
Linux的IO知识总结
文件系统,是对存储设备上的文件进行组织管理的一种机制。为了支持各类不同的文件系 统,Linux 在各种文件系统上,抽象了一层虚拟文件系统 VFS。
它定义了一组所有文件系统都支持的数据结构和标准接口。这样,应用程序和内核中的其他 子系统,就只需要跟 VFS 提供的统一接口进行交互。
在文件系统的下层,为了支持各种不同类型的存储设备,Linux 又在各种存储设备的基础 上,抽象了一个通用块层。 通用块层,为文件系统和应用程序提供了访问块设备的标准接口;同时,为各种块设备的驱 动程序提供了统一的框架。此外,通用块层还会对文件系统和应用程序发送过来的 I/O 请 求进行排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
通用块层的下一层,自然就是设备层了,包括各种块设备的驱动程序以及物理存储设备。
文件系统、通用块层以及设备层,就构成了 Linux 的存储 I/O 栈。存储系统的 I/O ,通常 是整个系统中最慢的一环。所以,Linux 采用多种缓存机制,来优化 I/O 的效率,比方说,
为了优化文件访问的性能,采用页缓存、索引节点缓存、目录项缓存等多种缓存机制,减 少对下层块设备的直接调用。
同样的,为了优化块设备的访问效率,使用缓冲区来缓存块设备的数据。
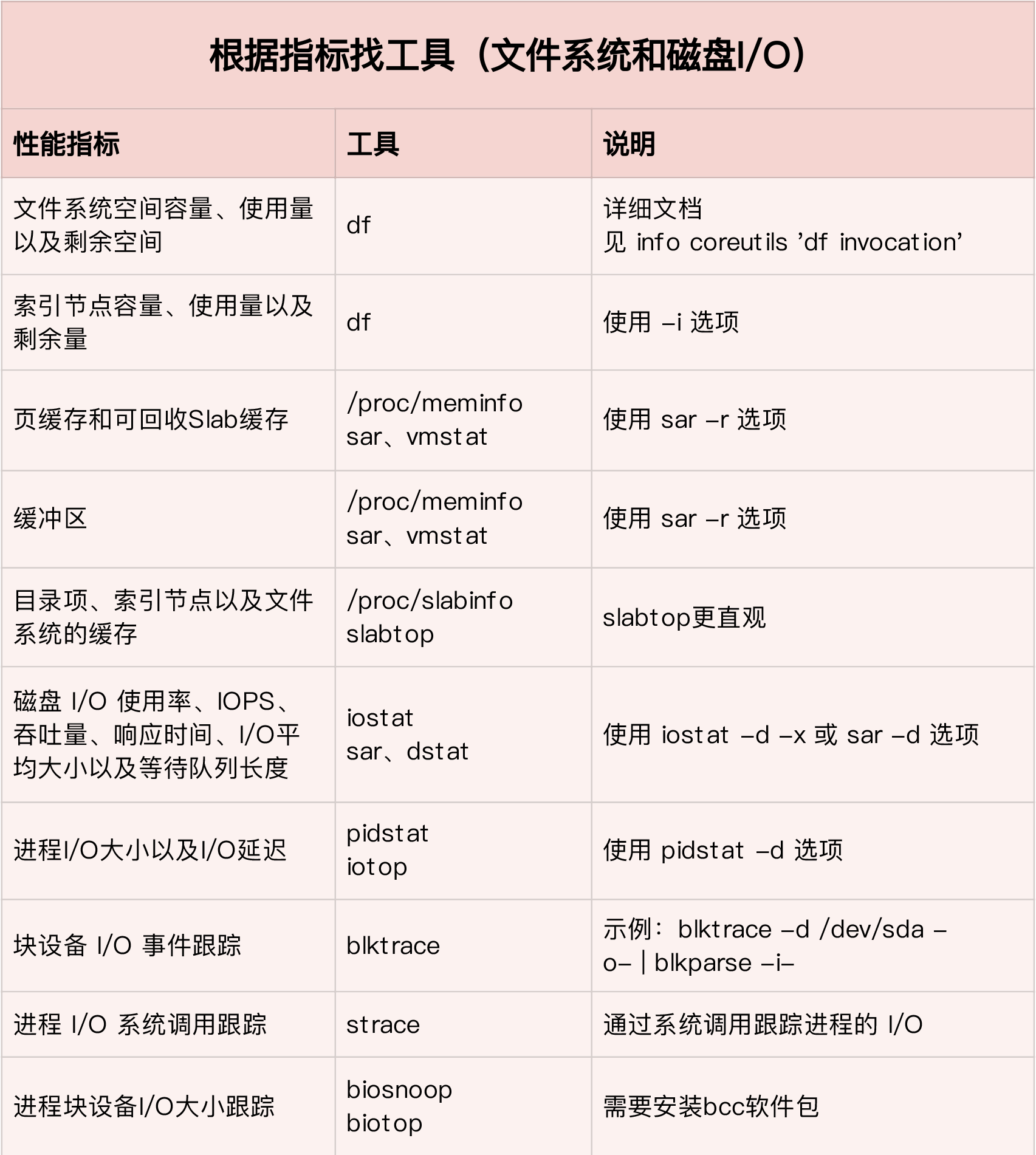
性能指标
文件系统 I/O 性能指标
数据本身存储空间
存储空间的使用情况,包括容量、使用量以及剩余空间等。磁盘空间的使用量,因为文件系统的数据最终还是存储在磁盘上。 这些只是文件系统向外展示的空间使用,而非在磁盘空间的真实用量,因为文 件系统的元数据也会占用磁盘空间。
配置了 RAID,从文件系统看到的使用量跟实际磁盘的占用空间,也会因为 RAID 级别的不同而不一样。比方说,配置 RAID10 后,你从文件系统最多也只能看到所有 磁盘容量的一半。
索引节点的使用情况
它也包括容量、使用量以及剩余量等三个指标。如果文件系统中存储过多的小文件,就可能碰到索引节点容量已满的问题。
缓存使用情况
包括页缓存、目录项缓存、索引节 点缓存以及各个具体文件系统(如 ext4、XFS 等)的缓存。这些缓存会使用速度更快的内存,用来临时存储文件数据或者文件系统的元数据,从而可以减少访问慢速磁盘的次数。
文件 I/O
包括 IOPS(包括 r/s 和 w/s)、响应 时间(延迟)以及吞吐量(B/s)等。
