【论文阅读】LightGlue: Local Feature Matching at Light Speed 2023
title: LightGlue: Local Feature Matching at Light Speed date: 2023-11-23 21:40:48 tags: 论文精读 轻量级 特征匹配
|
作者 |
Philipp Lindenberger1 Paul-Edouard Sarlin1 Marc Pollefeys1, |
|
单位 |
1 ETH Zurich 2 Microsoft Mixed Reality & AI Lab |
|
代码 |
https://github.com/cvg/LightGlue |
|
期刊/会议 |
ICCV 2023 |
|
关键词 |
2023 |
0.摘要
- 问题:
- 工作内容:
我们引入了LightGlue,这是一种深度神经网络,它学习匹配图像之间的局部特征。我们重新审视了SuperGlue的多个设计决策,即稀疏匹配的最新技术,并得出了简单但有效的改进。
- 效果:
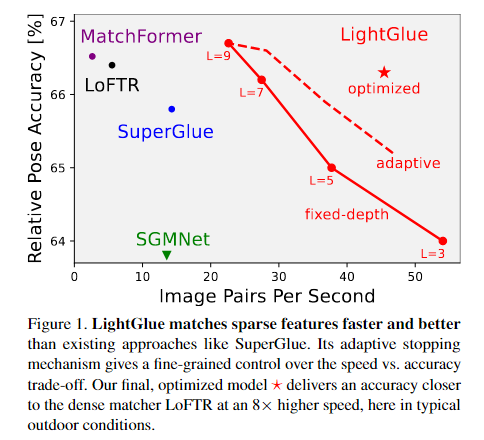
累积起来,他们在内存和计算方面使 LightGlue 更有效,更准确,更容易训练。一个关键的特性是LightGlue适应问题的难度:在直观上容易匹配的图像对上,推理要快得多,例如由于更大的视觉重叠或有限的外观变化。这为在诸如 3D 重建之类的延迟敏感应用中部署深度匹配器开辟了令人兴奋的前景。
1. Introduction
与以前的方法不同,LightGlue 适应每个图像对的难度,这因视觉重叠量、外观变化或判别信息。图 2 显示,在直觉上比具有挑战性的匹配对上的推理要快得多,这种行为让人想起人类如何处理视觉信息。这是通过 1) 在每个计算块之后预测一组对应关系,以及 2) 使模型能够引入它们并预测是否需要进一步计算来实现的。LigthGlue 还丢弃了无法匹配的早期阶段点,从而将注意力集中在共可见区域。
我们的实验表明,LightGlue 是 SuperGlue 的即插即用替代品:它在运行时的一小部分从两组局部特征预测强匹配。这为在SLAM[45,5]等延迟敏感应用中部署深度匹配器或从众包数据中重建更大的场景开辟了令人兴奋的前景[25,60,39,57]。
2. Related Work
3. Fast feature matching
问题表述:LightGlue 根据 SuperGlue 在 SuperGlue 之后预测从图像 A 和 B 中提取的两组局部特征之间的部分分配。
每个局部特征 i 由 2D 点位置 pi := (x, y)i ∈ [0, 1]2 组成,由图像大小归一化,视觉描述符 di ∈ Rd。图像 A 和 B 有 M 和 N 个局部特征,由 A := {1, ..., M } 和 B := {1,..., N },分别。
我们设计了LightGlue输出一组对应关系M = {(i, j)}⊂A × B。每个点至少匹配一次,因为它源于一个唯一的 3D 点,并且由于遮挡或非可重复性,一些关键点是不可匹配的。与之前的工作一样,我们在 A 和 B 中的局部特征之间寻求软部分分配矩阵 P ∈ [0, 1]M ×N,我们可以从中提取对应关系。
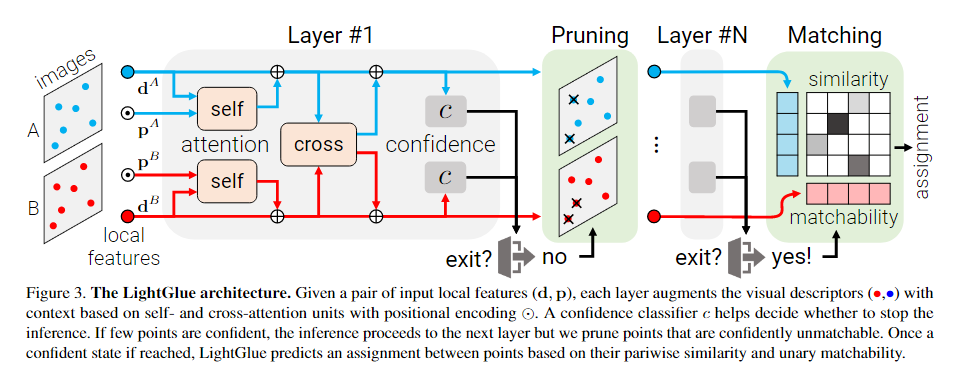
概述——图 3:LightGlue 由一堆 L 个相同的层组成,这些层联合处理两组。每一层都由更新每个点的表示的自我注意单元和交叉注意单元组成。然后,分类器在每一层决定是否停止推理,从而避免不必要的计算。轻量级头部最终从表示集中计算部分分配。
3.1. Transformer backbone
我们将图像 I ∈ {A, B} 中的每个局部特征 i 与状态 xi i ∈ Rd 相关联。状态初始化为对应的视觉描述符 xI i ← dI i 并随后由每一层更新。我们将一层定义为一系列自注意力和一个交叉注意力单元
注意力单元:在每个单元中,多层感知器 (MLP) 更新给定从源图像 S ∈ {A, B} 聚合的消息 mI←S i 的状态
