【论文精读】Iterative Geometry Encoding Volume for Stereo Matching(CVPR 2023)
title: Iterative Geometry Encoding Volume for Stereo Matching date: 2023-05-04 16:57:31 tags: 论文精读 基于RAFT改进
|
作者 |
Gangwei Xu Xianqi Wang Xiaohuan Ding Xin Yang |
|
单位 |
电子科技大学 |
|
代码 |
https://github.com/gangweiX/IGEV. |
|
期刊/会议 |
CVPR |
|
关键词 |
2023 |
0.摘要
Recurrent All-Pairs Field Transforms (RAFT) has shown great potentials in matching tasks. However, all-pairs correlations lack non-local geometry knowledge and have difficulties tackling local ambiguities in ill-posed regions. In this paper, we propose Iterative Geometry Encoding Volume (IGEV-Stereo), a new deep network architecture for stereo matching. The proposed IGEV-Stereo builds a combined geometry encoding volume that encodes geometry and context information as well as local matching details, and iteratively indexes it to update the disparity map. To speed up the convergence, we exploit GEV to regress an accurate starting point for ConvGRUs iterations. Our IGEV-Stereo ranks 1ston KITTI 2015 and 2012 (Reflective) among all published methods and is the fastest among the top 10 methods. In addition, IGEV-Stereo has strong cross-dataset generalization as well as high inference efficiency. We also extend our IGEV to multi-view stereo (MVS), i.e. IGEV-MVS, which achieves competitive accuracy on DTU benchmark. Code is available at https://github.com/gangweiX/IGEV.
