
以下内容是根据Unity 2020.3.32f1版本进行编写的
一、疑惑
最近在工作中,有需要将某个视频资源放到Unity中并播放,我一般都会先用小丸工具箱手动压缩一遍,再拖进项目中。
但我有点疑惑,首先,Unity没有针对视频资源的优化处理吗?我看项目中是没有在import setting中有override的设置的,都是用的默认导入设置;其次,小丸工具箱一般都是用x264编码器,调整CRF值来压缩视频的,一般都能压缩80%左右,100m的视频,一般能压缩到10m左右,为什么能压缩这么多,压缩这么多对视频有什么影响;第三,既然能压缩这么多,能否用已经压缩过的视频进行2次压缩甚至3次压缩,还能压吗,多次压缩对视频有什么影响......
二、小丸工具箱压缩参数和压缩流程
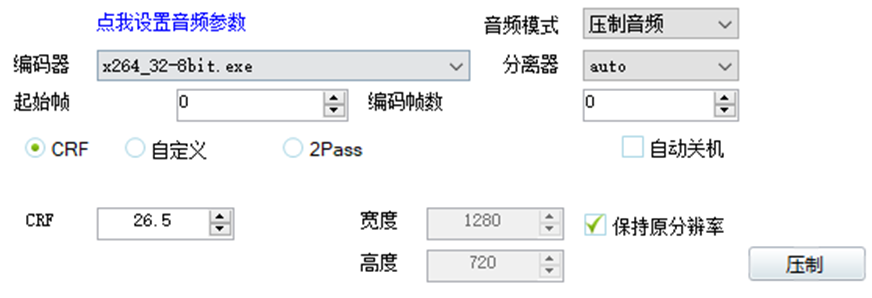
一般我都是调整CRF参数来控制压缩后视频大小的。
这里简单说一下小丸压缩视频的流程(豆包AI):
首先,小丸先用auto分离器自动识别原视频的封装格式(例如MP4、MKV、MOV等),解封装,分离出原始视频流和原始音频流,这里仅做拆分处理,不修改数据。
然后用H.264编码器,按设置的CRF值,对原始视频流做重编码压缩。
保持原分辨率,用H.264+CRF压缩视频时,视频压缩的本质是,剔除视频流中的3类冗余数据,通过量化算法降低数据量,同时保留人眼敏感的核心画质,具体如下:
1、空间冗余(单帧内的重复像素)
压缩对象:单帧画面中,相邻像素的重复信息,、大面积纯色/渐变区域的冗余数据
比如视频里的天空、墙面、静态背景,相邻像素的颜色、亮度几乎一致,原始视频会完整记录每一个像素的细节,H.264 编码器会通过“帧内预测”算法,只记录“像素差异值”,而非完整像素数据,大幅减少单帧体积。
CRF 的影响:CRF 越大,剔除的空间冗余越多 —— 大面积纯色区域会进一步合并细节,边缘轻微模糊,数据量更小;CRF 越小,保留的像素细节越完整,冗余剔除越少。
2、(帧与帧之间的重复画面)
压缩对象:连续帧之间的重复画面、缓慢运动的物体位移信息(视频最核心的冗余来源,占比 60%~80%)。
比如人物说话、静态场景的轻微晃动,前后 10 帧的画面 90% 都是重复的,原始视频会逐帧完整存储,H.264 会通过“帧间预测(P 帧 / B 帧)”算法,只记录帧间变化的部分,重复部分直接复用前一帧数据,仅用少量数据描述运动轨迹。
CRF 的影响:CRF 越大,帧间预测的“容错率”越高 —— 允许更大的帧间差异被忽略,重复画面复用更彻底,压缩率更高;CRF 越小,帧间差异记录越精细,运动画面更流畅,但冗余保留更多。
3. 视觉冗余(人眼不敏感的细节)
压缩对象:人眼无法感知的高频细节、暗部 / 亮部的过度细节、色彩冗余信息****。
人眼对“高频锐化细节(如微小纹理)、暗部噪点、高饱和色彩的细微渐变”不敏感,原始视频会完整记录这些无效细节,H.264 会通过“量化参数(QP,CRF 的核心底层指标)”,抹除这些视觉冗余,只保留人眼敏感的主体轮廓、核心色彩。
CRF 的核心作用:CRF 是「视觉质量控制指数」,直接决定量化的强度~~——CRF 数值每 +1,量化强度提升,视觉冗余剔除更多,视频体积约减少 20%~30%;CRF 每 -1,量化强度降低,冗余保留更多,体积约增加 20%30%。</font>~(删除线的这段话我不赞同,因为实际情况是一段1分钟左右的视频,CRF+1,体积仅减少约几M,并且CRF值越大,作用越来越弱,例如CRF+1,体积减少5M,CRF再+1,体积再减少3M)
接着,对音频段压缩,「压制音频」不是「不处理音频」,而是小丸对原始音频流做默认的重编码压缩(小丸 H.264 场景下,音频默认编码为 AAC LC 格式,安卓全平台兼容),压缩对象是音频的 2 类冗余:
1. 听觉冗余(人耳不敏感的频率 / 音量信息)
压缩对象:人耳无法感知的超高频 / 超低频声波、小音量背景噪点、音频采样的冗余量化数据。
原始音频(如 MP3 320kbps、WAV 无损)会完整记录所有频率声波,AAC 编码器会通过「心理声学模型」,剔除人耳听不到的冗余频率,仅保留核心人声、背景音乐的有效频率。
2. 码率压缩(降低音频数据率)
小丸「压制音频」的默认行为:将原始音频(无论原码率是 320kbps、无损 WAV,还是 128kbps),重编码为 96kbps~128kbps 的 AAC LC 音频(固定码率,小丸默认参数)。
压缩逻辑:降低音频的采样量化精度,减少每秒的音频数据量,同时保证语音 / 背景音乐的可听性(96kbps AAC 对语音几乎无失真,128kbps 对音乐足够)。
简单说:音频压缩的是「无效声波数据」和「过高的码率冗余」,最终输出更小体积的 AAC 音频流。
