
Redis rehash机制分析介绍
背景
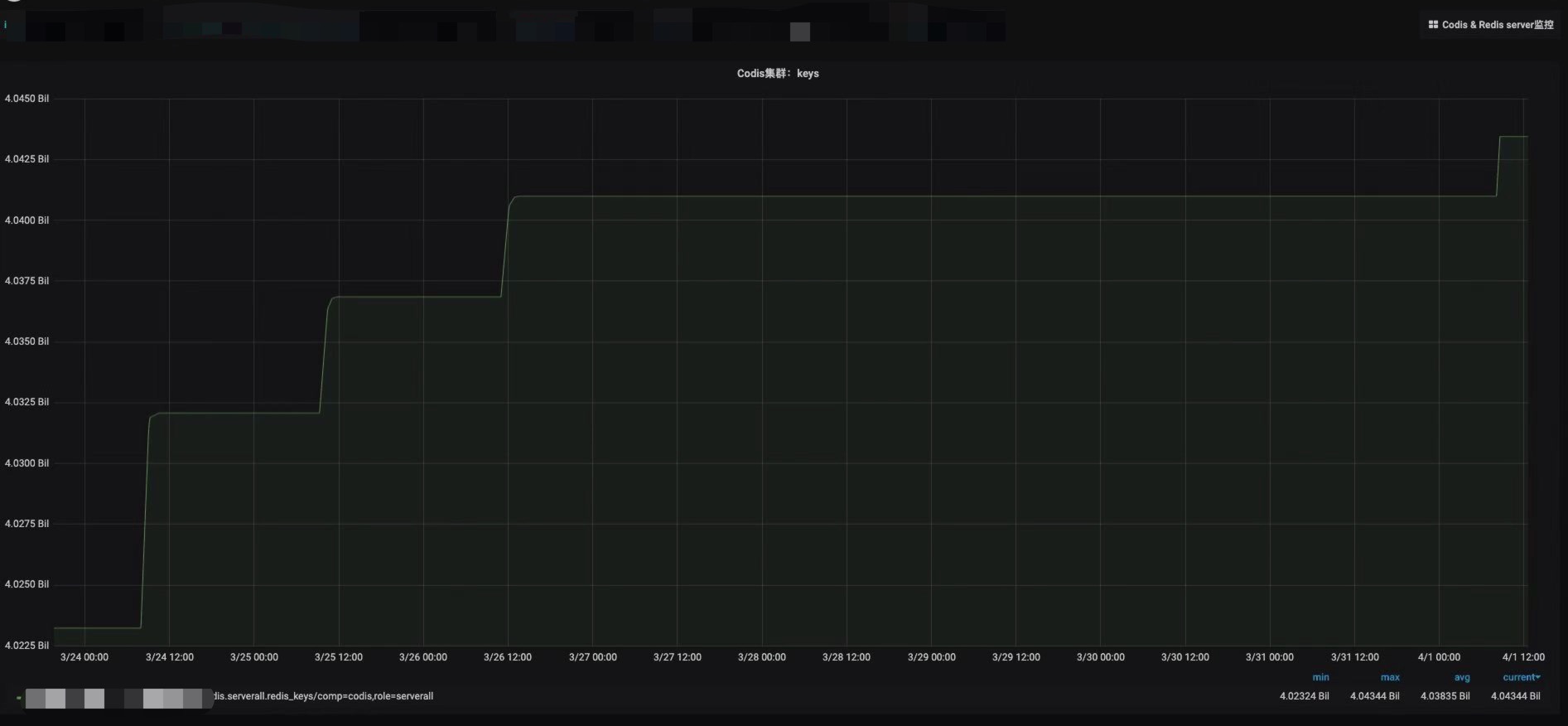
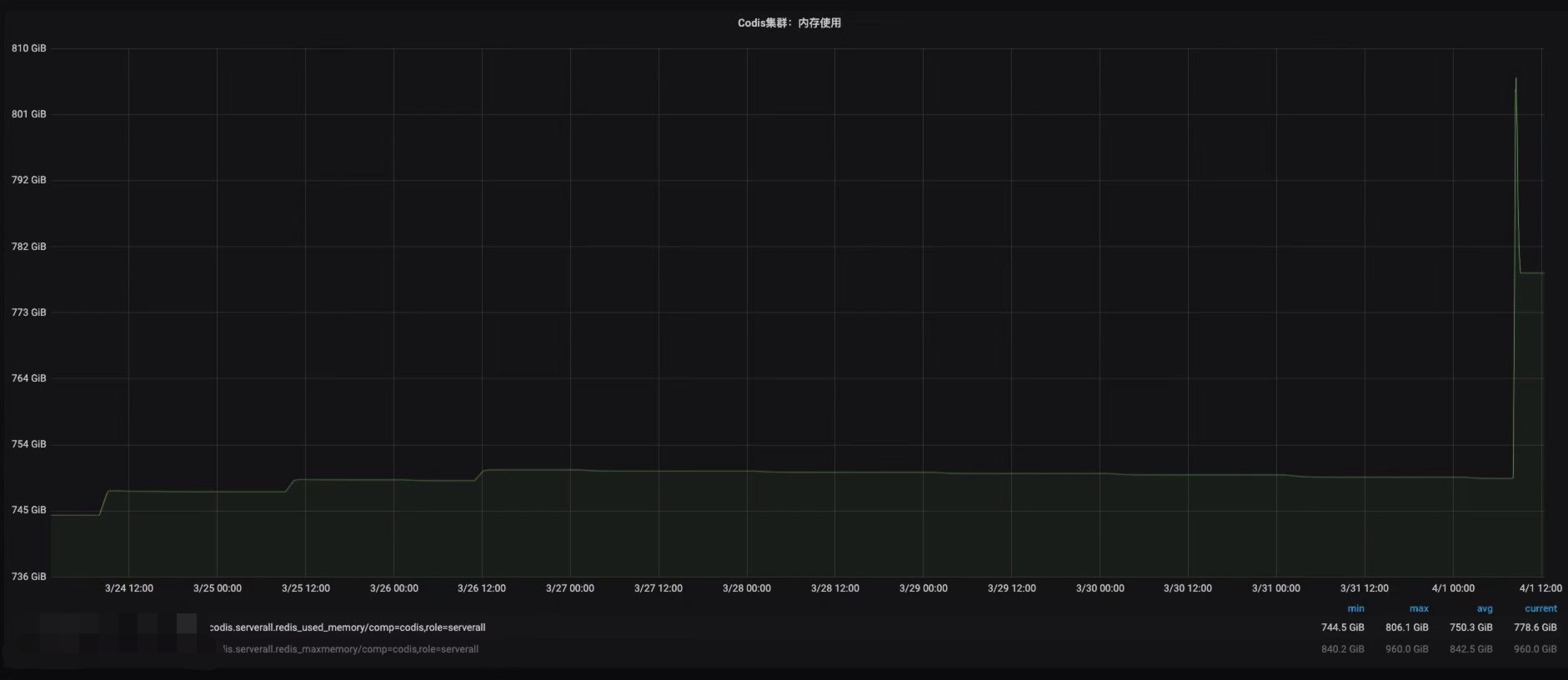
某个工作日,线上某集群跟往常一样导入约400万数据,集群内存却猛涨了约55G,BI导入的同学反馈没有变更。
其他现象:
该集群一共有60个主节点,其中有四个节点内存增长不明显,其他节点均瞬间增长了1G,并在增长了之后又降低了约500M。
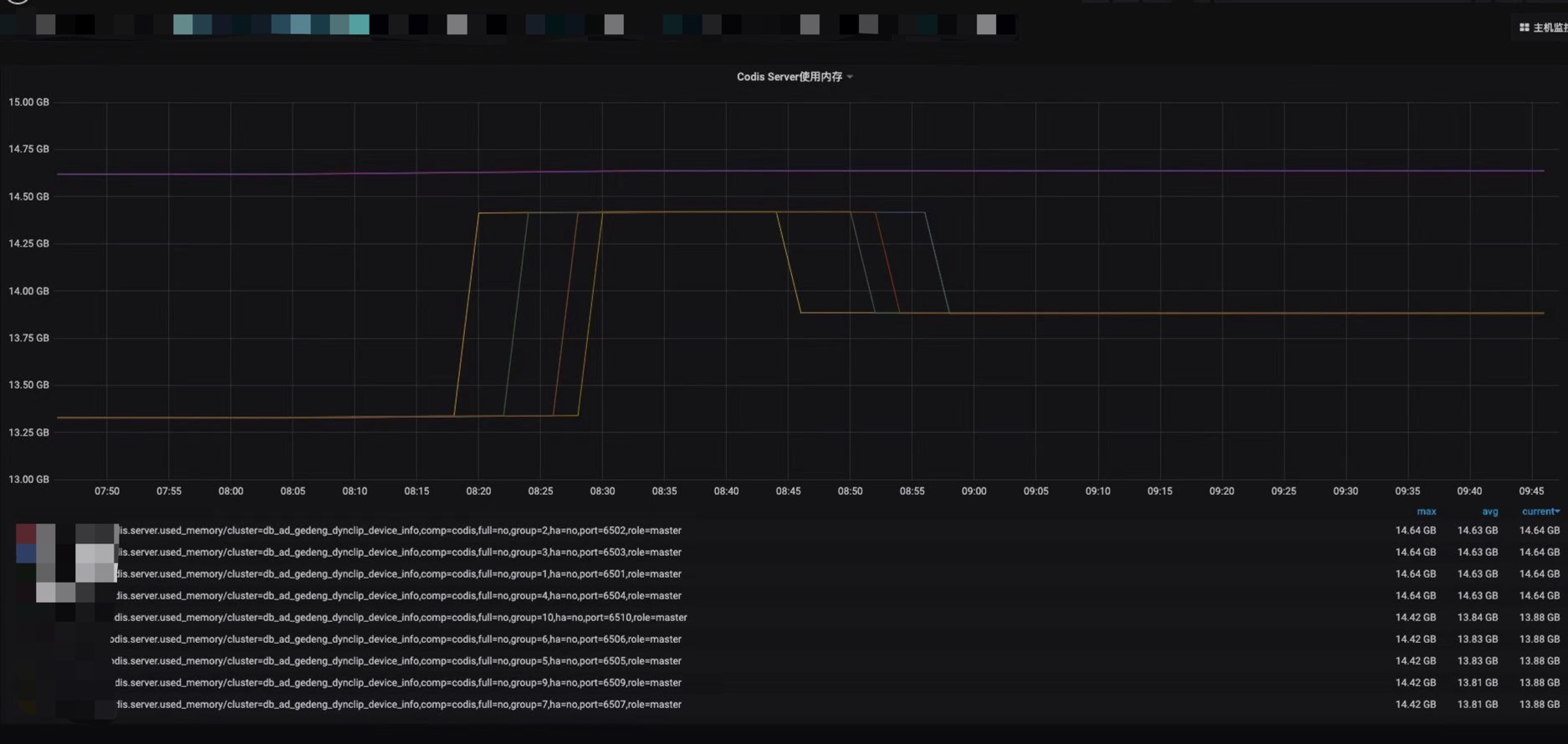
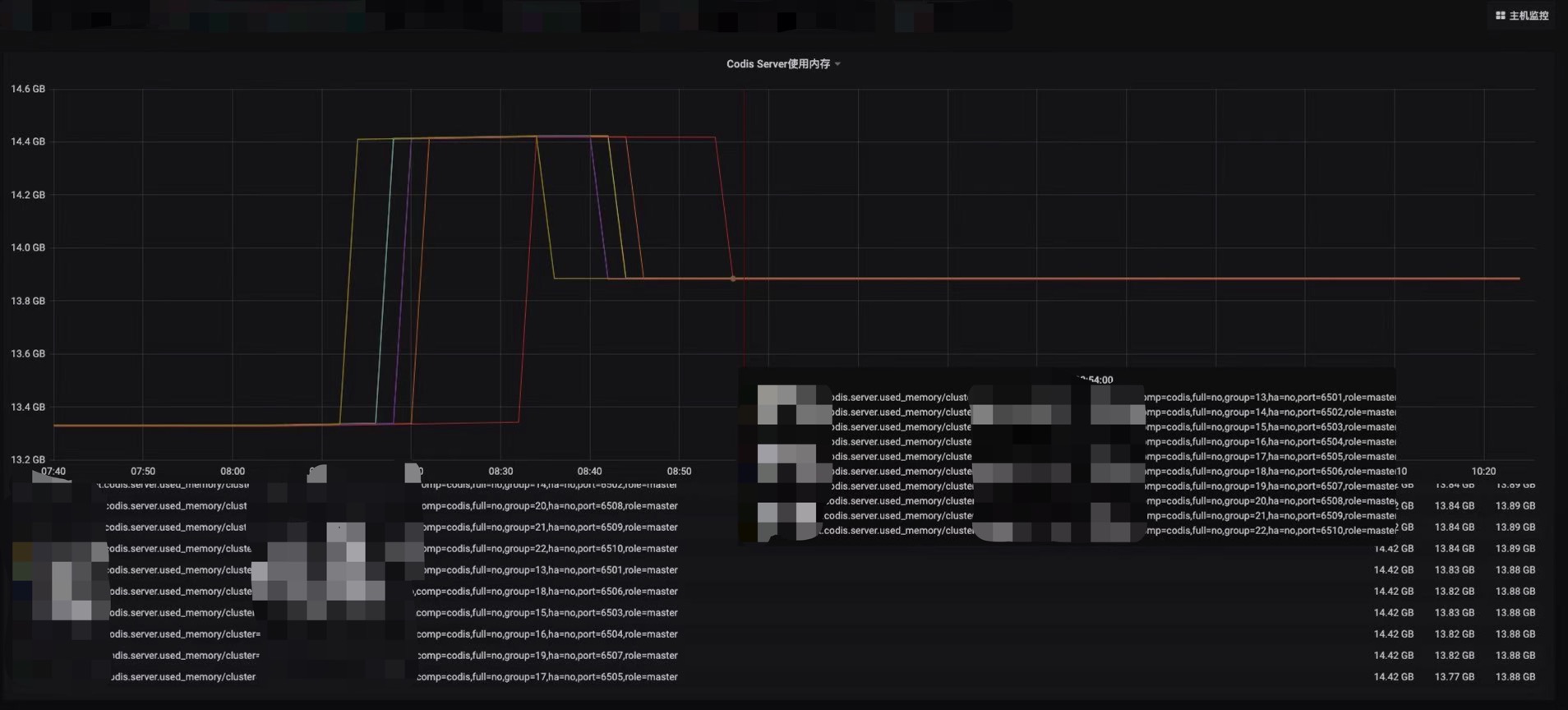
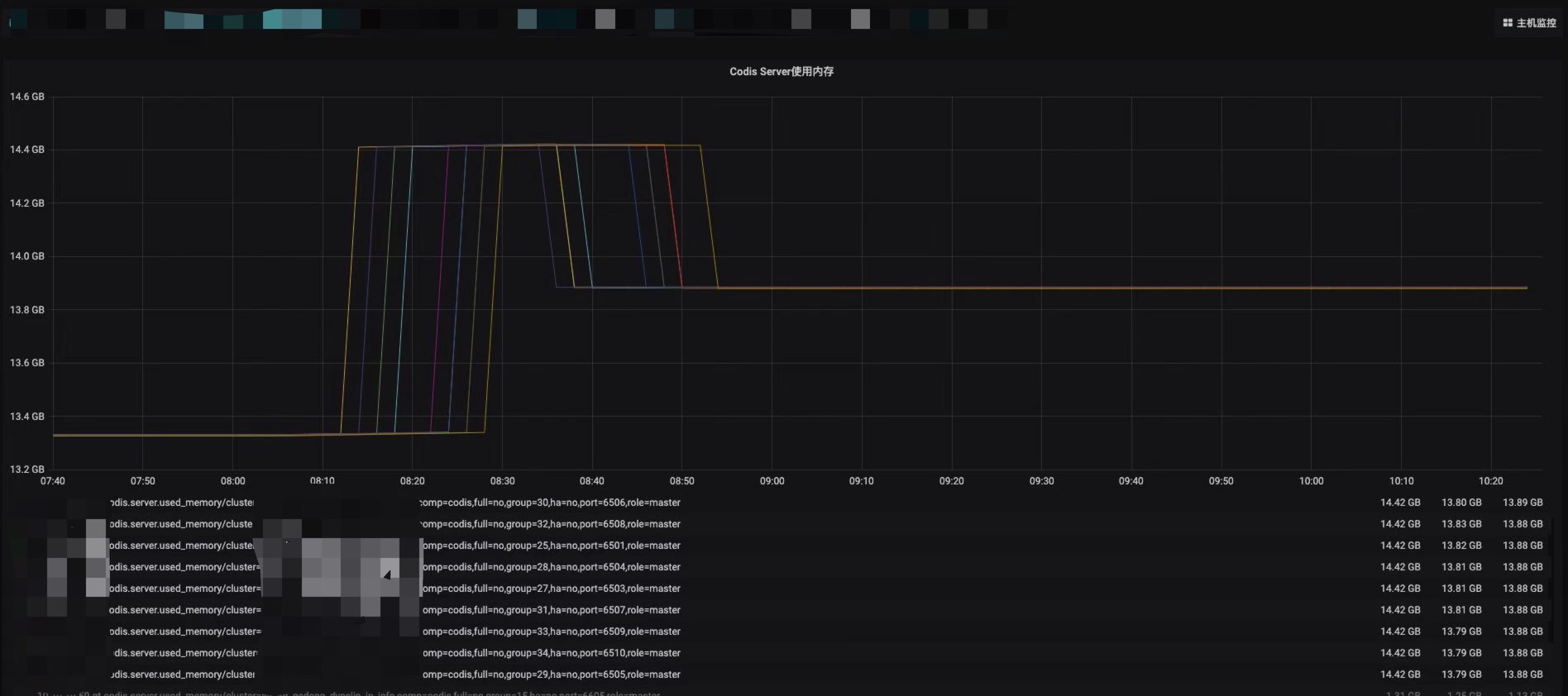
同时发现增长1G内存的节点内存碎片率发生了抖动,内存增长不明显的4个节点未抖动。
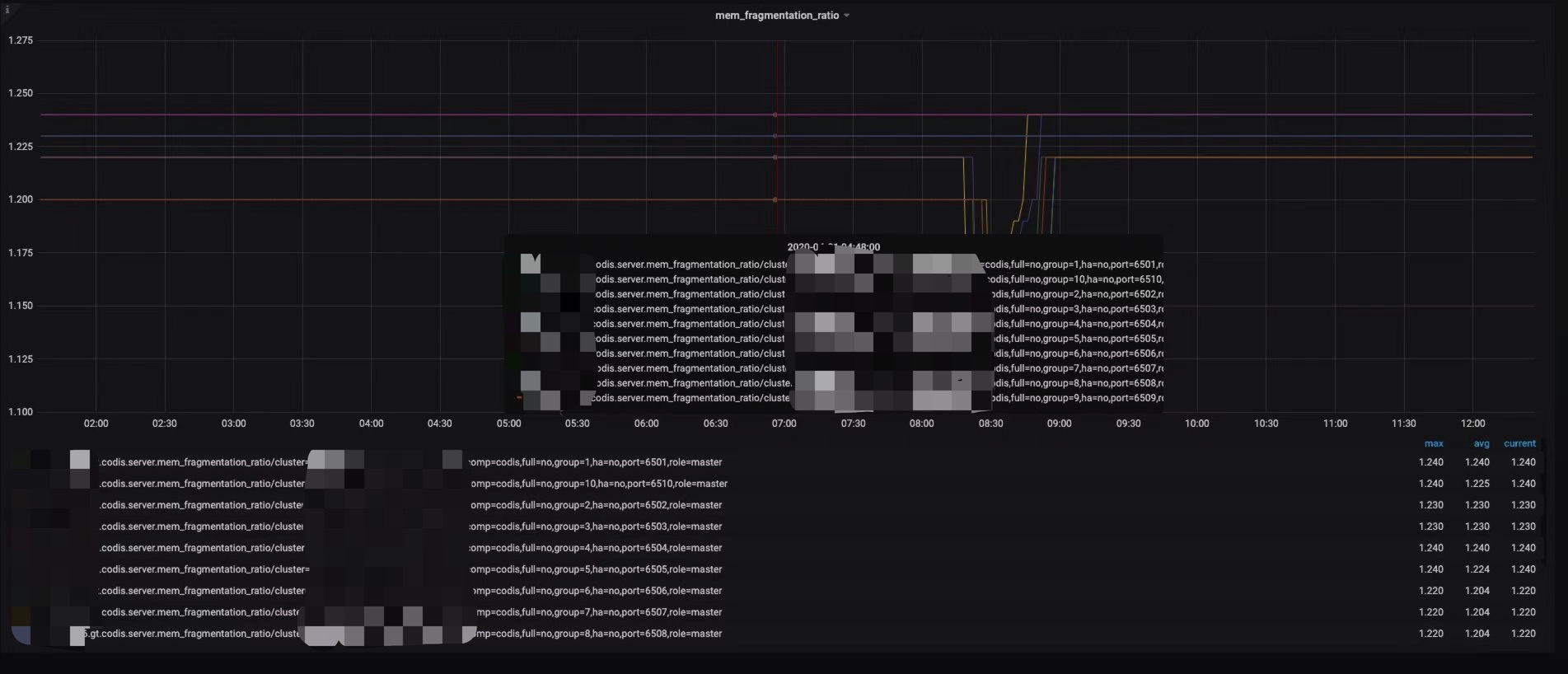
在查看codis-dashboard之后,发现未增长的节点分片为18,其他增长的节点为17。查找相关资料后发现是由于17个分片的节点key数量触发了Redis内部的内存rehash机制,导致内存分配了1G。

Rehash介绍
在Redis中,键值对(Key-Value Pair)存储方式是由字典(Dict)保存的,而字典底层是通过哈希表来实现的。通过哈希表中的节点保存字典中的键值对。