2022.6.6 java二面 - 面试题记录
1.如何衡量一个算法的稳定性?
答:如果在一个待排序的序列中,存在2个相等的数,在排序后这2个数的相对位置保持不变,那么该排序算法就是稳定的,否则是不稳定的。
2.如何衡量一个算法的好坏,可以从哪些维度分析?
答:时间复杂度,空间复杂度,还有算法的稳定性*。
3*.手写快速排序算法
答:暂时略
4.jdk中对 int[] 数组是怎么排序的?如何说数据规模很大的话,有没有采取另外别的方式呢?
5.数据量很大(上千万,上亿),如何快速找到一个指定的数?
暂未解决
6.java有内置的二分查找的api吗?如果有的话,是哪个(些)?
答:Arrays.binarySearch()
7.Java中的Map如何保证插入的顺序?
答:*如果是保证插入键的顺序,那么可以使用TreeMap。
9.有用过TreeSet吗?如何用TreeSet对Student对象的score字段排序?
10.假设有一个int型的count变量,它被多个线程同时访问(生产者,消费者,包括读取跟写入),那么可以通过哪些方式保证count变量的线程安全性(兼顾性能)?
12.如何防止内存泄漏?
答:
1)生命周期长的容器
这类容器,包括static字段容器,也包括声明在spring里面的bean的字段容器。由于生命周期长,如果put/remove不对称,就会产生内存泄露。如果容器大小到确定值不会再增长,就不存在泄露。
预防方法:在调用了put方法后,一定要确保有remove操作。要注意:如果在remove之前可能抛出异常,则一定要使用try…catch…finally语句来确保remove成功。
2) 未关闭的流
未关闭的网络流和文件流,会占用内存。如果存在大量的未关闭流,就会出现内存泄露。
