servlet Filter 是 Servlet 规范的一部分,实现依赖于 Web 容器。 Spring Interceptor 是 Spring MVC 框架的一部分,由 Spring MVC 框架来提供实现。
会先经过 Servlet Filter,然后再经过 Spring Interceptor,最后到达具体的业务代码中。
implements HandlerInterceptor
HandlerExecutionChain 类是职责链模式中 的处理器链。它的实现相较于 Tomcat 中的 ApplicationFilterChain 来说,逻辑更加清晰,不需要使用递归来实现,主要是因为它将请求和响应的拦截工作,拆分到了两个函数中实现。
在 Spring 框架中,DispatcherServlet 的 doDispatch() 方法来分发请求,它在真正的业务逻辑执行前后,执行 HandlerExecutionChain 中的 applyPreHandle() 和 applyPostHandle() 函数,用来实现拦截的功能。
状态模式
状态模式并不是很常用,但是在能够用到的场景里,它可以发挥很大的作用。
有限状态机
有限状态机,英文翻译是 Finite State Machine,缩写为 FSM,简称为状态机。状态机有 3 个组成部分:状态(State)、事件(Event)、动作(Action)。其中,事件也称为转 移条件(Transition Condition)。事件触发状态的转移及动作的执行。不过,动作不是必 须的,也可能只转移状态,不执行任何动作。
实现方式
- 第一种实现方式叫分支逻辑法。利用 if-else 或者 switch-case 分支逻辑,将每一个状态转移原模原样地直译成代码。对于简单的状态机来说,这种实现方式最简单、最直接,是首选。
- 第二种实现方式叫查表法。对于状态很多、状态转移比较复杂的状态机来说,查表法比较合适。通过二维数组来表示状态转移图,能极大地提高代码的可读性和可维护性。
- 第三种实现方式叫状态模式。对于状态并不多、状态转移也比较简单,但事件触发执行的动作包含的业务逻辑可能比较复杂的状态机来说,我们首选这种实现方式。
分支逻辑法
模拟马里奥游戏里面,不同状态的马里奥
public enum State {
SMALL(0),
SUPER(1),
FIRE(2),
CAPE(3);
private int value;
private State(int value) {
this.value = value;
}
public int getValue() {
return this.value;
}
}
public class MarioStateMachine {
private int score;
private State currentState;
public MarioStateMachine() {
this.score = 0;
this.currentState = State.SMALL;
}
public void obtainMushRoom() {
if (currentState.equals(State.SMALL)) {
currentState = State.SUPER;
score += 100;
}
}
public void obtainCape() {
if (currentState.equals(State.SMALL) || currentState.equals(State.SUPER)) {
this.currentState = State.FIRE;
this.score += 300;
}
}
public void obtainFireFlower() {
if (currentState.equals(State.SMALL) || currentState.equals(State.SUPER)) {
this.currentState = State.FIRE;
this.score += 300;
}
}
public void meetMonster() {
if (currentState == State.CAPE) {
score -= 200;
} else if (currentState == State.SUPER) {
score -= 100;
} else if (currentState == State.FIRE) {
score -= 300;
}
currentState = State.SMALL;
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState;
}
}
查表法
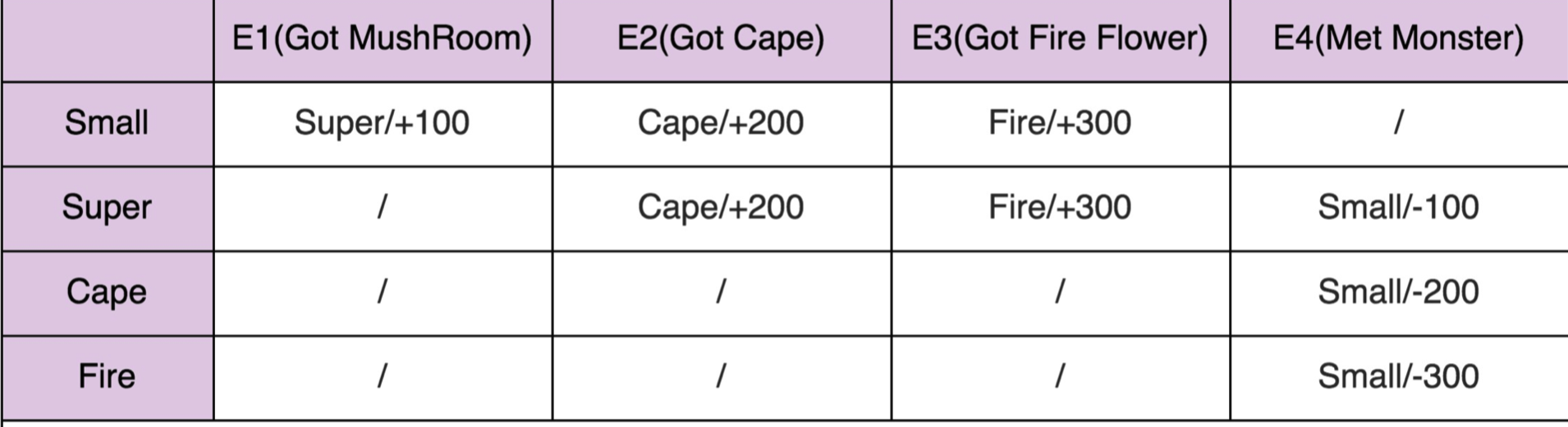
public enum Event {
GOT_MUSHROOM(0),
GOT_CAPE(1),
GOT_FIRE(2),
MET_MONSTER(3);
private int value;
private Event(int value) {
this.value = value;
}
public int getValue() {
return this.value;
}
}
public enum State {
SMALL(0),
SUPER(1),
FIRE(2),
CAPE(3);
private int value;
private State(int value) {
this.value = value;
}
public int getValue() {
return this.value;
}
}
public class MarioStateMachine {
private int score;
private State currentState;
private static final State[][] transitionTable = {{SUPER, CAPE, FIRE, SMALL}, {SUPER, CAPE, FIRE, SMALL}, {CAPE, CAPE, CAPE, SMALL}, {FIRE, FIRE, FIRE, SMALL}};
private static final int[][] actionTable = {{+100, +200, +300, +0}, {+0, +200, +300, -100}, {+0, +0, +0, -200}, {+0, +0, +0, -300}};
public MarioStateMachine() {
this.score = 0;
this.currentState = State.SMALL;
}
public void obtainMushRoom() {
executeEvent(Event.GOT_MUSHROOM);
}
public void obtainCape() {
executeEvent(Event.GOT_CAPE);
}
public void obtainFireFlower() {
executeEvent(Event.GOT_FIRE);
}
public void meetMonster() {
executeEvent(Event.MET_MONSTER);
}
private void executeEvent(Event event) {
int stateValue = currentState.getValue();
int eventValue = event.getValue();
this.currentState = transitionTable[stateValue][eventValue];
this.score = actionTable[stateValue][eventValue];
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState;
}
}
状态模式
状态是一个接口,每一个状态都有一个实现类,内部有当前状态下,事件发生时候的对应操作。
它通过将事件触发的状态转移和动作执行,拆分到不同的状态类中,以此来避免状态机类中的分支判断逻辑,应 对状态机类代码的复杂性。
public class ApplicationDemo {
public static void main(String[] args) {
MarioStateMachine mario = new MarioStateMachine();
mario.obtainMushRoom();
int score = mario.getScore();
IMario mario1 = mario.getMario();
System.out.println("mario score: " + score + "; state: " + mario1.getName());
}
}
public interface IMario {
State getName();
//以下是定义的事件
void obtainMushRoom(MarioStateMachine stateMachine);
void obtainCape(MarioStateMachine stateMachine);
void obtainFireFlower(MarioStateMachine stateMachine);
void meetMonster(MarioStateMachine stateMachine);
}
public class MarioStateMachine {
private int score;
private IMario mario; // 不再使用枚举来表示状态
public MarioStateMachine() {
this.score = 0;
this.mario = SmallMario.getInstance();
}
public void obtainMushRoom() {
mario.obtainMushRoom(this);
}
public void obtainCape() {
mario.obtainCape(this);
}
public void obtainFireFlower() {
mario.obtainFireFlower(this);
}
public void meetMonster() {
mario.meetMonster(this);
}
public void setScore(int score) {
this.score = score;
}
public int getScore() {
return this.score;
}
public IMario getMario() {
return mario;
}
public void setMario(IMario mario) {
this.mario = mario;
}
}
public class SmallMario implements IMario {
//用饿汉式实现单例模式
private static final SmallMario instance = new SmallMario();
private SmallMario() {
}
public static SmallMario getInstance() {
return instance;
}
@Override
public State getName() {
return State.SMALL;
}
@Override
public void obtainMushRoom(MarioStateMachine stateMachine) {
stateMachine.setMario(SuperMario.getInstance());
stateMachine.setScore(stateMachine.getScore() + 100);
}
@Override
public void obtainCape(MarioStateMachine stateMachine) {
stateMachine.setMario(new CapeMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 200);
}
@Override
public void obtainFireFlower(MarioStateMachine stateMachine) {
stateMachine.setMario(new FireMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 300);
}
@Override
public void meetMonster(MarioStateMachine stateMachine) {
}
}
实现方式选择
像游戏这种比较复杂的状态机,包含的状态比较多,我优先推荐使用查表法,而状态模式会引入非常多的状态类,会导致代码比较难维护。相反,像电商下单、外卖下单这种类型的状态机,它们的状态并不多,状态转移也比较简单,但事件触发执行的动作包含的业务逻辑可能会比较复杂,所以,更加推荐使用状态模式来实现。
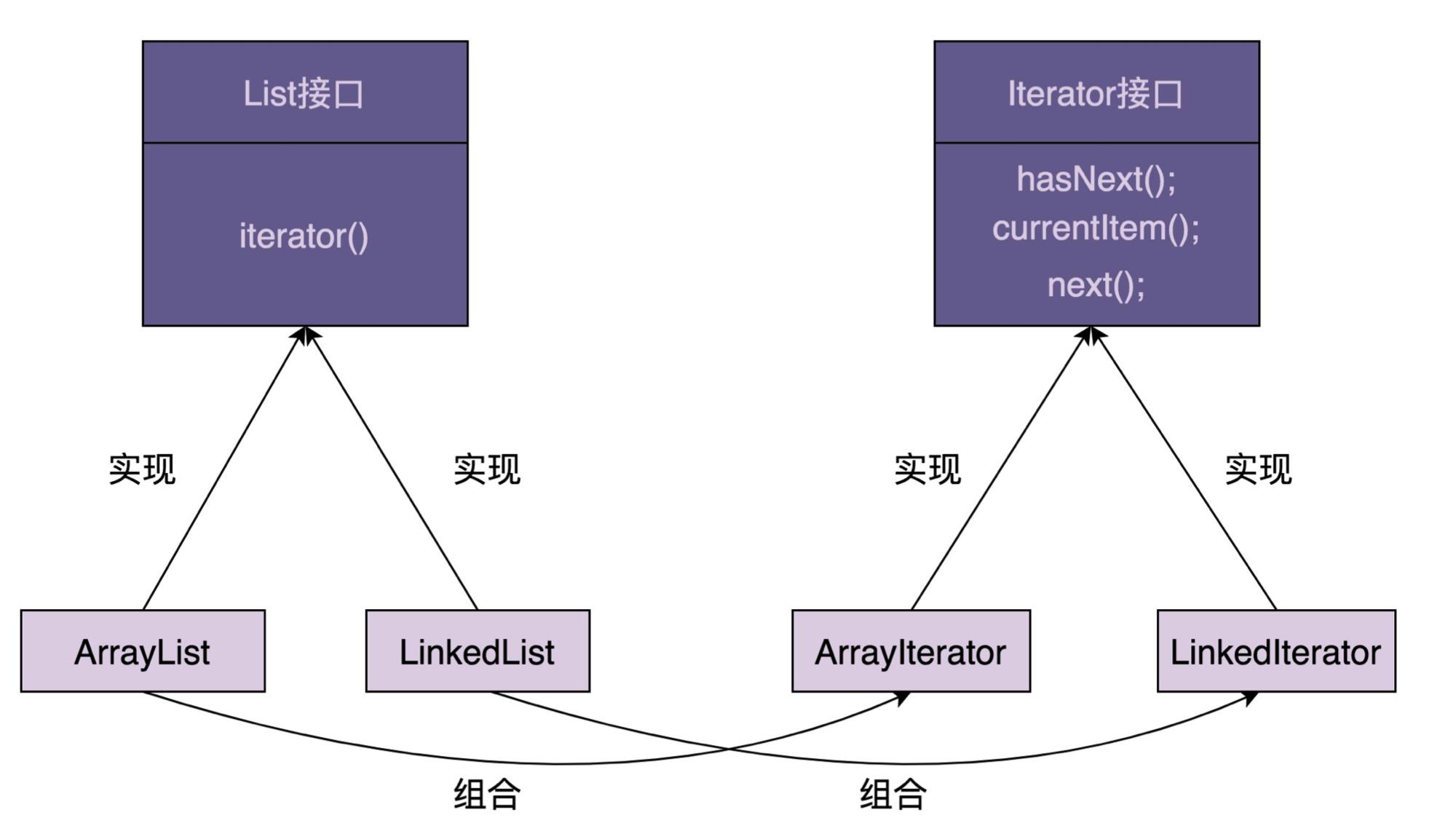
迭代器模式
迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一。
实现
迭代器接口中需要定义 hasNext()、currentItem()、next() 三个最基本的方法。当然next() 如果直接返回元素而不是void,那么currentItem()可以删除。
优势
遍历集合数据有三种方法:for 循环、foreach 循环、iterator 迭代器。foreach 循环只是一个语法糖而已,底层是基于迭代器来实现的。
推荐迭代器是因为
- 遍历常用,而且用户自己写遍历逻辑比较容易出错。
- 职责单一,符合开闭:比如从前往后遍历链表切换成从后往前遍历链表,客户端代码只需要将迭代器类从 LinkedIterator 切换为 ReversedLinkedIterator 即 可,其他代码都不需要修改。除此之外,添加新的遍历算法,我们只需要扩展新的迭代器 类,也更符合开闭原则。
并发修改异常的必要性和实现
在遍历的过程中删除集合元素,结果是不可预期的,删掉还没有走过去的,和删掉已经走过去的是不一样的。添加元素同样不可预期。
有两种比较干脆利索的解决方案:一种是遍历的时候不允许增删元素,另一种是增删元素之 后让遍历报错。
第二种 fail-fast 解决方式更加合理。第一种比较繁琐想实现完美控制。
这也是JDK中定义modCount的意义。
遍历时删除元素
迭代器类新增了一个 lastRet 成员变量,用来记录游标指向的前一个元素。通过迭代器去删除这个元素的时候,我们可以更新迭代器中的游标和 lastRet 值,来保证不会因为删除元素而导致某个元素遍历不到。如果通过容器来删除元素,并且希望更新迭代器中的游标值来保证遍历不出错,我们就要维护这个容器都创建了哪些迭代器,每个迭代器是否还在使用等信息,代码实现就变得比较复杂了。
访问者模式
在没有特别必要的情况下,建议你不要使用访问者模式。
允许一个或者多个操作应用到一组对象上,解耦操作和对象本身。
一般来说,访问者模式针对的是一组类型不同的对象(PdfFile、PPTFile、WordFile)。尽管这组对象的类型是不同的,但是,它们继承相同的父类(ResourceFile)或者实现相同的接口。在不同的应用场景下, 我们需要对这组对象进行一系列不相关的业务操作 (抽取文本、压缩等),为了避免不断添加功能导致类(PdfFile、PPTFile、WordFile) 不断膨胀,职责越来越不单一,以及避免频繁地添加功能导致的频繁代码修改,我们使用访问者模式,将对象与操作解耦,将这些业务操作抽离出来,定义在独立细分的访问者类 (Extractor、Compressor)中。不同类型本身不会有太多的业务逻辑。
public abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
abstract public void accept(Visitor vistor);
}
public class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
//...
}
//...PPTFile、WordFile跟PdfFile类似,这里就省略了...
public interface Visitor {
void visit(PdfFile pdfFile);
void visit(PPTFile pdfFile);
void visit(WordFile pdfFile);
}
public class Extractor implements Visitor {
@Override
public void visit(PPTFile pptFile) {
//...
System.out.println("Extract PPT.");
}
@Override
public void visit(PdfFile pdfFile) {
//...
System.out.println("Extract PDF.");
}
@Override
public void visit(WordFile wordFile) {
//...
System.out.println("Extract WORD.");
}
}
public class Compressor implements Visitor {
@Override
public void visit(PPTFile pptFile) {
//...
System.out.println("Compress PPT.");
}
@Override
public void visit(PdfFile pdfFile) {
//...
System.out.println("Compress PDF.");
}
@Override
public void visit(WordFile wordFile) {
//...
System.out.println("Compress WORD.");
}
}
public class ToolApplication {
public static void main(String[] args) {
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
for (ResourceFile resourceFile : resourceFiles) {
resourceFile.accept(extractor);
}
Compressor compressor = new Compressor();
for(ResourceFile resourceFile : resourceFiles) {
resourceFile.accept(compressor);
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
为什么支持 Double Dispatch 的语言不需要访问者模式?
Single Dispatch 之所以称为“Single”,是因为执行哪个对象的哪个方法,只跟“对象”的运行时类型有关。Java 支持多态特性,代码可以在运行时获得对象的实际类型。
Double Dispatch 之所以称为“Double”,是因为执行哪个对象的哪个方法,跟“对象”和“方法参数”两者的运行时类型有关。但 Java 设计的函数重载的语法规则是在编译时,根据传递进函数的参数的声明类型来决定调用哪个重载函数。
也就是说,JAVA 具体执行哪个对象的哪个方法,只跟对象的运行时类型有关,跟参数的运行时类型无关。所以,Java 语言只支持 Single Dispatch。
如果java 支持Double Dispatch ,下面的代码就不会在编译的时候报错:
public abstract class ResourceFile {
protected String filePath;
public ResourceFile(String filePath) {
this.filePath = filePath;
}
}
public class PdfFile extends ResourceFile {
public PdfFile(String filePath) {
super(filePath);
}
//...
}
//...PPTFile、WordFile代码省略...
public class Extractor {
public void extract2txt(PPTFile pptFile) {
//...
System.out.println("Extract PPT.");
}
public void extract2txt(PdfFile pdfFile) {
//...
System.out.println("Extract PDF.");
}
public void extract2txt(WordFile wordFile) {
//...