![]()
其中 [· | ·] 堆叠两个向量。这是并行计算两个图像中所有点。在自注意力单元中,每个图像 I 从同一图像的点中提取信息,因此 S = I。在交叉注意力单元中,每个图像从其他图像中提取信息,S = {A, B}\I。
该消息由注意力机制计算为图像 S 的所有状态 j 的加权平均值:
![]()
其中 W 是投影矩阵,ai ij 是图像 I 和 S 的点 i 和 j 之间的注意力分数。对于自注意力和交叉注意力单元,如何计算此分数。
Self-attention:每个点关注同一图像的所有点。我们对每个图像 I 执行相同的以下步骤,为了清楚起见,我们删除了上标 I。对于每个点 i,首先通过不同的线性变换将当前状态 xi 分解为键向量和查询向量 ki 和 qi。然后,我们将点 i 和 j 之间的注意力分数定义为
![]()
其中R(·)∈Rd×d是点之间相对位置的旋转编码[67]。我们将空间划分为 d/22D 子空间,并将它们中的每一个旋转一个角度对应,遵循傅里叶特征 [37],到投影在学习的基bk∈R2上
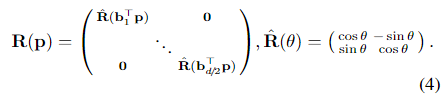
位置编码是注意力的关键部分,因为它允许根据它们的位置解决不同的元素。我们注意到,在投影相机几何中,视觉观测的位置是等变的,w.r.t.图像平面内相机的平移:来自同一正面平行平面上的3D点的2D点以相同的方式平移,并且它们的相对距离保持不变。这需要一种仅捕获点的相对位置而不是绝对位置的编码。
旋转编码[67]使模型能够从i中检索位于学习相对位置的点j。位置编码不应用于值vj,因此不会溢出到状态xi中。所有层的编码都是相同的,因此计算一次和缓存。
Cross-attention交叉注意:I中的每个点都关注其他图像S的所有点。我们为每个元素计算一个键 ki,但没有查询。这允许将分数表示为
![]()
因此,我们需要为 I ← S 和 S ← I 消息仅计算一次相似度。这个技巧以前被称为双向注意[77]。由于这一步很昂贵,复杂度为 O(NMd),因此它节省了 2 的显着因子。我们不添加任何位置信息,因为相对位置在图像中没有意义。
3.2. Correspondence prediction
我们设计了一个轻量级的头,在给定任何层的更新状态的情况下预测分配。
【Assignment scores】分配分数:我们首先计算两幅图像点之间的成对得分矩阵 S ∈ RM ×N:
![]()
其中 Linear(·) 是具有偏差的学习线性变换。该分数编码了每对点对应的亲和力,即同一3D点的2D投影。我们还计算,对于每个点,匹配性分数为
![]()
该分数编码 i 具有对应点的可能性。另一幅图像中未检测到的点,例如遮挡时,不匹配,因此σi→0。
【Correspondences】对应:我们将相似性和可匹配性分数组合成一个软部分分配矩阵 P 作为
![]()
当两点被预测为可匹配时,一对点 (i, j) 产生对应关系,当它们的相似度高于两个图像中的任何其他点时。我们选择 Pij 大于阈值 τ 和沿其行和列任何其他元素的对。
3.3. Adaptive depth and width
我们添加了两种避免不必要的计算和节省推理时间的机制:i) 我们根据输入图像对的难度来减少层数; ii) 我们修剪在早期自信拒绝的点。
【Confidence classifier】置信度分类器:LightGlue 的主干使用上下文增强输入视觉描述符。如果图像对容易,即视觉重叠高,外观变化小,这些通常是可靠的。在这种情况下,来自早期层的预测是自信的,并且与后期层的预测相同。然后我们可以输出这些预测并停止推理。
在每层结束时,LightGlue 推断每个点的预测分配的置信度:
![]()
较高的值表示 i 的表示是可靠和最终的——它自信地匹配或不匹配。这受到成功地将这种策略应用于语言和视觉任务的多项工作的启发 [62, 20, 71, 80,40]。紧凑的 MLP 在最坏的情况下只增加了 2% 的推理时间,但大多数通常节省了更多的推理时
【Exit criterion】退出标准:对于给定的层ℓ,如果ci > λℓ,则认为一个点是自信的。如果所有点的充分比率 α 有信心,我们会停止推理
