


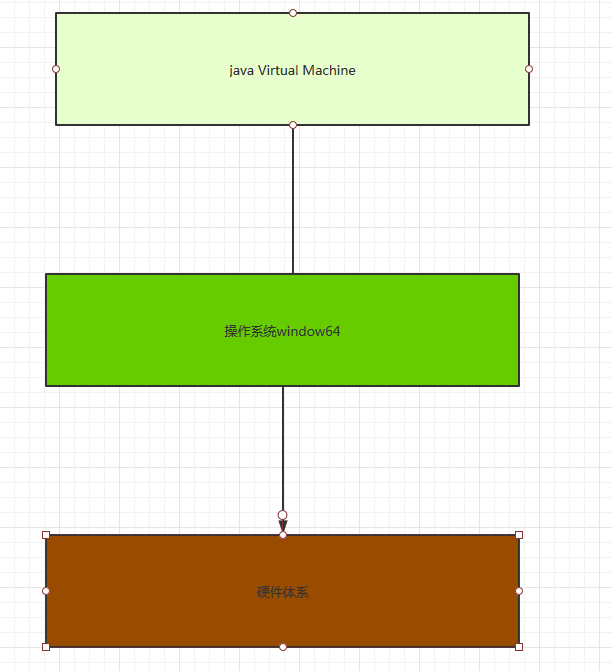
1 jvm 是面向的是操作系统的而不是直接面向硬件的。
启动类加载器BootStarp,BootStrap是根加载器,使用的是c
Extension Class Loader 使用的扩展类加载器 加载ext下的包
应用程序类加载器,也叫系统加载器,加载当前classpath所有类。
这里使用了双亲委派机制和沙箱安全机制 。
双亲委派机制就是先让上层的父类去加载,如果没有找到在加载自己的系统。
沙箱安全机制如果写了jdk的代码 那么不让jdk代码使用者篡改。
Java栈
栈可以理解成手枪的弹夹,先进后出。每一方法都是一个栈帧,每一个栈帧又包含了局部变量表,操作性栈,帧数据区 。
局部变量表 主要是一些变量
操作性栈 存储的是压栈和弹栈
帧数据区主要是一些数据的存储
栈也叫栈内存,主管java程序的运行,是在线程创建的时候开始,生命周期随着整个线程同步,垃圾回收不用去清理栈。
栈里面主要的存储有8种基本数据类型,对象的引用变量,实例方法。
运行时数据区
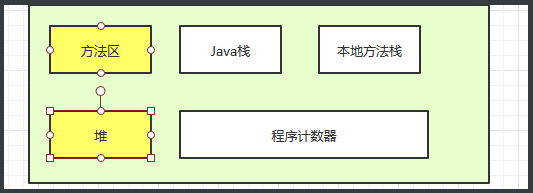
方法区 和堆会被gc回收
方法区是被所有线程共享,此区域是共享区域,会存储 静态变量 常量 类信息,接口定义 运行时常连池
这里面的局部变量是在java栈的 局部变量表中存储的
本地方法栈 是用来操作nactive方法 是用c操作的。
程序计数器 是每一个线程独有的,指向的是当前运行的指针,当此方法结束后,会指向下一个指针的操作。
堆
逻辑上分成了 年轻带 老年代 元空间
新生成则进入伊甸园区,没被回收进入幸存区,在存在直接进入老年代,如果文件较大直接进入老年代。
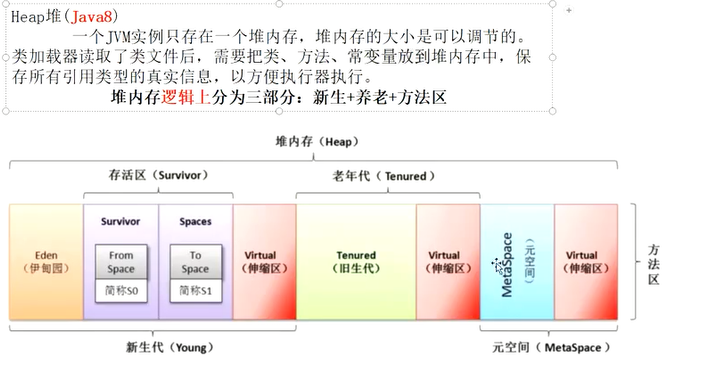
方法区和元空间得联系是什么?
物理上理解可以把元空间理解成方法区的现实。
什么是垃圾?
垃圾就是失去了引用。在堆内存中或者方法区无人使用了,通过gc清理。
gc的清除的算法?
