【论文阅读】SuperGlue: Learning Feature Matching with Graph Neural Networks 特征匹配 2020 CVPR
title: SuperGlue: Learning Feature Matching with Graph Neural Networks date: 2023-11-27 14:07:17 tags: 论文精读
|
作者 |
Paul-Edouard Sarlin1∗ Daniel DeTone2 Tomasz Malisiewicz2 Andrew Rabinovich2 |
|
单位 |
ETH Zurich 2 Magic Leap, Inc. |
|
代码 |
https://github.com/magicleap/SuperGluePretrainedNetwork |
|
期刊/会议 |
CVPR |
|
关键词 |
2020 |
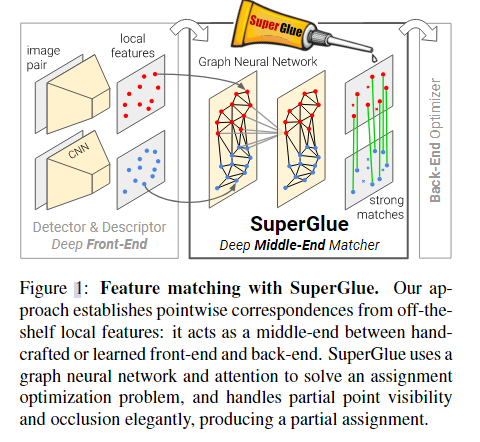
0.摘要
- 问题:
- 工作内容:
本文介绍了 SuperGlue,这是一种通过联合查找对应关系和拒绝不匹配点来匹配两组局部特征的神经网络。匹配是通过解决可微最优传输问题来估计的,该问题的成本由图神经网络预测。我们引入了一种基于注意力的灵活上下文聚合机制,使 SuperGlue 能够联合推理底层 3D 场景和特征分配。与传统的手工设计的启发式方法相比,我们的技术通过图像对的端到端训练来学习 3D 世界的几何变换和规律的先验。
- 效果:
SuperGlue 优于其他学习方法,在具有挑战性的现实世界室内和室外环境中在姿态估计任务中取得了最先进的结果。该方法在现代GPU上实时执行匹配,可以很容易地集成到现代SfM或SLAM系统中。
1. Introduction
2. Related Work
Local feature matching
Graph matching
Deep learning for sets
3. The SuperGlue Architecture
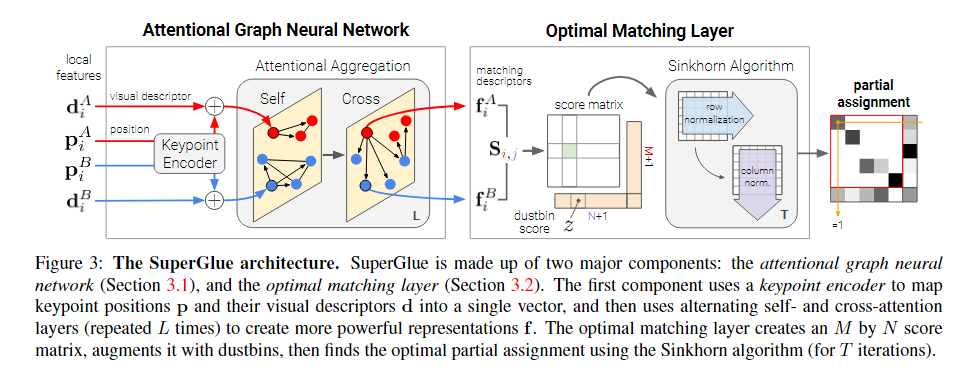
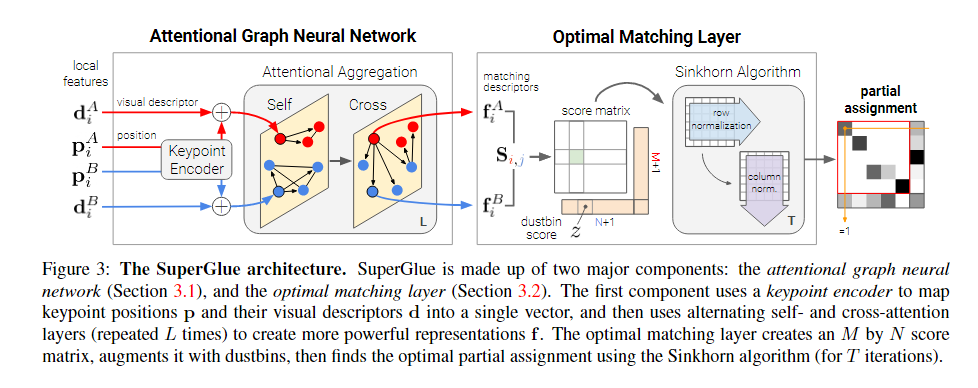
3.0.1 Motivation
在图像匹配问题中,可以利用世界的一些规律:3D世界在很大程度上是平滑的,有时是平面的,如果场景是静态的,则给定图像对的所有对应关系都来自单个极线变换,并且某些姿势比其他姿势更有可能。
此外,2D关键点通常是显著3D点的投影,如角点或斑点,因此图像之间的对应关系必须遵守某些物理约束:
- i ) 关键点在另一幅图像中最多只能具有单个对应关系;
- ii ) 由于检测器的遮挡和故障,一些关键点将不匹配。
特征匹配的有效模型应该旨在找到相同 3D 点的重投影和识别没有匹配的关键点之间的所有对应关系。我们将 SuperGlue(见图 3)制定为解决优化问题,其成本由深度神经网络预测。这减轻了对领域专业知识和启发式的需求——我们直接从数据中学习相关先验。
3.0.2 Formulation
