
用户和系统CPU使用率升高
CPU节拍率和节拍数
为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数。每发生一次时间中断,Jiffies 的值就加 1。
节拍率 HZ 是内核的可配选项,可以设置为 100、250、1000 等。不同的系统可能设置不同数值,你可以通过查询 /boot/config 内核选项来查看它的配置值。节拍率设置成了 250,也就是每秒钟触发 250 次时间中断。
grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=250
节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它总是固定为 100,也就是 1/100 秒。这样,用户空间程序并不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ。
CPU 使用率计算(一段时间内的)
数据空闲和总的时间来自于 <font style="color:#666666;background-color:rgba(246, 247, 251, 0.75);">cat /proc/stat | grep ^cpu </font>,,在05 里面有每一个字段的具体含义,可以查询。
使用上面的数据:开机以来的节拍数累加值,所以直接算出来的,是开机以 来的平均 CPU 使用率,一般没啥参考价值。我们计算的时候一般是用选个时间段来计算的

Linux中proc下的CPU和进程使用的统计信息
Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat 提供的就是系统的 CPU 和任务统计信息。
The proc file system is a pseudo-file system which is used as an interface to kernel data structures. It is commonly
mounted at /proc. Most of it is read-only, but some files allow kernel variables to be changed.
跟系统的指标类似,Linux 也给每个进程提供了运行情况的统计信息,也就是 /proc/[pid]/stat。
/proc/stat 和 /proc/[pid]/stat:性能分析工具给出的都是间隔一段时间的平均 CPU 使用率,所以要注意间隔时间的设置。
top 默认使用 3 秒时间间隔,而 ps 使用的却是进程的整个生命周期。所以二者的CPU使用率会不一样。
使用工具查看使用率
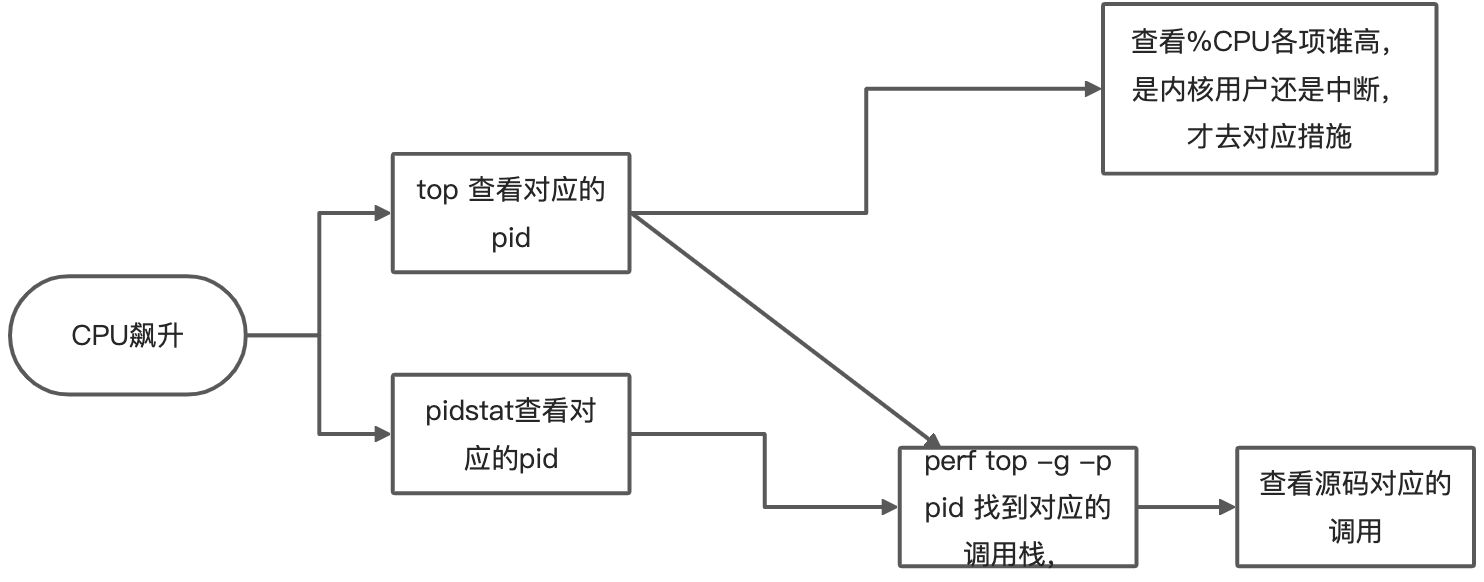
- top 显示了系统总体的** **CPU 和内存使用情况,以及各个进程的资源使用情况。
- ps 则只显示了每个进程的资源使用情况。
top:进程整体对CPU使用情况(重要)
top 默 认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。
第三行 %Cpu 就是系统的 CPU 使用率,具体每一列的含义:
- user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- 用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进 程的性能问题。
- 使用perf top -g -p pid 找到具体的调用关系
-
system(通常缩写为 sys),代表内核态 CPU 时间。
-
idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用 的性能问题。
-
iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现 了 I/O 问题。
