
Redis核心数据类型的底层编码(C源码)(重要)
Redis K-V 底层设计原理:字典hashtable
key:string
val:string、hash、list、set、sorted set
map 就是字典,还要支持海量数据的存储,查找和插入删除(hashtable)
hashtable 里面 hash(key) % hashtable.size ,最后的得到的就是[0, hashtable.size - 1]
hash碰撞的时候,线性探测或者链表法。Redis 使用的是链表法
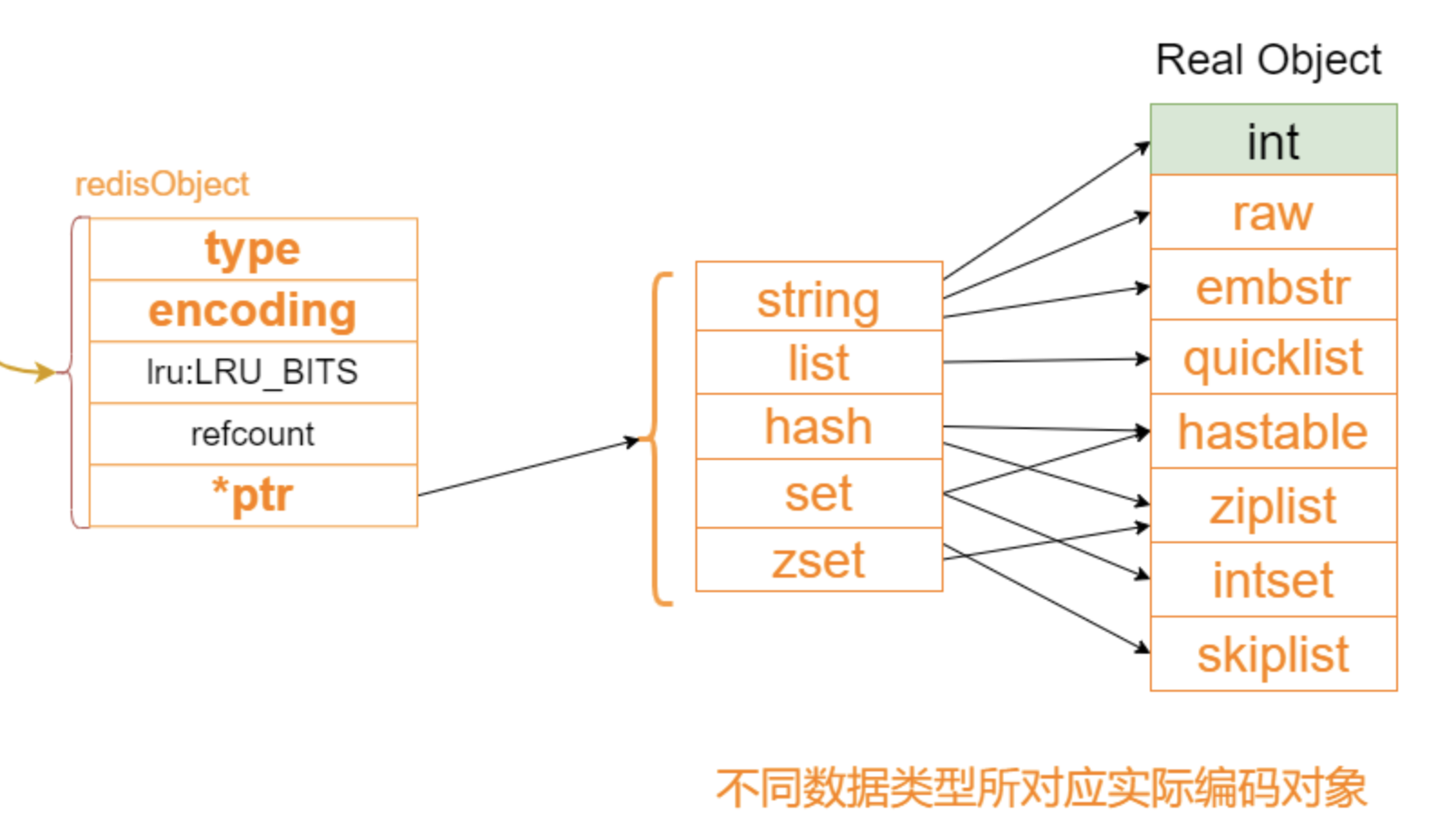
注意这个hashtable里面的value的类型是五种常见类型谁都可以放,因为最后都是使用指针指向的,value的包装类里面会执行是什么数据类型。
redisDb--dict--dictht--dictEntry--redisObject
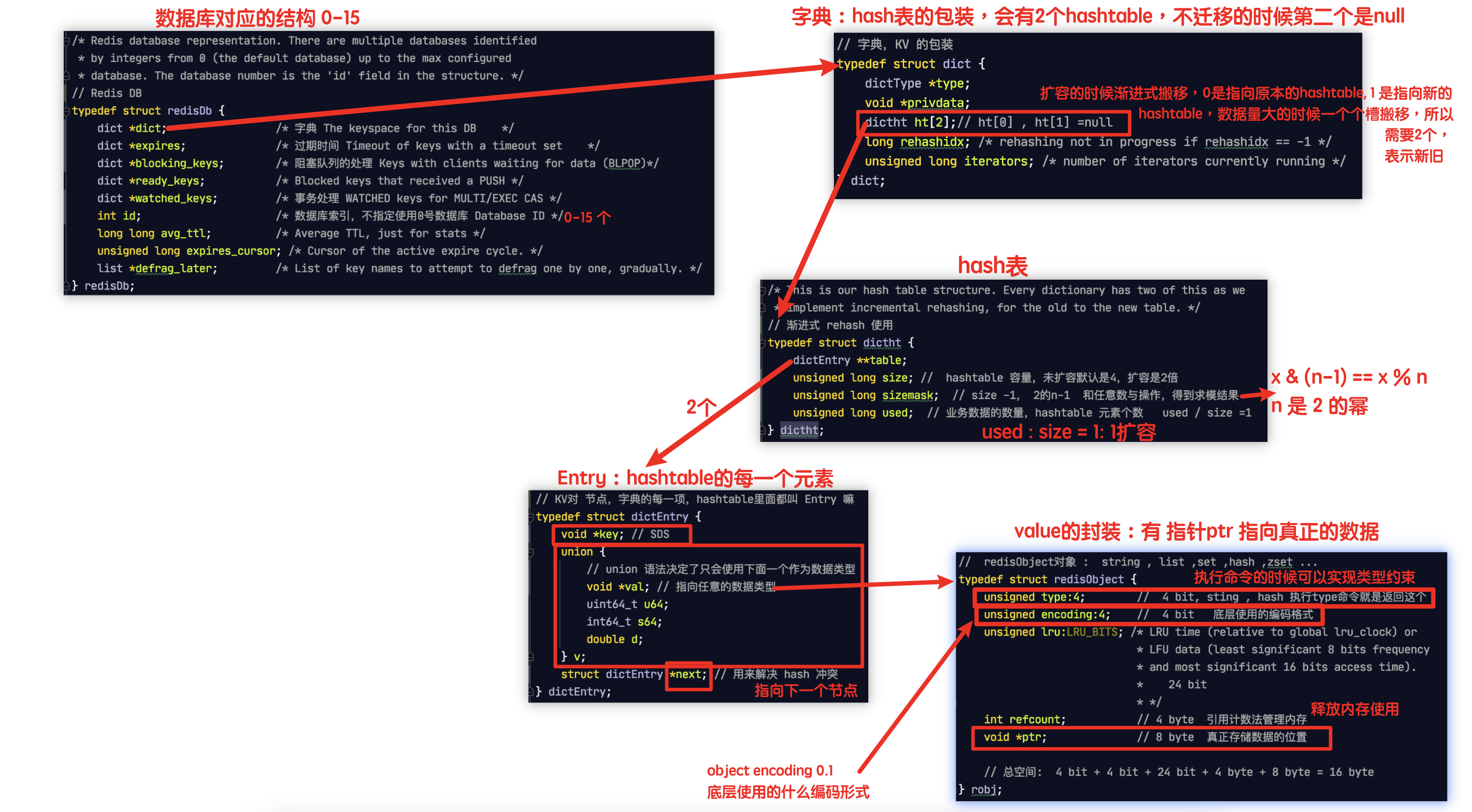