当HashMap中由于Hash冲突(负载因子)超过某个阈值时,出于链表性能的考虑,会进行Resize的操作。Redis也一样。Redis使用了一种叫做渐进式哈希(rehashing)的机制来提高字典的缩放效率,避免 rehash 对服务器性能造成影响,渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
Rehash的具体机制可参考美团文章:https://tech.meituan.com/2018/07/27/redis-rehash-practice-optimization.html
rehash 结构定义
(1)Redis 哈希表结构体:
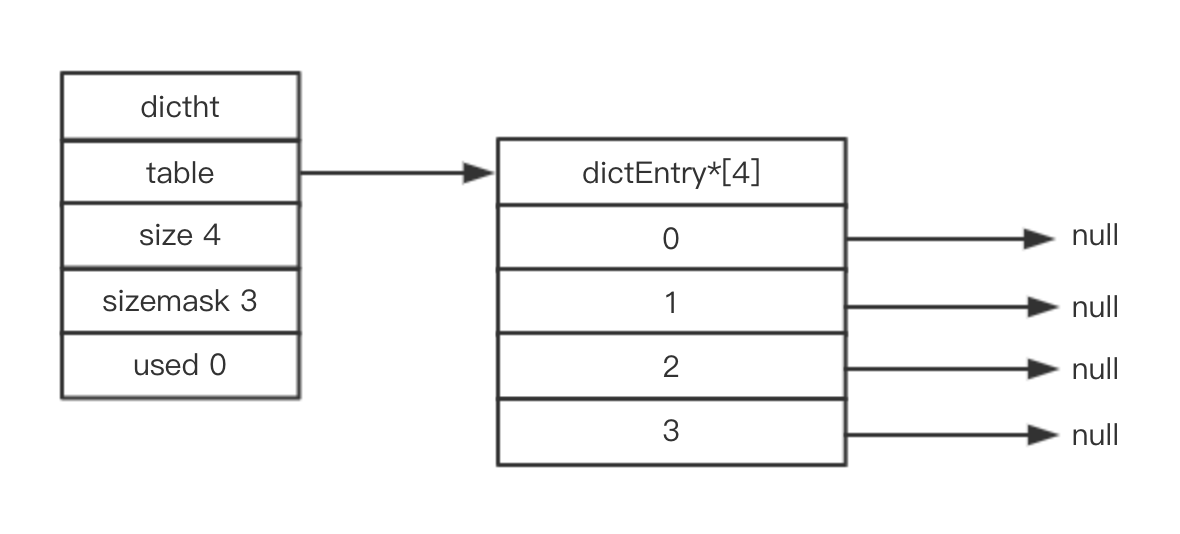
(2)哈希桶
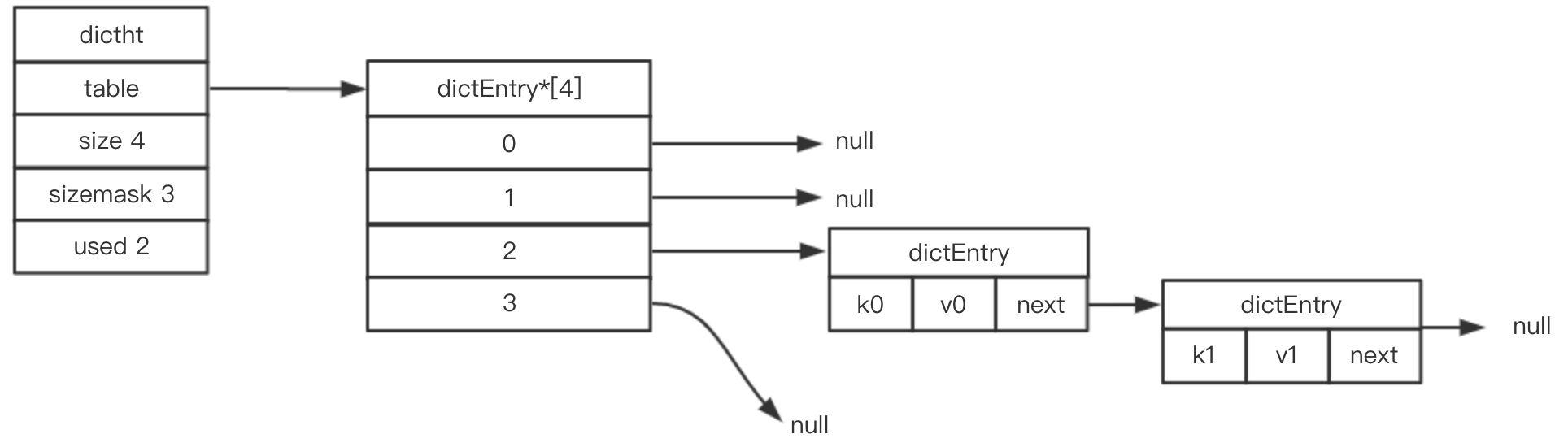
(3)定义字典
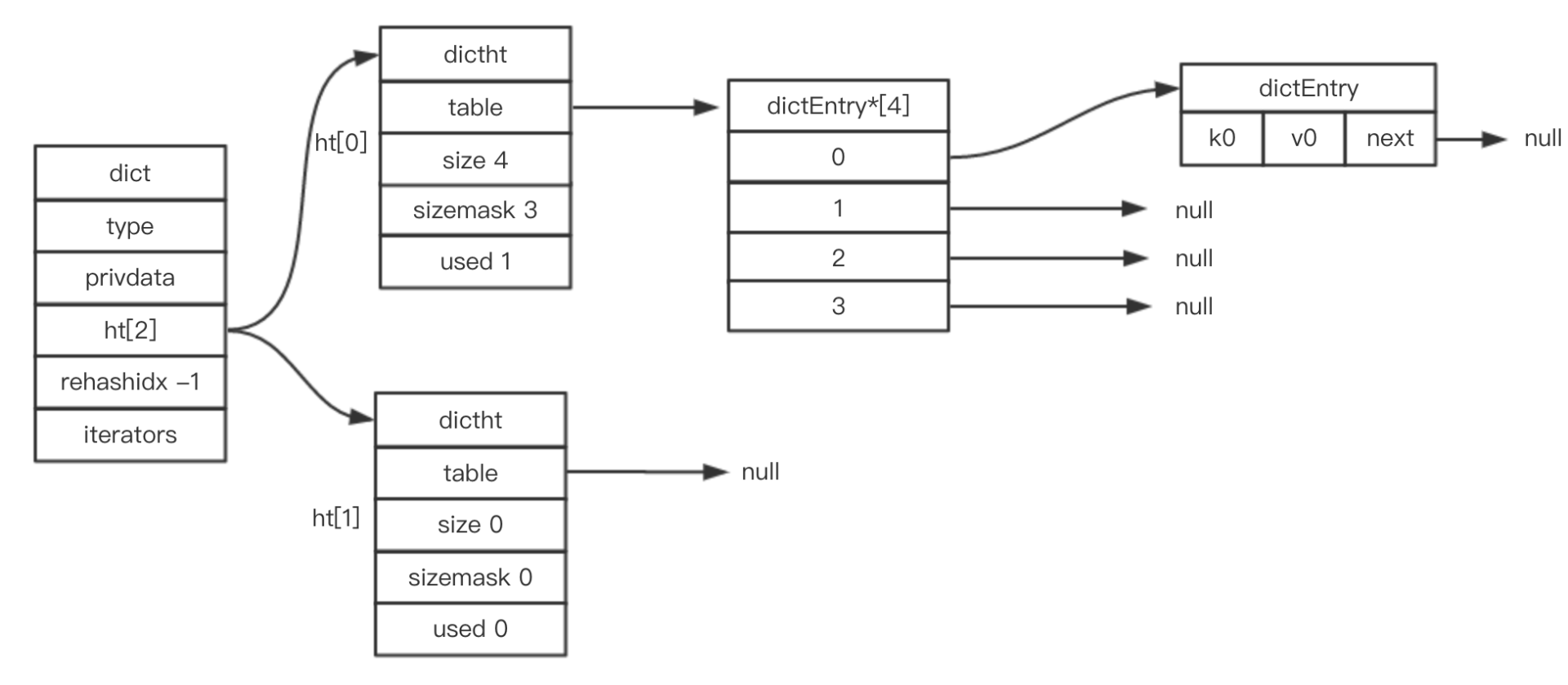
总结起来就是:
- 一个RedisDB对应一个Dict;
- 一个Dict对应2个Dictht,正常情况只用到ht[0];ht[1] 在Rehash时使用。
Rehash 逻辑
/* 根据相关触发条件扩展字典 */
static int _dictExpandIfNeeded(dict *d)
{
if (dictIsRehashing(d)) return DICT_OK; // 如果正在进行Rehash,则直接返回