System.out.println("Extract WORD.");
}
}
public class ToolApplication {
public static void main(String[] args) {
Extractor extractor = new Extractor();
List<ResourceFile> resourceFiles = listAllResourceFiles(args[0]);
for (ResourceFile resourceFile : resourceFiles) {
// 报错
extractor.extract2txt(resourceFile);
}
}
private static List<ResourceFile> listAllResourceFiles(String resourceDirectory) {
List<ResourceFile> resourceFiles = new ArrayList<>();
//...根据后缀(pdf/ppt/word)由工厂方法创建不同的类对象(PdfFile/PPTFile/WordFile)
resourceFiles.add(new PdfFile("a.pdf"));
resourceFiles.add(new WordFile("b.word"));
resourceFiles.add(new PPTFile("c.ppt"));
return resourceFiles;
}
}
备忘录模式
用来防丢失、撤销、恢复等。在不违背封装原则的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便之后恢复对象为先前的状态。
面试题,希望你编写一个小程序,可以接收命令行的输入。用户输入文本时,程序将其追加存储在内存文本中;用户输入“:list”,程序在命令行中输出内存文本的内容;用户输入“:undo”,程序会撤销上一次输入的文本,也就是从内存文本中将上次输入的文本删除掉。
public class InputText {
private StringBuilder text = new StringBuilder();
public String getText() { return text.toString(); }
public void append(String input) { text.append(input); }
// 不符合封装,快照的信息缺乏封装,外面居然可以随便修改
public void setText(String text) { this.text.replace(0, this.text.length(), text); }
}
public class SnapshotHolder {
private Stack<InputText> snapshots = new Stack<>();
public InputText popSnapshot() { return snapshots.pop(); }
public void pushSnapshot(InputText inputText) {
InputText deepClonedInputText = new InputText();
deepClonedInputText.setText(inputText.getText());
snapshots.push(deepClonedInputText);
}
}
public class ApplicationMain {
public static void main(String[] args) {
InputText inputText = new InputText();
SnapshotHolder snapshotsHolder = new SnapshotHolder();
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
String input = scanner.next();
if (input.equals(":list")) {
System.out.println(inputText.toString());
} else if (input.equals(":undo")) {
InputText snapshot = snapshotsHolder.popSnapshot();
inputText.setText(snapshot.getText());
} else {
snapshotsHolder.pushSnapshot(inputText);
inputText.append(input);
}
}
}
}
经典代码
其一,定义一个独立的类(Snapshot 类)来表示快照,而不是复用 InputText 类。这个类只暴露 get() 方法,没有 set() 等任何修改内部状 态的方法。其二,在 InputText 类中,我们把 setText() 方法重命名为 restoreSnapshot() 方法,用意更加明确,只用来恢复对象。
public class InputText {
private StringBuilder text = new StringBuilder();
public String getText() { return text.toString(); }
public void append(String input) { text.append(input); }
public Snapshot createSnapshot() {
return new Snapshot(text.toString());
}
public void restoreSnapshot(Snapshot snapshot) {
this.text.replace(0, this.text.length(), snapshot.getText());
}
}
public class Snapshot {
private String text;
public Snapshot(String text) { this.text = text; }
public String getText() { return this.text; }
}
public class SnapshotHolder {
private Stack<Snapshot> snapshots = new Stack<>();
public Snapshot popSnapshot() { return snapshots.pop(); }
public void pushSnapshot(Snapshot snapshot) { snapshots.push(snapshot); }
}
public class ApplicationMain {
public static void main(String[] args) {
InputText inputText = new InputText();
SnapshotHolder snapshotsHolder = new SnapshotHolder();
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
String input = scanner.next();
if (input.equals(":list")) {
System.out.println(inputText.toString());
} else if (input.equals(":undo")) {
Snapshot snapshot = snapshotsHolder.popSnapshot();
inputText.restoreSnapshot(snapshot);
} else {
snapshotsHolder.pushSnapshot(inputText.createSnapshot());
inputText.append(input);
}
}
}
}
备忘录和备份的区别
备忘录模式更侧重于代码的设计和实现,备份更侧重架构设计或产品设计。
命令模式
使用频率低、理解难度大,只在非常特定的应用场景下才会用到。
命令模式将请求(命令)封装为一个对象,这样可以使用不同的请求参数化其他对象(将不 同请求依赖注入到其他对象),并且能够支持请求(命令)的排队执行、记录日志、撤销等 (附加控制)功能。设计一个包含这个函数的类,实例化一个对象传来传去,这样就可以实现把函数像对象一样使用。从实现的角度来说,它类似我们之前讲过的回调。
游戏中的命令模式
为了提高性能,我们会把游戏中玩家的信息保存在内存中。在游戏进行的过程中,只更新内 存中的数据,游戏结束之后,再将内存中的数据存档,也就是持久化到数据库中。为了节省网络连接建立的开销,客户端和服务器之间一般采用长连接的方式来通信。通信的格式有多种,比如 Protocol Buffer、JSON、XML,甚至可以自定义格式。客户端发送给服 务器的请求,一般都包括两部分内容:指令和数据。其中,指令我们也可以叫作事件,数据是执行这个指令所需的数据。
整个手游后端服务器轮询获取客户端发来的请求,获取到请求之后,借助命令模式,把请求 包含的数据和处理逻辑封装为命令对象,并存储在内存队列中。然后,再从队列中取出一定 数量的命令来执行。执行完成之后,再重新开始新的一轮轮询。
public interface Command {
void execute();
}
public class GotDiamondCommand implements Command {
// 省略成员变量
public GotDiamondCommand(/*数据*/) { //...
}
@Override
public void execute() {
// 执行相应的逻辑
}
}
//GotStartCommand/HitObstacleCommand/ArchiveCommand类省略
public class GameApplication {
private static final int MAX_HANDLED_REQ_COUNT_PER_LOOP = 100;
private Queue<Command> queue = new LinkedList<>();
public void mainloop() {
while (true) {
List<Request> requests = new ArrayList<>();
//省略从epoll或者select中获取数据,并封装成Request的逻辑,
//注意设置超时时间,如果很长时间没有接收到请求,就继续下面的逻辑处理。
for (Request request : requests) {
Event event = request.getEvent();
Command command = null;
if (event.equals(Event.GOT_DIAMOND)) {
command = new GotDiamondCommand(/*数据*/);
command = new GotStartCommand(/*数据*/);
} else if (event.equals(Event.GOT_STAR)) {
command = new HitObstacleCommand(/*数据*/);
} else if (event.equals(Event.HIT_OBSTACLE)) {
command = new ArchiveCommand(/*数据*/);
} else if (event.equals(Event.ARCHIVE)) {
} // ...一堆else if...
queue.add(command);
}
int handledCount = 0;
while (handledCount < MAX_HANDLED_REQ_COUNT_PER_LOOP) {
if (queue.isEmpty()) { break; }
Command command = queue.poll();
command.execute();
}
}
}
}
命令模式VS策略模式
策略模式包含策略的定义、创建和使用三部分,非常像工厂模式。策略模式侧重“策略”或“算法”这个特定的应用场景,而工厂模式侧重封装对象的创建过程,这里的对象没有任何业务场景的限定,可以是策略,但也可以是其他东西。
在策略模式中,不同的策略具有相同的目的、不同的实现、互相之间可以替换。而在命令模式中,不同的命令具有不同的目的,对应不同的处理逻辑,并且互相之间不可替换。
解释器模式
使用频率低、理解难度大,只在非常特定的应用场景下才会用到。
用在编译器、规则引擎、正则表达式。解释器模式为某个语言定义它的语法(或者叫文法)表示,并定义一个解释器用来处理这个语法。
一般的做法是,将语法规则拆分成一些小的独立的单元,然后对每个单元进行解析,最终合并为对整个语法规则的解析。
假设自定义的告警规则只包含“||、&&、>、<、”这五个运算符,其中,“>、<、”运算符的优先级高于“||、&&”运算符,“&&”运算符优先级高于“||”。在表达式中,任意元素之间需要通过空格来分隔。除此之外,用户可以自定义要监控的 key。
public interface Expression { boolean interpret(Map<String, Long> stats); }
public class GreaterExpression implements Expression {
private String key;
private long value;
public GreaterExpression(String strExpression) {
String[] elements = strExpression.trim().split("\\s+");
if (elements.length != 3 || !elements[1].trim().equals(">")) {
throw new RuntimeException("Expression is invalid: " + strExpression);
}
this.key = elements[0].trim();
this.value = Long.parseLong(elements[2].trim());
}
public GreaterExpression(String key, long value) {
this.key = key; this.value = value;
}
@Override
public boolean interpret(Map<String, Long> stats) {
if (!stats.containsKey(key)) { return false; }
long statValue = stats.get(key);
return statValue > value;
}
}
// LessExpression/EqualExpression跟GreaterExpression代码类似,这里就省略了
public class AndExpression implements Expression {
private List<Expression> expressions = new ArrayList<>();
public AndExpression(String strAndExpression) {
String[] strExpressions = strAndExpression.split("&&");
for (String strExpr : strExpressions) {
if (strExpr.contains(">")) {
expressions.add(new GreaterExpression(strExpr));
} else if (strExpr.contains("<")) {
expressions.add(new LessExpression(strExpr));
} else if (strExpr.contains("==")) {
expressions.add(new EqualExpression(strExpr));
} else {
throw new RuntimeException("Expression is invalid: ");
}
}
}
public AndExpression(List<Expression> expressions) { this.expressions.addAll(expressions); }
@Override
public boolean interpret(Map<String, Long> stats) {
for (Expression expr : expressions) {
if (!expr.interpret(stats)) { return false; }
}
return true;
}
}
public class OrExpression implements Expression {
private List<Expression> expressions = new ArrayList<>();
public OrExpression(String strOrExpression) {
String[] andExpressions = strOrExpression.split("\\|\\|");
for (String andExpr : andExpressions) {
expressions.add(new AndExpression(andExpr));
}
}
public OrExpression(List<Expression> expressions) { this.expressions.addAll(expressions); }
@Override
public boolean interpret(Map<String, Long> stats) {
for (Expression expr : expressions) {
if (expr.interpret(stats)) { return true; } }
return false;
}
}
public class AlertRuleInterpreter {
private Expression expression;
public AlertRuleInterpreter(String ruleExpression) {
this.expression = new OrExpression(ruleExpression);
}
public boolean interpret(Map<String, Long> stats) {
return expression.interpret(stats);
}
}
中介模式
使用频率低、理解难度大,只在非常特定的应用场景下才会用到
中介模式定义了一个单独的(中介)对象,来封装一组对象之间的交互。 将这组对象之间的交互委派给与中介对象交互,来避免对象之间的直接交互。我们知道给代码解耦的一个方法就是引入中间层。通过引入中介这个中间层,将一组对象之间的交互关系(或者说依赖关系)从多对多(网状关系)转换为一对多(星状关系)。降低了代码的复杂度,提高了代码的可读性和可维护性。每架飞机只跟塔台来通信,发送自己的位置给塔台,由塔台来负责每架飞机的航线调度。这样就大大简化了通信网络。
观察者模式VS中介模式
在观察者模式中,一个参与者要么是观察者,要么是被观察者,不会兼具两种身份。
中介模式参与者之间的交互关系错综复杂,既可以是消息的发送者、也可以同时是消息的接收者。中介模式的应用会带来一定的副作用,有可能会产生大而复杂的上帝类。中介模式就可以利用中介类,通过先后调用不同参与者的方法,来实现顺序的控制,而观察者模式是无法实现这样的顺序要求的。
避免过度设计与设计不足
千万别手里拿着锤子就看什么都是钉子啊。
- 过度设计。在开始编写代码之前,花很长时间做代码设计,应用各种设计模式,未雨绸缪,希望代码更加灵活,为未来的扩展打好基础,实则过度设计,未来的需求并不一定会实现,实际上是增加了代码的复杂度,以后的所有开发都要在这套复杂的设计基础之上来完成。
- 设计不足。怎么简单怎么来,写出来的代码能跑就可以,顶多算是 demo,看似在实践 KISS、YAGNI 原则,实则忽略了设计环节,代码毫无扩展性、灵活性可言,添加、修改一个很小的功能就要改动很多代码。
避免过度设计
不忘初心:提高代码质量
不管走多远、产品经过多少迭代、转变多少次方向,“初心”一般都不会随便改。当我们在为产品该不该转型、该不该做某个功能而拿捏不定的时候,想想它符不符合我们创业的初心, 有时候就自然有答案了。
应用设计模式只是方法,最终的目的,也就是初心,是提高代码的质量。具体点说就是,提高代码的可读性、可扩展性、可维护性等。所有的设计都是围绕着这个初心来做的。这样做是否能真正地提高代码质量,能提高代码质量的哪些方面。如果自己很难讲清楚,或者给出的理由都比较牵强,没有压倒性的优势,那基本上就可以断定这是一种过度设计,是为了设计而设计。
过程是先有问题后有方案
如果我们把写出的代码看作产品,那做产品的时候,我们先要思考痛点在哪里,用户的真正需求在哪里,然后再看要开发哪些功能去满足,而不是先拍脑袋想出一个花哨的功能,再去 东搬西凑硬编出一个需求来。
不是看到某个场景之后,觉得跟之前在某本书中看到的某个设计模式的应用场景很相似,就套用上去。先要去分析代码存在的痛点,比如可读性不好、可扩展性不好等等,然后再针对性地利用设计模式去改善。
看到某段代码之后,你就能够自己分析得头头是道,说出它好的地方、不好的地方,为什么好、为什么不好,不好的如何改善,可以应用哪种设计模式,应用了之后有哪些副作用要控制等等。
不具备具体问题具体分析的能力,在面对真实项目的千变万化的代码的时候,很容易就会滥用设计模式,过度设计。
设计前提是场景首先复杂
设计模式要干的事情就是解耦。利用更好的代码结构将一大坨代码拆分成职责更单一的小类,让其满足高内聚低耦合等特性。创建型模式是将创建和使用代码解耦,结构型模式是将不同的功能代码解耦,行为型模式是将不同的行为代码解耦。而解耦的主要目的是应对代码的复杂性。设计模式就是为了解决复杂代码问题而产生的。
持续重构
在真正有痛点的时候,再去考虑用设计模式来解决,而不是一开始就为不一定实现的未来需求而应用设计模式。
当对要不要应用某种设计模式感到模棱两可的时候,你可以思考一下,如果暂时不用这种设计模式,随着代码的演进,当某一天不得不去使用它的时候,重构的代码是否很大。如果不是,那能不用就不用,怎么简单就怎么来。说句实话,对于 10 万行以内的代码,团队成员稳定,对代码涉及的业务比较熟悉的情况下,即便将所有的代码都推倒重写,也不会花太多时间,因此也不必为代码的扩展性太过担忧。
避免设计不足
- 理论储备、可以练习
- 代码质量意识、设计意识
设计模式面试
提问思路
- 给候选人一个功能需求,让他去做代码设计和实现,然后,基于他的代码实现, 讨论代码的可读性、扩展性等代码质量方面的问题,然后让候选人继续优化,直到满意为 止。
- 给候选人一段有质量问题的代码,让他去做 Code Review,找出代码存在 的问题,然后做代码重构。
本身没有标准答案,背景又过于复杂开 放,如果只是丢给候选人回答,中间没有任何交流和引导,候选人很难抓住重点,展现出 你心里期望的表现。所以,面试的过程切忌像笔试一样,一问一答单向沟通。相反,我们 要把面试当做一场与未来同事的技术讨论,在讨论的过程中去感受候选人的技术实力。
当候选人写完代码之后,如果面试官一个问题都不提,然后就跳到其他面试题目,这种体 验,不管是对候选人,还是面试官来说,都不是很好。相反,如果面试官能一语中的地提出设计中的缺陷,深入地跟候选人去讨论,这样一方面能给候选人充分发挥的机会,另一 方面,也会赢来候选人对公司技术的认可。
设计模式面试回答思路
对于第一种问题,大部分情况下,面试官给出的功能需求,都 是比较笼统、模糊的,这本身就是为了考察你的沟通能力、分析能力,是否能通过挖掘、 假设、取舍,搞清楚具体的需求,梳理出可以执行落地的需求列表。跟面试官确定好需求之后,就可以开始设计和实现了。前面也提到,面试的目的是考察候 选人在真实项目开发中的表现。在工作中,我们都是从最简单的设计和实现方案做起,所以,回答这种设计面试题,也不要一下子就搞得太复杂,为了设计而设计,非得用些比较 复杂的设计模式。不过,在用最简单方式实现之后,你可以再讲一下,如何基于某某设计模式,进一步对代 码进行解耦,进一步提高代码的扩展性。基于这种最简单的代码,再行讨论优化,这样跟 面试官讨论起来,也会更加言之有物。这也能体现你的代码演进思维,以及具体问题具体 分析的能力。
第二种面试题目会更加明确、具体。你就把它当作一次真实的 Code Review 来回答就好了。
实战设计
基于充血模型的DDD设计虚拟钱包系统
背景
一般来讲,每个虚拟钱包账户都会对应用户的一个真实的支付账户,有可能是银行卡账户, 也有可能是三方支付账户(比如支付宝、微信钱包)。限定钱包 暂时只支持充值、提现、支付、查询余额、查询交易流水这五个核心的功能。
- 充值:用户通过三方支付渠道,把自己银行卡账户内的钱,充值到虚拟钱包账号中。这整个过程, 我们可以分解为三个主要的操作流程:第一个操作是从用户的银行卡账户转账到应用的公共银行卡账户;第二个操作是将用户的充值金额加到虚拟钱包余额上;第三个操作是记录刚刚这笔交易流水。
- 支付:用户用钱包内的余额,支付购买应用内的商品。从用户的虚拟钱包账户划钱到商家的虚拟钱包账户上,然后触发真正的银行转账操作,从应用的公共银行账户转钱到商家的银行账户。除此之外,我们也需要记录这笔支付的交易流水信息。
- 提现:扣减用户虚拟钱包中的余额,并且触发真正的银行转账操作,从应用的公共银行账户转钱到用户的银行账户。同样,我们也需要记录这笔提现的交易流水信息。
- 查询余额:直接查询虚拟钱包的余额
- 查询交易流水:充值、支付、提现的时候,我们会记录相应的交易信息。在需要查询的时候,按照时间、类型等条件过滤之后,显示出来即可。
分析&设计
业务建模划分子系统
钱包系统的业务划分为两部分, 其中一部分单纯跟应用内的虚拟钱包账户打交道,另一部分单纯跟银行账户打交道。我们基于这样一个业务划分,给系统解耦,将整个钱包系统拆分为两个子系统:虚拟钱包系统和三方支付系统。
- 钱包系统
- 虚拟钱包系统
- 用户虚拟钱包
- 商家虚拟钱包
- 三方支付系统
- 用户银行卡
- 商家银行卡
- 应用公共银行卡
- 虚拟钱包系统
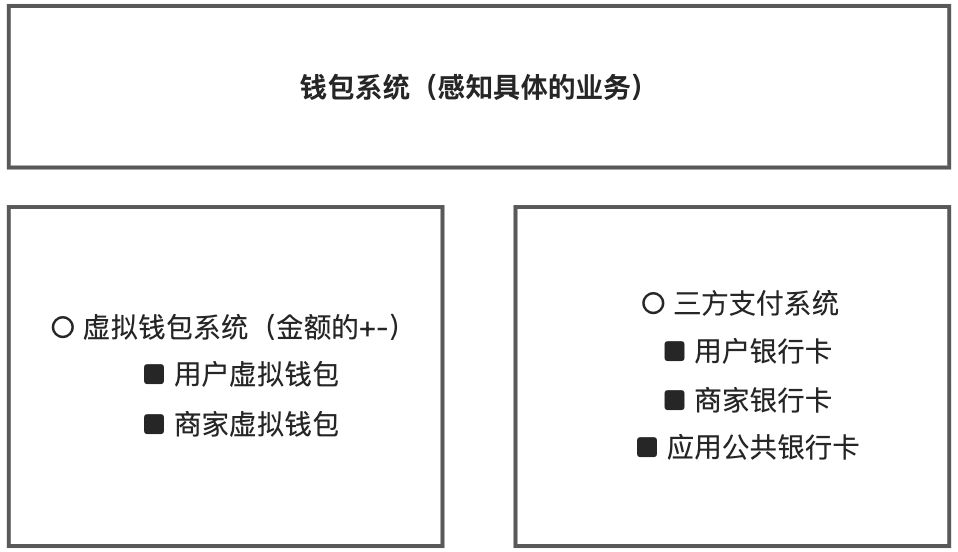
功能分析
钱包的五个核心功能:
- 充值(+余额)、提现(-余额)、支付(+-余额)、查询余额(查询余额)、查询交易流水
交易流水的记录格式选择:
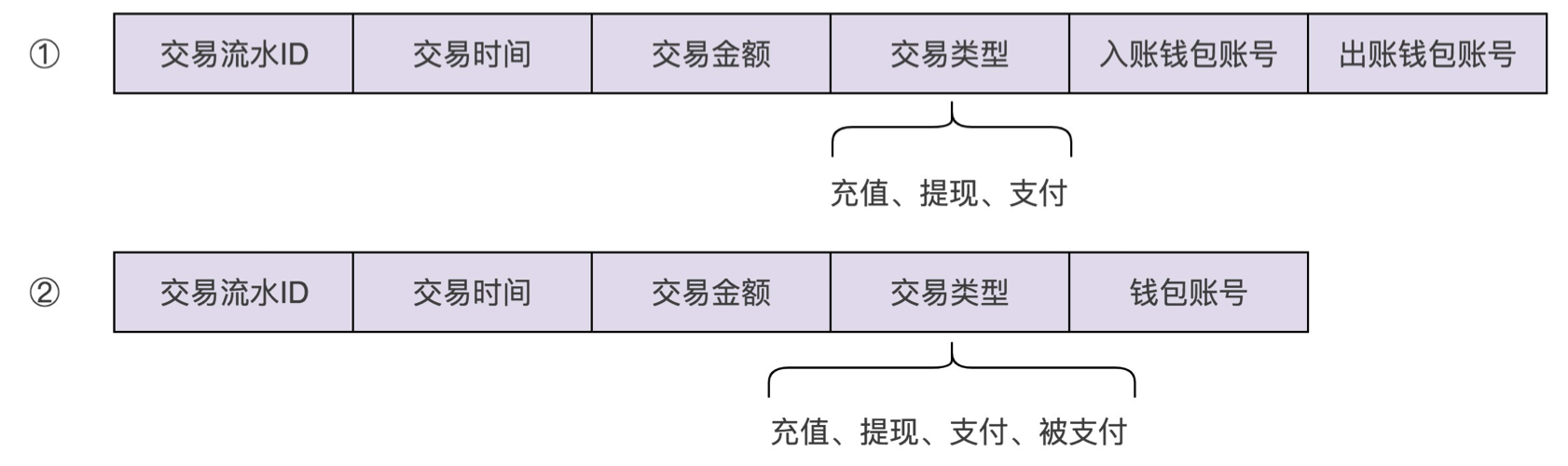
第二种在支付过程中会有两条记录进来,如果又是分库分表,本身数据一致性保证就比较麻烦。但是第一种虽然在数据上有冗余,对于充值没有出账钱包,对于提现没有入账钱包,但是没有数据一致性问题,所以还是会选择第一种方式记录。
虚拟钱包不应该感知业务交易类型
虚拟钱包只管钱的加减。职责单一。用户查询交易流水直接去上层的钱包系统,钱包系统可以感知充值、支付、提现等业务概念。在钱包系统这一层额外再记录一条包含交易类型的交易流水信息,而在底层的虚拟钱包系统中记录不包含交易类型的交易流水信息。
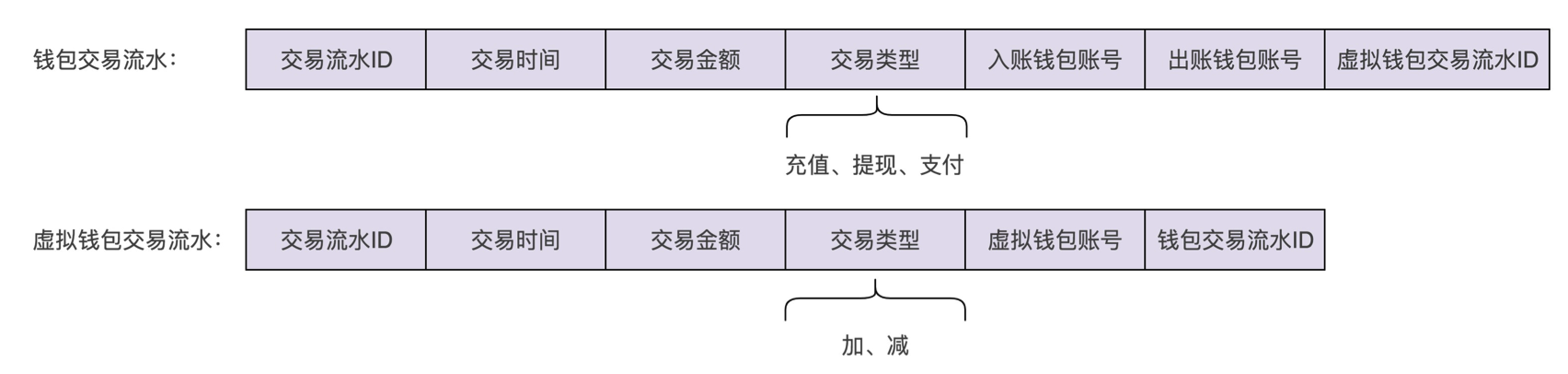
实现
基于贫血模型的传统开发模式
public class VirtualWalletController {
// 通过构造函数或者 IOC 框架注入
private VirtualWalletService virtualWalletService;
public BigDecimal getBalance(Long walletId) { ... } // 查询余额
public void debit(Long walletId, BigDecimal amount) { ... } // 出账
public void credit(Long walletId, BigDecimal amount) { ... } // 入账
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {}
}
public class VirtualWalletBo {
// 省略 getter/setter/constructor 方法
private Long id; private Long createTime; private BigDecimal balance;
}
public class VirtualWalletService {
// 通过构造函数或者 IOC 框架注入
private VirtualWalletRepository walletRepo;
private VirtualWalletTransactionRepository transactionRepo;
public VirtualWalletBo getVirtualWallet(Long walletId) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWalletBo walletBo = convert(walletEntity);
return walletBo;
}
// 查询余额
public BigDecimal getBalance(Long walletId) {
return virtualWalletRepo.getBalance(walletId);
}
// 转出
public void debit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
BigDecimal balance = walletEntity.getBalance();
if (balance.compareTo(amount) < 0) {
throw new NoSufficientBalanceException(...);
}
walletRepo.updateBalance(walletId, balance.subtract(amount));
}
// 转入
public void credit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
BigDecimal balance = walletEntity.getBalance();
walletRepo.updateBalance(walletId, balance.add(amount));
}
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransactionEntity();
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setFromWalletId(fromWalletId);
transactionEntity.setToWalletId(toWalletId);
transactionEntity.setStatus(Status.TO_BE_EXECUTED);
Long transactionId = transactionRepo.saveTransaction(transactionEntity);
try {
debit(fromWalletId, amount);
credit(toWalletId, amount);
} catch (InsufficientBalanceException e) {
transactionRepo.updateStatus(transactionId, Status.CLOSED);
...rethrow exception e...