最后,将压缩后的新视频流和新音频流封装为标准格式的MP4格式(小丸默认输出MP4,仅打包,不压缩)
三、多次压缩的影响

我将一段视频以CRF为26.5的参数,分别压缩了1、2、3次,可以看到,原视频是100M左右,压缩一次的视频大小是10.7M,压缩两次的视频大小是10.1M,压缩三次的视频大小是9.67M。
为了研究一下视频多次压缩后的影响,我首先尝试通过肉眼看看有没有区别,发现是直接看其实很难看出太大的差异,接下来就需要借助工具了。
首先尝试在Unity中分别以RGB三个通道播放视频,看看相同通道中,能不能对比看出多次压缩后有明显的像素被压缩了:
可以实现一个仅看R/G/B通道的Shader:
Shader "Custom/RGBAChannelViewer" {
Properties{ _MainTex("Texture", 2D) = "white" {} _Channel("Channel (0=R,1=G,2=B,3=A)", Int) = 0 }
SubShader{
Pass {
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
sampler2D _MainTex;
int _Channel;
struct appdata { float4 vertex : POSITION; float2 uv : TEXCOORD0; };
struct v2f { float2 uv : TEXCOORD0; float4 vertex : SV_POSITION; };
v2f vert(appdata v) { v2f o; o.vertex = UnityObjectToClipPos(v.vertex); o.uv = v.uv; return o; }
fixed4 frag(v2f i) : SV_Target {
fixed4 col = tex2D(_MainTex, i.uv);
return fixed4((_Channel == 0 ? col.r : 0), (_Channel == 1 ? col.g : 0), (_Channel == 2 ? col.b : 0), (_Channel == 3 ? col.a : 1));
}
ENDCG
}
}
}
然后在场景中摆出如下结构:
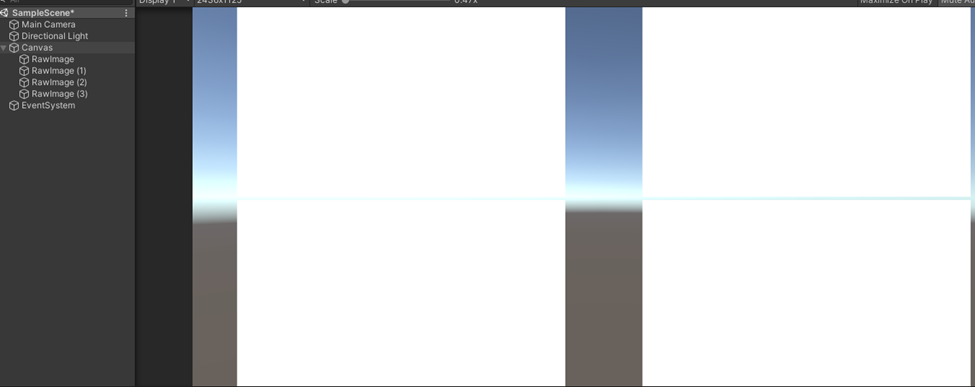
创建材质球并将4个品质的视频分别挂载到4个节点中播放,我这里用的是RawImage + VideoPlayer播放视频的,挂载的脚本:
using UnityEngine;
using UnityEngine.UI;
using UnityEngine.Video;
public class MyVideoPlayer : MonoBehaviour
{
private RenderTexture renderTexture;
void Awake()
{
RectTransform rectTransform = GetComponent<RectTransform>();
renderTexture = new RenderTexture((int)rectTransform.rect.width, (int)rectTransform.rect.height, 32);
VideoPlayer videoPlayer = GetComponent<VideoPlayer>();
RawImage rawImage = GetComponent<RawImage>();
if (videoPlayer && rawImage)
{
videoPlayer.targetTexture = renderTexture;
rawImage.texture = renderTexture;
}
}
}
运行效果:



左上是无压缩的视频,右上是压缩一次的视频,左下是压缩两次的视频,右下是压缩3次的视频,仅用肉眼也看不出什么区别。
既然如此,直接用数据说话:
用python实现一个工具,支持将视频导出成序列帧,然后逐帧逐像素对比多段不同压缩程度的视频与原视频的RGB差异
Python工具代码(还是豆包AI):
import cv2
import os
import numpy as np
from typing import List, Dict, Tuple
# 配置项(可根据需求修改)
FRAME_SAVE_FOLDER = "video_frames" # 帧存储根目录
REPORT_FILE = "pixel_compare_report.txt" # 对比报告文件
IMAGE_FORMAT = "png" # 导出帧格式(png无压缩,推荐)