- 问题:
最近,All-Pairs Field Transforms (RAFT)在匹配任务中显示出巨大的潜力。然而,所有的图相对相关性缺乏非局部几何知识,难以处理病态区域的局部模糊。
- 工作内容:
在本文中,我们提出了一种新的用于立体匹配的深度网络架构——迭代几何编码体(IGEV-Stereo)。提出的IGEV-Stereo构建了一个组合的几何编码卷,对几何和上下文信息以及局部匹配细节进行编码,并对其进行迭代索引以更新视差图。为了加快收敛速度,我们利用GEV为ConvGRUs迭代回归一个准确的起始点。
- 效果:
我们的IGEV-Stereo在所有发表的方法中排名1ston KITTI 2015和2012(反射),是前10种方法中最快的。此外,IGEV-Stereo具有较强的跨数据集泛化能力和较高的推理效率。我们还将IGEV扩展到多视图立体声(MVS),即IGEV-MVS,它在DTU基准上实现了具有竞争力的精度。
1. Introduction
通常需要进行大量的3D卷积来进行代价聚集和正则化,进而产生较高的计算和存储代价。因此,它很难应用于高分辨率图像和/或大规模场景。
最近,基于迭代优化的方法[21,24,30,39,43]在高分辨率图像和标准基准上都表现出了诱人的性能。与现有方法不同的是,迭代方法绕过了计算代价高昂的代价聚集操作,通过重复从高分辨率4D代价体中获取信息来逐步更新视差图。这种解决方案能够直接使用高分辨率成本量,因此适用于高分辨率图像。例如,RAFT-Stereo[24]利用多级卷积递归单元(ConvGRU)[10]来使用从所有对相关性(APC)检索到的局部成本值来递归地更新视差场。
然而,在没有成本聚合的情况下,原始成本量缺乏非本地几何形状和上下文信息(参见图2(B))。因此,现有的迭代方法很难处理不适定区域中的局部模糊问题,如遮挡、无纹理区域和重复结构。尽管如此,基于ConvGRU的更新器可以通过结合来自上下文要素和隐藏层的上下文和几何信息来改善预测的差异,例如原始成本的限制极大地限制了每次迭代的有效性,进而产生大量ConvGRU迭代以获得令人满意的性能。
我们认为基于成本过滤的方法和基于迭代优化的方法具有互补的优势和局限性。前者可以在代价体积中编码足够的非局部几何和上下文信息,这对于视差预测是必不可少的,特别是在具有挑战性的区域。后者可以避免用于3D代价聚集的较高的计算和存储开销,但仅基于所有对的相关性在不适定区域的能力较差。为了结合两种方法的优势互补,我们提出了迭代几何编码体积(IGEV-Stereo)。

我们的主要贡献是:
- 我们提出了迭代几何编码体积(IGEV-Stereo),这是一种新的立体匹配范式。
- 为了解决不适定区域引起的歧义,我们通过使用非常轻量级的3D正则化网络聚集和正则化代价体积来计算几何编码体积(GeometryEncoding Volume,GEV)。
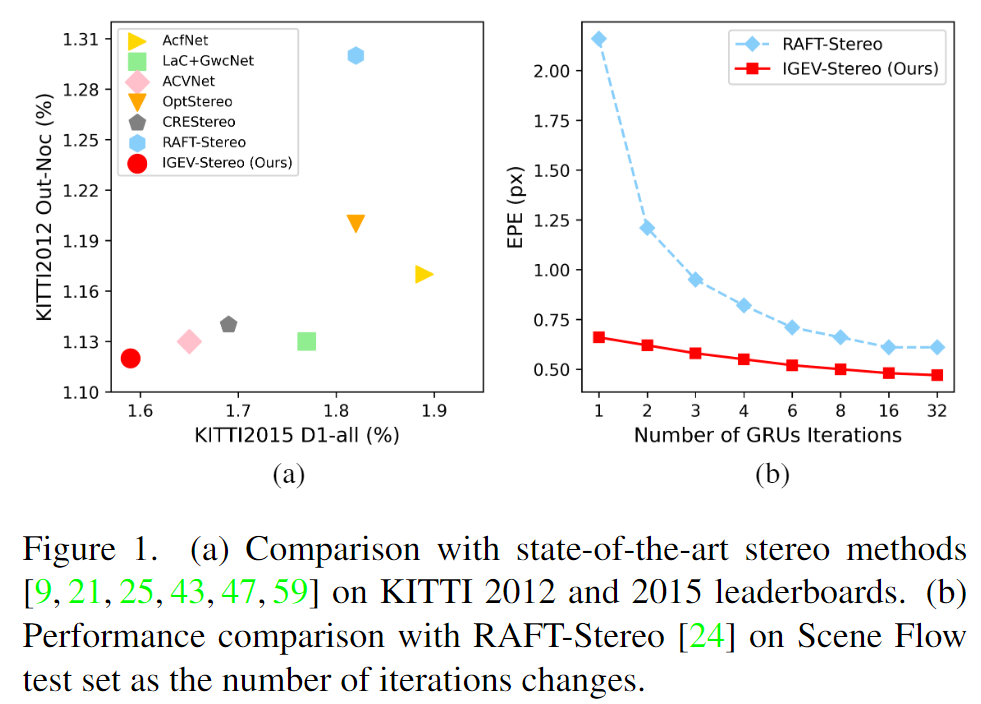
- 我们的IGEV-Stereo在精度和效率方面都优于RAFT-Stereo。在几个立体声基准上证明了我们的方法的有效性和有效性。
2. Related Work
Cost Filtering-based Methods(代价滤波,也就是代价聚合)
基于成本过滤的方法为了提高成本量的表示能力,大多数现有的基于学习的立体声方法[5,12,23,33,45,46,49,52]使用强大的CNN特征来构建成本量。然而,在遮挡区域、大的无纹理/反射区域和重复结构中,成本量仍然可能受到模糊问题的影响。三维卷积网络在规则化或过滤代价量方面显示出巨大的潜力,它可以将可伸缩的稀疏匹配传播到模糊和噪声区域。GCNet[20]首次使用3D编解码器结构来规则化4D级联体。PSMNet[5]提出了一种堆叠的沙漏3D CNN,并结合中间监管来规范串联体积。GwcNet[17]和ACVNet[47]分别提出了分组相关体积和注意串联体积,以提高代价体积的表达能力,进而提高歧义区域的性能。GANET[56]设计了半全局聚合层和局部引导聚合层,进一步提高了精度。然而,3D CNN的高计算和存储成本通常会阻止这些模型应用于高分辨率成本量。为了提高效率,已经提出了几种级联方法[16,36,48]。CFNet[36]和CasStereo[16]以从粗到精的方式构建了成本量金字塔,以逐步缩小预测的差异范围。尽管它们的表现令人印象深刻,但从粗略到精细的方法不可避免地涉及到粗略分辨率下的累积误差。
Iterative Optimization-based Methods
基于迭代优化的方法最近,许多迭代方法[24,39,41]被提出,并在匹配任务中取得了令人印象深刻的性能。RAFTStereo[24]建议使用从所有对相关性中检索到的局部成本值来递归地更新视差场。然而,所有配对的相关性缺乏非局部信息,并且在处理不适定区域的局部歧义方面存在困难。我们的IGEV-Stereo还采用ConvGRU作为RAFT-Stereo[24]来迭代更新视差。与RAFT-Stereo[24]不同,我们构造了一个编码非局部几何和上下文信息以及局部匹配细节的CGEV,以显著提高每次ConvGRU迭代的效率。此外,我们为ConvGRU更新器的启动提供了更好的初始视差图,产生了比RAFT-Stereo快得多的收敛速度[24]。
3. Method
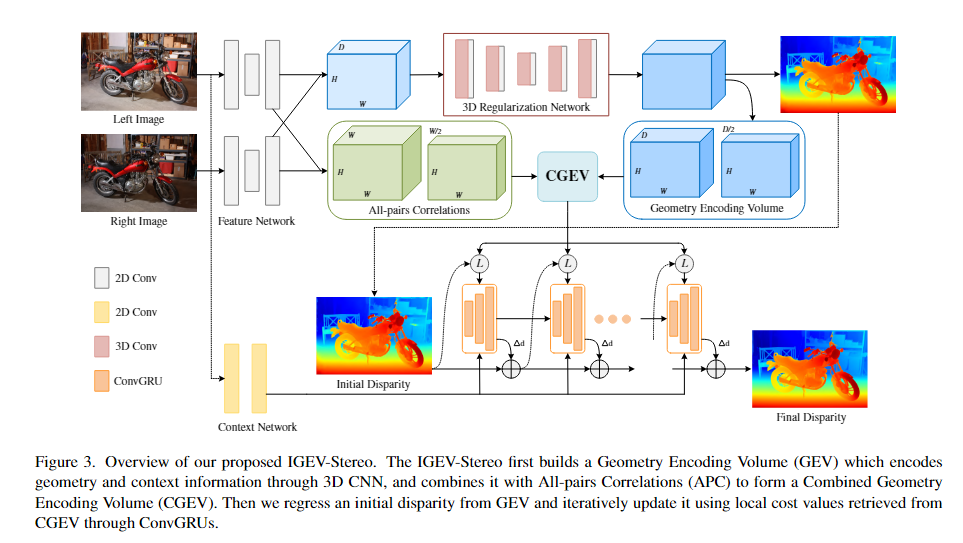
在这一部分中,我们详细介绍了IGEV-Stereo(图3)的结构,它由多尺度特征提取器、组合几何编码体、基于ConvGRU的更新模块和空间上采样模块。
