Hadoop集群分布搭建
一、准备工作
1、最少三台虚拟机或者实体机(官网上是默认是3台),我这边是3台
s1: 10.211.55.18
s2: 10.211.55.19
s3: 10.211.55.20
2、安装JDK
3、配置SSH
4、修改hosts 文件vi /etc/hosts
在文件中添加:
地址 主机名
10.211.55.18 s1
10.211.55.19 s2
10.211.55.20 s3
5、下载hadoop
二、安装hadoop
1、解压hadoop2.9.0
mkdir -r /usr/soft
tar -zxvf hadoop2.9.0.tar.gz -C /usr/soft #解压到/usr/soft
2、配置环境变量(ps:我这边是centos7)
cd /etc/profile.d/
touch hadoop_envi.sh #创建脚本
vi hadoop_envi.sh #编辑脚本
以下都是 hadoop_envi.sh 文件里面内容,也是添加环境变量
HADOOP_INSTALL=/usr/soft/hadoop-2.9.0 PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin export HADOOP_INSTALL export PATH
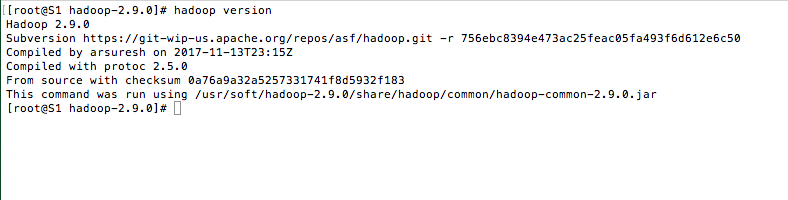
3、测试
hadoop version
三、编写hadoop配置文件,配置文件都在 hadoop2.9.0/etc/hadoop/ 下
1、core-site.xml 通用配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadooptmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>fs.defaultFS</name> #NameNode ip
<value>hdfs://s1/</value>
</property>
</configuration>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name> #资源管理器的主机
<value>s1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3. hdfs-site.xml 分布式文件相关配置
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/hdsf/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name> #文件块的备份数量 默认3个, 2、3都可以
<value>2</value>
</property>
</configuration>
4. mapre-site.xml 这个问题通过 mapred-site.xml.template复制而来的
<configuration>
<property>
<name>mapreduce.framework.name</name> #MapReduce框架名称
<value>yarn</value>
</property>
</configuration>
5、编辑slave
vi slaves
以下是 slaves 需要添加的内容
s2 #表示s2和s3 为数据节点,s2就是 10.211.55.19,s3就是 10.211.55.20 s3
四、启动hadoop
hadoop namenode -format #

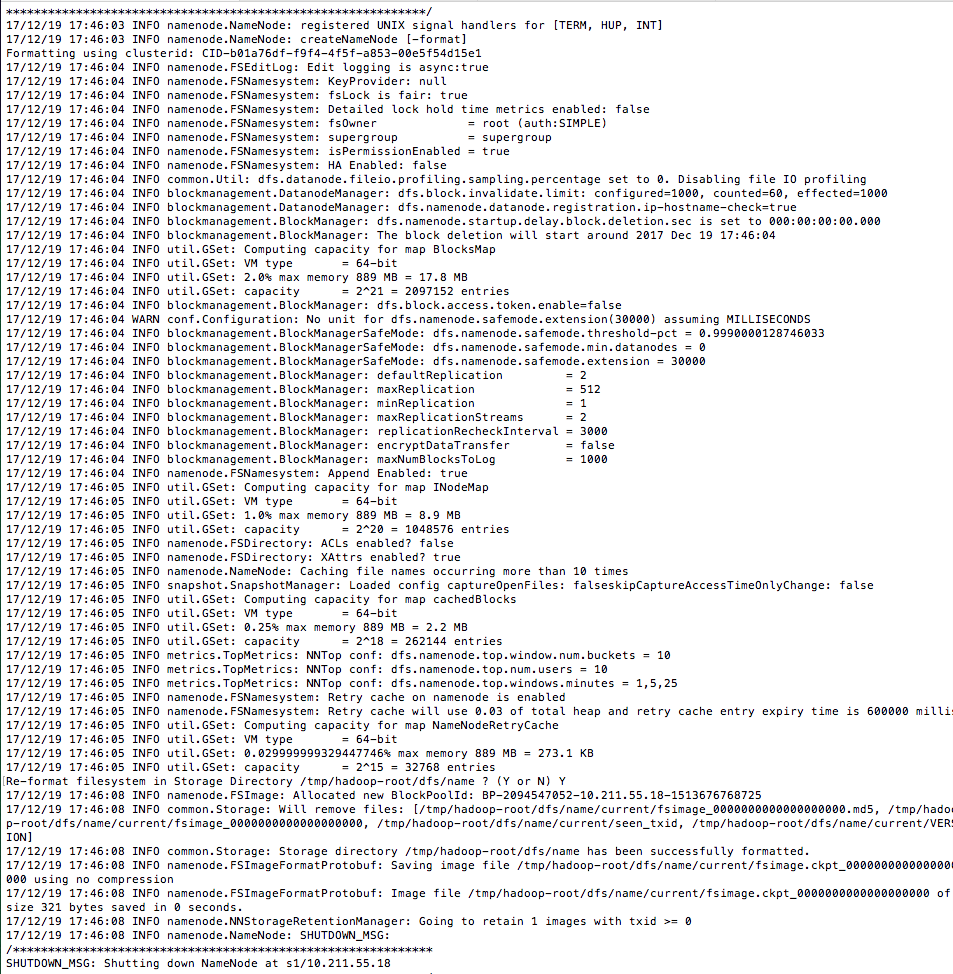
名称节点格式化成功
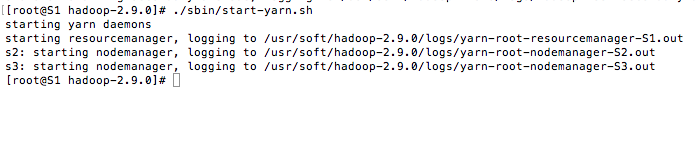
启动 dfs 和 yarn 这两个脚本文件都在 hadoop2.9.0/sbin 下
./sbin/start-dfs.sh