COLOR_MODE = cv2.COLOR_BGR2RGB # OpenCV默认BGR,转换为RGB计算
def init_folder() -> None:
"""初始化文件夹,避免路径不存在"""
if not os.path.exists(FRAME_SAVE_FOLDER):
os.makedirs(FRAME_SAVE_FOLDER)
# 清空旧报告
if os.path.exists(REPORT_FILE):
os.remove(REPORT_FILE)
def write_report(content: str) -> None:
"""写入对比报告(追加模式)"""
with open(REPORT_FILE, "a", encoding="utf-8") as f:
f.write(content + "\n\n")
def video2frames(video_path: str, start_sec: float, end_sec: float, frame_group_name: str) -> str:
"""
视频转序列帧(指定时间区间)
:param video_path: 视频文件路径
:param start_sec: 起始秒(≥0)
:param end_sec: 结束秒(>start_sec,超过视频时长则取到末尾)
:param frame_group_name: 帧组名称(如original/encode_50/encode_80,区分不同压缩程度)
:return: 帧组存储路径
"""
# 校验视频文件
if not os.path.exists(video_path):
raise FileNotFoundError(f"视频文件不存在:{video_path}")
# 创建帧组专属文件夹
frame_group_path = os.path.join(FRAME_SAVE_FOLDER, frame_group_name)
if os.path.exists(frame_group_path):
for f in os.listdir(frame_group_path):
os.remove(os.path.join(frame_group_path, f))
else:
os.makedirs(frame_group_path)
# 打开视频
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS) # 视频帧率
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 总帧数
video_duration = total_frames / fps # 视频总时长(秒)
# 修正时间区间(防止超出视频范围)
start_sec = max(0.0, start_sec)
end_sec = min(end_sec, video_duration)
if start_sec >= end_sec:
raise ValueError(f"起始时间{start_sec}秒≥结束时间{end_sec}秒,无法导出")
# 计算起始/结束帧索引
start_frame = int(start_sec * fps)
end_frame = int(end_sec * fps)
cap.set(cv2.CAP_PROP_POS_FRAMES, start_frame) # 跳转到起始帧
# 逐帧导出
frame_idx = start_frame
saved_frame_num = 0
while cap.isOpened() and frame_idx <= end_frame:
ret, frame = cap.read()
if not ret:
break
# 帧保存路径(命名:frame_00001.png,补零保证排序)
frame_save_name = f"frame_{saved_frame_num:05d}.{IMAGE_FORMAT}"
frame_save_path = os.path.join(frame_group_path, frame_save_name)
cv2.imwrite(frame_save_path, frame)
frame_idx += 1
saved_frame_num += 1
cap.release()
# 打印导出信息
info = f"【{frame_group_name}】帧导出完成\n" \
f"视频路径:{video_path}\n" \
f"时间区间:{start_sec}s ~ {end_sec}s(实际:{start_sec}s ~ {frame_idx/fps:.2f}s)\n" \
