【论文精读】HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching(CVPR 2021))
title: HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching date: 2023-04-10 08:35:32 tags: 论文精读 轻量级
|
作者 |
Vladimir Tankovich, Christian H ̈ane, Yinda Zhang, Adarsh Kowdle, Sean Fanello, Sofien Bouaziz |
|
单位 |
谷歌Google |
|
代码 |
https://github.com/google-research/google-research/tree/master/hitnet |
|
期刊/会议 |
CVPR |
|
关键词 |
2021 |
0.摘要
- 问题:
- 工作内容:
提出了一种用于实时立体匹配的新型神经网络结构HITNet。与最近许多基于完整成本体积并依赖3D卷积的神经网络方法相反,我们的方法并没有明确地构建体积,而是依赖于快速多分辨率初始化步骤、可微分的2D几何传播和warping机制来推断视差假设。为了达到高水平的精度,我们的网络不仅从几何上对差异进行推理,还推断倾斜的平面假设,从而更准确地执行几何翘曲和上采样操作。我们的架构本质上是多分辨率的,允许跨不同级别的信息传播。多个实验证明了该方法的有效性,其计算量仅为最先进方法所需计算量的一小部分。
- 效果:
HITNet在ETH3D网站上发布的双视立体声的所有指标中排名第1,在Middlebury-v3上所有端到端学习方法中的大多数指标中排名第1,在发布的速度超过100毫秒的流行KITTI 2012和2015基准中排名第1。

1. Introduction
最近对立体匹配深度的研究主要集中在开发准确但计算昂贵的深度学习方法上。大型卷积神经网络(CNNs)通常可以使用长达一秒甚至更长的时间来处理图像对并推断视差图。对于诸如移动机器人或自动驾驶汽车之类的主动代理来说,这样的高延迟是不希望的,而是需要能够在几毫秒内处理图像对的方法。尽管如此,在KITTI 2012排行榜上排名前100的方法中,只有4种是已发表的方法,耗时不到100毫秒1
基于端到端学习的计算立体方法中的一个常见模式是使用CNN,它基本上不知道立体匹配问题的几何财产。事实上,最初的端到端网络是基于通用的U-Net架构[38]。随后的工作指出,结合对像素分配视差的成本进行编码的显式匹配成本体积,结合3D卷积,在精度方面提供了显著的改进,但代价是显著增加了计算量[24]。后续工作[25]表明,下采样成本量可以在速度和准确性之间提供合理的权衡。然而,成本量的下采样是以牺牲准确性为代价的
最近的多种立体匹配方法[52,12,28]提高了主动立体视差估计的效率,同时保持了高水平的精度。这些方法主要基于三个直觉:首先,使用紧凑/稀疏特征进行快速高分辨率匹配成本计算;其次,非常有效的视差优化方案,不依赖于全部成本量;第三,使用倾斜平面进行迭代图像扭曲,以通过最小化图像差异来实现高精度。所有这些设计选择都是在没有明确操作整个3D成本体积的情况下使用的。通过这样做,这些方法为主动立体声实现了非常快速和准确的结果,但由于缺乏强大的机器学习系统,它们不能直接推广到被动立体声。
