NLP知识梳理
NLP知识梳理(上)
一、文本分类
文本分类顾名思义就是将一个文本归纳到一个特定的标签下,如好评差评分类,诗词情感分类等等。
输入一个文本,一个分类集,经过文本分类,得到预测的结果。如输入“The movie is good!” 和分类集{Positive, Negative, Neutual}经过文本分类,最终得出预测结果:Positive!
基于规则的方法
基于规则即找规律,通常如果文本中出现“好”,“厉害”等褒义词,我们就可以将它归为积极一类。
#判断褒贬
if there exists word w in document d such that w in [good, great, extra-ordinary, …],
then output Positive
# 判断是否邮件地址
if email address ends in [ithelpdesk.com, makemoney.com, spinthewheel.com, …]
then output SPAM
这样就没问题了吗?可以看出如果想要做到正确率高,就必须找到许多规则,有些规则甚至不为人类所知!这样的成本是巨大的。不易推广,很容易预测错误。
监督学习的方法
需要输入分类集,以及训练集(文本+标签)最终训练出分类器F
文本分类的基本流程
1、文本预处理
去噪、分句、分词、去停用词、取词干这些就是调$re, jieba,stopword$库函数,不是本节重点。
2、文本表示
将自然语言文本转换为能被计算机或算法识别的一种模式。
向量空间模型 VSM
将文本表示为多维词空间中的向量。通常词义相近的距离也近。
词袋模型(Bag of Words)
词袋模型能够把一个句子转化为向量表示,不考虑句子中的词序,只考虑词表中单词在这个句子中的出现次数。
"John likes to watch movies, Mary likes movies too"
"John also likes to watch football games"
通过上面的两句话,可以得到下列词表
[‘also’, ‘football’, ‘games’, ‘john’, ‘likes’, ‘mary’, ‘movies’, ‘to’, ‘too’, ‘watch’]
因此上面两句话的向量为:
[0,0,0,1,2,1,2,1,1,1]
[1,1,1,1,1,0,0,1,0,1]
以第一句为例,also,football,games在第一句均未出现,前三个值为0,likes和movies出现两次,值为2。其他词出现了一次,值为1。
3、特征选择
根据某个评价指标,对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项。常用的评价有文档频率、信息增益、χ2统计量等。在作业中选择的是词频前5%的词语。
在本例中选取了100个特征词,我们可以列出词袋。其中特征维度等于特征词数
最大似然估计和情感分类
使用这种方法需要假设每个单词(特征)独立于另一 个单词(特征),这种方法准确度虽然逊色于其他模型,但是速度快,是其他模型的基础。
假设d是文档,c为情感标签,$P(d|c)$表示一个条件概率,即该文档在情感标签为c的情况下概率多大。如何进一步表示$P(d|c)$呢 ?e.g. P("It's really really the worst movie ever”| "Positive")
最简单的就是把d拆成一个个单词但是这样不方便计算,我们前面说过单词两两独立,因此可以拆开
假设我们已经得到了以下概率值:
那么我们要判断如d=“really really the worst movie ever”这句话是positive 还是negative只需计算P(d|positive)和P(d|negative)即可,概率高的就是那个类别,在本例中明显属于negative范围。
贝叶斯分类器
我们回归分类的本质,可以看出我们实际要求的是给定文本X,求它的类别Y;假设$Y={y_1,y_2,...,y_n}$,
上式中的y就是就是最终的分类类别。
我们在之前已求得似然估计$P(X|Y)$,也很容易得出P(Y)的值,使用概率论中所学的贝叶斯公式,可求出$P(Y|X)$
通过公式,我们可看出无论y如何变化,分母的值均不变,因此只需比较Y=y的先验概率与X=x,Y=y的似然估计的乘积即可。
朴素贝叶斯
朴素贝叶斯得到的是概率的估计,应用了上面讲的不同类别但分母相同,因此它只计算分子上的乘积。再通过假设单词间两两独立,可将贝叶斯更加简化
----------->
概率估算
我们主要来讨论先验概率的估算$P(Y)$和条件概率的估算$P(X|Y)$,他们是计算似然估计和贝叶斯的基础
先验概率:训练集中该分类的总数占所有文档总数的比例。
