关于 JavaSrcipt 前端开发的建议:模块化开发
JavaScript 是一种优秀的脚本语言。
在 JavaScript 的诞生之初,便于 浏览器 密不可分,如今它更是到了服务器中大展身手。
但是这里不叙述服务端的开发建议。
Script 翻译过来就是 脚本,而前面所加入 Java 则是指现如今仍然流行的开发语言:Java。
在 Java 日常开发中,常使用 MVC 的模式进行开发,那么使用 JavaScript,不借助任何前端框架,我们可以使用这个模式编写出执行高效的前端页面脚本代码吗?
答案是 OK 的,如何做到?
了解 MVC 的一些常识:
MVC的全称是: Model(模型)、View(视图)、Controller(控制器)
它们各司其职,也为协同办公提供了底层上的支持:比如有的开发者负责模型搭建,有的则是开发视图(也就是我们所说的前端)、以及后台业务处理的控制层。
这是最基础的分工模式,还延伸了 Dao 层,也就是单纯与数据库打交道的。
各类原理图片网上亦有很多,这里就不多说了。
延伸:如何 JavaScipt 可以像 Java 开发后台那样游刃有余的开发前端?
前端脚本所需要实现的主要功能大致如下:
- 处理与服务器交互的数据的
- 处理与用户交互的数据的
- 处理界面点击响应的
- 处理缓存的
- 处理页面效果的
它们之间的依赖我大致整理了一下:
界面点击响应 -> 页面效果 -> 用户交互 -> 服务器交互
页面效果 -> 缓存 -> 服务器交互
简单梳理之后就可以发觉原来前端也可以高效开发!比方说,页面效果指的是用户所看到的,属于视觉层
而有些内容则是动态生成的,这就意味着需要与服务器进行交互拿到数据。
但是服务器如果同时在线的人数过多,那么每初始化一次就需要拿取数据,显然可能会不堪重负,所以加入了缓存
界面初始化后,用户会进行操作(界面点击响应),点击后的视觉会发生变化(页面效果)以让用户知道他已经成功操作,需要等待。
之后将用户交互产生的数据进入服务器交互区,上传给服务器处理。
就这样,一个前端的基本功能互相依赖,就变成了我们日常所看到的网站。
如何细分为脚本区域?让分段开发更有效?
我所建议的是,前期先分为多个文件进行开发,注意文件之间的顺序引入:因为HTML的解析是由上而下,上方的脚本是无法访问下方脚本的API的,除非有全局变量
<script type="text/javascript" src="/xx.js"></script> <script type="text/javascript" src="./xxx.js"></script>
若果是按上述代码所写,基本上 xx.js 的代码初始化中带有 xxx.js 的API,则会报 define 错误。
谁让 xxx.js 还没加载呢,所以起初分为多个文件开发,一定要注意顺序问题,或者都不进行初始化,等到最后一个文件加载时才进行初始化便不会报错。
好了,问题稍微注意下就好,这是针对刚进行开发的开发者提供的注意事项。
分为多个文件:
- 异常处理.js
- 缓存读写.js
- 数据库交互.js
- 数据服务.js
- 实体类.js(参考Java的编程模式)
- 界面效果.js
- 界面事件处理.js
大致分为七个文件,顺序亦按照上述所布置。
异常处理是处理如同断网、或者被某个扩展脚本阻拦产生的错误等处理,以便让用户明确地知道当前操作失败。通常有效的方式是发出一个弹窗(视情况发出不同类型的模态窗体)。
其它不再叙述。
后续编写完成后,可以容纳成单个文件,可以更好的节省HTTP连接数。
数据库交互文件无非是使用 Ajax 的方式进行提交,收取数据,关于 Ajax 的资料网络上非常多,JQuery 框架也集成了功能。
这里指的注意的是,要划分好后台提供的API,比方说:
后台提供了初始化页面的 JSON 数据,并且是一天才更新一次,而且参数是根据登录 Cookie 决定的,那么可以根据这样进行开发:
class Database extends Cache{ constructor() {
super(); // 只初始化一次,且当天数据保持不变 this.INIT_PAGE_DATA = null;
} initPage( cookie ){ // 查询是否有缓存的 Cookie 当前页面数据 -> 继承了缓存 API,可直接使用 this 关键字 this.queryCookie( init_page_data ); // 没有缓存 -> 进行 Ajax 操作拿到 数据:data this.INIT_PAGE_DATA = data; // 进行缓存到 Cookie 的操作 -> time : 时间,这里配置为 一天 this.cacheCookie( data, time ); } }
如此一来,就算是后台开发人员,只需要稍微了解 JavaScript 的常识,就可以开发自己擅长领域的脚本!