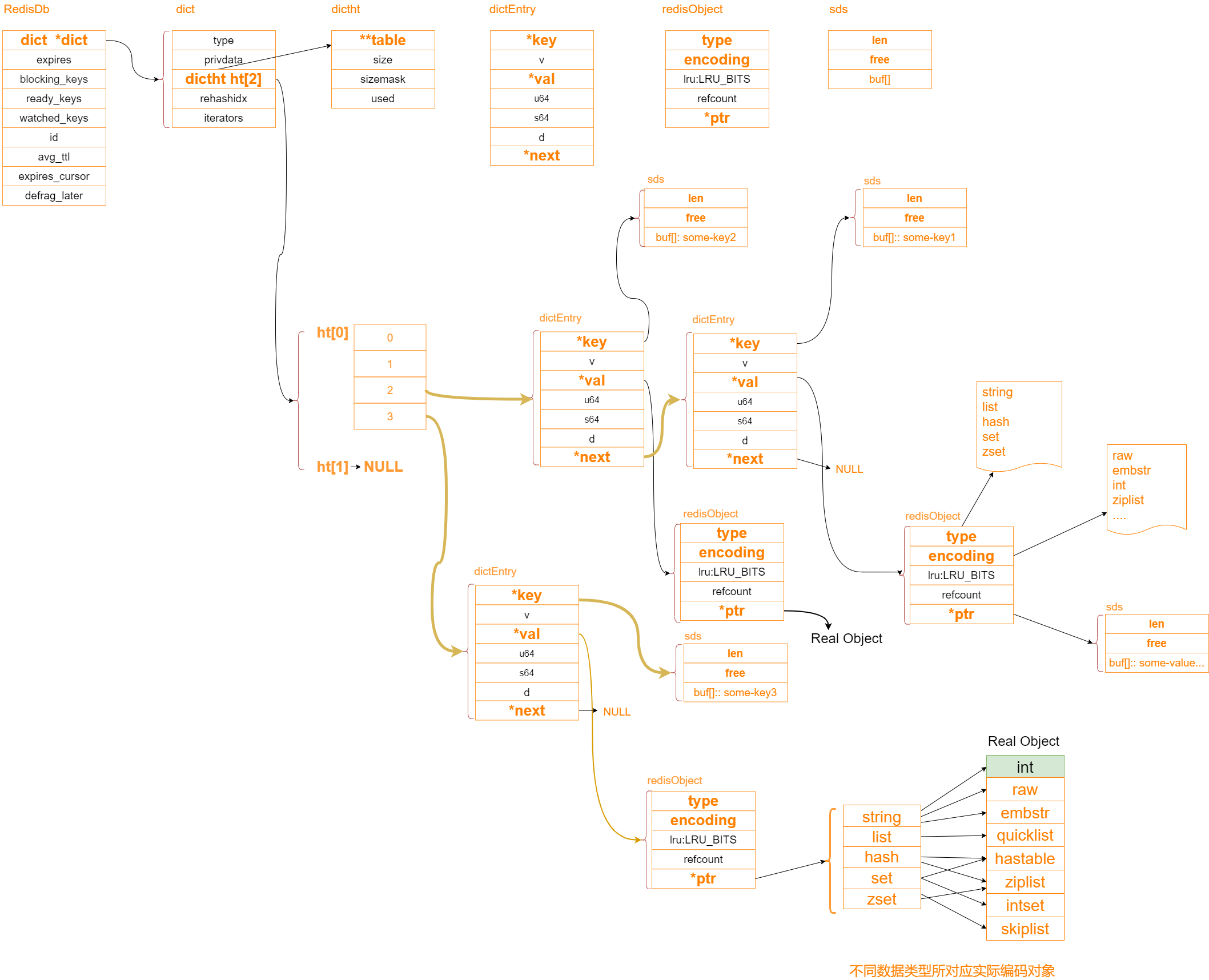
Redis 渐进式rehash及动态扩容机制
如图所示,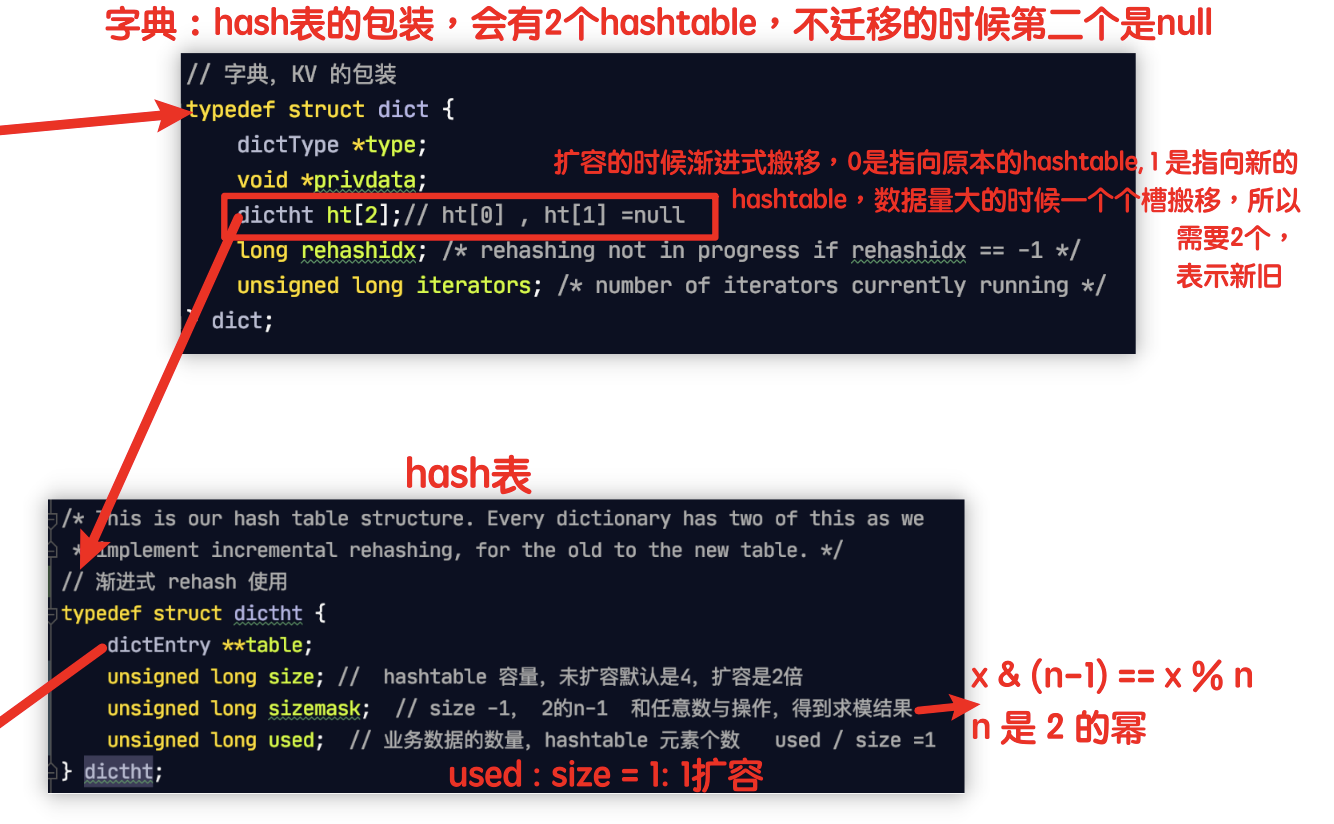
- 扩容时机:在使用的容量是大小的一样的时候就会扩容,
- 扩容大小:扩容的时候变为原来的2倍,
- 渐进式迁移:新建数组之后,数据迁移的时候,一个链表上的数据是一个桶为单位转移的,不能一下全部转移会导致单线程阻塞,所以有了渐进式rehash的设计,dict字典包装类里面是有新旧两个hash表ht[2],不转移的时候第二个就是null。最后迁移结束之后就会使用新的替换旧的
注意 hash表是可以存各种类型的,毕竟最后都是使用指针指向的。
Redis核心编码结构精讲(区分开数据类型)
查找源码技巧
在src/server.c里面有很多的命令对应的,点进去就可以看到执行流程
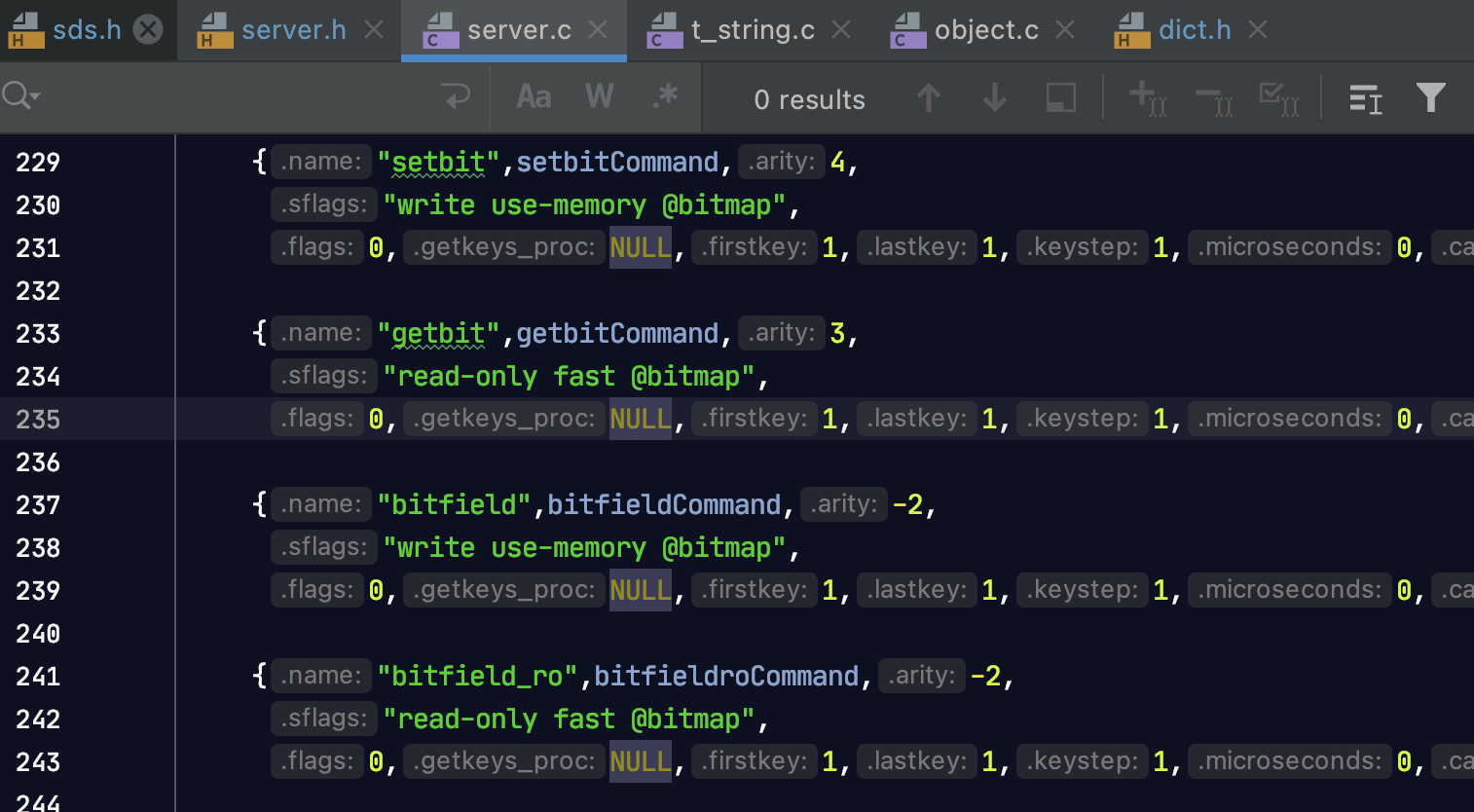
数据类型和数据编码的关系
help @list
为什么不直接使用C语言的字符串要自己实现SDS?