-
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
-
softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重 排查内核中的中断服务程序。
-
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
-
guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
-
guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的 CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、 通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境中, 它还包括了运行虚拟机占用的 CPU。
top 并没有细分进程的用户态 CPU 和内核态 CPU。
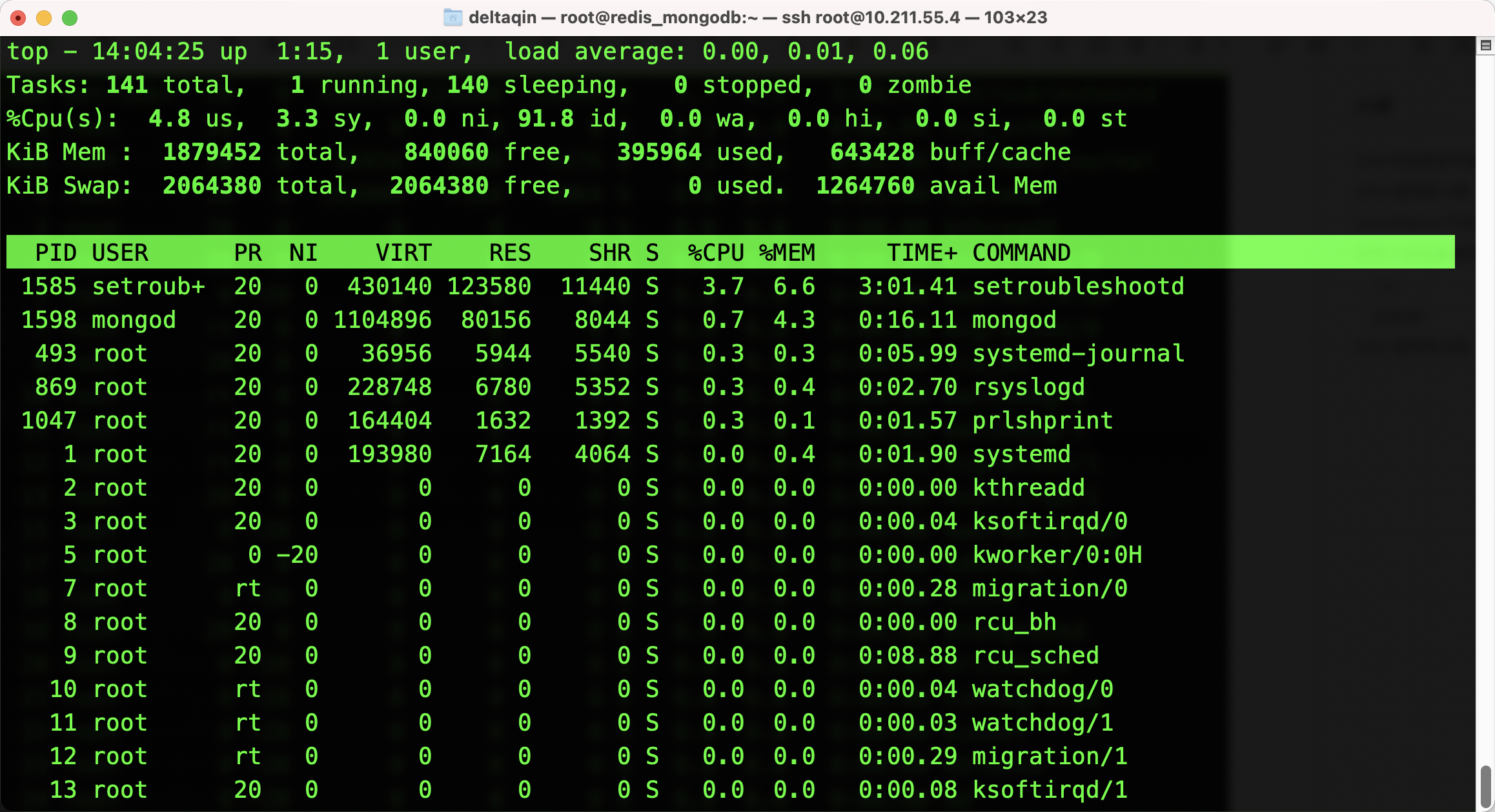
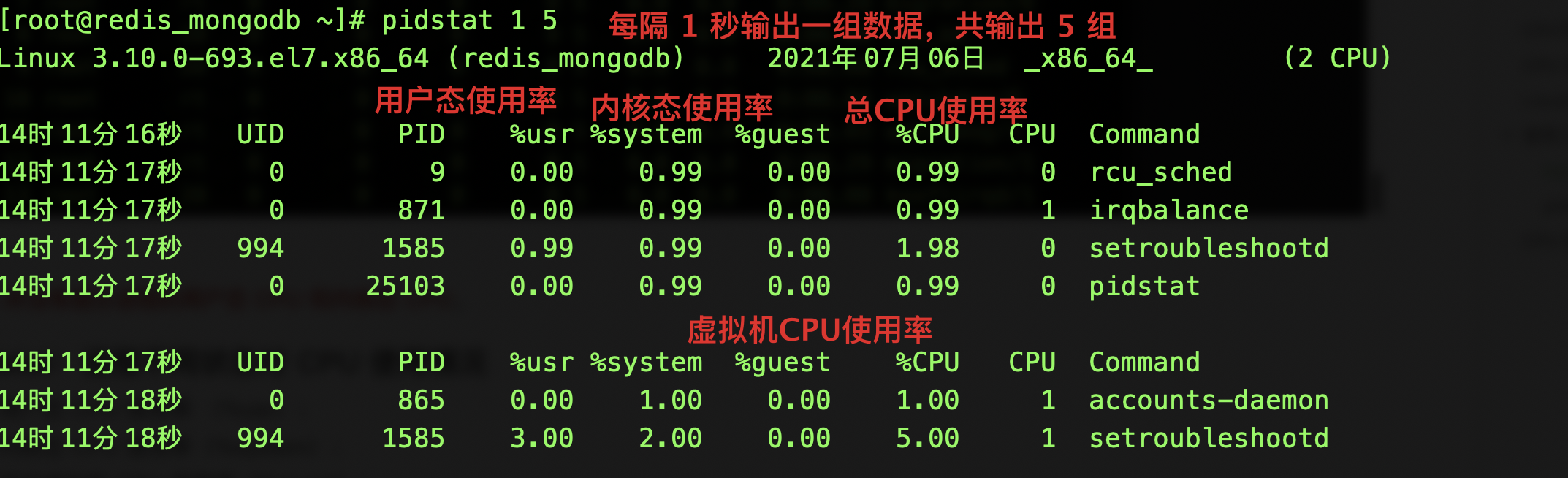
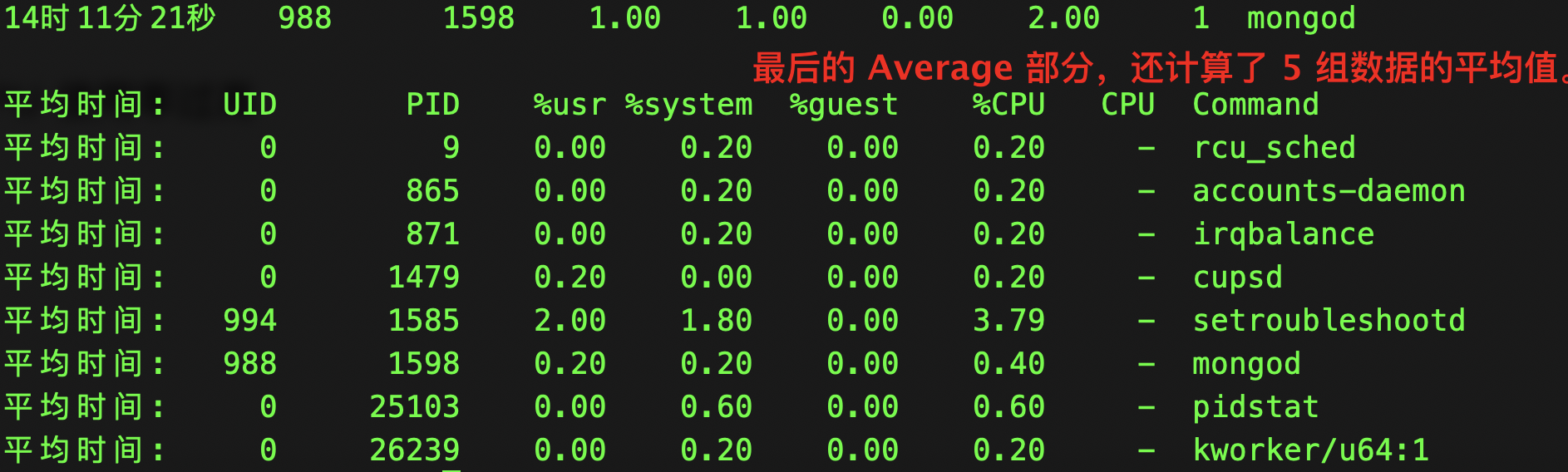
pidstat:进程不同状态对 CPU 使用情况
- 用户态 CPU 使用率 (%usr);
- 内核态 CPU 使用率(%system);
- 运行虚拟机 CPU 使用率(%guest);
- 等待 CPU 使用率(%wait);
- 以及总的 CPU 使用率(%CPU)。
找到 CPU 使用率较高的进程之后呢?--perf
perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事 件和内核性能,还可以用来分析指定应用程序的性能问题。
