【论文精读】ADCPNet: Adaptive Disparity Candidates Prediction Network for Efficient Real-Time Stereo Matching (2022 Q1)
title: ADCPNet: Adaptive Disparity Candidates Prediction Network for Efficient Real-Time Stereo Matching date: 2023-05-14 08:35:32 tags: 论文精读 轻量级 (2022年的SCI 1区)
|
作者 |
He Dai, Xuchong Zhang, Yongli Zhao, Hongbin Sun |
|
单位 |
西安交通大学 |
|
代码 |
https://github.com/google-research/google-research/tree/master/hitnet |
|
期刊/会议 |
IEEE Transactions on Circuits and Systems for Video Technology ( Volume: 32, Issue: 5, May 2022) |
|
关键词 |
Stereo matching network, dynamic offsets prediction, lightweight model, real-time, mobile application. |
0.摘要
Efficient real-time disparity estimation is critical for the application of stereo vision systems in various areas. Recently, stereo network based on coarse-to-fine method has largely relieved the memory constraints and speed limitations of large-scale network models. Nevertheless, all of the previous coarse-to-fine designs employ constant offsets and three or more stages to progressively refine the coarse disparity map, still resulting in unsatisfactory computation accuracy and inference time when deployed on mobile devices. This paper claims that the coarse matching errors can be corrected efficiently with fewer stages as long as more accurate disparity candidates can be provided. Therefore, we propose a dynamic offset prediction module to meet different correction requirements of diverse objects and design an efficient two-stage framework. In addition, a disparity-independent convolution is proposed to regularize the compact cost volume efficiently and further improve the overall performance. The disparity quality and efficiency of various stereo networks are evaluated on multiple datasets and platforms. Evaluation results demonstrate that, the disparity error rate of the proposed network achieves 2.66% and 2.71% on KITTI 2012 and 2015 test sets respectively, where the computation speed is 2× faster than the state-of-the-art lightweight models on high-end and source-constrained GPUs
- 问题:
有效的实时差异估计对于在各个领域应用立体声视觉系统至关重要。最近,基于从粗到细方法的立体声网络在很大程度上缓解了大规模网络模型的记忆约束和速度限制。尽管如此,所有先前从粗到细的设计都使用恒定补偿和三个或更多阶段来逐步细化粗略的视差图图,在部署到移动设备时,仍然导致计算准确度和推理时间不理想。
- 工作内容:
本文认为,只要能够提供更准确的视差候选者,就可以用更少的级数有效地校正粗匹配误差。因此,我们提出了一种动态偏移量预测模块,以满足不同对象的不同校正需求,并设计了一种高效的两阶段框架。此外,为了有效地规则化紧凑的代价体积,进一步提高整体性能,提出了与视差无关的卷积算法。
- 效果:
在多个数据集和平台上对各种立体网络的视差质量和效率进行了评估。评估结果表明,该网络在Kitti 2012和2015测试集上的视差错误率分别达到2.66%和2.71%,在高端和资源受限的GPU上的计算速度比现有的轻量级模型快2倍。
1. Introduction
在本文中,我们认为只要在精细视差估计阶段能够提供更准确的视差候选者,就可以用较少的阶段有效地校正粗匹配误差。
我们的主要贡献是:
- 提出了一种动态偏移量预测(DOP)模块来生成自适应视差候选,以适应不同对象的视差校正的不同要求(图1)。
- 在精细视差估计阶段,视差独立卷积(DIC)对于紧凑的代价体积提供了更有效的正则化,从而进一步提高了整体精度和速度。
- 基于这两个简单而高效的模块,我们设计了一个由粗到精的两级结构,即自适应视差候选预测网络(ADCPNet),以在计算精度和推理时间之间实现更好的平衡,从而实现高效的实时立体匹配。
2. Related Work
A. Deep Learning Based Stereo Matching
B. Real-Time Stereo Networks
AnyNet[22]、RTS2[23]和MADNet[24]是现有的三种针对低功耗TX2[25]平台实时部署的网络。所有这些设计都采用多阶段(≥3阶段)从粗到精的策略来降低计算复杂度和内存占用。具体来说,这些架构首先在低分辨率下通过正则化全范围成本体积来回归粗糙的视差图。然后,将粗视差图逐步上采样并用于高分辨率的特征翘曲。由于粗视差包含大量的不匹配,特别是在不连续区域,利用5个恒定偏移量(−2,−1,0,1,2)来产生更多的视差候选值,以便在精细视差估计阶段进行结果校正。
本文还采用了从粗到精的方法来满足移动应用的实时性。然而,我们的工作与上述模型在以下三个方面有所不同
- (1)提出了一种自适应预测模块来代替现有的常数偏移,以适应不同图像位置的不同校正范围。
- (2)我们提出了一种差异无关的卷积(即权重不共享的CNN),而不是使用传统的3D CNN来正则化紧凑的代价体积。
- (3)由于所提出的两个模块的有效性,我们采用了一种两阶段的粗精设计,可以同时实现精度和速度。在下一节中,我们将详细介绍整个网络体系结构和每个关键组件。
3. Method
3.1. Network Overview
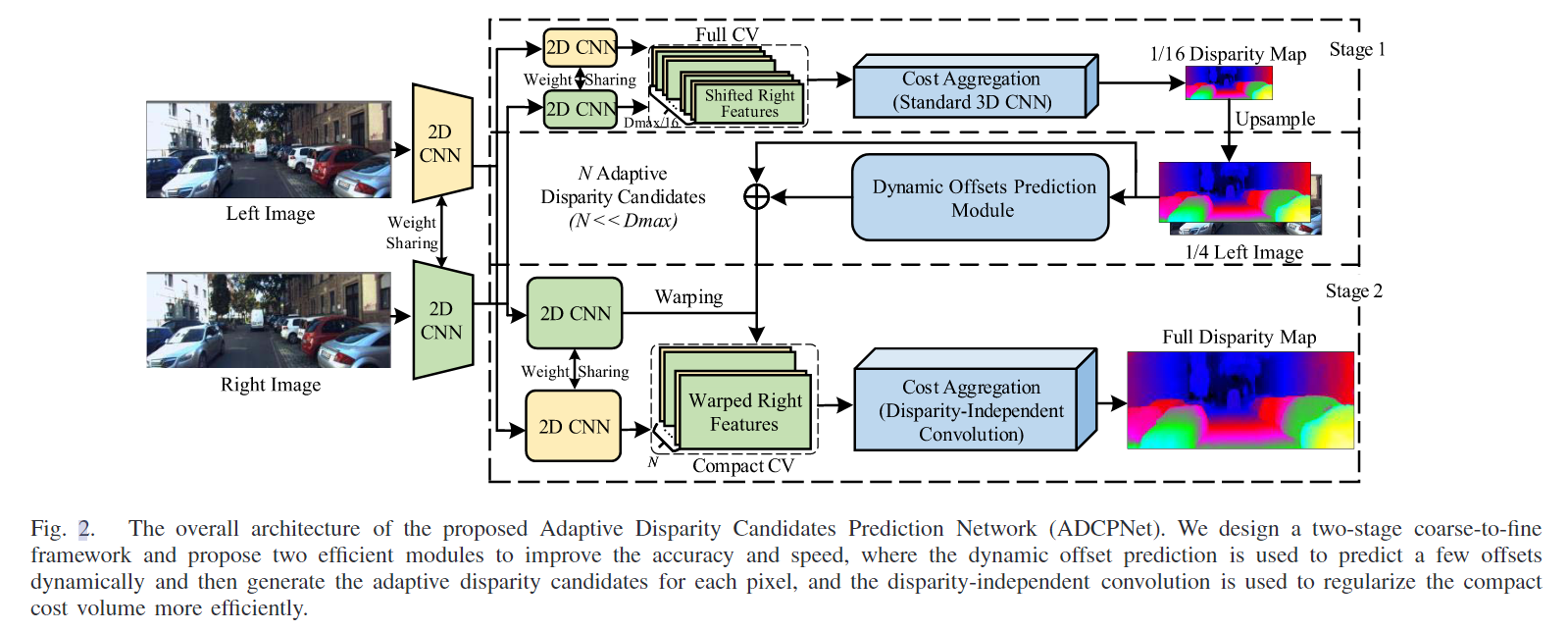
提出的ADCPNet的整体架构如图2所示。给定一个校正后的图像对,我们首先使用一系列步长为2的残差块[34]以1/2、1/4、1/8和1/16分辨率提取每个下采样特征图,其中两个输入图像之间的网络权值完全共享,每个尺度的特征大小分别设置为2C、2C、4C和8C。C是一个常量,它决定了特征提取器的性能和计算复杂度。然后,利用两阶段粗到精模型实现高效、精确的视差映射。