我们提出了HITNet,这是一种基于神经网络的深度估计框架,通过将图像扭曲、空间传播和快速高分辨率初始化步骤集成到网络架构中,克服了在3D体积上操作的计算缺点,而1其他速度超过100ms的方法也在排行榜上,但算法尚未公布,因此不知道结果是如何实现的。通过允许特征在网络中流动来保持学习表示的灵活性。我们方法的主要思想是将图像瓦片表示为平面贴片,平面贴片上附有学习的紧凑特征描述符。我们方法的基本原理是使用空间传播融合来自高分辨率初始化和当前假设的信息。传播是通过卷积神经网络模块实现的,该模块更新平面补丁及其附加特征的估计。为了使网络迭代地提高视差预测的准确性,我们使用网络内图像扭曲为网络提供了平面补丁周围窄带(±1视差)中的局部成本体积,从而使网络能够最大限度地减少图像差异。为了重建精细的细节,同时捕捉大的无纹理区域,我们从低分辨率开始,并将分层上采样预测提高到更高的分辨率。我们体系结构的一个关键特征是,在每个分辨率下,都提供来自初始化模块的匹配,以便于恢复无法在低分辨率下表示的薄结构。我们方法的示例输出显示了我们的网络如何恢复图1中非常精确的边界、精细的细节和薄结构。1。
我们的主要贡献是:
- 快速多分辨率初始化步骤,使用学习的特征计算高分辨率匹配。
- 一种有效的2D视差传播,利用带有学习描述符的倾斜支持窗口。
- 与其他方法相比,目前流行的基准测试使用了一小部分计算。
2. Related Work
几十年来,立体匹配一直是一个活跃的研究领域[37,44,19]。传统方法利用手工制作的方案来寻找局部对应[57,22,4,21],并利用全局优化来利用空间上下文[14,26,27]。大多数这些方法的运行时效率与视差空间的大小相关,这阻碍了实时应用。高效算法[31,35,5,3]通过使用patchmatch[1]和超像素[31]技术来避免搜索全视差空间。一系列基于机器学习的方法,使用随机森林和决策树,能够快速建立对应关系[10,11,12,13]。然而,这些方法需要特定于相机的学习或后期处理。最近,深度学习为立体匹配带来了巨大的改进。早期的工作训练连体网络来提取补丁特征或预测匹配成本[36,60,58,59]。已经提出了端到端网络来联合学习所有步骤,从而产生更准确的结果[47,38,41,48]。
现代架构中的一个关键组件是成本-体积层[24](或相关层[23]),允许网络运行每像素特征匹配。为了加快计算速度,已经提出了级联模型[40,7,33,16,54,61],以从粗到细的方式在视差空间中进行搜索。特别地,[40]使用多个残差块来改进当前视差估计。最近的工作[54]依赖于分层成本量,允许在高分辨率图像上训练该方法,并根据需要生成不同的分辨率。所有这些方法都依赖于使用3D卷积[54]或多个细化层[40]的昂贵成本的体积滤波操作,从而妨碍了实时性能。快速方法[25,62]在空间和视差空间中对成本体积进行下采样,并试图通过边缘感知上采样层来恢复精细细节。这些方法显示了实时性能,但牺牲了精度,尤其是对于薄结构和边缘,因为它们在低分辨率初始化中缺失。
