【论文阅读】UniNeXt(阿里 通用模型)2023
title: UniNeXt: Exploring A Unified Architecture for Vision Recognition date: 2023-05-142023-05-14 03:26:4103:26:42 tags: 通用模型 VIT 局部窗口有注意力

|
作者 |
Fangjian Lin1, Jianlong Yuan1, Sitong Wu1, Fan Wang1, Zhibin Wang1 |
|
单位 |
阿里 |
|
代码 |
https://github.com/jianlong-yuan/UniNeXt/tree/main |
|
期刊/会议 |
|
|
关键词 |
2023 |
摘要:Abstract—Vision Transformers have shown great potential in computer vision tasks. Most recent works have focused on elaborating the spatial token mixer for performance gains. However, we observe that a well-designed general architecture can significantly improve the performance of the entire backbone, regardless of which spatial token mixer is equipped. In this paper, we propose UniNeXt, an improved general architecture for the vision backbone. To verify its effectiveness, we instantiate the spatial token mixer with various typical and modern designs, including both convolution and attention modules. Compared with the architecture in which they are first proposed, our UniNeXt architecture can steadily boost the performance of all the spatial token mixers, and narrows the performance gap among them. Surprisingly, our UniNeXt equipped with naive local window attention even outperforms the previous state-ofthe-art. Interestingly, the ranking of these spatial token mixers also changes under our UniNeXt, suggesting that an excellent spatial token mixer may be stifled due to a suboptimal general architecture, which further shows the importance of the study on the general
