
主流中间件选型-RPC
发生服务循环消费时候关闭服务启动检查
默认情况下,若服务消费者先于服务提供者启动,则消费者端会报错。因为默认情况下消费者会在启动时查检其要消费的服务的提供者是否已经注册,若未注册则抛出异常。在消费者端的 spring 配置文件中添加 **check="false"**属性,则可关闭服务检查功能。
在循环消费场景下是必须要使用的。A 消费 B 服务,B 消费 C 服务,而 C 消费 A 服务。必须至少有一方要关闭服务检查功能,否则将无法启动任何一方。
多版本控制实现灰度发布
系统升级采用的“灰度发布(又称为金丝雀发布)” 是在低压力时段,让部分消费者先调用新的提供者实现类,其余的仍然调用老的实现类,在新的实现类运行没有问题的情况下,逐步让所有消费者全部调用成新的实现类。
<!--指定消费0.0.1版本,即oldService提供者-->
<!--<dubbo:reference id="someService" version="0.0.1"-->
<!--interface="com.abc.service.SomeService"/>-->
<!--指定消费0.0.2版本,即newService提供者-->
<dubbo:reference id="someService" version="0.0.2"
interface="com.abc.service.SomeService"/>
<!--注册Service实现类-->
<bean id="oldService" class="com.abc.provider.OldServiceImpl"/>
<bean id="newService" class="com.abc.provider.NewServiceImpl"/>
<!--暴露服务-->
<dubbo:service interface="com.abc.service.SomeService"
ref="oldService" version="0.0.1"/>
<dubbo:service interface="com.abc.service.SomeService"
ref="newService" version="0.0.2"/>
服务分组实现统一接口支撑多业务
**服务分组与多版本控制的使用方式几乎是相同的,只要将 version 替换为 group 即可。 **
使用版本控制的目的是为了升级,是为了替换。分组是统一接口为了不同的业务提供的不同实现。这些实现所提供的服务是并存的,例如,对于支付服务的实现,可以有微信支付实现与支付宝支付实现等。
<!--指定调用微信服务-->
<dubbo:reference id="weixin" group="pay.weixin"
interface="com.abc.service.SomeService"/>
<!--指定调用支付宝服务-->
<dubbo:reference id="zhifubao" group="pay.zhifubao"
interface="com.abc.service.SomeService"/>
<!--注册Service实现类-->
<bean id="weixinService" class="com.abc.provider.WeixinServiceImpl"/>
<bean id="zhifubaoService" class="com.abc.provider.ZhifubaoServiceImpl"/>
<!--暴露服务-->
<dubbo:service interface="com.abc.service.SomeService"
ref="weixinService" group="pay.weixin"/>
<dubbo:service interface="com.abc.service.SomeService"
ref="zhifubaoService" group="pay.zhifubao"/>
多协议方式提供统一服务
大数据小并发用短连接协议,小数据大并发用长连接协议。
| 协议 | 连接个数 | 连接方式 | 传输协议 | 传输方式 | 适用范围 |
|---|---|---|---|---|---|
| dubbo | 单连接 | 长连接 | TCP | NIO 异步传输 | 数据包大小建议小于100k,消费者比提供者个数多,尽量不传输大文件或超大字符串。 |
| rmi | 多连接 | 短连接 | TCP | BIO同步传输 | 传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件。 |
| hession | 多连接 | 短连接 | HTTP | BIO同步传输 | 传入传出参数数据包较大,提供者比消费者个数多,提供者可传文件 |
| http | 多连接 | 短连接 | HTTP | BIO同步传输 | 传入传出参数数据包大小混合,提供者比消费者个数多,可用浏览器查看, 可用表单或 URL 传入参数,暂不支持传文件。 |
| webservice | 多连接 | 短连接 | HTTP | BIO同步传输 | 系统集成,跨语言调用 |
| thrift | Thrift 是 Facebook 捐给 Apache 的一个 RPC 框架,其消息传递采用的协议即为 thrift 协议。当前 dubbo 支持的 thrift 协议是对 thrift 原生协议的扩展。Thrift 协议不支持 null 值的传递。 | ||||
| memcached /redis |
它们都是高效的 KV 缓存服务器。它们会对传输的数据使用相应的技术进行缓存。 | ||||
| rest | 若需要开发具有 RESTful 风格的服务,则需要使用该协议。 |
<!-- 声明要使用的多种协议 -->
<dubbo:protocol name="dubbo" port="20880"/>
<dubbo:protocol name="rmi" port="1099"/>
<!--注册Service实现类-->
<bean id="oldService" class="com.abc.provider.OldServiceImpl"/>
<bean id="newService" class="com.abc.provider.NewServiceImpl"/>
<!--暴露服务-->
<dubbo:service interface="com.abc.service.SomeService"
ref="oldService" version="0.0.1"
protocol="rmi, dubbo"/>
<dubbo:service interface="com.abc.service.SomeService"
ref="newService" version="0.0.2"/>
在提供者中要首先声明新添加的协议,然后在服务dubbo:service/标签中再增加该新的协议。若不指定,默认为 dubbo 协议。
<!--指定消费0.0.1版本,即newService提供者-->
<dubbo:reference id="someService" version="0.0.1"
protocol="dubbo"
interface="com.abc.service.SomeService"/>
<!--指定消费0.0.2版本,即newService提供者-->
<dubbo:reference id="someService" version="0.0.2"
protocol="rmi"
interface="com.abc.service.SomeService"/>
多Provider时候consumer的负载均衡策略
负载均衡算法可以在消费者端指定,也可以在提供者端指定:
- 若消费者与提供者均设置了负载均衡策略,消费者端设置的优先级高。
- 若消费者端没有显式的设置,但提供者端显式的设置了,且同一个服务(接口名、版本号、分组都相同)的负载均衡策略相同。消费者调用时会按照提供者设置的策略调用。
- 若多个提供者端设置的不相同,则最后一个注册的会将前面注册的信息覆盖。
对应负载均衡策略有:
- random:随机算法,是 Dubbo 默认的负载均衡算法。存在服务堆积问题。
