
系统监控与应用监控
很多应用都是等到用户抱怨响应慢了,或者系统崩 溃了后,才发现系统或者应用程序的性能出现了问题。虽然最终也能发现问题,但显然,这 种方法是不可取的,因为严重影响了用户的体验。要解决这个问题,就要搭建监控系统,把系统和应用程序的运行状况监控起来,并定义一系列的策略,在发生问题时第一时间告警通知。
监控系统要涵盖系统的整体资源使用情况,比如我们前面讲过的 CPU、内 存、磁盘和文件系统、网络等各种系统资源。不仅可以将系统资源的瓶颈快速暴露出 来,还可以借助监控的历史,事后追查定位问题。
而从应用程序来说,监控系统要涵盖应用程序内部的运行状态,这既包括进程的 CPU、磁盘 I/O 等整体运行状况,更需要包括诸如接口调用耗时、执行过程中的错误、内部对象的 内存使用等应用程序内部的运行状况。
系统监控
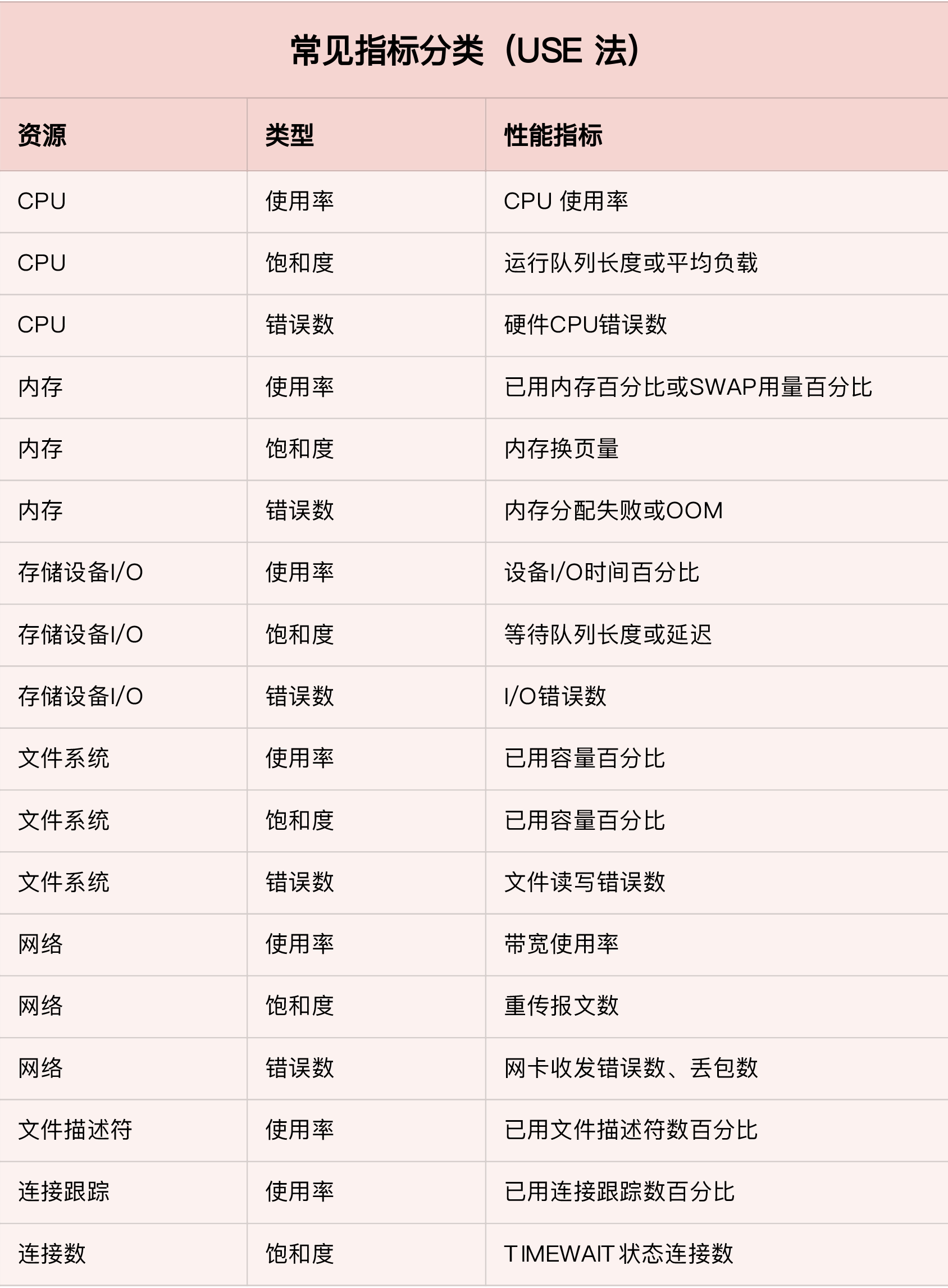
USE 法指标分类
专门用于性能监控的 USE(Utilization Saturation and Errors) 法。USE 法把系统资源的性能指标,简化成了三个类别,即使用率、饱和度以及错误数。
- 使用率,表示资源用于服务的时间或容量百分比。100% 的使用率,表示容量已经用尽或 者全部时间都用于服务。
- 饱和度,表示资源的繁忙程度,通常与等待队列的长度相关。100% 的饱和度,表示资源 无法接受更多的请求。
- 错误数表示发生错误的事件个数。错误数越多,表明系统的问题越严重。
任一类别的指标过高时,都代表相对应的系统资源可能存在性能瓶颈。
无论是对 CPU、内存、磁盘和文件系统、网络等硬件资源,还是对文件描 述符数、连接数、连接跟踪数等软件资源,USE 方法都可以帮你快速定位出,是哪一种系 统资源出现了性能瓶颈。
监控系统
一个完整的监控系统通常由数据采集、数据存储、数据查询和处理、告警以及可视化展示等多个模块组成。最常见的 Zabbix、 Nagios、Prometheus 等等。
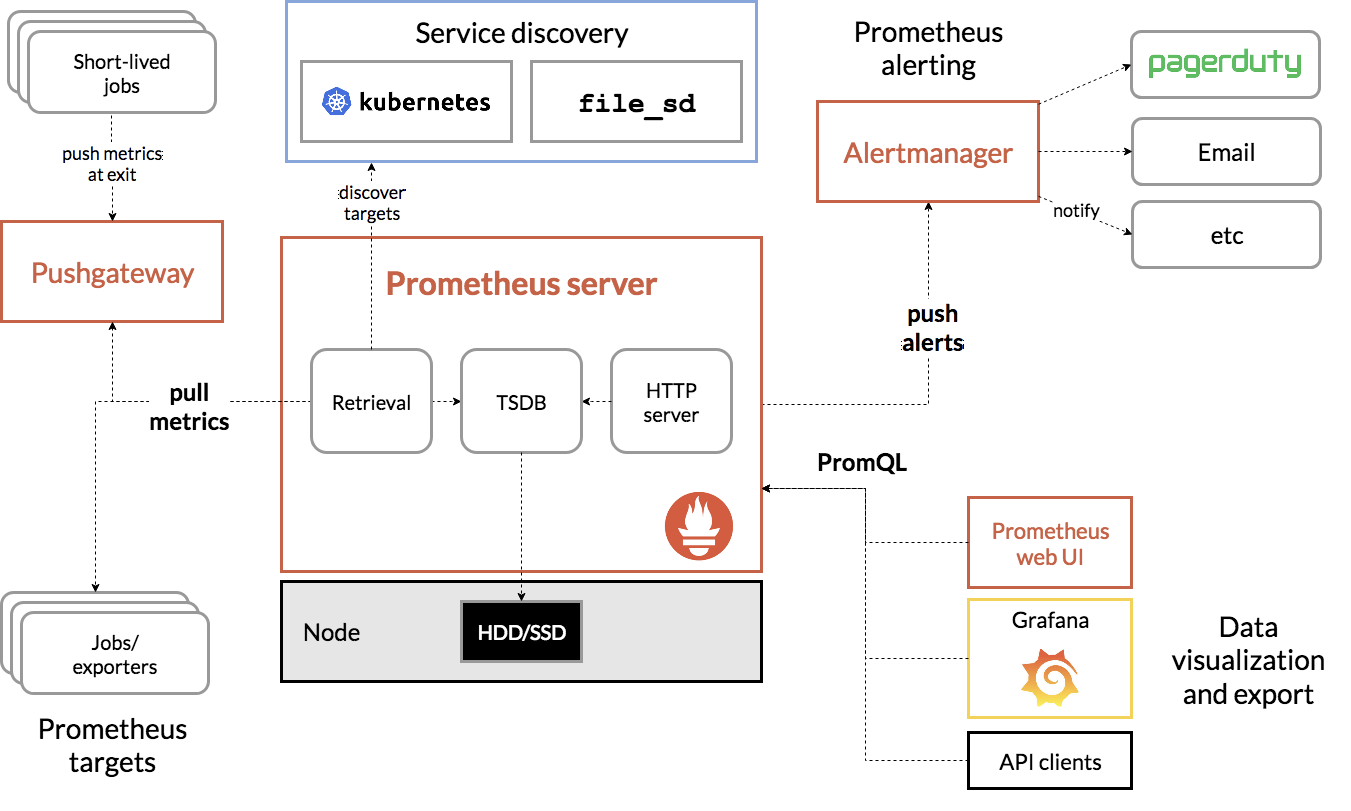
