汇编语言程序设计(六)包含多个段的程序
引言
- 前几章中程序都是只使用了代码段,本章综合使用代码段、数据段、栈段,毕竟C语言的编译器在将C语言编译成汇编语言的时候也是这个分成几个段来搞的。因此本章很重要啊。本章首先将数据、代码、栈都放在同一个段来使用,然后将它们放在不同段中使用,体会一下差异。
例题

将数据放在代码段实现一
- 如下例子中,dw是定义字型数据,db是定义字节型数据。数据之间以逗号分割。
- 例子中我们将3个数据都放到了代码段中,它们的段地址肯定是CS,由于dw定义的数据处于代码段最开始的地方,所以第一个数据的偏移地址为0。
![]()
![]()

将数据放在代码段实现二
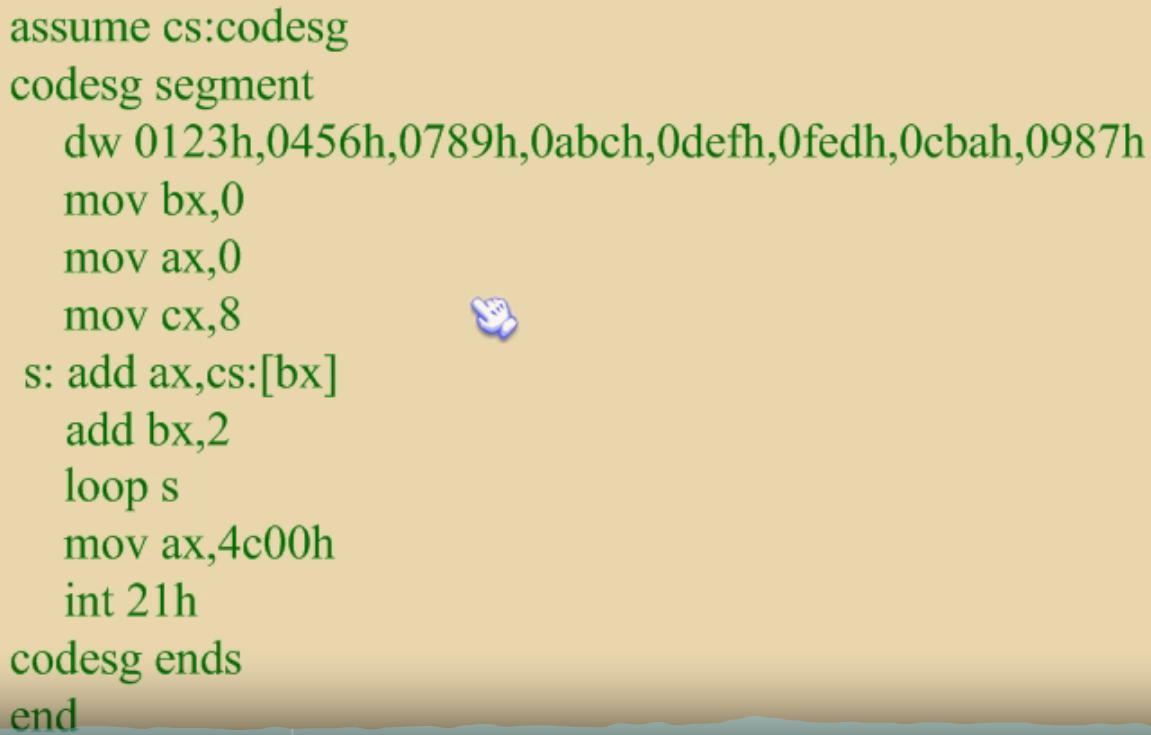
- 上边例子是不能直接运行的,因为dw定义的那些数据因为在代码段中,会被当成代码送到CPU,这就乱了套了,因为把数据当成了指令,导致后边所有指令也乱了。
- 因此需要重新定义程序的入口,将第一行dw定义数据那行绕过去。这里体现了end的两个作用,一个是通知编译器程序结束位置,一个是通知编译器程序的入口。
![]()
在代码段中使用栈
-