} catch (Exception e) {
transactionRepo.updateStatus(transactionId, Status.FAILED);
...rethrow exception e...
}
transactionRepo.updateStatus(transactionId, Status.EXECUTED);
}
}
基于充血模型的DDD开发模式
主要区别就在 Service 层,Controller 层和 Repository 层的代码基本上相同。
把虚拟钱包 VirtualWallet 类设计成一个充血的 Domain 领域模型,并且将原来在 Service 类中的部分业务逻辑移动到 VirtualWallet 类中,让 Service 类的实现依赖 VirtualWallet 类。
public class VirtualWallet {
// Domain 领域模型 (充血模型)
private Long id;
private Long createTime = System.currentTimeMillis();
private BigDecimal balance = BigDecimal.ZERO;
// 支持透支一定额度和冻结部分余额的功能。
// private boolean isAllowedOverdraft = true;
// private BigDecimal overdraftAmount = BigDecimal.ZERO;
// private BigDecimal frozenAmount = BigDecimal.ZERO;
public VirtualWallet(Long preAllocatedId) {
this.id = preAllocatedId;
}
public BigDecimal balance() { return this.balance; }
public void debit(BigDecimal amount) {
if (this.balance.compareTo(amount) < 0) {
throw new InsufficientBalanceException(...);
}
this.balance.subtract(amount);
}
public void credit(BigDecimal amount) {
if (amount.compareTo(BigDecimal.ZERO) < 0) {
throw new InvalidAmountException(...);
}
this.balance.add(amount);
}
}
public class VirtualWalletService {
// 通过构造函数或者 IOC 框架注入
private VirtualWalletRepository walletRepo;
private VirtualWalletTransactionRepository transactionRepo;
public VirtualWallet getVirtualWallet(Long walletId) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
return wallet;
}
public BigDecimal getBalance(Long walletId) { return virtualWalletRepo.getBalance(walletId); }
// 出账
public void debit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
wallet.debit(amount);
walletRepo.updateBalance(walletId, wallet.balance());
}
// 入账
public void credit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
wallet.credit(amount);
walletRepo.updateBalance(walletId, wallet.balance());
}
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {
//... 跟基于贫血模型的传统开发模式的代码一样 ...
}
}
现在和贫血相比没有优势,但是如果虚拟钱包系统需要支持更复杂的业务逻辑,那充血模型的优势就显现出来了。如果功能继续演进,我们可以增加更加细化的冻结策略、透支策略、 支持钱包账号(VirtualWallet id 字段)自动生成的逻辑(不是通过构造函数经外部传入 ID,而是通过分布式 ID 生成算法来自动生成 ID)等等。VirtualWallet 类的业务逻辑会变得越来越复杂,也就很值得设计成充血模型了。
DDD中Service的作用
在基于充血模型的 DDD 开发模式下,Service 类并不会完全移除,而是负责一些不适合放 在 Domain 类中的功能。比如,负责与 Repository 层打交道、跨领域模型的业务聚合功 能、幂等事务等非功能性的工作。
Controller 层和 Repository 层是否有必要充血?
基于充血模型的 DDD 开发模式跟基于贫血模型的传统开发模式相比,Controller 层和 Repository 层的代码基本上相同。这是因为,Repository 层的 Entity 生命周期有限, Controller 层的 VO 只是单纯作为一种 DTO。两部分的业务逻辑都不会太复杂。业务逻辑 主要集中在 Service 层。所以,Repository 层和 Controller 层继续沿用贫血模型的设计思 路是没有问题的。
接口鉴权需求的OOA、OOD、OOP
背景
参与开发一个微服务。微服务通过 HTTP 协议暴露接口给其他系统调用,设计实现一个接口调用鉴权功能,只有经过认证之后的系统才能调用我们的接口,没有认证过的系统调用我们的接口会被拒绝。
你的问题:
- 需求不明确:不管是需求分析还是面向对象分析,我们首先要做的都是将笼统的需求细化到足够清晰、可执行。我们需要通过沟通、挖掘、分析、假设、梳理,搞清楚具体的需求有哪些,哪些是现在要做的,哪些是未来可能要做的,哪些是不用考虑做的。
- 缺少锻炼:鉴权作为一个跟具体业务无关的功能,我们完全可以把它开发成一个独立的框架,集成到很多业务系统中。
面向对象分析:就是需求分析
面向对象分析的产出是详细的需求描述。需求分析的过程实际上是一个不断迭代优化的过程。我们不要试图一下就能给出一个完美的 解决方案,而是先给出一个粗糙的、基础的方案,有一个迭代的基础,然后再慢慢优化,这 样一个思考过程能让我们摆脱无从下手的窘境。
- 第一轮基础分析:最简单的解决方案就是,通过用户名加密码来做认证。请求时候携带过来校验
- 第二轮分析优化:每次都要传输明文或者加密之后的密码。密码很容易被截获,是不安全的。
- 最终分析:调用方进行接口请求的时候,将 URL、AppID、密码、时间戳拼接在一起,通过加密算法生成 token,并且将 token、AppID、时间戳拼接在 URL 中,一并发送到微服务端。微服务端在接收到调用方的接口请求之后,从请求中拆解出 token、AppID、时间戳。微服务端首先检查传递过来的时间戳跟当前时间,是否在 token 失效时间窗口内。如果 已经超过失效时间,那就算接口调用鉴权失败,拒绝接口调用请求。如果 token 验证没有过期失效,微服务端再从自己的存储中,取出 AppID 对应的密 码,通过同样的 token 生成算法,生成另外一个 token,与调用方传递过来的 token 进 行匹配;如果一致,则鉴权成功,允许接口调用,否则就拒绝接口调用。
面向对象设计
面向对象设计的产出就是类。
1. 划分职责进而识别出有哪些类
那就是根据需求描述,把其中涉及的功能点,一个一个 罗列出来,然后再去看哪些功能点职责相近,操作同样的属性,可否应该归为同一个类。
- 把 URL、AppID、密码、时间戳拼接为一个字符串;
- 对字符串通过加密算法加密生成 token;
- 将 token、AppID、时间戳拼接到 URL 中,形成新的 URL;
- 解析 URL,得到 token、AppID、时间戳等信息;
- 从存储中取出 AppID 和对应的密码;
- 根据时间戳判断 token 是否过期失效;
- 验证两个 token 是否匹配;
1、2、6、7 都是跟 token 有关,负责 token 的生成、 验证;
3、4 都是在处理 URL,负责 URL 的拼接、解析;
5 是操作 AppID 和密码,负责从 存储中读取 AppID 和密码。
所以,我们可以粗略地得到三个核心的类:AuthToken、 Url、CredentialStorage。AuthToken 负责实现 1、2、6、7 这四个操作;Url 负责 3、4 两个操作;CredentialStorage 负责 5 这个操作。
如果实际中的需求比这个复杂,一般需要先划分模块,之后在模块内部再切分需求做面向对象的设计。
2. 定义类及其属性和方法
AuthToken类:
- 把 URL、AppID、密码、时间戳拼接为一个字符串;
- 对字符串通过加密算法加密生成 token;
- 根据时间戳判断 token 是否过期失效;
- 验证两个 token 是否匹配;
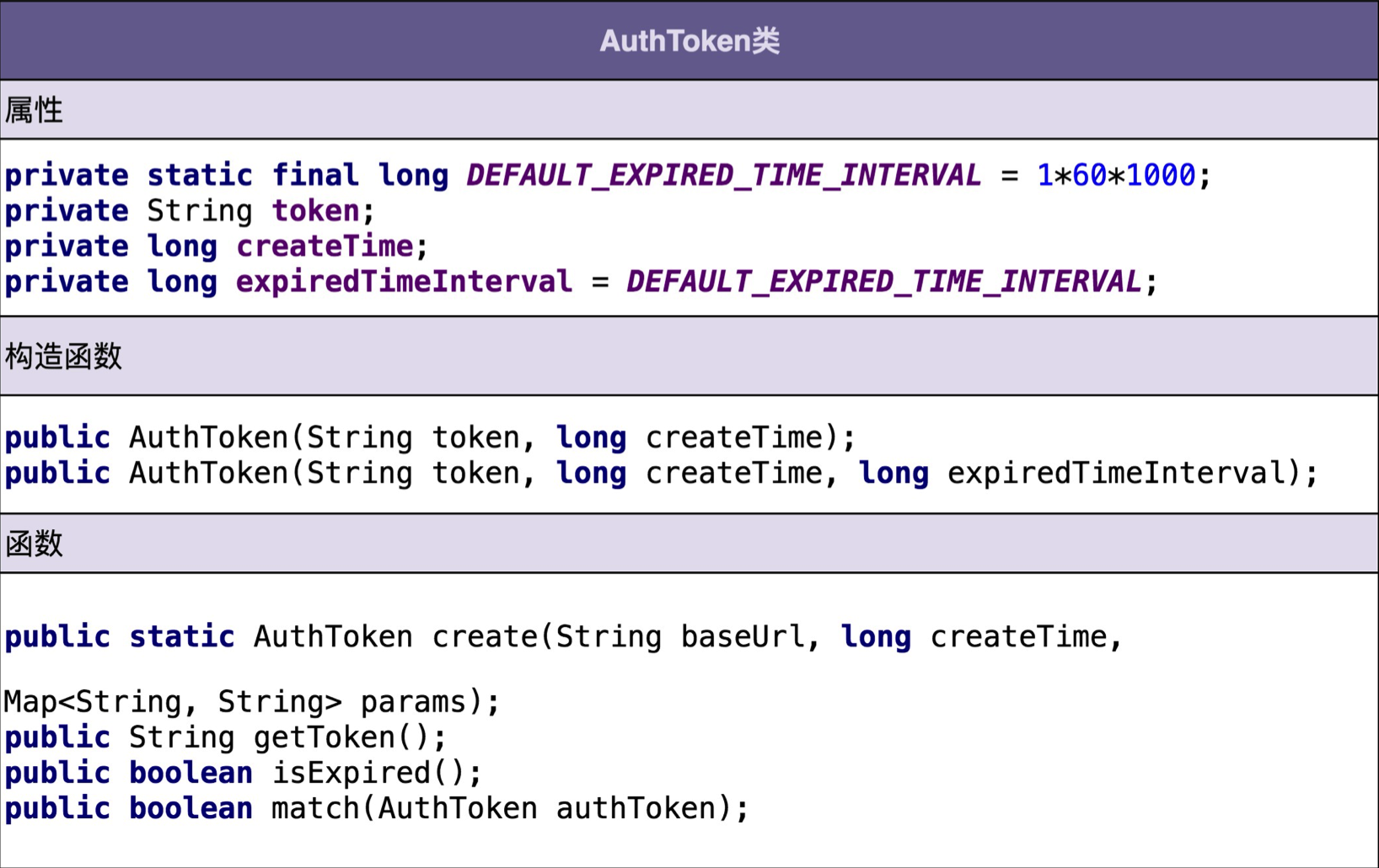
从业务模型上来说,不应该属于这个类的属性和方法,不应该被放到这个类里。比如 URL、AppID 这些信息,从业务模型上来说,不应该属于 AuthToken, 所以我们不应该放到这个类中。
在设计类具有哪些属性和方法的时候,不能单纯地依赖当下的 需求,还要分析这个类从业务模型上来讲,理应具有哪些属性和方法。这样可以一方面保证 类定义的完整性,另一方面不仅为当下的需求还为未来的需求做些准备。
URL 类
- 将 token、AppID、时间戳拼接到 URL 中,形成新的 URL;
- 解析 URL,得到 token、AppID、时间戳等信息;
接口请求并不一定是以 URL 的形式来表达,还有可能是 dubbo RPC 等其他形式。为了让这个类更加通用,命名更加贴切,我们接下来把它命名为 ApiRequest。
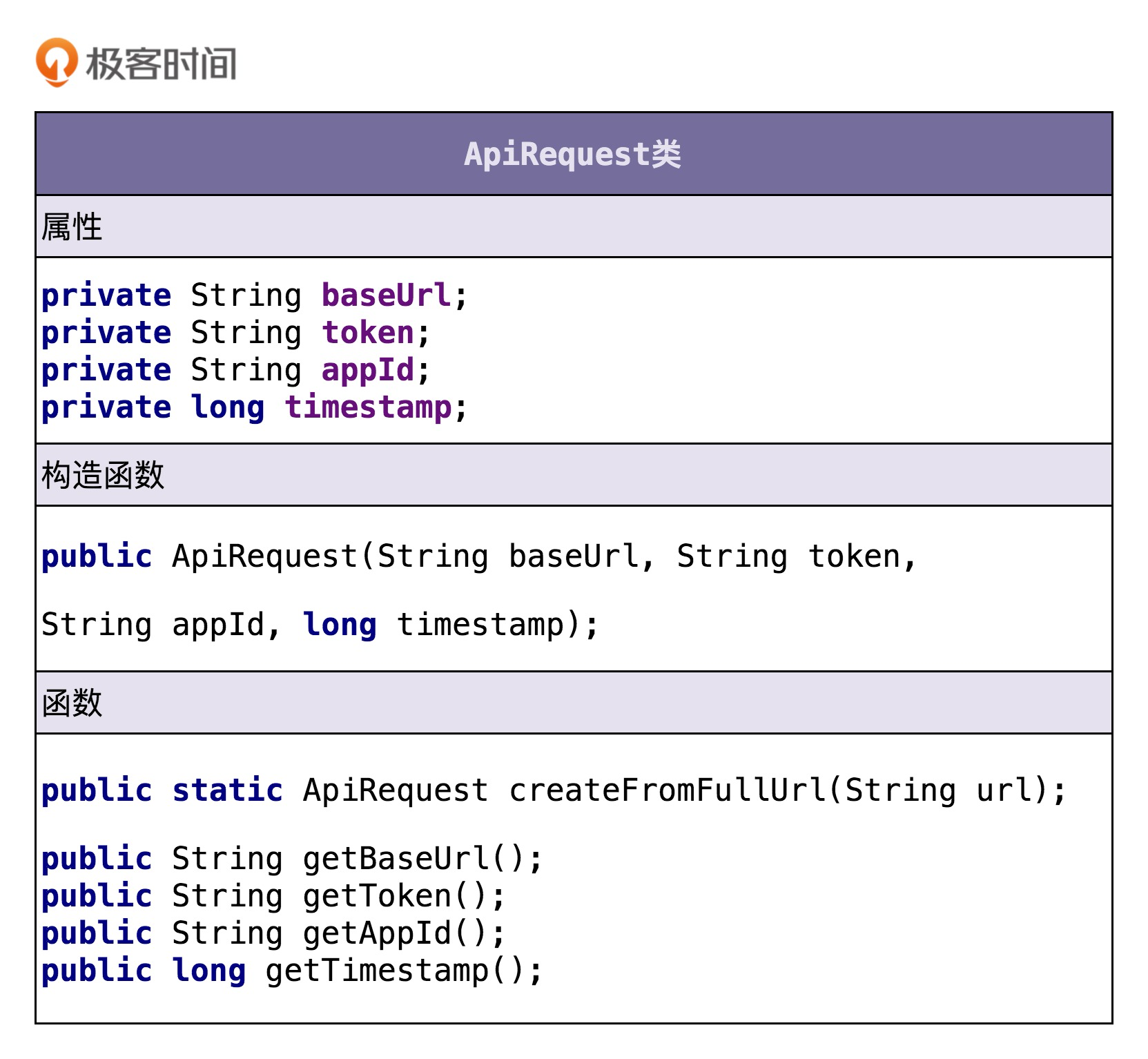
CredentialStorage 类
从存储中取出 AppID 和对应的密码。简单 就一个方法
3. 定义类与类之间的交互关系
UML 中有:泛化、实现、关联、聚合、组合、依赖。
- 泛化(Generalization)可以简单理解为继承关系。
- 实现(Realization)一般是指接口和实现类之间的关系。
- 聚合(Aggregation)是一种包含关系,A 类对象包含 B 类对象,B 类对象的生命周期可 以不依赖 A 类对象的生命周期,也就是说可以单独销毁 A 类对象而不影响 B 对象,比如课 程与学生之间的关系。

- 组合(Composition)也是一种包含关系。A 类对象包含 B 类对象,B 类对象的生命周期 跟依赖 A 类对象的生命周期,B 类对象不可单独存在,比如鸟与翅膀之间的关系。

- 关联(Association)是一种非常弱的关系,包含聚合、组合两种关系。具体到代码层面, 如果 B 类对象是 A 类的成员变量,那 B 类和 A 类就是关联关系。
- 依赖(Dependency)是一种比关联关系更加弱的关系,包含关联关系。不管是 B 类对象 是 A 类对象的成员变量,还是 A 类的方法使用 B 类对象作为参数或者返回值、局部变量, 只要 B 类对象和 A 类对象有任何使用关系,我们都称它们有依赖关系。
实现关系,也即 CredentialStorage 和 MysqlCredentialStorage 之间的关系。组装类的时候会用到依赖关 系、组合关系,但是泛化关系暂时没有用到。
4. 将类组装起来并提供执行入口
接口鉴权并不是一个独立运行的系统,而是一个集成在系统上运行的组件,所以,我们封装 所有的实现细节,设计了一个最顶层的 ApiAuthencator 接口类,暴露一组给外部调用者 使用的 API 接口,作为触发执行鉴权逻辑的入口。

面向对象实现
public interface ApiAuthencator {
void auth(String url);
void auth(ApiRequest apiRequest);
}
public class DefaultApiAuthencatorImpl implements ApiAuthencator {
private CredentialStorage credentialStorage;
public ApiAuthencator() { this.credentialStorage = new MysqlCredentialStorage(); }
public ApiAuthencator(CredentialStorage credentialStorage) {
this.credentialStorage = credentialStorage;
}
@Override
public void auth(String url) {
ApiRequest apiRequest = ApiRequest.buildFromUrl(url);
auth(apiRequest);
}
@Override
public void auth(ApiRequest apiRequest) {
String appId = apiRequest.getAppId();
String token = apiRequest.getToken();
long timestamp = apiRequest.getTimestamp();
String originalUrl = apiRequest.getOriginalUrl();
AuthToken clientAuthToken = new AuthToken(token, timestamp);
if (clientAuthToken.isExpired()) { throw new RuntimeException("Token is expired."); }
String password = credentialStorage.getPasswordByAppId(appId);
AuthToken serverAuthToken = AuthToken.generate(originalUrl, appId, password);
if (!serverAuthToken.match(clientAuthToken)) {
throw new RuntimeException("Token verfication failed.");
}
}
}
遵从设计原则的积分兑换系统
背景
积分是一种常见的营销手段,很多产品都会通过它来促进消费、增加用户粘性。积分系统无外乎就两个大的功能点,一个是赚取积分,另一个是消费积分。
针对业务系统的开发,如何做需求分析和设计?