- 先看数据采集模块。
- 最左边的 Prometheus targets 就是数据采集的对象,
- Retrieval 则 负责采集这些数据。从图中你也可以看到,Prometheus 同时支持 Push 和 Pull 两种数据 采集模式。
- Pull 模式,由服务器端的采集模块来触发采集。只要采集目标提供了 HTTP 接口,就可 以自由接入(这也是最常用的采集模式)。
- Push 模式,则是由各个采集目标主动向 Push Gateway(用于防止数据丢失)推送指 标,再由服务器端从 Gateway 中拉取过去(这是移动应用中最常用的采集模式)。
- 由于需要监控的对象通常都是动态变化的,Prometheus 还提供了服务发现的机制,可以 自动根据预配置的规则,动态发现需要监控的对象。这在 Kubernetes 等容器平台中非常 有效。
- 第二个是数据存储模块。为了保持监控数据的持久化,图中的 TSDB(Time series database)模块,负责将采集到的数据持久化到 SSD 等磁盘设备中。TSDB 是专门为时间 序列数据设计的一种数据库,特点是以时间为索引、数据量大并且以追加的方式写入。
- 第三个是数据查询和处理模块。刚才提到的 TSDB,在存储数据的同时,其实还提供了数据 查询和基本的数据处理功能,而这也就是 PromQL 语言。PromQL 提供了简洁的查询、过 滤功能,并且支持基本的数据处理方法,是告警系统和可视化展示的基础。
- 第四个是告警模块。右上角的 AlertManager 提供了告警的功能,包括基于 PromQL 语言 的触发条件、告警规则的配置管理以及告警的发送等。不过,虽然告警是必要的,但过于频 繁的告警显然也不可取。所以,AlertManager 还支持通过分组、抑制或者静默等多种方式 来聚合同类告警,并减少告警数量。
- 最后一个是可视化展示模块。Prometheus 的 web UI 提供了简单的可视化界面,用于执行 PromQL 查询语句,但结果的展示比较单调。不过,一旦配合 Grafana,就可以构建非常 强大的图形界面了。