问题:视觉Transformer在计算机视觉任务中显示出巨大的潜力。最近的工作都集中在阐述spatial token mixer以提高性能。然而,我们观察到,无论配备哪种空间令牌混合器,设计良好的通用架构都可以显著提高整个主干的性能。
工作内容:在本文中,我们提出了UniNeXt,这是一种改进的视觉主干通用架构。为了验证其有效性,我们用各种典型和现代的设计实例化了spatial token mixer,包括卷积和注意力模块。与最初提出的架构相比,我们的UniNeXt架构可以稳步提高所有空间令牌混合器的性能,并缩小它们之间的性能差距。
效果:令人惊讶的是,我们的UniNeXt配备了简单的局部窗口注意力,甚至超过了以前的技术水平。有趣的是,在我们的UniNeXt下,这些spatial token mixer的排名也发生了变化,这表明一个优秀的空间令牌混合器可能会因为次优的通用架构而被扼杀,这进一步表明了对视觉主干的通用架构研究的重要性。所有型号和代码都将公开。
三、 Methods
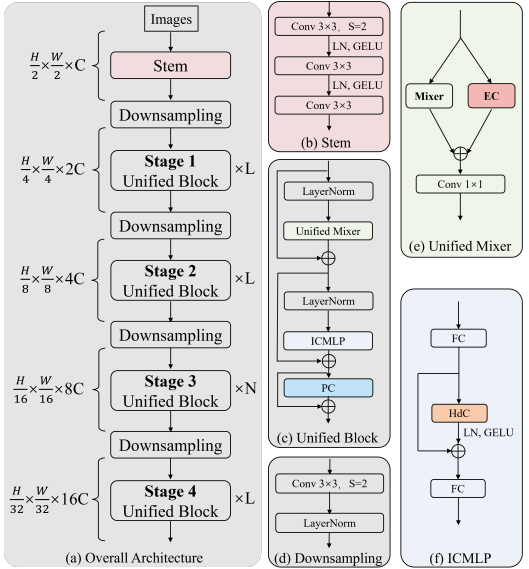
在本节中,我们首先描述我们的整体架构和变体。然后,我们详细描述了所提出的每个跳跃连接模块和空间令牌混合器(spatial token mixer.)。
A、Overall Architecture
整体架构我们统一架构的主要设计思想是通过3种方式增加归纳偏置/局部性:
a)在空间令牌混合器中添加一个并行EC分支;
b) 在所述信道MLP后面添加OC模块;
c) 将3×3 dwconv添加到FFN。
如图2所示,与经典作品[19]、[20]、[28]类似,UniNeXt是一个金字塔结构,由四个层次阶段组成。直接将图像转换为用于训练的tokens往往会忽略图像结构信息。stem[13]可以保持结构特征的平滑性并执行渐进下采样,因此首先通过stem层映射图像,以获得通道维度扩展且空间分辨率降低两倍的特征图。每个阶段都包含一个下采样层和多个统一块。在下采样层中,每个阶段的空间下采样率为2,并将通道维度扩展两倍。下采样层的输出被馈送到多个串行连接的统一块中,其中tokens的数量保持一致。在[7]、[19]之后,最后我们应用全局平均池化操作和全连接层来执行图像分类任务。
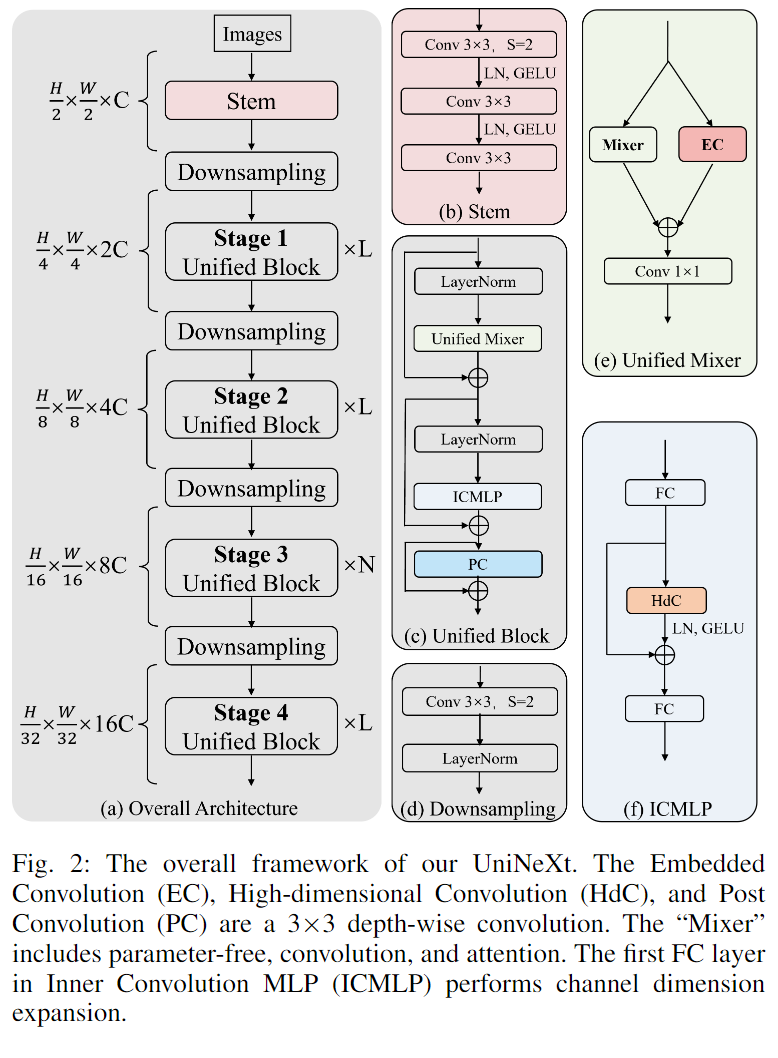
B、Variants
如表I所示,我们对UniNeXt进行了缩放,以获得三种不同尺寸的变体,包括UniNeXt-T、UniNeXt-S和UniNeXt-B。表的第i阶段中的超参数表示如下:
- •Hi:局部窗口注意力的头数,
- •Ri:ICMLP模块的扩展比,
- •Wi:图像分类任务中局部窗口注意的窗口大小,