前期的需求沟通分析、中期的代码设计实现、后期的系统上线维护等。
需求分析的开始就是:借鉴、百度、微创新。从零开始一方面这样做很难想全面,另一方面从零开始设计也比较浪费时间。除此之外, 我们还可以通过线框图和用户用例来细化业务流程,挖掘一些比较细节的、不容易想到的功能点。
面向对象设计聚焦在代码层面(主要是针对类),那系统设计就是聚焦在架构层面(主要是针对模块),两者有很多相似之处。很多设计原则和思想不仅仅可以应用到代码设计中,还 能用到架构设计中。实际上,我们可以借鉴面向对象设计的步骤,来做系统设计。
面向对象设计的本质就是把合适的代码放到合适的类中。合理地划分代码可以实现代码的高 内聚、低耦合,类与类之间的交互简单清晰,代码整体结构一目了然。类比面向对象设计, 系统设计实际上就是将合适的功能放到合适的模块中。合理地划分模块也可以做到模块层面 的高内聚、低耦合,架构整洁清晰。在面向对象设计中,类设计好之后,我们需要设计类之 间的交互关系。类比到系统设计,系统职责划分好之后,接下来就是设计系统之间的交互了。
需求分析
- 积分赚取和兑换规则。积分的赚取渠道包括:下订单、每日签到、评论等。积分兑换规则可以是比较通用的。比如,签到送 10 积分。再比如,按照订单总金额的 10% 兑换成积分,也就是 100 块钱的订单可以积累 10 积分。除此之外,积分兑换规则也 可以是比较细化的。比如,不同的店铺、不同的商品,可以设置不同的积分兑换比例。对于积分的有效期,我们可以根据不同渠道,设置不同的有效期。积分到期之后会作废;在 消费积分的时候,优先使用快到期的积分。
- 积分消费和兑换规则。积分的消费渠道包括:抵扣订单金额、兑换优惠券、积分换购、参与活动扣积分等。 我们可以根据不同的消费渠道,设置不同的积分兑换规则。比如,积分换算成消费抵扣金额 的比例是 10%,也就是 10 积分可以抵扣 1 块钱;100 积分可以兑换 15 块钱的优惠券 等。
- 积分及其明细。查询用户的总积分,以及赚取积分和消费积分的历史记录。
系统设计
1. 合理地将功能划分到不同模块
第一种划分方式是:积分赚取渠道及兑换规则、消费渠道及兑换规则的管理和维护(增删改 查),不划分到积分系统中,而是放到更上层的营销系统中。这样积分系统就会变得非常简 单,只需要负责增加积分、减少积分、查询积分、查询积分明细等这几个工作。
第二种划分方式是:积分赚取渠道及兑换规则、消费渠道及兑换规则的管理和维护,分散在 各个相关业务系统中,比如订单系统、评论系统、签到系统、换购商城、优惠券系统等。还 是刚刚那个下订单赚取积分的例子,在这种情况下,用户下订单成功之后,订单系统根据商 品对应的积分兑换比例,计算所能兑换的积分数量,然后直接调用积分系统给用户增加积 分。
第三种划分方式是:所有的功能都划分到积分系统中,包括积分赚取渠道及兑换规则、消费 渠道及兑换规则的管理和维护。还是同样的例子,用户下订单成功之后,订单系统直接告知 积分系统订单交易成功,积分系统根据订单信息查询积分兑换规则,给用户增加积分。
为了避免业务知识的耦合,让下层系统更加通用,一般来讲,我们不希望下层系 统(也就是被调用的系统)包含太多上层系统(也就是调用系统)的业务信息,但是,可以接受上层系统包含下层系统的业务信息。比如,订单系统、优惠券系统、换购商城等作为调 用积分系统的上层系统,可以包含一些积分相关的业务信息。但是,反过来,积分系统中最 好不要包含太多跟订单、优惠券、换购等相关的信息。所以,综合考虑,我们更倾向于第一种和第二种模块划分方式。积分系统所负责的工作是一样的,只包含积分的增、减、查询,以及积分明细的记 录和查询。
2. 设计模块与模块之间的交互关系
比较常见的系统之间的交互方式有两种,一种是同步接口调用,另一种是利用消息中间件异 步调用。第一种方式简单直接,第二种方式的解耦效果更好。
用户下订单成功之后,订单系统推送一条消息到消息中间件,营销系统订阅订单成功消息息,触发执行相应的积分兑换逻辑。这样订单系统就跟营销系统完全解耦,订单系统不需 要知道任何跟积分相关的逻辑,而营销系统也不需要直接跟订单系统交互。 除此之外,上下层系统之间的调用倾向于通过同步接口,同层之间的调用倾向于异步消息调 用。比如,营销系统和积分系统是上下层关系,它们之间就比较推荐使用同步接口调用。
3. 设计模块的接口、数据库、业务模型
业务系统本身的设计无外乎有这样三方面的工作要做:接口设计、数据库设计和业务模型设计。接口和数据库的时候,一定要多花点心思和时间,切不可过于随意。但是业务逻辑代码侧重内部实现,不涉及被外部依赖的接口,也不包含持久化的数据,所以对改动的容忍性更大。
- 数据库设计,只需要一张记录积分流水明细的表。
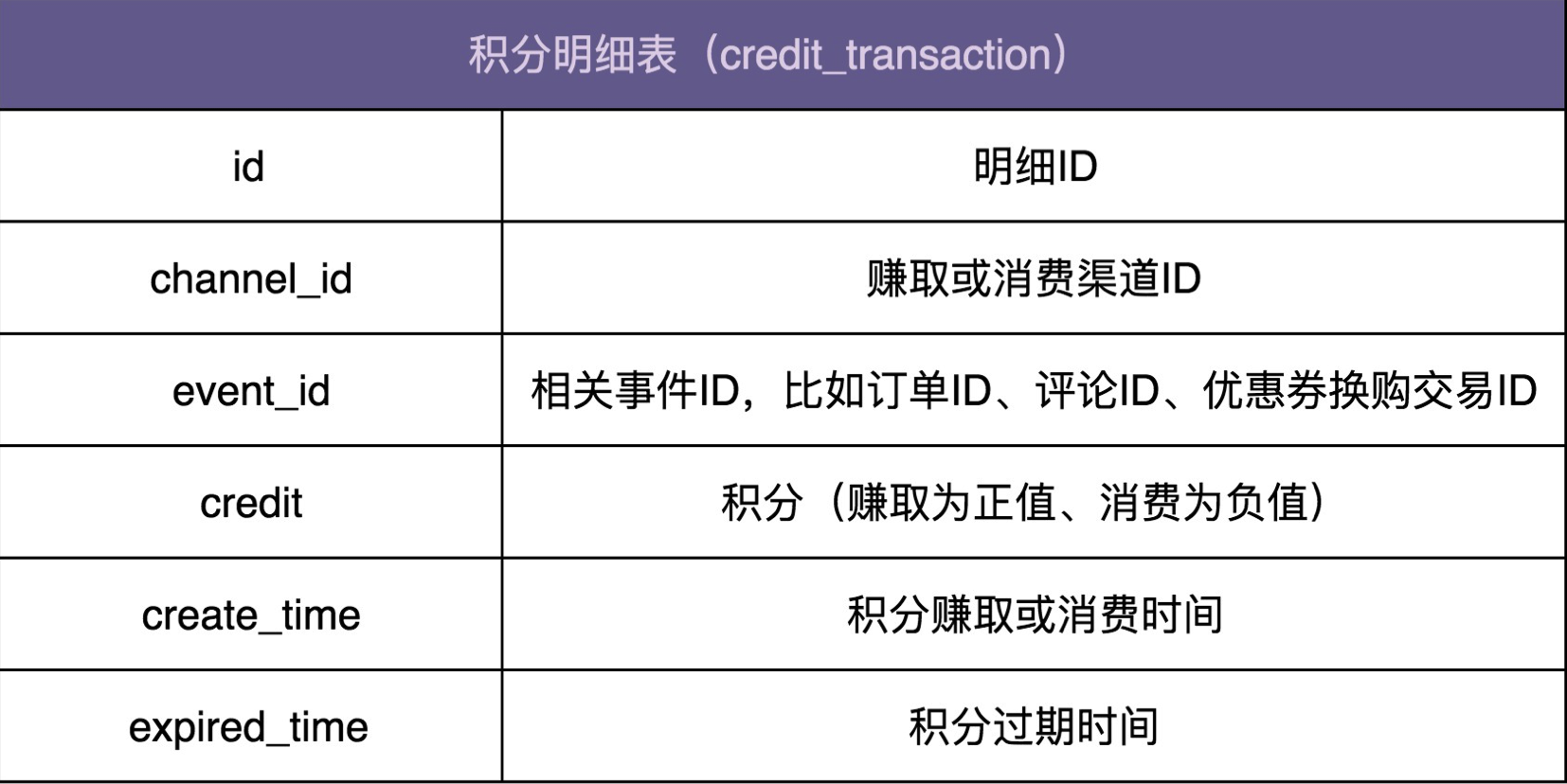
- 设计积分系统的接口,接口设计要符合单一职责原则,粒度越小通用性就越好。为了兼顾易用性和性能,我们可以借鉴 facade(外观)设计模式,在职责单一的细粒度接口之上,再封装一层粗粒度的接口给外部使用。
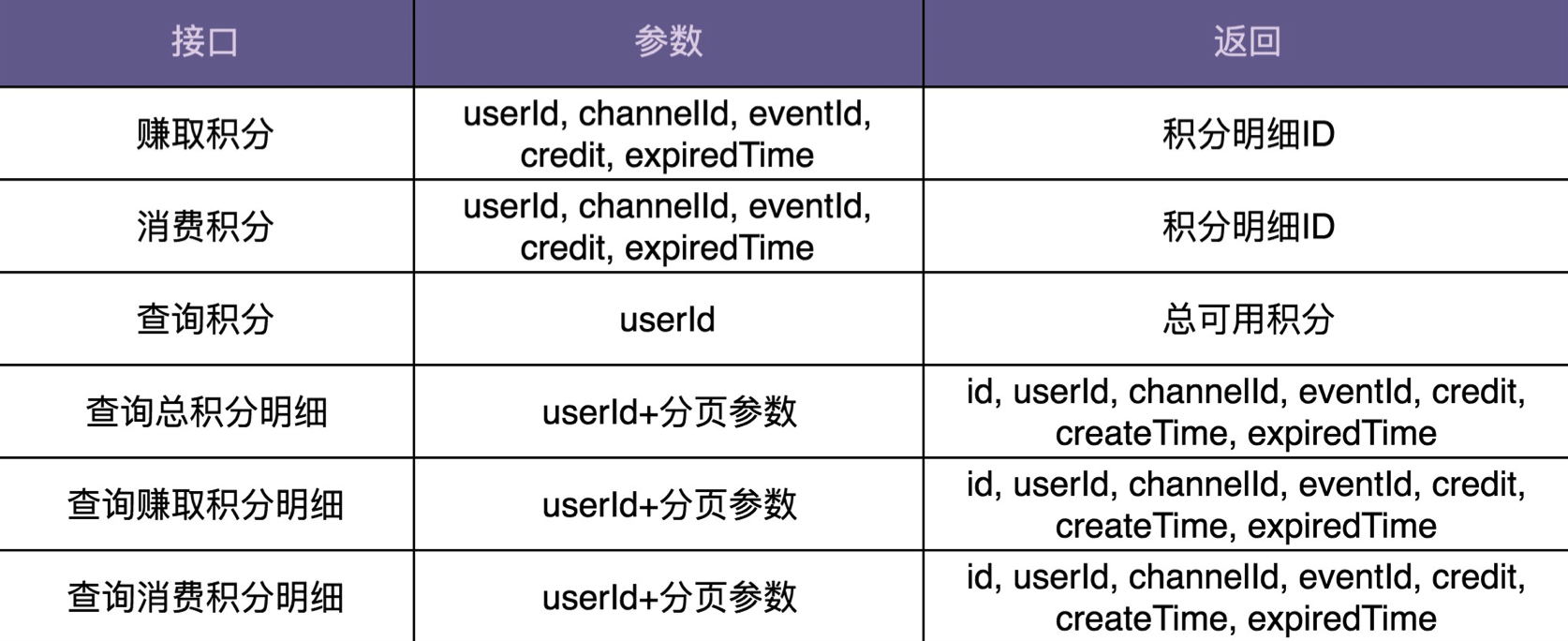
- 业务模型的设计,不管是 DDD 还是 OOP,高级开发模式的存在一般都是为了应对复杂系统,应对系统的复杂性。对于我们要开发的积分系统来说,因为业务相对比较简单,所以,选择简单的基于贫血模型的传统开发模式就足够了。
- 积分系统业务比较简单,代码量也不多,我更倾向于将它跟营销系统放到一个项目 中开发部署。只要我们做好代码的模块化和解耦,让积分相关的业务代码跟其他业务代码之 间边界清晰,没有太多耦合,后期如果需要将它拆分成独立的项目来开发部署,那也并不困难。
为什么要分 MVC 三层来开发?
- 代码复用
- 隔离变化,Service 不关心 Repository 的实现、
- 隔离关注点,每一层只关注自己的职责。Repository 层只关注数据的读写。Service 层只关注业务逻辑,不关注数据的来源。 Controller 层只关注与外界打交道,数据校验、封装、格式转换,并不关心业务逻辑。
- 提高代码的可测试性。单元测试不依赖不可控的外部组件,比如数据库。Repsitory 层的代码通过依赖注入的方式供 Service 层使用,当要测试包含核心业 务逻辑的 Service 层代码的时候,我们可以用 mock 的数据源替代真实的数据库,注入到 Service 层代码中。
- 应对系统的复杂性。水平方向基于业务来做拆分,就是模块化;垂直方向基于 流程来做拆分,就是这里说的分层。不管是分层、模块化,还是 OOP、DDD,以及各种设计模式、原则和思想, 都是为了应对复杂系统,应对系统的复杂性。
为什么要针对每层定义不同的数据对象?
VO(View Object)、BO(Business Object)、Entity, 例如 UserVo、UserBo、UserEntity。并非完全一样。比如,我们可以在 UserEntity、UserBo 中定义 Password 字段,但显然不能在 UserVo 中定义 Password 字段,否则就会将用户的密码暴露出去。虽然代码重复,但功能语义不重复,从职责上讲是不一样的。
支持各种统计规则的性能计数器
背景
设计开发一个小的框架,能够获取接口调用的各种统计信息,比如,响应时间的最 大值(max)、最小值(min)、平均值(avg)、百分位值(percentile)、接口调用次 数(count)、频率(tps) 等,并且支持将统计结果以各种显示格式(比如:JSON 格 式、网页格式、自定义显示格式等)输出到各种终端(Console 命令行、HTTP 网页、 Email、日志文件、自定义输出终端等),以方便查看。
针对非业务系统的开发,如何做需求分析和设计?