USE 方法为例使用 Prometheus,可以收集 Linux 服务器的 CPU、内存、磁盘、网络等各类资源的使用率、饱和度和错误数指标。然后,通过 Grafana 以及 PromQL 查询语句,就可以把它们以图形界面的方式直观展示出来。
应用监控
RED 方法
RED 方法,是 Weave Cloud 在监控微服务性能时,结合 Prometheus 监控,所提出的一 种监控思路——即对微服务来说,监控它们的请求数(Rate)、错误数(Errors)以及响 应时间(Duration)。所以,RED 方法适用于微服务应用的监控,而 USE 方法适用于系统资源的监控。
性能指标监控--性能瓶颈
构建应用程序的监控系统之前,首先也需要确定需要监控哪些指 标
哪些指标可以用来快速确认应用程序的性能问题。
对系统资源的监控,USE 法简单有效,却不代表其适合应用程序的监控。举个例子,即使 在 CPU 使用率很低的时候,也不能说明应用程序就没有性能瓶颈。因为应用程序可能会因 为锁或者 RPC 调用等,导致响应缓慢。
应用程序的核心指标,不再是资源的使用情况,而是请求数、错误率和响应时间。
第一个,是应用进程的资源使用情况,比如进程占用的 CPU、内存、磁盘 I/O、网络等。 使用过多的系统资源,导致应用程序响应缓慢或者错误数升高,是一个最常见的性能问题。
第二个,是应用程序之间调用情况,比如调用频率、错误数、延时等。由于应用程序并不是 孤立的,如果其依赖的其他应用出现了性能问题,应用自身性能也会受到影响。
第三个,是应用程序内部核心逻辑的运行情况,比如关键环节的耗时以及执行过程中的错误 等。在设计和开发时,就应该把这些指标提供出来,以便监控系统可以了解其内部运行状态。
由于业务系统通常会涉及到一连串的多个服务,形成一个复杂的分布式调用链。 为了迅速定位这类跨应用的性能瓶颈,你还可以使用 Zipkin、Jaeger、Pinpoint 等各类开 源工具,来构建全链路跟踪系统。全链路跟踪可以帮你迅速定位出,在一个请求处理过程中,哪个环节才是问题根源。