我们的方法受到经典立体匹配方法的启发,这些方法旨在传播良好的稀疏匹配[12,13,52]。特别是,Tankovich等人[52]提出了一种分层算法,该算法利用倾斜的支持窗口来分摊瓦片中的匹配成本计算。受这项工作的启发,我们提出了一种端到端的学习方法,该方法克服了手工制作算法的问题,同时保持了计算效率。
PWC Net[50]虽然是为光流估计而设计的,但与我们的方法有关。该方法通过图像扭曲和局部匹配成本计算,使用具有多个细化阶段的低分辨率成本体积。从而遵循经典的金字塔匹配方法,在该方法中,通过用先前级别的解决方案初始化当前级别来对低分辨率结果进行分层上采样和细化。相比之下,我们提出了一种快速、多尺度、高分辨率的初始化,它能够恢复在低分辨率下无法表示的精细细节。最后,我们的细化步骤产生局部倾斜平面近似,用于预测最终的差异,而不是[50]中使用的标准双线性扭曲和插值。
3. Method
HITNet的设计遵循了传统立体声匹配方法的原理[44]。特别是,我们观察到最近的有效方法依赖于以下三个步骤:
- 1©提取紧凑的特征表示[12,13];
- 2©高分辨率视差初始化步骤利用这些特征来检索可行的假设;
- 3©有效的传播步骤使用倾斜的支撑窗口来细化估计[52]。
受这些观察结果的启发,我们将视差图表示为不同分辨率的平面瓦片,并将可学习的特征向量附加到每个瓦片假设(第3.1节)。这使我们的网络能够了解关于视差图的一小部分的哪些信息与进一步改进结果相关。这可以被解释为可学习的3D成本量的有效和稀疏版本,已被证明是有益的
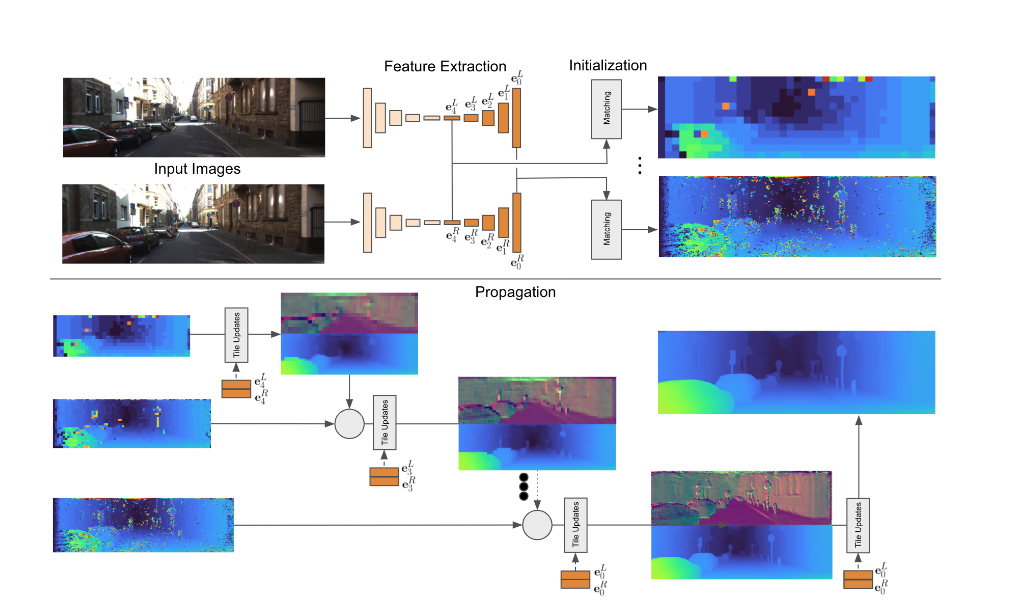
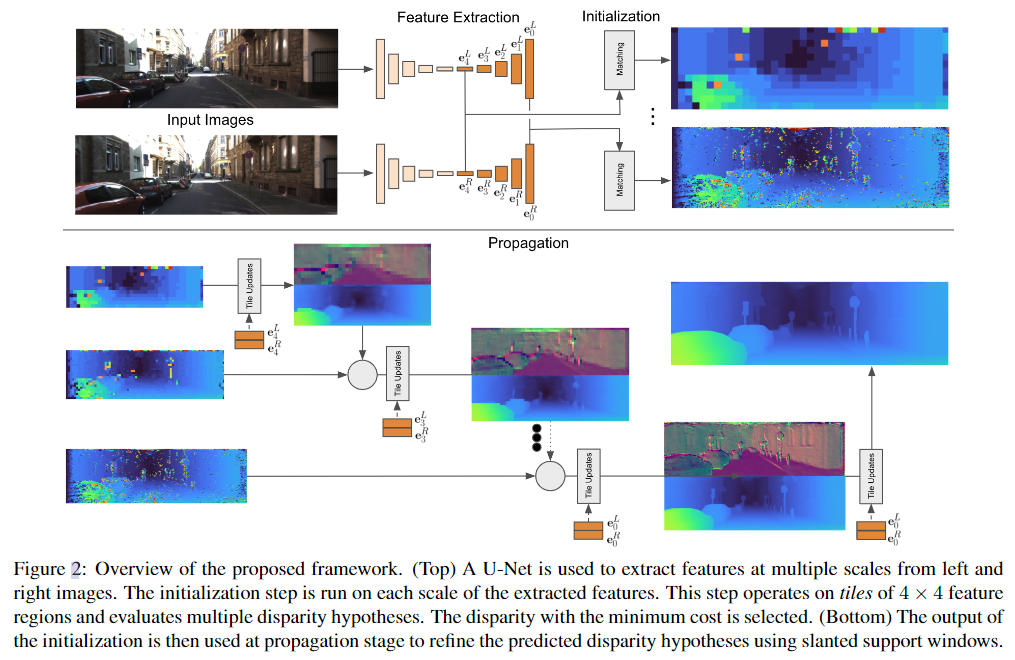
总体方法如图2所示。我们的特征提取模块依赖于非常小的U-Net[42],其中解码器的多分辨率特征被其他管道使用。这些特征编码图像的多尺度细节,类似于[7](第3.2节)。提取特征后,我们将视差图初始化为多分辨率的前向平行平铺。为此,匹配器评估多个假设,并选择左视图和右视图特征之间距离最小的假设。此外,使用小网络计算每个瓦片的紧凑描述符(第3.3节)。然后将初始化的输出传递到传播阶段,其作用类似于[12,52]中使用的近似条件随机场解。该阶段以迭代方式分层细化瓦片假设(第3.4节)。
3.1. Tile Hypothesis
我们将瓦片假设定义为带有可学习特征的平面补丁。具体而言,它由描述具有视差和x和y方向(dx,dy)视差梯度的倾斜平面的几何部分和可学习部分p组成,我们称之为瓦片特征描述符。因此,假设被描述为对倾斜的3D平面进行编码的向量,
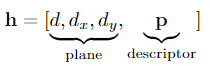
瓦片特征描述符是瓦片的学习表示,其允许网络将附加信息附加到瓦片。例如,这可能是匹配质量或局部曲面财产,例如几何体的实际平面度。我们不限制此信息,而是从数据中端到端地学习它。
3.2. Feature Extractor