f"帧率:{fps:.2f} | 导出帧数:{saved_frame_num} | 存储路径:{frame_group_path}"
print(info)
write_report(info)
return frame_group_path
def get_frame_file_list(frame_folder: str) -> List[str]:
"""获取帧文件夹内的有序帧文件列表(按命名排序)"""
if not os.path.exists(frame_folder):
raise FileNotFoundError(f"帧文件夹不存在:{frame_folder}")
frame_files = [f for f in os.listdir(frame_folder) if f.endswith(f".{IMAGE_FORMAT}")]
frame_files.sort() # 按命名升序,保证帧顺序一致
if not frame_files:
raise ValueError(f"帧文件夹{frame_folder}内无{IMAGE_FORMAT}格式帧文件")
return [os.path.join(frame_folder, f) for f in frame_files]
def pixel_compare(base_frame_path: str, comp_frame_path: str) -> Dict[str, np.ndarray]:
"""
单帧逐像素RGB对比(计算差值)
:param base_frame_path: 基准帧(无压缩)路径
:param comp_frame_path: 对比帧(压缩)路径
:return: 差值统计结果(各通道/总差值的均值、最大值、总和)
"""
# 读取帧并转换为RGB
base_img = cv2.imread(base_frame_path)
comp_img = cv2.imread(comp_frame_path)
if base_img is None or comp_img is None:
raise ValueError(f"帧读取失败:基准帧{base_frame_path} / 对比帧{comp_frame_path}")
# 校验帧尺寸一致(不一致无法对比)
if base_img.shape != comp_img.shape:
raise ValueError(f"帧尺寸不一致:基准帧{base_img.shape} vs 对比帧{comp_img.shape}")
base_rgb = cv2.cvtColor(base_img, COLOR_MODE)
comp_rgb = cv2.cvtColor(comp_img, COLOR_MODE)
# 逐像素计算RGB差值(绝对值,避免负差值)
pixel_diff = np.abs(base_rgb - comp_rgb) # 形状:(H, W, 3),3对应R/G/B
h, w, c = pixel_diff.shape
total_pixel = h * w # 总像素数
# 统计计算(R/G/B各通道 + 总差值)
result = {
# 各通道差值:(均值, 最大值, 总和)
"R": (np.mean(pixel_diff[:, :, 0]), np.max(pixel_diff[:, :, 0]), np.sum(pixel_diff[:, :, 0])),
"G": (np.mean(pixel_diff[:, :, 1]), np.max(pixel_diff[:, :, 1]), np.sum(pixel_diff[:, :, 1])),
"B": (np.mean(pixel_diff[:, :, 2]), np.max(pixel_diff[:, :, 2]), np.sum(pixel_diff[:, :, 2])),
# 总像素差值(单像素RGB差值和,再统计)
"total": (np.mean(pixel_diff.sum(axis=2)), np.max(pixel_diff.sum(axis=2)), np.sum(pixel_diff))
}
return result
def batch_compare(base_frame_folder: str, comp_frame_folders: List[Tuple[str, str]]) -> None:
"""
批量对比多组压缩帧与基准帧
:param base_frame_folder: 基准帧组(无压缩)路径
:param comp_frame_folders: 对比帧组列表,元素为(帧组名称, 帧组路径)
"""
