Linux性能分析、调优套路以及工具总结
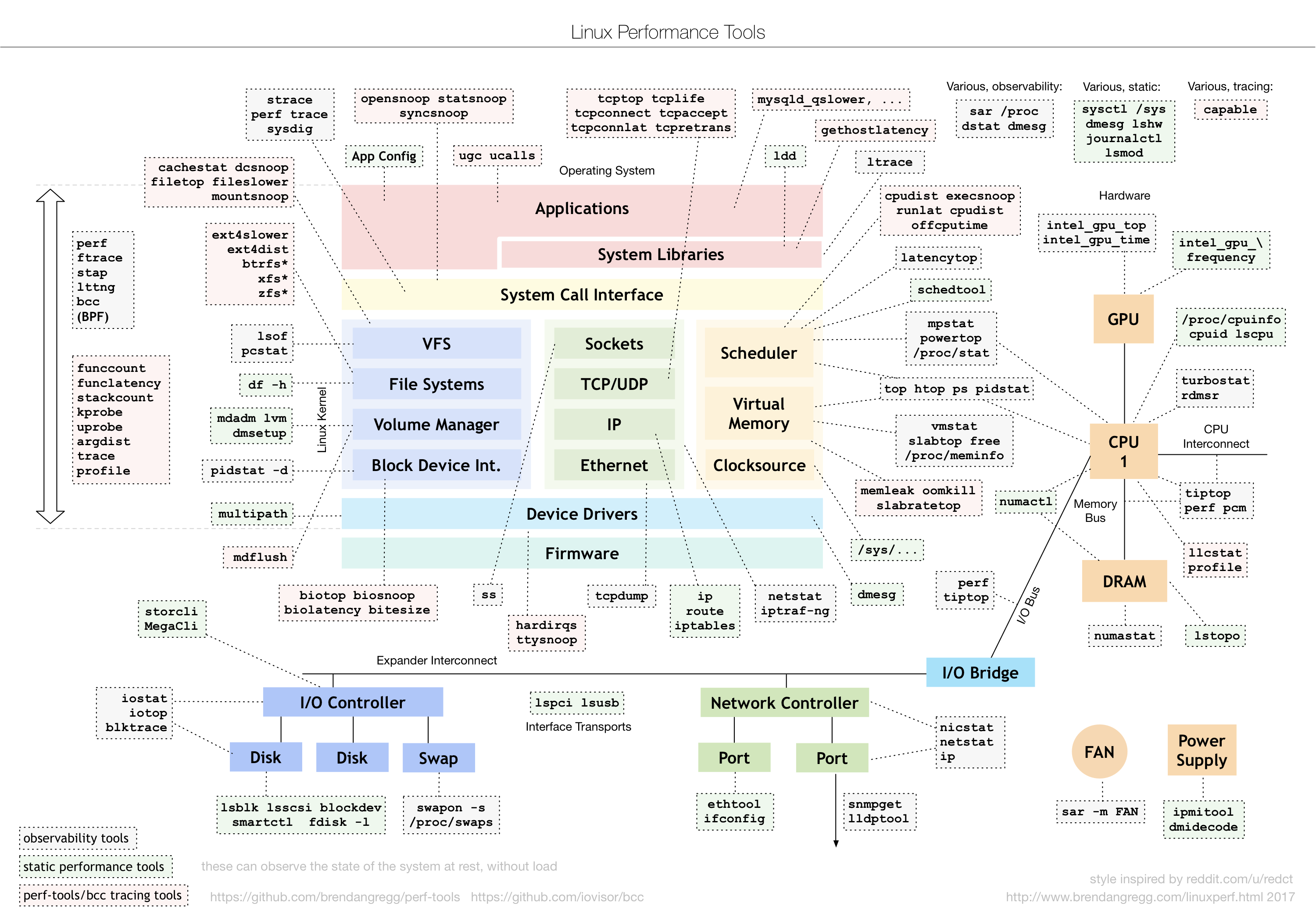
分析性能问题
从系统资源瓶颈的角度来说,USE 法是最为有效的方法,即从使用率、饱和度以及错误数 这三个方面,来分析 CPU、内存、磁盘和文件系统 I/O、网络以及内核资源限制等各类软 硬件资源。
从应用程序瓶颈的角度来说,资源瓶颈跟系统资源瓶颈,本质是一样的。依赖服务瓶颈,你可以使用全链路跟踪系统进行定位。而应用自身的问题,你可以通过系统调用、热点函数,或者应用自身的指标监控以及日志 监控等,进行分析定位。
值得注意的是,虽然我把瓶颈分为了系统和应用两个角度,但在实际运行时,这两者往往是 相辅相成、相互影响的。系统是应用的运行环境,系统的瓶颈会导致应用的性能下降;而应 用的不合理设计,也会引发系统资源的瓶颈。我们做性能分析,就是要结合应用程序和操作系统的原理,揪出引发问题的真凶。
系统资源瓶颈
USE 法,即使用 率、饱和度以及错误数这三类指标来衡量。
资源列表:
- CPU、内存、磁盘和文件系统以及网络等,都是最常见的硬件资源。
- 文件描述符数、连接跟踪数、套接字缓冲区大小等,则是典型的软件资源。
收到监控系统告警时,就可以对照这些资源列表,再根据指标的不同来进行定位。
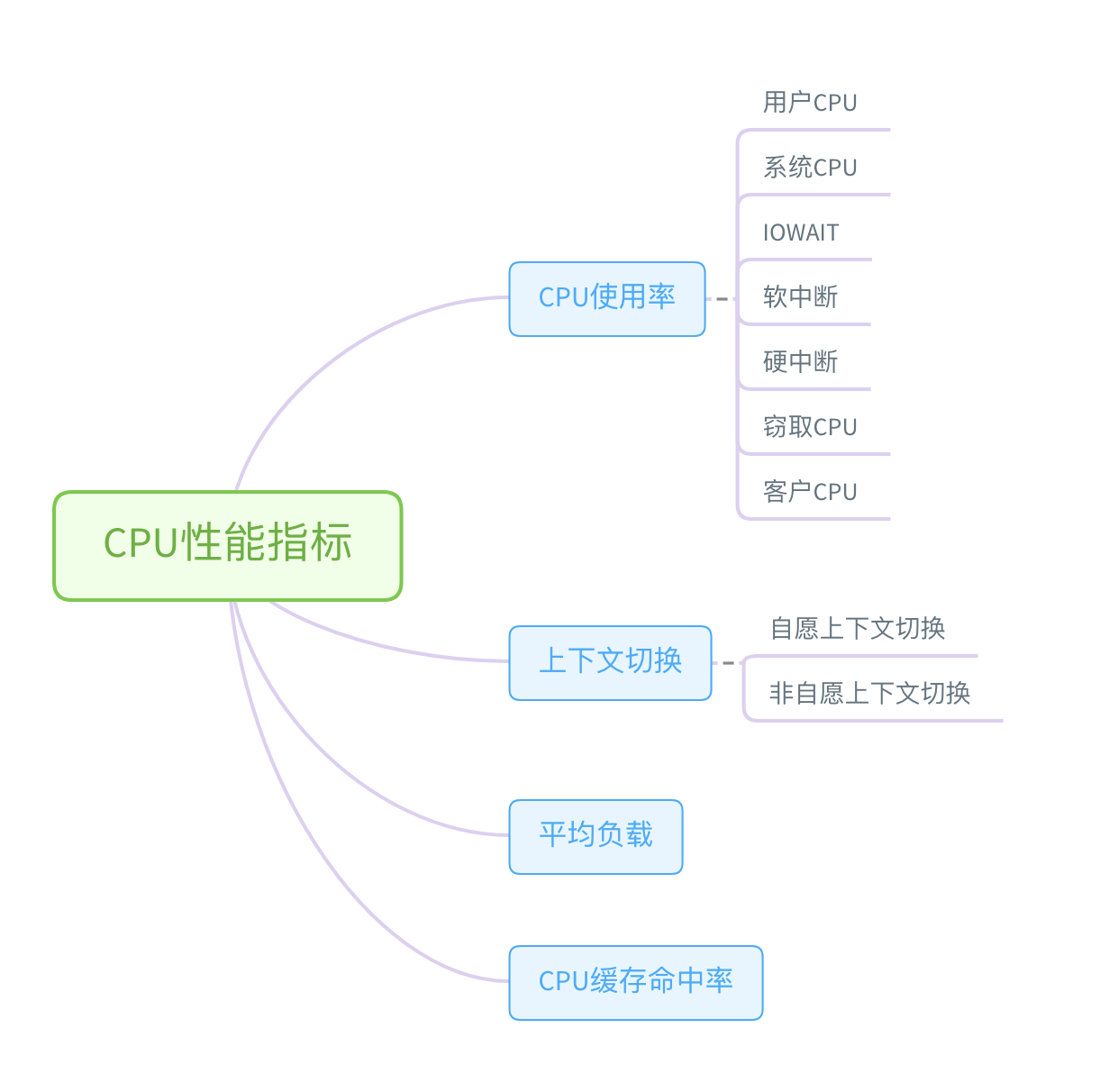
系统资源:CPU 性能分析
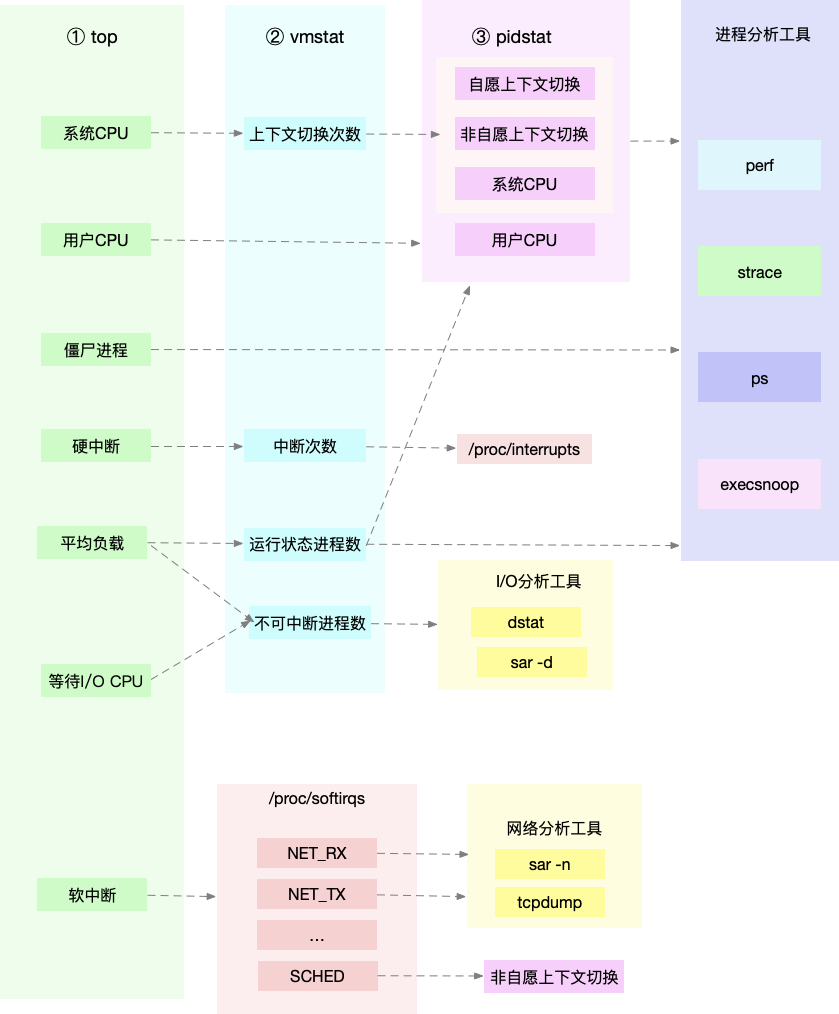
利用 top、vmstat、pidstat、strace 以及 perf 等几个最常见的工具, 获取 CPU 性能指标后,再结合进程与 CPU 的工作原理,就可以迅速定位出 CPU 性能瓶颈 的来源。