考虑两个图像 A 和 B,每个图像都有一组关键点位置 p 和相关的视觉描述符d——我们将它们联合 (p, d) 称为局部特征。位置由 x 和 y 图像坐标以及检测置信度 c、pi := (x, y, c)i 组成。视觉描述符di∈RD可以是像SuperPoint这样的CNN提取的描述符或传统的描述符,如SIFT。图像 A 和 B 有 M 和 N 个局部特征,由 A := {1, ..., M } 和 B := {1,..., N },分别表示。
3.0.3 Partial Assignment
约束 i) 和 ii) 意味着对应关系源自两组关键点之间的部分分配。对于集成到下游任务和可解释性更好,每个可能的对应关系都应该有一个置信度值。因此,我们将部分软分配矩阵 P ∈ [0, 1]M ×N 定义为:
![]()
我们的目标是设计一个神经网络,从两组局部特征中预测分配 P。
3.1. Attentional Graph Neural Network
除了关键点的位置及其视觉外观外,整合其他上下文线索可以直观地增加其独特性。例如,我们可以将其空间和视觉关系与其他共可见关键点联系起来,例如显著[29]、自相似[48]、统计共发生[65]或相邻关键点[52]。另一方面,第二幅图像中关键点的知识可以通过比较候选匹配或从全局和明确的线索估计相对光度或几何变换来帮助解决歧义。
当被要求匹配给定的模糊关键点时,人类在两个图像上来回看:他们筛选试探性匹配关键点,检查每个关键点,并寻找有助于消除与其他自相似性的真实匹配的歧义的上下文线索[10]。这暗示了一个迭代过程,可以将注意力集中在特定位置。
因此,我们将SuperGlue的第一个主要块设计为注意图神经网络(见图3)。给定初始局部特征,它通过让特征相互通信来计算匹配描述符 fi ∈ RD。正如我们将展示的那样,图像内部和跨图像的远程特征聚合对于鲁棒匹配至关重要
3.1.1 Keypoint Encoder 关键点编码器:
每个关键点 i 的初始表示 (0)xi 结合了其视觉外观和位置。我们将关键点位置嵌入到具有多层感知器 (MLP) 的高维向量中,如下所示:
![]()
该编码器使图网络能够稍后联合推理外观和位置,尤其是在与注意力相结合时,并且是语言处理中流行的“位置编码器”的一个实例 [20, 55]。
3.1.2 Multiplex Graph Neural Network: 多视角图神经网络:
我们考虑一个单一的完整图,其节点是两个图像的关键点。该图有两种类型的无向边——它是一个多路图[31,33]。图像内边或自边Eself,将关键点i连接到同一图像中的所有其他关键点。图像间边或交叉边Ecross将关键点i连接到另一幅图像中的所有关键点。我们使用消息传递公式 [21, 3] 沿两种类型的边传播信息。生成的多路图神经网络从每个节点的高维状态开始,并通过同时聚合所有节点的所有给定边的消息来计算每一层的更新表示。
设(ℓ)xA i为第ℓ层图像A中元素i的中间表示。消息 mE→i 是从所有关键点 {j : (i, j) ∈ E} 聚合的结果,其中 E ∈ {Eself, Ecross}。A中所有 i 的残差消息传递更新为:
![]()
其中 [· || ·] 表示连接。可以对图像 B 中的所有关键点同时执行类似的更新。固定数量的具有不同参数的层 L 被链接并沿自边和交叉边交替聚合。因此,从ℓ=1开始,如果ℓ是奇数,则E=Eself,如果ℓ是偶数,则E=Ecross。