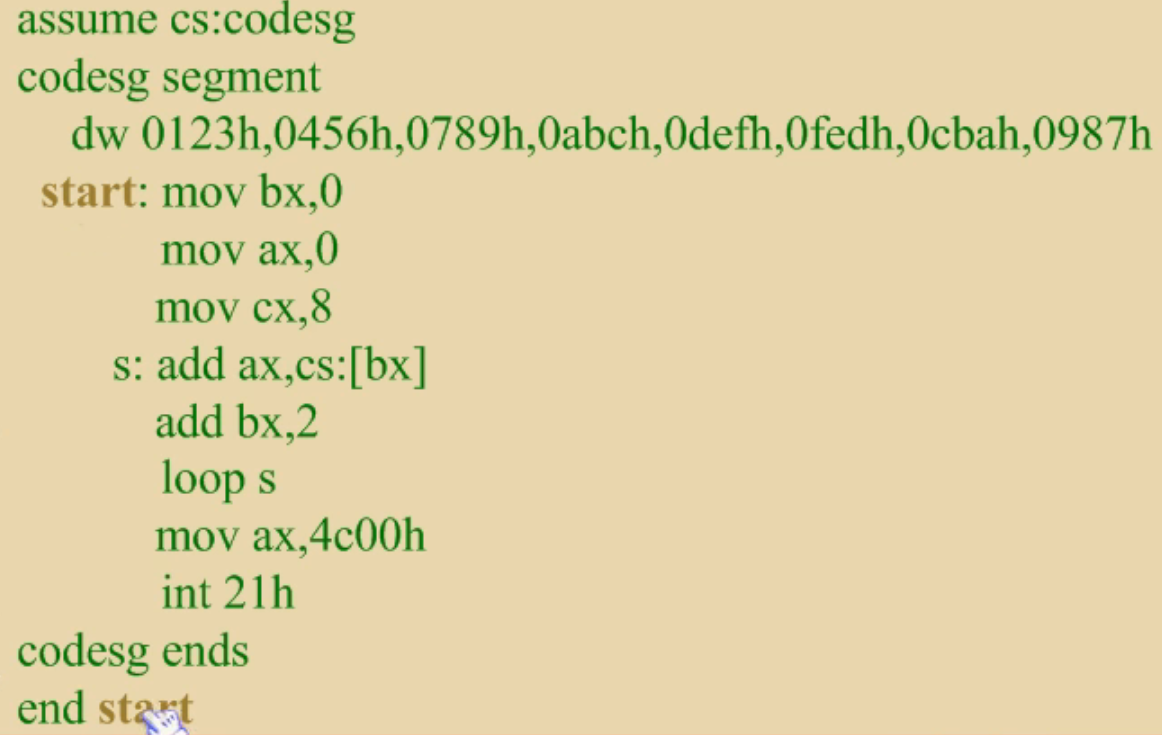
对于下面问题,思路是在程序运行时将定义的数据存放在CS:0到CS:15单元中,依次将这8个单元中的数据入栈,然后再依次将数据出栈并重新放到上边8个单元中,从而实现数据的逆序存放。
![]()
-
首先要先定义一些数据,让系统来分配空间,而这些空间被程序员当作栈来使用,如下例子,因为定义的8个0中,最后一个0的偏移地址是31,因此初试情况栈顶指针应该指向32。即栈空间地址是CS:16到CS:31。图中在给栈段寄存器ss赋值时,是通过寄存器ax来做中介的,这是因为段寄存器之间是没办法直接赋值的,因此要通过寄存器来做。
![]()
-
由上例可知,定义8个字型数据与开辟了8个字的内存空间,这两种说法是等效的,即前者相当于先开辟8个空间然后依次给8个空间赋值。

将数据、代码、栈放入不同的栈
-
前边例子中,将数据、代码、栈都放在了同一个段,但我们在编程时需要注意何处是数据、何处是代码、何处是栈。将所有东西都放入一个栈中会带来两个主要问题,一是使得程序看起来混乱,二是如果要处理的程序很多,或者需要的栈空间很大,那么一个段的空间不够。因此,可以像定义代码段一样定义多个段,在这些段里分别定义需要的数据,或通过定义数据来取得栈空间。