top、pidstat、vmstat 这类工具所汇报的 CPU 性能指标,都源自 /proc 文件系 统(比如 /proc/loadavg、/proc/stat、/proc/softirqs 等)。这些指标,都应该通过监控 系统监控起来。
收到系统的用户 CPU 使用率过高告警时,从监控系统中直接查询到,导致 CPU 使用率过高的进程;然后再登录到进程所在的 Linux 服务器中,分析该进程的行为。使用 strace,查看进程的系统调用汇总;也可以使用 perf 等工具,找出进程的热点函数;甚至还可以使用动态追踪的方法,来观察进程的当前执行过程,直到确定瓶颈的根 源。
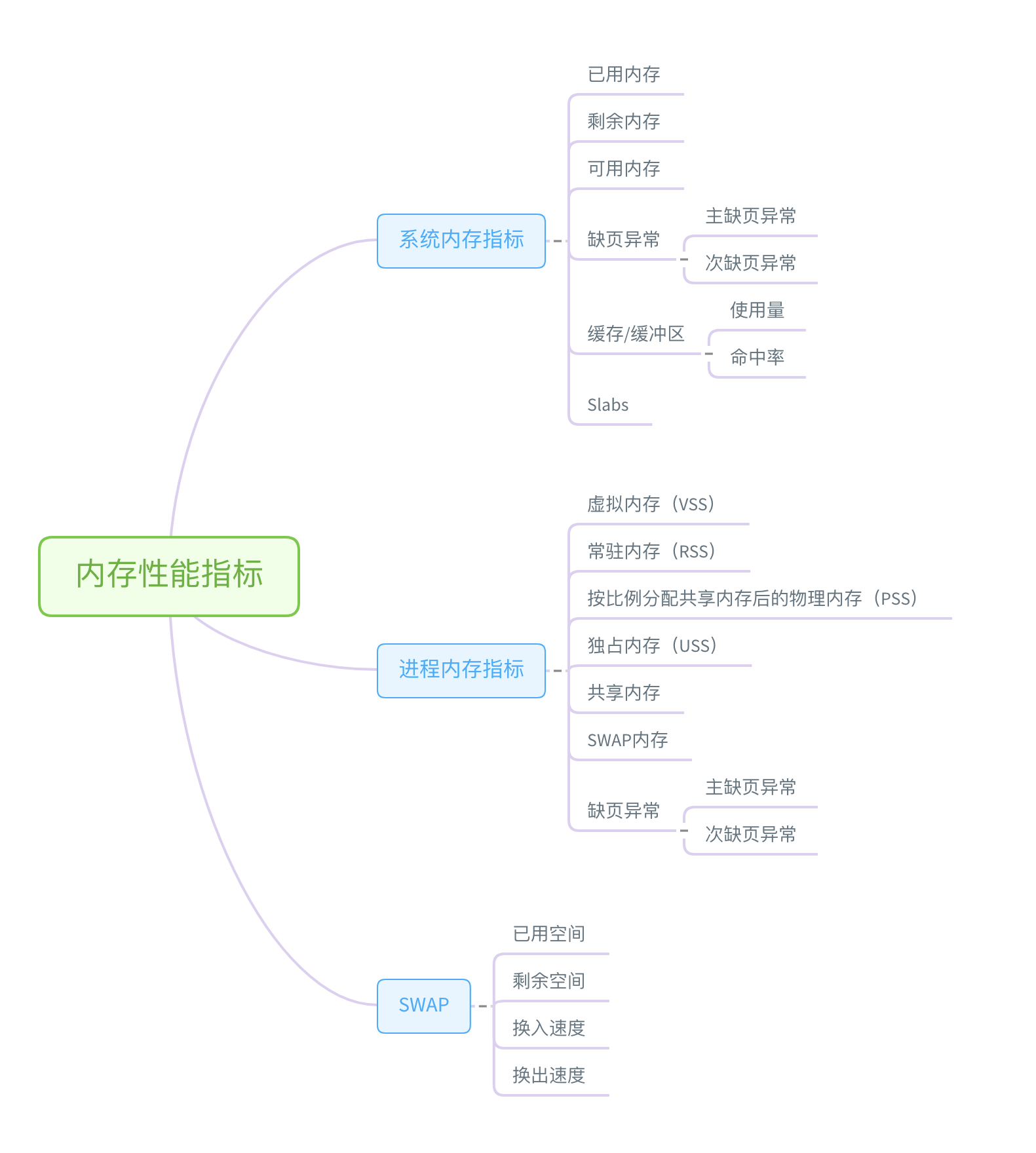
系统资源:内存性能分析
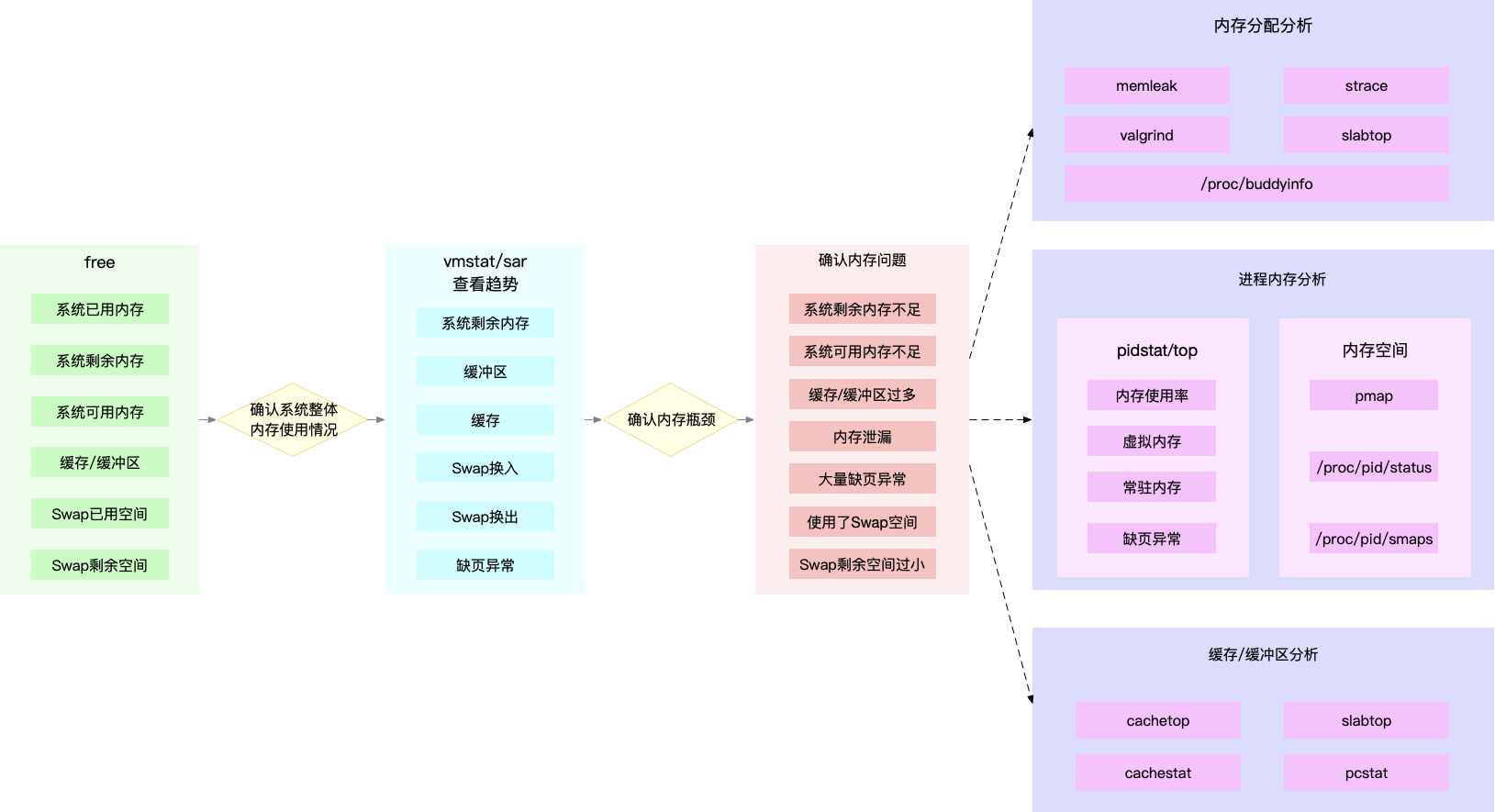
free 和 vmstat 输出的性 能指标,确认内存瓶颈;然后,再根据内存问题的类型,进一步分析内存的使用、分配、泄 漏以及缓存等,最后找出问题的来源。
很多内存的性能指标,也来源于 /proc 文件系统(比如 /proc/meminfo、/proc/slabinfo 等),它们也都应该通过监控系统监控起来。
收到内存不足的告警时,首先可以从监控系统中。找出占用内存最多的几个进 程。然后,再根据这些进程的内存占用历史,观察是否存在内存泄漏问题。确定出最可疑的 进程后,再登录到进程所在的 Linux 服务器中,分析该进程的内存空间或者内存分配,最 后弄清楚进程为什么会占用大量内存。
系统资源:磁盘和文件系统 I/O 性能分析
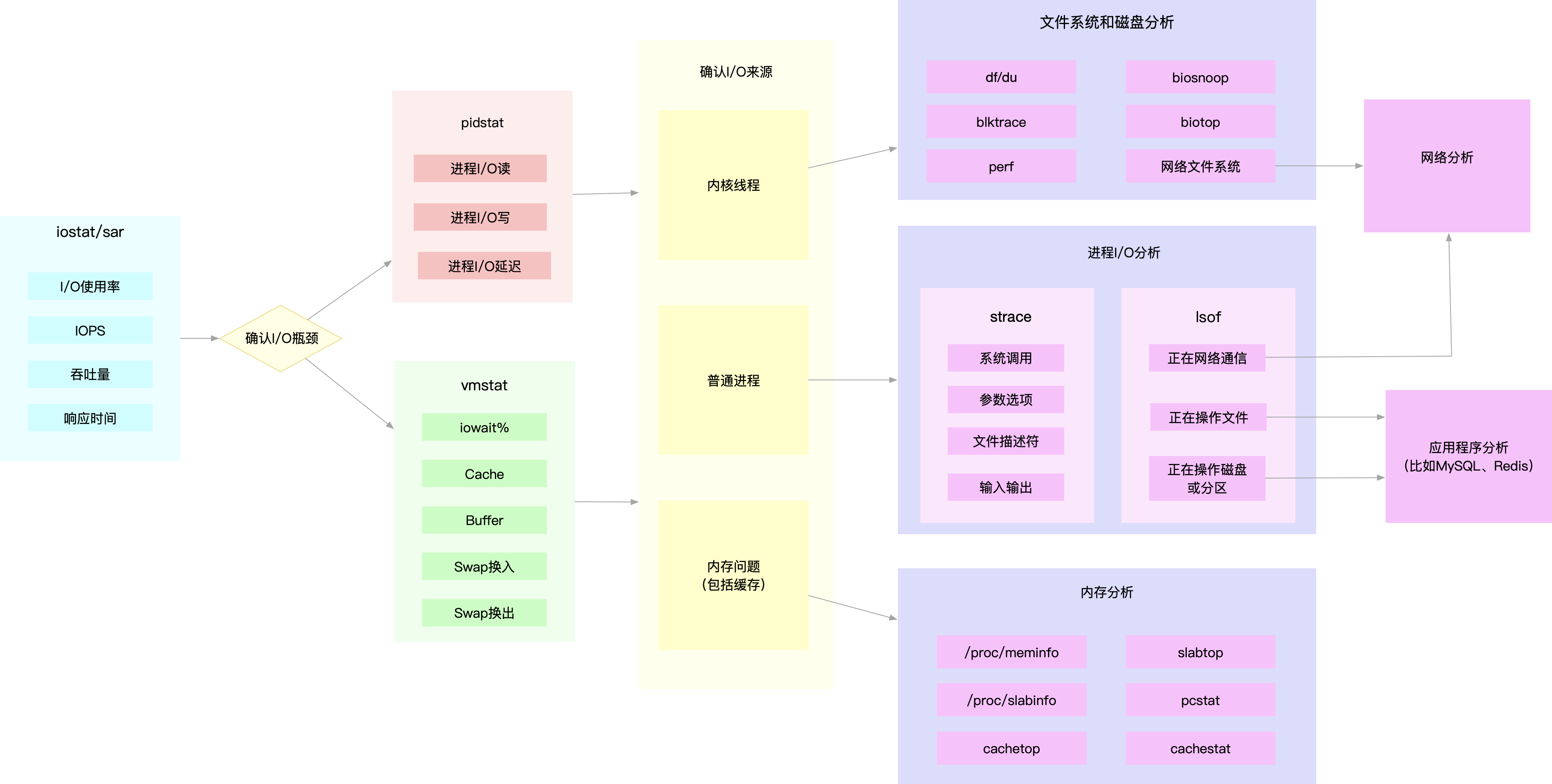
iostat ,发现磁盘 I/O 存在性能瓶颈(比如 I/O 使用率过 高、响应时间过长或者等待队列长度突然增大等)后,可以再通过 pidstat、 vmstat 等, 确认 I/O 的来源。接着,再根据来源的不同,进一步分析文件系统和磁盘的使用率、缓存 以及进程的 I/O 等,从而揪出 I/O 问题的真凶。