特征提取器提供一组多尺度特征图E={e0,…eM},用于初始匹配和传播阶段的扭曲。我们将特征图表示为el,并将嵌入向量el,x,y表示为分辨率为l∈0...M,0是原始图像分辨率,M表示2M×2M下采样分辨率。单个嵌入向量el,x,y由多个特征通道组成。我们将特征提取器E=F(I;θF)实现为类似U-Net的架构[42,34],即具有跳跃连接的编码器-解码器,具有可学习参数θF。该网络由跨步卷积和转置卷积组成,其中漏ReLU为非线性。我们在网络的其余部分是U-Net的上采样部分在所有分辨率下的输出。这意味着即使是高分辨率特征也包含一定量的空间上下文。更详细地说,U-Net的一个下采样块具有单个3×3卷积,然后是具有步长2的a2×2卷积。一个上采样块将2×2步长2转置卷积应用于较粗U-Net分辨率的上采样结果。特征通过跳过连接连接,然后应用1×1卷积和3×3卷积来合并当前分辨率的跳过和上采样特征。每个上采样块生成特征图el,然后将其用于下游任务,并在UNet中进一步上采样以生成更高分辨率的特征图。我们在左图像和右图像上运行特征提取器,并获得两个多尺度表示EL和ER。
3.3. Initialization
初始化的目标是在各种分辨率下提取每个瓦片的初始视差disni和特征向量pinit。初始化的输出是形式为hinit=[dniti,0,0,pinit]的前沿平行瓦片假设。瓦片视差。为了保持最初的冷静
Tile Disparity.。为了保持初始视差分辨率高,我们在右(次)图像中沿x方向(即宽度)使用重叠瓦片,但我们仍然在左(参考)图像中使用非重叠瓦片进行有效匹配。为了提取瓦片特征,我们对每个提取的特征图el进行4×4卷积。左(参考)图像和右(次)图像的步长不同,以便于上述重叠的瓦片。对于左侧图像,我们使用4×4的步长,对于右侧图像,我们采用4×1的步长,这对于保持全视差分辨率以最大限度地提高精度至关重要。该卷积之后是泄漏的ReLU和MLP。
这一步骤的输出将是一组新的特征图,E={e0,…,eM},每个瓦片的特征为el,x,y。请注意,EL和ER中的特征图的宽度现在不同了。每个瓦片的特征沿着扫描线被明确地匹配。我们将具有视差d的位置(x,y)和分辨率l处的匹配成本定义为:
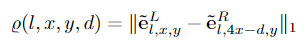
然后将初始差异计算为:
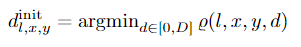
对于每个(x,y)位置和分辨率l,其中D是所考虑的最大视差。请注意,尽管初始化阶段会进行详尽的计算匹配所有差异-不需要存储整个成本量。在测试时,只需要提取最佳匹配的位置,这可以利用快速存储器非常有效地完成,例如GPU上的共享存储器和单个操作中的融合实现。因此,不需要存储和处理3D成本量。
Tile Feature Descriptor. 初始化阶段还预测每个(x,y)位置和分辨率l的特征描述pinitl,x,y:
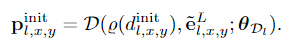
这些特征基于参考图像的嵌入向量eL l,x,y和最佳匹配视差的代价%。我们使用感知器D,具有可学习的权重θD,该感知器通过1×1卷积和泄漏的ReLU来实现。瓦片特征描述符的输入包括匹配成本%(·),这允许网络获得匹配的置信度。
3.4. Propagation
传播步骤将瓦片假设作为输入,并基于信息的空间传播和信息的融合输出细化的瓦片假设。它在内部将特征提取阶段的特征从右图像(次图像)扭曲到左图像(参考图像),以便预测到输入块的高精度偏移。预测了额外的置信度,该置信度允许来自早期传播层和初始化阶段的假设之间的有效融合。
