【论文精读】CRE-Stereo:Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation (CVPR 2022)
title: CRE-Stereo:Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation date: 2023-04-23 14:27:18 tags: 论文精读
|
作者 |
Jiankun Li1 Peisen Wang1* Pengfei Xiong2* Tao Cai1 Ziwei Yan1 Lei Yang1Jiangyu Liu1 Haoqiang Fan1 Shuaicheng Liu3,1† |
|
单位 |
旷视研究院、腾讯、电子科技大学 |
|
代码 |
https://github.com/megvii-research/CREStereo |
|
期刊/会议 |
CVPR |
|
关键词 |
2022 |

0.摘要
- 问题:
由于结构薄、校正不理想、摄像头模块不一致和各种硬壳场景等实际复杂因素,从智能手机等消费级设备拍摄的真实世界图像对中准确提取差异仍然是一个巨大的挑战。
- 工作内容:
在本文中,我们提出了一套创新的设计来解决实际的立体匹配问题:
1)为了更好地恢复精细的深度细节,我们设计了一个递归细化的分层网络来以从粗到精的方式更新视差,并设计了一个堆叠的级联结构来进行推理;
2)我们提出了一个自适应的组相关层来减轻错误纠正的影响;
3)我们引入了一个新的合成数据集,特别关注了困难的情况,以便更好地概括到真实场景。
- 效果:
我们的结果不仅在Middlebury和ETH3D基准测试中排名第一,远远超过现有最先进的方法,而且还展示了真实照片的高质量细节,这清楚地证明了我们贡献的有效性。
1. Introduction
然而,要使该算法在日常消费摄影场景中真正实用,我们仍然面临三大障碍。首先,对于大多数现有的算法来说,精确地恢复精细图像细节或薄结构(如网状物和线框)的视差仍然是一个复杂的问题。消费者照片是以更高分辨率制作的,这一事实只会让问题变得更糟。其次,对于真实世界的立体图像对,很难获得完美的校正,因为它们通常是由具有不同的特征。最后,虽然已经证明从足够大的合成数据集训练的模型可以很好地推广到真实世界场景,但在典型的困难情况下,如非纹理或重复纹理区域,视差估计仍然是困难的,这需要特别注意覆盖训练数据集中的相关场景。
在本文中,我们提出了CREStereo,即级联递归立体匹配网络,它包含了一系列新颖的设计,以解决实际的立体匹配问题。为了更好地恢复复杂的图像细节,我们设计了一个分层网络,以从粗到精的方式递归地更新视差;此外,我们还采用了堆叠的级联结构来进行高分辨率推理。为了减轻校正误差的负面影响,我们设计了一种自适应分组局部相关层进行特征匹配。此外,为了更好地推广到真实场景,我们引入了一个新的合成数据集,该数据集在光照、纹理和形状方面具有更丰富的变化。到目前为止,CREStereo在ETH3D双视立体声[36]和Middlebury[35]基准测试中都排名第一,在已发表的方法中,CREStereo在Kitti 2012/2015[11]上取得了具有竞争力的性能。此外,我们的网络在任意真实世界场景下表现出了卓越的性能,很好地证明了我们设计的有效性。
我们的主要贡献可以概括如下:
- 1)我们提出了一个用于实际立体匹配的级联递归网络和一个用于高分辨率推理的层叠结构;
- 2)我们设计了一个自适应组相关层来处理非理想校正;
- 3)我们创建了一个新的合成数据集,以更好地推广到真实场景;
- 4)我们的方法在公共基准测试(如Middlebury和ETH3D)上的性能明显优于现有的方法,并显著提高了真实世界立体图像恢复视差的精度。
2. Related Work
- Traditional algorithms.
- Learning-based algorithms.
- Practical stereo matching
- Synthetic datasets.
3. Method
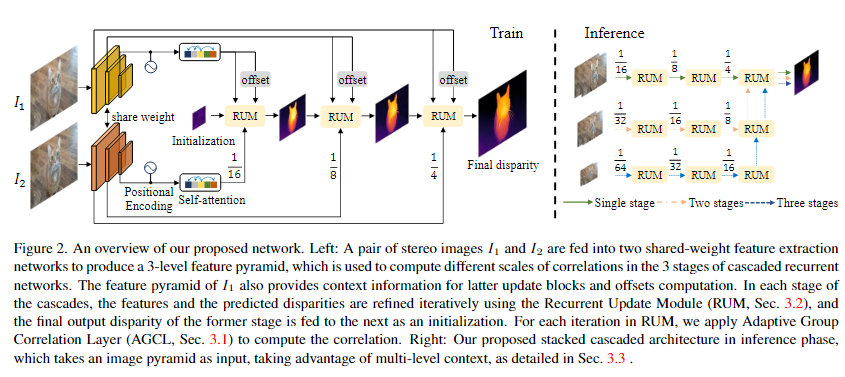
在这一部分中,我们介绍了提出的级联递归立体匹配网络(CREStereo)的关键组件和我们新的合成数据集。
3.1. Adaptive Group Correlation Layer
我们观察到,对于真实世界的立体摄像机来说,很难实现完美的标定。因此,对于立体图像对,对应的点可能不在同一扫描线上。
因此,我们提出了一种自适应组相关层(AGCL)来减少这种情况下的匹配模糊性,与仅计算局部相关性的所有对匹配[23,45]相比,获得了更好的性能。
Local Feature Attention.