很多磁盘和文件系统的性能指标,也来源于 /proc 和 /sys 文件 系统(比如 /proc/diskstats、/sys/block/sda/stat 等)。自然,它们也应该通过监控系统 监控起来。
发现某块磁盘的 I/O 使用率为 100% 时,首先可以从监控系统中,找出 I/O 最多的进程。然后,再登录到进程所在的 Linux 服务器中,借助 strace、lsof、perf 等工 具,分析该进程的 I/O 行为。最后,再结合应用程序的原理,找出大量 I/O 的原因。
系统资源:网络性能分析
网络接口和内核资源
从 Linux 网络协议栈的原理来切入。包括应用层、套机字接口、传输层、网络层以及 链路层等。通过使用率、饱和度以及错误数这 几类性能指标,观察是否存在性能问题。
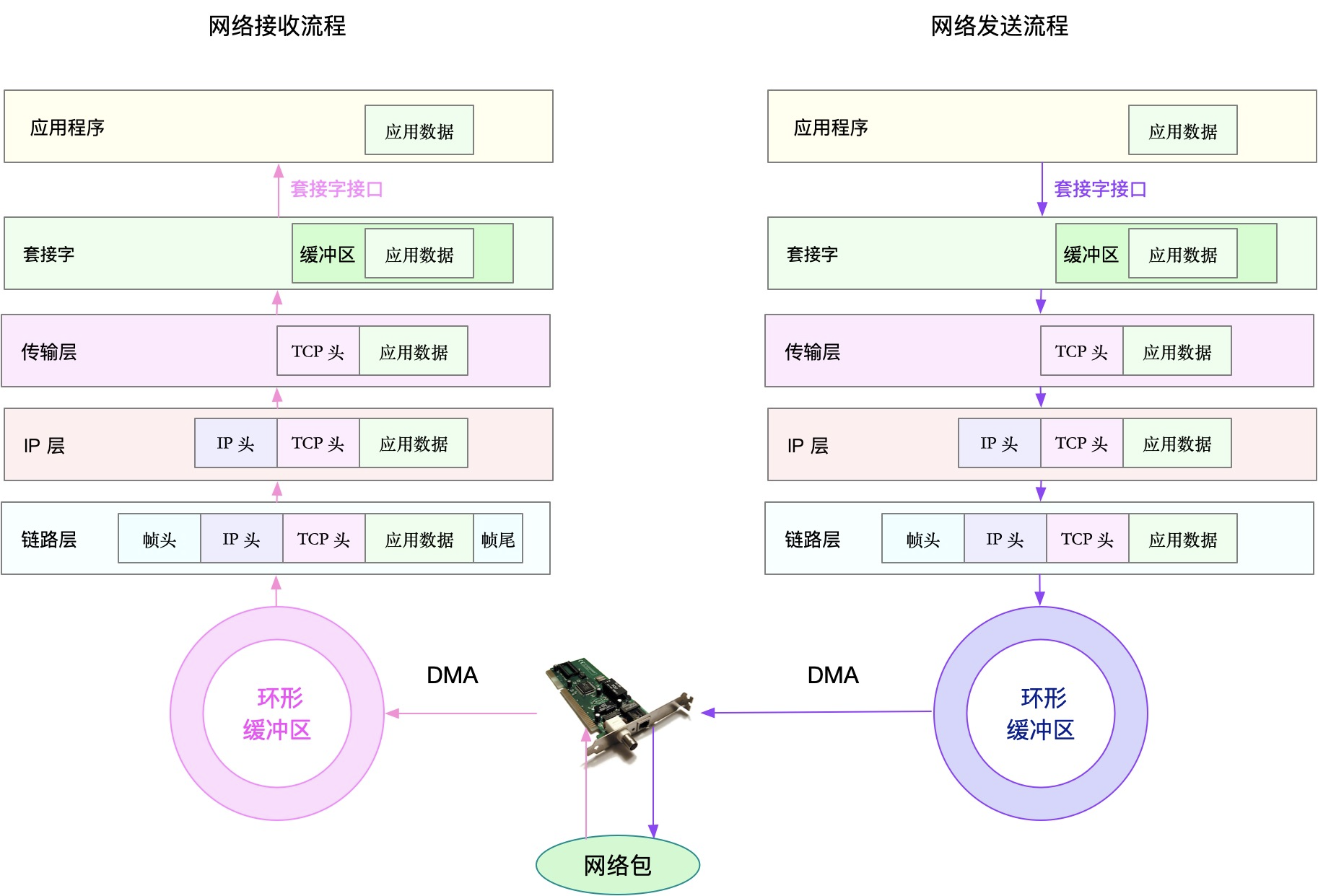
- 在链路层,可以从网络接口的吞吐量、丢包、错误以及软中断和网络功能卸载等角度分 析;
- 在网络层,可以从路由、分片、叠加网络等角度进行分析;
- 在传输层,可以从 TCP、UDP 的协议原理出发,从连接数、吞吐量、延迟、重传等角度 进行分析; 在应用层,可以从应用层协议(如 HTTP 和 DNS)、请求数(QPS)、套接字缓存等角 度进行分析。
网络的性能指标也都来源于内核,包括 /proc 文件系统(如 /proc/net)、网络接口以及 conntrack 等内核模块。这些指标同样需要被监控系统监控。