数据库编写者可以根据字段,写出严谨的前端实体类(好吧其实Java后台的实体类通常也是根据数据库字段而开发编写的)
在担心 class 关键字没有太多浏览器支持吗?其实那已经成为过去式了。
使用 function 关键字虽好,但是 class 操作价更高呀
至于原型链等深层的原理,这里不再概述,以后有时间再出相关的随笔吧。
那么实体类该怎样写才能做更多的事情,不至于产生贫血模型呢?
答案是让它们各司其职,数据写入前进行检查,顺道操作一下相关的API,这样界面事件处理的开发人员就不用写太多行来实现某个业务了。
比方我只需要一个实体类,载入所有数据后,将其提交给后台,保存在数据库里:
class entity_user{ constructor() { // 用户的名称 this.name = null; // 用户的年龄 this.age = null; // 不写太多了 } getName(){ return this.name; } setName( name ){
// 如果传入产生为空,那么其实是真的想设置为空 if (null == name ) { this.name = null; return; }
// 查查类型是不是 String,不是便抛出异常 if (typeof name !== "string") {
// 长度是否大于 1,也就是传入的是不是空字符串,是的话再抛出异常 if (name.length >= 1) { this.name = name ; return; } throw new Error("the parameter is incorrect"); } throw new Error("parameter not a string"); }
// someting code... }
这样一来,我们仅需要实例化这个实体类,插入用户交互产生的数据,然后将数据直接导入:
// 某业务方法内 Start try{ let user = new entity_user(); // 假设用户借助了某种工具就是要给你空字符串 user.setName(""); // 使用数据服务API将其提交给数据库交互处理 } catch(e){ // 其实可以自定义异常 } // 某业务方法内 End
不必担心会将空字符串传给服务器,因为在这里我们已经拦截了。
而自定义异常可以使我们像 Java 那样一层层的进行捕获,意味着可以更精准的处理某个异常。
异常处理中,则可以调用最顶层的 异常处理API ,根据不同级别,给用户传达不同级别的错误信息。
哦,对了,数据服务API 是区别于 数据库交互 的,它们的关系为:
数据服务 继承 数据交互 继承 缓存
也就是说,其实业务层(界面事件处理)根本不去想数据要经过怎样的流程,要怎样进行 Ajax 交互。
只需要简单的一行代码,塞入对应的实体类,就可以将实体类的数据提交给后台服务器。
这样一来,不觉得开发效率提高了很多很多吗?重要的是,它可以多人协作,各自编写各自的代码。
我总是说各司其职,也只有这样,才能让人更专注于某一件事。
其实这样分段编写,也便于扩展程序的新功能,而不是说:我们需要新增某个页面上的功能。就大费周章的重构原先的代码。。
关于异常处理API
所有的代码一定会发生无法处理的错误,因此异常处理是一个健壮程序所必备的编写环节。
但是遗憾的是,JavaScript 似乎对自定义异常并没有太大的支持
不过通过不断迭代,今天的 JavaScript 也已经可以胜任更加复杂的操作任务。
而自定义异常,我亦想出了一个办法,如下:
class Exception extends Error{ constructor( message ){ super(); this.name = "Exception"; this.message = message || ""; } } /* 空指针异常 */ class NullException extends Error{ constructor( message ){ super(); this.name = "NullException"; this.message = message || ""; } }
这是一个简单的自定义异常编写方式,参考了 Java 的异常类设计。
我们可以看到,Exception 继承了 Error 类,因为 JavaScript 的机制,我们只能让“子异常”也都继承 Error 类。
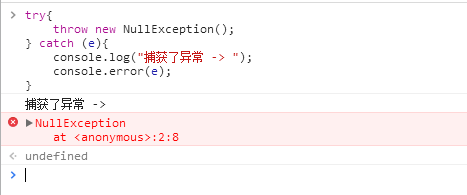
如此一来,自定义异常就算完成了。在程序中如果检测到某种错误,可以使用下方的方式进行抛出:
throw new NullException();
在实际中的效果是这样的:
你可以将抛出异常的代码写在任何函数里,之后遇到无法处理的错误,便可以抛出了。
而调用的一方则需要对抛出异常的函数进行捕获,并且进行精确处理。
比如 NullException(空指针异常)、NetWorkException(网络错误)等
看到这里,你可能会有一个疑问:怎么样才能精确处理?代码如下:
try{ throw new NullException(); } catch (e){ if ( e instanceof NullException ) { console.log("发生了空指针异常"); } }
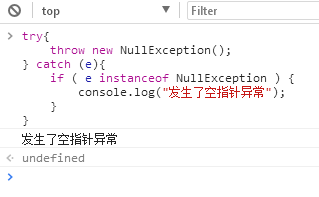
让我们再看看如果有多种异常时,代码能否按所想的如期执行

利用 instanceof 关键字,确实实现了精确捕获异常的操作。
虽然可能不是最优解,后期如果有更好的方式,我会进行更新并重新写一篇随笔,敬请关注吧
哦,对了,附上一张事件处理层上的几行代码拿到后台数据的截图吧:

这个是在控制台上直接进行编写的,实际上可能稍微复杂,但也差不到那里去,大概下方这样:

DBAPI 使用了自定义异常,这些异常包括了参数异常,网络异常,空指针异常,未知异常等多种常用异常,如果因为网络问题,那么 DBAPI 将会抛出以下异常:
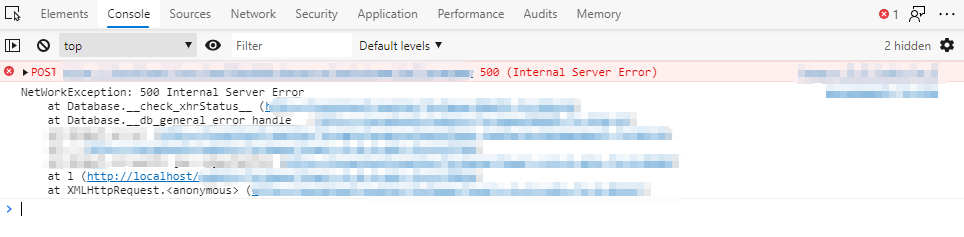
这样可以清晰的看见触发的是网络异常:NetWorkException。
500 状态码标示是服务器错误,这个错误原因是后台的数据交互部分未捕获数据库交互产生的未知异常而导致。
从图片上可以看见,事件处理层所做的事情大大减少到了五行代码。
而 DBService 是我所写的回调处理的帮助类,可以认为这个帮助类属于视觉层,因为其中的回调函数大都是需要直接渲染 DOM 树的操作
比方:success 是当 DBAPI 拿到数据成功时所回调的一个函数,因此 success 的回调函数必然需要处理相关的数据渲染进 document 中
所以 DBService 属于视觉层的帮助类,我想也无可厚非。
大概就写到这里了。
注:DBAPI 后续可能开源至 前端工具库
2020/2/6 下午 写于揭阳
转载请附上本文博客地址!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号