条件概率:在标签c下该单词$w_i$的总数与所有单词总数的商。
平滑
分析我们上面对条件概率的估算,如果一个词在训练集该类别中没有出现,那么它的条件概率为0,进而使得最大似然估计也为0,这明显是不合理的。因为少数单词的原因,导致零概率,分类的准确性大大下降。因此,我们引入数据平滑。
一个解决方法:给每个元素加一点概率量
--------->
通常$\alpha = 1$,V为词表的大小(不重复词的数量)
举个栗子:
首先计算先验概率和条件概率,可以看到计算条件概率时加入了平滑量
接下来使用朴素贝叶斯,分别计算测试集标签为c和j时的后验概率。
0.0003>0.0001 因此该句类别为c。
二、逻辑回归
把线性回归作为逻辑回归的输入,从而它 们组合在一起就有了逻辑回归
判别模型与生成模型
判别模型
“记忆者”,本身不认识这个模型,通过比对先验结果进行识别,适用小范围数据。如逻辑回归
判别式分类器
给两张猫和狗的图片,直接对比猫狗间的区别,对测试集做出分类
生成模型
“学习者”,先学习构想出模型的概念,再进行匹配判断标签。泛化能力强,需要大量数据保证准确性。如Naive Bayes
生成式分类器
给两张猫和狗的图片,首先获取猫狗的特征,建立猫狗的模型,对测试集分别在两个模型上进行运算,最后根据概率分类。
逻辑回归分类
将通过具体案例分析
特征向量
在BoW模型中,我们也说过特征选择,通过词频构建向量,但是这样会导致向量过于稀疏。因此可以通过自定义特征向量各维度的选择标准。
上图中特征向量共6个维度,通过褒贬词,标点,次数来决定数值。
代入计算
下面通过w向量,得到线性回归值z,再将z带入逻辑函数中即可完成最后的分类。
通过以上计算可得出,该段文字属于“+”。
损失函数
因为这个样例中测试集只有这一句话,所以n=1。$y_i$是真实值,即0或1,$\hat{y_i}$是由逻辑回归计算出的概率值。对于损失函数,最小值即为0,理想状况下计算概率与现实完全吻合。最大值为正无穷。$\hat{y_i}<1$,不可能算出负值。
三、词的语义向量表示
One-hot 编码
假设我们现在有单词数量为N的词表,那可以生成一个长度为N的向量来表示一个单词,在这个向量中该单词对应的位置数值为1,其余单词对应的位置数值全部为0。举例如下:
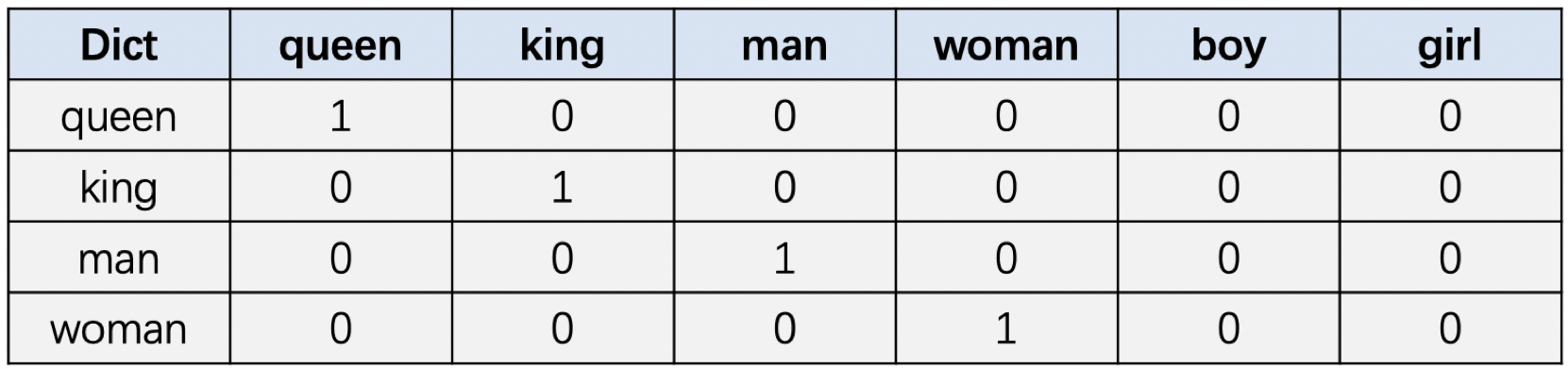
缺点:遇到单词较多时,维度高,向量太稀疏。维度(单词)间的关系,没有得到体现
词项-文档矩阵
看它的名字就知道,行列元素分别为单词和文档。具体一行代表一个单词在列表示的文档中出现的次数。
文档向量在图中是列向量,大小(维度)取决于词数;词向量是行向量,维度取决于文档数。如果两个词向量相似,那么词义相似。
TF-IDF
TF:词频,即一个词在文中出现的次数。
IDF:逆文档频率,与一个词的常见程度成反比,一个词在多少文档中出现。 出现的文档越少,值越大。
TF值可以很容易从矩阵中得到,如TF(dog, Hamlet) = 2/159
IDF由于是反比关系,它是包含t的文档数在文档总数中的倒数,再取对数。
$$
TFIDF(love, Hamlet) = TF(love, Hamlet) log (|D|/5)= 64/159*log(1.625)=0.08
$$
采用IDF的原因是削弱常用词的影响,保留重要的词语。是对词项-文档矩阵的一种重要加权方法。
词项-上下文矩阵
行列元素分别为单词和该单词的上下文单词,除此之外,还需要定义窗口大小,代表该词上下文的窗口。如window_size=1,代表选取前后各一个词
(information, data)= 6代表在文本中information上下文中data出现了6次。上面aprico 和pineapple向量相同,意思也确实相似,均为水果。
PMI
我们用PMI对词项上下文矩阵进行加权处理,计算方式如下:
比如我们算上表中的PMI(information, result),我们看到分母其实就是表中行列数据之和,$\sum\sum f_{ij}=2+1+1+6+1+1+1+1+1+4=19$
$p_{ij}$ 就是表中(information, result)值为4/19,$p_{i}=P(w=information)$即最后一行数据项之和11,pi=11/19,$p_{j}=P(c=result)$,即result一行数据项之和5,pj=5/19。代入最后的公式,即可算出PPMI值。
余弦相似度
得到词项-上下文矩阵后,还可通过计算余弦相似度判断词语的相似程度。使用余弦值,实际上是对参与点乘的v,w向量进行归一化处理
余弦值越靠近1,代表向量方向相似,因此上式中第二种情况最相似。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号