
数据结构与算法介绍
一、什么是数据结构
数据结构就是把数据组织起来,为了更方便地使用数据
我们为了解决问题,需要将数据保存下来,然后根据数据的存储方式来设计算法实现进行处理,那么数据的存储方式不同就会导致需要不同的算法进行处理。我们希望算法解决问题的效率越快越好,于是我们就需要考虑数据究竟如何保存的问题,这就是数据结构。
数据结构的概念:
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。
二、数据结构与算法作用
程序运行的效率和开销
遇到性能瓶颈,如何优化性能
程序 = 数据结构 + 算法
三、算法的概念和五大特性
算法的概念:
算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址供以后再调用。
算法是独立存在的一种解决问题的方法和思想。
算法的五大特性:
1、输入:算法具有0个或多个输入
2、输出:算法至少有1个或多个输出
3、有穷性:算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成
4、确定性:算法中的每一步都有确定的含义,不会出现二义性
5、可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
四、算法效率的衡量
实现算法程序的执行时间可以反映出算法的效率,即算法的优劣。但是单纯依靠运行时间来比较算法的优劣并不一定是客观准确的
时间频度:一个算法花费的时间与算法中语句的执行次数成正比,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度,记为T(n)。n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化
时间复杂度:算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示。如果存在一个整数函数g和实常数c>0,使得对于充分大的n总有T(n)<=c*g(n),就说函数g是T(n)函数的一个渐近函数(忽略常数),记为T(n)=O(g(n)),它称为算法的渐进时间复杂度,简称时间复杂度。这种用O()来体现算法时间复杂度的记法,我们称为大O表示法。
时间复杂度的分类:
1、最优时间复杂度:算法完成工作最少需要多少基本操作,其反映的只是最乐观最理想的情况,没有参考价值
2、最坏时间复杂度:算法完成工作最多需要多少基本操作,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作
3、平均时间复杂度:算法完成工作平均需要多少基本操作,没有保证,会因为应用算法的实例分布可能并不均匀而难以计算
所以,我们主要关注算法的最坏情况,即最坏时间复杂度
时间复杂度的几条基本计算规则:
1、基本操作,即只有常数项,认为其时间复杂度为O(1)
2、顺序结构,时间复杂度按加法进行计算
3、循环结构,时间复杂度按乘法进行计算
4、分支结构,时间复杂度取最大值
5、判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略
6、在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度
空间复杂度:
一个算法的空间复杂度S(n)定义为该算法所耗费的存储空间,它也是问题规模n的函数。渐近空间复杂度也简称为空间复杂度。空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度
对于一个算法,其时间复杂度和空间复杂度往往是相互影响的,大部分时间我们在完成一个程序时采用空间换时间的策略
算法的时间复杂度和空间复杂度合称为算法的复杂度
五、算法的分析
时间复杂度的计算方法
六、常见时间复杂度
| 执行次数函数举例 | 阶 | 非正式术语 |
| 12 | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| 3n2+2n+1 | O(n2) | 平方阶 |
| 5log2n+20 | O(logn) | 对数阶 |
| 2n+3nlog2n+19 | O(nlogn) | nlogn阶 |
| 6n3+2n2+3n+4 | O(n3) | 立方阶 |
| 2n | O(2n) | 指数阶 |
注意,经常将log2n(以2为底的对数)简写成logn
常见时间复杂度之间的关系
所消耗的时间从小到达:
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
六、Python内置类型性能分析
timeit模块的使用
1、作用:timeit模块可以用来测试一小段Python代码的执行速度。
2、使用的类:
timeit.Timer(stmt='pass', setup='pass', timer=<timer function>)
-
Timer是测量小段代码执行速度的类。
-
stmt参数是要测试的代码语句(statment);
-
setup参数是运行代码时需要的设置;
-
timer参数是一个定时器函数,与平台有关
3、类的方法:
Timer.timeit(number=1000000) Timer类中测试语句执行速度的对象方法
number参数是测试代码时的测试次数,默认为1000000次。方法返回执行代码的耗时,一个float类型的秒数。
4、例子:
list的操作测试
def t1(): l = [] for i in range(1000): l = l + [i] def t2(): l = [] for i in range(1000): l.append(i) def t3(): l = [i for i in range(1000)] def t4(): l = list(range(1000)) from timeit import Timer timer1 = Timer("t1()", "from __main__ import t1") print("concat ",timer1.timeit(number=1000), "seconds") timer2 = Timer("t2()", "from __main__ import t2") print("append ",timer2.timeit(number=1000), "seconds") timer3 = Timer("t3()", "from __main__ import t3") print("comprehension ",timer3.timeit(number=1000), "seconds") timer4 = Timer("t4()", "from __main__ import t4") print("list range ",timer4.timeit(number=1000), "seconds") # ('concat ', 1.7890608310699463, 'seconds') # ('append ', 0.13796091079711914, 'seconds') # ('comprehension ', 0.05671119689941406, 'seconds') # ('list range ', 0.014147043228149414, 'seconds')
insert与append比较
def t2(): li = [] for i in range(10000): li.append(i) def t5(): li = [] for i in range(10000): li.insert(0, i) timer2 = Timer('t2()', 'from __main__ import t2') print("append:", timer2.timeit(number=1000)) timer5 = Timer('t5()', 'from __main__ import t5') print("insert:", timer5.timeit(number=1000)) # append: 0.9202240769991477 # insert: 21.039387496999552
从结果可以看出,append从尾端添加元素效率远远高于insert从顶端添加元素
list内置操作的时间复杂度

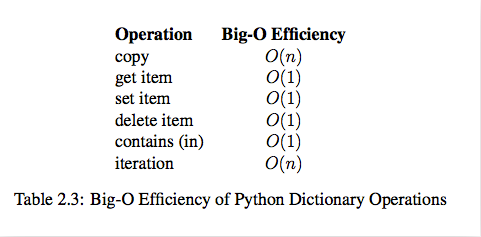
dict内置操作的时间复杂度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号