作为可被复用的框架,除了功能性需求之外,非功能性需求也非常重要。
1.功能性需求分析
- 接口统计信息:包括接口响应时间的统计信息,以及接口调用次数的统计信息等。
- 统计信息的类型:max、min、avg、percentile、count、tps 等。
- 统计信息显示格式:Json、Html、自定义显示格式。
- 统计信息显示终端:Console、Email、HTTP 网页、日志、自定义显示终端。
统计触发方式:包括主动和被动两种。主动表示以一定的频率定时统计数据,并主动推送到显示终端,比如邮件推送。被动表示用户触发统计,比如用户在网页中选择要统计的时间区间,触发统计,并将结果显示给用户。
统计时间区间:框架需要支持自定义统计时间区间,比如统计最近 10 分钟的某接口的 tps、访问次数,或者统计 12 月 11 日 00 点到 12 月 12 日 00 点之间某接口响应时间 的最大值、最小值、平均值等。
统计时间间隔:对于主动触发统计,我们还要支持指定统计时间间隔,也就是多久触发 一次统计显示。比如,每间隔 10s 统计一次接口信息并显示到命令行中,每间隔 24 小时发送一封统计信息邮件。
2. 非功能性需求分析
- 框架是否易集成、易插拔、跟业务代码是否松耦合、提供的接口是否够灵活
- 性能
- 扩展性
- 容错性
设计
稍微复杂系统的开发,很多人觉得不知从何开始。借鉴 TDD(测试驱动开 发)和 Prototype(最小原型)的思想,先聚焦于一个简单的应用场景,基于此设计实现一个简单的原型。是迭代设计的基础。
这就好比做算法题目。当我们想要一下子就想出一个最优解法时,可以先写几组测试数据, 找找规律,再先想一个最简单的算法去解决它。虽然这个最简单的算法在时间、空间复杂度上可能都不令人满意,但是我们可以基于此来做优化,这样思路就会更加顺畅。
对于性能计数器这个框架的开发来说,我们可以先聚焦于一个非常具体、简单的应用场景, 比如统计用户注册、登录这两个接口的响应时间的最大值和平均值、接口调用次数,并且将 统计结果以 JSON 的格式输出到命令行中。现在这个需求简单、具体、明确,设计实现起 来难度降低了很多。
最小原型的代码实现:
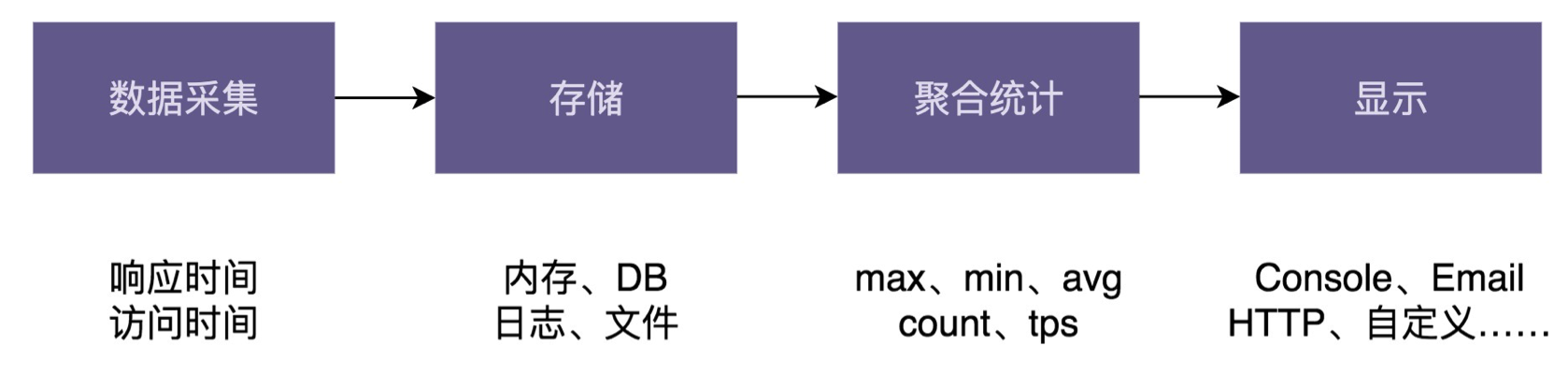
最小原型实现
recordResponseTime() 和 recordTimestamp() 两 个函数分别用来记录接口请求的响应时间和访问时间。startRepeatedReport() 函数以指定 的频率统计数据并输出结果。
// 统计工具类
public class Metrics {
// Map的key是接口名称,value对应接口请求的响应时间或时间戳;
private Map<String, List<Double>> responseTimes = new HashMap<>();
private Map<String, List<Double>> timestamps = new HashMap<>();
//定时器线程池
private ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();
/**
* 记录接口的响应时间
*/
public void recordResponseTime(String apiName, double responseTime) {
responseTimes.putIfAbsent(apiName, new ArrayList<>());
responseTimes.get(apiName).add(responseTime);
}
/**
* 记录接口的调用时间戳
*/
public void recordTimestamp(String apiName, double timestamp) {
timestamps.putIfAbsent(apiName, new ArrayList<>());
timestamps.get(apiName).add(timestamp);
}
public void startRepeatedReport(long period, TimeUnit unit) {
executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
Gson gson = new Gson();
Map<String, Map<String, Double>> stats = new HashMap<>();
for (Map.Entry<String, List<Double>> entry : responseTimes.entrySet()) {
String apiName = entry.getKey();
List<Double> apiRespTimes = entry.getValue();
stats.putIfAbsent(apiName, new HashMap<>());
stats.get(apiName).put("max", max(apiRespTimes));
stats.get(apiName).put("avg", avg(apiRespTimes));
}
for (Map.Entry<String, List<Double>> entry : timestamps.entrySet()) {
String apiName = entry.getKey();
List<Double> apiTimestamps = entry.getValue();
stats.putIfAbsent(apiName, new HashMap<>());
stats.get(apiName).put("count", (double) apiTimestamps.size());
}
System.out.println(gson.toJson(stats));
}
}, 0, period, unit);
}
/**
* 计算某接口的一组响应时间集合里最大响应时间
*/
private double max(List<Double> dataset) {
//省略代码实现}
return 0;
}
/**
* 计算某接口的一组响应时间集合里平均响应时间
*/
private double avg(List<Double> dataset) {
//省略代码实现
return 0;
}
}
// 数据采集
//应用场景:统计下面两个接口(注册和登录)的响应时间和访问次数
public class UserController {
private Metrics metrics = new Metrics();
public UserController() {
//60秒执行一次统计线程
metrics.startRepeatedReport(60, TimeUnit.SECONDS);
}
public void register(UserVo user) {
long startTimestamp = System.currentTimeMillis();
metrics.recordTimestamp("regsiter", startTimestamp);
//...
long respTime = System.currentTimeMillis() - startTimestamp;
metrics.recordResponseTime("register", respTime);
}
public UserVo login(String telephone, String password) {
long startTimestamp = System.currentTimeMillis();
metrics.recordTimestamp("login", startTimestamp);
//...
long respTime = System.currentTimeMillis() - startTimestamp;
metrics.recordResponseTime("login", respTime);
return null;
}
}
实现优化:代码解耦
第一个版本可以先实现一些基本功能,对于更高级、更复杂的功能,以及非功能性需求不做过高 的要求,在后续的 v2.0、v3.0……版本中继续迭代优化。
最小原型的实现,所有的代码都耦合在一个类中,这显然是不合理的。
- 根据需求描述,划分职责大致识别出下面几个接口或类:
- MetricsCollector 类负责提供 API,来采集接口请求的原始数据。
- MetricsStorage 接口负责原始数据存储,RedisMetricsStorage 类实现 MetricsStorage 接口。这样做是为了今后灵活地扩展新的存储方法
- Aggregator 类负责根据原始数据计算统计数据。
- ConsoleReporter 类、EmailReporter 类分别负责以一定频率统计并发送统计数据到命令行和邮件。
- 定义类及类与类之间的关系
/**
* 数据采集接口
*/
public class MetricsCollector {
//基于接口而非实现编程
private IMetricsStorage metricsStorage;
//依赖注入
public MetricsCollector(IMetricsStorage metricsStorage) {
this.metricsStorage = metricsStorage;
}
public void recordRequest(RequestInfo requestInfo) {
if (requestInfo == null || StringUtils.isBlank(requestInfo.getApiName())) {
return;
}
metricsStorage.saveRequestInfo(requestInfo);
}
}
/**
* 封装采集数据的原始信息
*/
@Data
public class RequestInfo {
private String apiName;
private double responseTime;
private long timestamp;
public RequestInfo(String apiName, double responseTime, long timestamp) {
this.apiName = apiName;
this.responseTime = responseTime;
this.timestamp = timestamp;
}
}
/**
* 数据存储接口,实现方式可能有内存、redis、数据库、文件等
*/
public interface IMetricsStorage {
void saveRequestInfo(RequestInfo requestInfo);
List<RequestInfo> getRequestInfos(String apiName, long startTime, long endTime);
Map<String, List<RequestInfo>> getRequestInfos(long startTime, long endTime);
}
/**
* redis的方式实现数据存储
*/
public class RedisMetricsStorage implements IMetricsStorage {
@Override
public void saveRequestInfo(RequestInfo requestInfo) {}
@Override
public List<RequestInfo> getRequestInfos(String apiName, long startTime, long endTime) {return null;}
@Override
public Map<String, List<RequestInfo>> getRequestInfos(long startTime, long endTime) {return null;}
}
/**
* 负责将原始数据计算得到统计数据
当需要扩展新的统计功能的时候,需要修改 aggregate() 函数代码,职责不单一 ,不易扩展
*/
public class Aggregator {
/**
* @param requestInfos
* @param durationInMillis 多少时间内,比如10分钟内
* @return
*/
public static RequestStat aggregate(List<RequestInfo> requestInfos, long durationInMillis) {
double maxRespTime = Double.MIN_VALUE;
double minRespTime = Double.MAX_VALUE;
double avgRespTime = -1;
double p999RespTime = -1;
double p99RespTime = -1;
double sumRespTime = 0;
long count = 0;
//计算最大值、最小值、总响应时间
for (RequestInfo requestInfo : requestInfos) {
++count;
double respTime = requestInfo.getResponseTime();
if (maxRespTime < respTime) {
maxRespTime = respTime;
}
if (minRespTime > respTime) {
minRespTime = respTime;
}
sumRespTime += respTime;
}
//计算平均时间
if (count != 0) {
avgRespTime = sumRespTime / count;
}
long tps = (long) (count / durationInMillis * 1000);
//将requestInfos里的元素按响应时间从小到大排序
Collections.sort(requestInfos, new Comparator<RequestInfo>() {
@Override
public int compare(RequestInfo o1, RequestInfo o2) {
double diff = o1.getResponseTime() - o2.getResponseTime();
if (diff < 0.0) {
return -1;
} else if (diff > 0.0) {
return 1;
} else {
return 0;
}
}
});
//获取所有响应时间里 10%、99%的响应时间在哪个区间
int idx999 = (int) (count * 0.999);
int idx99 = (int) (count * 0.99);
if (count != 0) {
p999RespTime = requestInfos.get(idx999).getResponseTime();
p99RespTime = requestInfos.get(idx99).getResponseTime();
}
RequestStat requestStat = new RequestStat();
requestStat.setMaxResponseTime(maxRespTime);
requestStat.setMinResponseTime(minRespTime);
requestStat.setAvgResponseTime(avgRespTime);
requestStat.setP999ResponseTime(p999RespTime);
requestStat.setP99ResponseTime(p99RespTime);
requestStat.setCount(count);
requestStat.setTps(tps);
return requestStat;
}
}
@Data
public class RequestStat {
private double maxResponseTime;
private double minResponseTime;
private double avgResponseTime;
private double p999ResponseTime;
private double p99ResponseTime;
private long count;
private long tps;
}
/**
* ConsoleReporter 类相当于一个上帝类,定时根据给定的时间区间,从数据库中取出数据,借助 Aggregator 类完成统计工作,并将统计结果输出到命令行。
*/
public class ConsoleReporter {
private IMetricsStorage metricsStorage;
private ScheduledExecutorService executor;
public ConsoleReporter(IMetricsStorage metricsStorage) {
this.metricsStorage = metricsStorage;
this.executor = Executors.newSingleThreadScheduledExecutor();
}
/**
* @param periodInSeconds
* @param durationInSeconds 统计多少秒之内的数据
*/
public void startRepeatedReport(long periodInSeconds, final long durationInSeconds) {
executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
// 第1个代码逻辑:根据给定的时间区间,从数据库中拉取数据;
long durationInMillis = durationInSeconds * 1000;
long endTimeInMillis = System.currentTimeMillis();
long startTimeInMillis = endTimeInMillis - durationInMillis;
Map<String, List<RequestInfo>> requestInfos = metricsStorage.
getRequestInfos(startTimeInMillis, endTimeInMillis);
Map<String, RequestStat> stats = new HashMap<>();
for (Map.Entry<String, List<RequestInfo>> entry : requestInfos.entrySet()) {
// 第2个代码逻辑:根据原始数据,计算得到统计数据;
RequestStat requestStat = Aggregator.aggregate(entry.getValue(), durationInSeconds);
stats.put(entry.getKey(), requestStat);
}
// 第3个代码逻辑:将统计数据显示到终端(命令行或邮件);
System.out.println("Time Span: [" + startTimeInMillis + ", " + endTimeInMillis + "]");
Gson gson = new Gson();
System.out.println(gson.toJson(stats));
}
}, 0, periodInSeconds, TimeUnit.SECONDS);
}
}
public class EmailReporter {
private static final Long DAY_HOURS_IN_SECONDS = 86400L;
private IMetricsStorage metricsStorage;
private EmailSender emailSender;
private List<String> toAddresses = new ArrayList<String>();
public EmailReporter(IMetricsStorage metricsStorage) {
this(metricsStorage, new EmailSender(/*省略参数*/));
}
public EmailReporter(IMetricsStorage metricsStorage, EmailSender emailSender) {
this.metricsStorage = metricsStorage;
this.emailSender = emailSender;
}
public void addToAddress(String address) {
toAddresses.add(address);
}
public void startDailyReport() {
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.DATE, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
Date firstTime = calendar.getTime();
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
long durationInMillis = DAY_HOURS_IN_SECONDS * 1000;
long endTimeInMillis = System.currentTimeMillis();
long startTimeInMillis = endTimeInMillis - durationInMillis;
Map<String, List<RequestInfo>> requestInfos = metricsStorage.getRequestInfos(startTimeInMillis, endTimeInMillis);
Map<String, RequestStat> stats = new HashMap<>();
for (Map.Entry<String, List<RequestInfo>> entry : requestInfos.entrySet()) {
String apiName = entry.getKey();
List<RequestInfo> requestInfosPerApi = entry.getValue();
RequestStat requestStat = Aggregator.aggregate(requestInfosPerApi, durationInMillis);
stats.put(apiName, requestStat);
}
// TODO: 格式化为html格式,并且发送邮件
}
}, firstTime, DAY_HOURS_IN_SECONDS * 1000);
}
}
// 数据采集,将类组装起来并提供执行入口
/**
* 将类组装起来并提供执行入口.
* 因为这个框架稍微有些特殊,有两个执行入口:一个是 MetricsCollector 类,提供了一组 API 来采集原始数据;另一个是 ConsoleReporter 类和 EmailReporter 类,
* 用来触发统计显示。框架具体的使用方式如下所示:
*/
public class Demo {
public static void main(String[] args) {
IMetricsStorage storage = new RedisMetricsStorage();
ConsoleReporter consoleReporter = new ConsoleReporter(storage);
consoleReporter.startRepeatedReport(60, 60);
EmailReporter emailReporter = new EmailReporter(storage);
emailReporter.addToAddress("wangzheng@xzg.com");
emailReporter.startDailyReport();
MetricsCollector collector = new MetricsCollector(storage);
collector.recordRequest(new RequestInfo("register", 123, 10234));
collector.recordRequest(new RequestInfo("register", 223, 11234));
collector.recordRequest(new RequestInfo("register", 323, 12334));
collector.recordRequest(new RequestInfo("login", 23, 12434));
collector.recordRequest(new RequestInfo("login", 1223, 14234));
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
大致地识别出几个核心的类之后,我的习惯性做法是,先在 IDE 中创建好这几个类,然后 开始试着定义它们的属性和方法。在设计类、类与类之间交互的时候,我会不断地用之前学 过的设计原则和思想来审视设计是否合理,比如,是否满足单一职责原则、开闭原则、依赖 注入、KISS 原则、DRY 原则、迪米特法则,是否符合基于接口而非实现编程思想,代码是 否高内聚、低耦合,是否可以抽象出可复用代码等等。 MetricsCollector 类的定义非常简单,具体代码如下所示。对比上一节课中最小原型的代 码,MetricsCollector 通过引入 RequestInfo 类来封装原始数据信息,用一个采集函数代 替了之前的两个函数。
实现优化:分解上帝类
Aggregator 类里面只有一个静态函数,有 50 行左右的代码量,负责各种统计数据的计 算。当要添加新的统计功能的时候,我们需要修改 aggregate() 函数代码。一旦越来越多 的统计功能添加进来之后,这个函数的代码量会持续增加,可读性、可维护性就变差了。
ConsoleReporter 和 EmailReporter 两个类中存在代码重复问题。在这两个类中,从数据 库中取数据、做统计的逻辑都是相同的,可以抽取出来复用,否则就违反了 DRY 原则。
/**
* 负责将原始数据计算得到统计数据
*/
public class Aggregator {
public Map<String, RequestStat> aggregate(Map<String, List<RequestInfo>> requestInfos, long durationInSeconds) {
Map<String, RequestStat> stats = new HashMap<>();
for (Map.Entry<String, List<RequestInfo>> entry : requestInfos.entrySet()) {
// 第2个代码逻辑:根据原始数据,计算得到统计数据;
RequestStat requestStat = this.doAggregate(entry.getValue(), durationInSeconds);
stats.put(entry.getKey(), requestStat);
}
return stats;
}
/**
* 这个方法的重构还是有点东西的,对比u026的未重构前的doAggregate
*
* @param requestInfos
* @param durationInMillis 多少时间内,比如10分钟内
* @return
*/
public RequestStat doAggregate(List<RequestInfo> requestInfos, long durationInMillis) {
//为啥还要循环再封装成List<Double> respTimes呢?直接把List<RequestInfo> requestInfos 传进各个函数不就好了?
List<Double> respTimes = new ArrayList<>();
for (RequestInfo requestInfo : requestInfos) {
respTimes.add(requestInfo.getResponseTime());
}
RequestStat requestStat = new RequestStat();
requestStat.setMaxResponseTime(max(respTimes));
requestStat.setMinResponseTime(min(respTimes));
requestStat.setAvgResponseTime(avg(respTimes));
requestStat.setP999ResponseTime(percentile999(respTimes));
requestStat.setP99ResponseTime(percentile99(respTimes));
requestStat.setCount(respTimes.size());
requestStat.setTps((long) tps(respTimes.size(), durationInMillis / 1000));
return requestStat;
}
// 以下的函数的代码实现均省略...
private double max(List<Double> dataset) {
return 0;
}
private double min(List<Double> dataset) {
return 0;
}
private double avg(List<Double> dataset) {
return 0;
}
private double tps(int count, double duration) {
return 0;
}
private double percentile999(List<Double> dataset) {
return 0;
}
private double percentile99(List<Double> dataset) {
return 0;
}
private double percentile(List<Double> dataset, double ratio) {
return 0;
}
}
/**
* 第 3 个逻辑:将统计数据显示到终端。我们将这部分逻辑剥离出来,设计成一个接口
*/
public interface StatViewer {
void output(Map<String, RequestStat> requestStats, long startTimeInMillis, long endTimeInMills);
}
public class ConsoleViewer implements StatViewer {
@Override
public void output(Map<String, RequestStat> requestStats, long startTimeInMillis, long endTimeInMills) {
System.out.println("Time Span: [" + startTimeInMillis + ", " + endTimeInMills + "]");
Gson gson = new Gson();
System.out.println(gson.toJson(requestStats));
}
}
public class EmailViewer implements StatViewer {
private EmailSender emailSender;
private List toAddresses = new ArrayList<>();
public EmailViewer() {
this.emailSender = new EmailSender(/*省略参数*/);
}
public EmailViewer(EmailSender emailSender) {
this.emailSender = emailSender;
}
public void addToAddress(String address) {
toAddresses.add(address);
}
@Override
public void output(Map requestStats, long startTimeInMillis, long endTimeInMills) {
// format the requestStats to HTML style.
// send it to email toAddresses.