./sbin/start-yarn.sh
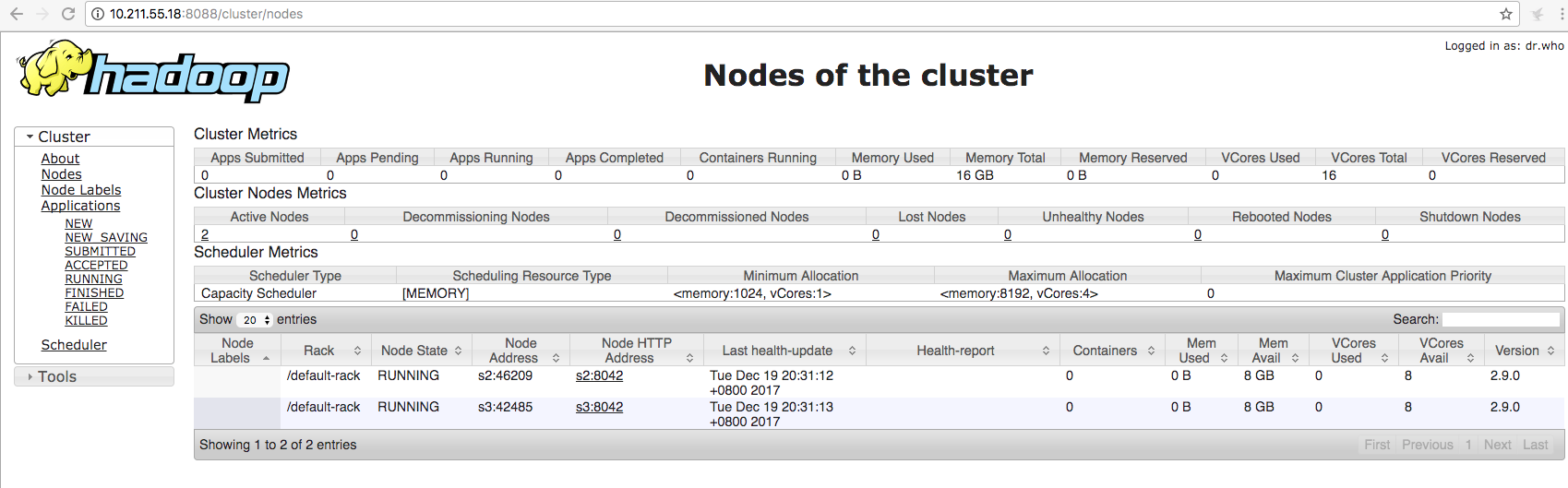
五、测试hadoop
前提:开发8088 和 50070端口 10.211.55.18是namenode 节点
http://10.211.55.18:8088
http://10.211.55.18:50070/



 浙公网安备 33010602011771号
浙公网安备 33010602011771号