
损失函数
损失函数就是来衡量模型的输出与真实值之间的差距,我们试图减小这个差距以达到训练模型的目的。因此,当损失函数比较大时,希望梯度也比较大。
回归:定量分析,预测连续类数量的任务 分类:定性分析,预测离散类标签的任务
回归问题
mean_squared_error(均方误差)
均方误差损失(简称MSE)是根据预测值与实际值之间的平方差的平均值计算得出的。无论预测值和实际值的符号如何,结果始终为正,理想值为0.是最简单最常用的损失函数,可通过极大似然估计推导求得。
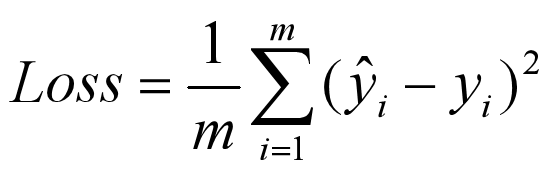
使用:用于回归问题的默认损失函数,如果目标变量的分布是正态分布,则是在最大似然推理框架下的首选损失函数。该损失函数是首先进行评估的函数,如果表现不好再更改。
mean_absolute_error(平均绝对误差)
计算为实际值和预测值之间的绝对差的平均值
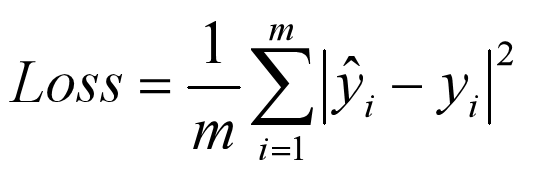
使用:在某些回归问题上,目标变量的分布可能大部分为正态分布,但也可能有离群值,例如,远离平均值的大或小值。在这种情况下,平均绝对误差或MAE损失是一种适当的损失函数,因为它对异常值更为稳健。
mean_squared_logarithmic_error(均方对数误差)
放松较大预测值中较大差异的惩罚效果的作用。作为一种损失度量,当模型直接预测未缩放的数量时,更加的适合。
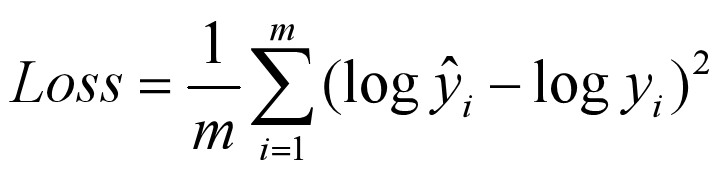
使用:在回归问题中,目标值可能有分散的值,并且在预测较大的值时,不希望像均方误差那样对模型进行比较大的惩罚
mean_absolute_percentage_error(绝对值百分比误差)
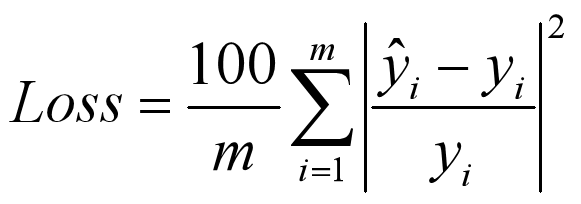
分类问题
sparse_categorical_crossentropy
一般最后一层搭配使用softmax激活函数。
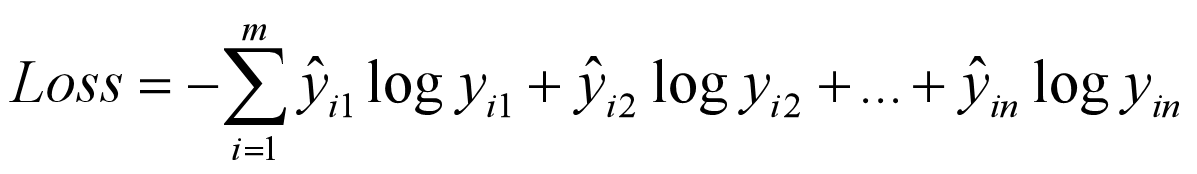
如果是one-hot编码则用Categorical_Crossentropy
数字编码则用sparse_categorical_crossentropy,一般最后一层均采用softmax的激活函数。
BinaryCrossentropy
一般最后一层使用 sigmoid 激活函数,一般用于二分类,这是针对概率之间的损失函数,只有 yi 和 ˆyi 相等时,loss才为0,否则 loss 是一个正数,且概率相差越大,loss就越大


 浙公网安备 33010602011771号
浙公网安备 33010602011771号