收到网络不通的告警时,就可以从监控系统中,查找各个协议层的丢包指标,确认丢包所在的协议层。然后,从监控系统的数据中,确认网络带宽、缓冲区、连接跟踪数等 软硬件,是否存在性能瓶颈。最后,再登录到发生问题的 Linux 服务器中,借助 netstat、 tcpdump、bcc 等工具,分析网络的收发数据,并且结合内核中的网络选项以及 TCP 等网 络协议的原理,找出问题的来源。
应用程序瓶颈
最典 型的应用程序性能问题,就是吞吐量(并发请求数)下降、错误率升高以及响应时间增大。
- 第一种资源瓶颈,其实还是指刚才提到的 CPU、内存、磁盘和文件系统 I/O、网络以及内 核资源等各类软硬件资源出现了瓶颈,从而导致应用程序的运行受限。对于这种情况,我们 就可以用前面系统资源瓶颈模块提到的各种方法来分析。
- 第二种依赖服务的瓶颈,也就是诸如数据库、分布式缓存、中间件等应用程序,直接或者间 接调用的服务出现了性能问题,从而导致应用程序的响应变慢,或者错误率升高。这说白了 就是跨应用的性能问题,使用全链路跟踪系统,就可以帮你快速定位这类问题的根源。
- 最后一种,应用程序自身的性能问题,包括了多线程处理不当、死锁、业务算法的复杂度过 高等等。对于这类问题,观察关键环 节的耗时和内部执行过程中的错误,就可以帮你缩小问题的范围。
需要应用程序在设计和开发时,就提供出这些指标,以便监控系统可以了解应用程序的内部运行 状态。如果这些手段过后还是无法找出瓶颈,你还可以用系统资源模块提到的各类进程分析工具, 来进行分析定位。
优化性能问题
从系统的角度来说,CPU、内存、磁盘和文件系统 I/O、网络以及内核数据结构等各类软硬件资源,需要优化。
从应用程序的角度来说,降低 CPU 使用,减少数据访问和网络 I/O,使用缓存、异步处理 以及多进程多线程等,都是常用的性能优化方法。除了这些单机优化方法,调整应用程序的 架构,或是利用水平扩展,将任务调度到多台服务器中并行处理,也是常用的优化思路。