C语言是字符数组,结束的标志是\0出现就是结尾。
二进制安全
Redis 是一个分布式缓存中间件和各种语言交互,直接使用C语言作为接收的方式自动会加上一个\0字符,使用C语言读取的时候可能会把数据截断,后面还有也读取不到,
自己定义的简单动态字符串SDS结构,是一个二进制安全的数据结构:
sds:
free: 0
len: 9
char buf[] = "delt\0aqin"
内存预分配机制:空间换时间
- 修改字符串的时候,C语言需要重新分配一个空间,浪费时间。
- SDS,
free字段表示buffer还有多少剩余的空间,len表示当前占用多少空间,扩容的时候会稍微分配一个大一点的空间,扩容的时候最后的buffer大小是(len+addlen)*2 - len是 1024*1024 的时候就不会成倍扩容了。而是每次加1M的空间
- 可以一次分配大一点的空间,避免频繁分配
下面的场景发生在append 以及 setbit(底层实现是字符串)的场景里面。
sds:
free: 0
len: 9
char buf[] = "deltaqin" --> "deltaqin11"
-----------
len: 9
addlen: 2
(len + addlen) * 2 = 22
-----------
都是成倍扩容的
sds:
free: 11
len: 11
char buf[] = "deltaqin11"
兼容C语言的函数库
自动在结尾加上 \0 字符
SDS( embstr+raw )--string
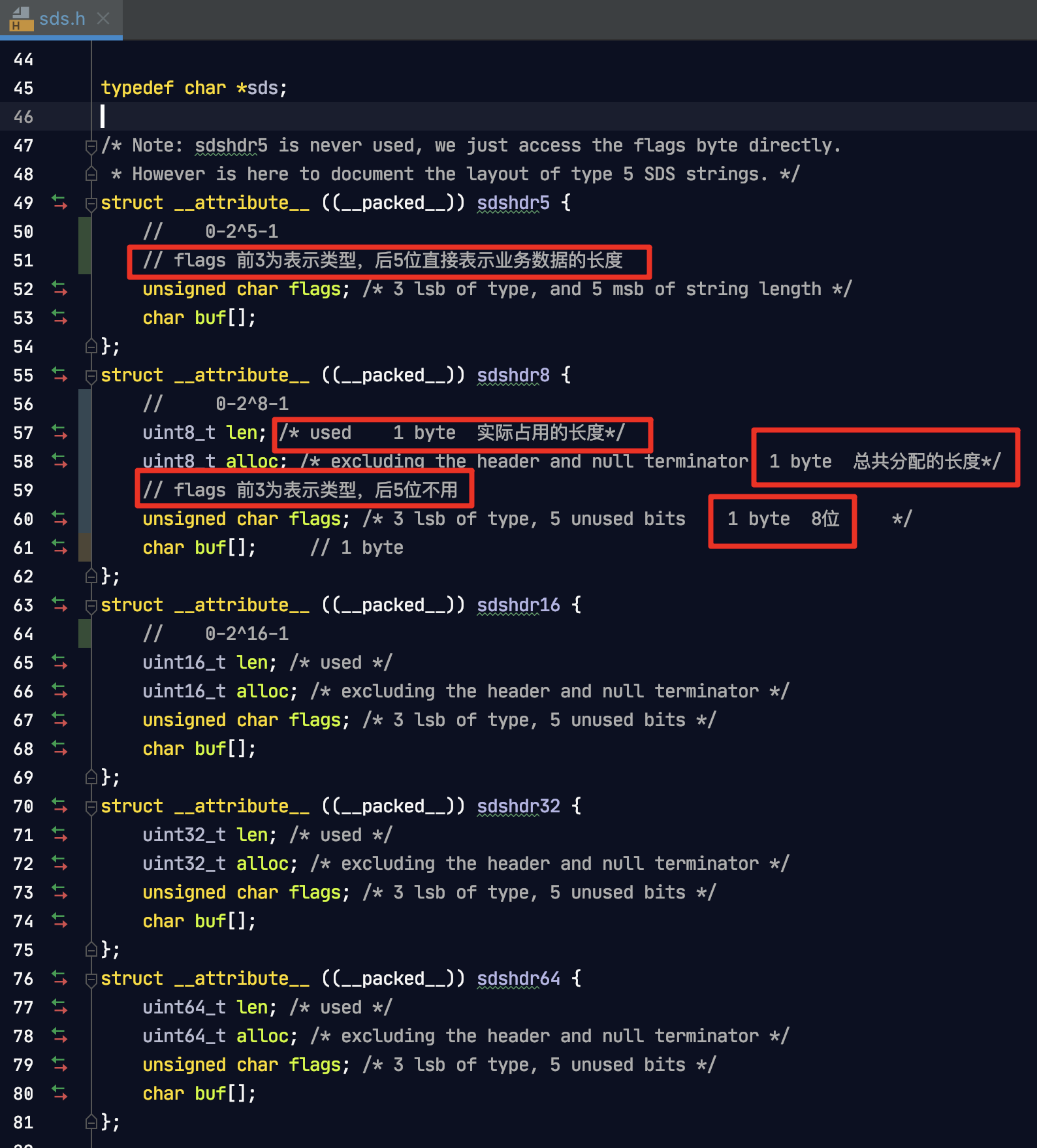
3.2以前
struct sdshdr {
int len; // 32位,0-2^32-1,浪费空间,42亿多的数据
int free; // 32位
char buf[]; // 真实存数据的,数据比较少,次数用的多
};
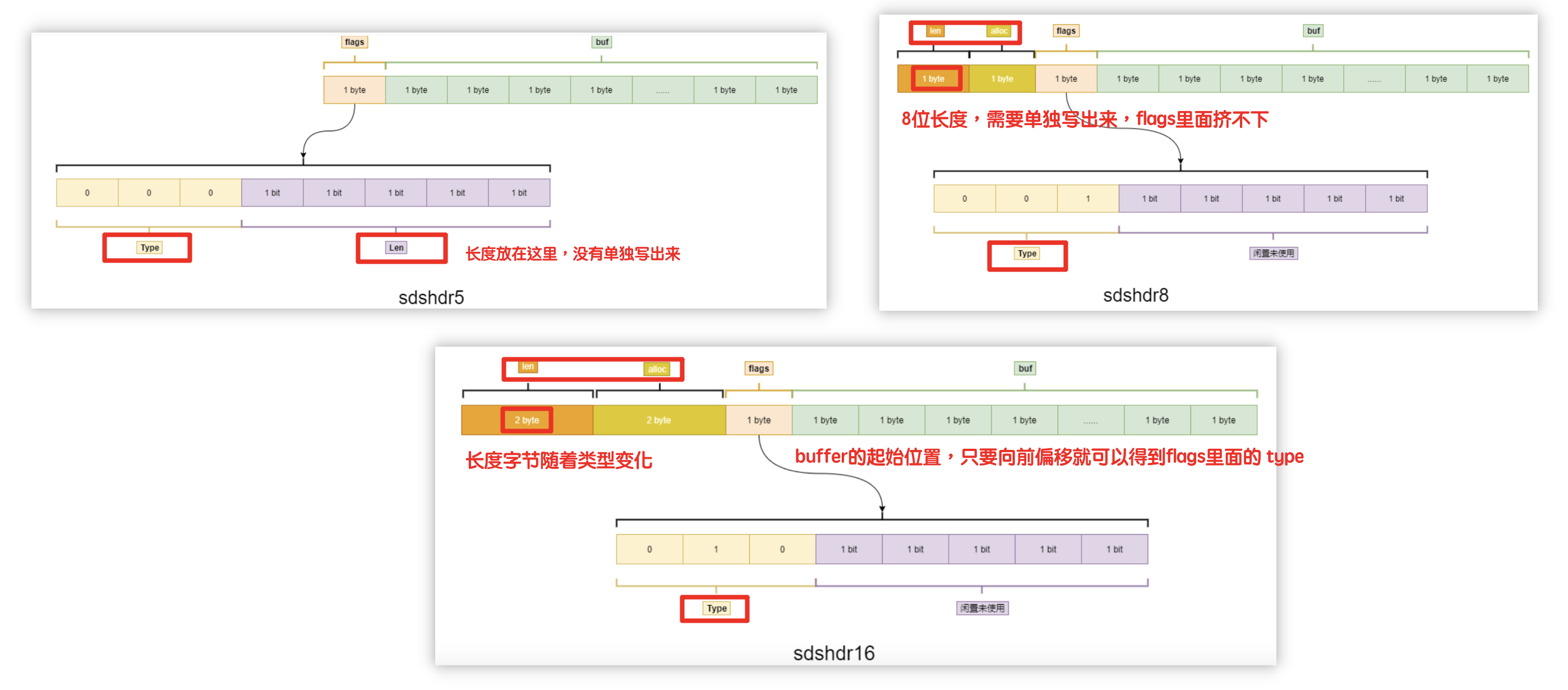
3.2以后
拆分为很多的类型
根据业务数据量得到具体的类型用什么
embstr嵌入式字符串--SDS的优化
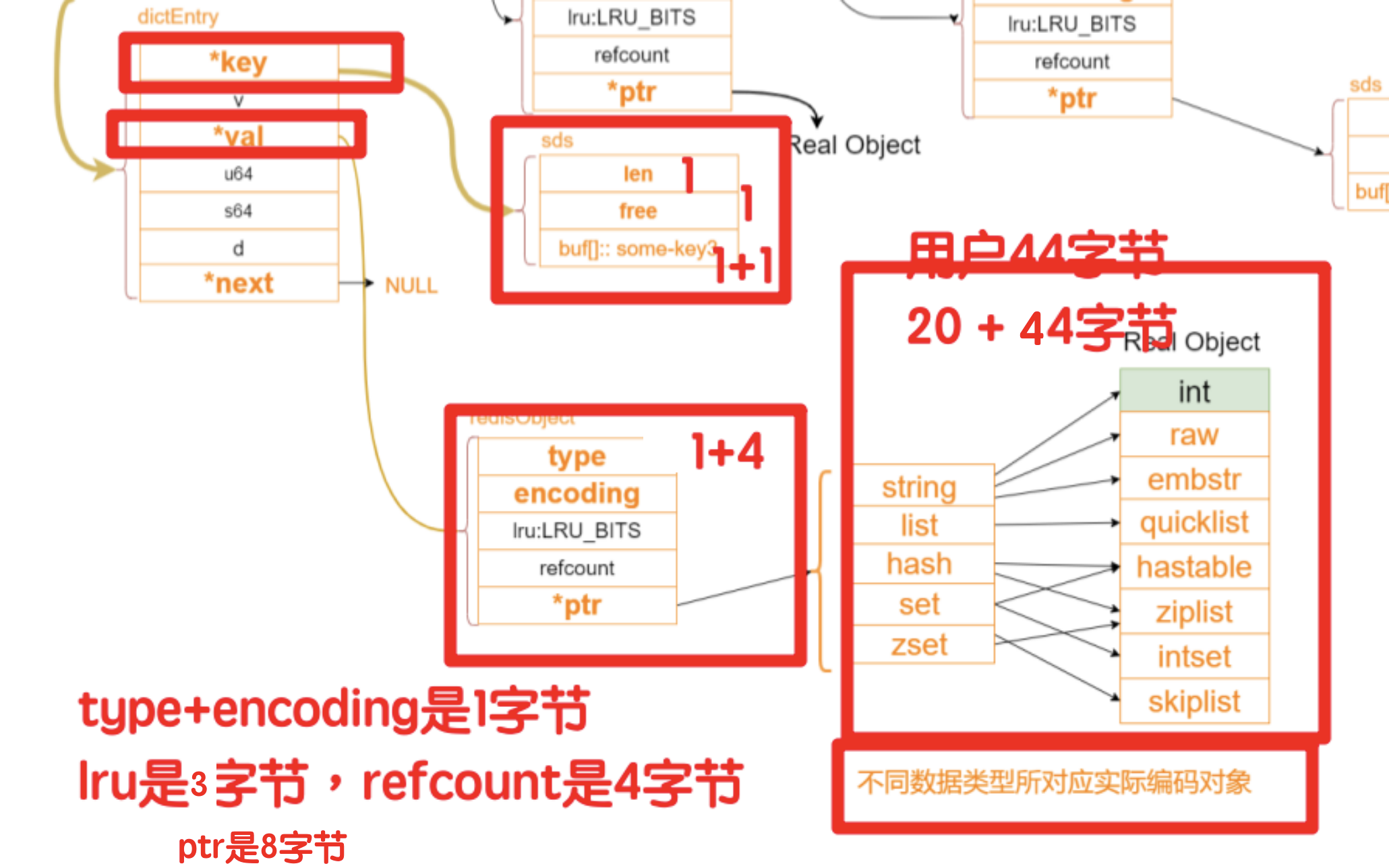
内容只有44字符也就44字节的时候,在64位机器上的缓存行的长度就是64位,计算可以看到 RedisObject 大小是16字节,加上key 的4字节(sds ,\0也是一个字节),最后占满一个缓存行。减少内存的IO。
如果是45个字符作为val 就是会得到raw的编码类型
raw--原始的SDS格式
ziplist
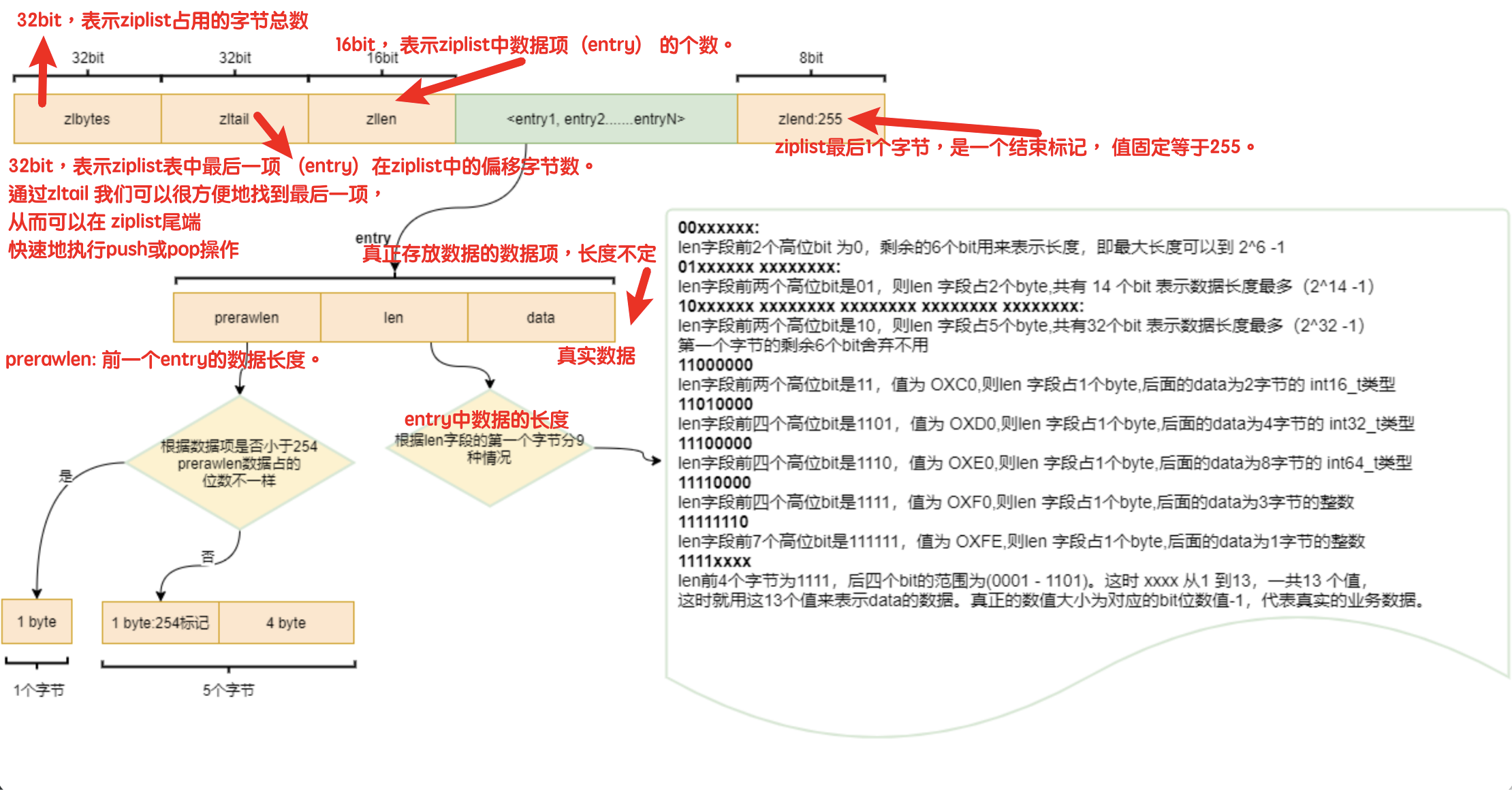
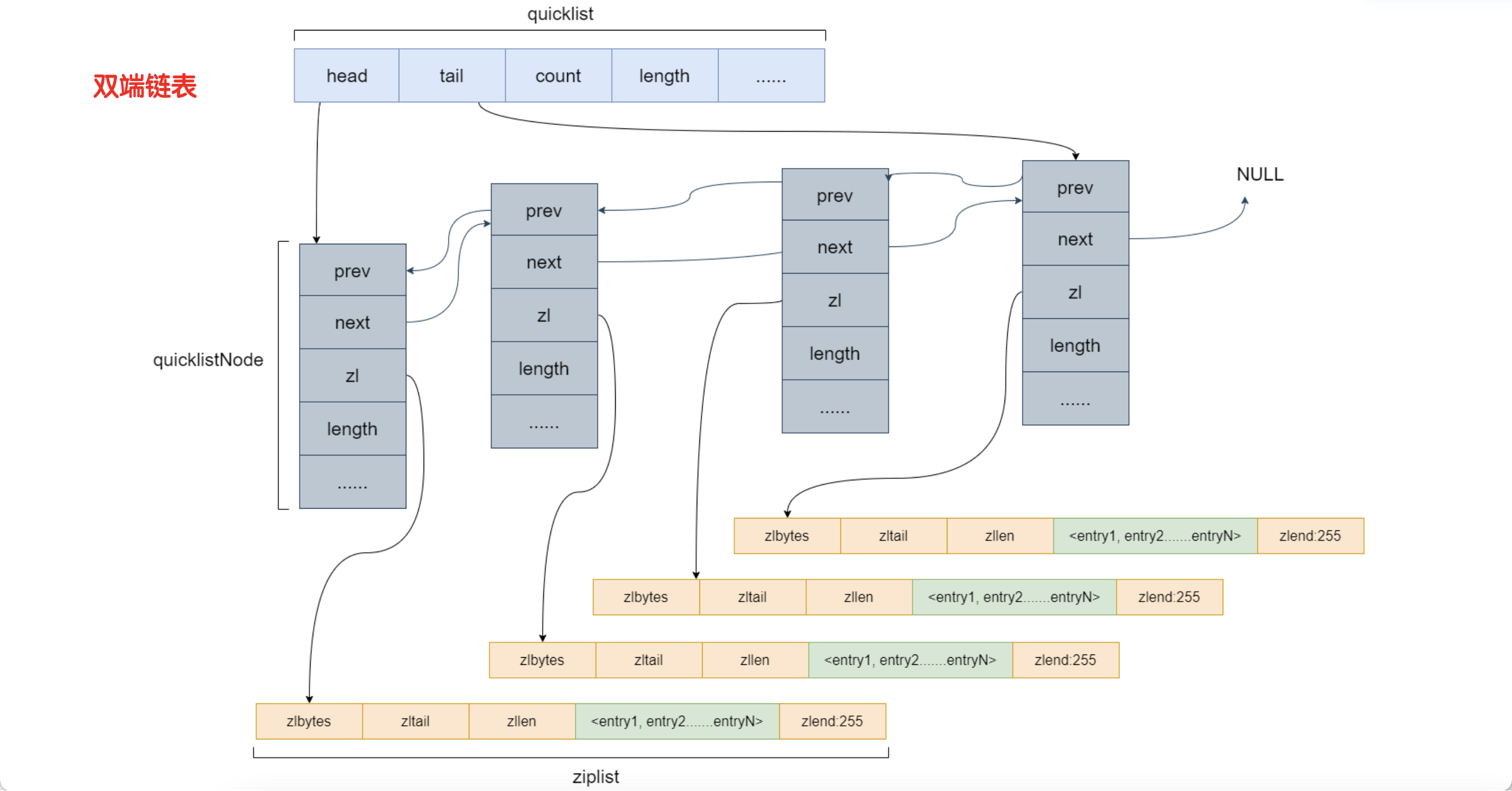
quicklist--list
Redis采用quicklist(双端链表) 实现List ,快表又依赖 ziplist 。