# 获取基准帧和所有对比帧的文件列表
base_frames = get_frame_file_list(base_frame_folder)
total_frame_num = len(base_frames)
compare_info = f"【批量对比初始化】\n基准帧组:{base_frame_folder}\n对比帧组数量:{len(comp_frame_folders)}\n总对比帧数:{total_frame_num}"
print(compare_info)
write_report(compare_info)
# 逐组对比
for comp_name, comp_folder in comp_frame_folders:
comp_frames = get_frame_file_list(comp_folder)
# 校验帧数一致
if len(comp_frames) != total_frame_num:
raise ValueError(f"【{comp_name}】帧数与基准帧不一致:基准{total_frame_num}帧 vs 对比{len(comp_frames)}帧")
# 初始化组级统计(累加所有帧的差值,最后计算均值)
group_stats = {
"R": [0.0, 0.0, 0.0], "G": [0.0, 0.0, 0.0], "B": [0.0, 0.0, 0.0],
"total": [0.0, 0.0, 0.0] # [均值和, 最大值和, 总和和]
}
group_max = {
"R": 0.0, "G": 0.0, "B": 0.0, "total": 0.0 # 组内单帧最大差值
}
# 逐帧对比
print(f"\n========== 开始对比【{comp_name}】==========")
write_report(f"========== 【{comp_name}】逐帧对比结果 ==========")
for frame_idx, (base_f, comp_f) in enumerate(zip(base_frames, comp_frames)):
frame_name = f"第{frame_idx:05d}帧"
try:
frame_result = pixel_compare(base_f, comp_f)
except Exception as e:
err_info = f"{frame_name}对比失败:{str(e)}"
print(err_info)
write_report(err_info)
continue
# 单帧结果格式化
frame_info = f"{frame_name}\n"
for ch in ["R", "G", "B", "total"]:
mean, max_val, sum_val = frame_result[ch]
frame_info += f" {ch}通道:均值差={mean:.4f} | 最大值差={max_val:.0f} | 总像素差={sum_val:.0f}\n"
# 更新组级统计
group_stats[ch][0] += mean
group_stats[ch][1] = max(group_stats[ch][1], max_val)
group_stats[ch][2] += sum_val
# 更新组内最大差值
group_max[ch] = max(group_max[ch], max_val)
print(frame_info.strip())
write_report(frame_info.strip())
# 计算组级平均(所有帧的均值)
group_avg = {
ch: [s[0]/total_frame_num, s[1], s[2]] for ch, s in group_stats.items()
}
# 组级结果格式化
group_info = f"【{comp_name}】全序列对比汇总(共{total_frame_num}帧)\n"
for ch in ["R", "G", "B", "total"]:
mean_avg, max_val, sum_total = group_avg[ch]
group_info += f" {ch}通道:平均均值差={mean_avg:.4f} | 全局最大差={max_val:.0f} | 总像素差={sum_total:.0f}\n"
print(f"\n{group_info.strip()}")
write_report(f"【{comp_name}】全序列汇总\n{group_info.strip()}")
def main():
"""主函数:配置视频路径、时间区间、压缩组,执行导出+对比"""
# 1. 初始化文件夹
init_folder()