一定要避免过早优化。性能优化往往会提 高复杂性,这一方面降低了可维护性,另一方面也为适应复杂多变的新需求带来障碍。
性能优化最好是逐步完善,动态进行;不追求一步到位,而要首先保证,能满足当前的性能要求。
发现性能不满足要求或者出现性能瓶颈后,再根据性能分析的结果,选择最重 要的性能问题进行优化。
系统优化
CPU 优化
- 第一种,把进程绑定到一个或者多个 CPU 上,充分利用 CPU 缓存的本地性,并减少进 程间的相互影响。
- 第二种,为中断处理程序开启多 CPU 负载均衡,以便在发生大量中断时,可以充分利用 多 CPU 的优势分摊负载。
- 第三种,使用 Cgroups 等方法,为进程设置资源限制,避免个别进程消耗过多的 CPU。 同时,为核心应用程序设置更高的优先级,减少低优先级任务的影响。
内存优化
可用内存不足、内存泄漏、 Swap 过多、缺页异常过多以及缓存过多等等
- 第一种,除非有必要,Swap 应该禁止掉。这样就可以避免 Swap 的额外 I/O ,带来内 存访问变慢的问题。
- 第二种,使用 Cgroups 等方法,为进程设置内存限制。这样就可以避免个别进程消耗过 多内存,而影响了其他进程。对于核心应用,还应该降低 oom_score,避免被 OOM 杀 死。
- 第三种,使用大页、内存池等方法,减少内存的动态分配,从而减少缺页异常。
磁盘和文件系统 I/O 优化
- 第一种,也是最简单的方法,通过 SSD 替代 HDD、或者使用 RAID 等方法,提升 I/O 性能。
- 第二种,针对磁盘和应用程序 I/O 模式的特征,选择最适合的 I/O 调度算法。比如, SSD 和虚拟机中的磁盘,通常用的是 noop 调度算法;而数据库应用,更推荐使用 deadline 算法。
- 第三,优化文件系统和磁盘的缓存、缓冲区,比如优化脏页的刷新频率、脏页限额,以及 内核回收目录项缓存和索引节点缓存的倾向等等。