通常还要考虑实际文件的读写情 况。比如,结合文件大小、文件数量、I/O 类型等,综合分析文件 I/O 的性能。
只能通过系统调用、动态跟踪或者基准测试等方法,间接进行观察、评估。
磁盘 I/O 性能指标
- 使用率,是指磁盘忙处理 I/O 请求的百分比。过高的使用率(比如超过 60%)通常意味 着磁盘 I/O 存在性能瓶颈。
- IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
- 吞吐量,是指每秒的 I/O 请求大小。 响应时间,是指从发出 I/O 请求到收到响应的间隔时间。
- 缓冲区 (Buffer)指标,它经常出现在内存和磁盘问题的分析中。
考察这些指标时,一定要注意综合 I/O 的具体场景来分析,比如读写类型(顺序还是随 机)、读写比例、读写大小、存储类型(有无 RAID 以及 RAID 级别、本地存储还是网络 存储)等。
有个大忌,就是把不同场景的 I/O 性能指标,直接进行分析对比。
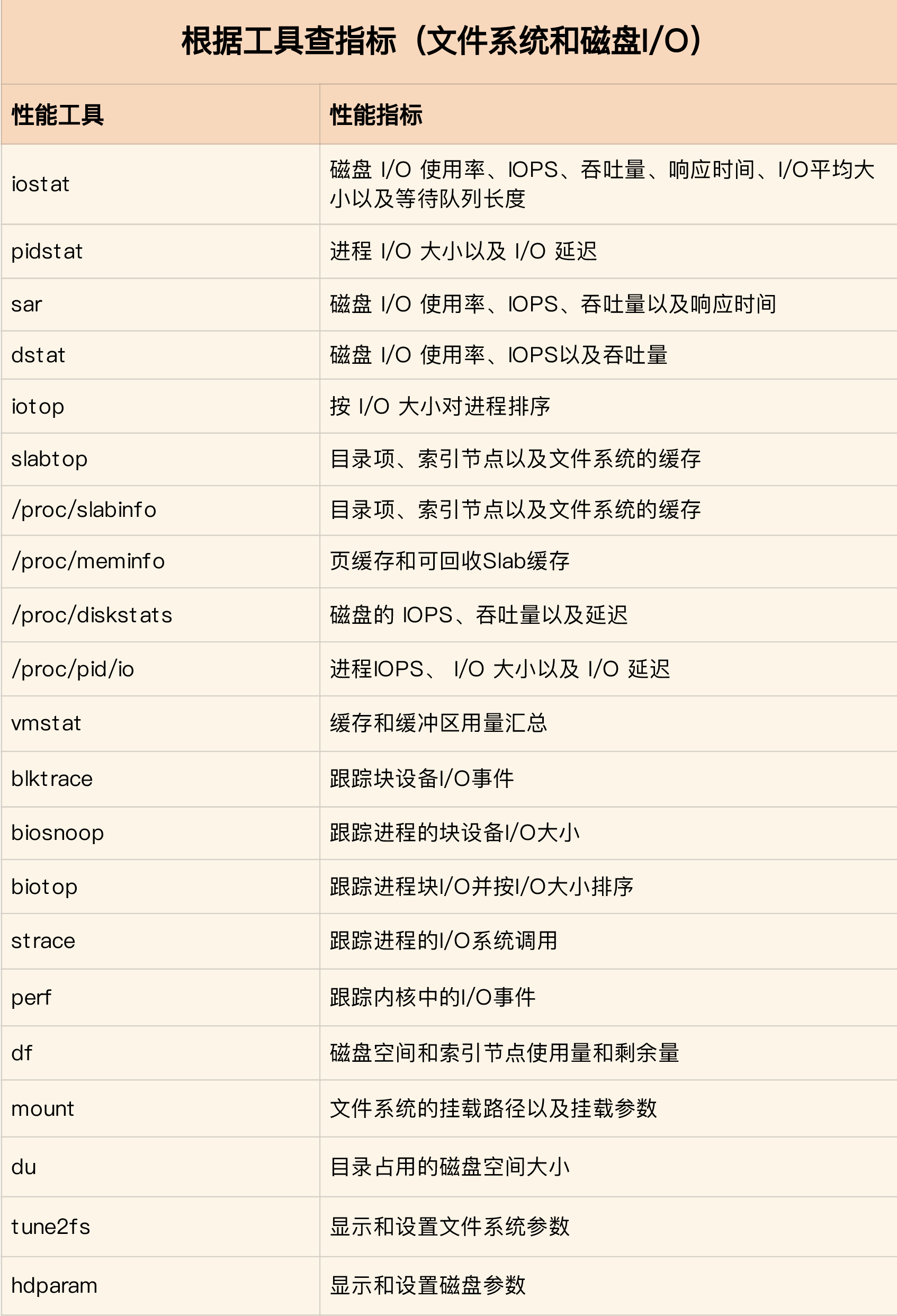
性能工具