在阶段1中,两个步长为1的残差块级联以学习1/16分辨率的一元特征。通过在视差搜索范围内(即0 ~ dmax /16)将左侧图像特征与其对应的右侧图像特征连接起来,构建全范围代价体积。然后,我们使用六个具有相同特征sizeC3d的标准3D卷积来正则化代价体积。最后通过软argmin函数和回归方案得到粗视差图[7]。值得注意的是,我们在3D卷积的第一层之后添加了一个中间视差输出,以在训练阶段提供额外的监督。
阶段2中的处理流类似于阶段1。这两个阶段之间的主要区别是用于构建成本量的差异候选生成和用于成本聚合的卷积操作。具体来说,我们提出了一种动态偏移预测方案以及一个与差值无关的卷积来进行精细的差值回归。所提出的ADCPNet的详细结构如表1所示,下面的小节分别描述了所提出的两个模块和损失函数。
3.2 Dynamic Offsets Prediction
在获得第一阶段的结果后,粗变细策略通过在每个像素的粗视差上附加一组偏移量,在接下来的阶段构建一个紧凑的代价体积。形式上,用于精细视差估计的视差候选可以定义为
![]()
其中dc p为像素p的候选集,dp和k np分别表示像素p的粗视差及其第n次偏移量。N是偏移量的数目。由于在高分辨率下,每个像素只包含几个视差候选点,而不是所有可能的视差候选点,即N D max,因此从粗到精的方法可以大幅降低复杂性并加快计算速度
在之前的所有著作[22]-[24]中,偏移量都被设置为常量,可以表示为
![]()
然而,这个常数设置的视差校正忽略了整个图像中不同物体对偏移范围的不同要求。根据我们的实验结果,我们实际上发现近距离物体的匹配误差需要较大的偏移量进行视差校正,而远距离区域需要较小的偏移量进行精细调整。此外,像树木和杆子这样的薄物体甚至需要与粗结果完全不同的差异,因为这些结构在低分辨率处理中容易受到下采样和上采样操作的破坏。因此,我们提出了一种有效的动态偏移预测(DOP)模块来解决上述问题。
DOP的基本思想是根据粗视差结果和图像信息的指导,动态预测每个像素的偏移量。具体来说,我们将偏移量预测定义为粗视差图和原始左侧图像的函数,
![]()
其中k np为第n个预测偏移量(k1p = 0), Ip为像素p的RGB信息。为了获得最优偏移量,我们建议使用CNN模块近似该函数。具体来说,本文提出的DOP首先将粗视差图和左侧图像调整到相同的尺寸。然后,连接的视差图和彩色图像通过一个2D CNN,该CNN输出一个C - D - O - P维表示。步长为1的4个2D残块跟随学习最终预测。DOP模块的输出是一个n维偏移张量,然后将其添加到粗视差中以生成用于精细视差估计的自适应候选视差。我们注意到超参数sn和C DOP决定了DOP模块的性能和计算复杂度。
