【论文精读】RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching 【3DV (best paper) 2021】
title: HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching date: 2023-04-10 08:35:32 tags: 论文精读 轻量级
|
作者 |
Lahav Lipson 、 ZacharyTeed、Jia Deng |
|
单位 |
Princeton University |
|
代码 |
https://github.com/ princeton-vl/RAFT-Stereo |
|
期刊/会议 |
3DV (best paper) |
|
关键词 |
2021 |
0.摘要
We introduce RAFT-Stereo, a new deep architecture for rectified stereo based on the optical flow network RAFT [35]. We introduce multi-level convolutional GRUs, which more efficiently propagate information across the image. A modified version of RAFT-Stereo can perform accurate real-time inference. RAFT-stereo ranks first on the Middlebury leaderboard, outperforming the next best method on 1px error by 29% and outperforms all published work on the ETH3D two-view stereo benchmark. Code is available at https://github.com/ princeton-vl/RAFT-Stereo.- 问题:
光流估计成果RAFT到立体匹配领域的转化。
- 工作内容:
本文介绍了一种基于光流网络RAFT[35]的立体声整流深度架构RAFT- stereo。我们引入了多级卷积GRUs,它更有效地在图像上传播信息。改进后的RAFT-Stereo可以进行准确的实时推断。
- 效果:
RAFT-stereo在Middlebury 排行榜上排名第一,在1px误差上优于下一个最佳方法29%,并且在ETH3D双视图立体声基准上优于所有已发表的工作。
1. Introduction
光流与整流立体是密切相关的问题。在光流中,任务是预测像素位移场,这样对于第一帧中的每个像素,我们可以估计其在第二帧中的对应关系。在整流立体中,任务是相同的,除了我们有额外的约束,x位移总是正的,相应的点在一条水平线上——因此,y位移总是0。
尽管立体和流之间有相似之处,但这两种任务的神经网络架构却有很大的不同。在立体声中,主要的方法是使用三维卷积神经网络。首先通过枚举整数差异构建三维代价体,然后使用三维卷积网络对代价体进行过滤[43,4,19,12,47,48]。该公式利用立体几何作为网络设计中的归纳先验。然而,使用3D卷积来处理成本体积的计算成本很高,并且限制了可能的操作分辨率。需要专门的方法来处理高分辨率的图像,比如来自Middlebury数据集的百万像素图像。
另一方面,光流通常采用迭代细化的方法。RAFT[35]表明迭代细化完全可以在高分辨率下执行,提出了一个在标准流基准上表现良好的简单架构。RAFT首先从输入图像中提取特征,然后通过计算所有像素对之间的相关性来构建一个4D成本体积。最后,基于gru的更新操作符使用从相关卷检索的特征迭代地更新流场。
我们介绍RAFT-Stereo,一种新的双视点立体音响架构。我们的方法概述如图1所示。总体设计基于RAFT[35]。首先,我们只计算相同高度像素之间的视觉相似性,将全对4D相关体积替换为3D体积。此外,我们引入了多级GRU单元,通过交叉连接在多个分辨率上保持隐藏状态,但仍然生成单个高分辨率视差更新。这提高了更新操作符在图像中传播信息的能力,提高了视差场的全局一致性。
RAFT-Stereo与以前的立体声网络有本质上的不同。现有的工作通常依赖3D卷积网络处理立体代价体积。相比之下,RAFT-Stereo仅使用2D卷积和使用单个矩阵乘法构建的轻量级成本体积。通过避免3D卷积的高计算和内存成本,RAFT-Stereo可以直接应用百万像素图像,而不需要调整图像大小或对图像进行补丁处理。此外,通过使用迭代网络,我们可以很容易地用准确性换取早期停止的效率。RAFT-Stereo也不需要额外复杂的损失条款,使其易于训练。
我们的主要贡献是:
- 一个新的立体网络,它统一了立体和光流方法。
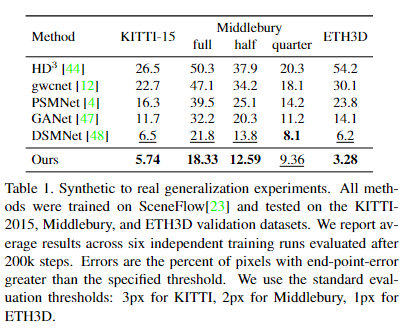
- RAFT-Stereo显示出比现有神经网络更好的跨数据集泛化能力。当只对合成数据进行训练时,我们的网络在诸如KITTI[24]、ETH3D[29]和Middlebury[28]等真实数据集上表现非常好,优于在相同设置下评估的所有其他工作。
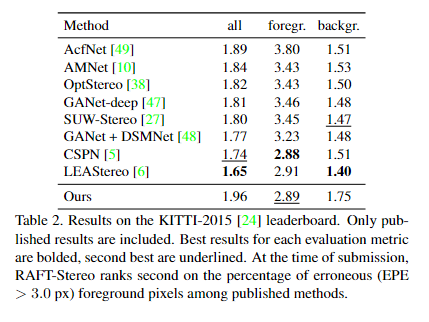
- 此外,raft立体声是准确的。它在Middlebury排行榜[28]上排名第一,并在ETH3D排行榜[29]上超越所有已发表的作品。
由于RAFT-Stereo算法具有较高的精度和较好的泛化性,我们相信它将成为一种有用的非自立体声算法。
2. Related Work
MC-CNN GCNET .......