第一,在文件系统的原理中,df既可以查看文件系 统数据的空间容量,也可以查看索引节点的容量。至于文件系统缓存,我们通过 /proc/meminfo、/proc/slabinfo 以及 slabtop 等各种来源,观察页缓存、目录项缓存、 索引节点缓存以及具体文件系统的缓存情况。
第二,在磁盘 I/O 的原理中,用 iostat 和 pidstat 观察了磁盘和进程的 I/O 情 况。它们都是最常用的 I/O 性能分析工具。通过 iostat ,我们可以得到磁盘的 I/O 使用 率、吞吐量、响应时间以及 IOPS 等性能指标;而通过 pidstat ,则可以观察到进程的 I/O 吞吐量以及块设备 I/O 的延迟等。
第三,在狂打日志的案例中, top 查看系统的 CPU 使用情况,发现 iowait 比较 高;然后,又用 iostat 发现了磁盘的 I/O 使用率瓶颈,并用 pidstat 找出了大量 I/O 的进 程;最后,通过 strace 和 lsof找出了问题进程正在读写的文件,并最终锁定性能问 题的来源——原来是进程在狂打日志。
第四,在磁盘 I/O 延迟的单词热度案例中,top、iostat ,发现磁盘有 I/O 瓶颈,并用 pidstat 找出了大量 I/O 的进程。在随后的 strace 命令中,居然没看到 write 系统调用。用新工具 filetop 和 opensnoop ,从内核中跟踪系统调用,最终找出瓶颈的来源。
最后,在 MySQL 和 Redis 的案例中,同样的思路, top、iostat 以及 pidstat , 确定并找出 I/O 性能问题的瓶颈来源,它们正是 mysqld 和 redis-server。随后,我们又 用 strace+lsof 找出了它们正在读写的文件。
关于 MySQL 案例,根据 mysqld 正在读写的文件路径,再结合 MySQL 数据库引擎的原 理,我们不仅找出了数据库和数据表的名称,还进一步发现了慢查询的问题,最终通过优化 索引解决了性能瓶颈。
至于 Redis 案例,根据 redis-server 读写的文件,以及正在进行网络通信的 TCP Socket,再结合 Redis 的工作原理,我们发现 Redis 持久化选项配置有问题;从 TCP Socket 通信的数据中,我们还发现了客户端的不合理行为。于是,我们修改 Redis 配置选 项,并优化了客户端使用 Redis 的方式,从而减少网络通信次数,解决性能问题。