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); // 如果ht[0]字典为空,则创建并初始化ht[0]
/* (ht[0].used/ht[0].size)>=1前提下,
当满足dict_can_resize=1或ht[0].used/t[0].size>5时,便对字典进行扩展 */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); // 扩展字典为原来的2倍
}
return DICT_OK;
}
...
/* 计算存储Key的bucket的位置 */
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
/* 检查是否需要扩展哈希表,不足则扩展 */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
/* 计算Key的哈希值 */
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask; //计算Key的bucket位置
/* 检查节点上是否存在新增的Key */
he = d->ht[table].table[idx];
/* 在节点链表检查 */
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return -1;
he = he->next;
}
if (!dictIsRehashing(d)) break; // 扫完ht[0]后,如果哈希表不在rehashing,则无需再扫ht[1]
}
return idx;
}
...
/* 将Key插入哈希表 */
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // 如果哈希表在rehashing,则执行单步rehash
/* 调用_dictKeyIndex() 检查键是否存在,如果存在则返回NULL */
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry)); // 为新增的节点分配内存
entry->next = ht->table[index]; // 将节点插入链表表头
ht->table[index] = entry; // 更新节点和桶信息
ht->used++; // 更新ht
/* 设置新节点的键 */
dictSetKey(d, entry, key);
return entry;
}
...
/* 添加新键值对 */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key); // 添加新键
if (!entry) return DICT_ERR; // 如果键存在,则返回失败
dictSetVal(d, entry, val); // 键不存在,则设置节点值
return DICT_OK;
}
继续dictExpand的源码实现:
int dictExpand(dict *d, unsigned long size)
{
dictht n; // 新哈希表
unsigned long realsize = _dictNextPower(size); // 计算扩展或缩放新哈希表的大小(调用下面函数_dictNextPower())
/* 如果正在rehash或者新哈希表的大小小于现已使用,则返回error */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* 如果计算出哈希表size与现哈希表大小一样,也返回error */
if (realsize == d->ht[0].size) return DICT_ERR;
/* 初始化新哈希表 */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*)); // 为table指向dictEntry 分配内存
n.used = 0;
/* 如果ht[0] 为空,则初始化ht[0]为当前键值对的哈希表 */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* 如果ht[0]不为空,则初始化ht[1]为当前键值对的哈希表,并开启渐进式rehash模式 */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
...
