webscraper 元素选择和翻页
用于记录供以后使用,原文https://blog.csdn.net/qq_29027865/article/details/82216755和https://blog.csdn.net/chen801090/article/details/105841851/
一、选择器介绍
1.使用link可以使得爬取到的内容多获取两列,一列是该指定link处的文字text,一列是跳转的链接的url;
2.使用link爬取多级页面时,如果想获得多级页面下的内容,不管这个页面是在当页打开,或是在新的页面打开,都可以在创建的类型为link的结构下,再对子页面的元素进行抓取;
3.Text用于文本,Table用于表格,image用于图片;
4.Element用于结构体,可以在结构体内再去选择子元素,但是其子元素不用勾选multiple选项;
5.Element scroll down用于爬取下拉滚动式的页面结构体;
6.Element click用来爬取需要点击的分页页面;
7.Element click的使用基本上有两种(应该使适用于页面不刷新情况下翻页):
第一是采用click one的方式直接全部选取:
第二是采用click more的方式来点击下一页进行获取:
8.遇到有规律的分页,可以使用[2-5]表示第2页到第5页,如果是步长为2页,则可以:[2-5:2]
二、具体分析步骤
-
单页数据抓取
主要为了一条记录的各数据项对应上,先创建一级element节点(选择多个需要勾选multiple),再在element节点下选择具体数据(此时multiple不用选,是在一个结构体内选择元素) -
多页抓取
2.1. 切换页面url有规律变化时
通过设置starturl来实现,
![]()
2.2.无规律的翻页场景
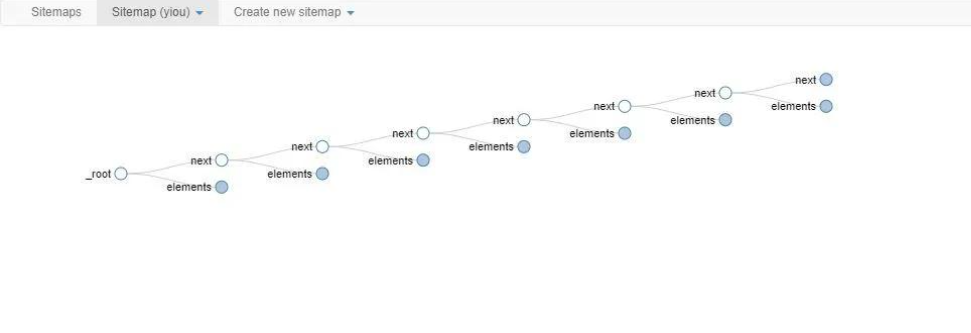
可以利用循环嵌套抓取结构来实现翻页抓取,首先在一级selector增加一个获取下一页链接的selector。该next selector获取当前页面的下一页链接。elements selector获取当前页面的元素。
![]()


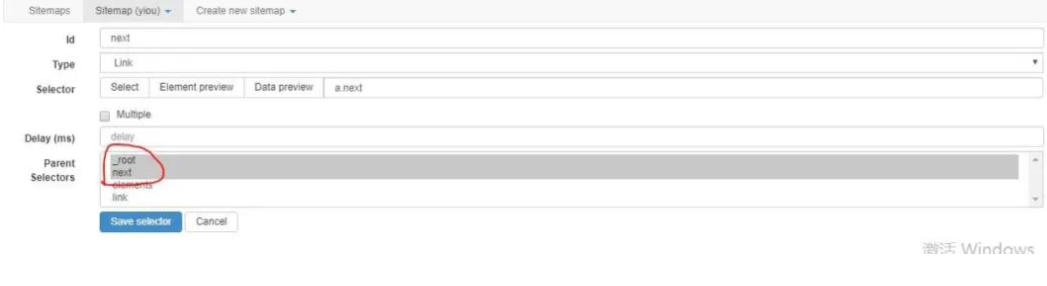
接着,我们分别配置elements和next的父节点,next的父节点除了root以外,我们将next自身也添加为父节点。
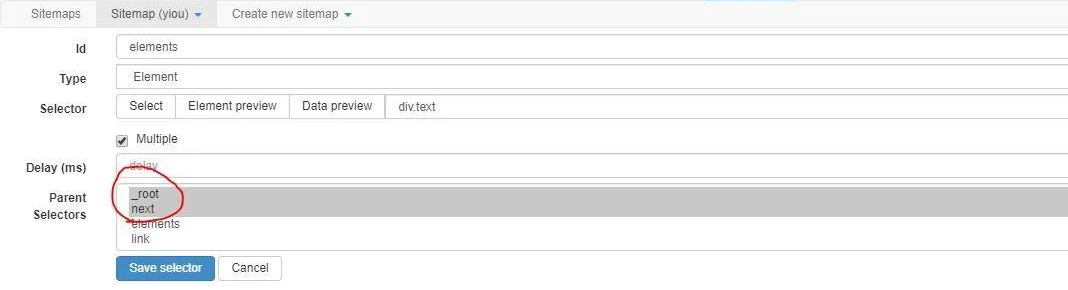
elements的父节点除了root以外,我们也将next添加为父节点。
最后,我们来看下整个抓取结构图,如下所示,点击next,可以看到整个结构会无限循环下去,通过这种方式,我们就可以构建一个通用的翻页循环抓取结构!