全链路跟踪除了可以帮你快速定位跨应用的性能问题外,还可以帮你生成线上系统的调用拓 扑图。这些直观的拓扑图,在分析复杂系统(比如微服务)时尤其有效。
日志监控--辅助性能监控提供上下文
同样的一个接口,当请求传入的参数不同时,就可能会导致完全不同的性能问题。所以,除了指标外,我们还需要对这些指标的上下文信息进行监控,而日志正是这些上下文的最佳来源。
指标是特定时间段的数值型测量数据,通常以时间序列的方式处理,适合于实时监控。 而日志则完全不同,日志都是某个时间点的字符串消息,通常需要对搜索引擎进行索引 后,才能进行查询和汇总分析。
对日志监控来说,最经典的方法,就是使用 ELK 技术栈,即使用 Elasticsearch、Logstash 和 Kibana 这三个组件的组合。
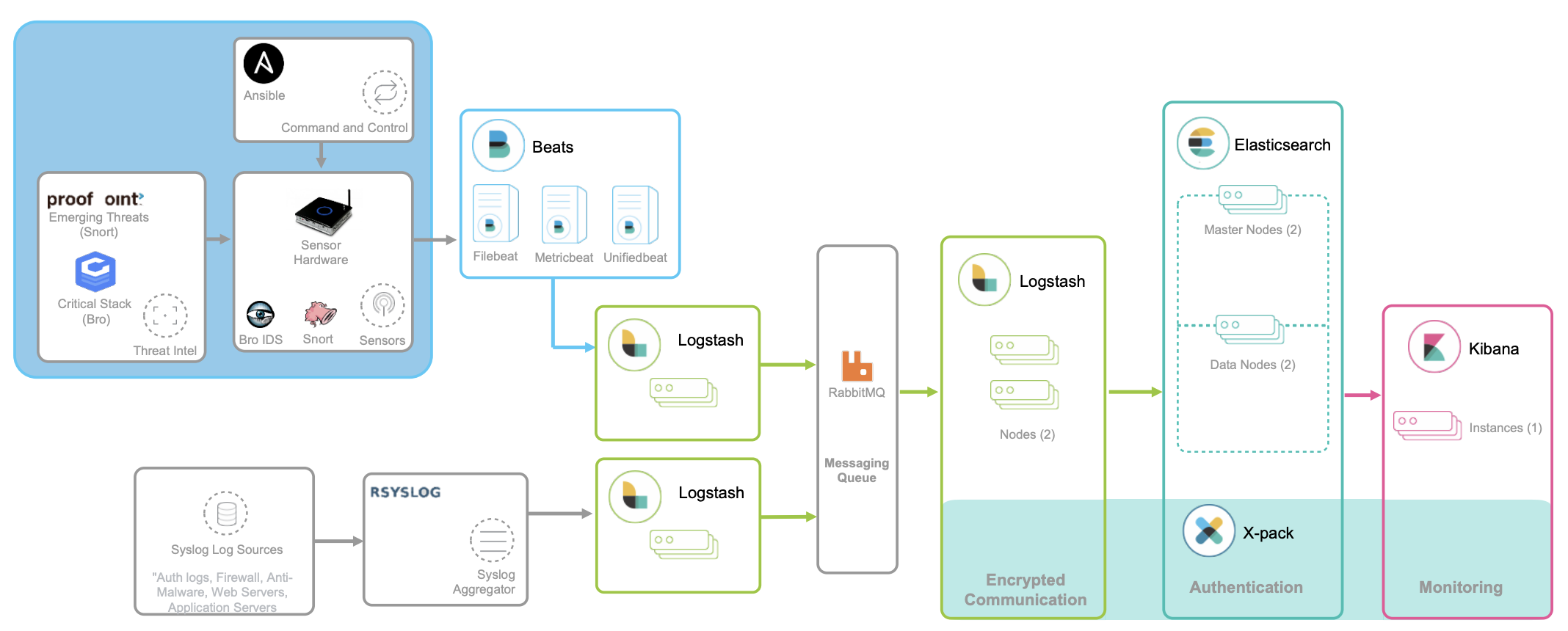
Logstash 负责对从各个日志源采集日志,然后进行预处理,最后再把初步处理过的日志,发送给 Elasticsearch 进行索引。
Elasticsearch 负责对日志进行索引,并提供了一个完整的全文搜索引擎,这样就可以方便你从日志中检索需要的数据。
Kibana 则负责对日志进行可视化分析,包括日志搜索、处理以及绚丽的仪表板展示等。
ELK 技术栈中的 Logstash 资源消耗比较大。所以,在资源紧张的环境中, 我们往往使用资源消耗更低的 Fluentd,来替代 Logstash(也就是所谓的 EFK 技术栈)。
总结
指标监控主要是对一定时间段内性能指标进行测量,然后再通过时间序列的方式,进行处 理、存储和告警。
日志监控则可以提供更详细的上下文信息,通常通过 ELK 技术栈来进行收集、索引和图 形化展示。
在跨多个不同应用的复杂业务场景中,可以构建全链路跟踪系统。这样可以动态跟踪调用链中各个组件的性能,生成整个流程的调用拓扑图,从而加快定位复杂应用的性能问题。
posted on 2025-10-12 21:44 chuchengzhi 阅读(24) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号