【读书笔记】人工智能芯片设计 03 第三章
人工智能芯片设计 03
第三章 智能计算的挑战
3.1 基本网络层的数学模型
(1)网络层类型: 卷积层、全连接层、池化层、递归层。
(2)卷积层的计算通常占到卷积神经网络计算总量的90%以上,是设计智能计算芯片需要重点考虑的部分。
(3)池化层也称为下采样层,常采用最大池化和平均池化。最大池化可以有效的减轻旋转、平移或则缩放影响。
(4)递归神经网络会对前面的信息进行记忆并应用与当前输出的计算中,即隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。计算公式如下:
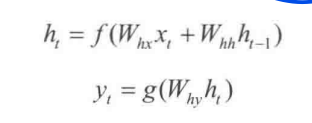
3.2 基本网络层的计算特点
一、从数学模型分析
(1)第一,网络进行的基本运算包含累加、非线性运算、池化运算等基本操作。乘累加计算量为主要的计算消耗操作,乘累加运算的高效执行对于神经网络的计算具有重要意义。
(2)神经网络不仅计算量大,而且访问操作量也很大,控制则比较简单。
(3)神经网络数据结构与底层硬件存储结构之间存在巨大差异,前者到后者的映射所带来的能效损耗称为智能计算芯片架构设计面临的重要挑战。(卷积三维、存储单元三维,这种神经网络数据结构与硬件储存结构的差异造成内润访问50%以上的微操作都是空操作,能耗损失较大。)
(4)第四,不同类型的神经网络基本层具有不同的计算特点,呈现多样化特征、
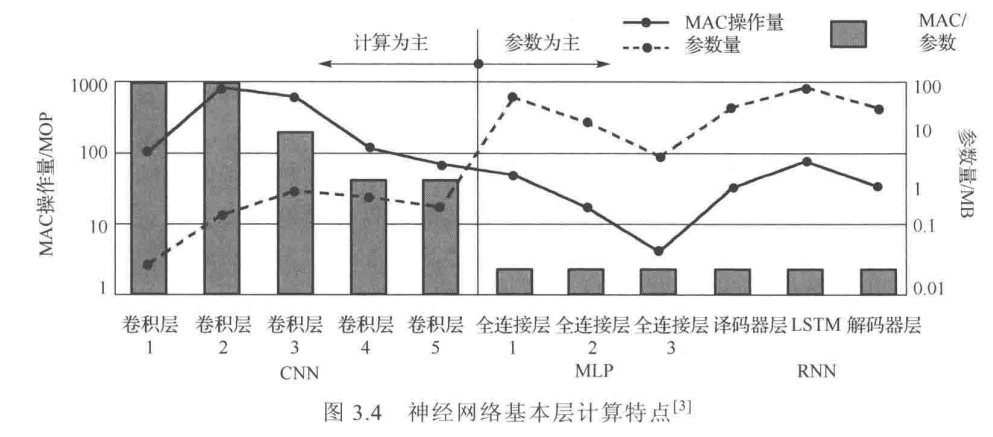
统计了alexnet的卷积层、全连接层和递归层的计算量和参数量。从图中可以看到卷积层以计算为主,参数访存操作量相对较小。而全连接层和递归层则以擦书访存操作为主。
3.3 智能计算的挑战现状分析
基于网络基本层的特点,从神经网络整体以及不同神经网络之间的差异着手,可以总结出智能计算所面临的挑战。
一、访存能力
内存墙:目前的深度学习网络类智能计算高度依赖海量数据,然而运算单元与内存之间的性能差异越来越大,内存子系统已经成为芯片整体处理能力提高的障碍,也就是通常所说的“内存墙”。而神经网络数据密集型工作负载,需要大量的存储和各层次存储器间的数据搬移,导致“内存墙”问题更加突出。
因此,如何缓解计算单元和存储器之间的差异,已经成为目前学术界和工业界无法回避的主要挑战。
(1)卷积层大量多通道的卷积核,再加上滑动窗口多次重复访问,且参与计算的时间不连续,导致访存量激增。
(2)全连接层权重矩阵尺寸与输入特征图尺寸相同,需要的数据访问量也很大。
如此巨大的参数量不仅需要巨大的存储容量,而且必须进行高效访问。因此,对内存数据、仿存带宽和内存管理方法都有很高的要求,这些对于智能计算芯片来说都是巨大挑战。