该算法不需要计算每一对像素的全局相关性,而是只在局部窗口中进行点匹配,避免了较大的内存消耗和计算代价。在稀疏特征匹配的LoFTR[41]的基础上,我们在第一级级联的相关性计算之前增加了注意力模块,以便在单一或交叉特征映射中聚合全局上下文信息。在[41]之后,我们将位置编码添加到主干输出,这增强了特征图的位置相关性。自我注意和交叉注意是交替计算的,其中使用线性注意层来降低计算复杂度。
2D-1D Alternate Local Search.
与光流估计网络RAFT[45]及其立体匹配版本[23]不同的是,所有对的相关性是通过两个C×H×W特征映射的矩阵相乘来计算的,其输出的是4D:H×W×H×W或3D:H×W×W代价体积,而我们只在输出小得多的H×W×D体积的局部搜索窗口中计算相关性,以节省存储和计算成本。
我们的相关性计算也不同于像[7,18,49,51]这样的基于成本量的立体网络,其中搜索范围与前景对象的最大位移相关。这个固定的范围比我们使用的本地相关对的数量大得多,这会导致更多的噪声干扰。此外,当模型推广到具有不同基线的立体声对时,我们不需要预先设置范围。给定两个重采样和参与的特征地图F1和F2,位置(x,y)处的局部相关性可表示为
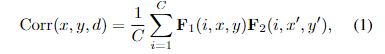
其中x‘=x+f(D),y’=y+g(D),Corr(x,y,d)∈RH×W×D是第d(d∈[0,D−1])个相关对的匹配代价,C是特征通道的数目,f(D)和g(D)表示当前像素在水平和垂直方向上的固定偏移。传统上,搜索d
在传统的立体匹配中,两幅矫正图像之间的搜索方向只在极线上。针对非理想的立体矫正情况,采用2D-1D交替局部搜索策略来提高匹配精度。在一维搜索模式下,我们设置g(D)=0和f(D)∈[−r,r],其中r=4。保留f(D)的正位移值,以便在每次迭代采样后调整不准确的结果。计算结果与公式计算结果一致。1在通道维度上被堆叠和连接,用于最终的相关体积。在2D搜索模式中,使用具有类似于膨胀卷积[53]的膨胀l的k×k网格来进行相关计算。我们设置k=(√2R+1)以确保输出-特征具有相同数量的通道,以便它们可以被馈送到共享权重更新块。与迭代重采样协作,交替局部搜索还充当循环求精的传播模块,其中网络学习用更准确的邻居来取代对当前位置的有偏预测。
Deformable search window.
立体匹配通常在遮挡或无纹理区域中受到歧义的影响。在固定形状的局部搜索窗口中计算的相关性往往容易受到这些情况的影响。将可变形卷积[57]扩展到相关性计算中,我们使用内容自适应搜索窗口来生成相关对,这与AANet[49]中仅在代价聚集中采用类似的策略不同。利用学习到的附加偏移量dx和dy,新的相关性可以计算为
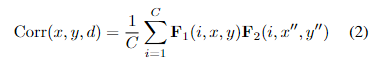
式中x‘’=x+f(D)+dx,y‘’=y+g(D)+dy。图4示出了偏移如何改变传统搜索窗口的形成。
Group-wise correlation
受文献[12]引入分组4D成本量的启发,我们将特征图分成G组,分别计算局部相关性。最后,将d×H×W的G相关体级联在通道维度上,得到G D×H×W的输出量。程序如图3所示。
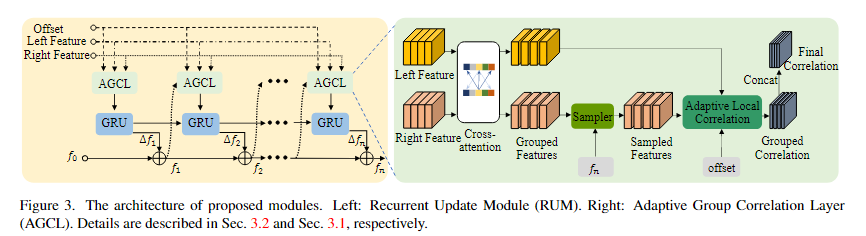
对于非纹理或重复纹理区域,使用低分辨率和高层次特征映射的匹配更稳健,因为它具有较大的接受场和足够的语义信息。然而,精细结构的细节可能会在这样的特征地图中丢失。为了在保持鲁棒性的同时保留高分辨率输入中的细节,我们提出了级联递归求精的相关性计算和视差更新
Recurrent Update Module.