perf top 实时系统性能信息
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者 指令,因此可以用来查找热点函数,
第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事 件总数量(Event count)
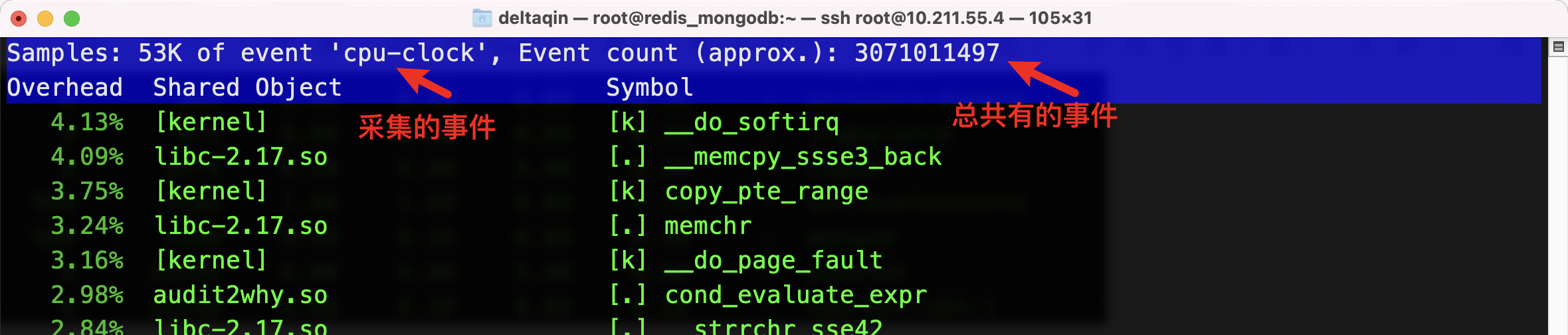
主要是使用-g 和 -p 找到进程的函数调用栈,看看是哪个函数在调用,造成目前的高负载,之后去源码找问题
-g 开启调用关系分析,-p 指定 php-fpm 的进程号 21515
按方向键切换到对应的进程,再按下回车键展开进程的调用关系,你会发现,调用关系最终到的函数。拷贝出来代码
docker cp phpfpm:/app .
grep sqrt -r app/ # 找到了 sqrt 调用
grep add_function -r app/ # 没找到 add_function 调用,这其实是 PHP 内置函数
文件的源码找到 sqrt 调用
perf record 保存数据,perf report 解析展示
perf record # 按 Ctrl+C 终止采样
perf report # 展示类似于 perf top 的报告
根本找不到CPU高的应用--短时任务,不断失败重启的任务
-
系统 CPU 使用率( %Cpu )这一行,你会发现,系统的整体 CPU 使用率是比 较高的:用户 CPU 使用率(us)已经到了 80%,系统 CPU 为 15.1%,而空闲 CPU (id)则只有 2.8%。
-
top 输出的进程列表可以发现,CPU 使用率最高的进程也只不过才 2.7%,看起来并 不高。
-
**pidstat 1 ** 间隔 1 秒输出一组数据(按 Ctrl+C 结束) 依旧很低
-
