【读书笔记】人工智能芯片设计 04 [第四章-人工智能芯片架构设计]
人工智能芯片设计
第四章 人工智能芯片架构设计
本章将围绕精确度、能耗、吞吐率、成本、灵活性等关键指标,对现有的人工智能芯片架构进行分析,并讨论有助于进一步优化人工智能芯片的新方法, 同时给出实验评估结果。
4.1 研究现状
第三章给出的网络层的数学模型,可以看到智能计算主要是大量的线性代数计算,典型的如张量处理,而控制流程则相对简单,非常适合采用并行计算范式来提高性能。因此,人工智能芯片架构通常采用高度并行的计算架构,主要包括下图所示的时域计算架构和空域计算架构。
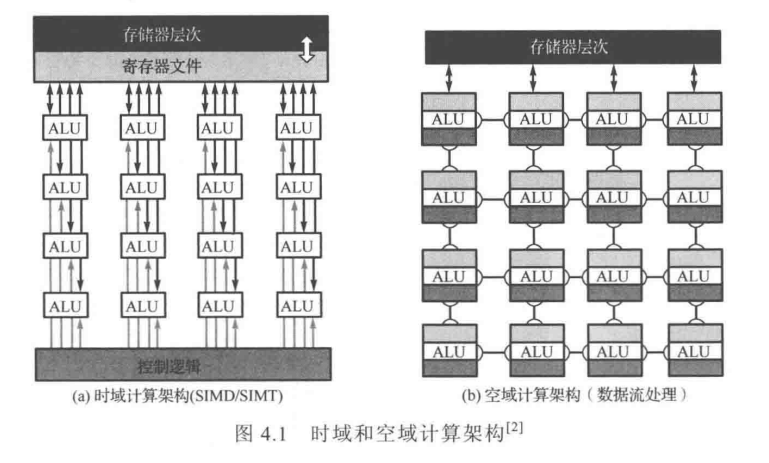
4.1.1 时域计算架构
通常是指采用专门针对神经网络算法定制指令集的专用处理器(Application Specific Instruction-set Processor, ASIP)架构。如图4.1(a)所示,它基于指令流对计算资源算术逻辑单元(Arithmetric Logic Unit, ALU)和存储资源进行集中控制,每个ALU都从集中式存储系统获取运算数据,并向其写回原酸结果。
时域并行计算架构:最直接的改进思路是让一条指令同时针对多个数据元素执行相同的操作。(GPU的流处理器本身就是一种高效的向量处理器,在单个时钟周期内,可以处理数百到数千次运算。)因此,时域计算框架主要出现在应用于人工智能应用的CPU或GPU中。