3.1.3 Attentional Aggregation 注意聚合:
注意力机制执行聚合并计算消息 mE→i。Self edge 基于 self-attention [55],cross edge 基于交叉注意力。与数据库检索类似,i 的表示,query查询 qi,根据它们的属性(key键 kj)检索某些元素的values值 vj。消息被计算为值的加权平均值:
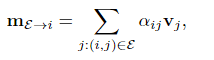
其中注意力权重 αij 是key-query相似度上的 Softmax:αij = Softmaxj(q⊤i kj)。密钥key、query查询和values值被计算为图神经网络的深层特征的线性投影。考虑到query查询关键点i在图像Q中,并且所有源关键点都在图像S中,(Q,S)∈{A,B}2,我们可以写
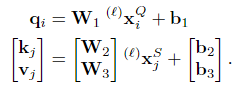
每层ℓ 具有针对两个图像的所有关键点学习和共享的自己的投影参数。在实践中,我们通过多头注意力来提高表现力[55]。
我们的公式提供了最大的灵活性,因为网络可以学习基于特定属性的关键点子集(见图4)。SuperGlue可以根据外观和关键点位置来检索或参与,因为它们在表示xi中编码。这包括关注附近的关键点并检索相关相似或显著关键点的位置。这样可以表示几何变换和赋值。最终的匹配描述符是线性投影:
![]()
类似地,对于B中的关键点
3.2. Optimal matching layer
SuperGlue的第二个主要块(见图3)是最佳匹配层,它产生一个部分分配矩阵。与标准图匹配公式一样,赋值P可以通过计算所有可能匹配的得分矩阵S∈RM×N,并在等式1的约束下最大化总分∑i,j Si,j Pi,j来获得。这相当于求解线性分配问题。
3.2.1 Score Prediction 分数预测:
为所有M×N的潜在匹配建立一个单独的表示是令人望而却步的。相反,我们将成对得分表示为匹配描述符的相似性:
![]()
其中<·,·>是内积。与学习的视觉描述符相反,匹配描述符不是归一化的,并且它们的幅度可以在每个特征和训练期间变化,以反映预测置信度。
3.2.2 Occlusion and Visibility: 遮挡和可见性:
为了让网络抑制一些关键点,我们用一个垃圾箱来增加每个集合,以便将不匹配的关键点显式分配给它。这种技术在图匹配中很常见,SuperPoint[16]也使用垃圾箱来解释可能没有检测到的图像单元。我们通过添加一个新行和列,即点到bin和bin到bin的分数,将分数S增加到̄S,并填充一个可学习的参数:
![]()
虽然 A 中的关键点将分配给 B 中的单个关键点或dustbins ,但每个dustbins 的匹配度与另一组中的关键点相同:A、B 中dustbins 的 N、M。我们将 a = [1⊤M N ]⊤ 和 b = [1⊤N M ]⊤ 表示 A 和 B 中每个关键点和dustbins 的预期匹配数。增强分配 ̄P 现在有约束
![]()
3.2.3Sinkhorn算法:
上述优化问题的解对应于离散分布a和b之间的最优传输[36],分数为̄S。它的熵正则化公式自然会导致所需的软分配,并且可以在GPU上高效地求解,通过使用Sinkhorn算法[49,11]。它是匈牙利算法[32]的可微版本,通常用于二部匹配,它包括沿行和列迭代归一化exp(̄S),类似于行和列Softmax。经过T次迭代,我们去掉垃圾箱,恢复P =̄P1:M,1:N。
3.3. Loss
通过设计,图神经网络和最优匹配层都是可微的——这使得从匹配到视觉描述符的反向传播成为可能。SuperGlue 以监督方式从地面实况匹配 M = {(i, j)} ⊂ A × B 进行训练。这些是从地面实况相对转换估计的——使用姿势和深度图或单应性。这也让我们标记一些关键点 I ⊆ A 和 J ⊆ B 不匹配,如果它们在其附近没有任何重投影。给定这些标签,我们最小化分配 ̄P 的负对数似然:
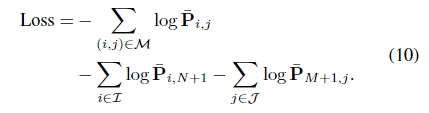
这种监督旨在同时最大化匹配的精度和召回率。
3.4. 与相关工作的比较
SuperGlue架构与图像内关键点的排列等变。与其他手工制作或学习方法不同,它也与图像的排列等变,这更好地反映了问题的对称性,并提供了有益的归纳偏差。此外,最优传输公式强制匹配的互惠,如相互检查,但以类似于[43]的软方式,因此将其嵌入到训练过程中。
SuperGlue 与实例归一化 [54]:
SuperGlue 使用的注意力是一种比实例归一化更灵活和更强大的上下文聚合机制,它平等地对待所有关键点,正如先前关于特征匹配的工作所使用的那样 [30, 63, 29, 41, 6]。
SuperGlue 与 ContextDesc [29]:
SuperGlue 可以联合推理外观和位置,而 ContextDesc 分别处理它们。此外,ContextDesc 是一个前端,它还需要更大的区域提取器,以及关键点评分的损失。SuperGlue 只需要局部特征、学习或手工制作的,因此可以对现有匹配器进行简单的替换。
SuperGlue vs. Transformer[55]:
SuperGlue借鉴了Transformer的自我注意,但将其嵌入到图神经网络中,并额外引入了对称交叉注意。这简化了架构并导致跨层更好的特征重用。
5. Experiments
6. Conclusion
本文展示了基于注意力的图神经网络在局部特征匹配方面的能力。SuperGlue 的架构使用了两种注意力:(i)自注意力,它提高了局部描述符的感受野,以及(ii)交叉注意力,可以实现跨图像通信,并受到人类在匹配图像时来回看的方式的启发。我们的方法通过求解最优传输问题优雅地处理部分分配和遮挡点。我们的实验表明,SuperGlue 与现有方法相比取得了显着的改进,能够在极端宽基线室内和室外图像对上实现高精度的相对姿态估计。此外,SuperGlue 实时运行,并且可以很好地处理经典和学习特征。总之,我们可学习的中间端用一个强大的神经模型取代了手工制作的启发式方法,该模型在单个统一的架构中同时执行上下文聚合、匹配和过滤。我们相信,当结合深度前端时,SuperGlue 是端到端深度 SLAM 的主要里程碑。
------------
参考: 1.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号