- roundrobin:轮询算法。按照设定好的权重依次进行调度。
- leastactive:最少活跃度调度算法。即被调度的次数越少,其优选级就越高,被调度到的机率就越高。
- consistenthash:一致性 hash 算法。对于相同参数的请求,其会被路由到相同的提供者。
负载均衡算法可以在服务上指定,就会在服务的所有方法生效,也可以在服务的方法上生效,就会在每一个方法上单独生效
<dubbo:service interface="com.abc.service.SomeService"
loadbalance="roundrobin"
ref="someService"/>
<dubbo:service interface="com.abc.service.SomeService"
ref="someService">
<dubbo:method name="m1" loadbalance="roundrobin"/>
<dubbo:method name="m2" loadbalance="leastactive"/>
<dubbo:method name="m3" loadbalance="random"/>
</dubbo:service>
<dubbo:reference id="someService"
interface="com.abc.service.SomeService"
loadbalance="roundrobin"/>
<dubbo:reference id="someService"
interface="com.abc.service.SomeService">
<dubbo:method name="m1" loadbalance="roundrobin"/>
<dubbo:method name="m2" loadbalance="leastactive"/>
<dubbo:method name="m3" loadbalance="random"/>
</dubbo:reference>
集群容错(消费者端的逻辑)
当消费者调用提供者集群时发生异常的处理方案。容错策略可以设置在消费者端,也可以设置在提供者端。若消费者与提供者均做了设置,则消费者端的优先级更高。
- Failover:故障转移策略。调用失败会自动尝试调用其它服务器。通常用于读操作。
- Failfast:快速失败策略。消费者端只发起一次调用,若失败则立即报错。通常用于非幂等性的写操
- Failsafe:失败安全策略。当消费者调用提供者出现异常时,直接忽略本次消费操作。不太重要的任务,例如,写入审计日志等操作。
- Failback:失败自动恢复策略。消费者调用提供者失败后,Dubbo 会记录下该失败请求,然后定时自动重新发送该请求。该策略通常用于实时性要求不太高的服务,例如消息通知操作。
- Forking:并行策略。消费者对于同一服务并行调用多个提供者服务器,只要一个成功即调用结束并返回结果。通常用于实时性要求较高的读操作,但其会浪费较多服务器资源。
- Broadcast:广播策略。广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
如果使用的是默认的策略 Failover,则可以指定重试次数,注意设置的是重试次数,不含第一次正常调用:
<dubbo:service interface="com.abc.service.SomeService"
ref="oldService" version="0.0.1"
retries="2"
protocol="rmi, dubbo"/>
<dubbo:service interface="com.abc.service.SomeService"
ref="someService">
<dubbo:method name="m1" loadbalance="roundrobin" retries="2"/>
<dubbo:method name="m2" loadbalance="leastactive"/>
<dubbo:method name="m3" loadbalance="random"/>
</dubbo:service>
指定容错策略指定是服务级别的,不能是方法级别的:
<dubbo:service interface="com.abc.service.SomeService"
ref="someService"
cluster="failfast"/>
使用Mock机制实现服务降级
当服务器压力剧增的情况下,根据当前降低服务级别,以释放服务器资源,保证核心任务的正常运行。例如,双 11 时 0 点-2 点期间淘宝用户不能修改收货地址,不能查看历史订单,就是典型的服务降级。
能够实现服务降级方式很多:
- 部分服务暂停:页面能够访问,但是部分服务暂停服务,不能访问。
- 部分服务延迟:页面可以访问,当用户提交某些请求时系统会提示该操作已成功提交给了服务器,由于当前服务器繁忙,此操作随后会执行。在等待了若干时间后最终用户可以看到正确的执行结果。
- 全部服务暂停:系统入口页面就不能访问,提示由于服务繁忙此服务暂停。跳转到一个预先设定好的静态页面。
- 随机拒绝服务:服务器会按照预先设定好的比例,随机挑选用户,对其拒绝服务。作为用户,其看到的就是请重试。可能再重试就可获得服务。
dubbo 使用的Mock降级处理机制:
- Mock Null:
<!-- 有返回值的方法降级结果是null,没有返回值的方法降级结果是无任何显示 -->
<dubbo:reference id="userService"
mock="return null"
check="false"
interface="com.abc.service.UserService"/>
- Class Mock:在业务接口所在的包中定义一个类,该类的命名需要满足:业务接口简单类名 + Mock。
<dubbo:reference id="userService"
mock="true"
check="false"
interface="com.abc.service.UserService"/>
public class UserServiceMock implements UserService {
@Override
public String getUsernameById(int id) {
return "没有该用户:" + id;
}
@Override
public void addUser(String username) {
System.out.println("添加该用户失败:" + username);
}
}
服务调用超时设置
前面的服务降级的发生,其实是由于消费者调用服务超时引起的。
即从发出调用请求到获取到提供者的响应结果这个时间超出了设定的时限。默认服务调用超时时限为 1 秒。可以在消费者端与提供者端设置超时时限。
<dubbo:service interface="com.abc.service.UserService"
ref="userService" timeout="3000"/>
服务限流
- 直接限流:通过对连接的数量直接限制来达到限流的目的。超过限制则会让再来的请求等待,直到等待超时,或获取到相应服务(官方方案)。
- 间接限流:通过一些非连接数量设置的间接手段来达到限流的目的(个人经验)。
executes 限流:仅提供者
该属性仅能设置在提供者端。可以设置为接口级别,也可以设置为方法级别。对指定服 务(方法)的连接数量进行限制。
executes="10" 在接口上指定就是接口的每一个方法并发执行数不能超过10个。
accepts 限流:仅提供者
该属性仅可设置在提供者端的<dubbo:provider/>与<dubbo:protocol/>,是针对指定协议的连接数进行限制。
actives 限流:两端均可
该限流方式与前两种不同的是,其可以设置在提供者端,也可以设置在消费者端。可以设置为接口级别,也可以设置为方法级别。
提供者端:
根据客户端与服务端建立的连接是长连接还是短连接,其意义不同:
长连接:当前这个服务上的一个长连接最多能够处理的请求个数。对长连接数量没有限制。
短连接:当前这个服务上可以同时处理的短连接数量。