1 Mark-Sweep(标记清除) 看到 不使用的直接清除掉 这种 不好处碎片化比较多
2 Copying(拷贝)分一半进行切割,把好用的copy过来 这种耗费内存
3 Mark-compat(标记压缩) ,一边清楚,一半用可用内存进行顶替上 ,这种效率低,但不浪费 是比较好的方法
StringTable
常量池的字符串 仅仅时符号,只有当第一次使用的时候才会变成对象 字符串常量拼接的原理是编译期优化的
通过使用itern的方法将字符串放入串池中。如果串池中有该字符串那么则不用创建,如果没有 则创建,并返回当前串池的引用
StringTable的位置
在1.8中是在堆内存中,这样有利于垃圾回收,不需要全gc 就可以在堆中回收。
参数设置:-XX:PrintStringTableStatistics // 打印串池详情 -XX:PrintGCDetails - verbose:gc // 打印详情
StringTable性能调优
StringTable 可以理解成 类似hash ,因为每次去创建的时候,都会区寻找单独唯一的hash值,所以创建的时候越大 越方便让串池的hash更快返回。
参数:
-XX:PrintStringTableStatistics // 打印串池 -XX:StringTableSize=2000 / 设置大小
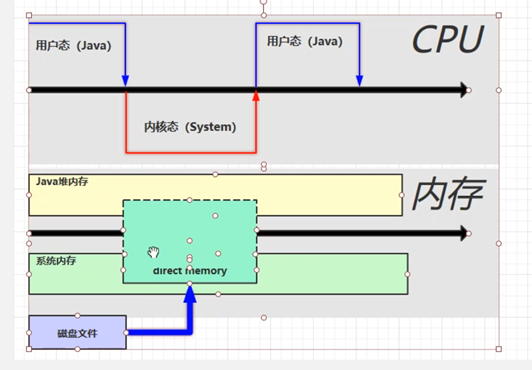
直接内存
直接内存不是java的内存,而是操作系统本身的内存。
直接内存主要是nio 操作得byteBuffer
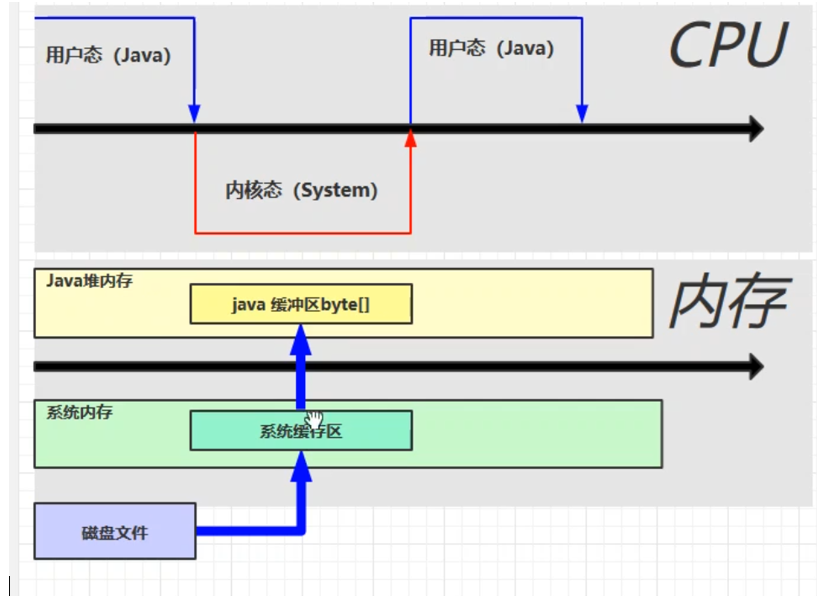
java先调用一个内核态 然后内核操作操作系统,操作系统把数据写入到系统的缓存区 ,在写像java的缓存区,在一点点读。 因为java 只能读取 java 缓冲区的数据 而无法读取 系统缓冲区的数据 。
By'te'Buffer.allocateDirecr() 是采用的直接分配,jva可以直接读取到该区域分配的数据 。
GC 快照实例 创建
通过jmap方式来创建实时的内存快照
jmap -dump:format=b,live,file=2.bin 进程号 live 执行的时候会主动触发一次垃圾回收
Java中的四种引用 ?
强,软,弱,虚。
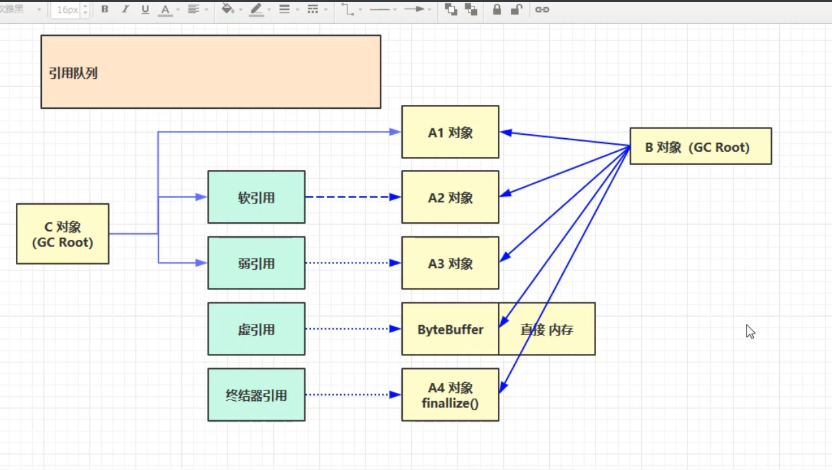
强引用 的时候不会被垃圾回收
软引用 当内存满了的时候而且软引用没有硬引用的时候 就会被垃圾回收给回收掉。
弱引用 只要发生了垃圾回收,只要没有其他的硬引用就可以把他回收掉。
虚引用
虚引用要配合引用队列使用,虚引用创建时 对应的对象,在被回收的时候 让他进入回收对象,然后在引用队列中 通过
一个系统后台自带的定时任务,调用释放功能。列入byetBuffer.