3.3 Disparity-Independent Convolution
用于成本聚合的正则化方法对立体网络的性能有至关重要的影响。在以往基于粗到精方案的轻量化设计中,利用一系列具有3 × 3 × 3核的标准3D cnn对全范围代价体积和紧凑代价体积进行正则化,其中卷积核的参数在每个阶段的所有视差候选点之间完全共享。然而,对于这是否是每个阶段的最佳操作,却鲜有讨论。本文认为,与全范围代价体积相比,这种差异维度上的权值共享方案具有不同的局部统计特征,并不是紧凑代价体积正则化的最佳选择。在粗视差估计阶段,在整个搜索范围内的所有视差候选具有相同的概率为最优结果。然而,在精细视差估计阶段的N个候选视差实际上具有不同的概率.由于前一阶段的粗糙结果已经为视差校正提供了先验信息。传统的沿视差维数共享权值的3D cnn不能有效地学习到不同的候选表示。
基于上述观察,我们提出了一个视差独立卷积(DIC)来解决紧凑成本体积的这些不同特征。与传统的代价聚合操作不同,DIC的核大小被设置为3 × 3 × N,并且对N个差异候选向量以不共享权重的方式独立学习参数。需要强调的是,由于N个候选点的内在相关性,我们使用3 × 3 × N核来组合它们的所有信息,而使用不共享权方案来学习它们彼此之间的独立表示。因此,该模块进一步提高了视差精度
3.4 Disparity Regression and Loss Function
对于第一阶段的粗视差回归,我们使用了[7]中提出的软argmin方案,该方案是完全可微的,并且可以进行亚像素估计。粗视差d1是所有视差候选者按其概率加权的和
![]()
其中,每个视差的概率d是通过softmax运算从总代价c d计算出来的。对于阶段2,除了候选视差为d1 + k n之外,视差d1的计算方法与此类似
![]()
对于损失函数,由于其鲁棒性和对异常值的低灵敏度,我们采用平滑L1来监督整个网络。由于如上所述,每个阶段有两个输出,因此将损失定义
![]()
其中λsi表示阶段s.P中第i个输出的权重值,p为有效像素的数目,d * j为真地差。光滑L1计算为
![]()
5. Experiments
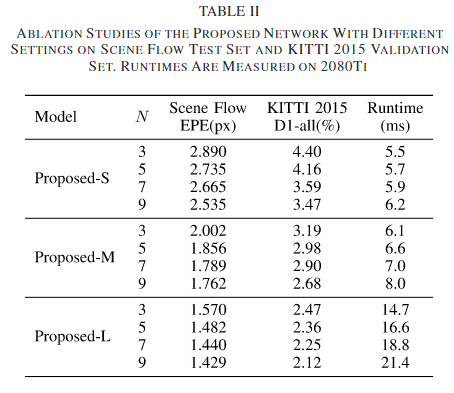
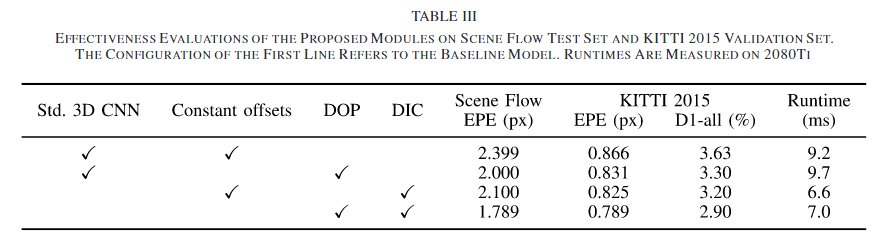
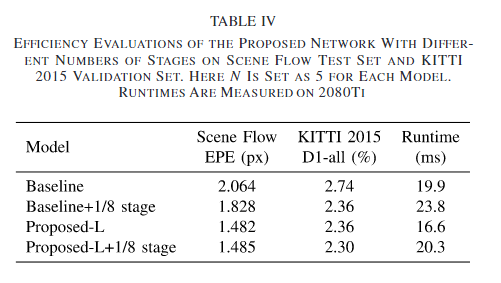
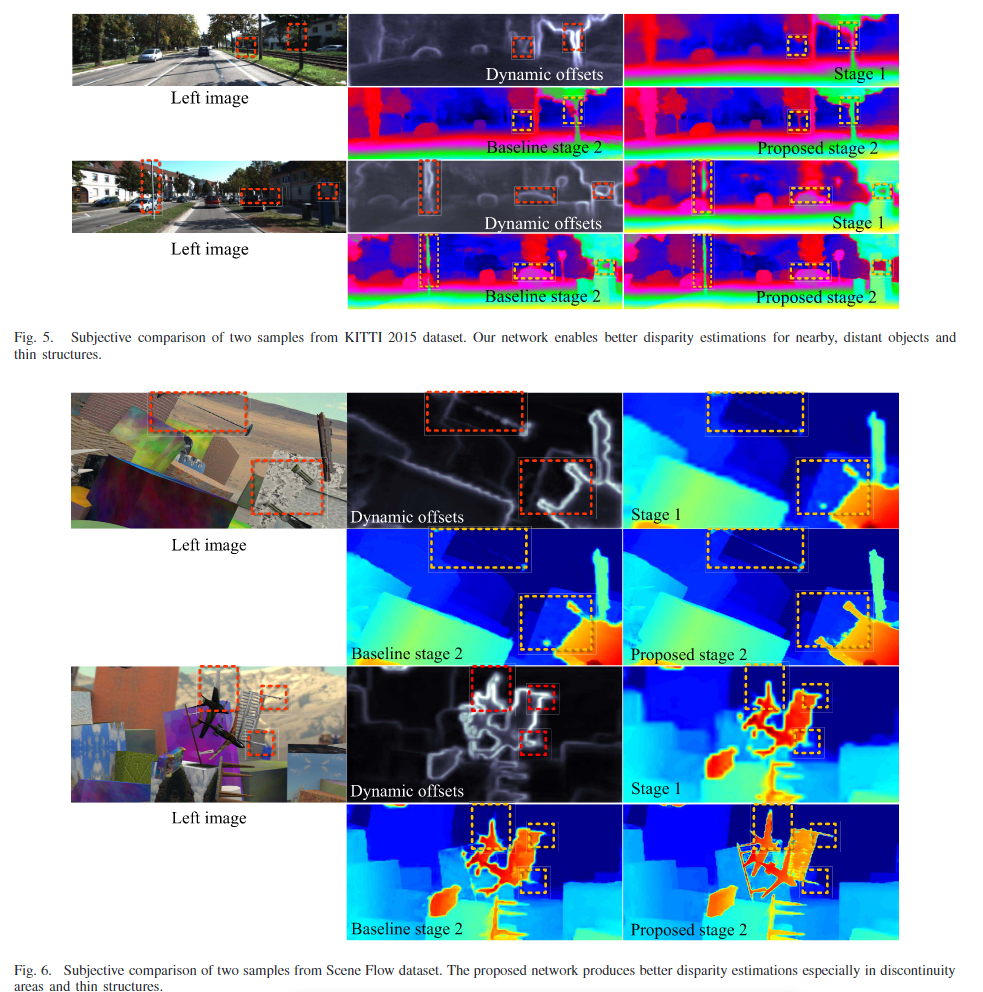
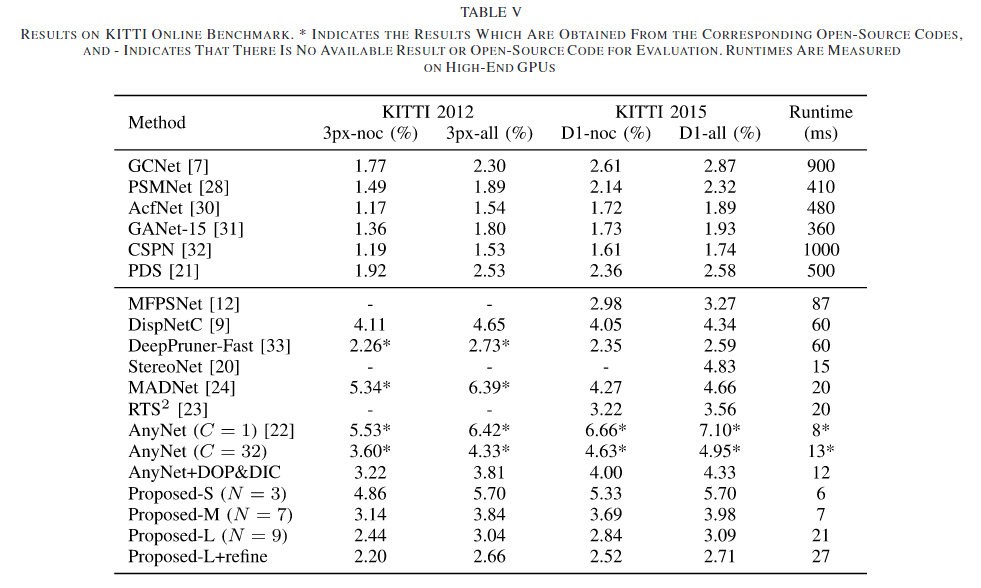

6. Conclusion
------------
参考: 1.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号