虽然深度学习方法在KITTI[24]和FlyingThings3D[23]等数据集上优于传统方法,但3D卷积的计算成本很高,并且通常无法在外部进行推广
另一项工作是用更轻便的模块取代3D网络中更昂贵的组件。
3. Method
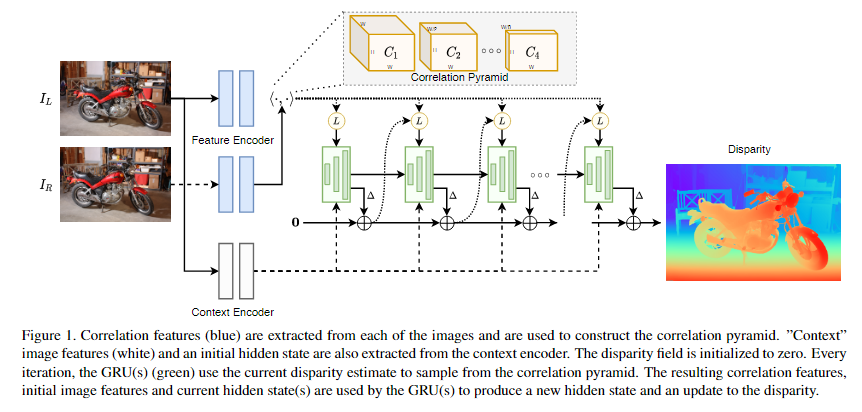
给定一对校正图像(IL, IR),我们的目标是估计一个视差场d,给出IL中每个像素的水平位移。与RAFT[35]类似,我们的方法由三个主要部分组成:特征提取器,相关金字塔和基于gru的更新算子,如图1所示。更新操作符迭代地从相关金字塔中检索特征,并对视差字段执行更新。
3.1. Feature Extraction
我们使用两个独立的特征提取器,称为特征编码器和上下文编码器。特征编码器应用于左右图像,并将每个图像映射到密集的特征映射,然后使用该特征映射构建相关体。该网络由一系列残差块和下采样层组成,根据实验中使用的下采样层的数量,以256通道的1/4或1/8输入图像分辨率生成特征映射。我们在特征编码器中使用实例规范化[37]。
上下文编码器与特征编码器具有相同的架构,只是我们用批处理规范化[17]取代了实例规范化,并且只在左侧图像上应用上下文编码器。上下文特征用于初始化更新操作符的隐藏状态,并在每次迭代更新操作符时注入GRU。
3.2 Correlation Pyramid关联金字塔
Correlation Volume:关联体积:
我们使用特征向量之间的点积作为视觉相似性的度量。与RAFT[35]通过计算所有像素对之间的视觉相似性来构建4D相关体类似,我们将相关体的计算限制在具有相同y坐标的像素上。给定分别从IL和IR中提取的feature mapsf, g∈RH×W ×D,可以通过修改4D体构建,将内积的计算限制为共享相同第一指标的特征向量,从而计算三维相关体:
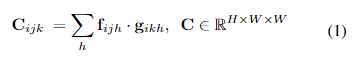
与4D体积一样,3D体积的计算可以使用单个矩阵乘法有效地实现,可以在GPU上轻松计算,并且只占用总运行时间的一小部分。在整流立体中,我们通常可以假设所有的差都是正的;因此,相关性体积实际上只需要计算正差异。然而,计算整个体积的优点是可以使用高度优化的矩阵乘法来实现操作。这简化了整体架构,允许我们使用通用操作,而不需要定制GPU内核。
Correlation Pyramid:相关金字塔:
通过对最后一个维度的重复平均池化,我们构建了一个4层的相关体积金字塔。金字塔的第k层是从k层的体积构建而来的,使用一维平均池化,内核大小为2,步长为2,产生一个新的体积Ck+1,尺寸为H × W × W/2k。金字塔的每一层都有一个增加的接受域,但通过只汇集最后一个维度,我们保持了原始图像中存在的高分辨率信息,这使我们能够恢复非常精细的结构
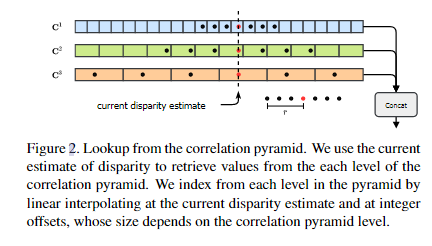
Correlation Lookup:相关性查找:
为了在相关性金字塔中建立索引,我们定义了一个类似于RAFT中定义的查找操作符LC。给定视差d的当前估计,我们在当前视差估计周围构造一个具有整数偏移的1D网格,如图2所示。网格用于从相关金字塔中的每个级别建立索引。由于网格值是实数,我们在索引每个卷时使用线性插值。然后将检索到的值连接到单个特征映射中。
3.3. Multi-Level Update Operator
我们预测了一系列视差场{d1,…, dN}从初始点d0 = 0开始。在每次迭代中,我们使用当前的视差估计来索引相关量,产生一组相关特征。这些特征通过2个卷积层传递。同样,当前的视差估计也通过2个卷积层传递。相关性、差异和上下文特征,然后连接并注入到GRU中。GRU更新隐藏状态。然后使用新的隐藏状态来预测视差更新。
Multiple Hidden States多个隐藏状态:
原始RAFT完全以固定的高分辨率执行更新。这种方法的一个问题是,随着GRU更新的数量,接收域的增长非常缓慢。这对于具有大的无纹理区域和很少的局部信息的场景来说是有问题的。我们通过提出一个多分辨率更新操作符来解决这个问题,该操作符同时在1/8、1/16和1/32分辨率的特征图上操作。在我们的实验中,我们证明了使用多分辨率更新操作符可以获得更好的泛化性能。
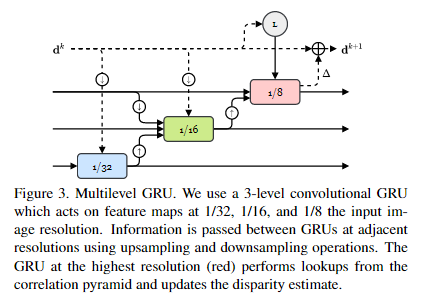
如图3所示,gru之间以彼此的隐藏状态作为输入进行交叉连接。相关性查找和最终的视差更新由GRU以最高分辨率执行。我们还实验了一个更高分辨率的模型,GRU更新的分辨率分别为输入图像的1/4、1/8和1/16。
Upsampling:上采样:
预测的视差场是输入图像分辨率的1/4或1/8。为了输出全分辨率的视差图,我们使用与RAFT相同的凸上采样方法。RAFT-Stereo将全分辨率视差值作为其粗分辨率邻居的3x3网格的凸组合。采用最高分辨率的GRU预测凸组合权重。