3.1. Feature Extractor
特征提取器包括两部分:1) 特征网络(Feature Network.),用于提取多尺度特征,用于工程量建设和指导费用聚合;2) 上下文网络(Context Network.),用于提取多尺度上下文特征,用于ConvGRU隐藏状态的初始化和更新。
Feature Network.。给定左右图像Il(R)∈R3×H×W,我们首先应用在ImageNet[11]上预先训练的MobileNetV2将Il(R)缩小到原始大小的1/32,然后使用带有跳跃连接的上采样块将其恢复到1/4尺度,从而产生多尺度特征{fl,i(fr,i)∈Rci×Hi×Wi}(i=4,8,16,32和Ci,用于特征通道)。F1,4和fr,4用于构建成本量。并且将f1,i(i=4,8,16,32)用作3D正则化网络的指导。
Context Network.。在RAFT-Stereo[24]之后,上下文网络由一系列剩余块和下采样层组成,在128个通道的输入图像分辨率的1/4、1/8和1/16下产生多尺度上下文特征。多尺度上下文特征用于初始化基于ConvGRU的更新算子的隐藏状态,并在每次迭代时插入到ConvGRU中。
3.2. Combined Geometry Encoding Volume
给定从Il和Ir中提取的左特征f1,4和右特征fr,4,我们构造了分组对应沿着通道维度将特征f1,4(fr,4)分割成Ng(Ng=8)组并逐组计算相关图的分割体积[17],
![]()
其中,⟨…,·⟩是内积,d是视差指数,Nc表示特征通道的数量。仅基于特征相关性的代价体积Ccorr缺乏捕获全局几何结构的能力。为了解决这个问题,我们进一步使用轻量级3D正则化网络R来处理Ccorr,以获得几何编码体CG ,
![]()
3D正则化网络R基于由三个下采样块和三个上采样块组成的轻量级3D UNET。每个下采样块由两个3×3×3的3D卷积组成。三个下采样块的通道数分别为16、32、48。每个上采样块由一个4×4×43d的转置卷积和两个3×3×3的3D卷积组成。我们遵循Coex[2],它用从用于成本聚集的左特征计算的权重来激励成本量通道。对于成本聚合中的D/i×H/i×W/i成本量Ci(i=4、8、16和32),引导成本量激励表示为,
![]()
其中σ是Sigmoid函数,⊙表示Hadamard积。在3D正则化网络中加入引导代价体激发操作,可以有效地推断和传播场景几何信息,从而产生几何编码体。我们还计算对应的左、右特征之间的所有对相关性,以获得局部特征相关性。
为了增加感受野,我们使用核大小为2、步长为2的一维平均池化来池化视差维度,形成一个两级CG金字塔和所有对相关体积CA金字塔。然后将CG金字塔和CA金字塔相结合,形成一个组合的几何编码体。
3.3. ConvGRU-based Update Operator
