mysql基础
https://blog.csdn.net/weixin_51717597/article/details/124257608
https://zhuanlan.zhihu.com/p/403656116
https://www.nowcoder.com/discuss/353158449435451392
操作类型
- DDL: 数据定义语言,操作
数据库、表、字段等数据库层面的内容; - DML: 数据操作语言,用来对数据库表中的
数据进行增删改; - DQL: 数据查询语言,用来
查询数据库中表的记录; - DCL: 数据控制语言,用来创建
数据库用户、控制数据库的控制权限。
数据库各个层面的增删改查:
- 数据库的增删改查:
- 增:
CREATE DATABASE IF NOT EXISTS testdatabase [ DEFAULT CHARSET 字符集] [COLLATE 排序规则 ] - 删:
DROP DATABASE IF EXISTS users; - 改:MYSQL不支持直接修改数据库的名字。
- 查:SHOW DATABASES;
- 增:
- 表的增删改查
- 增:
CREATE TABLE IF NOT EXISTS users ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), age INT ); - 删:
DROP database users; - 改:
ALTER TABLE 表名 RENAME TO 新表名 - 查:
SHOW TABLES;
- 增:
- 字段的增删改查:
- 增:
ALTER TABLE emp ADD nickname varchar(20) COMMENT '昵称' - 删:
ALTER TABLE emp DROP nickname; - 改:
将表中的字段nickname修改为username ,类型如后面所示:ALTER TABLE emp CHANGE nickname username varchar(30) COMMENT '昵称'; - 查:
DESC users;
- 增:
- 数据的增删改查:
-
增:
INSERT INTO users(如果不写的话就是全部字段都增加) (字段名1, 字段名2, ...) VALUES (值1, 值2, ...); -
删:
DELETE FROM users WHERE id < 3; -
改:
UPDATE users SET name = 'Jack' WHERE id = 1; -
查:

-
索引篇:
索引失效
https://blog.csdn.net/weixin_44382896/article/details/138202372
- 使用了模糊匹配并且使用LIKE '%你好'
- 索引参与了计算或者使用了函数比如说:
explain select * from student_info where student_age+1 =21;、SELECT * FROM table WHERE column + 1 = 10; - 联合索引跳过了前面的索引:
以下是正缺的索引:
但是如果跳过前面的索引就会失效:SELECT * FROM table WHERE col1 = 'value'; -- 使用了 col1 SELECT * FROM table WHERE col1 = 'value' AND col2 = 'value'; -- 使用了 col1 和 col2 SELECT * FROM table WHERE col1 = 'value' AND col2 = 'value' AND col3 = 'value'; -- 全部使用索引

- 使用OR时候导致索引失效:
1 OR 2条件中,如果1字段是索引,但是2字段不是索引值,所以可能就会出现索引失效 - 索引范围很大,索引的作用很小:
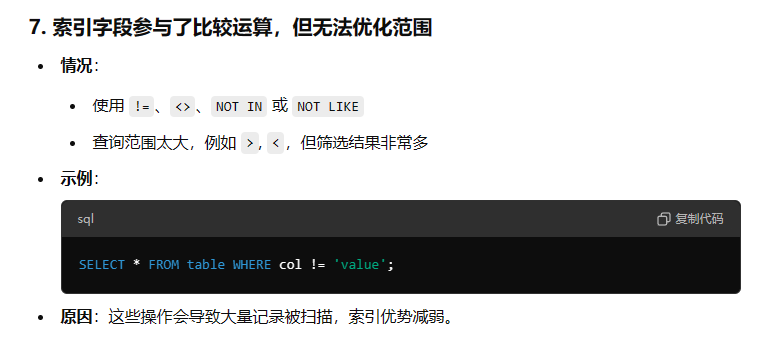
索引失效的检查:
和MySQL慢查询的排查类似,使用 Explain 语句来进行排查。
索引的分类以及区别
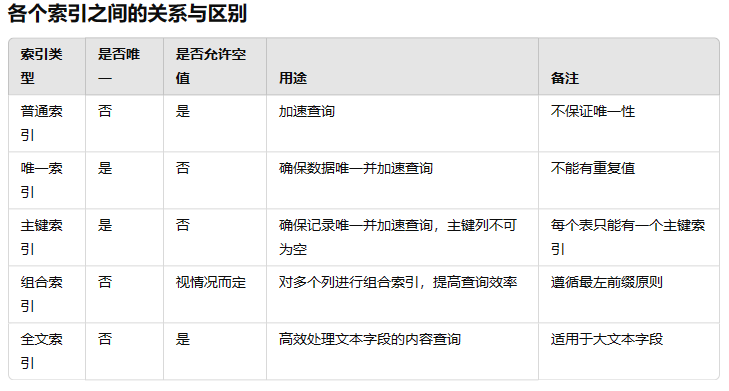
聚簇索引与非聚簇索引:
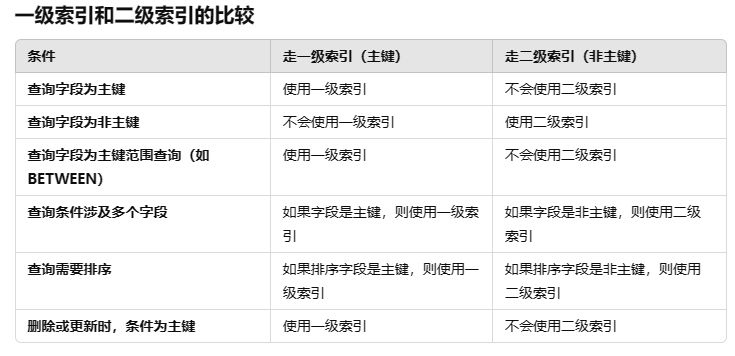
索引优化的方法
- 前缀索引优化:
采用某个字段的前几个字符建立索引,原理减少索引的大小,来达到加快查询的目的,减少了大小之后一个是减少了存储的空间、一个是搜索的时候可以减少处理的数据; - 覆盖索引优化:
对于经常要查询的所有列创建一个覆盖索引,比如我们有两个字段经常要查询,SELECT name, age FROM users WHERE age > 30,你可以为age和name字段创建一个复合索引。这样,数据库可以直接从索引中读取name和age,无需访问数据表。 - 主键索引最好是自增的:
如果我们使用非自增主键,由于每次插入主键的索引值都是随机的,因此每次插入新的数据时,就可能会插入到现有数据页中间的某个位置,这将不得不移动其它数据来满足新数据的插入,甚至需要从一个页面复制数据到另外一个页面,我们通常将这种情况称为页分裂。页分裂还有可能会造成大量的内存碎片,导致索引结构不紧凑,从而影响查询效率。 - 索引建立的时候设置为非空。
- 防止出现索引失效。
通用篇
MyISAM 和 InnoDB 存储引擎的区别有哪些:
- InnoDB 支持事务,MyISAM 不支持;
- InnoDB 支持外键,而 MyISAM 不支持;
- InnoDB 是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高;MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针,主键索引和辅助索引是独立的;
- InnoDB 不保存表的具体行数,MyISAM 用一个变量保存了整个表的行数。
主键与外键