预防办法:使用try-with-resources语法
13.对于资源型的,要如何关闭?(除了在try... finally...中的finally中关闭外)
答:使用try-with-resources
14.在生产环境运行的项目,24小时内页面一直没反应,你如何排查?
15.CPU 100% 如何定位?
答:
1)如果是window环境,使用任务管理器查看进程。
2)如果是Linux系统,那么可以使用top命令。
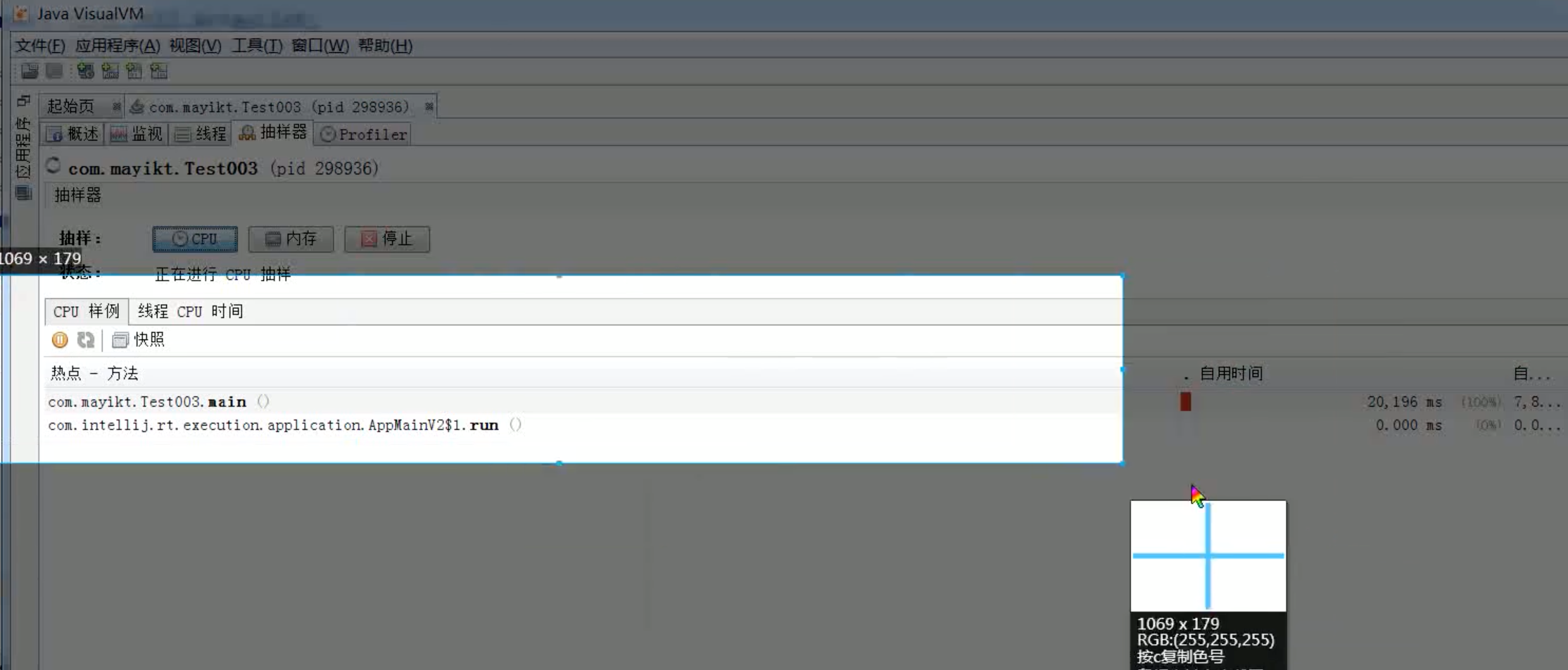
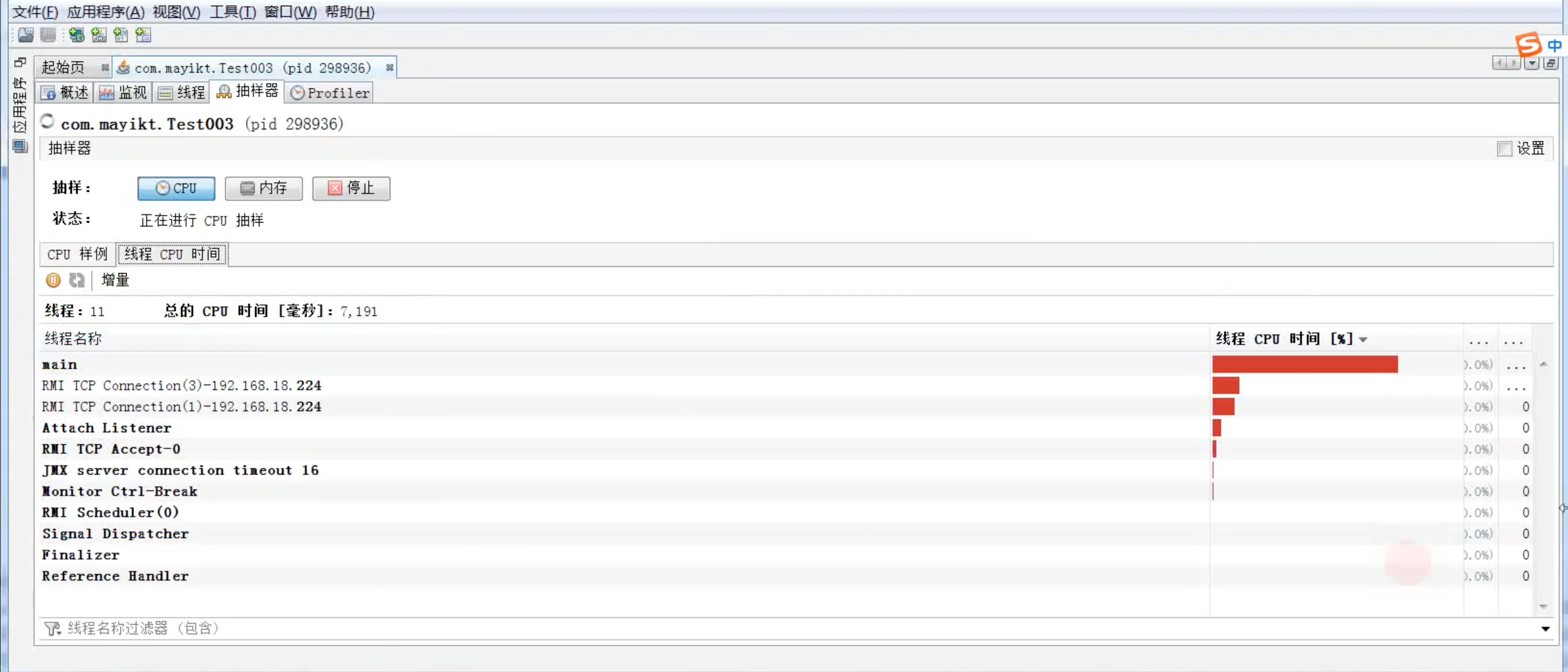
3)如果是Java进程的话,还可以使用JVisualVM来排查:通过该工具可以连到某台主机(本机或其他机器(ip, port))。
之后就可以看到相关的jvm进程信息,并且可以通过里面的控制面板的一些操作,可以看到cpu占用的一些信息等等。
该工具里面有一个抽样器,可以点击对它进行CPU抽样或者内存抽样,之后我们就可以看到一些信息,对于CPU抽样,可以看到最耗时的方法信息(是哪个全限定名类下的方法)以及线程的
CPU时间(是哪个具体的线程,显示的是线程的名称)。通过这样的话,我们就能根据方法跟线程去到项目代码里面,再去进一步定位排查我们的问题。通过该工具的话,能确定的东西并不是直接确定原因,而是确定问题发生在哪里。
>>> 分析cpu原因的话,首先看线程。
16.对于数据库表设计的范式的了解,以及一些注意事项。
17.单张表数据量很大,怎么处理?
*答:
1、读写分离
读写分离,将数据库的读写操作分开,比如让性能比较好的服务器去做写操作,性能一般的服务器做读操作。写入或更新操作频繁可以借助MQ,进行顺序写入或更新。