我们应用soft-argmin根据以下公式从几何编码体积CG回归初始起始视差d0。
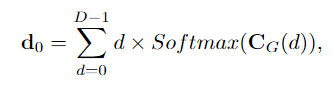
其中d是1/4分辨率下的视差指数的预定集合。然后,从d0开始,我们使用三个级别的ConvGRU来迭代更新视差(如图3所示)。这种设置有助于迭代视差优化的快速收敛。从多尺度上下文特征初始化三个级别的ConvGRU的隐藏状态。
对于每次迭代,我们使用当前视差dk通过线性插值从组合的几何编码体积中进行索引,产生一组几何特征Gf。Gf的计算公式为,
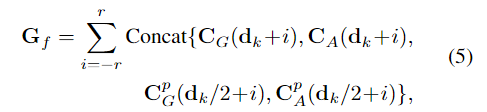
其中,dk是当前视差,r是索引半径,p表示池化操作。这些几何特征和当前视差预测dk通过两个编码器层,然后与dk连接以形成xk。然后,我们使用ConvGRU将隐藏状态hk−1更新为RAFT Stereo[24],
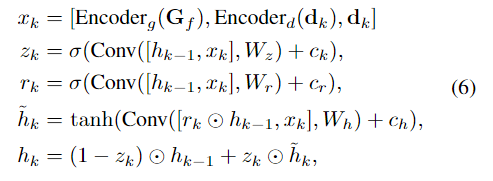
其中ck、cr、ch是从上下文网络生成的上下文特征。ConvGRU的隐藏状态中的通道数量为128,并且上下文特征的通道数量也是128。编码器和编码器分别包含两个卷积层。基于隐藏状态hk,我们对残差视差进行解码△dk通过两个卷积层,然后我们更新当前视差,
![]()
3.4. Spatial Upsampling
我们通过1/4分辨率的预测视差dk的加权组合来输出全分辨率视差图。与RAFT Stereo[24]在1/4分辨率下从隐藏状态hk预测权重不同,我们利用更高分辨率的上下文特征来获得权重。我们对隐藏状态进行卷积以生成特征,然后将其上采样到1/2分辨率。将上采样的特征与左图像中的fl,2连接,以产生权重W∈RH×W×9。我们通过粗分辨率邻居的加权组合来输出全分辨率差异
3.5. Loss Function
我们计算了从GEV回归的初始分配0上的平滑L1损失
![]()
其中dgt表示地面实况差异。我们在所有预测的差异{di}N i=1上计算L1损失。我们按照[24]指数增加权重,总损失定义为:
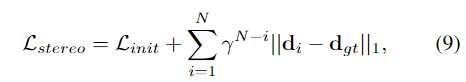
其中γ=0.9,dgt表示地面实况。
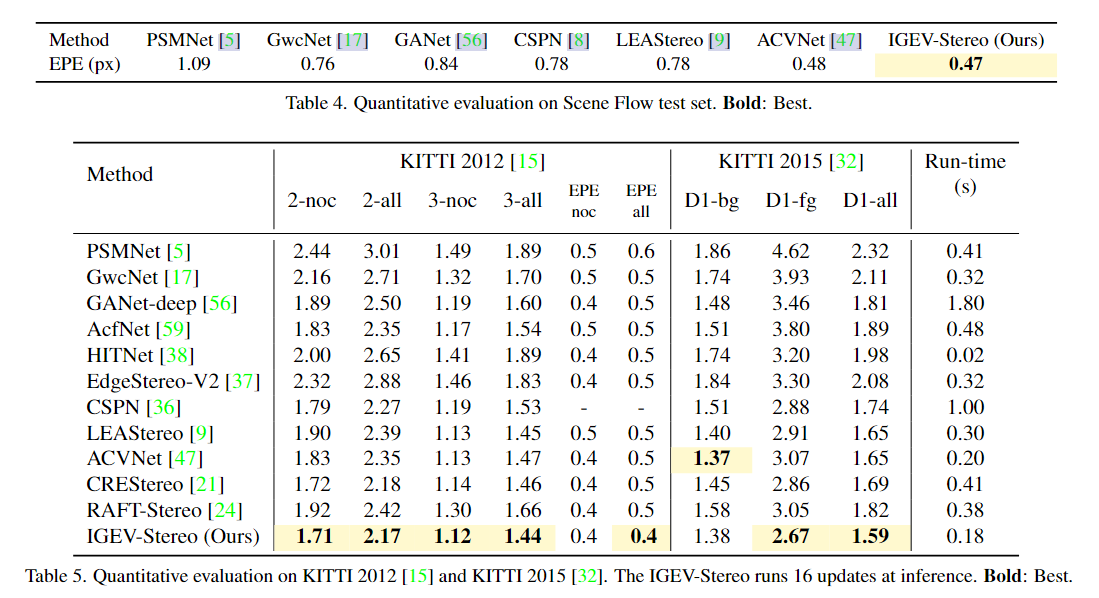
5. Experiments
Scene Flow [31] is a synthetic dataset containing 35, 454 training pairs and 4,370 testing pairs with dense disparity maps. We use the Finalpass of Scene Flow, since it is more like real-world images than the Cleanpass, which contains more motion blur and defocus.
