

HashMap
HashMap:
1.底层由数组,链表组成。jdk1.8以后加入了红黑树。(目的是为了降低深度)
2.以键值对的方式存储,存储是无序的。允许使用多个null值和一个null键。
3.默认长度是16,扩容因子是0.75,每次扩容2倍。



至于为什么扩容两倍,就要从如何存储说起。每当put一个entry时,要先通过key的hashcode值来判断存放数组的下标,那么为了降低存放同一个位置的概率必须设计一定的算法。正如我们想到的可以使用取余的算法
如:hashcode%16
这无疑是可行的,但是在计算机中,位运算可以达到同样的效果且效率更高,所以采用这种方式,即每次扩容必须为2的指数次幂。

4.链表长度大于等于8时(一般不会达到这种情况,官方给出了测试数据),且数组长度大于64,会自动转化为红黑树结构。如果数组长度小于64则会先进行扩容,因为红黑树的转化以及保持平衡是有代价的,而且当数组太小时,很容易引发扩容,又会涉及到树转换为链表,这显然是不合适的。当链表长度小于等于6时,会自动转为链表结构。
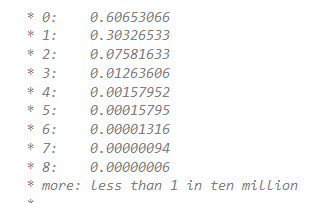
在同一个链表下出现次数的概率:
在添加键值对的时候会进行判断,是否达到链表转化红黑树的条件:
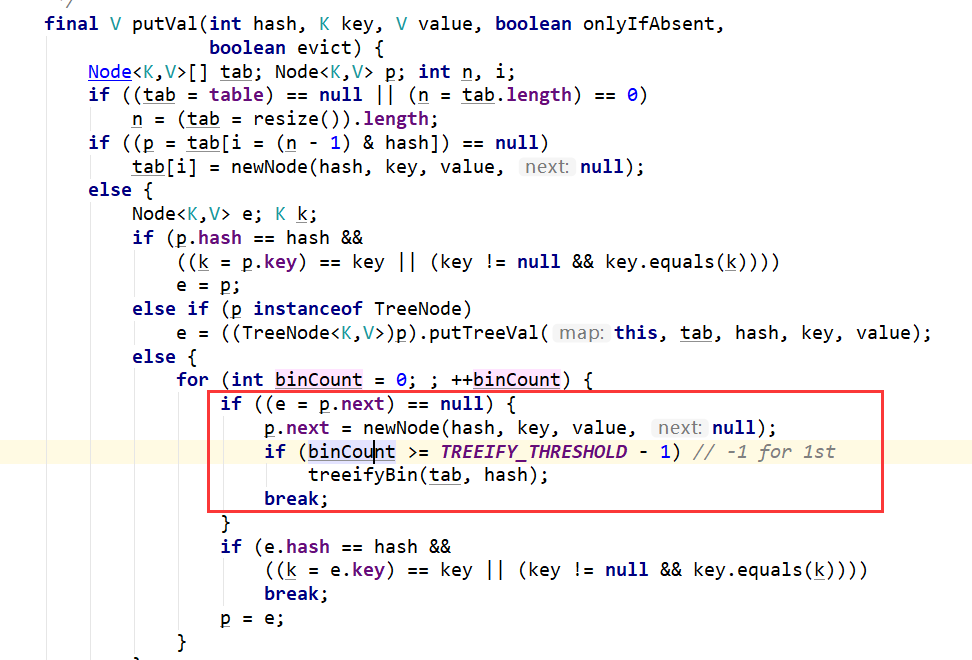

至于为什么要加入红黑树:因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。而且中间的7可以起到保护,过度的作用,避免频繁在该区间增删导致性能下降。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号