二、功耗控制
问题:在智能计算过程中,由于参数量过于庞大,拥有有限空间的片上静态随机存储器(Static Random Access Memory, SRAM)无法全部存储,绝大部分数据被存入片外冬天随机存取存储器(Dynamic Random Accesss Memory, DRAM),造成了频繁的存储器访问(简称仿存)。有些仿存造成的功耗甚至超过了计算。
举例如图:

(1)最靠近计算单元的局部寄存器(Register File, RF)的功耗最低,与乘累加操作相当,而最远的片外DRAM的功耗则高达乘累加操作的200倍。因此,理论上,让数据尽可能多的靠近计算单元的地方停留并被多次重用,才能减少数据仿存的功耗。
(2)当然,各级存储器空间会受到成本和面积的约束,这就需要进行权衡折中,精心设计智能计算芯片的硬件架构和数据流。
因此,如何解决大规模数据仿存带来的功耗问题是智能计算需要解决的重点和难点。
三、架构通用性
(1)为了提高精度,神经网络正朝着层次更深、拓扑链接更复杂、和网络混合更丰富方向快速演进,神经网络层与层间及不同类型网络间的差异性不断加大。
(2)因此,适用于高效处理不同神经网络的硬件互连结构、基础计算部件都存在较大差异,与之匹配的硬件架构需求也截然不同。
(3)举例,针对神经网络的加速架构,在执行长短期记忆网络LSTM模型时并行利用率可能还不到20%,即使时可重构架构也难以摆脱硬件固有的固化性,其架构可重构的空间也是有限的,所以在架构设计时如何解决智能计算芯片的通用性问题也是智能计算的重要挑战之一。
(4)明确定位计算芯片的应用范围、合理缩小设计的通用性目标是有效的解决方法之一,如定位为专门加速某一种网络,或是适用于图像识别、语音识别等场景中的多种常用网络。
四、稀疏性
在神经网络中,很多因素都可以带来网络的稀疏性,例如矩阵本身的洗属性、ReLU等函数带来的激活值的稀疏性等。
稀疏化会导致非规则化,为了匹配硬件运算把稀疏化网络进行规则化(如补0)有可能会抹杀稀疏化的收益,这就产生了矛盾,导致执行性能并没有或得相应提升。
如何有效的利用稀疏化的优点,提高智能计算的性能和能效,也是设计智能计算芯片的重要挑战之一。
五、混合精度计算
(1)随着低功耗和性能需求不断提高,神经网络逐渐从过去的只能全精度(32bit浮点)运算像支持16bit、8bit、4bit、甚至三值化、二值化等多种低精度运算扩展。
(2)量化过程,使用尽可能低的精度,达到预期效果,同时可以节省大量内存和降低能量消耗。