}
}
public class ConsoleReporter {
private IMetricsStorage metricsStorage;
private ScheduledExecutorService executor;
private Aggregator aggregator;
private StatViewer viewer;
public ConsoleReporter(IMetricsStorage metricsStorage, Aggregator aggregator, StatViewer viewer) {
this.metricsStorage = metricsStorage;
this.aggregator = aggregator;
this.viewer = viewer;
this.executor = Executors.newSingleThreadScheduledExecutor();
}
/**
* @param periodInSeconds
* @param durationInSeconds 统计多少秒之内的数据
*/
public void startRepeatedReport(long periodInSeconds, final long durationInSeconds) {
executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
// 第1个代码逻辑:根据给定的时间区间,从数据库中拉取数据;
long durationInMillis = durationInSeconds * 1000;
long endTimeInMillis = System.currentTimeMillis();
long startTimeInMillis = endTimeInMillis - durationInMillis;
Map<String, List<RequestInfo>> requestInfos = metricsStorage.getRequestInfos(startTimeInMillis, endTimeInMillis);
// 第2个代码逻辑:根据原始数据,计算得到统计数据;
Map<String, RequestStat> stats = aggregator.aggregate(requestInfos, durationInSeconds);
// 第3个代码逻辑:将统计数据显示到终端(命令行或邮件);
viewer.output(stats, startTimeInMillis, endTimeInMillis);
}
}, 0, periodInSeconds, TimeUnit.SECONDS);
}
}
public class EmailReporter {
private static final Long DAY_HOURS_IN_SECONDS = 86400L;
private IMetricsStorage metricsStorage;
private Aggregator aggregator;
private StatViewer statViewer;
private EmailSender emailSender;
private List<String> toAddresses = new ArrayList<String>();
public EmailReporter(IMetricsStorage metricsStorage, Aggregator aggregator, StatViewer statViewer) {
this.metricsStorage = metricsStorage;
this.statViewer = statViewer;
this.aggregator = aggregator;
this.emailSender = new EmailSender(/*省略参数*/);
}
public void addToAddress(String address) {
toAddresses.add(address);
}
public void startDailyReport() {
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.DATE, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
Date firstTime = calendar.getTime();
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
// 第1个代码逻辑:根据给定的时间区间,从数据库中拉取数据;
long durationInMillis = DAY_HOURS_IN_SECONDS * 1000;
long endTimeInMillis = System.currentTimeMillis();
long startTimeInMillis = endTimeInMillis - durationInMillis;
Map<String, List<RequestInfo>> requestInfos = metricsStorage.getRequestInfos(startTimeInMillis, endTimeInMillis);
// 第2个代码逻辑:根据原始数据,计算得到统计数据;
Map<String, RequestStat> stats = aggregator.aggregate(requestInfos, DAY_HOURS_IN_SECONDS);
// 第3个代码逻辑:将统计数据显示到终端(命令行或邮件);
statViewer.output(stats, startTimeInMillis, endTimeInMillis);
}
}, firstTime, DAY_HOURS_IN_SECONDS * 1000);
}
}
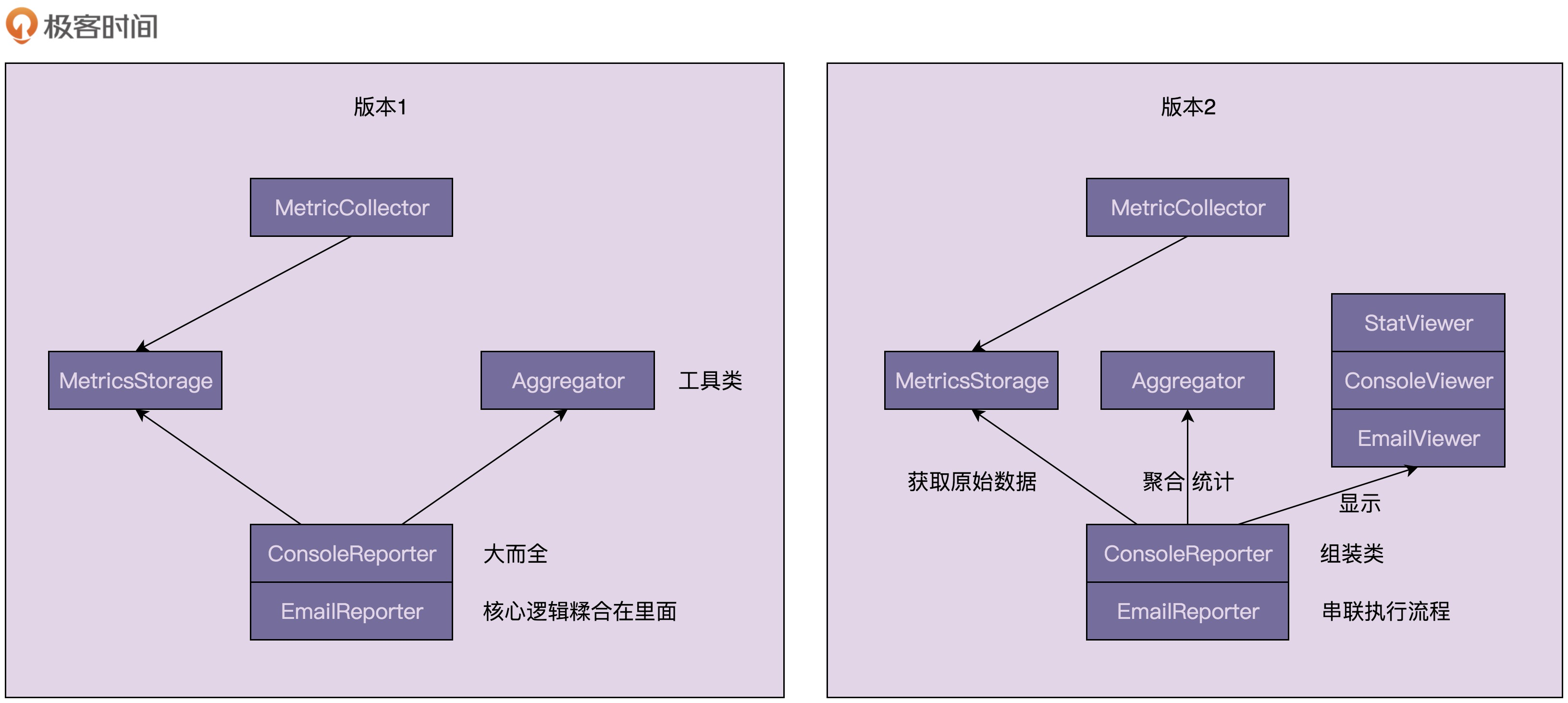
- 数据采集:负责打点采集原始数据,包括记录每次接口请求的响应时间和请求时间。
- 存储:负责将采集的原始数据保存下来,以便之后做聚合统计。数据的存储方式有很多 种,我们暂时只支持 Redis 这一种存储方式,并且,采集与存储两个过程同步执行。
- 聚合统计:负责将原始数据聚合为统计数据,包括响应时间的最大值、最小值、平均 值、99.9 百分位值、99 百分位值,以及接口请求的次数和 tps。
- 显示:负责将统计数据以某种格式显示到终端,暂时只支持主动推送给命令行和邮件。 命令行间隔 n 秒统计显示上 m 秒的数据(比如,间隔 60s 统计上 60s 的数据)。邮件 每日统计上日的数据。
重构优化
ConsoleReporter 和 EmailReporter 经过重构之后,代码的重复问题变小了,但仍然没有 完全解决。尽管这两个类不再调用 Aggregator 的静态方法,但因为涉及多线程和时间相 关的计算,代码的测试性仍然不够好。将 ConsoleReporter 和 EmailReporter 中的相同代码逻辑,提取到父类 ScheduledReporter 中,以解决代码重复问题。
public abstract class ScheduledReporter {
private static final long MAX_STAT_DURATION_IN_MILLIS = 10 * 60 * 1000; // 10minutes,一次性最多取到内存中的数据量,防止撑爆内存
// 因为涉及到子类,这里不能用private了
protected IMetricsStorage metricsStorage;
protected Aggregator aggregator;
protected StatViewer viewer;
public ScheduledReporter(IMetricsStorage metricsStorage, Aggregator aggregator, StatViewer viewer) {
this.metricsStorage = metricsStorage;
this.aggregator = aggregator;
this.viewer = viewer;
}
/**
* 当统计的时间间隔较大的时候,需要统计的数据量就会比较大。我们可以将其划分为一些小的时间区间(比如 10 分钟作为一个统计单元),针对每个小的时间区间分别进行统计,
* 然后将统计得到的结果再进行聚合,得到最终整个时间区间的统计结果。
*/
protected void doStatAndReport(long startTimeInMillis, long endTimeInMillis) {
Map<String, RequestStat> stats = doStat(startTimeInMillis, endTimeInMillis);
viewer.output(stats, startTimeInMillis, endTimeInMillis);
}
private Map<String, RequestStat> doStat(long startTimeInMillis, long endTimeInMillis) {
Map<String, List<RequestStat>> segmentStats = new HashMap<>();
long segmentStartTimeMillis = startTimeInMillis;
while (segmentStartTimeMillis < endTimeInMillis) {
long segmentEndTimeMillis = segmentStartTimeMillis + MAX_STAT_DURATION_IN_MILLIS;
if (segmentEndTimeMillis > endTimeInMillis) {
segmentEndTimeMillis = endTimeInMillis;
}
Map<String, List<RequestInfo>> requestInfos = metricsStorage.getRequestInfos(segmentStartTimeMillis, segmentEndTimeMillis);
if (requestInfos == null || requestInfos.isEmpty()) {
continue;
}
//这段时间的数据已经统计好了
Map<String, RequestStat> segmentStat = aggregator.aggregate(requestInfos, segmentEndTimeMillis - segmentStartTimeMillis);
addStat(segmentStats, segmentStat);
segmentStartTimeMillis += MAX_STAT_DURATION_IN_MILLIS;
}
long durationInMillis = endTimeInMillis - startTimeInMillis;
Map<String, RequestStat> aggregatedStats = aggregateStats(segmentStats, durationInMillis);
return aggregatedStats;
}
private void addStat(Map<String, List<RequestStat>> segmentStats, Map<String, RequestStat> segmentStat) {
for (Map.Entry<String, RequestStat> entry : segmentStat.entrySet()) {
String apiName = entry.getKey();
RequestStat stat = entry.getValue();
List<RequestStat> statList = segmentStats.putIfAbsent(apiName, new ArrayList<>());
statList.add(stat);
}
}
/**
* 还要将一段段时间的统计数据再进行一次求出最大数/最小数/平均数等,好像有点蛋疼吧
*/
private Map<String, RequestStat> aggregateStats(Map<String, List<RequestStat>> segmentStats, long durationInMillis) {
Map<String, RequestStat> aggregatedStats = new HashMap<>();
for (Map.Entry<String, List<RequestStat>> entry : segmentStats.entrySet()) {
String apiName = entry.getKey();
List<RequestStat> apiStats = entry.getValue();
double maxRespTime = Double.MIN_VALUE;
double minRespTime = Double.MAX_VALUE;
long count = 0;
double sumRespTime = 0;
for (RequestStat stat : apiStats) {
if (stat.getMaxResponseTime() > maxRespTime) maxRespTime = stat.getMaxResponseTime();
if (stat.getMinResponseTime() < minRespTime) minRespTime = stat.getMinResponseTime();
count += stat.getCount();
sumRespTime += (stat.getCount() * stat.getAvgResponseTime());
}
RequestStat aggregatedStat = new RequestStat();
aggregatedStat.setMaxResponseTime(maxRespTime);
aggregatedStat.setMinResponseTime(minRespTime);
aggregatedStat.setAvgResponseTime(sumRespTime / count);
aggregatedStat.setCount(count);
aggregatedStat.setTps(count / durationInMillis * 1000);
aggregatedStats.put(apiName, aggregatedStat);
}
return aggregatedStats;
}
}
import com.google.common.annotations.VisibleForTesting;
import java.util.*;
public class EmailReporter extends ScheduledReporter {
private static final Long DAY_HOURS_IN_SECONDS = 86400L;
private EmailSender emailSender;
private List<String> toAddresses = new ArrayList<String>();
// 兼顾代码的易用性,新增一个封装了默认依赖的构造函数
public EmailReporter() {
this(new RedisMetricsStorage(), new Aggregator(), new EmailViewer());
}
// 兼顾灵活性和代码的可测试性,这个构造函数继续保留
public EmailReporter(IMetricsStorage metricsStorage, Aggregator aggregator, StatViewer statViewer) {
super(metricsStorage, aggregator, statViewer);
this.emailSender = new EmailSender(/*省略参数*/);
}
public void addToAddress(String address) {
toAddresses.add(address);
}
public void startDailyReport() {
//获取当前时间的下一天的 0 点时间
Date firstTime = trimTimeFieldsToZeroOfNextDay(new Date());
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
// 第1个代码逻辑:根据给定的时间区间,从数据库中拉取数据;
long durationInMillis = DAY_HOURS_IN_SECONDS * 1000;
long endTimeInMillis = System.currentTimeMillis();
long startTimeInMillis = endTimeInMillis - durationInMillis;
doStatAndReport(startTimeInMillis, endTimeInMillis);
}
}, firstTime, DAY_HOURS_IN_SECONDS * 1000);
}
// 设置成protected而非private是为了方便写单元测试
@VisibleForTesting
protected Date trimTimeFieldsToZeroOfNextDay(Date date) {
Calendar calendar = Calendar.getInstance();
calendar.setTime(date); //重新设置时间,为什么要重新设置呢?完全是为了提高代码的可测试性
calendar.add(Calendar.DATE, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
return calendar.getTime();
}
}
ID生成器优化
背景
/**
* 整个 ID 由三部分组成。第一部分是本机名的最后一个字段。第二部分是当前时间戳,精确到毫秒。第三部分是 8 位的随机字符串,包含大小写字母和数字。尽管这样生成的 ID 并不是绝对唯一的,有重复的可能,但事实上重复的概率非常低。
*
* 例如:
*
103-1577456311467-3nR3Do45
103-1577456311468-0wnuV5yw
103-1577456311468-sdrnkFxN
103-1577456311468-8lwk0BP0
1、整段代码还可以抽取最小函数出来,比如hostName的生成、随机8位字符串的生成。
2、一些魔数可以用常量替换,比如几位随机字符串。
3、整个代码可测试性不好,比如测试hostName、随机数生成,这点可以跟第一点一起解决。
4、没有注释,可阅读性很差,比如随机8位字符串生成的代码为何要这样写。
*/
public class IdGenerator {
private static final Logger logger = LoggerFactory.getLogger(IdGenerator.class);
public static String generate() {
String id = "";
try {
String hostName = InetAddress.getLocalHost().getHostName();
String[] tokens = hostName.split("\\.");
if (tokens.length > 0) {
hostName = tokens[tokens.length - 1];
}
char[] randomChars = new char[8];
int count = 0;
Random random = new Random();
while (count < 8) {
int randomAscii = random.nextInt(122);
if (randomAscii >= 48 && randomAscii <= 57) {
randomChars[count] = (char)('0' + (randomAscii - 48));
count++;
} else if (randomAscii >= 65 && randomAscii <= 90) {
randomChars[count] = (char)('A' + (randomAscii - 65));
count++;
} else if (randomAscii >= 97 && randomAscii <= 122) {
randomChars[count] = (char)('a' + (randomAscii - 97));
count++;
}
}
id = String.format("%s-%d-%s", hostName,
System.currentTimeMillis(), new String(randomChars));
} catch (UnknownHostException e) {
logger.warn("Failed to get the host name.", e);
}
return id;
}
}
分析
自问清单
第一轮重构:提高代码的可读性
我们抽象出两个接口,一个是 IdGenerator,一个是 LogTraceIdGenerator,LogTraceIdGenerator 继承 IdGenerator。实现类实现接口 IdGenerator,命名为 RandomIdGenerator、SequenceIdGenerator 等。
第二轮重构:提高代码的可测试性
generateRandomAlphameric() 和 getLastSubstrSplittedByDot() 这两个函数的访 问权限设置为 protected。这样做的目的是,可以直接在单元测试中通过对象来调用两 个函数进行测试。
@VisibleForTesting。这个 annotation 没有任何实际 的作用,只起到标识的作用,告诉其他人说,这两个函数本该是 private 访问权限的, 之所以提升访问权限到 protected,只是为了测试,只能用于单元测试中。
第三轮重构:编写完善的单元测试
第四轮重构:所有重构完成之后添加注释
public interface IdGenerator {
String generator();
}
public interface LogTraceIdGenerator extends IdGenerator {
}
/**
* ID generator that is userd to generate random IDs.
* The IDs generated by this class are not absolutely unique,
* but the probability of duplication is very low.
*/
public class RandomIdGenerator implements LogTraceIdGenerator {
private static final Logger logger = LoggerFactory.getLogger(IdGenerator.class);
/**
* Generate the random ID,The IDs may be duplicated only in extreme situation.
*
* @return an random ID
*/
public String generator() {
String id = "";
String substrOfHostName = getLastfieldOfHostName();
String randomString = generateRandomAlphameric(8);
id = String.format("%s-%d-%s", substrOfHostName,
System.currentTimeMillis(), randomString);
return id;
}
/**
* 生成合适的随机字符串
* Generate random string with
* only contains digits,uppercase letters and lowercase letters.
*
* @param length should not be less than 0
* @return return the random string .Returns empty string if {@length} is 0.
*/
@VisibleForTesting
public String generateRandomAlphameric(int length) {
char[] randomChars = new char[length];
int count = 0;
Random random = new Random();
while (count < length) {
int maxAscii = 'z';
int randomAscii = random.nextInt(maxAscii);
//换种写法去掉多余的if
boolean isDigit = randomAscii >= '0' && randomAscii <= '9';
boolean isUppercase = randomAscii >= 'A' && randomAscii <= 'Z';
boolean isLowercase = randomAscii >= 'a' && randomAscii <= 'z';
if (isDigit || isUppercase || isLowercase) {
randomChars[count] = (char) (randomAscii);
++count;
}
}
return new String(randomChars);
}
/**
* 从 getLastfieldOfHostName() 函数中,将逻辑比较复杂的那部分代码剥离出来,定义为 getLastSubstrSplittedByDot() 函数。
* 因为 getLastfieldOfHostName() 函数依赖本地主机名,所以,剥离出主要代码之后这个函数变得非常简单,可以不用测试。
* 我们重点测试 getLastSubstrSplittedByDot() 函数即可。
*
* @return
* @throws UnknownHostException
*/
private String getLastfieldOfHostName() {
String substrOfHostName = null;
try {
String hostName = InetAddress.getLocalHost().getHostName();
substrOfHostName = getLastSubstrSplittedByDot(hostName);
} catch (UnknownHostException e) {
logger.warn("Failed to get the host name.", e);
}
return substrOfHostName;
}
/**
* Get the last field of {@hostName} splitted by delemiter '.'
*
* @param hostName should not be null
* @return the last field of {@hostName}.Returns empty string if {@hostName} is empty string
*/
@VisibleForTesting
public String getLastSubstrSplittedByDot(String hostName) {
String[] tokens = hostName.split("\\.");
//因为substrOfHostName和hostName有不同的语义功能,所以这里不能重用hostName
String substrOfHostName = hostName;
if (tokens.length > 0) {
substrOfHostName = tokens[tokens.length - 1];
}
return substrOfHostName;
}
}
//代码使用举例
LogTraceIdGenerator logTraceIdGenerator = new RandomIdGenerator();
函数出错应该返回啥?
- 返回错误码:C 语言没有异常这样的语法机制,返回错误码便是最常用的出错处理方式。而 Java、 Python 等比较新的编程语言中,大部分情况下,我们都用异常来处理函数出错的情况,极 少会用到错误码。
- 返回 NULL 值:对于查找函数来说,数据 不存在并非一种异常情况,是一种正常行为,所以返回表示不存在语义的 NULL 值比返回 异常更加合理。
- 返回空对象当函数返回的数据是字符串类型或者集合类型的时候,我们可以用空字符串或空集合替代 NULL 值,来表示不存在的情况。这样,我们在使用函数的时候,就可以不用做 NULL 值判断。
- 抛出异常对象。对于函数抛出的异常,我们有三种处理方法:直接吞掉、直接往上抛出、包裹成新的异常抛出。
第五轮重构:处理异常
public class IdGenerationFailureException extends RuntimeException {
String tips;
public IdGenerationFailureException(String tips) {
this.tips = tips;
}
}
/**
* ID generator that is userd to generate random IDs.
* The IDs generated by this class are not absolutely unique,
* but the probability of duplication is very low.
*/
public class RandomIdGenerator implements LogTraceIdGenerator {
private static final Logger logger = LoggerFactory.getLogger(IdGenerator.class);
/**
* Generate the random ID,The IDs may be duplicated only in extreme situation.
*
* @return an random ID
*/
public String generator() throws IdGenerationFailureException {
String substrOfHostName = null;
try {
substrOfHostName = getLastfieldOfHostName();
} catch (UnknownHostException e) {
throw new IdGenerationFailureException("host name is empty.");
}
String randomString = generateRandomAlphameric(8);
String id = String.format("%s-%d-%s", substrOfHostName,
System.currentTimeMillis(), randomString);
return id;
}
/**
* 生成合适的随机字符串
* Generate random string with
* only contains digits,uppercase letters and lowercase letters.
*
* @param length should not be less than 0
* @return return the random string .Returns empty string if {@length} is 0.
*/
@VisibleForTesting
public String generateRandomAlphameric(int length) {
if (length <= 0) {
throw new IllegalArgumentException("...");
}
char[] randomChars = new char[length];
int count = 0;
Random random = new Random();
while (count < length) {
int maxAscii = 'z';
int randomAscii = random.nextInt(maxAscii);
//换种写法去掉多余的if
boolean isDigit = randomAscii >= '0' && randomAscii <= '9';
boolean isUppercase = randomAscii >= 'A' && randomAscii <= 'Z';
boolean isLowercase = randomAscii >= 'a' && randomAscii <= 'z';
if (isDigit || isUppercase || isLowercase) {
randomChars[count] = (char) (randomAscii);
++count;
}
}
return new String(randomChars);
}
/**
* 从 getLastfieldOfHostName() 函数中,将逻辑比较复杂的那部分代码剥离出来,定义为 getLastSubstrSplittedByDot() 函数。
* 因为 getLastfieldOfHostName() 函数依赖本地主机名,所以,剥离出主要代码之后这个函数变得非常简单,可以不用测试。
* 我们重点测试 getLastSubstrSplittedByDot() 函数即可。
*
* @return
* @throws UnknownHostException
*/
private String getLastfieldOfHostName() throws UnknownHostException {
String substrOfHostName = null;
String hostName = InetAddress.getLocalHost().getHostName();
if (hostName == null || hostName.isEmpty()) { // 此处做判断
throw new UnknownHostException("...");
}
substrOfHostName = getLastSubstrSplittedByDot(hostName);
return substrOfHostName;
}
/**
* Get the last field of {@hostName} splitted by delemiter '.'