3.4. Slow-Fast GRU
与更新1/16分辨率的隐藏状态相比,将gru更新到1/8分辨率的隐藏状态需要大约4倍的flop。为了利用这一事实进行更快的推断,我们训练了一个版本的RAFT-Stereo,在这个版本中,我们对1/16和1/32分辨率隐藏状态进行多次更新,每次更新到1/8分辨率隐藏状态。在32次GRU更新的KITTI分辨率图像上,这个简单的更改将RAFTStereo的运行时间从0.132秒减少到0.05秒,减少了52%。见表6。
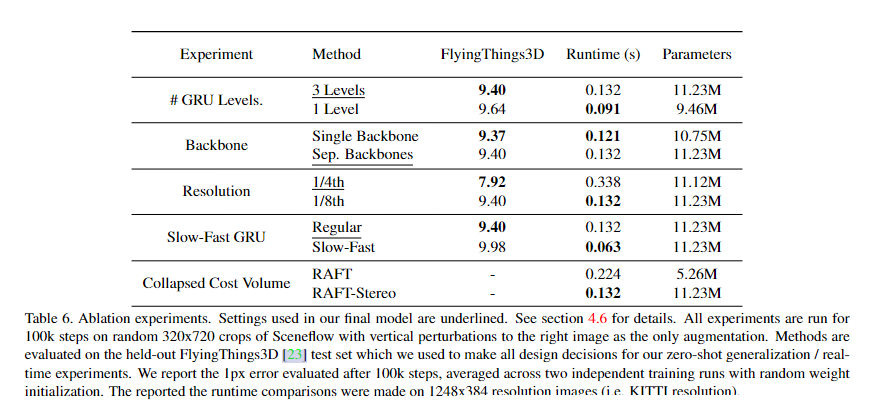
这种修改使我们能够实现与最先进的实时立体视觉方法相竞争的性能,使用RAFT-Stereo(见第4.7节),该方法的运行速度快了一个数量级。
3.5. Supervision
我们在整个预测序列上监督预测和实际真相差异之间的l1距离,{d1,…, dN},权值呈指数增长。给定地真值差dgt,损失定义为
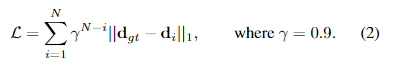
5. Experiments
我们在ETH3D [29], Middlebury[28]和KITTI-2015[24]上评估RAFT-Stereo。在之前的工作之后,我们在合成的scenflow数据集[23]上预训练我们的模型。我们的方法在ETH3D和Middlebury排行榜上实现了最先进的性能,并且我们在ETH3D, KITTI和Middlebury上的零射击泛化设置中优于现有的方法。
RAFT-Stereo is implemented in Pytorch [26] and is trained using two RTX 6000 GPUs. A

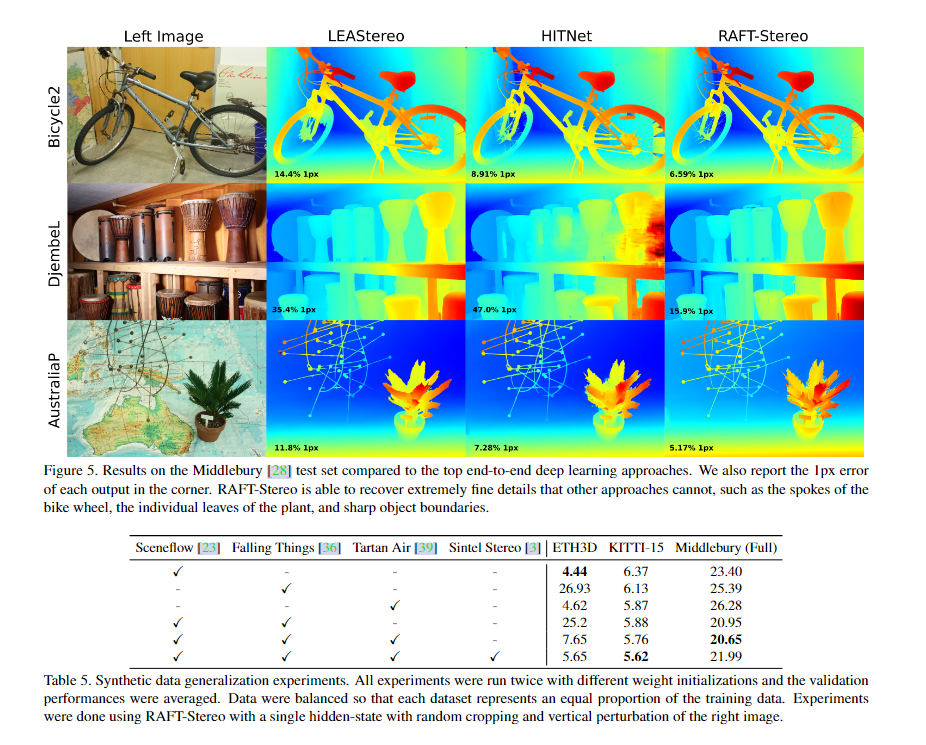
6. Conclusion
我们提出了一种新的基于RAFT[35]的双视图立体深度架构RAFT-Stereo。RAFT- stereo通过利用多级gru有效地在图像上传递信息来扩展RAFT。我们的方法实现了最先进的跨数据集泛化,在Middlebury基准中排名第一,优于所有在ETH3D上发表的工作。
------------
参考: 1.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号