Warping.扭曲步骤计算与瓦片相关联的特征分辨率l下的特征图eL l和eR l之间的匹配成本。此步骤用于围绕当前假设建立本地成本量。每个瓦片假设都被转换成一个尺寸为4×4的平面补丁,它最初覆盖在特征图中。我们将对应的4×4局部视差图表示为d′,其中
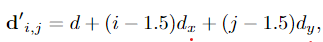
对于面片坐标i,j∈{0,··,3}。然后使用局部视差来使用沿着扫描线的线性插值将特征eR l从右(次)图像扭曲到左(参考)图像。这导致扭曲的特征表示eR′l,如果局部视差图d′是准确的,则其应该与左(参考)图像eL的相应特征非常相似。比较参考(x,y)瓦片和翘曲的次瓦片的特征,我们将成本向量φφ(e,d′)∈R16定义为:
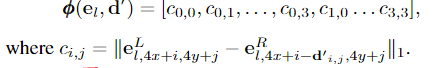
Tile Update Prediction.该步骤以n个瓦片假设作为输入,并预测瓦片假设的增量加上每个瓦片的标量值w,该标量值w指示该瓦片是正确的可能性,即置信度测量。该机制被实现为CNN模块U,卷积架构允许网络在空间邻域中看到瓦片假设,因此能够在空间上传播信息。这一步骤的一个关键部分是,我们用翘曲步骤的匹配成本φφ来扩充瓦片假设。通过对视差空间中的一个小邻域这样做,我们建立了一个局部成本量,这使得网络能够有效地细化瓦片假设。具体地说,我们将瓦片中的所有差异在正方向和负方向上移动一个差异1的恒定偏移,并计算三次成本。使用此设a为输入瓦片映射h的扩充瓦片假设映射:
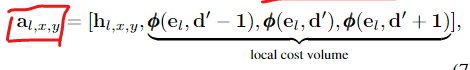
对于位置(x,y)和分辨率l,CNN模块Ulthen预测n个瓦片假设映射中的每一个的更新,以及表示瓦片假设的置信度的wi∈R:
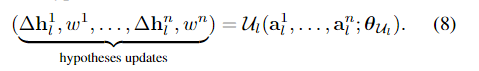
U的体系结构是用残差块[20]实现的,但没有批量归一化。在[25]之后,我们使用扩张卷积来增加感受野。在运行具有不同膨胀因子的残差块序列之前,我们运行1×1卷积,然后运行泄漏的ReLU,以减少特征通道的数量。更新模块以分层迭代的方式应用(见图2)。在最低分辨率l=M下,从初始化阶段开始,每个位置只有1个瓦片假设,hencen=1。我们通过对输入瓦片假设和增量求和来应用瓦片更新,并在每个方向上以因子2对瓦片进行上采样。从而,使用瓦片的平面方程对视差d进行上采样,并且使用最近邻采样对瓦片假设dx、dy和p的剩余部分进行上采样。在下一个分辨率M−1下,我们现在有两个假设:一个来自初始化阶段,另一个来自较低分辨率的上采样假设,因此n=2。我们利用wi为每个位置选择具有最高置信度的更新瓦片假设。我们迭代这个过程,直到达到分辨率0,这对应于我们所有实验中的瓦片大小4×4和全视差分辨率。为了进一步细化视差图,我们使用4×4瓦片的获胜假设,并应用传播模块3次:对于4×4、2×2、1×1分辨率,使用n=1。瓦片大小为1×1的输出是我们的最终预测。补充材料中提供了有关网络架构的更多细节。
4. Loss Functions
我们的网络是利用本节剩余部分中描述的损失,利用地面实况差异dgt进行端到端训练的。最终损失是所有尺度和像素上的损失之和:
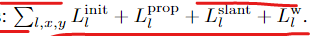
4.1. Initialization Loss