我们基于GRU块和我们的自适应组相关层(AGCL)构建了一个递归更新模块(RUM)。不像在RAFT,当特征金字塔被构建在单个相关层中,输出被合并到一个体积中时,我们分别计算不同级联级别的每个特征地图的相关性,并独立地对几次迭代的差异进行细化。如图3所示,采样器以从fn导出的坐标网格为输入对分组特征的位置进行采样。{f1,...,fn}是具有初始化f0的n次迭代的中间预测。当前相关体积由学习偏移量o∈R2×(2R+1)×h×w构成,GRU块更新当前预测并在下一次迭代中将其反馈给AGCL。
Cascaded Refinement.
除了第一级级联以输入分辨率的1/16开始,并且视差值被初始化为全零之外,其他级联采用上一级预测的上采样版本作为初始化。尽管处理不同级别的提纯,所有朗姆酒都具有相同的权重。在最后的精化级别之后,进行凸上采样[45]以获得输入分辨率的最终预测。
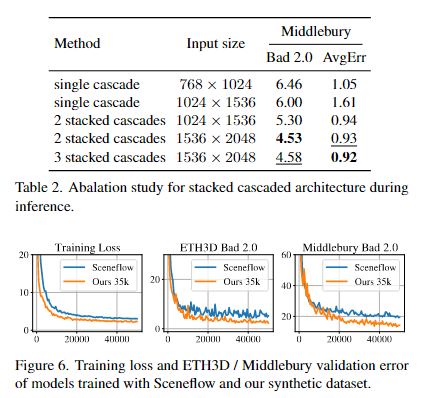
3.3. 用于推理的堆叠级联 Stacked Cascades for Inference
正如前面几节所讨论的,在训练期间,我们使用固定分辨率的三级特征金字塔来进行分层细化。然而,对于分辨率较高的图像作为输入,为了扩大特征提取和相关计算的接受范围,需要进行更多的下采样。但是对于高分辨率图像中位移较大的小目标,这些区域的特征可能会随着直接下采样而恶化。为了解决这个问题,我们设计了一种具有推理快捷方式的堆叠级联体系结构。具体来说,我们对图像对进行下采样,构建一个图像金字塔,并将它们送入同一个训练好的特征提取网络,以利用多层上下文。图2的右侧显示了堆叠级联体系结构的概述,其中为简洁起见没有显示同一级中的跳过连接。对于堆叠级联的特定级(在图2中表示为行),该级中的所有朗姆酒将与较高分辨率级中的最后一级朗姆酒一起使用。在训练期间,堆叠的级联的所有阶段都分担相同的重量,因此不需要进行微调。
3.4. Loss Function
对于特征金字塔的每个阶段的∈{1 /16,1 /8,1/ 4},我们使用上采样操作符μs将输出序列{f si,···,f s n}的大小调整到完全预测分辨率,并使用类似于RAFT[45]的指数加权L1距离作为损失函数(γ设置为0.9时)。给定地面实况差异DGT,总损失定义为:
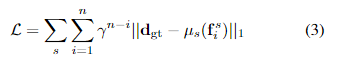
3.5. Synthetic Training Data
与以前的合成数据集相比,我们的数据生成管道特别关注现实世界场景中具有挑战性的情况,并具有各种增强功能。我们利用Blender[3]来生成我们的合成训练数据。每个场景由左右图像对和对应的像素精确的密集视差图组成,由双虚拟摄像机和常规定位的对象捕获。我们的主要设计考虑如下所示,一些例子如图5所示。
Shape.
我们通过多个来源使用作主要场景内容的模型的形状多样化:1)ShapeNet[6]数据集,包含40,000多个具有不同形状的常见对象的3D模型,构成了我们的基本内容来源。2)Blender的树苗Gen附加组件,提供精细且杂乱的视差图。3)我们使用搅拌器的内部基本形状与线框修改器相结合来生成具有挑战性的场景的模型,这些场景具有洞和开放式结构。
Lighting and texture.
我们将不同类型的随机颜色和亮度的灯光放置在场景内部的随机位置,从而产生复杂的照明环境。真实世界的图像被用作物体和场景背景的纹理,特别是包含重复图案或缺乏可见特征的硬场景。此外,我们利用Blender的Cycle渲染器的光线跟踪能力,随机设置对象为透明或具有金属反射的对象,以覆盖具有相似属性的真实场景
Disparity distribution.