KITTI 2012 [15] and KITTI 2015 [32] are datasets for real-world driving scenes. KITTI 2012 contains 194 training pairs and 195 testing pairs, and KITTI 2015 contains 200 training pairs and 200 testing pairs. Both datasets provide sparse ground-truth disparities obtained with LIDAR.
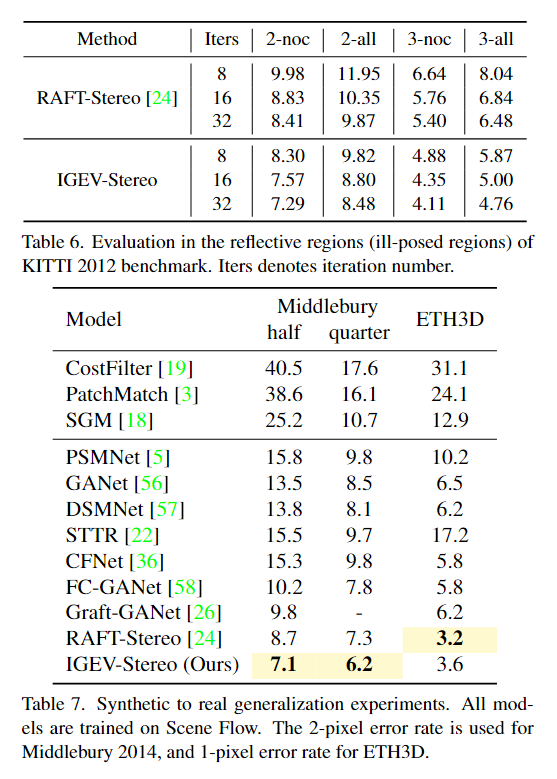
Middlebury 2014 [34] is an indoor dataset, which provides 15 training pairs and 15 testing pairs, where some samples are under inconsistent illumination or color conditions. All of the images are available in three different resolutions. ETH3D [35] is a gray-scale dataset with 27 training pairs and 20 testing pairs. We use the training pairs of Middlebury 2014 and ETH3D to evaluate cross-domain generalization performance.
4.1. Implementation Details
We implement our IGEV-Stereo with PyTorch and perform our experiments using NVIDIA RTX 3090 GPUs. For all training, we use the AdamW [28] optimizer and clip gradients to the range [-1, 1]. On Scene