消费者端:
根据客户端与服务端建立的连接是长连接还是短连接,其意义不同:
长连接:当前这个消费者的一个长连接最多能够提交的请求个数。对长连接数量没有限制。
短连接:当前这个消费者可以同时提交的短连接数量。
connections 限流:两端均可
可以设置在提供者端,也可以设置在消费者端。限定连接的个数。
一般情况下,我们使用的都是默认的服务暴露协议 Dubbo,所以,一般会让 connections 与 actives 联用。connections 限制长连接的数量,而 actives 限制每个长连接上的请求数量。
lazy 延迟连接
消费者真正调用提供者方法时才创建长连接。 仅可设置在消费者端,且不能设置为方法级别。仅作用于 Dubbo 服务暴露协议。用于减少长连接数量。
当前消费者所有接口的方法发出连接都采用延迟连接
<dubbo:consumer lazy="true"/>
<dubbo:reference id="userService"
lazy="true"
interface="com.abc.service.UserService"/>
粘连连接
让所有客户端要访问的同一接口的同一方法,尽可能是的由同一Inovker 提供服务。其用于限定流向。
粘连连接仅能设置在消费者端,其可以设置为接口级别,也可以设置为方法级别。仅作用于 Dubbo 服务暴露协议。用于减少长连接数量。粘连连接的开启将自动开启延迟连接。
<dubbo:reference id="userService"
sticky="true"
interface="com.abc.service.UserService"/>
声明式缓存
为了进一步提高消费者对用户的响应速度,减轻提供者的压力,Dubbo 提供了基于结果的声明式缓存。该缓存是基于消费者端的,所以使用很简单,只需修改消费者配置文件,与提供者无关。该缓存是缓存在消费者端内存中的,一旦缓存创建,即使提供者宕机也不会影响消费者端的缓存。
<dubbo:reference id="someService"
cache="true"
interface="com.abc.service.SomeService"/>
默认可以缓存 1000 个结果。若超出 1000,将采用 LRU 策略来删除缓存,以保证最热的数据被缓存。注意,该删除缓存的策略不能修改。
指定多注册中心以及仅订阅和仅注册
同一个服务注册到不同的中心,使用逗号进行分隔。
对于消费者工程,用到哪个注册中心了,就声明哪个注册中心,无需将全部注册中心进行声明。
<!--声明注册中心-->
<dubbo:registry id="bjCenter" address="zookeeper://bjZK:2181"/> <!--北京中心-->
<dubbo:registry id="shCenter" address="zookeeper://shZK:2181"/> <!--上海中心-->
<dubbo:registry id="gzCenter" address="zookeeper://gzZK:2181"/> <!--广州中心-->
<dubbo:registry id="cqCenter" address="zookeeper://cqZK:2181"/> <!--重庆中心-->
<!--注册Service实现类-->
<bean id="weixinService" class="com.abc.provider.WeixinServiceImpl"/>
<bean id="zhifubaoService" class="com.abc.provider.ZhifubaoServiceImpl"/>
<!--暴露服务:同一个服务注册到不同的中心;不同的服务注册到不同的中心-->
<dubbo:service interface="com.abc.service.SomeService"
ref="weixinService" group="pay.weixin" register="bjCenter, shCenter"/>
<dubbo:service interface="com.abc.service.SomeService"
ref="zhifubaoService" group="pay.zhifubao" register="gzCenter, cqCenter"/>
<!--声明注册中心-->
<dubbo:registry id="bjCenter" address="zookeeper://bjZK:2181"/>
<dubbo:registry id="gzCenter" address="zookeeper://gzZK:2181"/>
<dubbo:registry id="cqCenter" address="zookeeper://cqZK:2181"/>
<!--指定调用bjCenter注册中心微信服务-->
<dubbo:reference id="weixin" group="pay.weixin" registry="bjCenter"
interface="com.abc.service.SomeService"/>
<!--指定调用gzCenter与cqCenter注册中心支付宝服务-->
<dubbo:reference id="gzZhifubao" group="pay.zhifubao" registry="gzCenter"
interface="com.abc.service.SomeService"/>
<dubbo:reference id="cqZhifubao" group="pay.zhifubao" registry="cqCenter"
interface="com.abc.service.SomeService"/>
<!--声明注册中心:仅订阅-->
<dubbo:registry id="gzCenter" address="zookeeper://gzZK:2181" register="false"/>
<!--声明注册中心:仅注册-->
<dubbo:registry id="gzCenter" address="zookeeper://gzZK:2181" subscribe="false"/>
服务暴露延迟
如果我们的服务启动过程需要 warmup 事件,就可以使用 delay 进行服务延迟暴露。
在服务提供者的<dubbo:service/>标签中添加 delay 属性。其值可以有三类:
- 正数:单位为毫秒,表示在提供者对象创建完毕后的指定时间后再发布服务。
- 0:默认值,表示当前提供者创建完毕后马上向注册中心暴露服务。
- -1:表示在 Spring 容器初始化完毕后再向注册中心暴露服务。
消费者异步调用与提供者异步执行
异步调用一般应用于提供者提供的是耗时性 IO 服务。
Futrue 与 CompletableFuture 的区别与联系
对于消费者不用获取提供者所调用的耗时操作结果的情况,使用 Future 与 CompletableFuture 效果是区别不大的。但对于需要获取返回值的情况,Future源自于 JDK5,通过 Future 的 get()获取返回结果,get()方法会阻塞轮询,CompletableFuture 源自于 JDK8,Dubbo2.7.0 之后使用 Future 实现消费者对提供者的异步调用。通过 CompletableFutrue 的回调获取返回结果,不会发生阻塞,好用。
使用 Future 实现
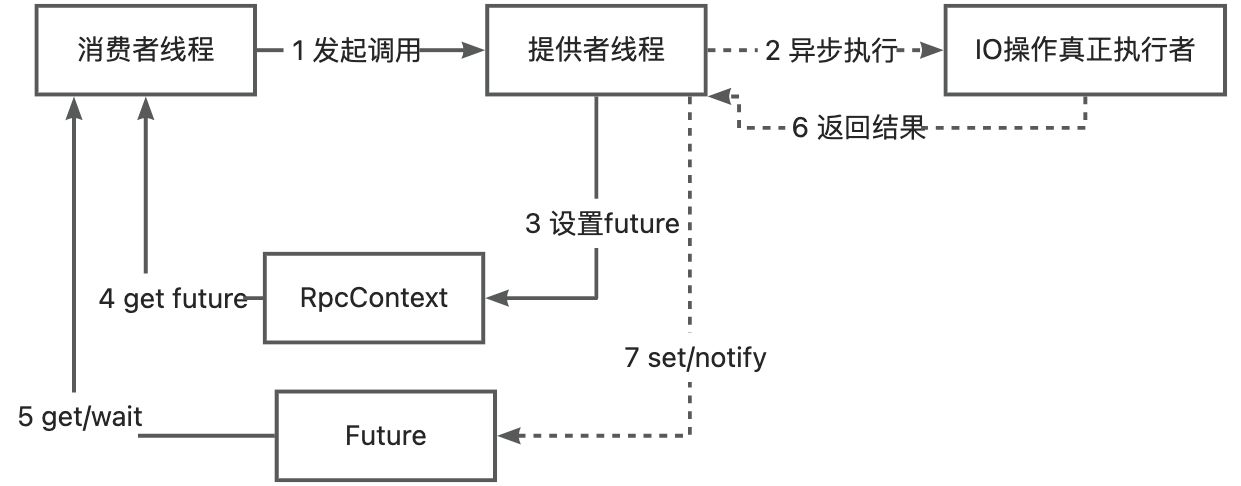
提供方接口定义:
public interface OtherService {
String doFirst();
String doSecond();
String doThird();
String doFourth();
}
消费方调用定义:
// 异步调用
String result1 = service.doThird();
System.out.println("调用结果1 = " + result1);
Future<String> thirdFuture = RpcContext.getContext().getFuture();