-
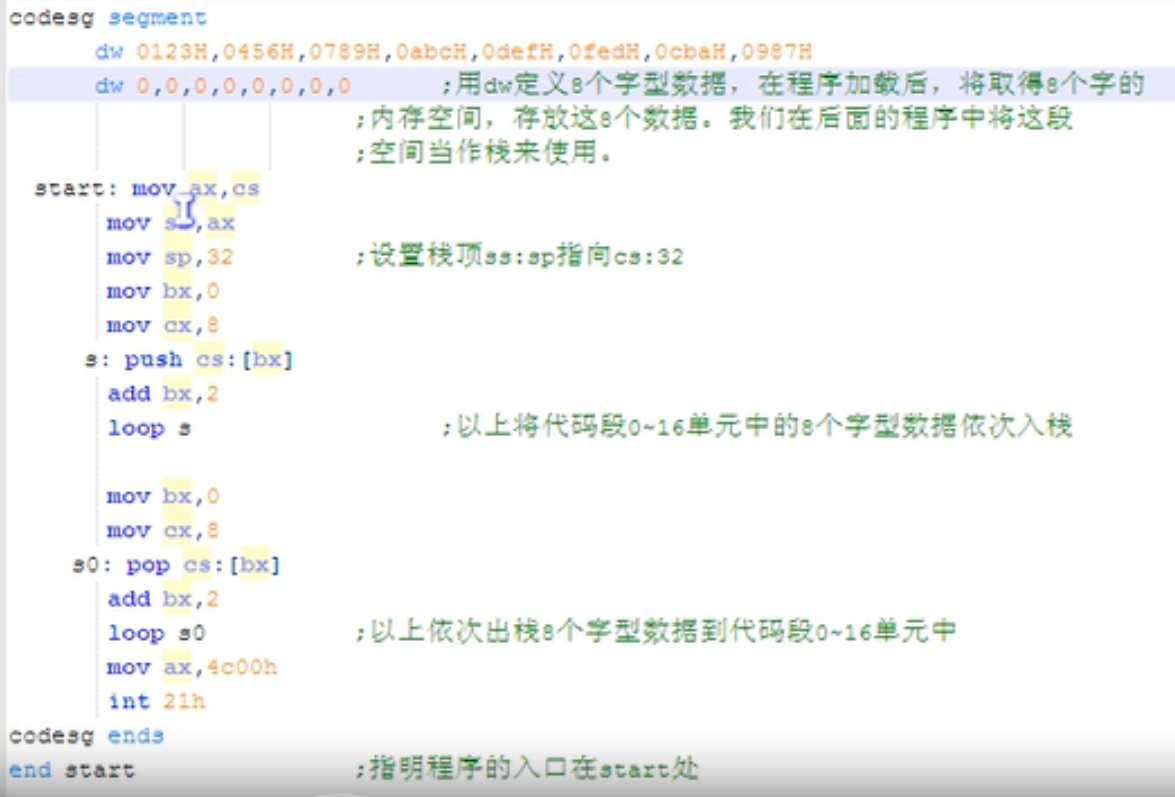
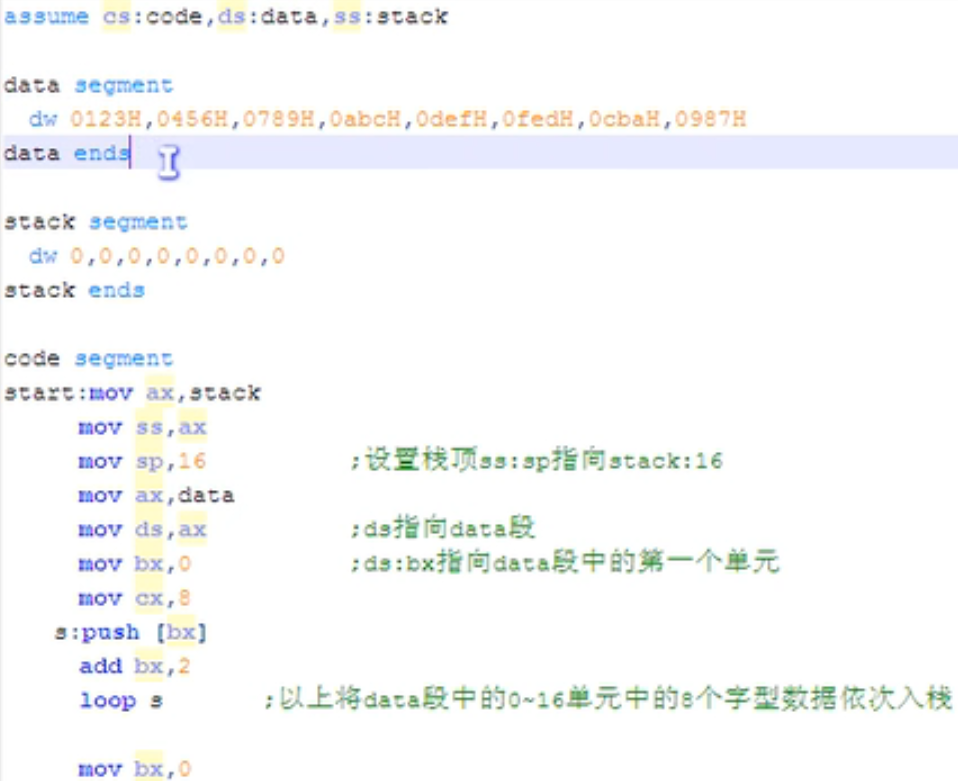
如下例子,分别用多个段寄存器来与多个段关联,注意图中的data和stack等标号会被自动解析成地址来用。assume并没有将data的地址自动送入数据段寄存器data,需要通过一个辅助寄存器来手动送进去。8086CPU不允许将一个数值直接送入段寄存器,这里的data本质上就是一个地址数据。
![]()
![]()
-
可知,所谓代码段、数据段、栈段、完全都是程序员的安排。
-
如上边例子中,虽然我们为三个段取了有含义的名字data,code,stack,但是其实叫a, b, c也没关系,因为汇编器不会靠名字来讲某个段看作代码段,数据段,或栈段。
-
上例中,用assume cs:code,ds:data,ss:stack讲代码段寄存器cs、数据段寄存器ds和栈段寄存器ss分别和code、data、stack段相连,但是这样做了之后cpu就会将cs指向code,ds指向data,ss指向stack,然后按照程序员意图来处理这些段吗?当然也不会,因为这些是伪指令,是给编译器看的,cpu不会管,这是一种假设。
-
那cpu是如何识别三个段的呢?首先,一定是从代码段开始识别,因为数据段和栈段都是依附于代码段存在的,即通过end start来识别程序的入口,这个入口会被写入可执行文件的描述信息,这个入口所在的段当然就是代码段。当可执行程序被加载入内存后,CPU的CS:IP会被设置指向这个入口,然后开始执行程序中的第一条指令。即CPU通过end start来识别代码段。
-
数据段和栈段的识别是在代码段中通过汇编指令实现的,比如上例mov ax, stack, mov ss,ax,这就将stack这个段的地址放到了栈段寄存器ss中,这样CPU就会将stack段当作栈空间来使用。
-
同理,在代码段中将data段的地址放入ds寄存器,则data段就会被CPU当作数据段寄存器来使用。
-
综上,CPU通过end start来识别代码段,然后通过数据段寄存器ds和栈段寄存器ss来识别数据段和栈段。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号