- 除此之外,使用不同磁盘隔离不同应用的数据、优化文件系统的配置选项、优化磁盘预读、 增大磁盘队列长度等,也都是常用的优化思路。
网络优化
- 从内核资源和网络协议的角度来说,我们可以对内核选项进行优化,比如:
- 可以增大套接字缓冲区、连接跟踪表、最大半连接数、最大文件描述符数、本地端口范 围等内核资源配额;
- 可以减少 TIMEOUT 超时时间、SYN+ACK 重传数、Keepalive 探测时间等异常处理 参数;
- 可以开启端口复用、反向地址校验,并调整 MTU 大小等降低内核的负担。
- 其次,从网络接口的角度来说,我们可以考虑对网络接口的功能进行优化,
- 将原来 CPU 上执行的工作,卸载到网卡中执行,即开启网卡的 GRO、GSO、 RSS、VXLAN 等卸载功能;
- 可以开启网络接口的多队列功能,这样,每个队列就可以用不同的中断号,调度到不同 CPU 上执行;
- 可以增大网络接口的缓冲区大小以及队列长度等,提升网络传输的吞吐量。
- 在极限性能情况(比如 C10M)下,内核的网络协议栈可能是最主要的性能瓶颈, 所以,一般会考虑绕过内核协议栈。
- 可以使用 DPDK 技术,跳过内核协议栈,直接由用户态进程用轮询的方式,来处理网 络请求。同时,再结合大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络 包的处理效率。
- 还可以使用内核自带的 XDP 技术,在网络包进入内核协议栈前,就对其进行处理。这 样,也可以达到目的,获得很好的性能。
应用程序优化
系统的软硬件资源,是保证应用程序正常运行的基础,性能优化的最佳位 置,还是应用程序内部。
- 系统 CPU 使用率(sys%)过高的问题。有时候出现问题,虽然表面现象是 系统 CPU 使用率过高,应用程序的不合理系统调用才是 罪魁祸首。这种情况下,优化应用程序内部系统调用的逻辑,显然要比优化内核要简单也有 用得多。