Flow, we train IGEVStereo for 200k steps with a batch size of 8. On KITTI, we finetune the pre-trained Scene Flow model on the mixed KITTI 2012 and KITTI 2015 training image pairs for 50k steps. We randomly crop images to 320 × 736 and use the same data augmentation as [24] for training. The indexing radius is set to 4. For all experiments, we use a one-cycle learning rate schedule with a learning rate of 0.0002, and we use 22 update iterations during training.
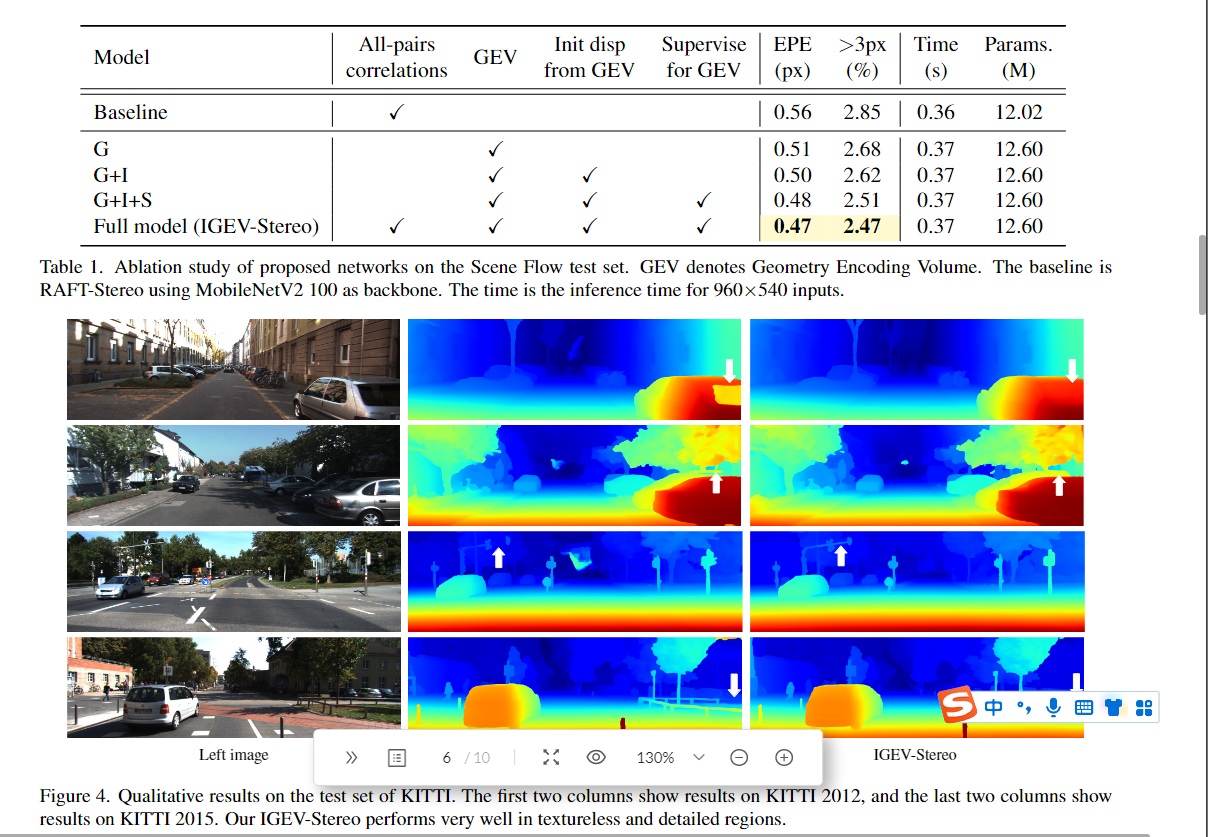
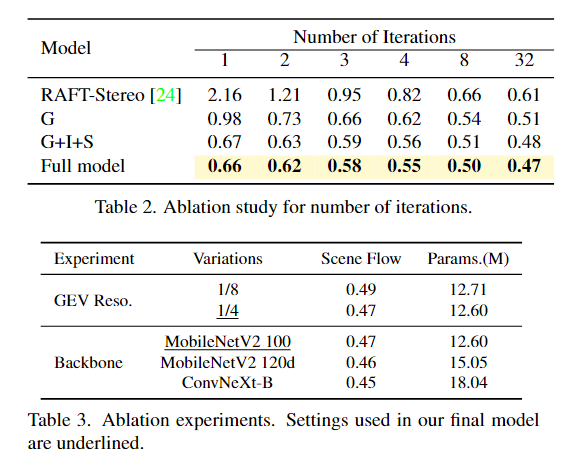

6. Conclusion
提出了一种新的用于立体匹配和多视点立体(MVS)的深层网络体系结构--迭代几何编码体积(IGEV)。IGEV构建对几何和上下文信息以及局部匹配细节进行编码的组合几何编码体,并迭代地对其进行索引以更新视差图。我们的IGEV-Stereo在所有已公布的方法中在Kitti 2015排行榜上排名第一,并实现了最先进的跨数据集泛化能力。我们的IGEV-MVS在DTU基准上也获得了具有竞争力的性能。我们使用一个轻量级的3D CNN来过滤成本量并获得GeV。然而,当处理表现出较大视差范围的高分辨率图像时,使用3D CNN来处理所产生的大尺寸代价体积仍然会导致较高的计算和存储成本。未来的工作包括设计一个更轻量级的正规化网络。此外,我们还将探索利用级联成本体的方法,使我们的方法适用于高分辨率图像。
------------
参考: 1.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号