地面实况差异是以亚像素精度给出的,然而初始化中的匹配是以整数差异进行的。因此,我们使用线性插值来计算亚像素视差的匹配成本。亚像素差异的成本如下所示
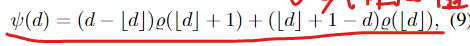
为了清晰起见,我们去掉了l、x、y下标。为了在多个分辨率下计算它们,我们将地面实况视差图最大化,以将它们向下采样到所需的分辨率。我们的目标是将特征E训练为使得匹配成本ψ在地面实况视差处最小,而在其他地方更大。为了实现这一点,我们施加了`1对比损失[18]
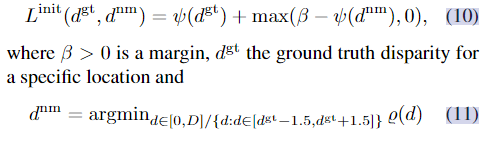
相同位置的最低成本不匹配的差异。该成本将基本事实成本推向0,并且将最低成本不匹配推向一定的裕度。在我们所有的实验中,我们将裕度设置为β=1。在早期基于深度学习的立体匹配方法中,类似的对比损失已被用于学习匹配分数[60,36]。然而,他们要么使用随机不匹配位置作为负样本,要么使用所有不匹配位置分别作为负样本。
4.2. Propagation Loss
在传播过程中,我们对瓦片几何结构d、dx、dy和瓦片置信度w施加损失。我们使用地面实况视差dgt和地面实况视差梯度dgtx和dgty,我们通过将平面稳健地拟合到以像素为中心的9×9窗口来计算。为了在瓦片几何结构上应用损失,我们首先使用类似于等式的平面方程(d,dx,dy)将瓦片扩展到全分辨率视差。5。在应用倾斜损失之前,还使用最近邻方法将倾斜部分上采样到全分辨率。我们使用[2]中的一般鲁棒损失函数ρ(·),它类似于光滑的“1”损失,即Huber损失。此外,我们对阈值为a的损失进行了截断
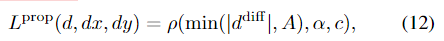
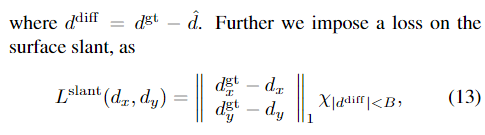
其中,χ是一个指标函数,当条件满足时,它的值为1,否则为0。为了监督置信度w,我们施加损失,如果预测的假设离基本事实比阈值C1更近,则该损失增加置信度,如果预测假设离基本真相比阈值C2更远,则降低置信度。
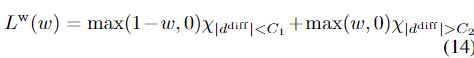
对于我们所有的实验,A=B=C1=1;C2=1.5。对于最后几个级别,当只有一个假设可用时,损失应用于所有像素(a=∞)。
5. Experiments
我们在流行的基准上评估了所提出的方法,与其他方法相比,该基准在很短的计算时间内显示出有竞争力的结果。
我们考虑以下数据集:SceneFlow[38]、KITTI 2012[15]、KITTI2015[39]、ETH3D[45]、Middlebury数据集V3[43]。
根据标准评估设置,我们考虑两个流行的度量:终点误差(EPE),它是预测输出和地面实况之间的视差空间中的绝对距离;x像素误差,即视差误差大于x的像素的百分比。
对于SceneFlow上的EPE计算,我们采用与PSMNet[7]相同的方法,该方法将所有实际视差大于192的像素排除在评估之外。除非另有说明,否则我们使用具有5个级别的HITNet,即M=4。
5.1. Comparisons with State-of-the-art
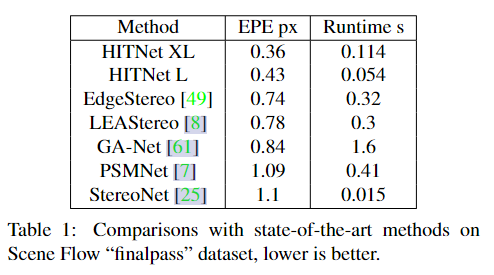
SceneFlow.