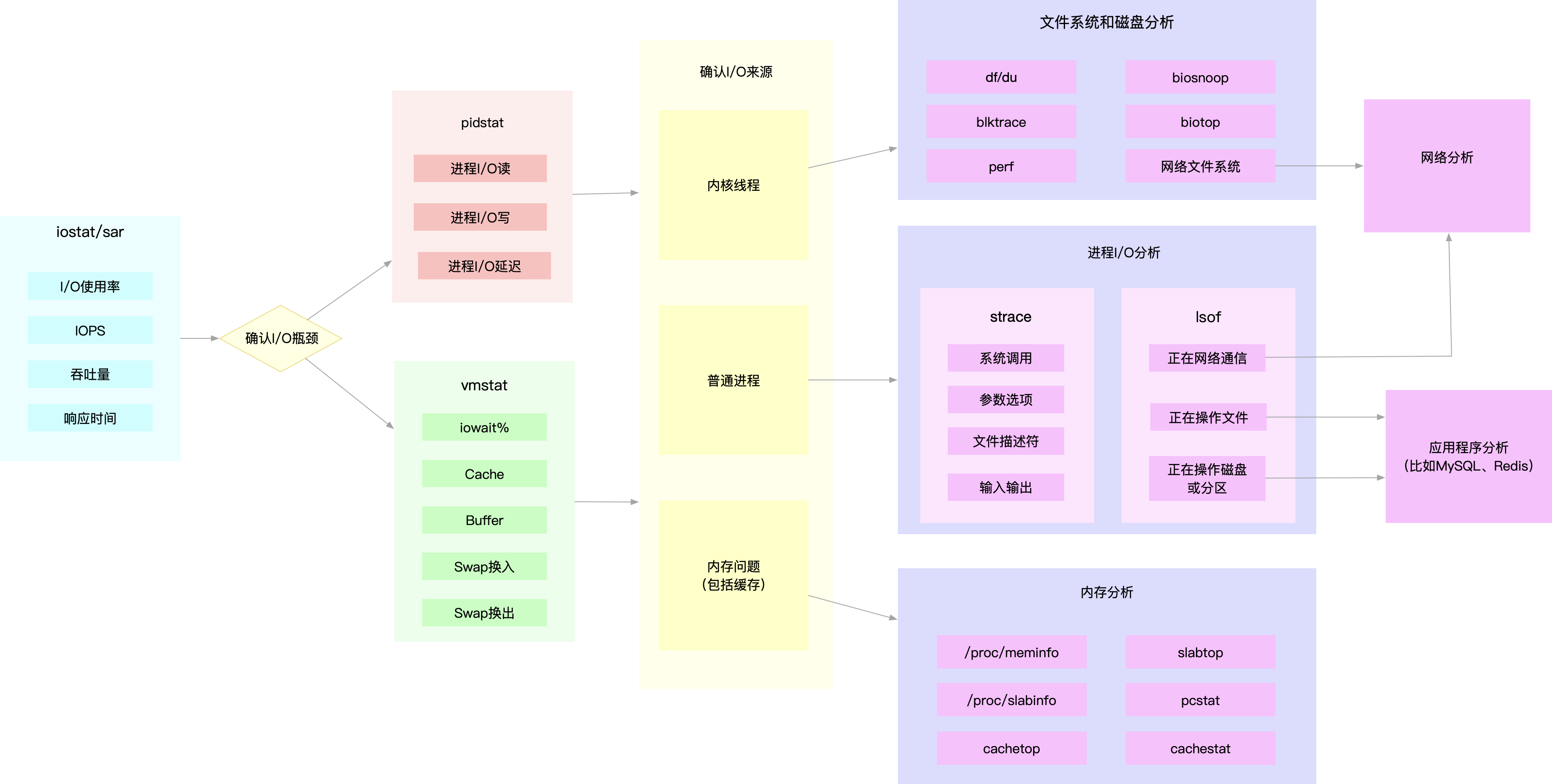
分析思路
-
先用 iostat 发现磁盘 I/O 性能瓶颈;
-
再借助 pidstat ,定位出导致瓶颈的进程;
-
随后分析进程的 I/O 行为;
-
最后,结合应用程序的原理,分析这些 I/O 的来源。
为了缩小排查范围,我通常会先运行那几个支持指标较多的工具,如 iostat、 vmstat、pidstat 等。然后再根据观察到的现象,结合系统和应用程序的原理,寻找下一 步的分析方向。
不要依赖系统缓 存来加速磁盘 I/O 的访问
依赖系统缓 存来加速磁盘 I/O 的访问。一旦系统中还有其他应用同时运行, 就很难充分 利用系统缓存。因为系统缓存可能被其他应用程序占用,甚至直接被清理掉。所以,一般来说,最好能在应用程序的内部分配内存,构建完全自主控制的缓存,比如 MySQL 的 InnoDB 引擎,就同时缓存了索引和数据;或者,可以使用第三方的缓存应用,比如 Memcached、Redis 等。
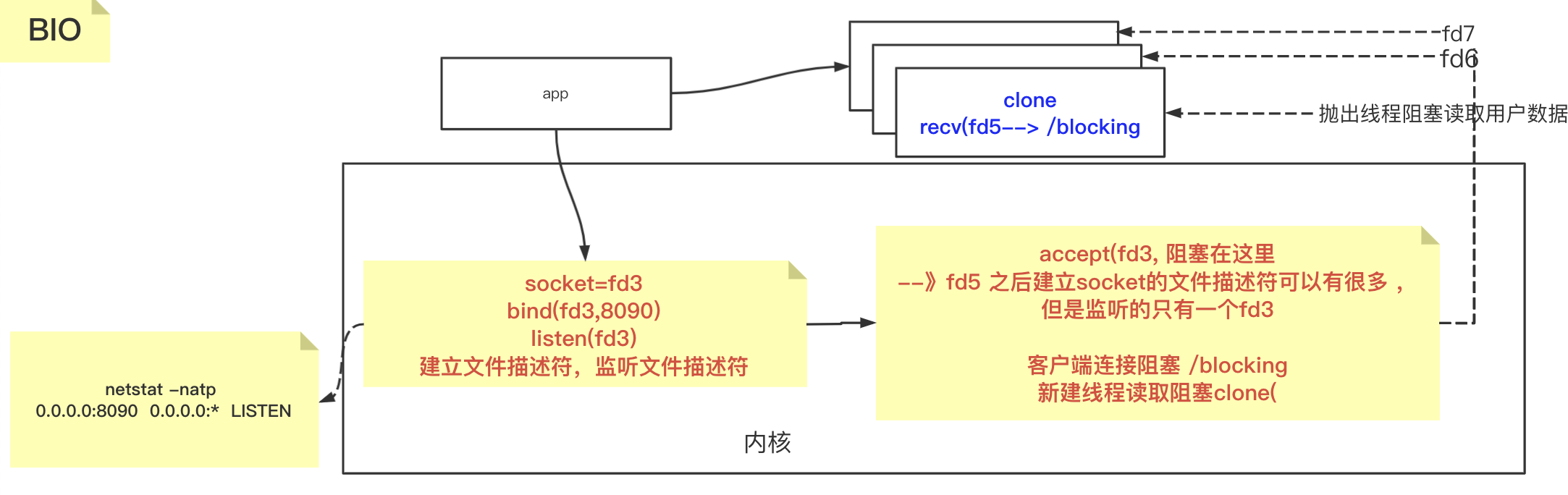
BIO
所有的java 封装的IO 调用都是最后和系统的内核交互
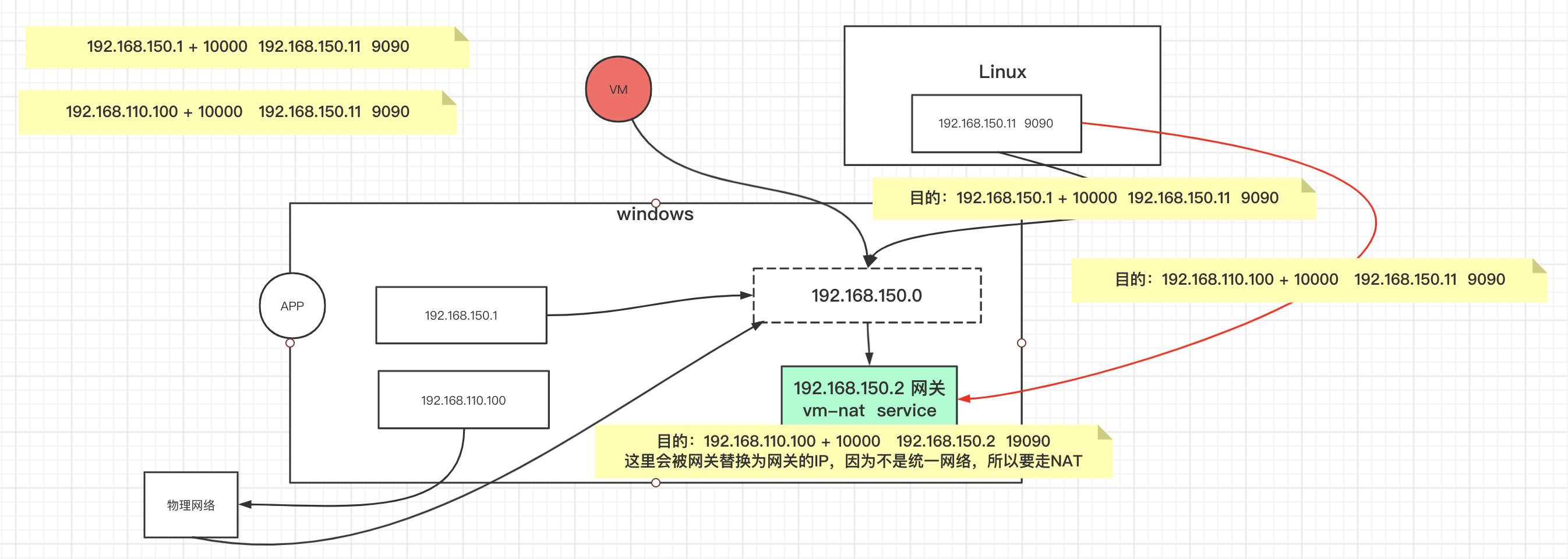