- 主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
- 外键:在一个表中存在的另一个表的主键称此表的外键。
三范式:
- 原子性:每列中的数据必须是单一的、不可再分的值,不能有重复的列或列表;
- 消除部分依赖:如果一个表的主键由“学生ID”和“课程ID”组成,而另一个字段“课程名称”仅依赖于“课程ID”,而不是整个复合主键,则“课程名称”应该移到另一个单独的表中。
- 消除传递依赖:其中“部门名称”依赖于“部门ID”,而“部门ID”依赖于“员工ID”,那么“部门名称”应该从原表中移到“部门表”中,以消除这种传递依赖。
数据库的查询过程:
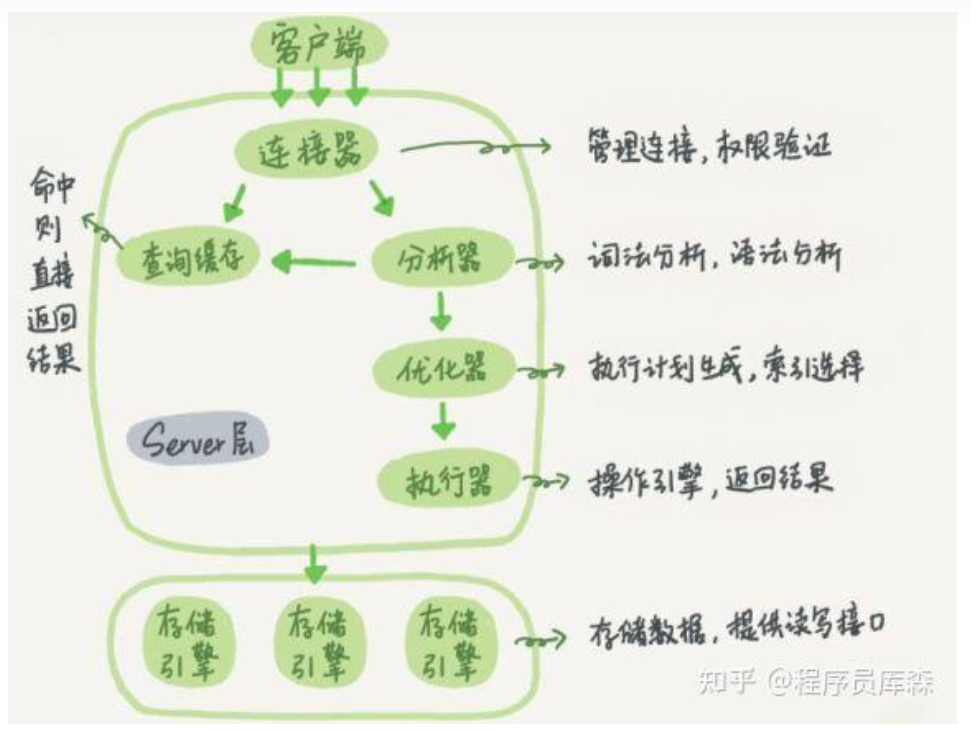
为什么使用B+树作为存储结构
- B+树比二分查找树的优点:
二分查找树会失去平衡性能不稳定,因为没有自平衡技术,会导致出现二分查找树变成链表,时间复杂度会从O(logn)蜕变成O(n)。 - B+树比B树的优点:
- 数据存储在叶子节点;
- 叶子节点通过链表连接在一起,可以使得范围查询和顺序扫描效率更高;
- 每个节点的子节点数量大于两个,存储密度更高;
事务篇
什么是事务:
事务就是保证数据库从一个状态到另外一个状态,不存在中间状态,也就意味着一组操作要么都执行,要么都不执行。
事务的四大特性
- 原子性:如事务的介绍一致;
- 一致性:从一个状态到另外一个状态,不存在中间状态;
- 隔离性:一个事务的执行不能其它事务干扰。即一个事务内部的//操作及使用的数据对其它并发事务是隔离的;
- 持续性:也称永久性,指一个事务一旦提交,它对数据库中的数据的改变就应该是永久性的。
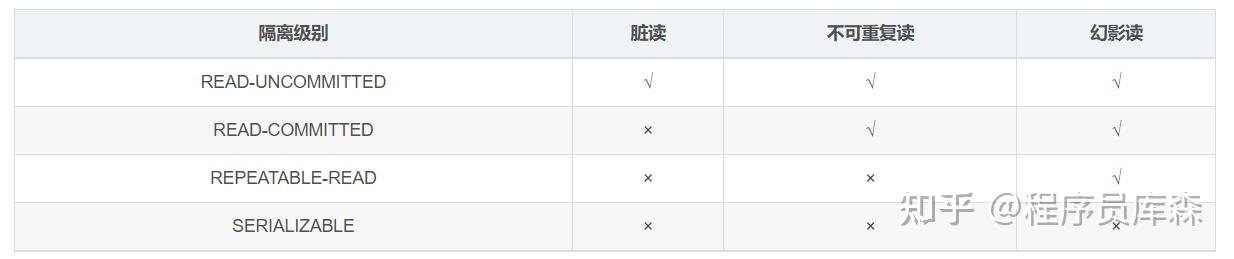
事务的隔离级别:
什么是脏读、不可重复读、幻读:
- 脏读:脏读发生在一个事务读取到另一个事务尚未提交的修改数据时;
- 不可重复读:不可重复读指的是在一个事务内部,当它多次读取某个数据项时,这个数据项的值在事务的执行过程中被其他事务修改。
- 幻读:幻读是指在事务执行期间,另一个事务插入、删除或更新了符合查询条件的数据行,导致事务在执行多次查询时得到不同的结果
不可重复读和幻读的区别:不可重复读是查询到的数据项还是在的,但是数据本省发生了变化,而幻读是数据项发生了变化。
事务的相关指令
- START TRANSACTION / BEGIN: 用于开启一个新的事务块;
- COMMIT:用于提交事务的所有更改;
- ROLLBACK:回滚整个事务的所有操作;
- ROLLBACK savepoint_name:回滚到名字为savepoint_name的保存点;
- SAVEPOINT savepoint_name:设置名称为savepoint_name的保存点;
- RELEASE SAVEPOINT savepoint_name:删除名称为savepoint_name的保存点;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号