String result3 = service.doFourth();
System.out.println("调用结果3 = " + result3);
Future<String> fourFuture = RpcContext.getContext().getFuture();
// 阻塞
String result2 = thirdFuture.get();
System.out.println("调用结果2 = " + result2);
String result4 = fourFuture.get();
System.out.println("调用结果4 = " + result4);
需要在消费方的XML中声明为异步的,注意此时的服务端还是在同步执行的:
<dubbo:reference id="otherService" timeout="20000"
interface="com.abc.service.OtherService" >
<dubbo:method name="doThird" async="true"/>
<dubbo:method name="doFourth" async="true"/>
</dubbo:reference>
使用 CompletableFuture� 实现
提供方接口定义:
String doFirst();
String doSecond();
CompletableFuture<String> doThird();
CompletableFuture<String> doFourth();
下面第一种写法还是由业务线程执行耗时操作,使用第二种写法就是异步调用执行耗时操作了
@Override
public CompletableFuture<String> doThird() {
// 耗时操作仍由业务线程调用
sleep();
CompletableFuture<String> future =
CompletableFuture.completedFuture("doThird()-----");
return future;
}
@Override
public CompletableFuture<String> doFourth() {
// 异步调用耗时操作
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
sleep();
return "doFourth()";
});
return future;
}
消费方调用定义:
// 异步调用
CompletableFuture<String> doThirdFuture = service.doThird();
CompletableFuture<String> doFourthFuture = service.doFourth();
// 回调方法
doThirdFuture.whenComplete((result, throwable) -> {
if(throwable != null) {
throwable.printStackTrace();
} else {
System.out.println("异步调用提供者的doThird()返回值:" + result);
}
});
doFourthFuture.whenComplete((result, throwable) -> {
if(throwable != null) {
throwable.printStackTrace();
} else {
System.out.println("异步调用提供者的doFourth()返回值:" + result);
}
});
泛化调用
在 <dubbo:service/> 与 <dubbo:reference/> 中都有一个 generic 属性,分别代表泛化服务和泛化引用。泛化服务与泛化引用无需同时使用。其主要是针对某一方没有具体业务接口的.class 情况的。
泛化服务
<!--泛化服务-->
<dubbo:service interface="com.abc.service.SomeService" ref="someService"
generic="true"/>
public class GenericServiceImpl implements GenericService {
/**
*
* @param method 消费者调用的方法名
* @param parameterTypes 消费者调用的方法的参数类型列表
* @param args 消费者调用方法时传递的实参值
* @return
* @throws GenericException
*/
@Override
public Object $invoke(String method, String[] parameterTypes,
Object[] args) throws GenericException {
if ("hello".equals(method)) {
return "Generic hello," + args[0];
}
return null;
}
}
泛化引用
<!--泛化引用-->
<dubbo:reference id="someService" interface="com.abc.service.SomeService"
check="false" generic="true" />
ApplicationContext ac = new ClassPathXmlApplicationContext("spring-consumer.xml");
GenericService service = (GenericService) ac.getBean("someService");
Object hello = service.$invoke("hello", new String[]{String.class.getName()}, new Object[]{"Tom"});
System.out.println("================ " + hello);
属性优先级
Provider 端要配置合理的 Provider 端属性, Provider 端上尽量多配置 Consumer 端属性。一开始就思考消费者需要什么样子的性能,如何更好为消费者提供服务。
<dubbo:consumer/>设置在消费者端,用于设置消费者端的默认配置
<dubbo:provider/>设置在提供者端,用于设置提供者端的默认配置
Dubbo 配置文件中各个标签属性配置的优先级总原则是: 方法级(<dubbo:method/>)优先,接口级(服务级<dubbo:reference/> <dubbo:service>)次之,全局配置(<dubbo:consumer>``<dubbo:provider>)再次之。 如果级别一样,则消费方优先,提供方次之。
服务路由
一条路由规则,规定了服务消费者可调用哪些服务提供者。Dubbo 目前提供了三种服务路由实现,分别为条件路由 ConditionRouter、脚本路由 ScriptRouter 和标签路由 TagRouter。其中条件路由是我们最常使用的。路由规则是在 Dubbo 管控平台 Dubbo-Admin 中的。
黑名单。少数不能用,例如:主机到时间没有缴费,就加到黑名单
大多数是不能用,就加到白名单。
具体的路由配置参见官方的文档:
https://dubbo.apache.org/zh/docs3-v2/java-sdk/advanced-features-and-usage/traffic/routing-rule/
feign + ribbon
thrift
grpc
开源中间件原理剖析
Dubbo的底层原理实现
dubbo 整体架构
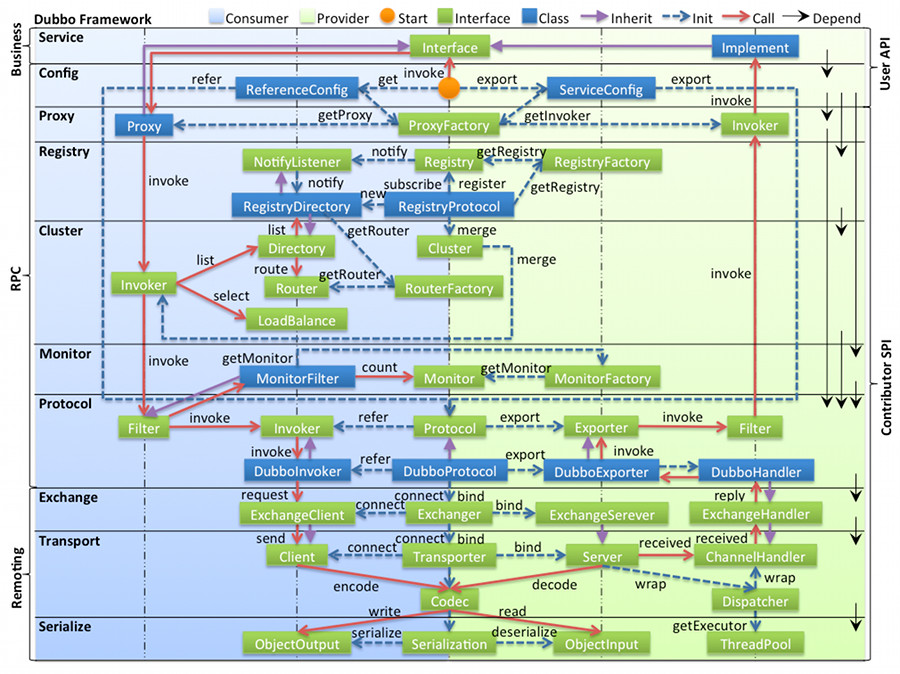
https://dubbo.apache.org/zh/docs3-v2/java-sdk/concepts-and-architecture/code-architecture/
十层架构:
- Business 层:仅包含一个 service 服务层,该层与实际业务逻辑有关,根据服务消费方和服务提 供方的业务设计,实现对应的接口。