static unsigned long _dictNextPower(unsigned long size) {
unsigned long i = DICT_HT_INITIAL_SIZE; // 哈希表的初始值:4
if (size >= LONG_MAX) return LONG_MAX;
/* 计算新哈希表的大小:第一个大于等于size的2的N 次方的数值 */
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
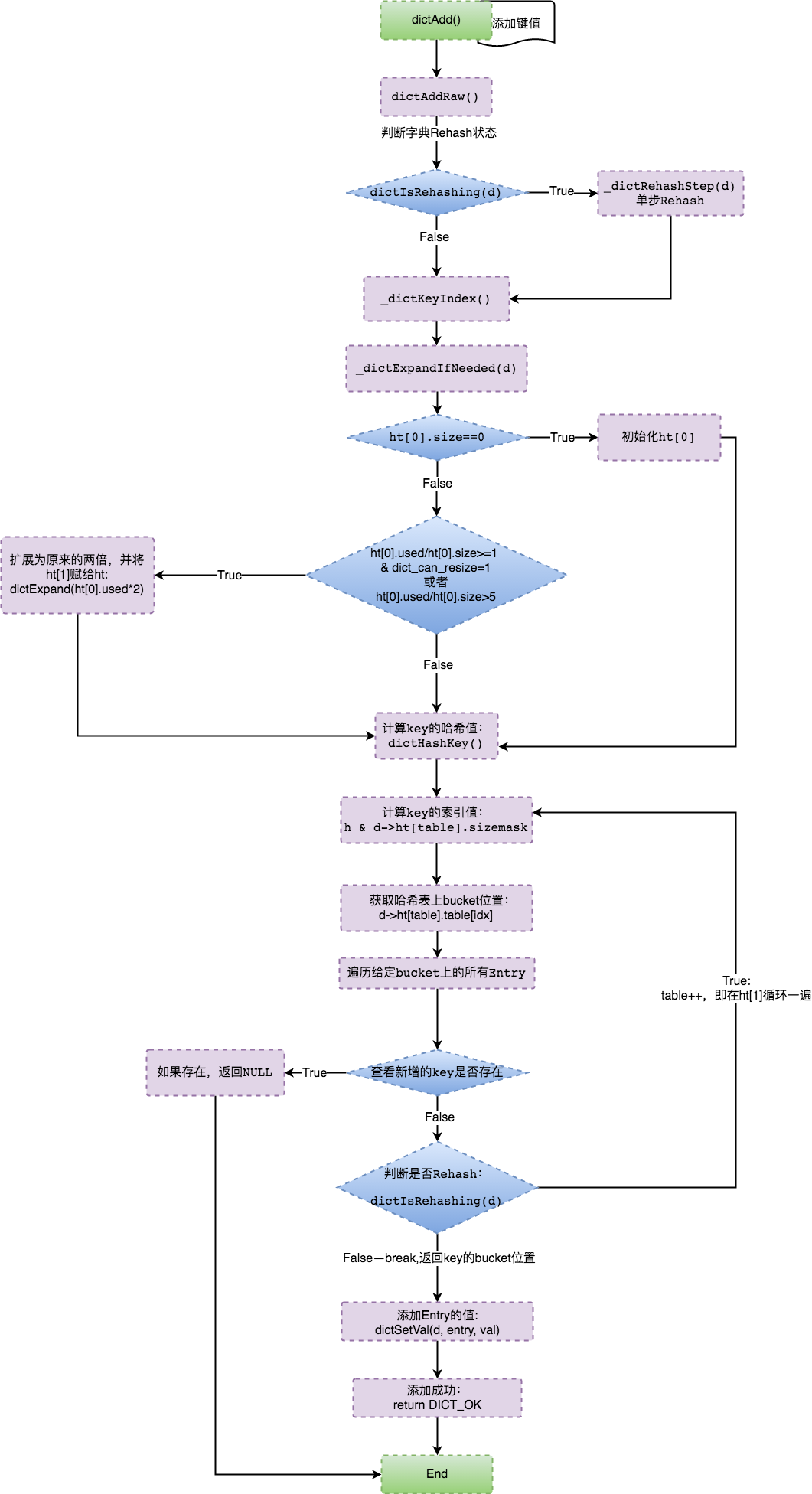
可以确认当Redis Hash冲突到达某个条件时就会触发dictExpand()函数来扩展HashTable。
DICT_HT_INITIAL_SIZE初始化值为4,通过上述表达式,取当4*2^n >= ht[0].used*2的值作为字典扩展的size大小。即为:ht[1].size 的值等于第一个大于等于ht[0].used*2的2^n的数值。
Redis通过dictCreate()创建词典,在初始化中,table指针为Null,所以两个哈希表ht[0].table和ht[1].table都未真正分配内存空间。只有在dictExpand()字典扩展时才给table分配指向dictEntry的内存。