# ====================== 【核心配置:修改这里!】======================
# 视频列表:(视频文件路径, 帧组名称, 起始秒, 结束秒)
# 第一个为**无压缩基准视频**,后续为不同压缩程度的视频(保持时间区间一致!)
video_configs = [
(r"original_video.mp4", "original", 0.0, 10.0), # 无压缩:0-10秒
(r"encode_30.mp4", "encode_30", 0.0, 10.0), # 压缩30%:0-10秒
(r"encode_60.mp4", "encode_60", 0.0, 10.0), # 压缩60%:0-10秒
(r"encode_90.mp4", "encode_90", 0.0, 10.0), # 压缩90%:0-10秒
]
# =====================================================================
# 2. 批量导出所有视频的序列帧
frame_group_paths = [] # 存储(帧组名称, 帧组路径)
for idx, (v_path, g_name, s_sec, e_sec) in enumerate(video_configs):
try:
g_path = video2frames(v_path, s_sec, e_sec, g_name)
frame_group_paths.append((g_name, g_path))
print("-" * 80 + "\n")
except Exception as e:
print(f"【{g_name}】帧导出失败:{str(e)}\n" + "-" * 80 + "\n")
raise e # 导出失败则终止程序
# 3. 批量对比:以第一个帧组为基准,对比后续所有帧组
base_name, base_path = frame_group_paths[0]
comp_groups = frame_group_paths[1:]
if comp_groups:
batch_compare(base_path, comp_groups)
else:
print("无对比帧组,仅完成帧导出")
print(f"\n所有操作完成!对比报告已保存至:{os.path.abspath(REPORT_FILE)}")
print(f"序列帧已保存至:{os.path.abspath(FRAME_SAVE_FOLDER)}")
if __name__ == "__main__":
main()
【encode_1】全序列汇总
【encode_1】全序列对比汇总(共251帧)
R通道:平均均值差=101.1290 | 全局最大差=255 | 总像素差=38014138763
G通道:平均均值差=80.5719 | 全局最大差=255 | 总像素差=30286796076
B通道:平均均值差=105.7605 | 全局最大差=255 | 总像素差=39755120190
total通道:平均均值差=287.4614 | 全局最大差=765 | 总像素差=108056055029
【encode_2】全序列汇总