- RPC 层:主机之间的交互
- config 层:加载和解析dubbo相关的配置,放到 ServiceConfig 和 ReferenceConfig
- proxy 层:胶水层,没有这一层RPC也正常运行,只是看起来不那么透明,Invoker会直接裸露出来给用户使用。服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton, 以 ServiceProxy 为中心,扩展接口为 ProxyFactory。下面层都是和 Invoker 相关的,只有用户使用的时候需要转换为对应接口的实现
- registry 层:封装服务地址的注册和发现,以服务 URL 为中心,扩展接口为 RegistryFactory、Registry、 RegistryService,可能没有服务注册中心,此时服务提供方直接暴露服务。
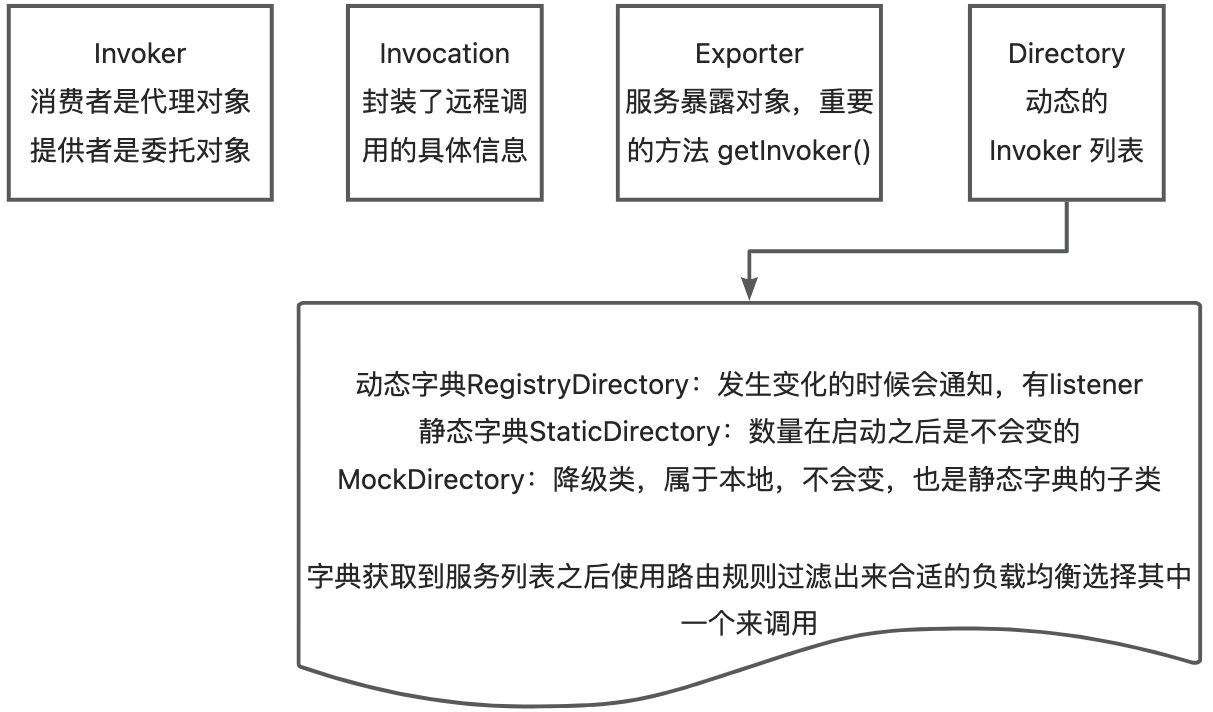
- cluster 层:路由层。封装多个提供者的路由和负载均衡,并桥接注册中心,以 Invoker 为中心,扩展接口为 Cluster、Directory、Router 和 LoadBalance,将多个服务提供方组合为一个服务提供方,实现 对服务消费通明。只需要与一个服务提供方进行交互。Dubbo 官方指出,在 Dubbo 的整体架构中,Cluster 只是一个外围概念。Cluster 的目的 是将多个 Invoker 伪装成一个 Invoker,这样用户只需关注 Protocol 层 Invoker 即可,加上 Cluster 或者去掉 Cluster 对其它层都不会造成影响,因为只有一个提供者时,是不需要 Cluster 的。
- monitor 层:RPC 调用时间和次数监控,以 Statistics 为中心,扩展接口 MonitorFactory、Monitor 和 MonitorService。
- protocol 层:封装 RPC 调用,以 Invocation 和 Result 为中心,扩展接口为 Protocol、Invoker 和 Exporter。 Protocol 是服务域,它是 Invoker 暴露和引用的主功能入口,它负责 Invoker 的生命周期管理。 Invoker 是实体域,它是 Dubbo 的核心模型,其他模型都是向它靠拢,或转换成它,它代表一个可执行体,可向它发起 Invoker 调用,它有可能是一个本地实现,也有可能是一个远程 实现,也有可能是一个集群实现。Protocol 是核心层,也就是只要有 Protocol + Invoker + Exporter 就可以完成非透明的 RPC 调用,然后在 Invoker 的主过程上 Filter 拦截点。
- Remoting 层:Remoting 实现是 Dubbo 协议的实现,如果我们选择 RMI 协议,整个 Remoting 都不会用
- exchange 信息交换层:在传输层之上封装了 Request-Response 语义。封装请求响应模式,同步转异步,以 Request 和 Response 为中心,扩展接口为 Exchanger 和 ExchangeChannel,ExchangeClient 和 ExchangeServer。
- transport 网络传输层:只负责单向消息传输。抽象和 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel、Transporter、 Client、Server 和 Codec。
- serialize 数据序列化层:可复用的一些工具,扩展接口为 Serialization、ObjectInput、ObejctOutput 和 ThreadPool。
整体设计原则:
- “微内核 + 插件” 的设计模式,内核里面主要包含了 dubbo 自己的 SPI 机制、自适应机制Adaptive、包装机制Wrapper、激活机制 Activate,使用这些机制来组装(IOC、AOP)插件,使得几乎所有的组件都可方便扩展和增强替换。
- dubbo 整个框架使用 URL 作为配置信息的介质,例如
协议://IP:port/服务名?元数据信息k=v&k=v,没有使用JSON是因为URL更加简洁,数据量小,还涉及通信协议。所有扩展点参数都包含 URL 参数,URL 作为上下文信息贯穿整个扩展点设计体系。
三大领域:
- Protocol 服务域:是 Invoker 暴露和引用的主功能入口,它负责 Invoker 的生命周期管理。
- Invoker 实体域:是 Dubbo 的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起 invoke 调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。
- Invocation 会话域:它持有调用过程中的变量,比如方法名,参数等。
四大组件:
- Provider
- Consumer
- Registry:服务注册与发现的中心,提供目录服务,亦称为服务注册中心
- Monitor:统计服务的调用次数、调用时间等信息的日志服务,亦称为服务监控中心
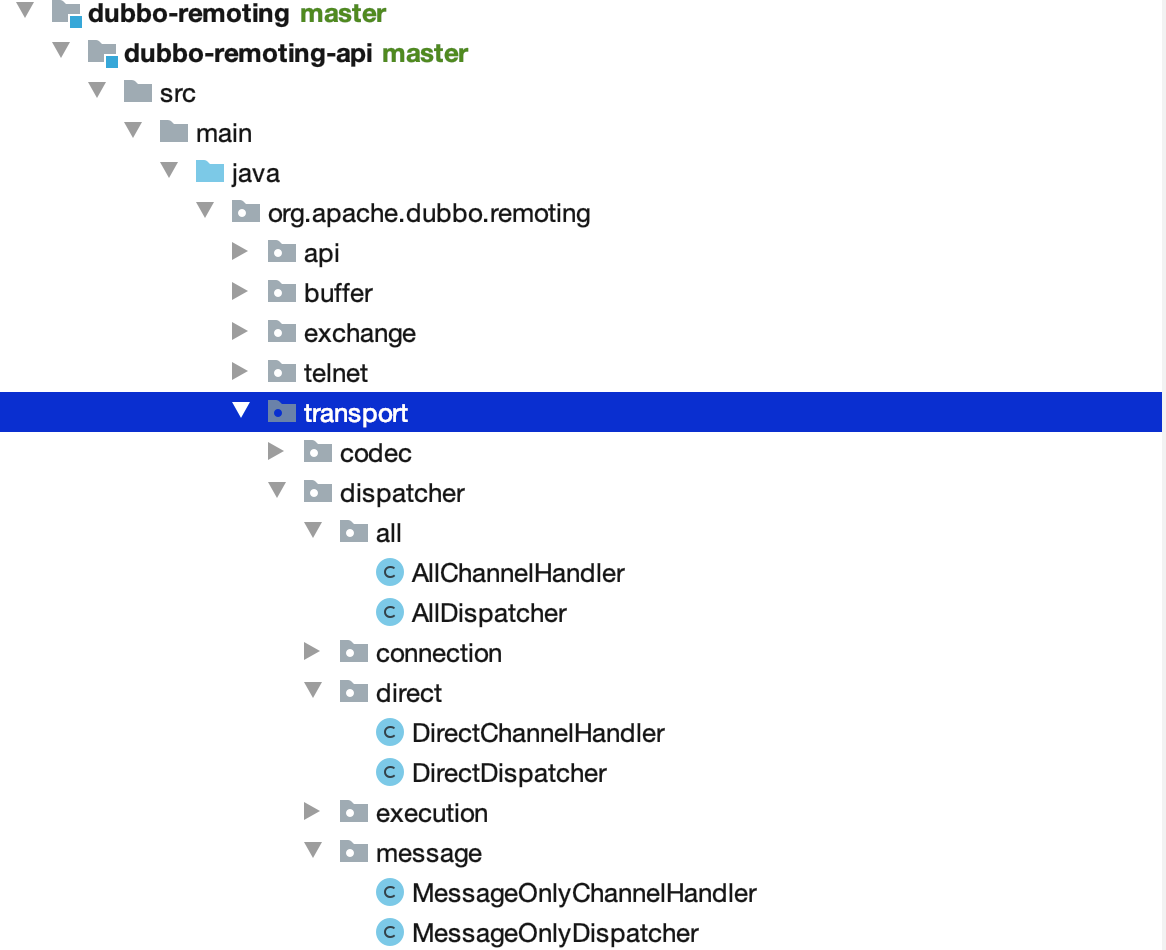
源码项目结构
dubbo-remoting 通信模块
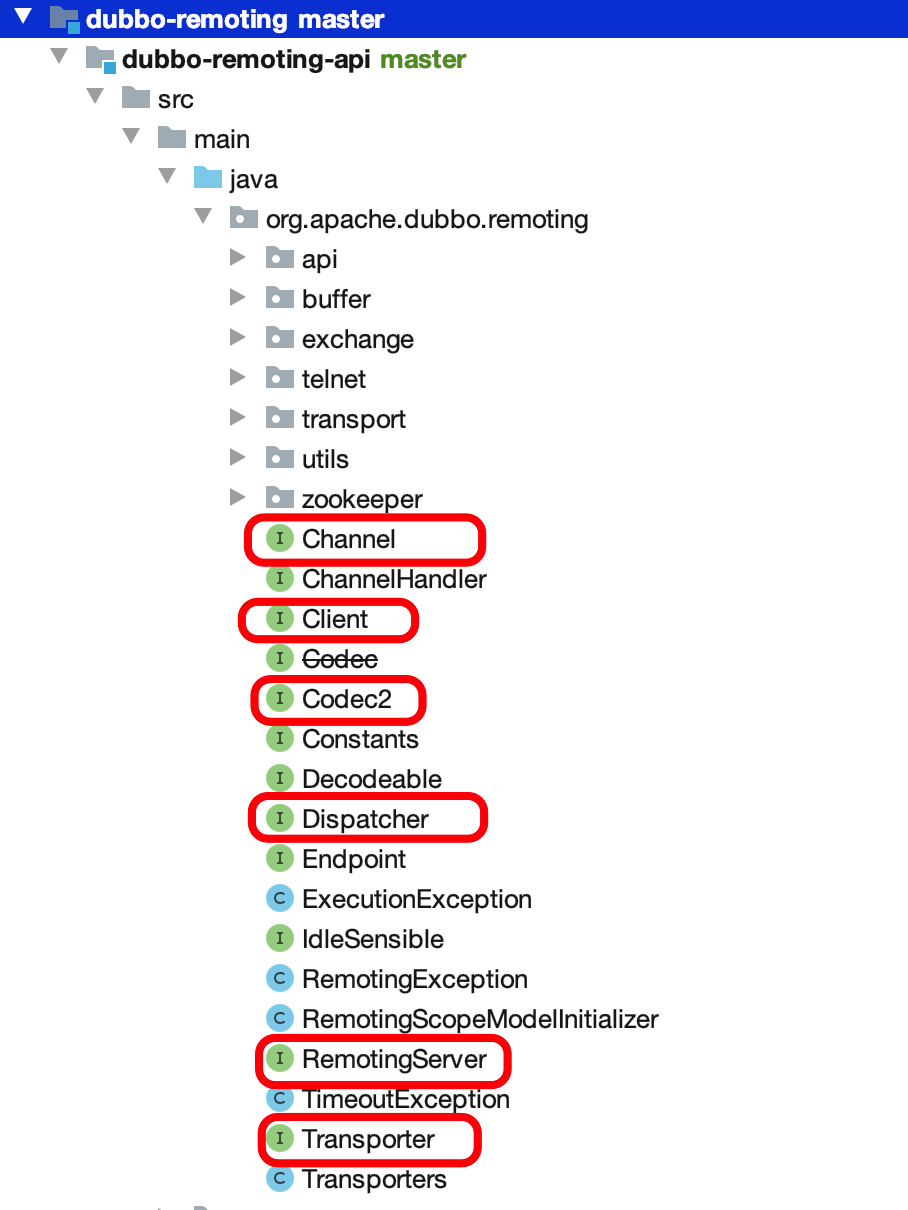
主要提供通用的客户端和服务端通讯功能。
只需要看:
- dubbo-remoting-api + dubbo-remoting-netty4:相当于 dubbo 通信中的 client 和 server 的接口定义以及实现。
- dubbo-remoting-zookeeper:相当于 zk 的客户端,用于和 zk 的 server 通信。
dubbo-common 工具+通用模型
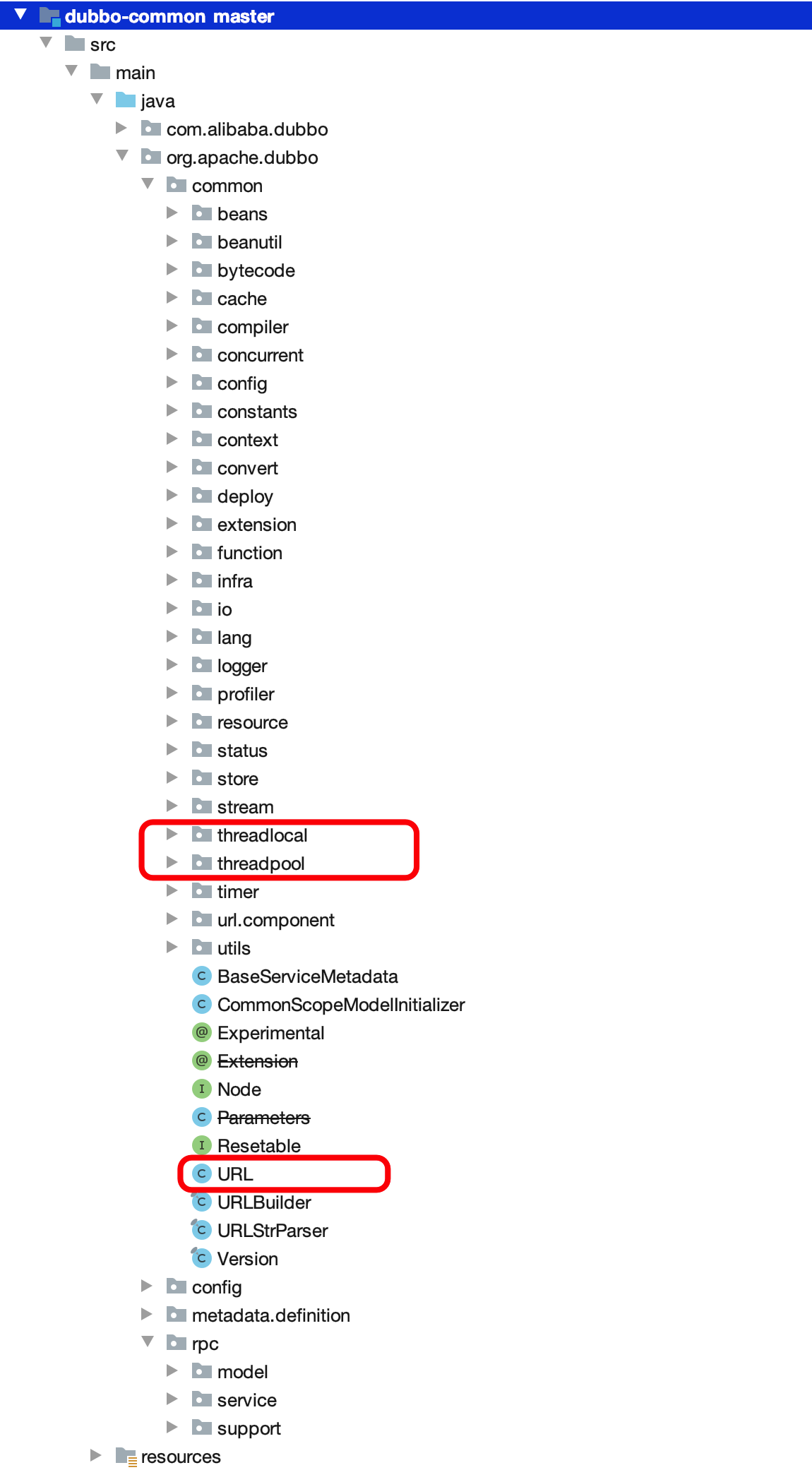
所有配置最终都将转换为 Dubbo URL 表示,并由服务提供方生成,经注册中心传递给消费方
dubbo-rpc 远程调用协议抽象与实现以及动态代理工厂

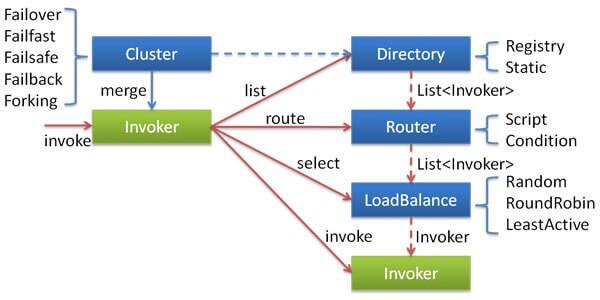
dubbo-cluster 多提供方伪装为一个提供方:容错、路由、负载均衡
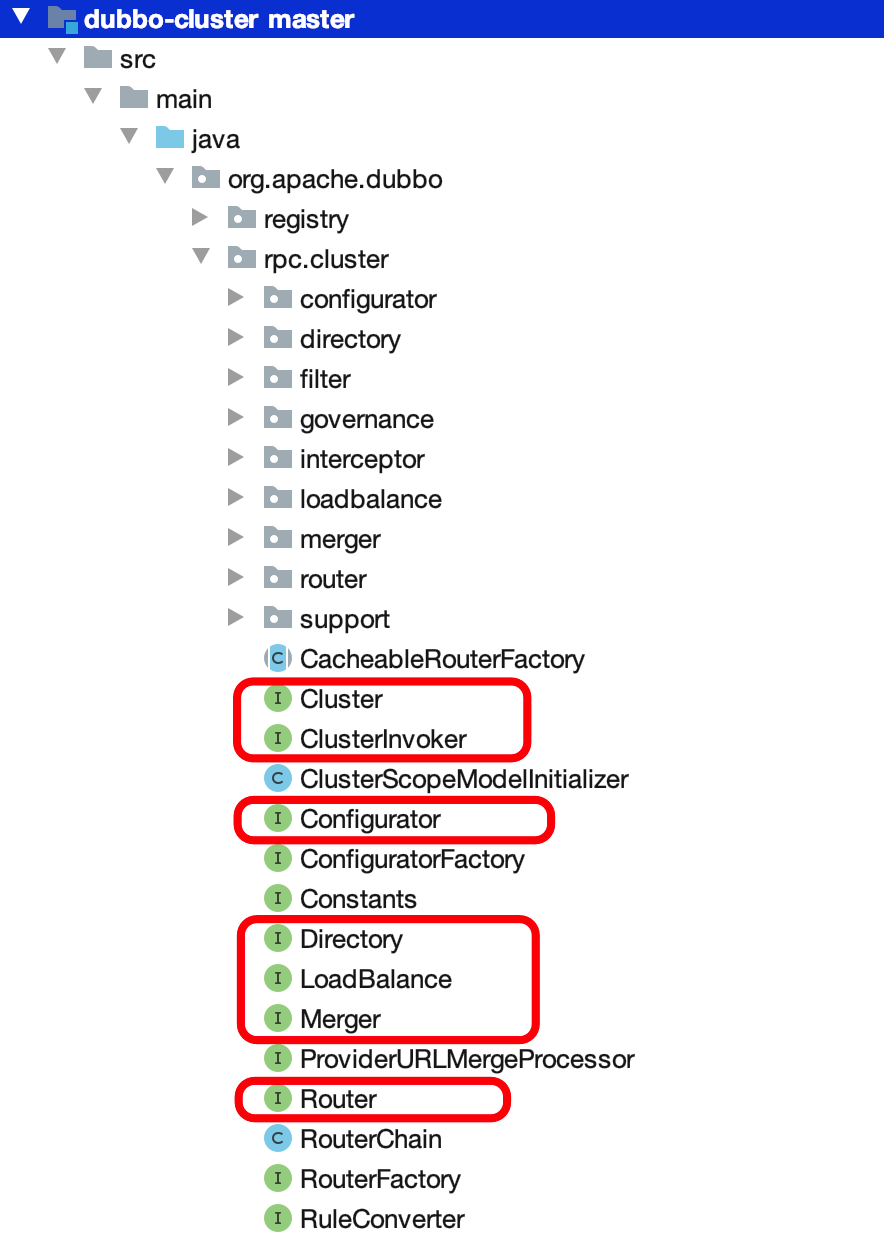
- 容错
- com.alibaba.dubbo.rpc.cluster.Cluster 接口 + com.alibaba.dubbo.rpc.cluster.support 包。
- Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个。
- 目录
- com.alibaba.dubbo.rpc.cluster.Directory 接口 + com.alibaba.dubbo.rpc.cluster.directory 包。
- Directory 代表了多个 Invoker ,可以把它看成 List ,但与 List 不同的是,它的值可能是动态变化的,比如注册中心推送变更。
- 路由
- com.alibaba.dubbo.rpc.cluster.Router 接口 + com.alibaba.dubbo.rpc.cluster.router 包。
- 负责从多个 Invoker 中按路由规则选出子集,比如读写分离,应用隔离等。
- 配置
- com.alibaba.dubbo.rpc.cluster.Configurator 接口 + com.alibaba.dubbo.rpc.cluster.configurator 包。
- 负载均衡
- com.alibaba.dubbo.rpc.cluster.LoadBalance 接口 + com.alibaba.dubbo.rpc.cluster.loadbalance 包。
- LoadBalance 负责从多个 Invoker 中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选。
- 合并结果