- 数据库的 CPU 使用率高、I/O 响应慢,也是最常见的一种性能问题。并不是因为数据库本身性能不好,而是应用程序不合理的表结构或者 SQL 查询语句导致的。这时候,优化应用程序中数据库表结构的逻辑或者 SQL 语句,显然要比 优化数据库本身,能带来更大的收益。
所以,在观察性能指标时,先查看应用程序的响应时间、吞吐量以及错误率等指标, 因为它们才是性能优化要解决的终极问题。
- 第一,从 CPU 使用的角度来说,简化代码、优化算法、异步处理以及编译器优化等,都 是常用的降低 CPU 使用率的方法,这样可以利用有限的 CPU 处理更多的请求。
- 第二,从数据访问的角度来说,使用缓存、写时复制、增加 I/O 尺寸等,都是常用的减 少磁盘 I/O 的方法,这样可以获得更快的数据处理速度。
- 第三,从内存管理的角度来说,使用大页、内存池等方法,可以预先分配内存,减少内存 的动态分配,从而更好地内存访问性能。
- 第四,从网络的角度来说,使用 I/O 多路复用、长连接代替短连接、DNS 缓存等方法, 可以优化网络 I/O 并减少网络请求数,从而减少网络延时带来的性能问题。
- 第五,从进程的工作模型来说,异步处理、多线程或多进程等,可以充分利用每一个 CPU 的处理能力,从而提高应用程序的吞吐能力。
- 除此之外,你还可以使用消息队列、CDN、负载均衡等各种方法,来优化应用程序的架 构,将原来单机要承担的任务,调度到多台服务器中并行处理。这样也往往能获得更好的整 体性能。
工具
从性能指标出发,根据性能指标的不同,找工具。
info 可以理解为 man 的详细版本,只有在 man 的输出不太好理解时,才会再去参考 info 文档。
有些工具不需要额外安装,就可以直接使用,比如内核的 /proc 文件系统;