2.3. 滚动加载场景
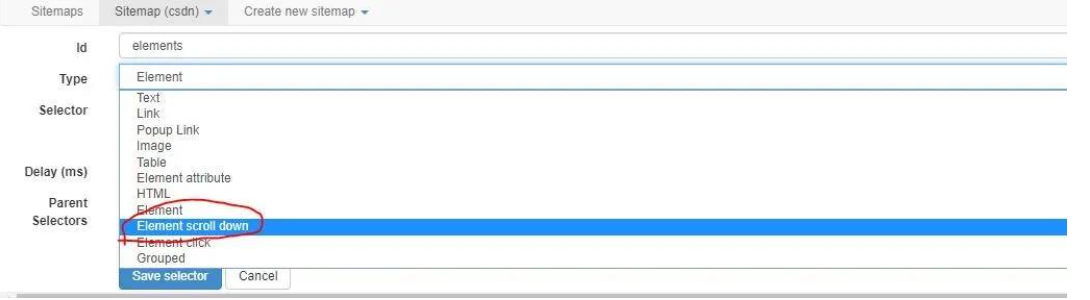
其实很简单,webscraper已经帮我们设计好了这种元素类型,即selector type里的elements scroll down,在选择type时,将之前的elements换成这个类型即可,其他配置方式保持不变,我们即可以实现滚动加载数据的抓取。
2.4. 点击加载场景(加载更多按钮)
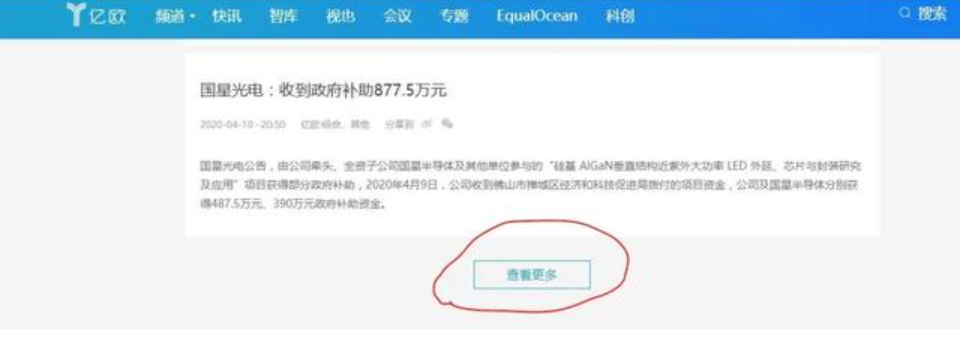
当然少不了我们强大的webscraper啦!webscraper提供了一种type类型,即elements click,可以轻松解决此类问题,接下来让我们看一个具体的实例,我们以亿欧网站为例,打开快讯栏目,我们可以看到如果要获取更多数据的话,必须点击查看更多才会加载。
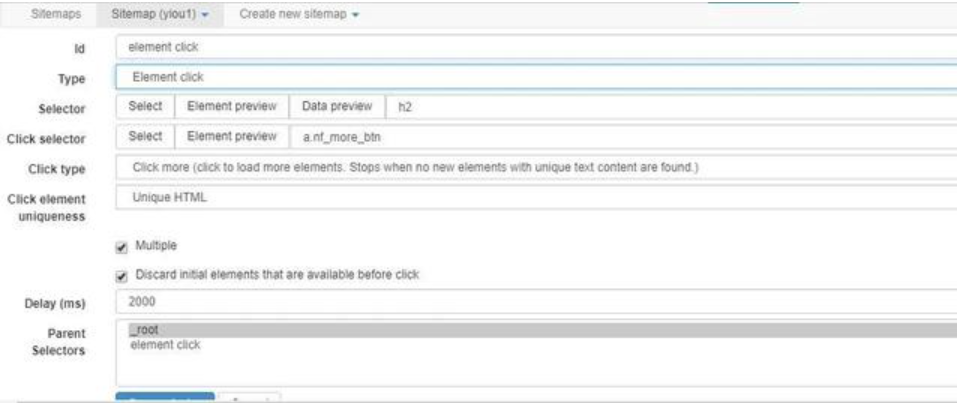
与滚动加载场景一样,我们在一级selector设置element click 的选择器,配置内容如下:
id:选择器名称
type:选择elements click
selector:选择需要抓取的元素,与之前设置方式一致,选择元素即可
click selector:这里选择查看更多的元素,也即我们点击加载按钮的元素。
click type:一种为click once,即同一个按钮只点击一次,一种为click more,同一个按钮可点击多次,直到按钮发生变化为止。这里我们选择click more,因为需要不断点击查看更多来获取更多数据。
click element uniqueness:判定是否同一按钮的条件,主要用于停止条件的判定,有以下四种类型可选择:
Unique Text - 有同样文本内容的按钮被视为同一按钮
Unique HTML+Text - 有同样 HTML 和文本内容的按钮被视为同一按钮
Unique HTML - 有同样 HTML 的按钮被视为同一按钮
Unique CSS Selector - 有同样 CSS 选择器的按钮被视为同一按钮
Discard initial elements(忽略初始元素)- 选择器不会选中在第一次点击按钮前就已经存在的元素。用在去重的场景
Delay:这里需要按照实际情况配置,如果等待加载的时间配置过短,很容易造成抓取不到数据的情况。
配置完click selector过后,接着在其二级子selector继续配置想要抓取的数据即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号