由上可知,当Redis触发Resize后,就会动态分配一块内存,最终由ht[1].table指向,动态分配的内存大小为:realsize*sizeof(dictEntry*),table指向dictEntry*的一个指针,大小为8bytes(64位OS),即ht[1].table需分配的内存大小为:8*2*2^n (n大于等于2)。
| ht[0].size | 触发Resize时,ht[1]需分配的内存 |
|---|---|
| 4 | 64bytes |
| 8 | 128bytes |
| 16 | 256bytes |
| … | … |
| 65536 | 1024K |
| … | … |
| 8388608 | 128M |
| 16777216 | 256M |
| 33554432 | 512M |
| 67108864 | 1024M |
| … | … |
现在回过头来看内存上涨1G的时候,节点的key的数量刚好触发了67108864这个值,触发了rehash机制。系统需要分配1G内存的ht[1]表。
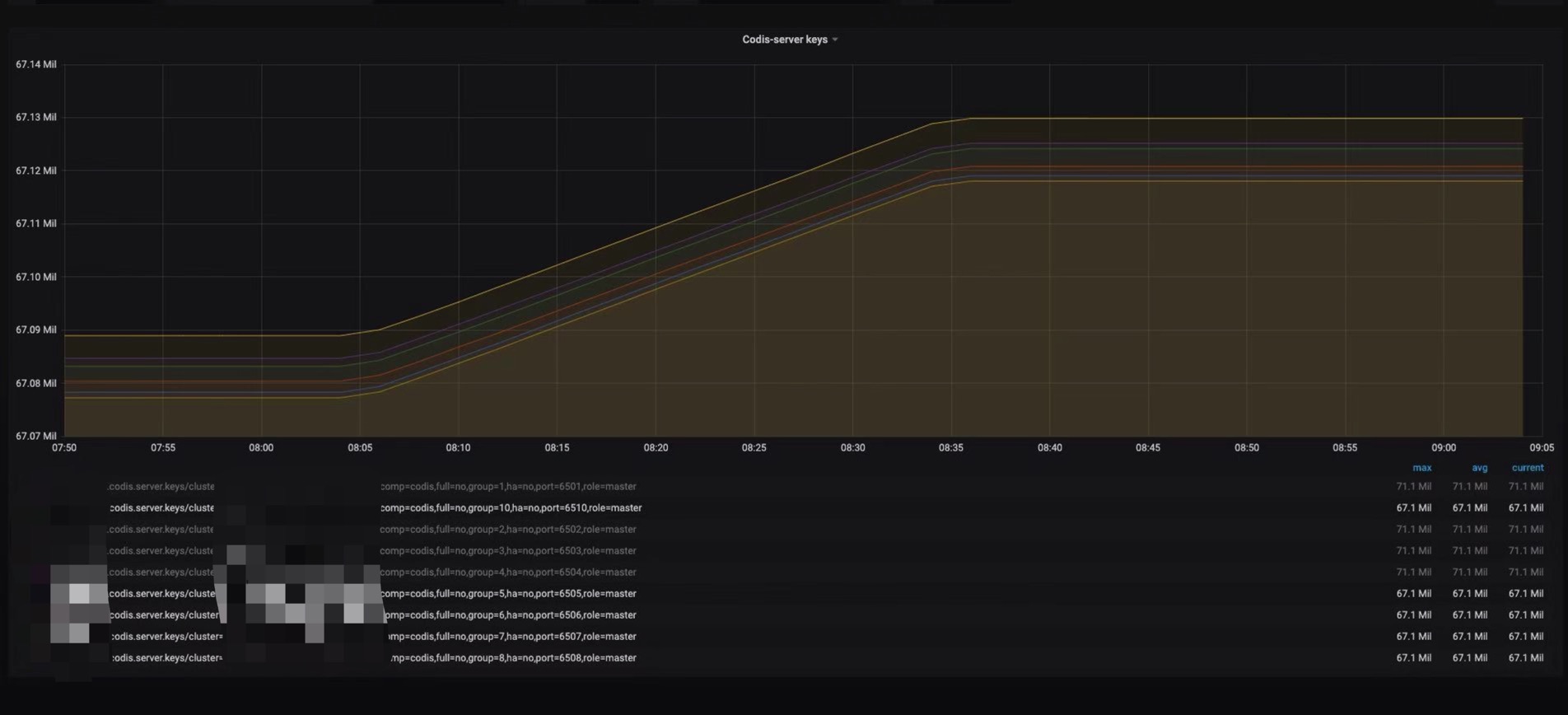
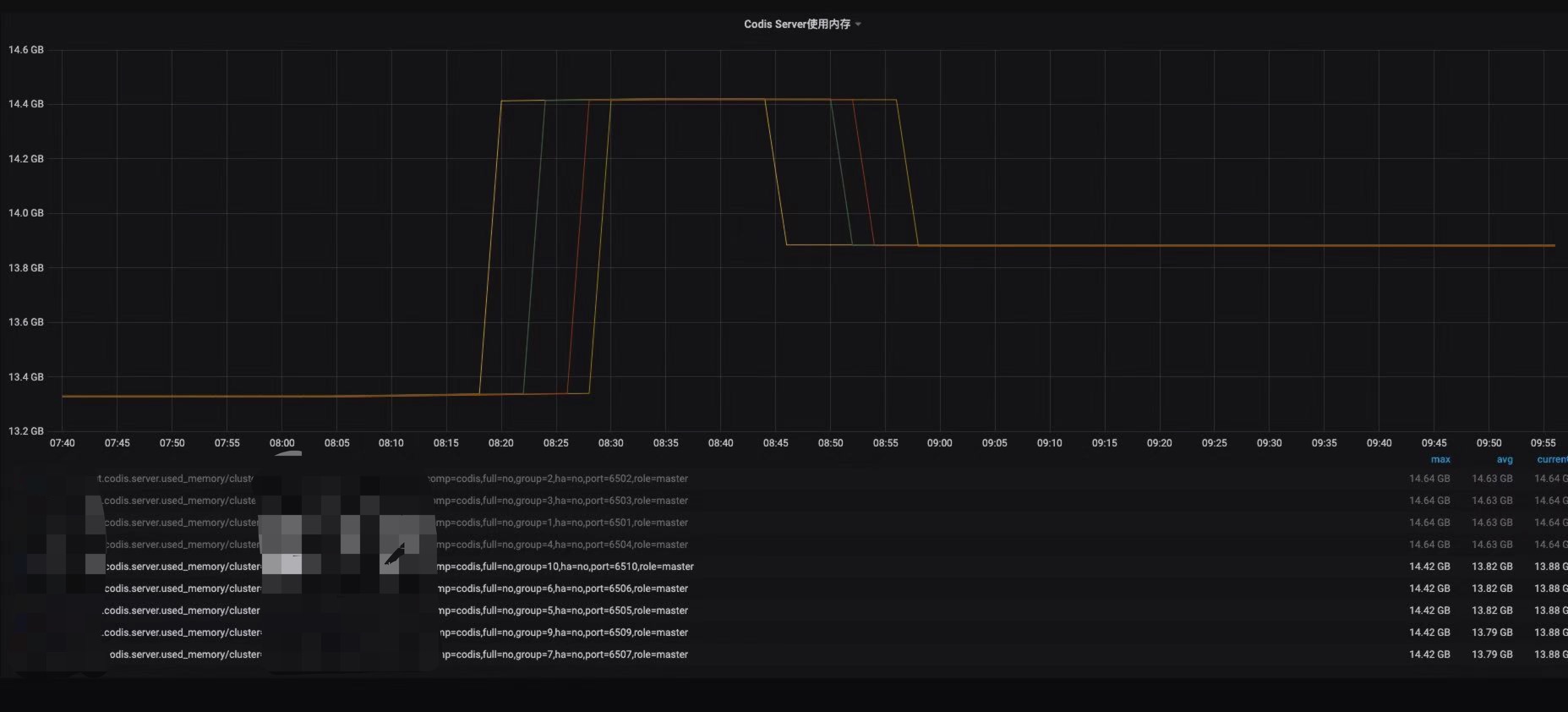
根据我们推到的rehash机制,来回顾前面4个内存未变化的节点发现,1月4号早上8点40左右,上述4个节点到达了67108864线,触发了rehash机制,系统分配给ht[1]表1G内存