快表的每一个节点都会指向压缩表。节点和节点之间实现是链表。
直接使用链表会产生大量的内存碎片,所以为了减少碎片但是保留list的的特性,对list的数据进行局部的聚集,局部使用数组来存放,这个数据就是 ziplist 压缩表实现的。
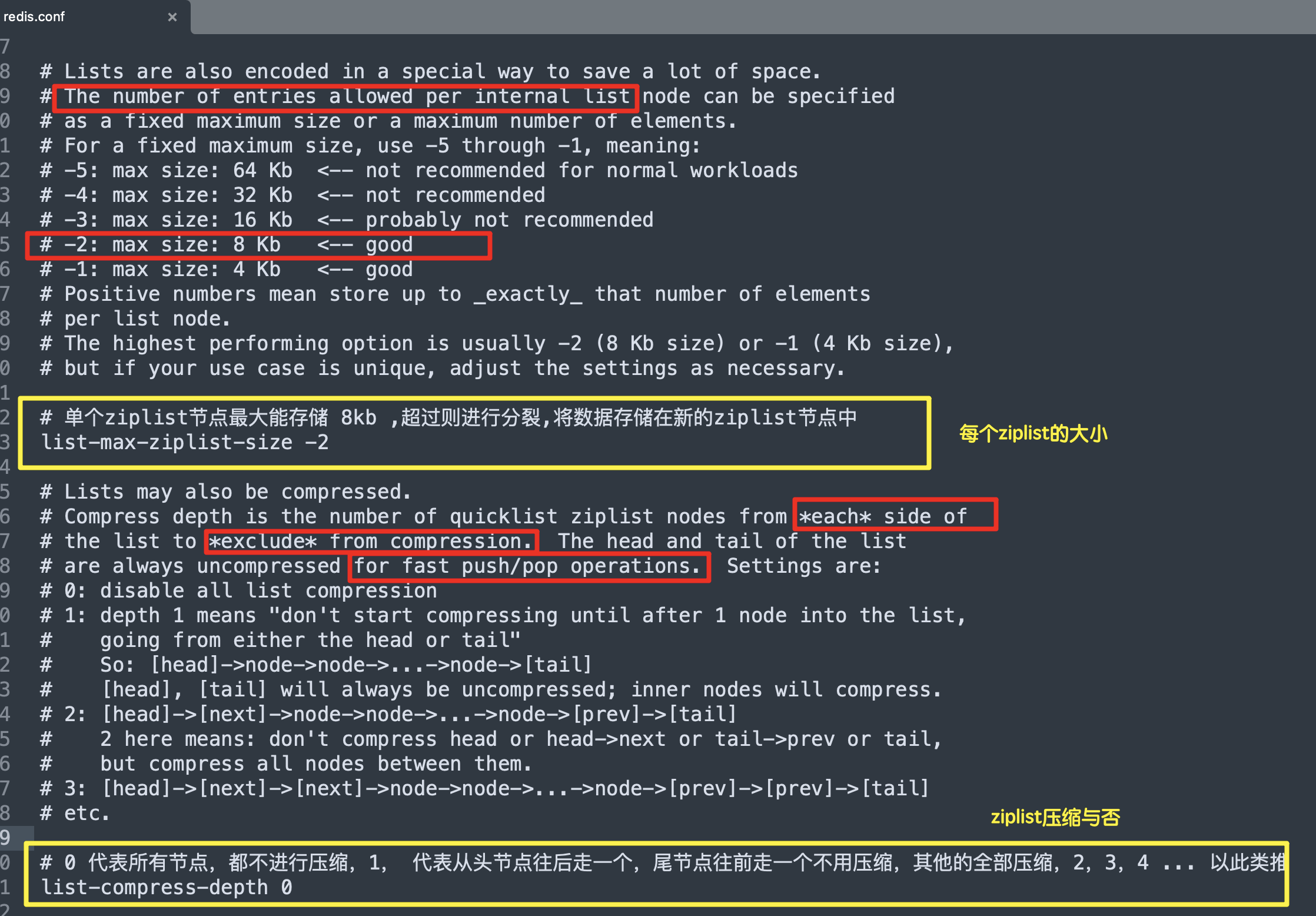
优化压缩表的参数,提升存取效率:
- 设置最大的分裂阈值:
list-max-ziplist-size -2, - 设置压缩的排除范围:
list-compress-depth 1
ziplist 或 hashtable--hash
/> help @hash
HSET key field value [field value ...]
HGET key field
HMGET key field [field ...]
HKEYS key
HGETALL key
HVALS key
HEXISTS key field
HDEL key field [field ...]
HINCRBY key field increment
HINCRBYFLOAT key field increment
HLEN key
HSCAN key cursor [MATCH pattern] [COUNT count]
HSETNX key field value
HSTRLEN key field
- 数据量少的时候,直接使用ziplist编码。这个时候直接查看set的元素是有序的
- hash-max-ziplist-entries 512 // ziplist 元素个数超过 512 ,将改为hashtable编码
- hash-max-ziplist-value 64 // 单个元素大小超过 64 byte时,将改为hashtable编码
- 数据量大的时候,直接使用hashtable编码,此时再查看元素就是无序的

intset 或 hashtable--set
SADD key member [member ...]
summary: Add one or more members to a set
SCARD key
summary: Get the number of members in a set
SISMEMBER key member
summary: Determine if a given value is a member of a set
SMEMBERS key
summary: Get all the members in a set
SPOP key [count]
summary: Remove and return one or multiple random members from a set
SRANDMEMBER key [count]
summary: Get one or multiple random members from a set