*
* @param hostName should not be null
* @return the last field of {@hostName}.Returns empty string if {@hostName} is empty string
*/
@VisibleForTesting
public String getLastSubstrSplittedByDot(String hostName) {
if (hostName == null || hostName.isEmpty()) {
//运行时异常
throw new IllegalArgumentException("...");
}
String[] tokens = hostName.split("\\.");
//因为substrOfHostName和hostName有不同的语义功能,所以这里不能重用hostName
String substrOfHostName = hostName;
if (tokens.length > 0) {
substrOfHostName = tokens[tokens.length - 1];
}
return substrOfHostName;
}
}
支持各种算法的限流框架
背景
对于公共服务平台来说,接口请求来自很多不同的系统(后面统称为调用方),因为调用方代码 bug 、不正确地使用服务(比如启动 Job 来调用接口获取数据)、业务上面的突发流量 (比如促销活动),导致来自某个调用方的接口请求数突增,过度争用服务的线程资源,而 来自其他调用方的接口请求,因此来不及响应而排队等待,导致接口请求的响应时间大幅增 加,甚至出现超时。
开发接口限流功能,限制每个调用方对接口请求的频率。当超过预先设定的访问频 率后,我们就触发限流熔断,比如,限制调用方 app-1 对公共服务平台总的接口请求频率 不超过 1000 次 / 秒,超过之后的接口请求都会被决绝。还希望能对单独某个 接口的访问频率进行限制,比如,限制 app-1 对接口 /user/query 的访问频率为每秒钟不 超过 100 次。
分析
画线框图、写用户用例、测试驱动开发等等。针对这个场景写一个框架使用的 Demo 程序。
功能性
- 在集成了限流框架的应用启动的时候, 限流框架会将限流规则,按照事先定义的语法,解析并加载到内存中。
- 接收到接口请求之后,应用会将请求发送给限流框架,限流框架会告诉应用,这个接口请 求是允许继续处理,还是触发限流熔断。
从使用的角度来说,限流框架主要包含两部分功能:配置限流规则和 提供编程接口(RateLimiter 类)验证请求是否被限流。
非功能性
对于限流框架,非功能性需求:易用性、扩展性、灵活性,希望能够灵活地扩展各种限流算法。同时,我们还希望支持不同 格式(JSON、YAML、XML 等格式)、不同数据源(本地文件配置或 Zookeeper 集中配 置等)的限流规则的配置方式。性能方面,因为每个接口请求都要被检查是否限流,这或多或少会增加接口请求的响应时 间。而对于响应时间比较敏感的接口服务来说,我们要让限流框架尽可能低延迟,尽可能减 少对接口请求本身响应时间的影响。容错性方面,接入限流框架是为了提高系统的可用性、稳定性,不能因为限流框架的异常, 反过来影响到服务本身的可用性。所以,限流框架要有高度的容错性。比如,分布式限流算 法依赖集中存储器 Redis。如果 Redis 挂掉了,限流逻辑无法正常运行,这个时候业务接 口也要能正常服务才行。
设计
限流规则
- 时间粒度
- 过大的时间粒度会达不到限流的效果。
- 过小的时间粒度,会误杀很多本不应该限流的请求。所以,尽管越细的时间粒度限流整形效果越好,流量曲线越平滑,但也并不是时间粒度越小越合适。
- 最小惊奇原则:支持 XML、YAML、Properties 等几种配 置文件格式,同时,约定默认的配置文件名为 ratelimiter-rule.yaml,默认放置在 classpath 路径中。
- 兼容从其他数据源获取配置的方式,比如 Zookeeper 或者自研的配置中心。
限流算法
常见的限流算法有:固定时间窗口限流算法、滑动时间窗口限流算法、令牌桶限流算法、漏 桶限流算法。
限流模式
限流模式分为两种:单机限流和分布式限流。所谓单机限流,就是针对单个实例的访问频率进行限制,注意有可能一台物理机器部署多个实例。所谓的分布式限流,就是针对某个服务的多个实例的总的访问频率进行限制。单机限 流只需要在单个实例中维护自己的接口请求计数器。而分布式限流需要集中管理计数器(比 如使用 Redis 存储接口访问计数)。
因为分布式限流基于外部存储 Redis,网络通信成本较高,框架的高容错和 低延迟的设计,主要是针对基于 Redis 的分布式限流模式。不能因为 Redis 的异常,影响 到集成框架的应用的可用性和稳定性。不能因为 Redis 访问超时,导致接口访问超时。
集成使用
开发一个 Ratelimiter-Spring 类库,能够方便使用了 Spring 的项目集成限流框架,将易用性做到极 致。
最小原型实现
在 V1 版本中,对于接口类型,我们只支持 HTTP 接口(也就 URL)的限流,暂时不支持 RPC 等其他类型的接口限流。对于限流规则,我们只支持本地文件配置,配置文件格式只 支持 YAML。对于限流算法,我们只支持固定时间窗口算法。对于限流模式,我们只支持 单机限流。
划分职责识别类、定义属性和方法、定义类之间的交互关系、组装类并 提供执行入口。
串联整个限流流程。它先读取限流规则配置文件,映射为内存中的 Java 对象(RuleConfig),然后再将这个中间结构构建成一个支持快速查询的数据结构(RateLimitRule)。除此之外,这个类还提供供用户直接使用的最顶层接口(limit() 接口)。
public class RateLimiter {
private static final Logger log = LoggerFactory.getLogger(RateLimiter.class);
// 为每个api在内存中存储限流计数器
private ConcurrentHashMap<String, RateLimitAlg> counters = new ConcurrentHashMap<>();
private RateLimitRule rule;
public RateLimiter() {
// 将限流规则配置文件ratelimiter-rule.yaml中的内容读取到RuleConfig中
InputStream in = null;
RuleConfig ruleConfig = null;
try {
in = this.getClass().getResourceAsStream("/ratelimiter-rule.yaml");
if (in != null) {
Yaml yaml = new Yaml();
ruleConfig = yaml.loadAs(in, RuleConfig.class);
}
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
log.error("close file error:{}", e);
}
}
}
// 将限流规则构建成支持快速查找的数据结构RateLimitRule
this.rule = new RateLimitRule(ruleConfig);
}
public boolean limit(String appId, String url) throws InternalErrorException {
ApiLimit apiLimit = rule.getLimit(appId, url);
if (apiLimit == null) {
return true;
}
// 获取api对应在内存中的限流计数器(rateLimitCounter)
String counterKey = appId + ":" + apiLimit.getApi();
RateLimitAlg rateLimitCounter = counters.get(counterKey);
if (rateLimitCounter == null) {
RateLimitAlg newRateLimitCounter = new RateLimitAlg(apiLimit.getLimit());
rateLimitCounter = counters.putIfAbsent(counterKey, newRateLimitCounter);
if (rateLimitCounter == null) {
rateLimitCounter = newRateLimitCounter;
}
}
// 判断是否限流
return rateLimitCounter.tryAcquire();
}
}
/**
configs: <!--对应RuleConfig-->
- appId: app-1 <!--对应AppRuleConfig-->
limits:
- api: /v1/user <!--对应ApiLimit-->
limit: 100
unit:60
- api: /v1/order
limit: 50
- appId: app-2
limits:
- api: /v1/user
limit: 50
- api: /v1/order
limit: 50
*/
public class RuleConfig {
private List<AppRuleConfig> configs;
public List<AppRuleConfig> getConfigs() {
return configs;
}
public void setConfigs(List<AppRuleConfig> configs) {
this.configs = configs;
}
public static class AppRuleConfig {
private String appId;
private List<ApiLimit> limits;
public AppRuleConfig() {}
public AppRuleConfig(String appId, List<ApiLimit> limits) {
this.appId = appId;
this.limits = limits;
}
//...省略getter、setter方法...
}
}
public class ApiLimit {
private static final int DEFAULT_TIME_UNIT = 1; // 1 second
private String api;
private int limit;
private int unit = DEFAULT_TIME_UNIT;
public ApiLimit() {}
public ApiLimit(String api, int limit) {
this(api, limit, DEFAULT_TIME_UNIT);
}
public ApiLimit(String api, int limit, int unit) {
this.api = api;
this.limit = limit;
this.unit = unit;
}
// ...省略getter、setter方法...
}
public class RateLimitRule {
public RateLimitRule(RuleConfig ruleConfig) {
//...
}
public ApiLimit getLimit(String appId, String api) {
//...
}
}
public class RateLimitAlg {
/* timeout for {@code Lock.tryLock() }. */
private static final long TRY_LOCK_TIMEOUT = 200L; // 200ms.
private Stopwatch stopwatch;
private AtomicInteger currentCount = new AtomicInteger(0);
private final int limit;
private Lock lock = new ReentrantLock();
public RateLimitAlg(int limit) {
this(limit, Stopwatch.createStarted());
}
@VisibleForTesting
protected RateLimitAlg(int limit, Stopwatch stopwatch) {
this.limit = limit;
this.stopwatch = stopwatch;
}
public boolean tryAcquire() throws InternalErrorException {
int updatedCount = currentCount.incrementAndGet();
if (updatedCount <= limit) {
return true;
}
try {
if (lock.tryLock(TRY_LOCK_TIMEOUT, TimeUnit.MILLISECONDS)) {
try {
if (stopwatch.elapsed(TimeUnit.MILLISECONDS) > TimeUnit.SECONDS.toMillis(1)) {
currentCount.set(0);
stopwatch.reset();
}
updatedCount = currentCount.incrementAndGet();
return updatedCount <= limit;
} finally {
lock.unlock();
}
} else {
throw new InternalErrorException("tryAcquire() wait lock too long:" + TRY_LOCK_TIMEOUT + "ms");
}
} catch (InterruptedException e) {
throw new InternalErrorException("tryAcquire() is interrupted by lock-time-out.", e);
}
}
}
可读性没有太大问题,问题主要在于可扩展性。主要的修改点有两个,一个是将 RateLimiter 中的规则配置文件的读取解析逻辑拆出来,设计成独立的类,另一个是参照基于接口而非实现编程思想,对于 RateLimitRule、RateLimitAlg 类提炼抽象接口。
// 重构前:
com.xzg.ratelimiter
--RateLimiter
com.xzg.ratelimiter.rule
--ApiLimit
--RuleConfig
--RateLimitRule
com.xzg.ratelimiter.alg
--RateLimitAlg
// 重构后:
com.xzg.ratelimiter
--RateLimiter(有所修改)
com.xzg.ratelimiter.rule
--ApiLimit(不变)
--RuleConfig(不变)
--RateLimitRule(抽象接口)
--TrieRateLimitRule(实现类,就是重构前的RateLimitRule)
com.xzg.ratelimiter.rule.parser
--RuleConfigParser(抽象接口)
--YamlRuleConfigParser(Yaml格式配置文件解析类)
--JsonRuleConfigParser(Json格式配置文件解析类)
com.xzg.ratelimiter.rule.datasource
--RuleConfigSource(抽象接口)
--FileRuleConfigSource(基于本地文件的配置类)
com.xzg.ratelimiter.alg
--RateLimitAlg(抽象接口)
--FixedTimeWinRateLimitAlg(实现类,就是重构前的RateLimitAlg)
public class RateLimiter {
private static final Logger log = LoggerFactory.getLogger(RateLimiter.class);
// 为每个api在内存中存储限流计数器
private ConcurrentHashMap<String, RateLimitAlg> counters = new ConcurrentHashMap<>();
private RateLimitRule rule;
public RateLimiter() {
//改动主要在这里:调用RuleConfigSource类来实现配置加载
RuleConfigSource configSource = new FileRuleConfigSource();
RuleConfig ruleConfig = configSource.load();
this.rule = new TrieRateLimitRule(ruleConfig);
}
public boolean limit(String appId, String url) throws InternalErrorException, InvalidUrlException {
//...代码不变...
}
}
com.xzg.ratelimiter.rule.parser
--RuleConfigParser(抽象接口)
--YamlRuleConfigParser(Yaml格式配置文件解析类)
--JsonRuleConfigParser(Json格式配置文件解析类)
com.xzg.ratelimiter.rule.datasource
--RuleConfigSource(抽象接口)
--FileRuleConfigSource(基于本地文件的配置类)
public interface RuleConfigParser {
RuleConfig parse(String configText);
RuleConfig parse(InputStream in);
}
public interface RuleConfigSource {
RuleConfig load();
}
public class FileRuleConfigSource implements RuleConfigSource {
private static final Logger log = LoggerFactory.getLogger(FileRuleConfigSource.class);
public static final String API_LIMIT_CONFIG_NAME = "ratelimiter-rule";
public static final String YAML_EXTENSION = "yaml";
public static final String YML_EXTENSION = "yml";
public static final String JSON_EXTENSION = "json";
private static final String[] SUPPORT_EXTENSIONS =
new String[] {YAML_EXTENSION, YML_EXTENSION, JSON_EXTENSION};
private static final Map<String, RuleConfigParser> PARSER_MAP = new HashMap<>();
static {
PARSER_MAP.put(YAML_EXTENSION, new YamlRuleConfigParser());
PARSER_MAP.put(YML_EXTENSION, new YamlRuleConfigParser());
PARSER_MAP.put(JSON_EXTENSION, new JsonRuleConfigParser());
}
@Override
public RuleConfig load() {
for (String extension : SUPPORT_EXTENSIONS) {
InputStream in = null;
try {
in = this.getClass().getResourceAsStream("/" + getFileNameByExt(extension));
if (in != null) {
RuleConfigParser parser = PARSER_MAP.get(extension);
return parser.parse(in);
}
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
log.error("close file error:{}", e);
}
}
}
}
return null;
}
private String getFileNameByExt(String extension) {
return API_LIMIT_CONFIG_NAME + "." + extension;
}
}
通用的接口幂等框架
背景
接口返回的结果一般包含成功、失败、超时,但是超时的话其实是不同情况不一样的:
- 接口只包含查询、删除、更新这些操作,那接口天然是幂等的,超时重试即可,除非:
- 删除操作需要当心 ABA 问题。删除操作超时了,又触发一次删除。
- update x = x+delta 这样格式的更新操作并非幂等,只有 update x=y 这样格式的更新操作才是幂等的。
- 如果项目中需要支持超时重试的业务比较多,我们最好是把超时重试这些非业务相关的逻辑,统一在框架层面解决。超时重试需要接口幂等的支持。
分析
业务的每一个请求都有一个唯一的标识作为幂等号码。
幂等框架使用流程(功能性需求):
- 接口调用方生成幂等号,并且跟随接口请求,将幂等号传递给接口实现方。
- 接口实现方接收到接口请求之后,按照约定,从 HTTP Header 或者接口参数中,解析出幂等号。
- 通过幂等号查询幂等框架。如果幂等号已经存在,说明业务已经执行或正在执行,则直接返回;如果幂等号 不存在,说明业务没有执行过,则记录幂等号,继续执行业务。
幂等框架的非功能性需求:
- 易用性,只需编写简单的配置以及少许代码,对业务代码低侵入松耦合,在统一的地方(比如 Spring AOP 中)接入幂等框架,而不是将它耦合在业务代码中。
- 性能方面,针对每个幂等接口,尽可能减少对接口请求本身响应时间的影响。
- 容错性方面,跟限流框架相同,不能因为幂等框架本身的异常,导致接口响应异常,影响服务本身的可用性。比如,存储幂等号的外部存储器挂掉了,幂等逻辑无法正常运行,这个时候业务接口也要能正常服务才行。
设计
代码运行异常。不同情况下超时、异常:
- 发送请求失败或者超时,幂等号还没有记录下来,重试请求 会被执行,符合我们的预期。
- 业务逻辑执行完成了,只是在发送 结果给调用方的时候,失败或者超时了,这个时候,幂等号已经记录下来,重试请求不会被 执行,也符合我们的预期。
- 业务代码在执行过程中抛出异常的时候,比较复杂:发生异常(不管是业务异常还是 系统异常),是否允许再重试执行业务逻辑,交给开发这块业务的工程师来决定是最合适的 了,毕竟他最清楚针对每个异常该如何处理。而幂等框架本身不参与这个决定,它只需要提 供删除幂等号的接口,由业务工程师来决定遇到异常的时候,是否需要调用这个删除接口, 删除已经记录的幂等号。
机器宕机,但是幂等号保存了,业务没有执行:
- 建议业务系统记录 SQL 的执行日志,在日志中附加上幂等号。这样我们就能在机器宕机时,根据日志来判断业务执行情况和幂等号的记录是否一致。不一致就删除幂等号,一样就说明业务无需补救。
幂等框架异常:
- 这种情况和限流不一样,不能让业务代码裸奔,会有数据问题、
实现
实现生成幂等号的功能
方式一:集中生成并且分派 给调用方。需要部署一套幂等号的生成系统,并且提供相应的远程接口 (Restful 或者 RPC 接口)
方式二:直接由调用方生成。调用方按照跟接口实现方预先商量好的算法,自己来生成幂等号。执行效率更高。但是,重复开发,违反 DRY 原则。并且较为复杂,不确定性高
综合,由幂等框架来统一提供幂等号生成算法的代码实现,并封装成开发类库,提供给各个调用方复用。
实现存储、查询、删除幂等号的功能
存储直接用Redis。因为没有复杂的关系。
在幂等判重逻辑中,我们需要先检查幂等号是否存在。如果没有存在,再将幂等号存储进 Redis。多个线程会导致插入幂等号业务被重复执行。为了避免这种情况发生,我们要给“检查 - 设置”操作加分布式锁:setnx(key, value)。它先检查 key 是否存在,如果存在,则返 回结果 0;如果不存在,则将 key 值存下来,并将值设置为 value,返回结果 1。因为 Redis 本身是单线程执行命令的,所以不存在并发问题。
最小原型实现
public class Idempotence {
// 灵活性问题:comment-1: 如果要替换存储方式,是不是很麻烦呢?
private JedisCluster jedisCluster;
// comment-2: 如果幂等框架要跟业务系统复用jedisCluster连接呢?
// comment-3: 是不是应该注释说明一下redisClusterAddress的格式,以及config是否可以传递进null呢?
public Idempotence(String redisClusterAddress, GenericObjectPoolConfig config) {
// comment-4: 这段逻辑放到构造函数里,不容易写单元测试
String[] addressArray= redisClusterAddress.split(";");
Set<HostAndPort> redisNodes = new HashSet<>();
for (String address : addressArray) {
String[] hostAndPort = address.split(":");
redisNodes.add(new HostAndPort(hostAndPort[0], Integer.valueOf(hostAndPort[1])));
}
this.jedisCluster = new JedisCluster(redisNodes, config);
}
// 可读性问题:comment-5: generateId()是不是比缩写要好点?