2、分库分表
分库分表是最常规有效的一种大数据解决方案。垂直拆分表,例如将表的大文本字段分离出来,成为独立的新表。水平拆分表,可以按时间,根据实际情况一个月或季度创建一个表,另外还可以按类型拆分。单表拆分数据应控制在1000万以内。分库分表后要注意对SQL语句的支持,稍不小心,可能就会造成业务数据混乱等问题。
3、数据缓存
使用缓存技术降低对数据库直接访问的压力,比如使用Redis内存数据库存储热点数据,全量缓存内存占用太大,所以要识别出热点数据进行缓存,比用用户信息表,可以考虑缓存一段时间内的活跃用户。但是使用服务缓存也有缺点,最常见的问题就是“击穿”,假如缓存都失效了,这时候并发请求都去访问MySQL,此时可能造成服务器挂掉,这个时候为了避免这种情况,一般都是使用互斥量来解决这种问题。
4、SQL语句优化,尽量避免联表查询,避免递归等消耗性能的语句。表设计优化,例如单表字段不宜过多,时间类型使用TIMESTAMP,字段尽量避免NULL等。索引优化,合理创建索引,索引不是越多越好,也不是所有的字段都适合建立索引。
18.对数据仓库有了解吗?
答:数据仓库,英文名称Data Warehouse,简写为DW。数据仓库顾名思义,是一个很大的数据存储集合,出于企业的分析性报告和决策支持目的而创建,对多样的业务数据进行筛选与整合。它为企业提供一定的BI(商业智能)能力,指导业务流程改进、监视时间、成本、质量以及控制。
数据仓库的输入方是各种各样的数据源,最终的输出用于企业的数据分析、数据挖掘、数据报表等方向。
附图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号