C10K
两个不同的IP建立连接的时候的作用
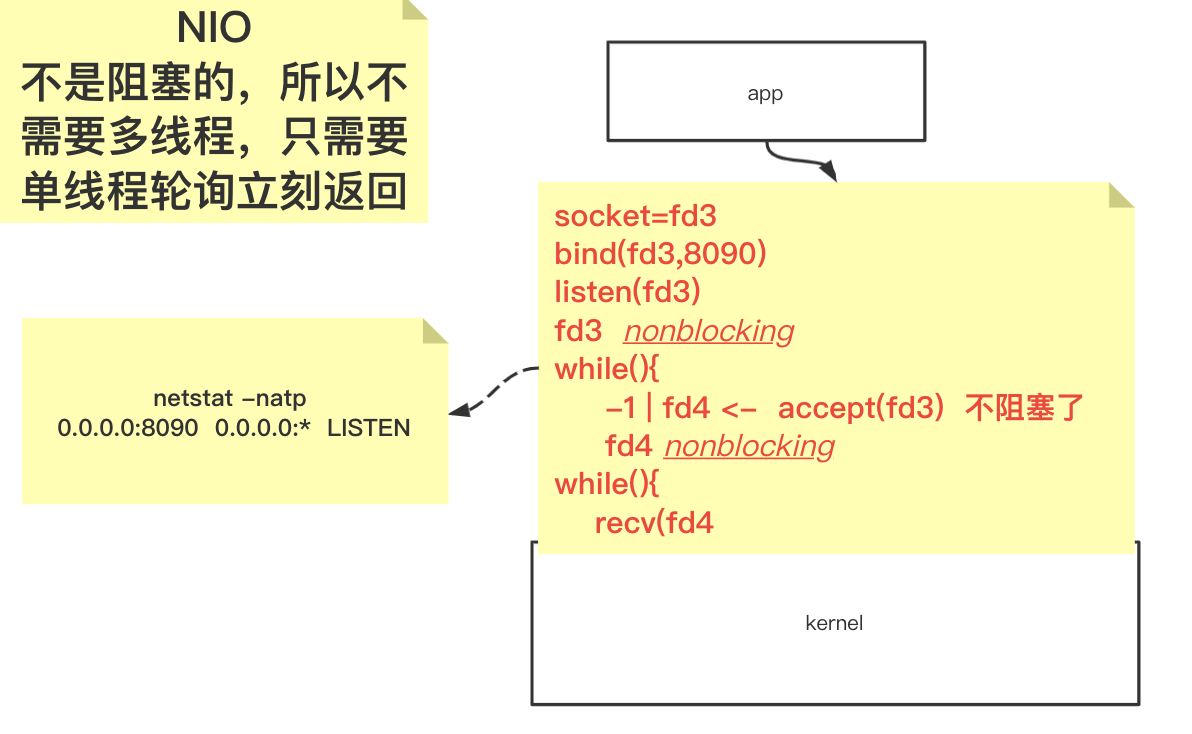
NIO
说说IO阻塞与⾮阻塞是什么?各⾃有啥好处?知道多路复⽤吗?了解过 select 吗?说说他与 epoll 的区别
多路复用器
多路复用不会负责读写
四次挥手
客户端发送数据之后将自己的链接关闭
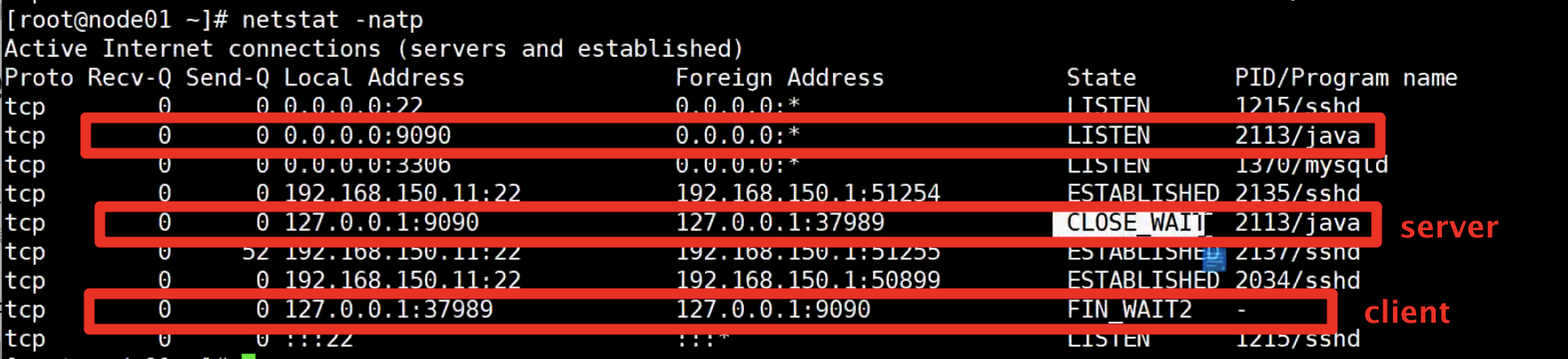
服务端关闭进入closed之后(下面没显示)。客户端会进入time_wait阶段
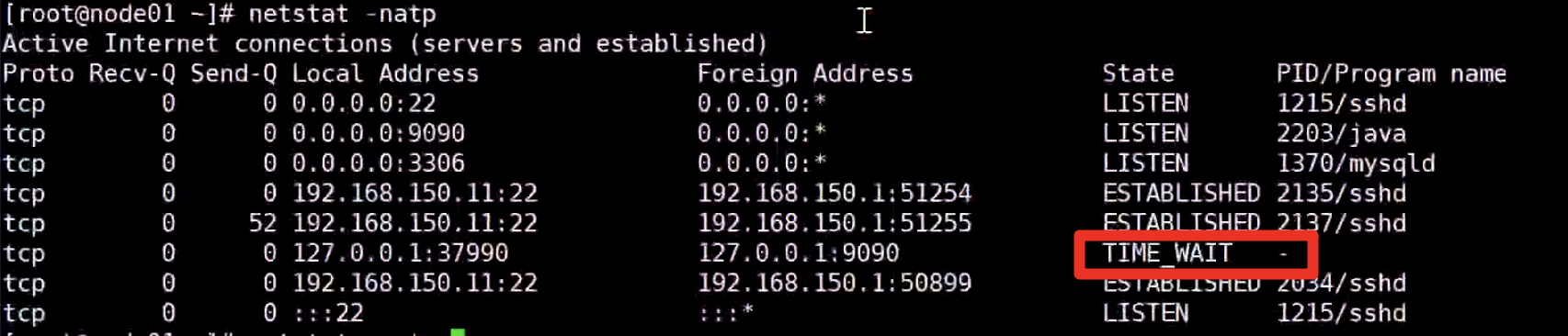
TIME_WAIT :报文活动时间 * 2 (MSL * 2)
谁先提起FIN,谁最后就是这个状态。
为什么需要?有可能最后的ACK对方没有收到,自己先等等再关闭,为了对方服务。(内核里面的,PID已经没有绑定的了)
在TIME_WAIT没有结束前,内核中的socket的四元组被占用,相同的对端不能使用这个资源建立新的连接。
浪费的是当前IP的客户端的名额!这个不是DDOS,其他IP的客户端可以连接,因为四元组不一样
java 的 Selector (包装多路复用器)
懒加载
触发一次系统调用
register对应的epoll_ctl 实际上是在 调用Selector的select的时候(也就是epoll_wait)才会执行。
写事件
send-queue 只要是空的就可以调用写事件。
read 是从客户端读取,write是写给客户端
单线程,所有事情线性发生
只有一个线程
多线程:无论读写都新一个线程,主线程只负责使用多路复用器发现事件
select() 最后返回的是事件结果集。所以迭代删除key.cancel()的时候不会删除内核里面红黑树上注册的事件,只会删除自己取回来的集合里面的事件
只要send-queue 不为空,就会一直写事件,key.cancel() 将事件删除了。就不会一直调用了
单线程模式
混杂模式
- 初始:Listen和自己的client是在同一个组,不同组之间相互隔离。
- 改进:Listener不仅仅是管理自己组的,还要持有其余组的。
主从模式
posted on 2025-10-12 21:44 chuchengzhi 阅读(14) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号