// 接口隔离原则:comment-6: 根据接口隔离原则,这个函数跟其他函数的使用场景完全不同,这个函数主要用在调用方,
// 其他函数用在实现方,是不是应该分别放到两个类中?
public String genId() {
return UUID.randomUUID().toString();
}
// comment-7: 返回值的意义是不是应该注释说明一下?
public boolean saveIfAbsent(String idempotenceId) {
Long success = jedisCluster.setnx(idempotenceId, "1");
return success == 1;
}
public void delete(String idempotenceId) {
jedisCluster.del(idempotenceId);
}
}
重构
- 在代码可读性方面,我们对构造函数、saveIfAbsense() 函数的参数和返回值做了注释,并且将 genId() 函数改为全拼 generateId()。不过,对于这个函数来说,缩写实际上问题也不大。
- 在代码可扩展性方面,我们按照基于接口而非实现的编程原则,将幂等号的读写独立出来,设计成 IdempotenceStorage 接口和 RedisClusterIdempotenceStorage 实现类。RedisClusterIdempotenceStorage 实现了基于 Redis Cluster 的幂等号读写。如果我们需要替换新的幂等号读写方式,比如基于单个 Redis 而非 Redis Cluster,我们就可以再定义一个实现了 IdempotenceStorage 接口的实现类:RedisIdempotenceStorage。除此之外,按照接口隔离原则,我们将生成幂等号的代码抽离出来,放到 IdempotenceIdGenerator 类中。这样,调用方只需要依赖这个类的代码就可以了。幂等号生成算法的修改,跟幂等号存储逻辑的修改,两者完全独立,一个修改不会影响另外一个。
- 在代码可测试性方面,我们把原本放在构造函数中的逻辑抽离出来,放到了 parseHostAndPorts() 函数中。这个函数本应该是 Private 访问权限的,但为了方便编写单元测试,我们把它设置为成了 Protected 访问权限,并且通过注解 @VisibleForTesting 做了标明。
- 在代码灵活性方面,为了方便复用业务系统已经建立好的 jedisCluster,我们提供了一个新的构造函数,支持业务系统直接传递 jedisCluster 来创建 Idempotence 对象。
// 每个类的代码实现
public class Idempotence {
private IdempotenceStorage storage;
public Idempotence(IdempotenceStorage storage) {
this.storage = storage;
}
public boolean saveIfAbsent(String idempotenceId) {
return storage.saveIfAbsent(idempotenceId);
}
public void delete(String idempotenceId) {
storage.delete(idempotenceId);
}
}
// 幂等号生成类
public class IdempotenceIdGenerator {
public String generateId() {
return UUID.randomUUID().toString();
}
}
// 接口:用来读写幂等号
public interface IdempotenceStorage {
boolean saveIfAbsent(String idempotenceId);
void delete(String idempotenceId);
}
// IdempotenceStorage 的实现类
public class RedisClusterIdempotenceStorage implements IdempotenceStorage {
private JedisCluster jedisCluster;
/**
* Constructor
* @param redisClusterAddress the format is 128.91.12.1:3455;128.91.12.2:3452;289.13.2.12:8978
* @param config should not be null
*/
public RedisIdempotenceStorage(String redisClusterAddress, GenericObjectPoolConfig config) {
Set<HostAndPort> redisNodes = parseHostAndPorts(redisClusterAddress);
this.jedisCluster = new JedisCluster(redisNodes, config);
}
public RedisIdempotenceStorage(JedisCluster jedisCluster) {
this.jedisCluster = jedisCluster;
}
/**
* Save {@idempotenceId} into storage if it does not exist.
* @param idempotenceId the idempotence ID
* @return true if the {@idempotenceId} is saved, otherwise return false
*/
public boolean saveIfAbsent(String idempotenceId) {
Long success = jedisCluster.setnx(idempotenceId, "1");
return success == 1;
}
public void delete(String idempotenceId) {
jedisCluster.del(idempotenceId);
}
@VisibleForTesting
protected Set<HostAndPort> parseHostAndPorts(String redisClusterAddress) {
String[] addressArray= redisClusterAddress.split(";");
Set<HostAndPort> redisNodes = new HashSet<>();
for (String address : addressArray) {
String[] hostAndPort = address.split(":");
redisNodes.add(new HostAndPort(hostAndPort[0], Integer.valueOf(hostAndPort[1])));
}
return redisNodes;
}
}
支持自定义规则的灰度发布组件
背景
使用功能开关做新老接口调用方式的切换,我们还希望调用方在替换某个接口的时候,先让小部分接口请求,调用新的 RESTful 接口,剩下的大部分接口请 求,还是调用老的 RPC 接口,验证没有问题之后,再逐步加大调用新接口的请求比例,最终,将所有的接口请求,都替换成调用新的接口。这就是所谓的“灰度”。在不需要重新部署和重启系统的情况,做到快速回滚或新老代码逻辑的切换。
这里的灰度,是代码级别的灰度,目的是保证项目质量,规避重大 代码修改带来的不确定性风险。实际上,我们平时经常讲的灰度,一般都是产品层面或者系 统层面的灰度。产品层面,有点类似 A/B Testing,让不同的用户看到不同的功能,对比两组用户的使 用体验,收集数据,改进产品。所谓系统层面的灰度,往往不在代码层面上实现,一般是通 过配置负载均衡或者 API-Gateway,来实现分配流量到不同版本的系统上。系统层面的灰 度也是为了平滑上线功能,但比起我们讲到的代码层面的灰度,就没有那么细粒度了,开发 和运维成本也相对要高些。
分析
决定使用什么来做灰度,也就是灰度的对象。我们可以针对请求携带的时间戳 信息、业务 ID 等信息,按照区间、比例或者具体的值来做灰度。
我们把功能开关和灰度相关的代码,抽象封装为一个灰度组件,提供给各个调用方来 复用。调用方只需要把灰度规则和功能开关,按照某种事先约定好的格式,存 储到配置文件或者配置中心。
组件使用流程/功能性需求:
组件使用者需要设置一个 key 值,来唯一标识要灰度的功 能,然后根据自己业务数据的特点,选择一个灰度对象(比如用户 ID),在配置文件或者 配置中心中,配置这个 key 对应的灰度规则和功能开关。
features:
- key: call_newapi_getUserById
enabled: true // enabled为true时,rule才生效
rule: {893,342,1020-1120,%30} // 按照用户ID来做灰度
- key: call_newapi_registerUser
enabled: true
rule: {1391198723, %10} //按照手机号来做灰度
- key: newalgo_loan
enabled: true
rule: {0-1000} //按照贷款(loan)的金额来做灰度
灰度组件在业务系统启动的时候,会将这个灰度配置,按照事先定义的语法,解析并加载到内存对象中,业务系统直接使用组件提供的灰度判定接口,给业务系统使用,来判定某个灰度对象是否灰度执行新的代码逻辑。配置的加载解析、灰度判定逻辑这部分代码,都不需要业务系统来从零开发。所以得到的两大功能就是:
- 灰度规则配置解析
- 提供编程接口(DarkFeature)判定是否灰度
- 灰度规则的格式和存储方式要支持不同格式(JSON、YAML、XML 等)、不同存储方式(本地配置文件、Redis、Zookeeper、或者自研配置中心等)。和限流框架中限流规则的格式和存储方式完全一致
- 支持三种灰度规则语法格式:具体值(比如 893)、区间值(比如 1020-1120)、比例值(比如 %30)。对于更加复杂的灰度规则,比如只对 30 天内购买过某某商品并且退货次数少于 10 次的用户进行灰度,我们通过编程的方式来实现。
- 灰度规则的内存组织方式类似于限流框架中的限流规则,我们需要把灰度规则组织成支持快速查找的数据结构,能够快速判定某个灰度对象(darkTarget,比如用户 ID),是否落在灰度规则设定的范围内。
- 灰度规则热更新修改了灰度规则之后,我们希望不重新部署和重启系统
非功能性需求:
在易用性方面,限流、幂等因为其跟业务无关,但是代码级别的灰度跟业务代码耦合的比较紧密,比较难做到低侵入。
在扩展性、灵活性方面,对于大部分业务的灰度,我们使用最基本的语法规 则(具体值、区间值、比例值)就能满足了。对于极个别复杂的灰度规则,我们借鉴 Spring 的编程式配置,由业务方编程实现。
在性能方面,只需要把灰度规则组织成快速查找的数据结构,能够支持快速判定某个灰度对象(darkTarget,比如用户 ID),是否落在灰度规则设定的区间内。
在容错性方面,限流框架要高度容错,容忍短暂、小规模的限流失效,但不容忍框架异常导致的接口响应异常。幂等框架正好相反,不容忍幂等功能的失效,一旦出现异常,幂等功能失效,我们的处理原则是让业务也失败。这两种处理思路都可以用在灰度组件对异常的处理中,灰度应该也是让业务直接失败。
设计
支持更灵活、更复杂的灰度规则
只对 30 天内购买过某某商品并且退货次数少于 10 次的用户进行灰度,通过定义语法规则来支持,是很难实现的。可以使用规则引擎,比如 Drools,在配置文件中调用 Java 代码。另一种是支持编程实现灰度规则,这样做灵活性更高。不过,缺点是更新灰度规则需要更新代码,重新部署。
对于大部分业务的灰度,我们使用前面定义的最基本的语法规则(具体值、区间值、比例 值)就能满足了。对于极个别复杂的灰度规则,我们借鉴 Spring 的编程式配置,由业务方编程实现。这样既兼顾了易用性,又 兼顾了灵活性。不使用 Drools 规则引擎,主要是出于不想为了不常用的功能,引入复杂的第三方框架。
如何实现灰度规则热更新
性能计数器项目也有,创建一个定时器,每隔固定时间(比如 1 分 钟),从配置文件中,读取灰度规则配置信息,并且解析加载到内存中,替换掉老的灰度规 则。需要特别强调的是,更新灰度规则,涉及读取配置、解析、构建等一系列操作,会花费 比较长的时间,我们不能因为更新规则,就暂停了灰度服务。所以,在设计和实现灰度规则 更新的时候,我们要支持更新和查询并发执行。
实现
只支持 YAML 格式本地文件的配置存储方式。
实现灰度组件基本功能
// 代码目录结构
com.xzg.darklaunch
--DarkLaunch(框架的最顶层入口类)
--DarkFeature(每个feature的灰度规则)
--DarkRule(灰度规则)
--DarkRuleConfig(用来映射配置到内存中)
// 灰度组件的两个直接使用的类DarkLaunch 类和 DarkFeature 类。
public class DarkDemo {
public static void main(String[] args) {
DarkLaunch darkLaunch = new DarkLaunch();
DarkFeature darkFeature = darkLaunch.getDarkFeature("call_newapi_getUserById");
System.out.println(darkFeature.enabled());
System.out.println(darkFeature.dark(893));
}
}
DarkLaunch 类。这个类是灰度组件的最顶层入口类。它用来组装其他类对象,串联整个操作流程,提供外部调用的接口。先读取灰度规则配置文件,映射为内存中的 Java 对象(DarkRuleConfig),然后再将这个中间结构,构建成一个支持快速查询的数据结构(DarkRule)。除此之外,它还负责定期灰度规则热更新。为了避免更新规则和查询规则的并发执行冲突,使用COW实现
public class DarkLaunch {
private static final Logger log = LoggerFactory.getLogger(DarkLaunch.class);
private static final int DEFAULT_RULE_UPDATE_TIME_INTERVAL = 60; // in seconds
private DarkRule rule;
private ScheduledExecutorService executor;
public DarkLaunch(int ruleUpdateTimeInterval) {
loadRule();
this.executor = Executors.newSingleThreadScheduledExecutor();
// 定时任务加载规则
this.executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
loadRule();
}
}, ruleUpdateTimeInterval, ruleUpdateTimeInterval, TimeUnit.SECONDS);
}
public DarkLaunch() {
this(DEFAULT_RULE_UPDATE_TIME_INTERVAL);
}
private void loadRule() {
// 将灰度规则配置文件dark-rule.yaml中的内容读取DarkRuleConfig中
InputStream in = null;
DarkRuleConfig ruleConfig = null;
try {
in = this.getClass().getResourceAsStream("/dark-rule.yaml");
if (in != null) {
Yaml yaml = new Yaml();
ruleConfig = yaml.loadAs(in, DarkRuleConfig.class);
}
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
log.error("close file error:{}", e);
}
}
}
if (ruleConfig == null) {
throw new RuntimeException("Can not load dark rule.");
}
// 更新规则并非直接在this.rule上进行,
// 而是通过创建一个新的DarkRule,然后赋值给this.rule,
// 来避免更新规则和规则查询的并发冲突问题
DarkRule newRule = new DarkRule(ruleConfig);
this.rule = newRule;
}
public DarkFeature getDarkFeature(String featureKey) {
DarkFeature darkFeature = this.rule.getDarkFeature(featureKey);
return darkFeature;
}
}
// DarkRuleConfig 类嵌套了一个内部类 DarkFeatureConfig。这两个类跟配置文件的两层嵌套结构完全对应。
// 灰度规则配置(dark-rule.yaml)放置在classpath路径下
features:
- key: call_newapi_getUserById
enabled: true
rule: {893,342,1020-1120,%30}
- key: call_newapi_registerUser
enabled: true
rule: {1391198723, %10}
- key: newalgo_loan
enabled: true
rule: {0-1000}
public class DarkRuleConfig {
private List<DarkFeatureConfig> features;
public List<DarkFeatureConfig> getFeatures() {
return this.features;
}
public void setFeatures(List<DarkFeatureConfig> features) {
this.features = features;
}
public static class DarkFeatureConfig {
private String key;
private boolean enabled;
private String rule;
// 省略getter、setter方法
}
}
DarkRule 包含所有要灰度的业务功能的灰度规则。它用来支持根据业务功能标识(feature key),快速查询灰度规则(DarkFeature)。
public class DarkRule {
private Map<String, DarkFeature> darkFeatures = new HashMap<>();
public DarkRule(DarkRuleConfig darkRuleConfig) {
List<DarkRuleConfig.DarkFeatureConfig> darkFeatureConfigs = darkRuleConfig.getFeatures();
for (DarkRuleConfig.DarkFeatureConfig darkFeatureConfig : darkFeatureConfigs) {
darkFeatures.put(darkFeatureConfig.getKey(), new DarkFeature(darkFeatureConfig));
}
}
public DarkFeature getDarkFeature(String featureKey) {
return darkFeatures.get(featureKey);
}
}
DarkFeature 类表示每个要灰度的业务功能的灰度规则。DarkFeature 将配置文件中灰度规则,解析成一定的结构(比如 RangeSet),方便快速判定某个灰度对象是否落在灰度规则范围内。
public class DarkFeature {
private String key;
private boolean enabled;
private int percentage;
private RangeSet<Long> rangeSet = TreeRangeSet.create();
public DarkFeature(DarkRuleConfig.DarkFeatureConfig darkFeatureConfig) {
this.key = darkFeatureConfig.getKey();
this.enabled = darkFeatureConfig.getEnabled();
String darkRule = darkFeatureConfig.getRule().trim();
parseDarkRule(darkRule);
}
@VisibleForTesting
protected void parseDarkRule(String darkRule) {
if (!darkRule.startsWith("{") || !darkRule.endsWith("}")) {
throw new RuntimeException("Failed to parse dark rule: " + darkRule);
}
String[] rules = darkRule.substring(1, darkRule.length() - 1).split(",");
this.rangeSet.clear();
this.percentage = 0;
for (String rule : rules) {
rule = rule.trim();
if (StringUtils.isEmpty(rule)) {
continue;
}
if (rule.startsWith("%")) {
int newPercentage = Integer.parseInt(rule.substring(1));
if (newPercentage > this.percentage) {
this.percentage = newPercentage;
}
} else if (rule.contains("-")) {
String[] parts = rule.split("-");
if (parts.length != 2) {
throw new RuntimeException("Failed to parse dark rule: " + darkRule);
}
long start = Long.parseLong(parts[0]);
long end = Long.parseLong(parts[1]);
if (start > end) {
throw new RuntimeException("Failed to parse dark rule: " + darkRule);
}
this.rangeSet.add(Range.closed(start, end));
} else {
long val = Long.parseLong(rule);
this.rangeSet.add(Range.closed(val, val));
}
}
}
public boolean enabled() {
return this.enabled;
}
public boolean dark(long darkTarget) {
boolean selected = this.rangeSet.contains(darkTarget);
if (selected) {
return true;
}
long reminder = darkTarget % 100;
if (reminder >= 0 && reminder < this.percentage) {
return true;
}
return false;
}
public boolean dark(String darkTarget) {
long target = Long.parseLong(darkTarget);
return dark(target);
}
}
添加、优化灰度组件功能
// 第一步的代码目录结构
com.xzg.darklaunch
--DarkLaunch(框架的最顶层入口类)
--DarkFeature(每个feature的灰度规则)
--DarkRule(灰度规则)
--DarkRuleConfig(用来映射配置到内存中)
// 第二步的代码目录结构
com.xzg.darklaunch
--DarkLaunch(框架的最顶层入口类,代码有改动)
--IDarkFeature(抽象接口)
--DarkFeature(实现IDarkFeature接口,基于配置文件的灰度规则,代码不变)
--DarkRule(灰度规则,代码有改动)
--DarkRuleConfig(用来映射配置到内存中,代码不变)
public interface IDarkFeature {
boolean enabled();
boolean dark(long darkTarget);
boolean dark(String darkTarget);
}
基于这个抽象接口,业务系统可以自己编程实现复杂的灰度规则,然后添加到 DarkRule 中。为了避免配置文件中的灰度规则热更新时,覆盖掉编程实现的灰度规则,在 DarkRule 中,我们对从配置文件中加载的灰度规则和编程实现的灰度规则分开存储。
public class DarkRule {
// 从配置文件中加载的灰度规则
private Map<String, IDarkFeature> darkFeatures = new HashMap<>();
// 编程实现的灰度规则
private ConcurrentHashMap<String, IDarkFeature> programmedDarkFeatures = new ConcurrentHashMap<>();
public void addProgrammedDarkFeature(String featureKey, IDarkFeature darkFeature) {
programmedDarkFeatures.put(featureKey, darkFeature);
}
public void setDarkFeatures(Map<String, IDarkFeature> newDarkFeatures) {
this.darkFeatures = newDarkFeatures;
}
public IDarkFeature getDarkFeature(String featureKey) {
IDarkFeature darkFeature = programmedDarkFeatures.get(featureKey);
if (darkFeature != null) {
return darkFeature;
}
return darkFeatures.get(featureKey);
}
}
public class DarkLaunch {
private static final Logger log = LoggerFactory.getLogger(DarkLaunch.class);
private static final int DEFAULT_RULE_UPDATE_TIME_INTERVAL = 60; // in seconds
private DarkRule rule = new DarkRule();
private ScheduledExecutorService executor;
public DarkLaunch(int ruleUpdateTimeInterval) {
loadRule();
this.executor = Executors.newSingleThreadScheduledExecutor();
this.executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
loadRule();
}
}, ruleUpdateTimeInterval, ruleUpdateTimeInterval, TimeUnit.SECONDS);
}
public DarkLaunch() {
this(DEFAULT_RULE_UPDATE_TIME_INTERVAL);
}
private void loadRule() {
InputStream in = null;
DarkRuleConfig ruleConfig = null;
try {
in = this.getClass().getResourceAsStream("/dark-rule.yaml");
if (in != null) {
Yaml yaml = new Yaml();
ruleConfig = yaml.loadAs(in, DarkRuleConfig.class);
}
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
log.error("close file error:{}", e);
}
}
}
if (ruleConfig == null) {
throw new RuntimeException("Can not load dark rule.");
}
// 修改:单独更新从配置文件中得到的灰度规则,不覆盖编程实现的灰度规则
Map<String, IDarkFeature> darkFeatures = new HashMap<>();
List<DarkRuleConfig.DarkFeatureConfig> darkFeatureConfigs = ruleConfig.getFeatures();
for (DarkRuleConfig.DarkFeatureConfig darkFeatureConfig : darkFeatureConfigs) {
darkFeatures.put(darkFeatureConfig.getKey(), new DarkFeature(darkFeatureConfig));
}
this.rule.setDarkFeatures(darkFeatures);
}
// 新增:添加编程实现的灰度规则的接口
public void addProgrammedDarkFeature(String featureKey, IDarkFeature darkFeature) {
this.rule.addProgrammedDarkFeature(featureKey, darkFeature);
}
public IDarkFeature getDarkFeature(String featureKey) {
IDarkFeature darkFeature = this.rule.getDarkFeature(featureKey);
return darkFeature;
}
}
// 灰度规则配置(dark-rule.yaml),放到classpath路径下
features:
- key: call_newapi_getUserById
enabled: true
rule: {893,342,1020-1120,%30}
- key: call_newapi_registerUser
enabled: true
rule: {1391198723, %10}
- key: newalgo_loan
enabled: true
rule: {0-100}
// 编程实现的灰度规则
public class UserPromotionDarkRule implements IDarkFeature {
@Override
public boolean enabled() {
return true;
}
@Override
public boolean dark(long darkTarget) {
// 灰度规则自己想怎么写就怎么写
return false;
}
@Override
public boolean dark(String darkTarget) {
// 灰度规则自己想怎么写就怎么写
return false;
}
}
// Demo
public class Demo {
public static void main(String[] args) {
DarkLaunch darkLaunch = new DarkLaunch(); // 默认加载classpath下dark-rule.yaml文件中的灰度规则
darkLaunch.addProgrammedDarkFeature("user_promotion", new UserPromotionDarkRule()); // 添加编程实现的灰度规则
IDarkFeature darkFeature = darkLaunch.getDarkFeature("user_promotion");
System.out.println(darkFeature.enabled());
System.out.println(darkFeature.dark(893));
}
}
posted on 2025-10-14 23:08 chuchengzhi 阅读(25) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号