而有些工具,则需要安装额外的软件包,比如 sar、pidstat、iostat 等。
CPU 性能工具
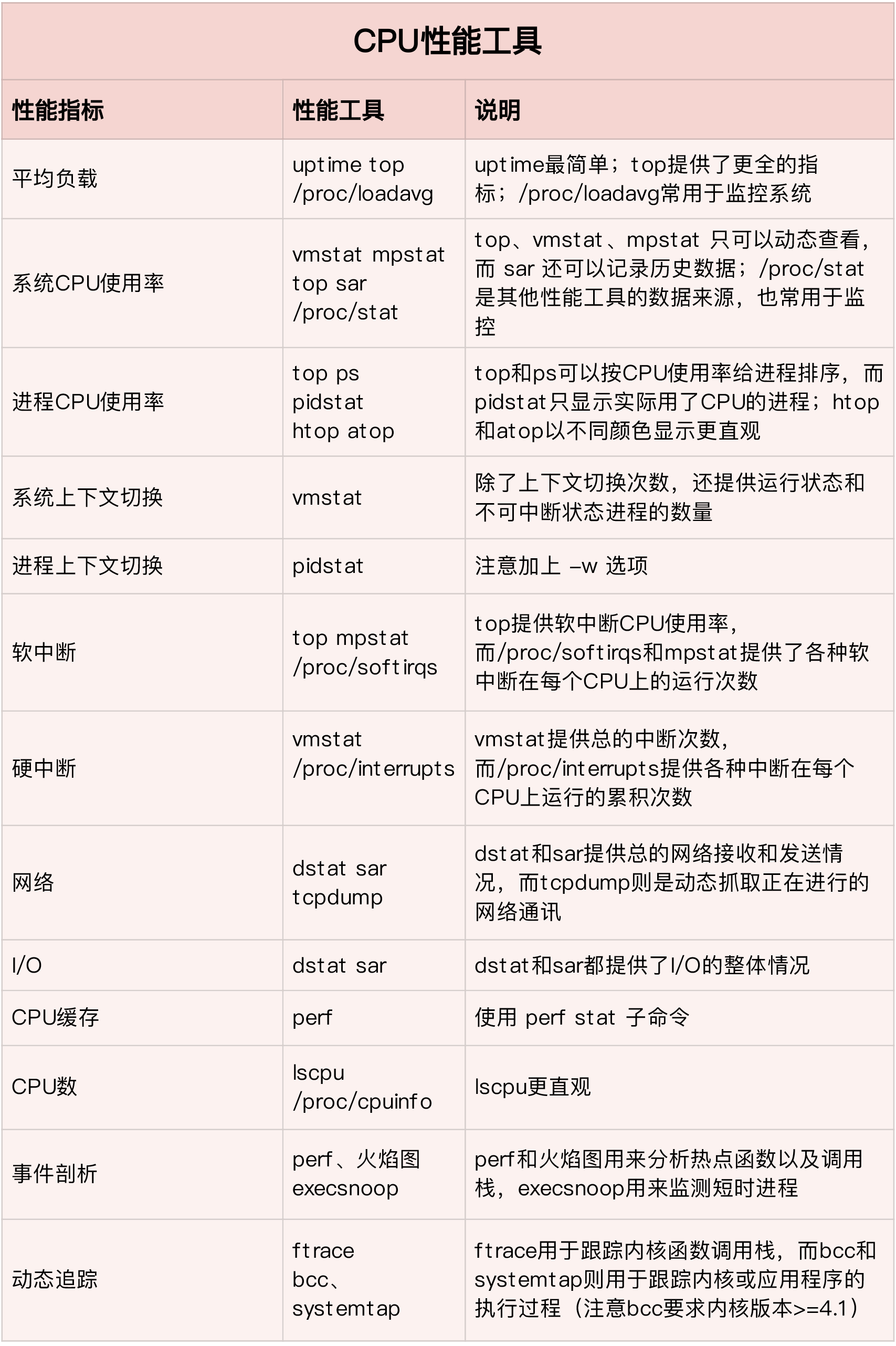
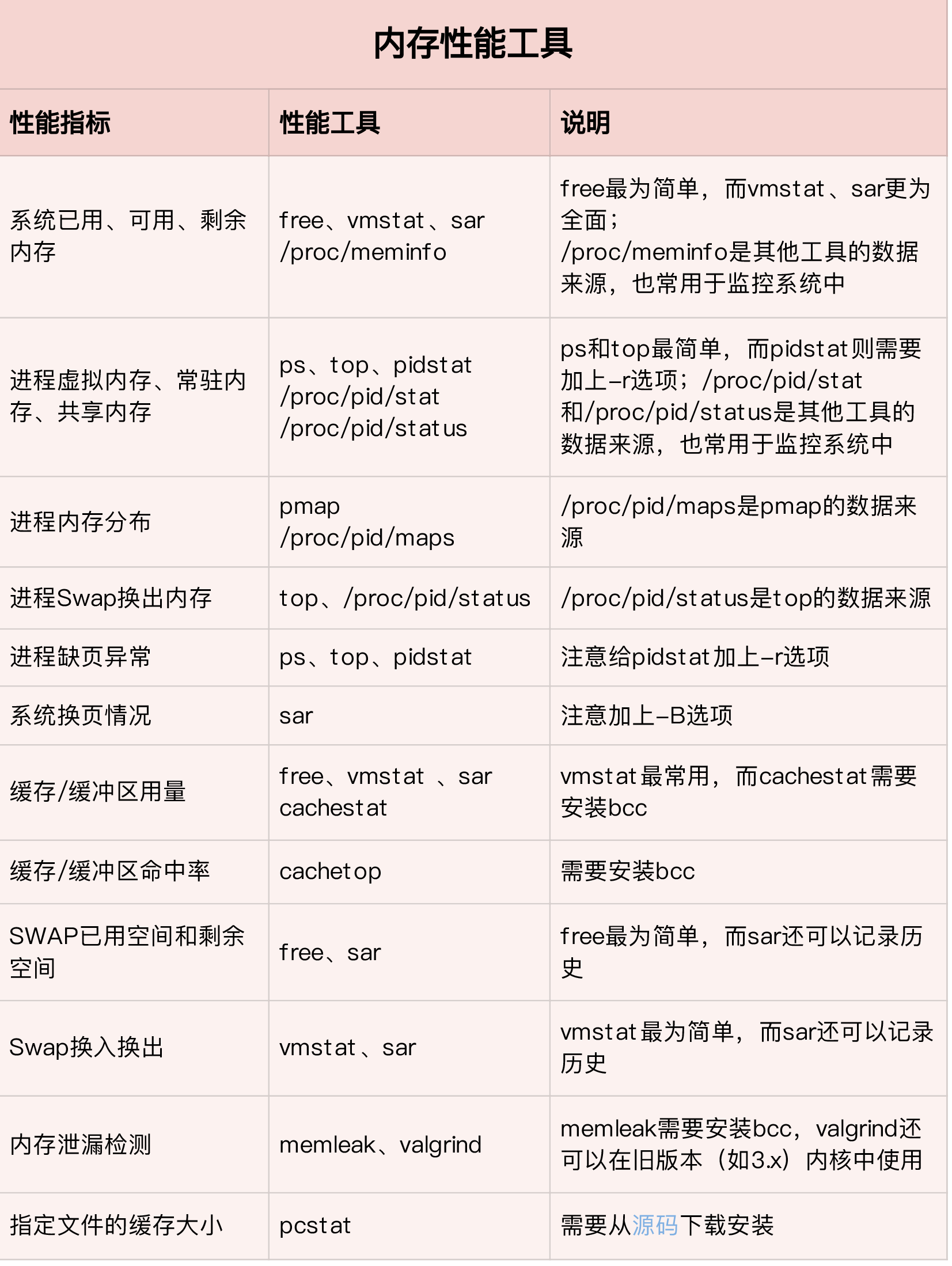
内存性能工具
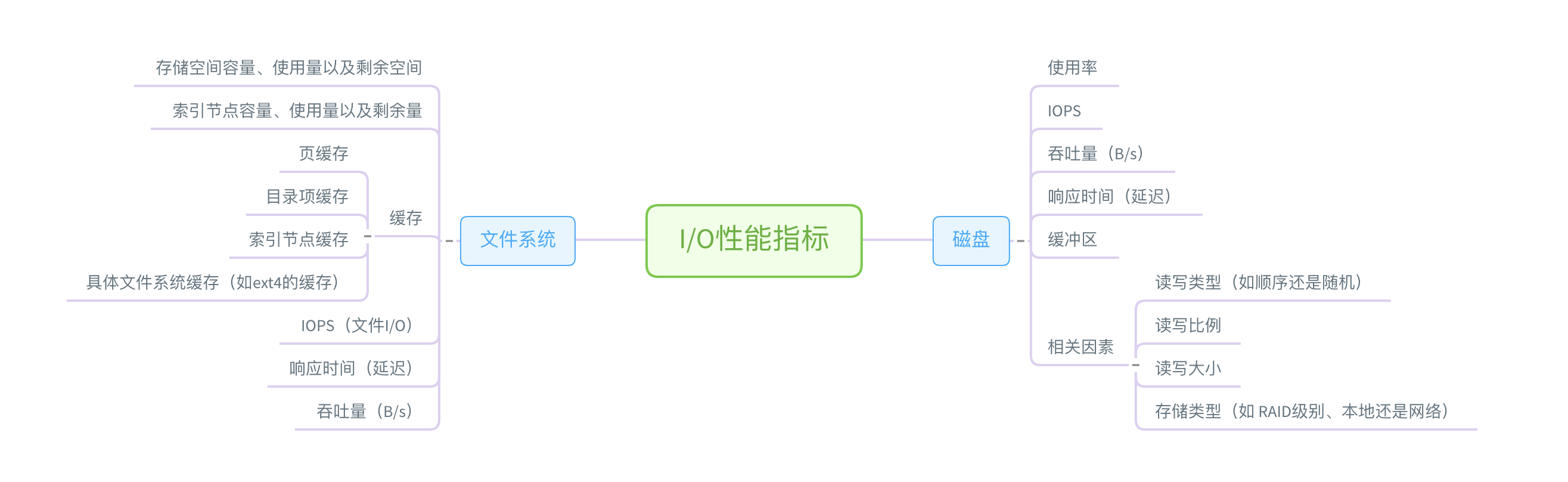
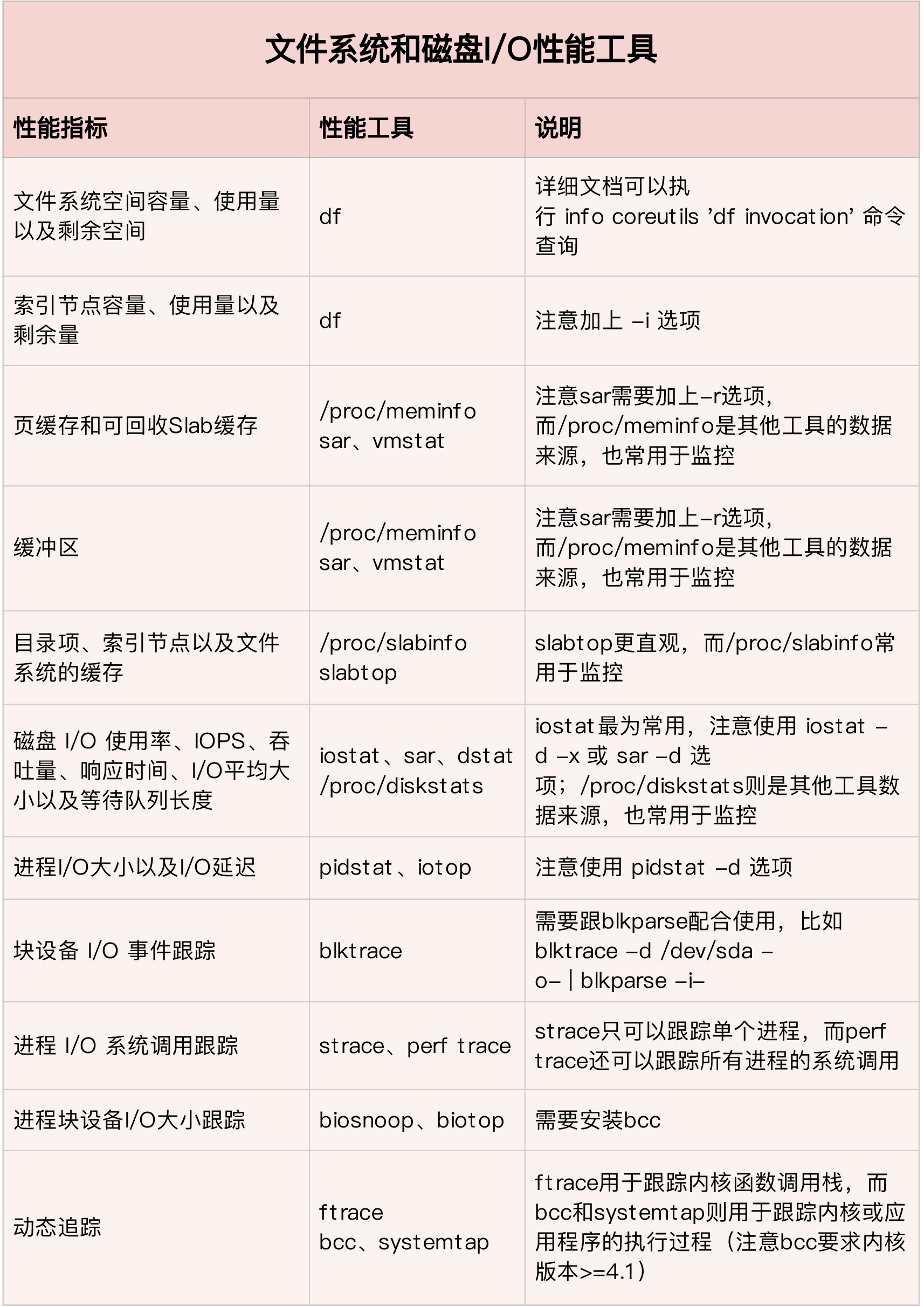
磁盘 I/O 性能工具
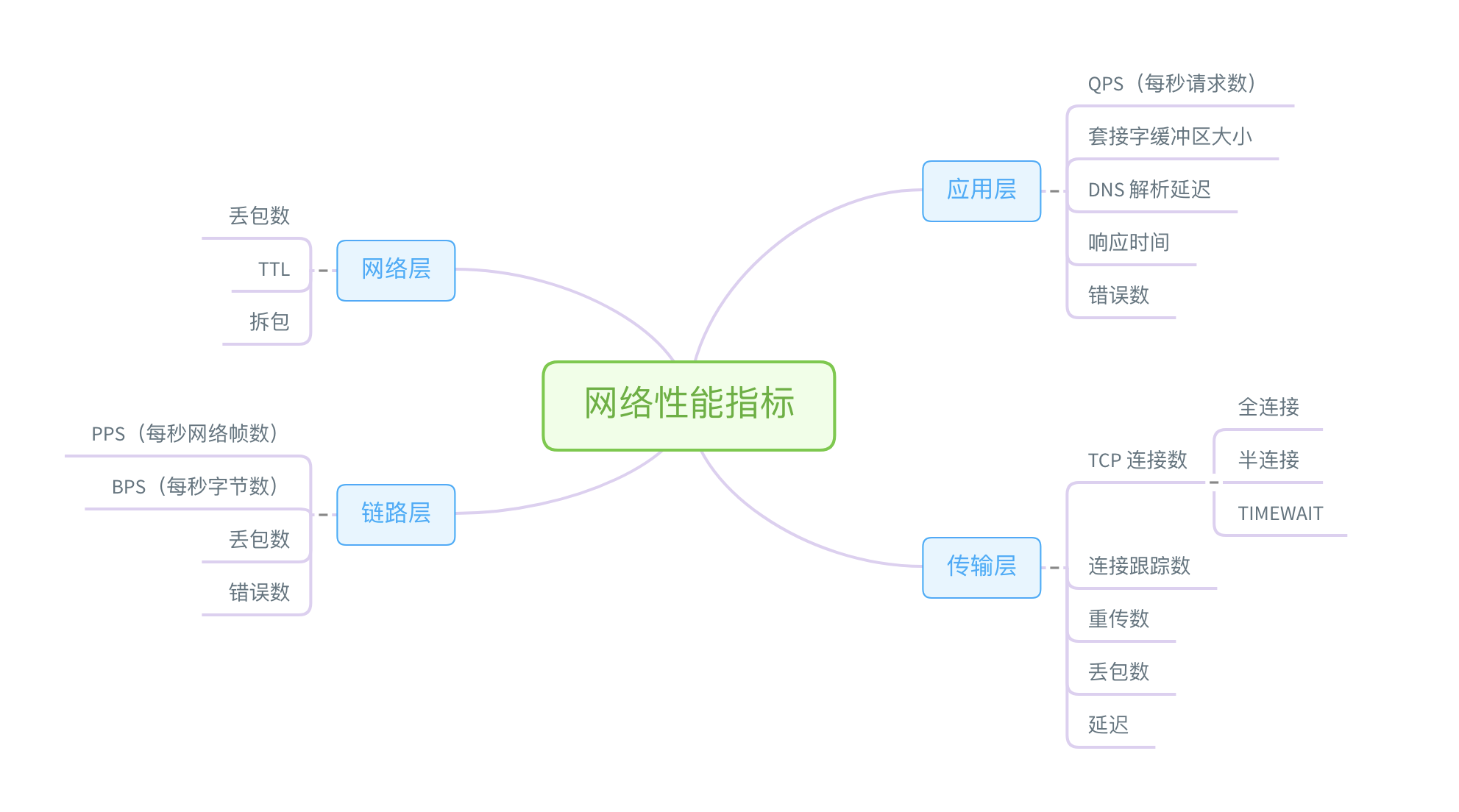
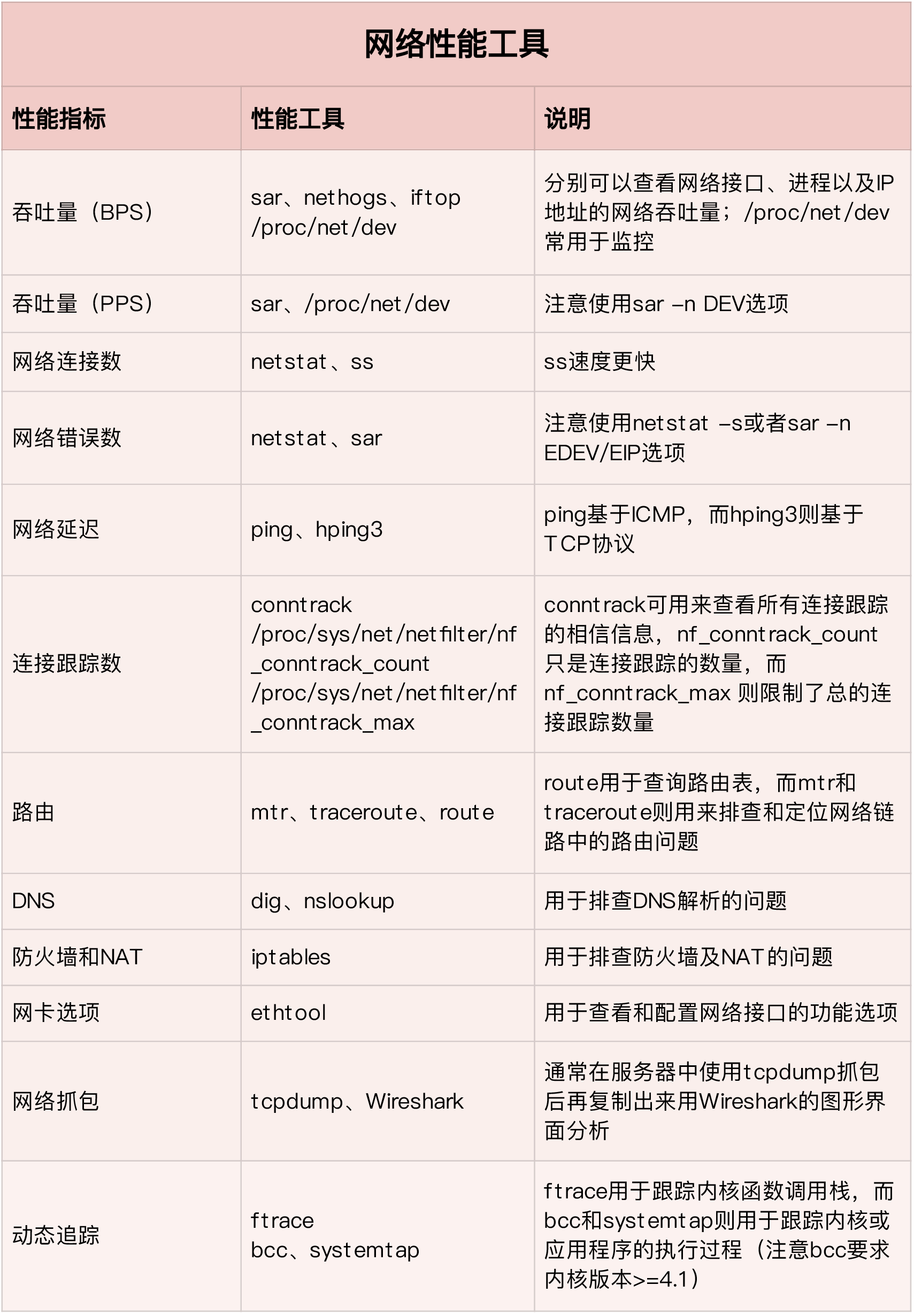
网络性能工具
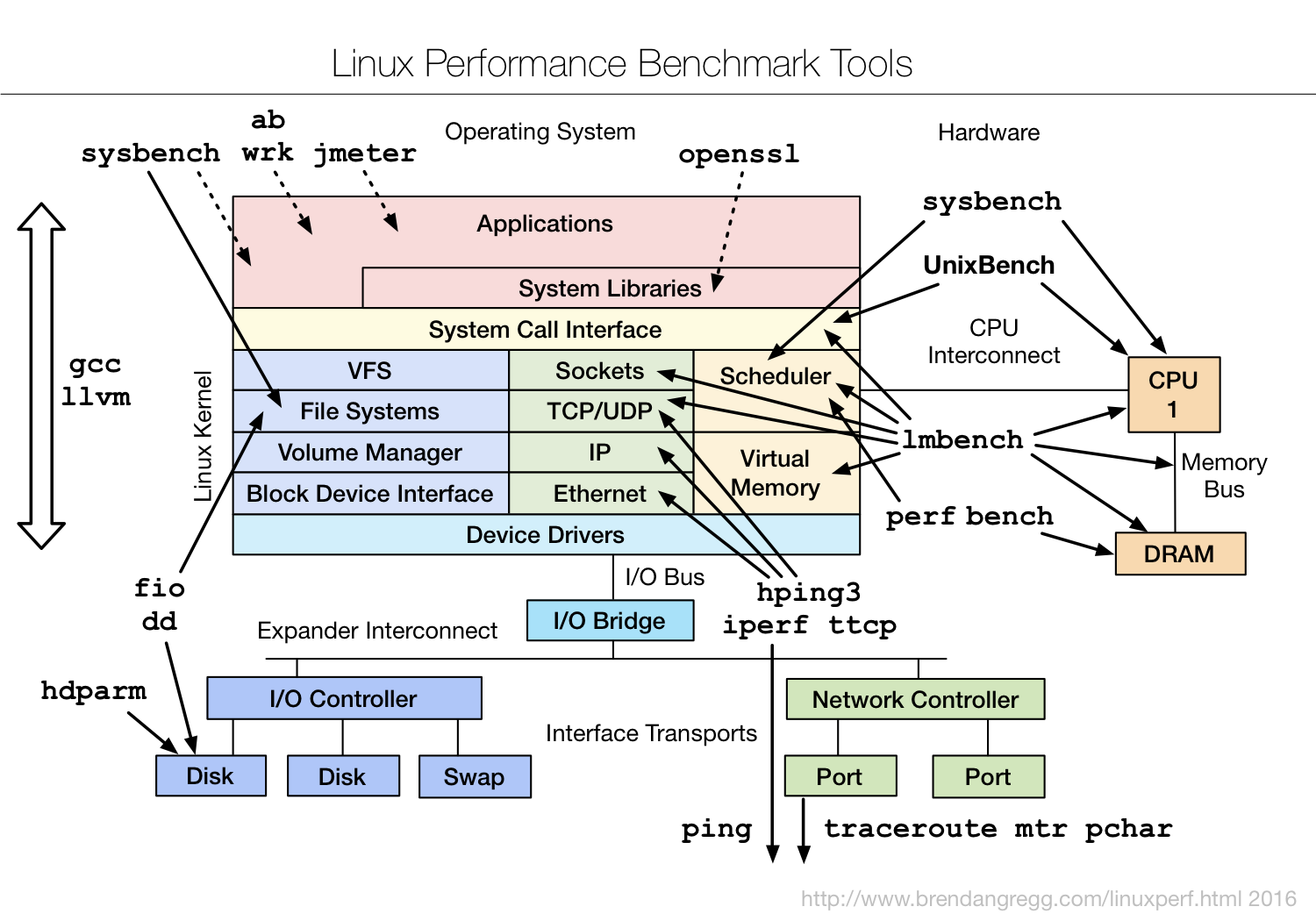
基准测试工具
除了性能分析外,我们还需要对系统性能进行基准测试。比如,使用 fio 工具,测试磁盘 I/O 的性能。使用 iperf、pktgen 等,测试网络的性能。使用 ab、wrk 等,测试 Nginx 应用的性能。
总结
- 从性能瓶颈出发,根据系统和应用程序的运行原理,确认待分析的性能指标。
- 选出最合适的性能工具,然后了解并使用工具,从而更快观测到 需要的性能数据。
当然,正如咱们专栏一直强调的,不要把性能工具当成性能分析和优化的全部。
- 一方面,性能分析和优化的核心,是对系统和应用程序运行原理的掌握,而性能工具只是 辅助你更快完成这个过程的帮手。
- 另一方面,完善的监控系统,可以提供绝大部分性能分析所需的基准数据。从这些数据中,你很可能就能大致定位出性能瓶颈,也就不用再去手动执行各类工具了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号