- com.alibaba.dubbo.rpc.cluster.Merger 接口 + com.alibaba.dubbo.rpc.cluster.merger 包。
- 合并返回结果,用于分组聚合。
dubbo-registry 注册中心接口定义和实现

dubbo-monitor 监控模块:统计服务调用次数,调用时间,调用链路追踪

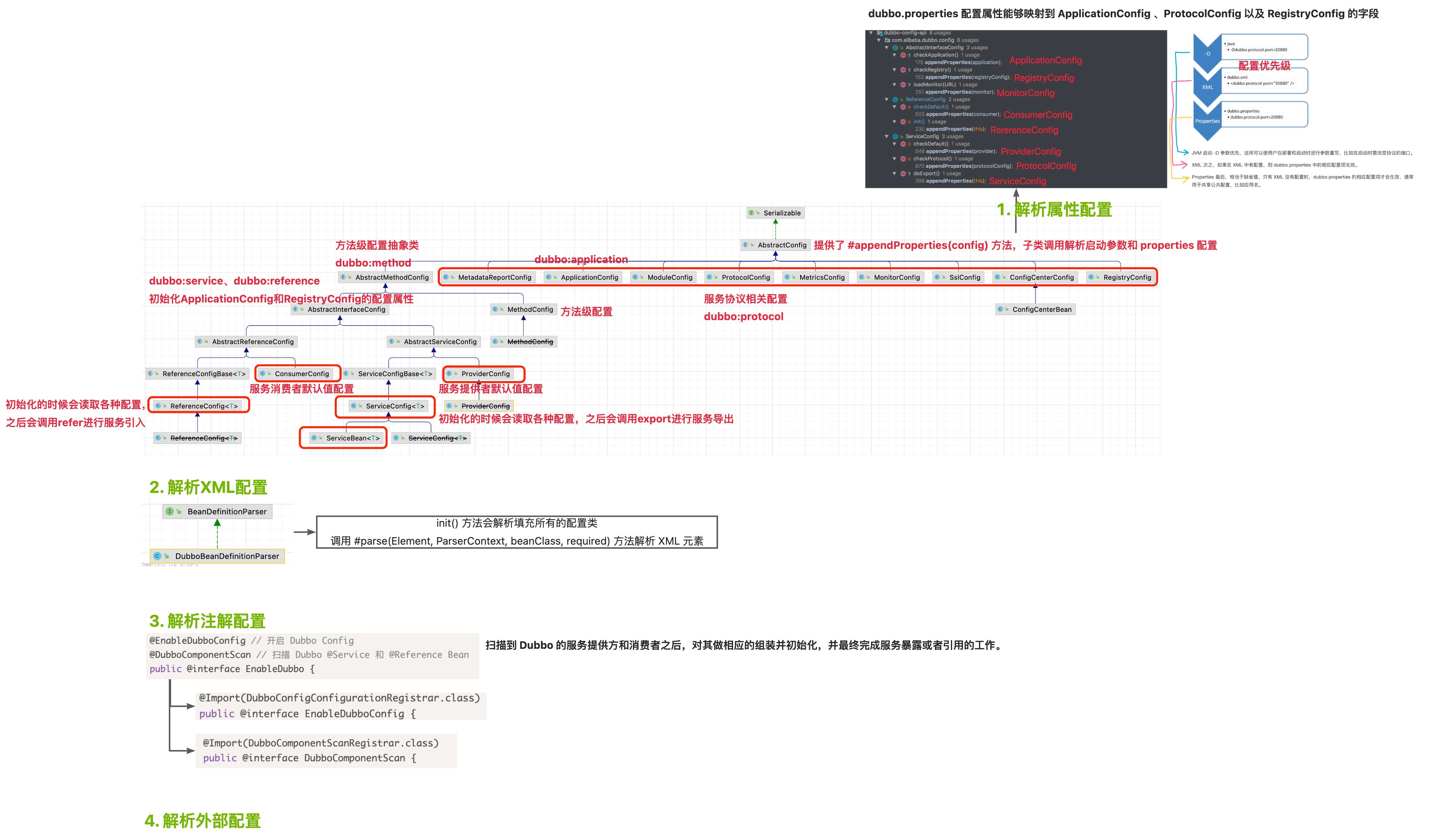
dubbo-config :Dubbo 对外的 API,用户通过 Config 使用Dubbo,隐藏 Dubbo 所有细节
- dubbo-config-api ,实现了 API 配置 和 属性配置 功能。
- dubbo-config-spring ,实现了 XML 配置 和 注解配置 功能。
dubbo-container:容器用来加载服务
Standlone 的容器,以简单的 Main 加载 Spring 启动,因为服务通常不需要 Tomcat/JBoss 等 Web 容器的特性,没必要用 Web 容器去加载服务。
- dubbo-container-api :定义了 com.alibaba.dubbo.container.Container 接口,并提供加载所有容器启动的 Main 类。
- 实现 dubbo-container-api
- dubbo-container-spring ,提供了 com.alibaba.dubbo.container.spring.SpringContainer 。
- dubbo-container-log4j ,提供了 com.alibaba.dubbo.container.log4j.Log4jContainer 。
- dubbo-container-logback ,提供了 com.alibaba.dubbo.container.logback.LogbackContainer 。
dubbo-filter 过滤器模块:内置过滤器

包含了缓存过滤器和参数校验过滤器。
pom 结构
dubbo SPI机制
一个接口下面是有很多的扩展点的,到底是哪一个,需要使用定义的名字来指定。
实现类配置文件路径,依次查找的目录为:META-INF/dubbo/internal、META-INF/dubbo、META-INF/services,合并在一起,文件的名字是接口的全限定类名。
META-INF/dubbo/internal/目录下,从名字上可以看出,用于 Dubbo 内部提供的拓展实现。META-INF/dubbo/目录下,用于用户自定义的拓展实现。META-INF/service/目录下,Java SPI 的配置目录。
配置文件的内容为key=value 形式,value 为该接口的实现类的全限定类名,key 可以随意,但一般为该实现类的“标识前辍”(首字母小写)。一个类名占一行。拓展名分隔符,使用逗号。
java SPI
JDK 标准的 SPI 会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源。
Dubbo 有很多的拓展点,例如 Protocol、Filter 等等。并且每个拓展点有多种的实现,例如 Protocol 有 DubboProtocol、InjvmProtocol、RestProtocol 等等。那么使用 JDK SPI 机制,会初始化无用的拓展点及其实现,造成不必要的耗时与资源浪费。
普通扩展类
普通的接口实现类/扩展点
@SPI("alipay")
public interface Order {
// 支付方式
String way();
}
注意微信这里没有写key,会自动使用接口的前缀作为key,所以 test01 还是可以正常运行的。

@Test
public void test01() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
Order alipay = loader.getExtension("alipay");
System.out.println(alipay.way());
Order wechat = loader.getExtension("wechat");
System.out.println(wechat.way());
}
@Test
public void test02() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
// Order alipay = loader.getExtension("");
// Order alipay = loader.getExtension(null);
// 上面两个都会报错,下面这个会返回使用 @SPI 注解标明的实现类
Order alipay = loader.getExtension("true");
System.out.println(alipay.way());
}
Wrapper 包装机制
相当于AOP的机制,在将对应的扩展点实例化之后,就会使用 Wrapper 包装,将其赋值到 Wrapper 中的成员变量。
使用方法:首先也是要实现对应的接口,和普通扩展点的区别就是有一个接口为入参的构造方法,接口作为成员变量。该类名称以 Wrapper 结尾。
注意:
- 有多个切面的时候,就一直在外面包就可以了,暂时是不支持顺序的。
- 不能独立使用,是对其他扩展类的增强
public class OrderWrapper2 implements Order {
private Order order;
public OrderWrapper2(Order order) {
this.order = order;
}
@Override
public String way() {
System.out.println("before-OrderWrapper222对way()的增强");
String way = order.way();
System.out.println("after-OrderWrapper222对way()的增强");
return way;
}
@Override
public String pay(URL url) {
System.out.println("before-OrderWrapper222对pay()的增强");
String pay = order.pay(url);
System.out.println("after-OrderWrapper222对pay()的增强");
return pay;
}
}

@Test
public void test02() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
Order order = loader.getAdaptiveExtension();
URL url = URL.valueOf("xxx://localhost:8080/ooo/jjj?order=alipay");
System.out.println(order.pay(url));
}
原理
**cachedClasses + cachedAdaptiveClass + cachedWrapperClasses**** 才是完整缓存的拓展实现类的配置。**
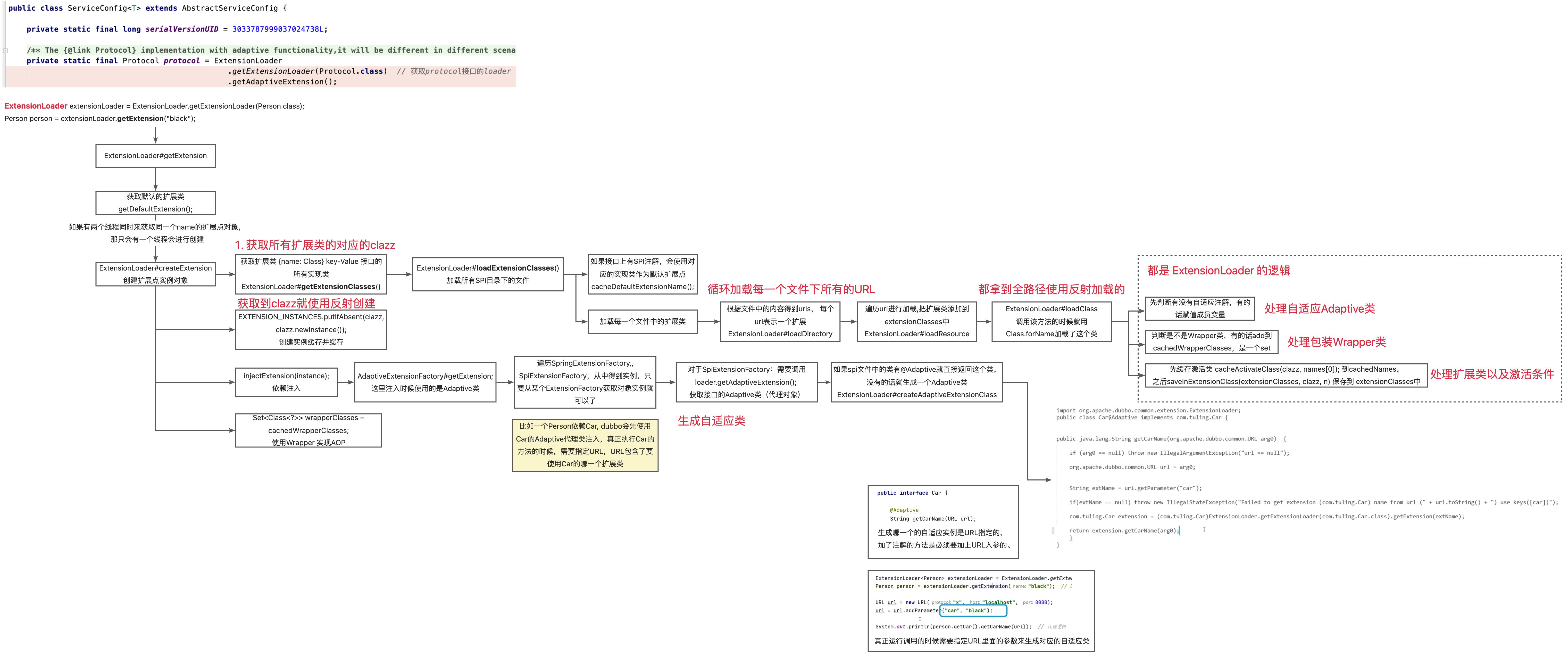
有多个线程同时获取一个实现类的对象,其实值需要一个线程创建出来就可以,另一个直接获取。所以在创建的时候使用了双重检查锁。
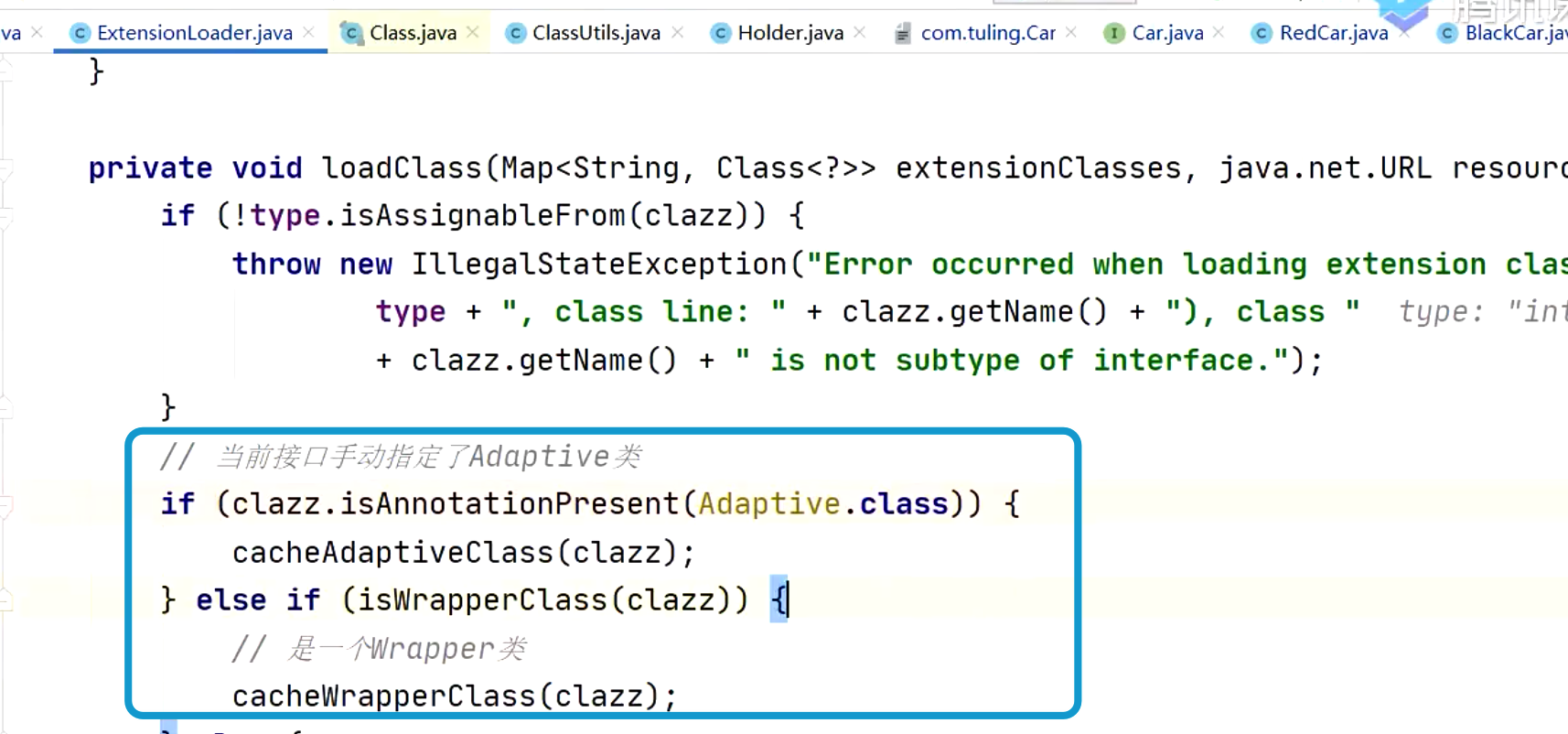
判断是否为 Wrapper 类的逻辑就是判断有没有当前接口作为入参的构造方法。如果是的话就会放到 ConcurrentHashSet 里面
自适应机制 Adaptive
Wrapper 其实是对直接扩展类的包装,Adaptive 是对直接扩展类的选择。
扩展类的自适应机制。可以指定想要加载的扩展名。若不指定,则直接加载默认的扩展类。其是通过@Adaptive 注解实现的。
自适应类不会动态生成代码,需要手写。
自适应方法会动态生成代码,会运行时候自动生成。
@Adaptive 修饰类