(3)对于卷积神经网络、全连接神经网络和循环神经网络等网络,其网络各层适宜的精度也不相同。如果仍然采用固定位宽的基本计算单元设计,虽然可以极大的简化设计复杂性,但是这样的设计存在灵活性不足的天生缺陷,要么位数不足导致无法接受的错误,要么位数太多导致浪费存储、带宽及消耗。
3.4 智能计算平台现状
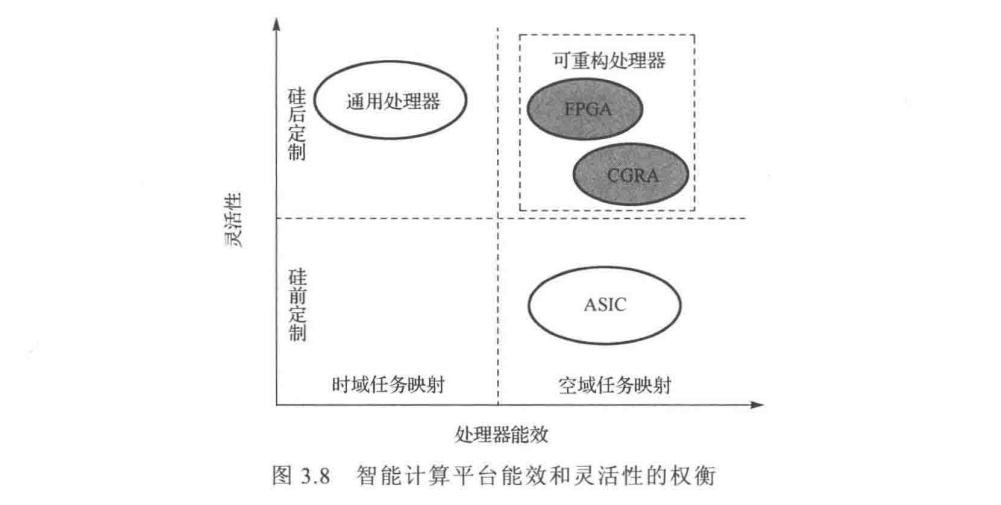
智能计算目前常用的平台分为通用处理器、专用处理器和可重构处理器三大类。
一、通用处理器
主要包括CPU和GPU,它们都是基于冯诺依曼体系结构的指令集处理器,受控制流驱动,具有很强的功能灵活性和使用便利性;采用运算与存储分离的结构,为计算机的通用性奠定了基础。因此,迄今为止,以冯诺依曼体系结构为基础设计的通用处理器仍然主导现代计算芯片的发展。
基于冯诺依曼体系结构的通用处理器在智能计算应用中遭遇了以下问题。
第一,控制流驱动的时域计算架构,为完成核心的“执行”运算,需要大量的辅助性工作,如“取指”“译码”“寄存器访问”和“数据回写”等,极大地限制了处理的性能,浪费了能耗。
第二,存储与运算分离的计算架构下,冯诺依曼架构的处理执行命令必须先从外部存储单元中读取数据,执行完成后必须写回数据,对于智能计算这样访存量大的应用,存算分离架构中的频繁数据交换导致大量功耗浪费在总线上,同时也严重限制了神经网络处理的并行性。
第三,冯诺依曼计算机采用固定位宽的运算单元设计,无法灵活高效的支持智能计算多精度协同的运算需求。
第四,知恩阁计算采用三维张量数据结构进行卷积运算,映射到冯诺依曼机的一维线性存储器上,仿存效率低,将导致极大的性能和能耗损失。
目前,基于冯诺依曼体系结构的CPU和GPU已经不再是智能计算的唯一选择,专用处理器和现场可编程门阵列FPGA开始越来越多的在神经网络加速处理应用领域崭露头角。
二、专用处理器
主要指专门针对智能计算、基于ASIC方式设计的定制处理器。
NVIDIA也在其最新产品中增加了专门用于张量和矩阵运算的Tensor Core
谷歌的TPU
虽然,专用处理器在性能、功耗和能效方面具有明显优势,但是其在通用性受限,往往只能支持固定的一种计算模式,很难根据神经网络结构的不同和执行目标的不同来改变计算架构。而重新设计一款基于ASIC的专用处理器需要经历架构设计、寄存器传输级实现、仿真验证、流片生产、测试等一系列繁复而耗时的挂糊,其上市周期通常在一年左右。
三、可重构处理器
基于可重构器件实现的神经网络加速处理器对用用处理器平台和基于ASIC的专用处理器进行了折中。这一类处理器包含FPGA和粗粒度可重构阵列(CFRA),具有硬件可编程能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号