SREM key member [member ...]
summary: Remove one or more members from a set
SSCAN key cursor [MATCH pattern] [COUNT count]
summary: Incrementally iterate Set elements
SDIFF key [key ...]
summary: Subtract multiple sets
SDIFFSTORE destination key [key ...]
summary: Subtract multiple sets and store the resulting set in a key
SINTER key [key ...]
summary: Intersect multiple sets
SINTERSTORE destination key [key ...]
summary: Intersect multiple sets and store the resulting set in a key
SUNION key [key ...]
summary: Add multiple sets
SUNIONSTORE destination key [key ...]
summary: Add multiple sets and store the resulting set in a key
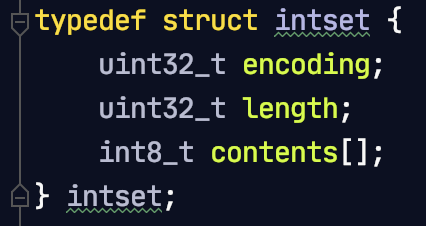
Set 为无序的,自动去重的集合数据类型,Set 数据结构底层实现为一个value 为 null 的 字典 ( dict ),当数据可以用整形表示时,Set集合将被编码为intset数据结构。两个条件任意满足时 Set将用hashtable存储数据:
- 元素个数大于 set-max-intset-entries
- 元素无法用 整形表示
intset 是有序的,使用这个是因为字典耗费空间,可以用整型就直接使用整型表示,
encoding: 编码类型 length: 元素个数 contents[]: 元素存储
二分查找
ziplist 或 skiplist--zset
/> help @sorted_set
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]
ZCARD key
ZCOUNT key min max
ZINCRBY key increment member
ZRANGE key start stop [WITHSCORES]
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
ZRANK key member # Determine the index of a member in a sorted set
ZREM key member [member ...]