被@Adapative 修饰的 SPI 接口扩展类称为 Adaptive 类,该 SPI 扩展类会按照该类中指定的方式获取,其是装饰者设计模式的应用。
@Adaptive
public class AdaptiveOrder implements Order {
private String defaultName;
public void setDefaultName(String defaultName) {
this.defaultName = defaultName;
}
@Override
public String way() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
Order order;
if (StringUtils.isEmpty(defaultName)) {
order = loader.getDefaultExtension();
} else {
order = loader.getExtension(defaultName);
}
return order.way();
}
}

使用自适应扩展类获取需要的扩展类,上面写的返回逻辑是不指定名字就返回默认扩展类,指定名字就返回对应的SPI扩展类。
@Test
public void test01() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
// 获取Order的自适应扩展类实例
Order order = loader.getAdaptiveExtension();
System.out.println(order.way());
}
@Test
public void test02() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
// 获取Order的自适应扩展类实例
Order order = loader.getAdaptiveExtension();
((AdaptiveOrder)order).setDefaultName("alipay");
System.out.println(order.way());
}
// adaptive类不属于直接扩展类,其不能独立使用,其是对其它扩展类的选择方式
@Test
public void test03() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
// 获取该SPI的所有支持的扩展类类名。支持的扩展类也称为直接扩展类
// 可以独立使用的扩展类就是直接扩展类
Set<String> extensions = loader.getSupportedExtensions();
System.out.println(extensions);
}
@Adaptive 修饰方法
被@Adapative 修饰 SPI 接口中的方法称为 Adaptive 方法。在 SPI 扩展类中若没有找到 Adaptive 类,但系统却发现了 Adapative 方法,就会根据 Adaptive 方法自动为该 SPI 接口动态生成一个 Adaptive 扩展类,并自动将其编译。例如 Protocol 接口中就包含两个 Adaptive 方法。
@SPI("wechat")
public interface Order {
String way();
// 其参数包含 URL 类型的参数,或参数可以获取到 URL 类型的值。
// 调用方法的时候使用 URL 传递要加载的扩展名的。
@Adaptive
String pay(URL url);
}

@Test
public void test01() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
Order order = loader.getAdaptiveExtension();
URL url = URL.valueOf("xxx://localhost:8080/ooo/jjj");
System.out.println(order.pay(url));
System.out.println(order.way());
}
@Test
public void test02() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
Order order = loader.getAdaptiveExtension();
URL url = URL.valueOf("xxx://localhost:8080/ooo/jjj?order=alipay");
System.out.println(order.pay(url));
}
如果接口的名字是好几个单词,则对应的key就是小写字母用 **.** 拼接起来的:

public class GoodsOrder$Adaptive implements com.abc.spi.GoodsOrder {
public java.lang.String pay(org.apache.dubbo.common.URL arg0) {
if (arg0 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg0;
// goods.order
String extName = url.getParameter("goods.order", "wechat");
if (extName == null)
throw new IllegalStateException("Failed to get extension (com.abc.spi.GoodsOrder) name from url (" + url.toString() + ") use keys([goods.order])");
com.abc.spi.GoodsOrder extension = (com.abc.spi.GoodsOrder) ExtensionLoader.getExtensionLoader(com.abc.spi.GoodsOrder.class).getExtension(extName);
return extension.pay(arg0);
}
public java.lang.String way() {
throw new UnsupportedOperationException("The method public abstract java.lang.String com.abc.spi.GoodsOrder.way() of interface com.abc.spi.GoodsOrder is not adaptive method!");
}
}
@Test
public void test01() {
ExtensionLoader<GoodsOrder> loader = ExtensionLoader.getExtensionLoader(GoodsOrder.class);
GoodsOrder goodsOrder = loader.getAdaptiveExtension();
// 需要在 URL 的参数中指定要加载的扩展名
URL url = URL.valueOf("xxx://localhost:8080/ooo/jjj?goods.order=alipay");
System.out.println(goodsOrder.pay(url));
}
自动生成的Adaptive类的动态编译
当一个 SPI 接口没有 Adaptive 类时,系统会根据 Adaptive 方法为其自动生成一个 Adaptive 类,这个自动生成的类是一个 java 代码类,这个类是需要编译的。而该编译是由系统动态完成的。
Javassist 是一个开源的分析、编辑和创建 Java 字节码的类库。使用 Javassist,可以直接使用 java 编码的形式,而不需要了解虚拟机指令,就能动态改变类的结构,或者动态生成类。
Dubbo 所有的动态编译都是javaAssisant,都是先生成对应的类之后再编译。

Activate 激活机制