【encode_2】全序列对比汇总(共251帧)
R通道:平均均值差=106.8183 | 全局最大差=255 | 总像素差=40152755007
G通道:平均均值差=82.0401 | 全局最大差=255 | 总像素差=30838667948
B通道:平均均值差=110.9818 | 全局最大差=255 | 总像素差=41717776075
total通道:平均均值差=299.8402 | 全局最大差=765 | 总像素差=112709199030
【encode_3】全序列汇总
【encode_3】全序列对比汇总(共251帧)
R通道:平均均值差=110.1980 | 全局最大差=255 | 总像素差=41423166423
G通道:平均均值差=82.5065 | 全局最大差=255 | 总像素差=31013984941
B通道:平均均值差=113.7487 | 全局最大差=255 | 总像素差=42757880723
total通道:平均均值差=306.4532 | 全局最大差=765 | 总像素差=115195032087
从工具逐帧逐像素对比视频RGB差异值可以得出,压缩次数越多,总像素差异越大,但是这里为什么肉眼看不出来,其实是因为除了第一次压缩时压缩了很多(压缩了90M),第二次压缩只压缩了0.6M,第三次压缩仅0.43M,所以其实视频中的每帧没差多少,但是如果一直压缩下去,肯定会出现糊的情况。
所以一般只压缩一次,压缩前调整好CRF参数,如果压缩后的视频太小了,可以适当调小CRF参数,保留更多细节,反之则调大CRF参数,牺牲部分肉眼看不出来的细节优化视频大小。
四、Unity中Video Clip的import setting
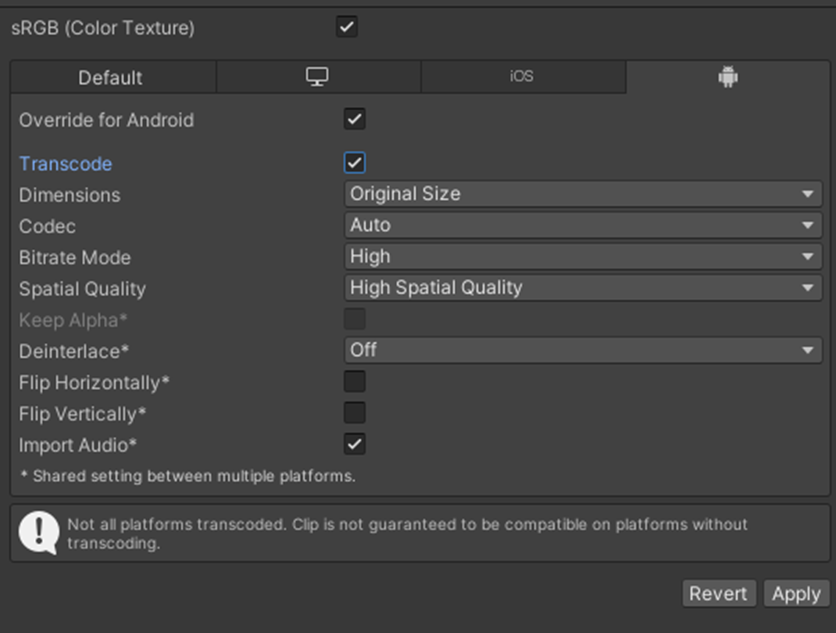
后续的Unity版本估计会支持更多参数,但这里主要解释转码(Transcode)对视频的影响
Unity是有对Video Clip类型的资源做优化处理的,默认情况下不会优化,需要勾选Override for Android/Override for iPhone,并勾选Transcode才能调整视频导入的一些设置。
这里简短说明一下,主要就是这个Transcode勾不勾选的情况,不勾选的情况下,Unity会直接将视频文件打进包里,不会做任何处理,视频原来是多大的,打进包后就是多大的;如果勾选后,Unity会按导入设置,将视频进行优化处理,具体是对视频文件进行重新编码+格式适配+压缩优化。
勾选转码后,分别将上述4个不同压缩次数的视频文件打包。
原视频大小:

打包后的文件:
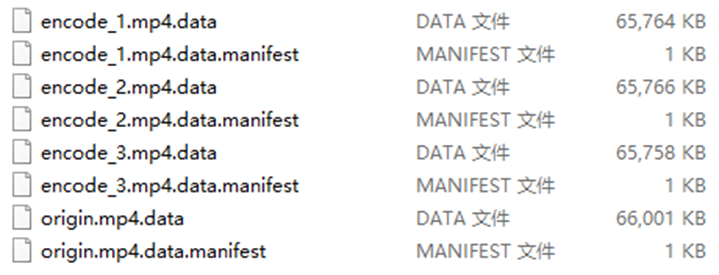
可以看出,转码后100M左右的视频被压缩了,但是已经压缩过的视频,被Unity转码压缩后,文件大小反而变大了。
这是因为Unity的转码是兼容性优化的标准化重编码,而手动压缩是极致体积优化的自定义压缩。
简单来说就是,Unity有一套最低标准,但是能保证在各个平台的兼容性,所以按这个标准,转码后的大小是差不多的(但还是有零点几兆的差异,估计就是因为已经压缩过导致的数据丢失)。
大佬们发现有错误欢迎拍砖~
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号