时域计算框架的两个典型的代表性设计:
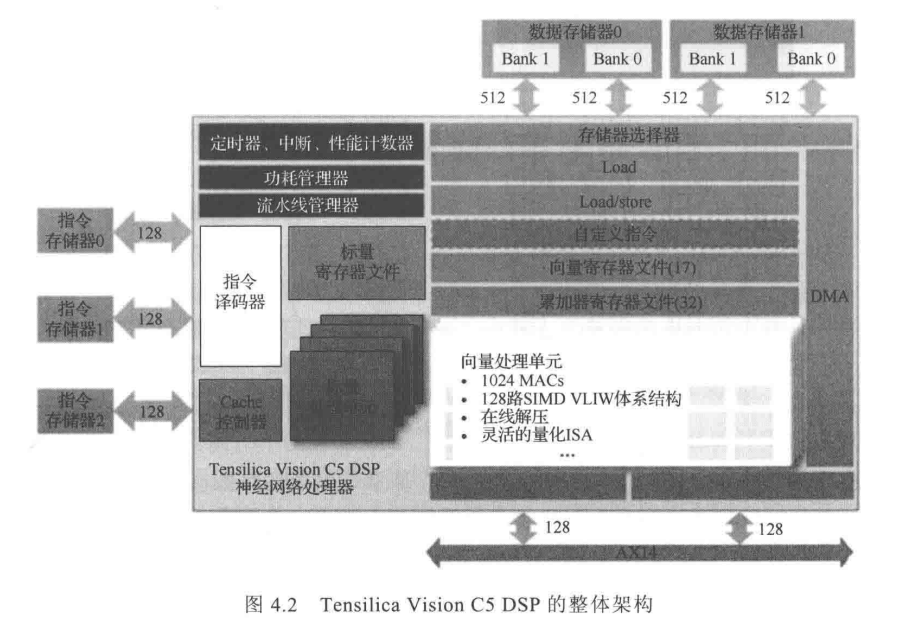
(1)Cadence公司的Vision C5 DSP
C5 基于SIMD VLIW体系结构设计,支持卷积、全连接、池化等全连接神经网络处理功能,能够在不到1mm2的芯片面积上实现1TMAC/s、的计算能力。基于业界知名的AlexNe CNN基准测试集,Vision C5 DSP的计算速度较2017年业界的GPU最快提高6倍;基于Inception V3 CNN基准测试集,则可达9倍的性能提升效果。
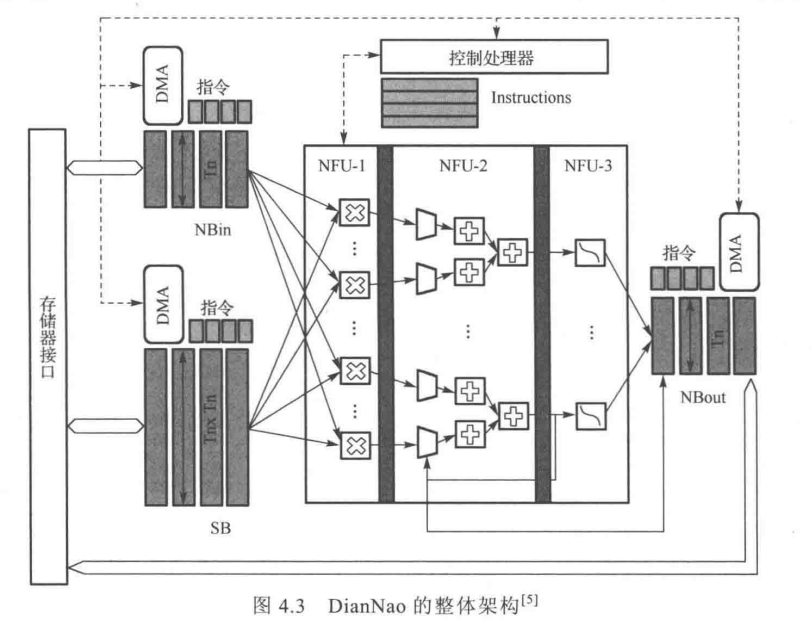
(2)中国科学院计算技术研究所DianNao系列神经网络加速器。(首款2014年)
由三部分组成:
(1)神经功能单元(Neural Functional Unit, NFU)
(2)用于存储输入输出数据与网络参数缓存(NBin \ NBout \ SB)
(3)控制器
NFU和存储器在指令流驱动下受控制器的统一组织调度。