为了覆盖不同的基线设置,我们努力确保生成的数据的差异在大范围内平稳分布。我们将物体放置在由摄像机的视场和最大距离形成的锥形空间内。从概率分布中随机选择每个对象的确切位置,然后根据对象的距离对对象进行缩放,以防止遮挡视线。这种做法会产生随机化但可控的视差分布。
4. Experiments
4.1. Datasets and Evaluation Metrics
我们在三个流行的公共基准上对我们的方法进行了评估。
- Middlebury 2014[33]提供了23个不同照明环境下的高分辨率图像对。通过大基线立体摄像机拍摄,米德尔伯里的最大视差可以超过600像素。
- ETH3D[36]由27个单色立体图像对组成,其中的视差由激光扫描仪采样,覆盖室内和室外场景。
- KITTI2012/2015[28]由200对广角立体街景图像组成,带有激光采样稀疏视差地面真相。
除了我们呈现的数据集,我们还收集用于训练的主要公共数据集,包括Sceneflow[27]、Sintel[5]和Flowing Things[46]。
- Sceneflow包含39K对多个合成场景设置的训练对。
- Falling things包含了大量家庭物体模型的场景图像。
- Sintel提供来自各种合成序列的1.2K立体声对。
- 我们使用的其他数据源是InStereo2K[1]、Carla[9]和AirSim[37]。
在评价方面,我们遵循了AvgErr(平均误差)、Bad2.0(视差误差大于2像素的像素百分比)[35、36]、D1-ALL(左侧图像中视差异常像素的百分比)[11]等流行的度量标准。
4.2. Implementation Details
The model is trained on 8 NVIDIA GTX 2080Ti GPUs, with a batch size of 16. The whole training process is set to 300,000 iterations.
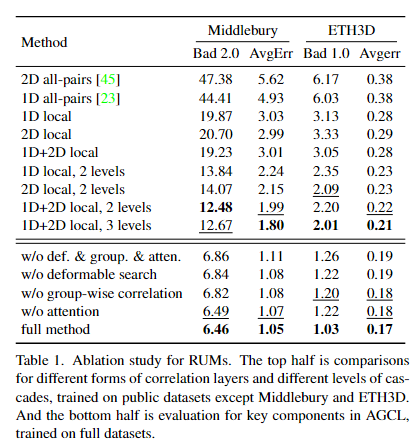
4.3. Ablation Study
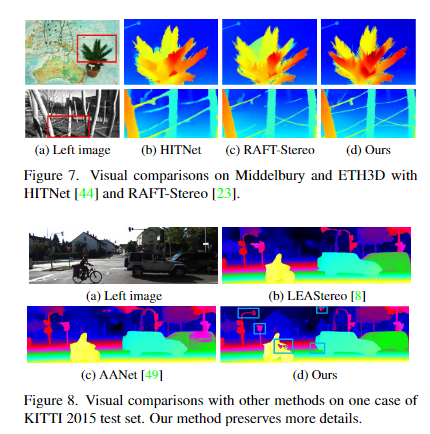
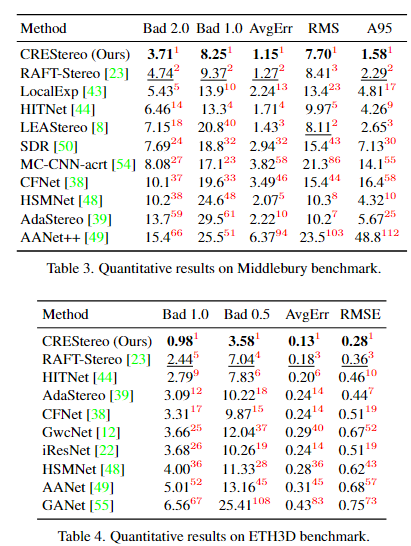
5. Conclusion
尽管深度立体声网络取得了前所未有的成功,但在准确恢复现实世界场景中的差异方面仍然存在障碍。在本文中,我们提出了CREStereo,这是一个新颖的立体匹配网络,在公共基准和现实场景中都取得了最先进的结果。我们在这里要传达的关键信息是,网络架构和训练数据都需要经过严格的考虑,才能使算法在现实世界中真正发挥作用。通过具有自适应相关性的级联递归网络,我们能够比现有方法更好地恢复精细的深度细节;通过精心设计我们的合成数据集,我们设法更好地处理非纹理或重复纹理区域等硬场景。我们方法的一个局限性是该模型还不够高效,不能在当前的移动应用中运行。未来可以进行改进,使我们的网络适应各种便携式设备,最好是实时的。
------------
参考: 1.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号