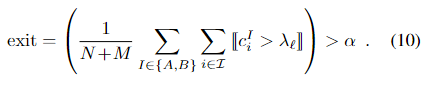
我们观察到,如 [62] 所示,分类器本身在早期层中不太有信心。因此,我们根据每个分类器的验证精度在整个层中衰减 λℓ。出口阈值 α 直接控制准确性和推理时间之间的权衡。
【Point pruning】点修剪:当不满足退出标准时,被预测为自信和不匹配的点不太可能帮助后续层中其他点的匹配。例如,这些点在图像中明显不可见的区域。因此,我们在每一层丢弃它们,并且只将剩余的点馈送到下一个点。考虑到注意力的二次复杂度,这显着减少了计算,不影响准确性。
3.4. Supervision
我们分两个阶段训练 LightGlue:我们首先对其进行训练以预测对应关系,然后才训练置信分类器。因此,后者不会影响最后一层的准确性或训练的收敛性。
【Correspondences】对应关系:我们监督具有从两个视图转换估计的基本真值标签的分配矩阵P。给定单应性或像素深度和相对姿态,我们将点从A变换到B,反之亦然。地面实况匹配M是在两个图像中具有低重投影误差和一致深度的点对。当一些点的重投影或深度误差与所有其他点足够大时,它们被标记为不可匹配。然后,我们最小化在每一层预测的分配的对数似然性ℓ, 推动LightGlue尽早预测正确的对应关系:
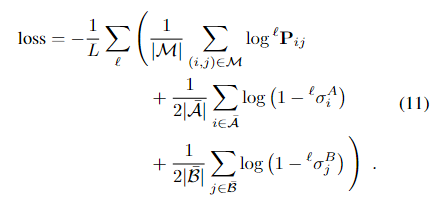
这种损失在正面和负面标签之间是平衡的。
【Confidence classifier】置信分类器:然后我们训练Eq.(9)的MLP来预测每一层的预测是否与最后一层相同。设l mA i∈B∪{•}是B中与i匹配的点在l层上的索引,当i不匹配时,l mA i =•。每个点的基真二标号为J∑mA i = LmA i K,对于b也是相同的。然后,我们将层∈{1,…L−1}。
3.5. Comparison with SuperGlue
LightGlue的灵感来自于SuperGlue,但在准确性、效率和易于培训的关键方面有所不同。
位置编码:SuperGlue用MLP编码绝对点位置,并将它们与描述符早期融合。我们观察到,模型往往会忘记这一点贯穿各层的位置信息。相反,LightGlue依赖于一种相对编码,这种编码可以更好地跨图像进行比较,并添加到每个自关注单元中。这使得更容易利用位置并提高更深层次的准确性。
预测头:SuperGlue 通过使用 Sinkhorn 算法 [66]、48] 解决可微最优传输问题来预测分配。它由许多逐行和逐列归一化迭代组成,这在计算和内存方面都很昂贵。SuperGlue 添加了一个dustbin来拒绝不匹配的点。我们发现dustbin纠缠了所有点的相似度得分,从而产生次优的训练动态。LightGlue 解开相似性和可匹配性,这对于预测更有效。这也产生了更清晰的梯度。
深度监督:由于Sinkhorn成本昂贵,SuperGlue在每一层之后无法进行预测,并且仅在最后一层进行监督。LightGlue 的较轻头部使得预测每一层的分配并监督它成为可能。这加快了收敛速度,能够在任何层之后退出推理,这是LightGlue效率提高的关键。
5. Experiments
6. Conclusion
本文介绍了 LightGlue,这是一种深度神经网络,经过训练可以在图像之间匹配稀疏的局部特征。基于 SuperGlue 的成功,我们将注意力机制的力量与有关匹配问题的见解以及 Transformer 最近的创新相结合。我们给出了这个模型来介绍自己预测的置信度的能力。这产生了一种优雅的方案,将计算量调整为每个图像对的难度。它的深度和宽度都是自适应的:1)如果所有预测都准备好,则推理可以在早期停止,2)被认为不匹配的点从进一步的步骤早期被丢弃。由此产生的模型 LightGlue 最终比长私有 SuperGlue 更快、更准确、更容易训练。总之,LightGlue 是一种仅有好处的滴替代品。代码将公开发布,以便社区的利益。
------------
参考: 1.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号