从上面介绍的两种典型设计可以看到,时域计算架构的计算单元配置虽然非常灵活,但是每一步操作都需要精确的指令来控制存储器访问和具体计算单元的操作类型, 而且集中式存储设计导致架构与片外存储交互频繁,因此性能和能效受限。
4.1.2 空域计算架构
每个ALU都具有独立的控制逻辑,并可以带本地存储器,如本地缓存或者寄存器文件。带有本地存储器的ALU通常称为计算单元PE。整个框架采用数据流控制,即所有ALU形成处理链关系,数据直接在ALU之间传递。
一、MIT设计的Eyeriss是采用空域计算架构设计的典型代表(2016)
行固定模式:数据复用--卷积计算
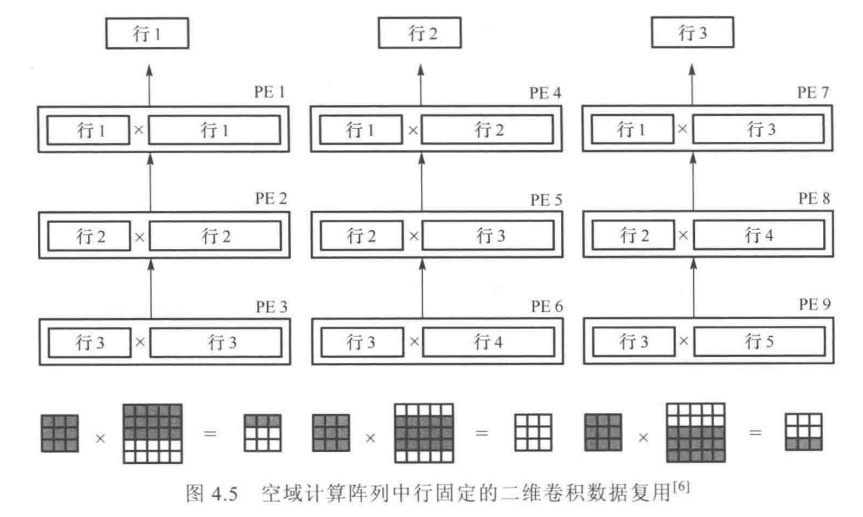
Eyeriss将智能计算的整体能效较传统方法提升了10倍,是得在移动设备上执行自然语言处理和面部识别等复杂的智能计算任务称为可能,推导了人工智能边缘计算处理器研发的热潮。
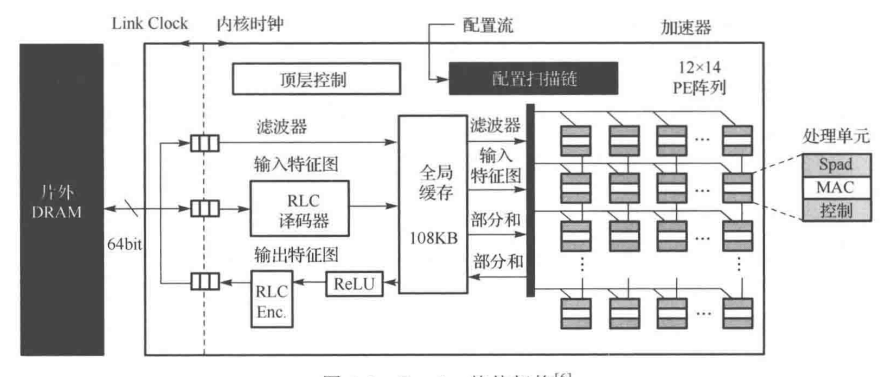
二、比利时鲁汶大学的ENVISION架构(2017)
这是一种用于低功耗卷积神经网络、精度可扩展的计算架构。
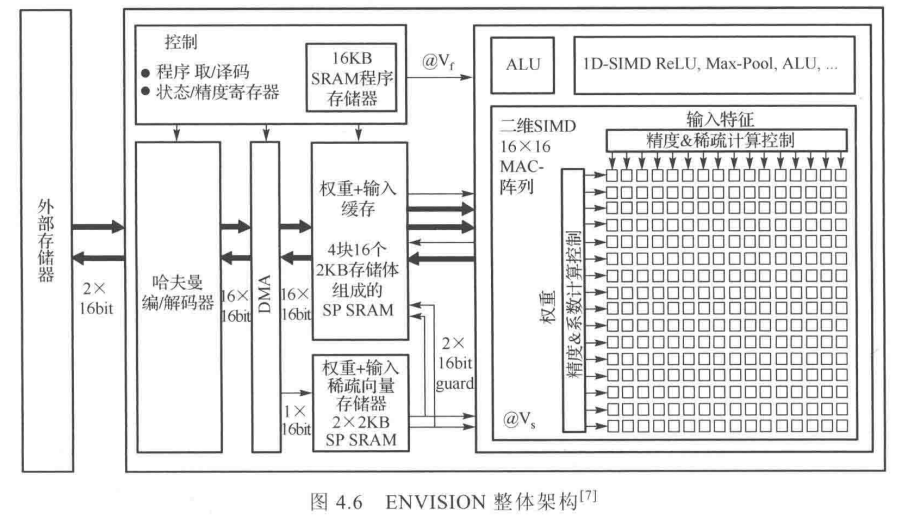
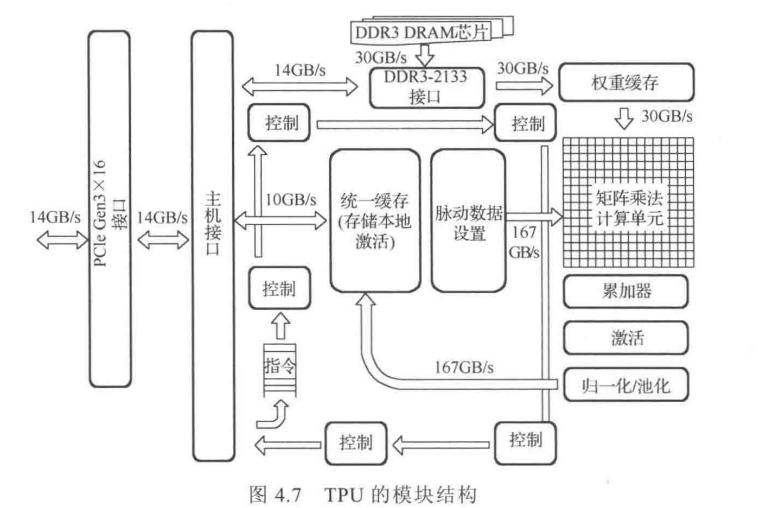
三、谷歌公司ASIC型云端神经网络加速器TPU(Tensor Processing Unit)