@Activate 就是用来决定指定的条件是否成立来判断是否需要激活当前的直接扩展类:
- before、after 两个属性已经过时,剩余有效属 性还有三个。它们的意义为:
- group:为扩展类指定所属的组别,是当前扩展类的一个标识。String[]类型,表示一个扩展类可以属于多个组。
- value:为当前扩展类指定的 key,是当前扩展类的一个标识。String[]类型,表示一个扩展类可以有多个指定的 key。
- order:指定筛选条件相同的扩展类的加载顺序。序号越小,优先级越高。默认值为 0。
注意事项:激活标签是group属性与value属性 **与** 的结果
// @Activate(group = "online")
// 激活标签是group属性与value属性 与 的结果
@Activate(group = "online", value = "alipay")
// order属性用于指定当前类激活的优先级,数字越小优先级越高,默认值为0
// @Activate(group = {"online", "offline"}, order = 3)
public class AlipayOrder implements Order {
@Override
public String way() {
System.out.println("--- 使用支付宝支付 ---");
return "支付宝支付";
}
}
@Test
public void test02() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
URL url = URL.valueOf("xxx://localhost:8080/ooo/jjj");
// 激活所有group为offline线下支付的扩展类
List<Order> online = loader.getActivateExtension(url, "", "offline");
for (Order order : online) {
System.out.println(order.way());
}
}
@Test
public void test03() {
ExtensionLoader<Order> loader = ExtensionLoader.getExtensionLoader(Order.class);
URL url = URL.valueOf("xxx://localhost:8080/ooo/jjj?xxx=alipay");
// 激活所有group为online线上支付的扩展类
// 该方法中的参数二与参数三的关系是 或
List<Order> online = loader.getActivateExtension(url, "xxx", "online");
for (Order order : online) {
System.out.println(order.way());
}
}
Spring 和 dubbo 整合的原理
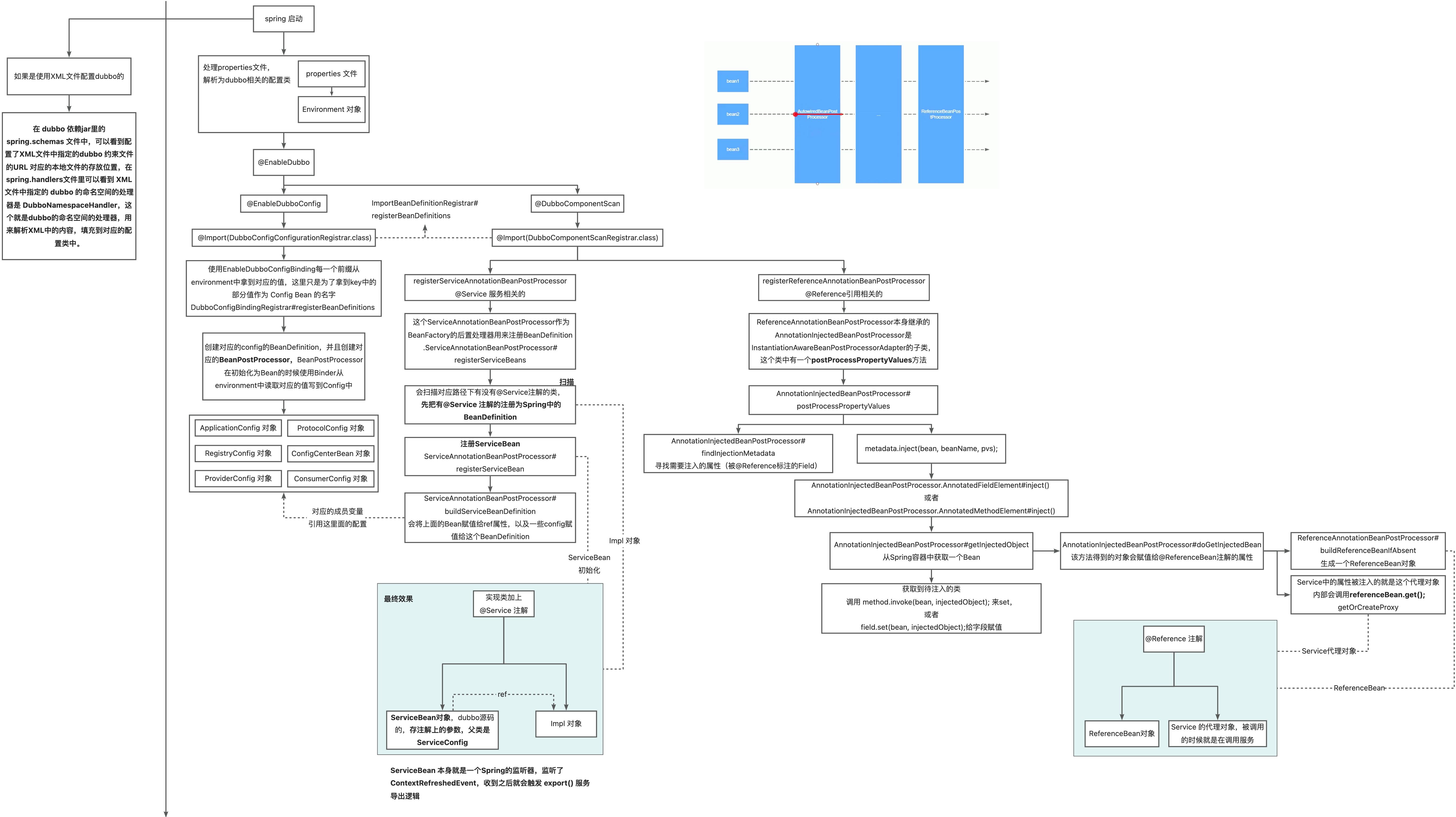
主要接口之间的关系
dubbo 服务导出、注册原理
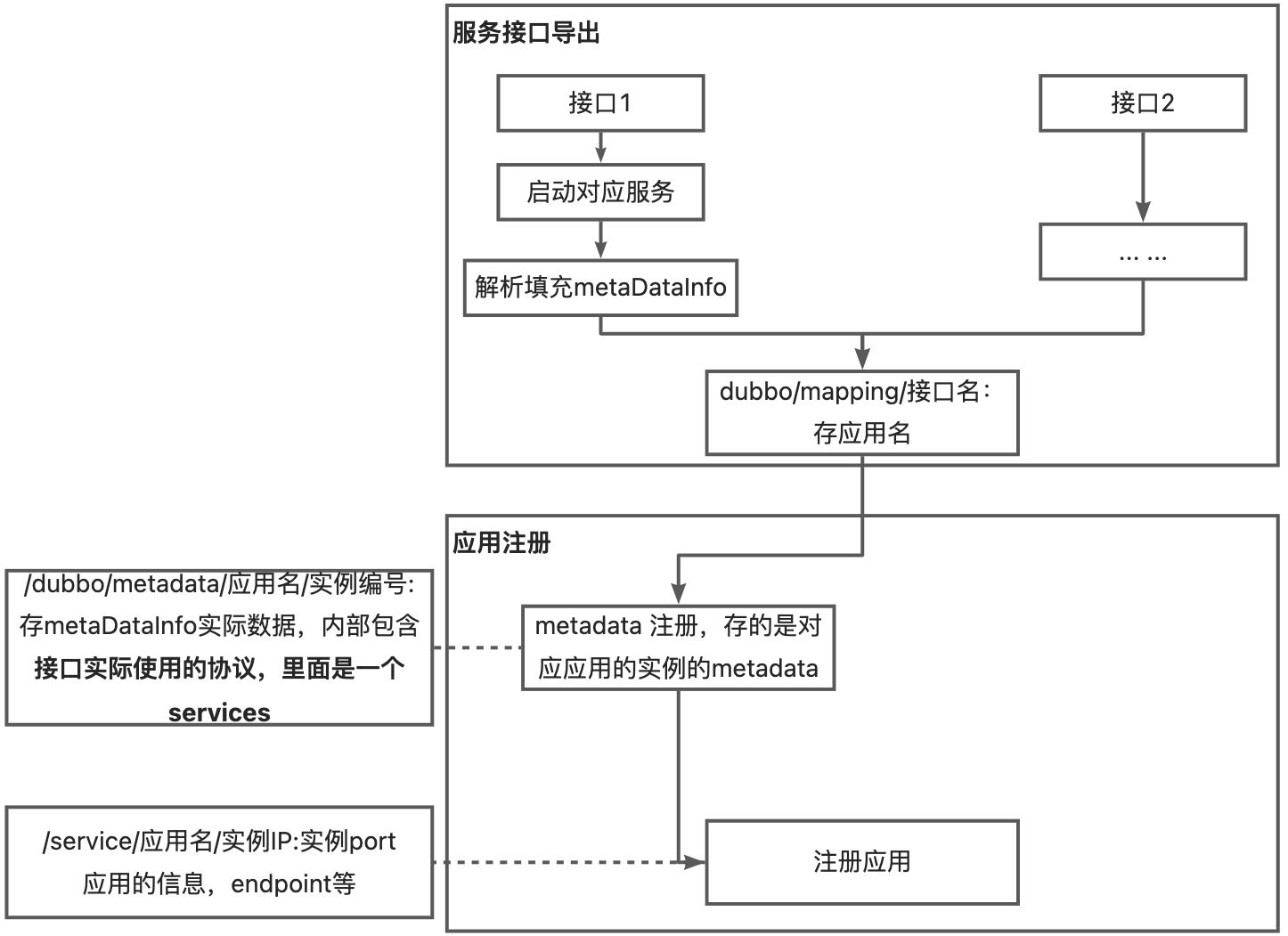
每一个 ServiceConfig 都代表一个服务接口,生成之后就会调用 export 方法。配置了几个 Protocol 就会生成几个URL,也就是每一个协议各对应一个服务的URL,
针对每一个URL都会有两个方式放到注册中心,兼容2.7的版本就还是 dubbo/接口名/providers 下会有多个URL
针对3.0版本再将当前实例的 IP 信息存到 MetaDataInfo 对象当中,当前接口所有的服务 URL 都存到这个元数据对象中之后,存到元数据中心,再把这个 metaDataInfo 对象存到元数据中心,

dubbo 服务引入
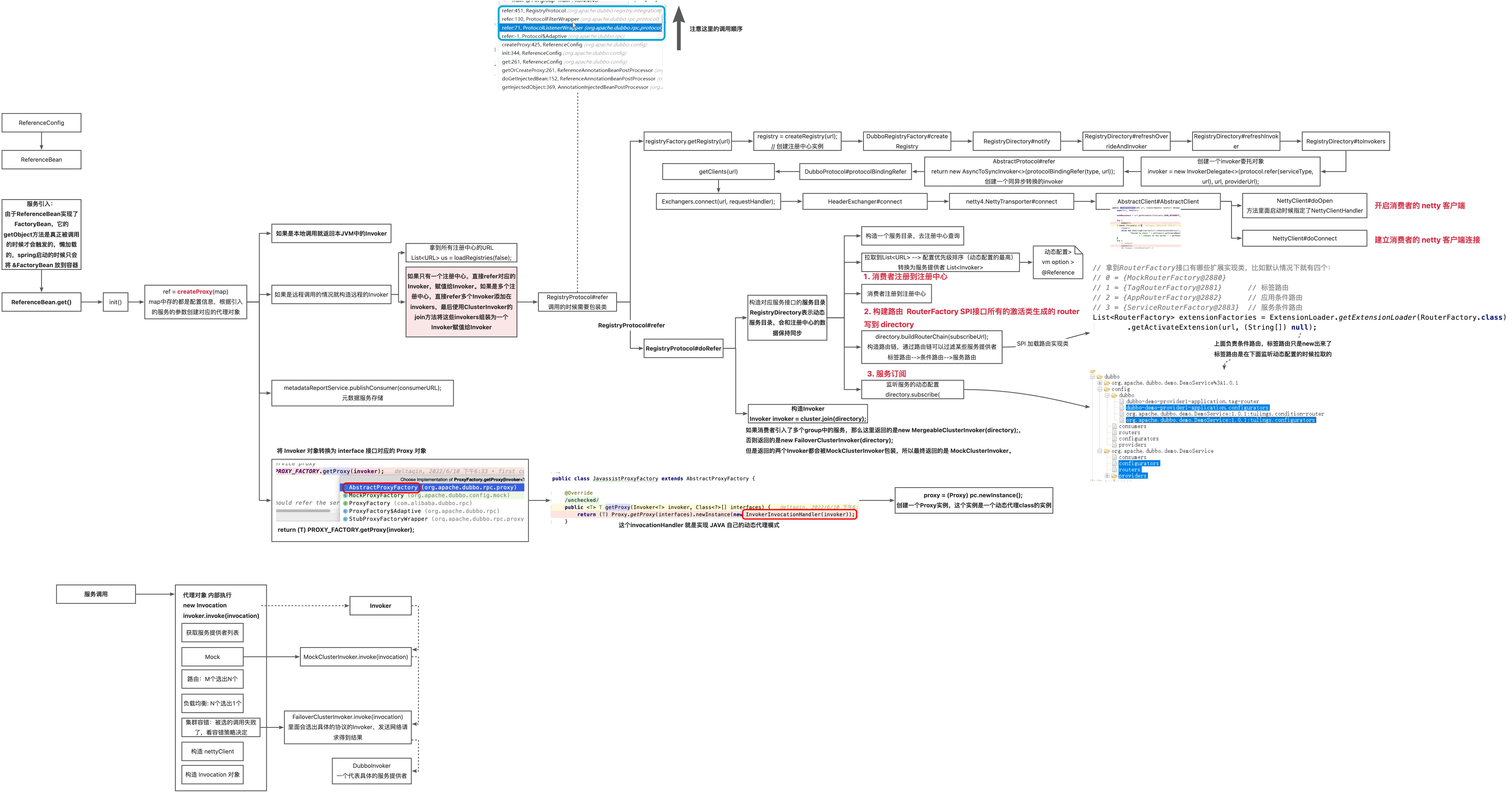
dubbo 服务调用
Protocol 对于提供者就是 export。引入就是 refer 方法。调用就是invoke方法

如何实现服务降级
调用服务发现抛出异常之后,直接调用自己本地的mock类或者方法
如何实现服务容错
调用失败的时候,首先是容错处理,处理不成功的时候才会开始降级,降级是最后的处理方案。
消费者在启动的时候,refer 内部使用用户指定的容错策略创建对应的容错实例 Invoker,之后用户发起调用的时候就是使用这个 Invoker,内部包含了不同的容错处理策略。
dubbo 的线程和线程池
根据实际情况选择对应的分配策略。
Dubbo对channel上的操作大致分类为5种:org.apache.dubbo.remoting.ChannelHandler
- 建立连接:connected,主要是的职责是在channel记录read、write的时间,以及处理建立连接后的回调逻辑,比如dubbo支持在断开后自定义回调的hook(onconnect),即在该操作中执行。
- 断开连接:disconnected,主要是的职责是在channel移除read、write的时间,以及处理端开连接后的回调逻辑,比如dubbo支持在断开后自定义回调的hook(ondisconnect),即在该操作中执行。
- 发送消息:sent,包括发送请求和发送响应。记录write的时间。
- 接收消息:received,包括接收请求和接收响应。记录read的时间。
- 异常捕获:caught,用于处理在channel上发生的各类异常。
在protocol下配置dispatcher: all,即可把dubbo协议的线程模型调整为All Dispatcher,这些类型决定了Dubbo对channel上的操作是在IO线程上处理还是 dubbo 的线程池中处理。
默认的 all 会导致所有的请求都会被从 workGroup 交给 dubbo 的线程池去处理。
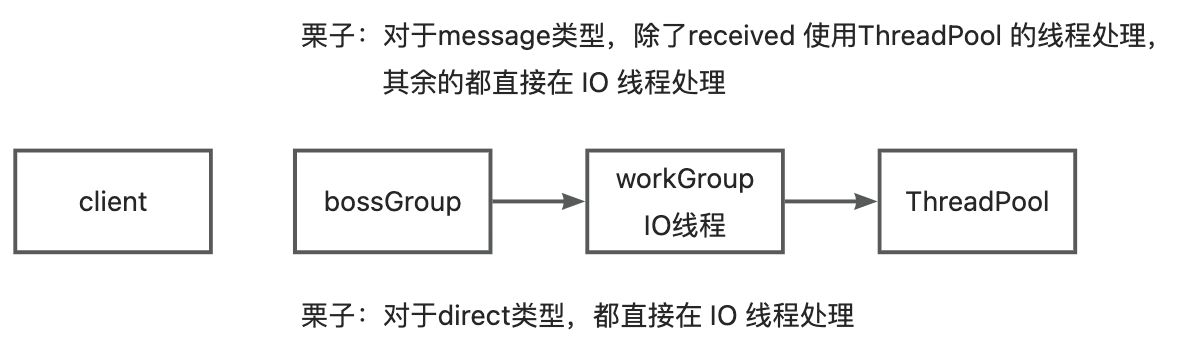
线程池暂略
dubbo 的Filter 链
dubbo3 新特性汇总
dubbo3 Triple协议与原本协议的对比
如果要定义自己的协议?
- header:一般header都是定长的。可以采用定义数据的长度的方法解决粘包拆包。包含调用的协议调用的方法,是否需要返回,以及魔数。
- body 的内容需要序列化和反序列化
dubbo 协议:header 16字节,每一个部分:
传输协议就是通信协议,双方都会对传输的数据做约定,速度和安全都是需要保障的,
dubbo 3 的标准协议,就是 dubbo 和 triple。
-
HTTP1的劣势与HTTP2的优势
-
Http2之数据帧与Stream介绍
-
Triple协议服务调用底层原理
-
Triple协议服务响应底层原理
-
Triple流式调用底层原理分析
dubbo3 应用级别服务注册
以前是接口级别注册服务的接口,如果一个应用本来提供了三个接口,就会在注册中心有三条记录,如果新增一台机器实例部署Provider,在注册中心就会多出一套,变为六条记录。这样节点提供接口频繁变动的时候注册中心的节点就会频繁变动,增加注册中心的维护压力,这样不好。
改为和SpringCloud一样的,应用级别的服务注册,就可以减少注册中心中维护的服务提供者的节点数据变化的频率。不是接口维度的,而是应用维度的。
选型总结
| Dubbo | Feign | Thrift | grpc | |
|---|---|---|---|---|
| 优点 | ||||
| 缺点 | ||||
| 使用场景 | ||||
- 面向互联网的应用场景,更加注重MQ的吞吐量,需要将消息尽快的保存下来,再供后端慢慢消费。
- Kafka是第一个场景的不二代表
- 针对企业内部的应用场景,更加注重MQ的数据安全性,在复杂多变的业务场景下,每一个消息都需要有更加严格的安全保障。
- RabbitMQ作为一个老牌产品,是第二个场景最 有力的代表。
posted on 2025-10-13 17:43 chuchengzhi 阅读(11) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号