ZREMRANGEBYRANK key start stop
ZREMRANGEBYSCORE key min max
ZREVRANGE key start stop [WITHSCORES]
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
ZREVRANK key member
ZSCAN key cursor [MATCH pattern] [COUNT count]
ZSCORE key member
ZSet 为有序的,自动去重的集合数据类型,ZSet 数据结构底层实现为 字典(dict) + 跳表 (skiplist) ,
ziplist:
- 当数据比较少时,用ziplist编码结构存储。
- zset-max-ziplist-entries 128 // 元素个数超过128 ,将用zskiplist编码
- zset-max-ziplist-value 64 // 单个元素大小超过 64 byte, 将用 zskiplist编码

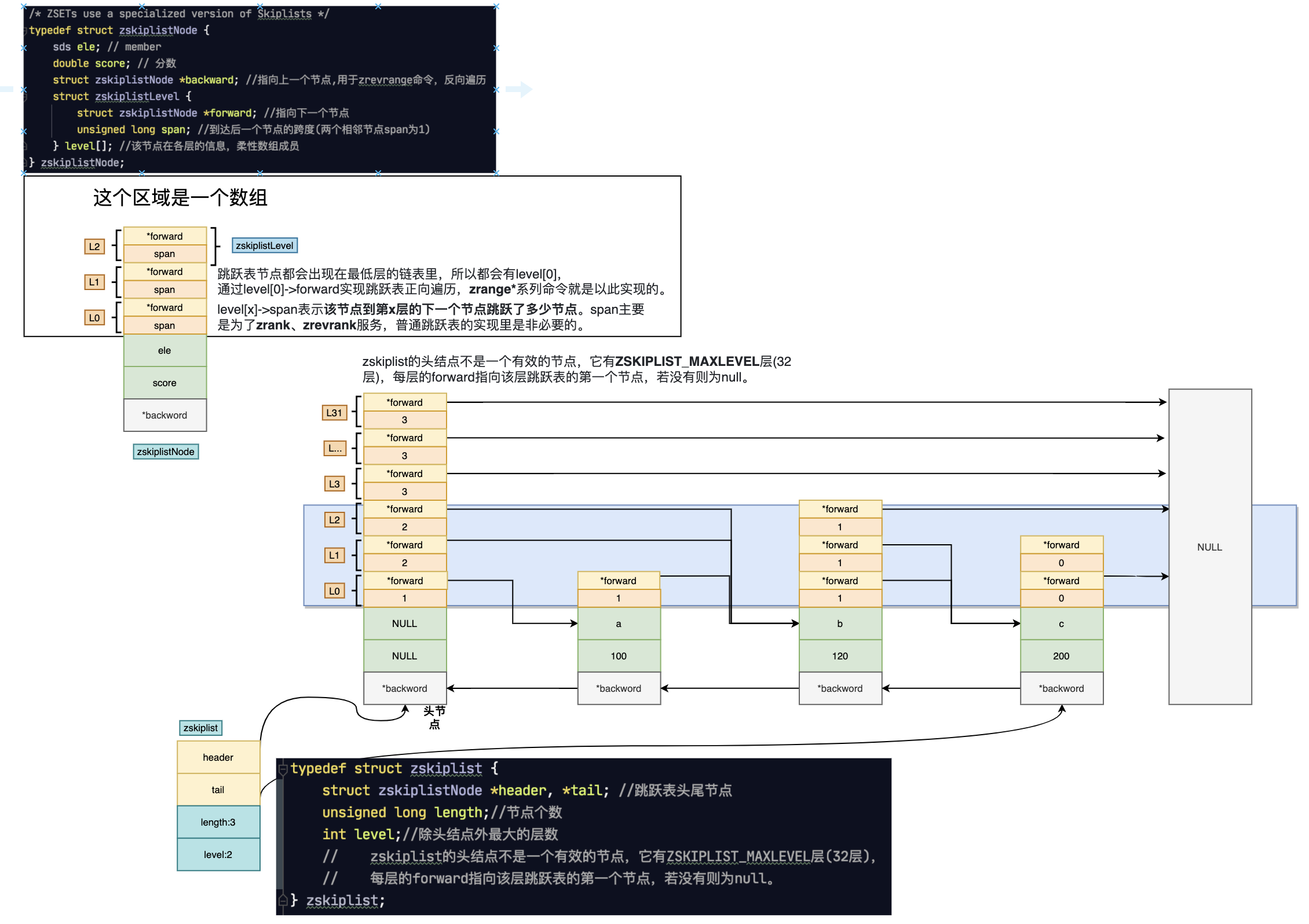
字典 dict + 跳表 zskiplist
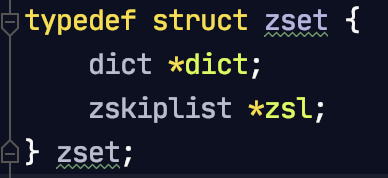 字典是为了使用field查询分数的时候方便,跳表是为了使用范围查询以及查询前几名的时候方便。
字典是为了使用field查询分数的时候方便,跳表是为了使用范围查询以及查询前几名的时候方便。
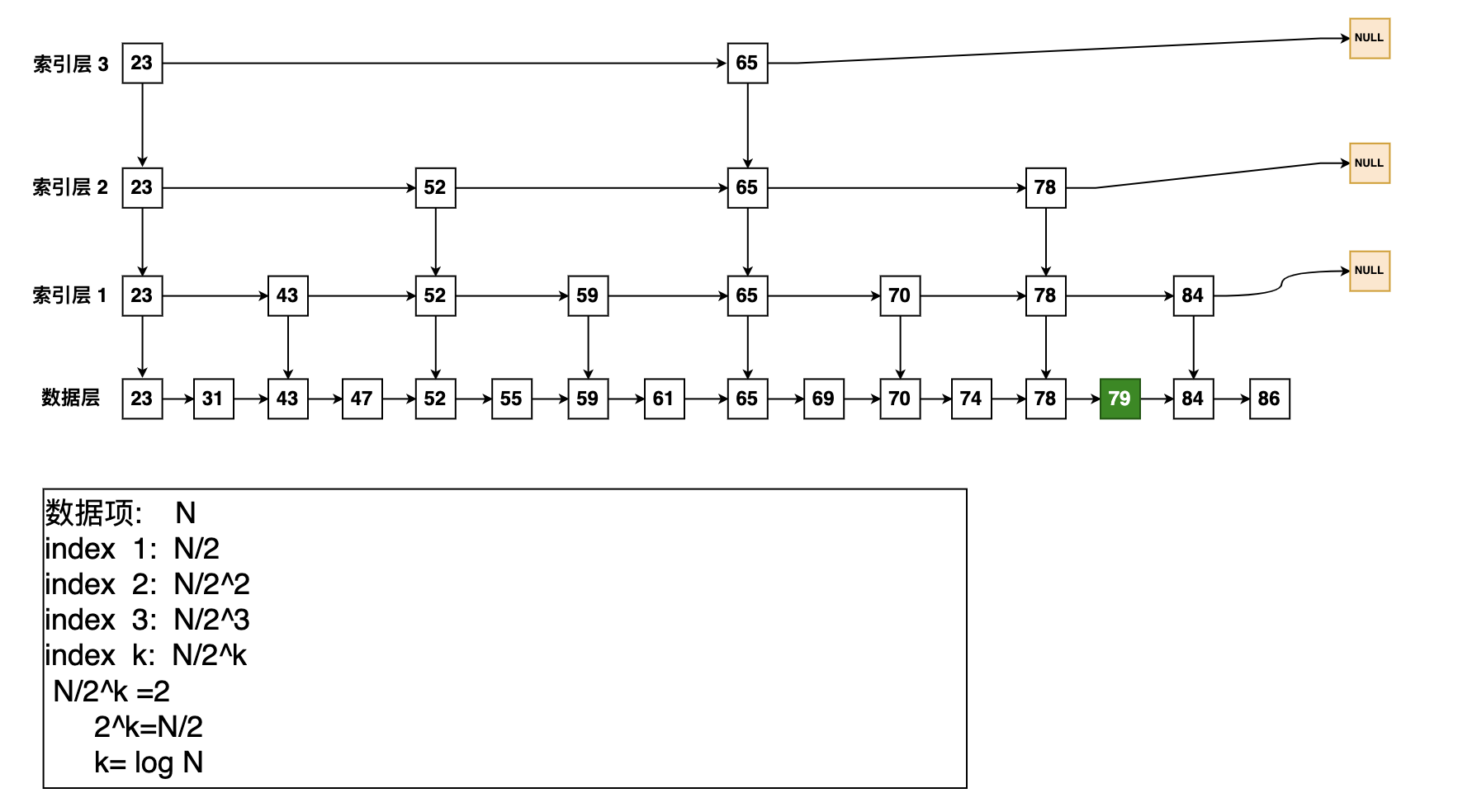
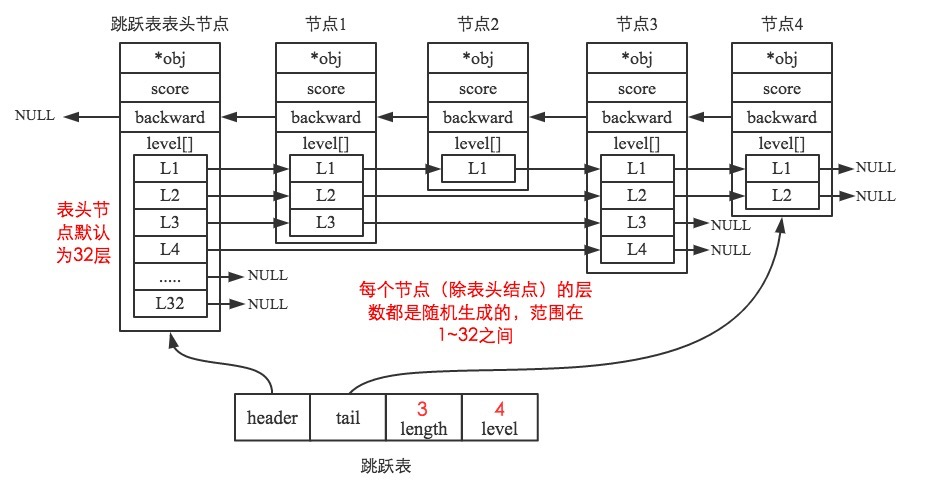
跳跃表作为底层实现,它在添加、删除、查找节点上都拥有与红黑树相当的性能,它其实说白了就是一种特殊的链表,链表的每个节点存了不同的“层”信息,用这种分层存节点的方式在查找节点时能跳过些节点,从而使添加、删除、查找操作都拥有了O(logn)的平均时间复杂度。
跳表操作:
- 每次查找的时候从最高层开始查找,找到一个小于等于target的最大节点。就停止进入下一层。直到到达最后一层,由于高层的查找会跳过间隔之间的一些点,所以提高查询效率。
- 跳表插入的时候先查找要插入的位置,之后都会在最底层插入,但是是否还要在上层重复“插入”是一个概率事件,Redis里面是1/4的概率会重复插入。没上一层的概率是1/4。(注意上层的插入不是真的插入,就是维护一下level数组的信息,有几层就维护几个元素的数据)
应用Geo
GeoHash是一种地理位置编码方法。 将地理位置编码为一串简短的字母和数字。它是一种分层的空间数据结构,将空间细分为网格形状的桶,这是所谓的z顺序曲线的众多应用之一,通常是空间填充曲线。
Hash经纬度编码
- 二维变为一维的可排序、可比较的的字符串编码
- 最后得到的编码就是z阶曲线
- 每5位一个,十进制就是32,base32编码得到一个字符串,越相似地理位置越近,只有一个范围没有精准的位置,不精准,
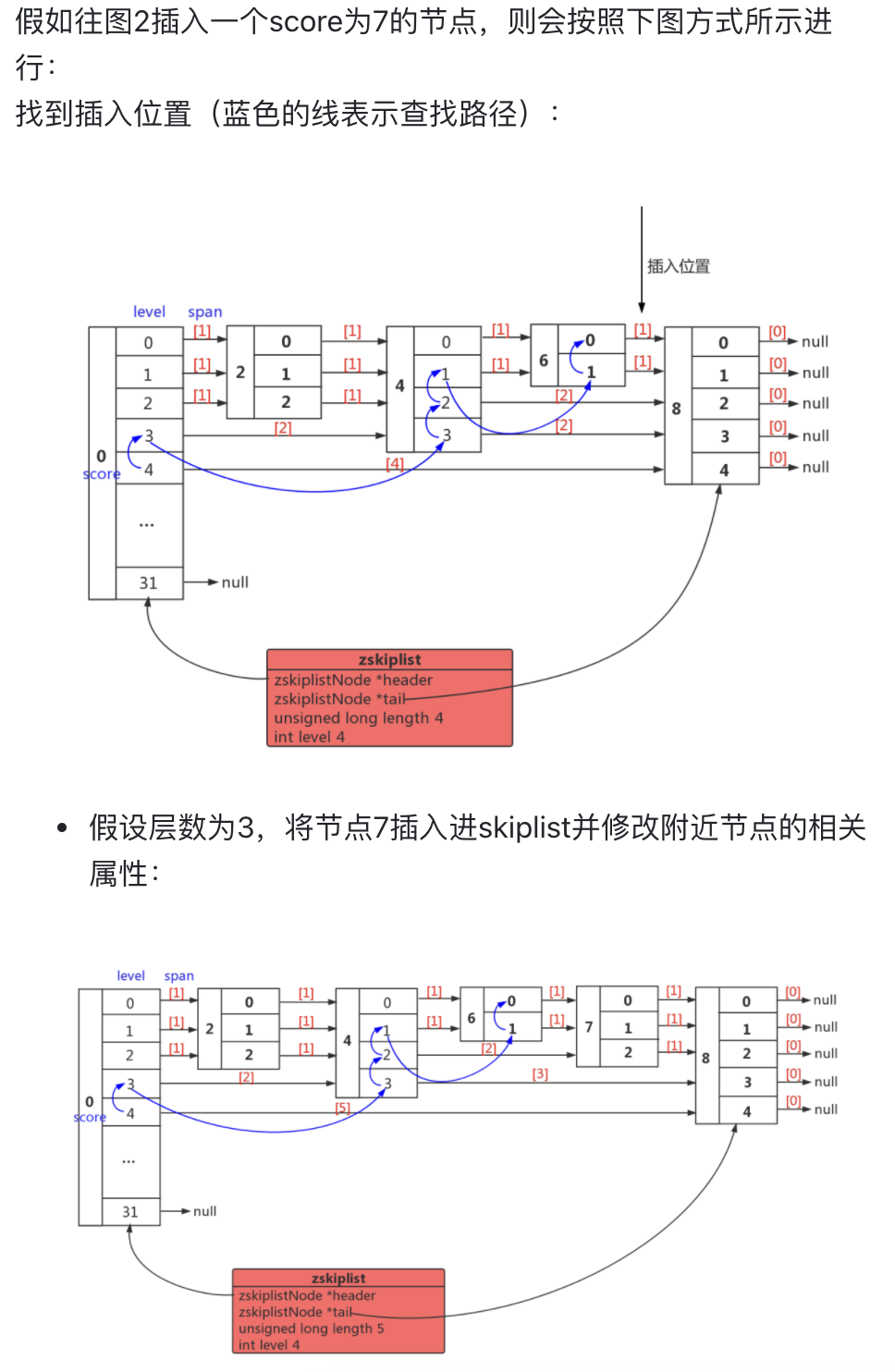
经度范围是东经180到西经180,纬度范围是南纬90到北纬90,我们设定西经为负, 南纬为负,所以地球上的经度范围就是[-180, 180],纬度范围就是[-90,90]。 如果以本初子午线、赤道为界,地球可以分成4个部分。
如果纬度范围[-90°, 0°)用二进制0代表,(0°, 90°]用二进制1代表,经度范围[-180°, 0°)用二进制0代表, (0°, 180°]用二进制1代表,那么地球可以分成如下(左图 )4个部分