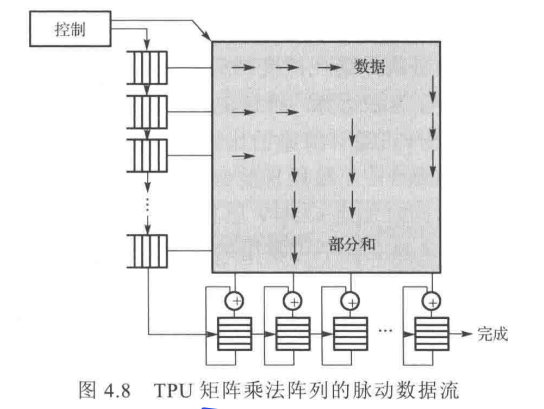
脉动结构(systolic architecture)
alphago在谷歌云上使用了50个TPU。
TPU(相比CPU和GPU)在性能上获得30倍提升,能效方面则或得30~80倍提升。
4.2 现状分析
几种地那行设计之外,研究人员还提出多种新兴智能计算架构,但普遍存在以下问题:
第一,已有的设计没有利用神经网络对于地位宽量化的天然容错性来提升高计算能效。(高位宽限制)
第二,大部分优化几种在网络的卷积层,限制了人工智能芯片的整体性能和能效。(各层资源独立、不可复用,限制灵活性、资源利用率和效率)
第三,通常计算为固定的计算模型。(不同的计算需求不平衡)
第四,存储系统通常采用固定的设计。(访问和数据流不灵活)
4.3 多粒度可重构计算框架
以Thinker的架构为例:
4.3.1 系统总体架构
(1)位宽自适应MAC
(2)算子重构的PE(通用PE和超级PE)
(3)片上存储系统
(4)有限状态控制器
(5)I/O和解码器
4.3.2 计算数据流
4.3.3 基于融合数据模式的存储划分
4.3.4 按需动态阵列划分
4.3.5 实验评估

 浙公网安备 33010602011771号
浙公网安备 33010602011771号