终结器引用
终结器引用,所有的java类继承了Object ,object 中还有一个finlize(),当对象重写了finalize的方法,这个时候就可以当成垃圾被回收,那么终结方法什么时候被回收,通过终结器引用,没有强引用,通过虚拟机创建,把终结器引用加入到对应的引用队列,通过finalize()结束回收。
相关参数
堆初始大小
-Xms
堆最大大小
-Xmx或-XX:MaxHeapSige size
新生代大小
-Xmn或(-XX.NewSize- size + -XX:MaxNewSize size )
幸存区比例(动态)
-XX:InitialSurvivorRatio=ratio 和-XX:+UseAdaptiveSizePolicy // 动态调整 比例 正常1:1:8
幸存区比例
-XX:SurvivorRatio=ratio
晋升阈值
-XX:MaxTenuringThreshold- threshold // 新生带到老年代 的等级数
晋升详情
XX:+PrintTenuringDistribution // 打印晋升的详情
GC详情
-Xx:+PrintGCDetails -verbose:gc // 打印详情信息
FullGC前MinorGC
-XX:+ScavengeBeforeFulIGC //fullGc之前 进行一次minorGC 加速进度。
GC 大对象
大对象直接存储在老年代
垃圾回收器
1 串行的垃圾回收器
2 吞吐量优先的 垃圾回收的时间占程序的占比
3 响应时间优先 让垃圾回收 stopTheWorld 变短。
4.1串行垃圾回收器
-XX:UseSerialGC =Serial + SerialOld Serial 采用的是复制算法 SerialOdl 是标记加整理
1.8下默认的
ParallelGC 并行的垃圾回收器 ,复制算法 OldGC 标记+整理算法
老年代标记整理算法,只要开启其中一个另外一个也会自动开启 ,垃圾回收器会开启多个线程。和cpu的核数有关。
-XX: +UseAdaptiveSizePolicy 调正自适应的新生代
响应时间优先的
用户线程和线程并发执行的
CMS 工作在老年代的 与之配合的是ParNewGC 复制算法 当发生 异常的时候 会使用SerialOld
1 初始标记 stw 一次 标记根对象
2 用户线程并发执行与此同时去寻找对应的标记处理
3 从新标记 stw一下 会有新的垃圾产生
4 继续执行
G1 是标记整理算法 而cms是 标记清除算法
1.8 不是默认的 1.9之后就是默认的了
并发标记 在老年代百分之45的时候 进行并发标记 老年代也使用了复制算法 根据最大的暂停时间 有选择进行 复制 ,找到回收价值比较高的 进行处理 。
在新生带的时候进行初始标记 ,当老年代占用的一定空间比列的时候 进行并发标记 。 并发标记不会影响线程的运行 不会stw 老年代占用 整个空间的 45%
混合收集 老年代 采用了复制算法 优先收集 垃圾多的地方 主要目的达到 最大化收集 ,
G1 就是当 产生的垃圾跟不上并发垃圾收集的时候 就会退化串行gc ,然后调用了fullGC.
老年代引用新生带的时候 这个时候老年代创建了一个卡表,然后通过卡表里的每一个 512字节 和新生代 去匹配匹配上了 就是脏卡
对G1 增强 并发标记的类卸载 之前是无法卸载的尤其是一些自定义的类或者加载器 ,对垃圾回收也是不利的,会存在类卸载的机制 ,类所在的类加载器 都不会使用 ,
把所有的类全部去掉 对于框架程序都是自定义程序,一个类加载器和一个类全部没人用都可以卸载掉 。
G1 回收巨型对象 一个对象大于Region的一半的时候 就可以称之为巨型对象,G1 不会拷贝巨型对象,当发生年轻代GC的时候会被优先回收掉,前提是没有引用了。
巨型对象 在卡表为0 的时候 年轻代就可以回收 就是没有了引用就可以回收了,在新生带就可以回收了



 浙公网安备 33010602011771号
浙公网安备 33010602011771号