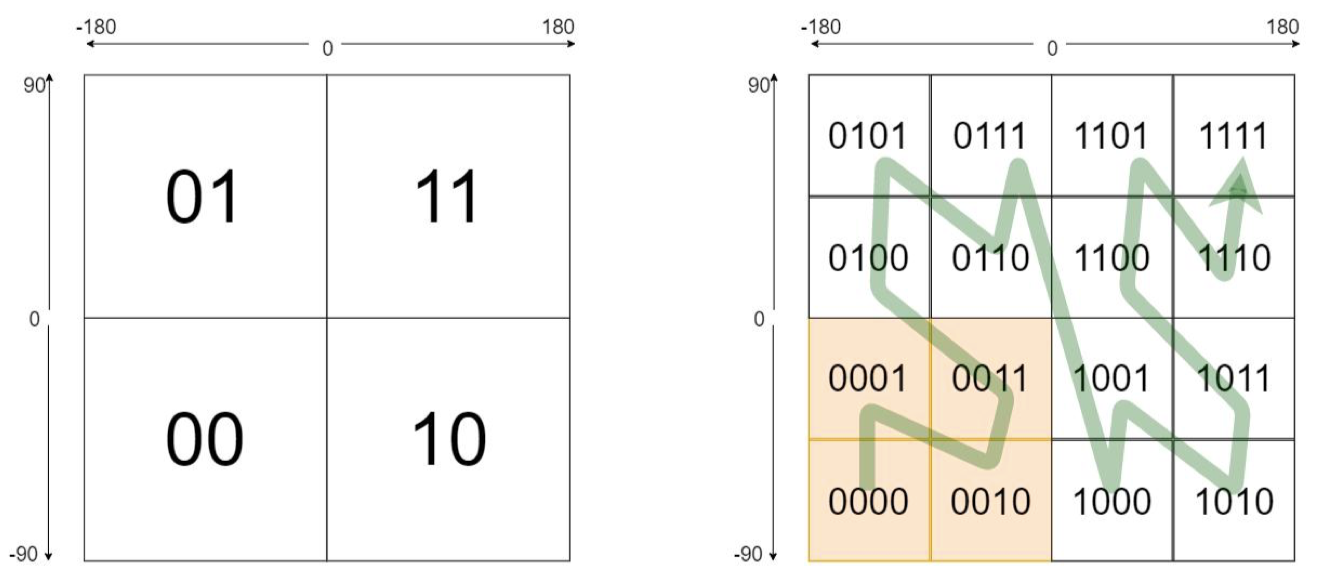
在编码中的 每个字符代表一个区域,并且前面的字符是后面字符的父区域:
根据GeoHash 来计算 纬度的 二进制编码 地球纬度区间是[-90,90], 如某纬度是39.92324,可以通过下面算法来进行维度编码:
1)区间[-90,90]进行二分为[-90,0),[0,90],称为左右区间,可以确定39.92324属于右区间[0,90],给标记为1 2)接着将区间[0,90]进行二分为 [0,45),[45,90],可以确定39.92324属于左区间 [0,45),给标记为0
3)递归上述过程39.92324总是属于某个区间[a,b]。随着每次迭代区间[a,b]总在缩小,并越来越逼近39.928167
4)如果给定的纬度(39.92324)属于左区间,则记录0,如果属于右区间则记录1,这样随着算法的进行会 产生一个序列1011 1000 1100 0111 1001,序列的长度跟给定的区间划分次数有关。
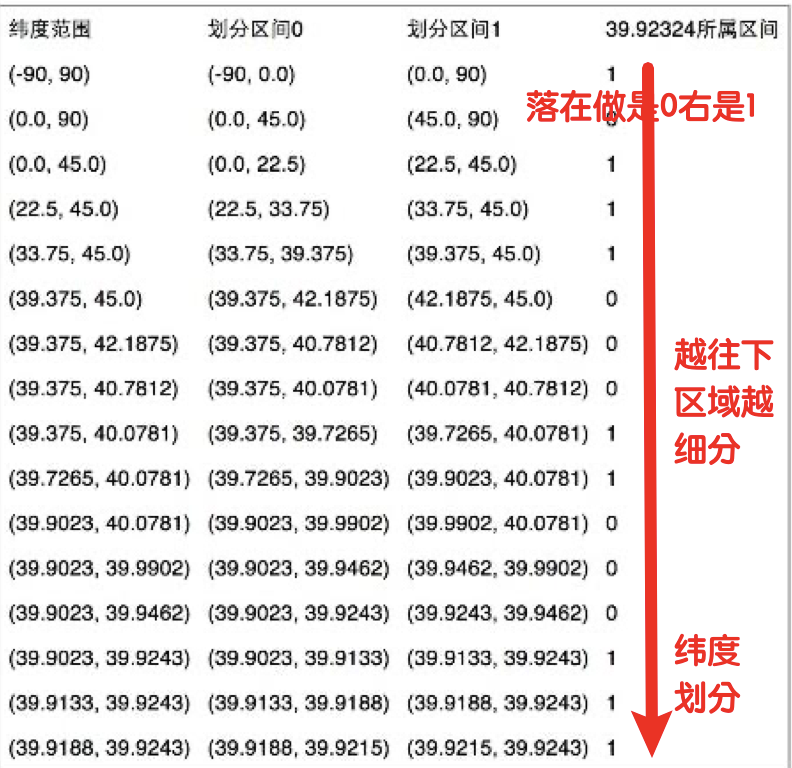
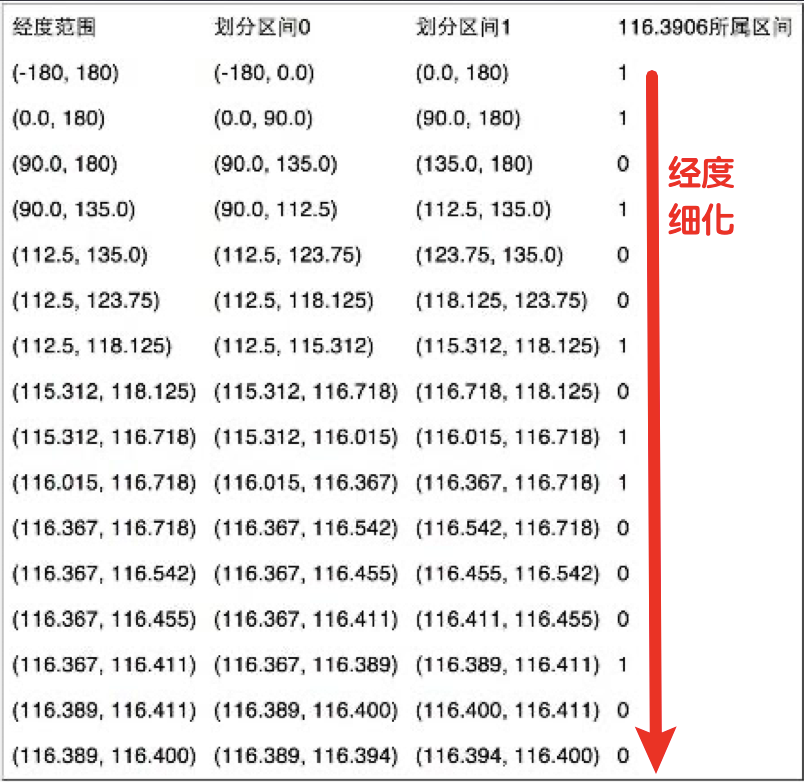
纬度产生的编码为1011 1000 1100 0111 1001,经度产生的编码为1101 0010 1100 0100 0100。 偶数位放经度,奇数位放纬度,把2串编码组合生成新串: 11100 11101 00100 01111 00000 01101 01011 00001。
最后使用用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码(5个一组),首先将11100 11101 00100 01111 00000 01101 01011 00001转成十进制 28,29,4,15,0,13,11,1,十进制对应的编 码就是wx4g0ec1。同理,将编码转换成经纬度的解码算法与之相反

- 优点:GeoHash利用Z阶曲线进行编码,Z阶曲线可以将二维所有点都转换成一阶曲线。地理位置坐标点通过编 码转化成一维值,利用 有序数据结构如B树、SkipList等,均可进行范围搜索。因此利用GeoHash算法 查找邻近点比较快
- 缺点:Z 阶曲线有一个比较严重的问题,虽然有局部保序性,但是它也有突变性。在每个 Z 字母的拐角,都有可能出现顺序的突变。
与红黑树比较
- 缺点:Node需要维护的数据更多,维护了一个层的数组信息
- 优点:
- 实现简单,
- 一般用zset的操作都是执行zrange之类的操作,取出一片连续的节点。这些操作的缓存命中率不会比红黑树低。
亿级用户日活统计bitMap
实现计算每天登陆的用户量
setbit key offset 0 | 1
setbit a-map userId 1
setbit a-map userId 1
getbit a-map userId
# 统计每天的用户登录情况
# userid是 100 的用户11 06号登录了
setbit login_11_06 100 1
# userid是 100 的用户11 07号登录了
setbit login_11_07 100 1
STRLEN login_11_06
# 返回的是13,也就是100/8就是12.5,也就是13字节
type login_11_06