从头开始看 top 的每行输出 ,Tasks 这一行就绪队列中居然有 6 个 Running 状态的进程(6 running)
-
top 的 进程列表,这次主要看 Running(R) 状态的进程。想要的 都处于 Sleep(S)状态,而真正处于 Running(R)状态的,却是几个 stress 进程。
-
还是使用 pidstat 来分析这几个进程,并且使用 -p 选项指定进程的 PID。首先,从上 面 top 的结果中,找到这几个进程的 PID。比如,先随便找一个 24344,然后用 pidstat 命令看一下它的 CPU 使用情况:pidstat -p 24344,没有输出任何
-
从所有进程中查找 PID 是 24344 的进程 $ ps aux | grep 24344,还是没有输出。 原来这个进程已经不存在了,所以 pidstat 就没有任何 输出。
-
再次使用top查看。stress的pid不一样了,说明
- 第一个原因,进程在不停地崩溃重启,比如因为段错误、配置错误等等,这时,进程在退 出后可能又被监控系统自动重启了。
- 第二个原因,这些进程都是短时进程,也就是在其他应用内部通过 exec 调用的外面命 令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的 工具发现
-
用 pstree 就可以用树状形式显示所有进程之间的 关系:pstree | grep stress , 找到父进程后 ,再从父进程所在 的应用入手,排查问题的根源。看应用源码, 再执行 grep 查找是不是有代码再调用 stress 命令:
-
验证猜测: perf record -g, 记录性能事件,等待大约 15 秒后按 Ctrl+C 退出 。perf report 查看报告
posted on 2025-10-12 21:37 chuchengzhi 阅读(22) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号