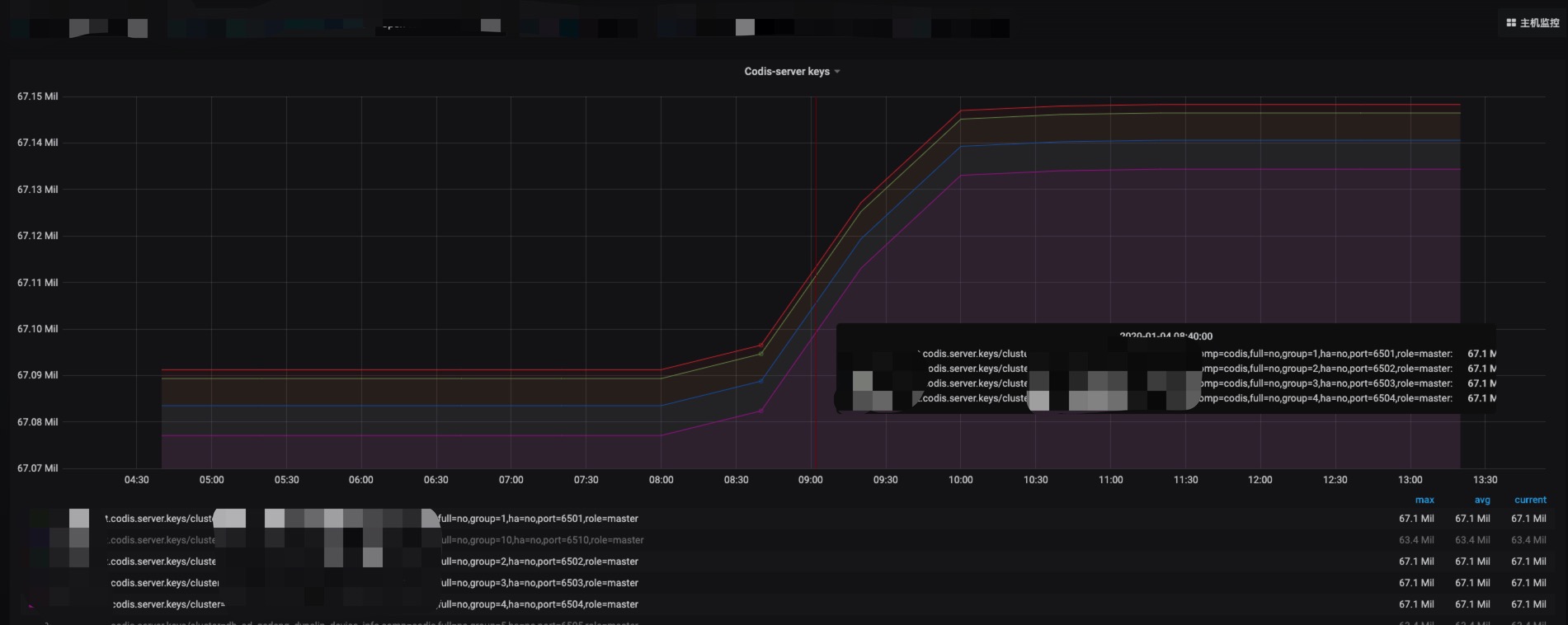
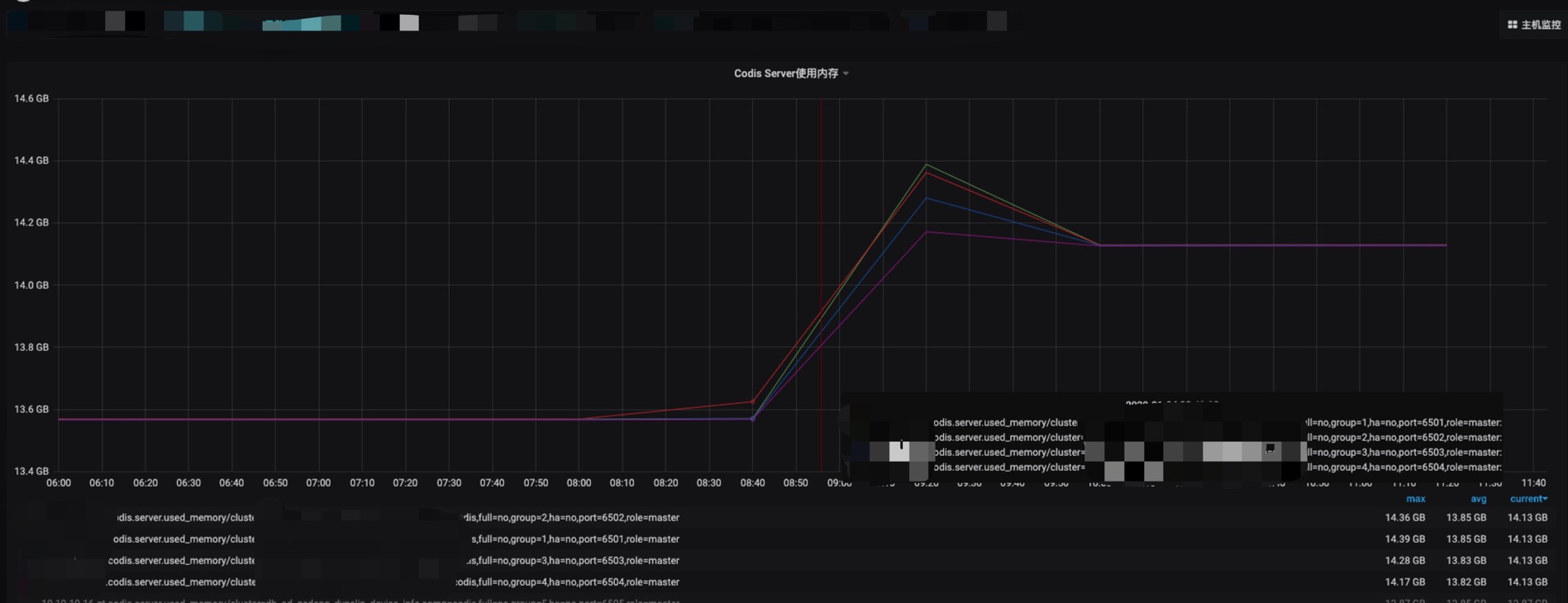
redis-benchmark测试
在测试环境生成67108865个key,当key的数量从67108864加1变成67108865时,使用内存立刻增加1G
redis-cli -r 1000 -i 1 -p 6035 info | egrep "used_memory_human|used_memory:|db0:keys|mem_fragmentation_ratio

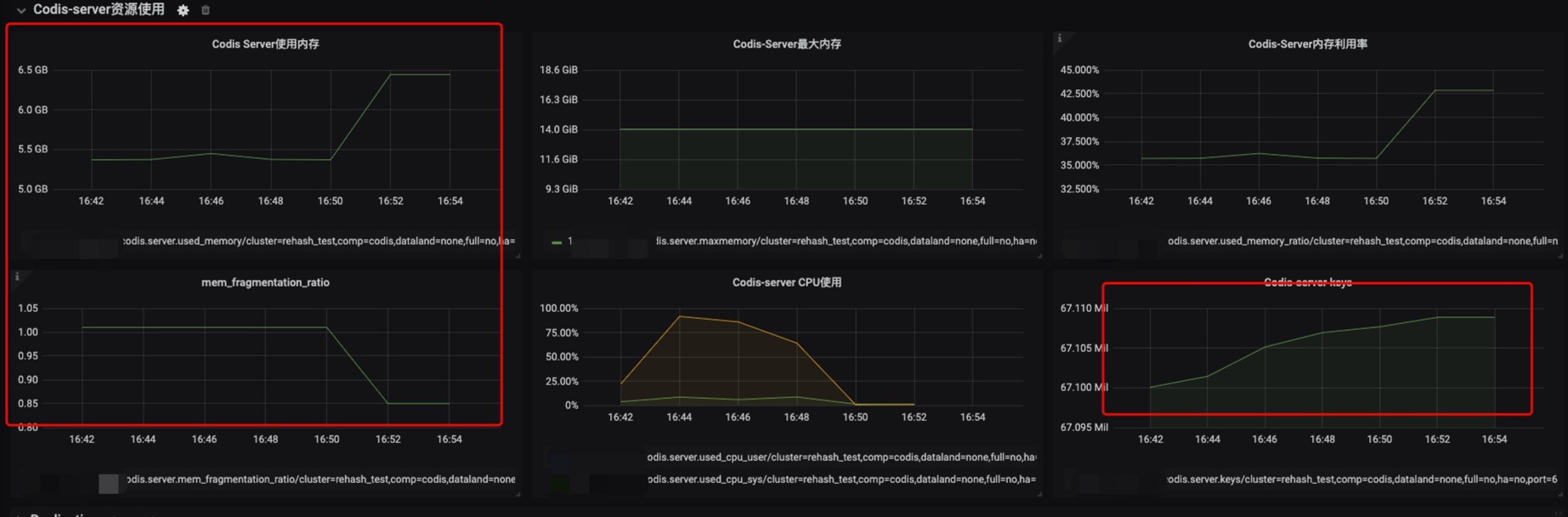
总结
当Redis 节点中的Key总量到达临界点后,Redis就会触发Dict的扩展,进行Rehash,申请扩展后相应的内存空间大小。
风险点:keys过多触发rehash需要分配的内存较多,分片均匀的集群尤为突出,且容易达到内存上限造成大量驱逐过期key,导致Redis服务无法响应请求。
解决方法:根据rehash的触发机制,做好当前可用内存和rehash需要申请内存的监控,在触发rehash前进行干预,避免rehash申请内存后造成内存超用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号