- •ÍWi:密集预测任务(包括分割和检测)中局部窗口注意的窗口大小。
表I中的[3×3,32,s=2]×1表示具有32个输出通道和步长=2的3×3卷积。请注意,所有变体都具有相同的深度、膨胀比和窗口大小,差异在于通道尺寸和头的数量
C、UniNeXt Block
高维卷积(HdC)。研究人员[10],[33]发现,在MLP中添加轻量级的3×3深度卷积可以提高性能。我们继承并扩展了这种卷积嵌入机制。首先,使用MLP的第一线性层映射特征维度,以获得高维特征F。然后,使用3×3 depth-wise convolution 进行空间局部融合,对高维隐式特征进行编码,这可以带来效率增益。向前传球可以公式化如下:F
![]()
其中φ表示对空间维度的扁平化运算,φ表示反向运算。
嵌入式卷积(EC)。设计嵌入式卷积(EC)的动机主要有两个方面。首先,它增强了模型的归纳偏差,这对学习和泛化至关重要。其次,EC与所有令牌混合器兼容,提供了跨各种架构实现的灵活性和易用性。如图2所示,对于输入令牌混合器的特征图F,公式可以描述为:
![]()
其中令牌混合器包括无参数和卷积,dwconv表示轻量级的3×3深度卷积。对于注意力,我们直接对值执行深度卷积,而不是在窗口变换之后,使其普遍适用于各种注意力。为了输入到注意力的特征图F中,向前传播可以被描述为:
![]()
其中Φ表示完全连接层,φ和φ可以在方程1中找到。我们已经通过广泛的消融研究证明,嵌入式卷积(EC)可以为模型带来性能改进。
后卷积(PC)。为了进一步增强卷积嵌入偏差和增强局部表示,我们提出了后卷积算法,通过引入轻量级的3×3深度卷积,可以极大地提高模型的性能,特别是在密集预测任务中。具体地说,首先将tokens F∈RB×N×C转换为二维图像表示,然后进行深度卷积进行局部上下文融合,然后执行平坦化操作,最后使用剩余连接来防止权重的过度缩放:
![]()
Stem。与之前使用BatchNorm[15] (BN)执行规范化的词干[10]、[13]、[18]架构不同,我们受到ConvNeXt[20]和Vision Transformer[8]的启发,并使用层归一化[1](LN)而不是BN来执行归一化,使归一化操作在整个模型中是一致的,这有助于模型训练更好和产生更好的性能。详细的架构如图 2 所示。
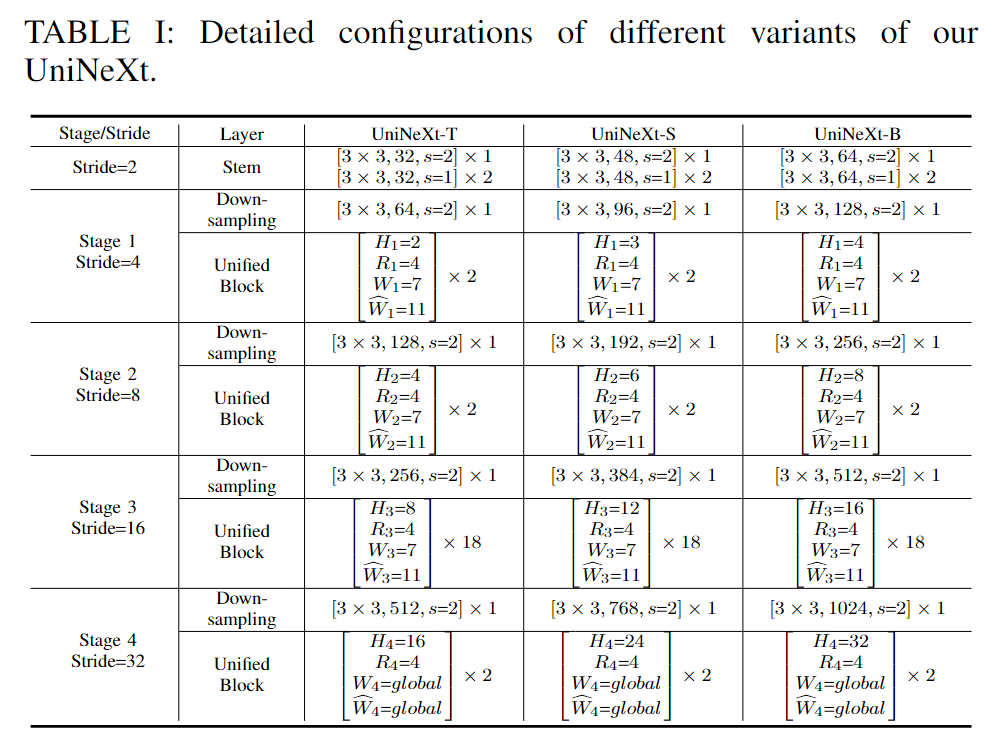
统一混合器Unified Mixer.。通过实例化不同的令牌混合器(例如,无参数、卷积和注意力),我们的架构中模型性能稳步提高。此外,在我们的框架中仅使用普通的局部窗口注意力,优于以前的 sota 结果。如图 3 所示,我们首先在特征图上执行非重叠窗口分区,对于下游任务(例如检测和分割)使用窗口大小=7,更详细的消融研究可以在表 VII 中找到。然后执行多头自注意力
![]()
其中 Q、K 和 V 生成如式 3 所示。请注意,与 ViT [8] 和 Swin [19] 不同,我们不使用额外的绝对位置编码或相对位置编码,因为所提出的卷积嵌入技术足以表示令牌之间的位置关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号