# 返回的是string,也就是bitmap的数据类型是string ,操作的是bit位
# BITCOUNT login_11_06 [start end] 其实和结束的位置,13个字节,结束位置就是12
BITCOUNT login_11_06
BITCOUNT login_11_06 0 12
# 得到当前值是1的个数,这里返回1
# string最大是512M,对应的索引值最大就是2的32-1
# 数据量小,但是间隔区间大,就会浪费空间
#
实现连续登陆的用户量--与运算
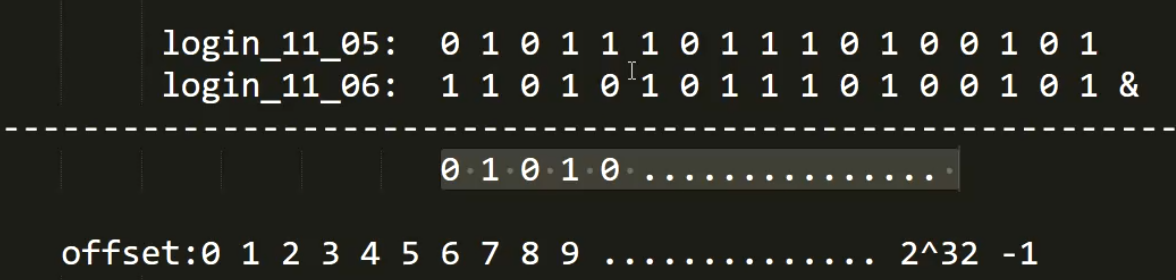
再对结果计算一个bitcount ,就把结果计算好了

实现周活用户量--或运算
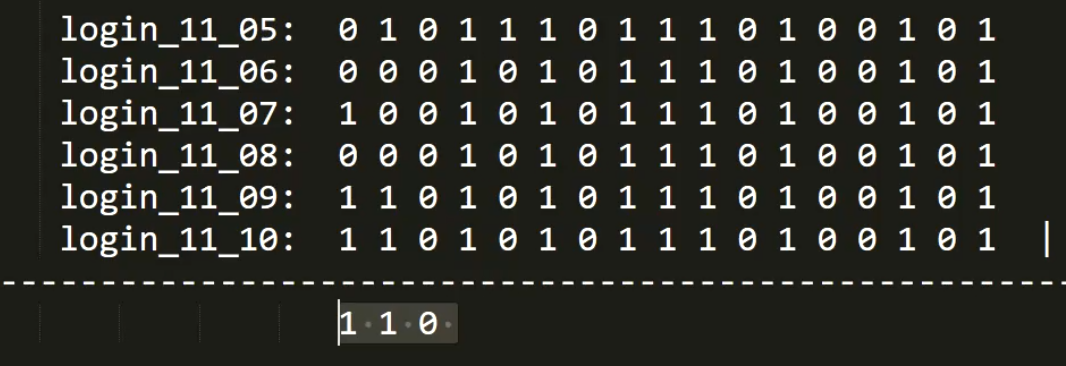
再对结果计算一个bitcount ,就把结果计算好了

setbit 源码

一次偏移就可以拿到原来的数据,之后做一个位运算得到结果
void setbitCommand(client *c) {
robj *o;
char *err = "bit is not an integer or out of range";
size_t bitoffset;
ssize_t byte, bit;
int byteval, bitval;
long on;
// 解析 offset
if (getBitOffsetFromArgument(c,c->argv[2],&bitoffset,0,0) != C_OK)
return;
// 解析 整型value
if (getLongFromObjectOrReply(c,c->argv[3],&on,err) != C_OK)
return;
/* Bits can only be set or cleared... *
*
* bit 位 只能是 0 / 1 否则直接返回失败
*/
if (on & ~1) {
addReplyError(c,err);
return;
}
if ((o = lookupStringForBitCommand(c,bitoffset)) == NULL) return;
/* Get current values
* 获取原来的值,用于返回旧值
* */
byte = bitoffset >> 3; // 除以8得到当前的位置
byteval = ((uint8_t*)o->ptr)[byte]; // 找到数据
bit = 7 - (bitoffset & 0x7); // 算出 bit 的位置
bitval = byteval & (1 << bit); // 获得旧值
/* Update byte with new bit value and return original value */
byteval &= ~(1 << bit);
byteval |= ((on & 0x1) << bit); // 按位或,数据赋值
((uint8_t*)o->ptr)[byte] = byteval;
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"setbit",c->argv[1],c->db->id);
server.dirty++;
addReply(c, bitval ? shared.cone : shared.czero);
}
posted on 2025-10-13 00:37 chuchengzhi 阅读(27) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号