我们的方法在保持实时性能的同时实现了最低的EPE。定性结果见图3
Middlebury Stereo Dataset v3.
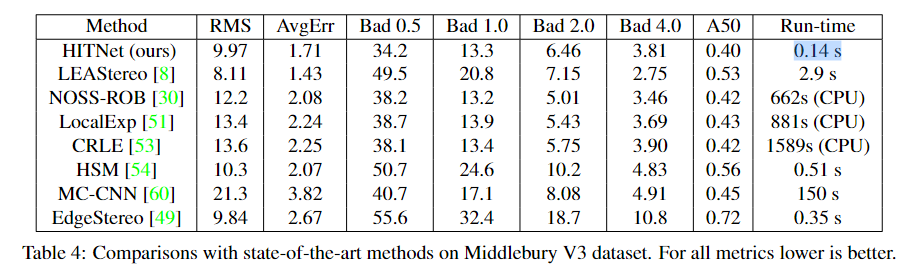
我们在大多数指标上都优于所有其他基于端到端学习的方法,当考虑到手工方法时,我们跻身前10名,特别是我们在Bad 0.5和A50方面排名第一,在Bad 1和Avgerr方面排名第二。
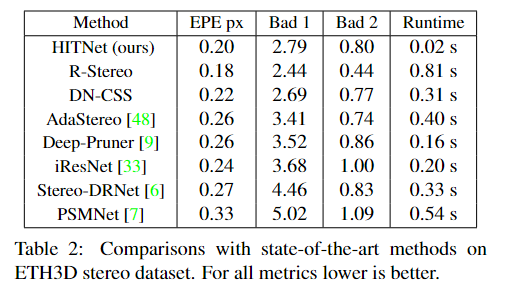
ETH3D two view stereo.
HITNet在网站公布的所有指标中排名第一至第四。特别是,我们的方法在以下指标上对1ND进行了排名:Bad 0.5,Bad 4,平均误差,RMS误差,50%分位数,90%分位数:这表明HITNet对所选的特定度量具有弹性,而竞争方法在选择不同的度量时表现出显著的差异。
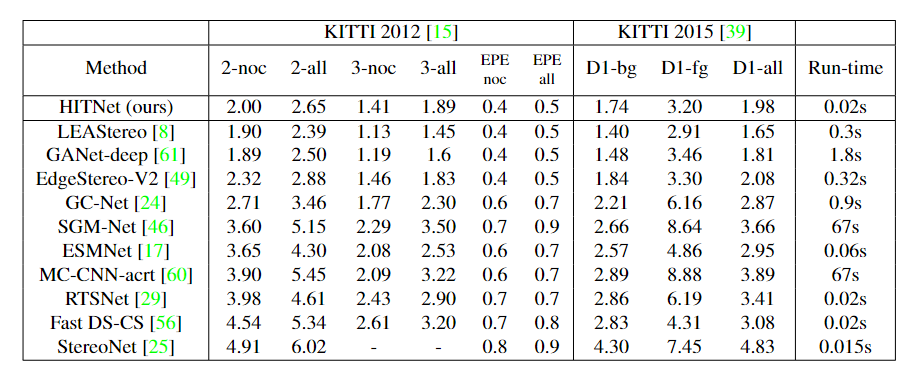
Kitti 2012和2015
在撰写本文时,在发布的速度超过100ms的方法中,HITNet在Kitti 2012和2015基准测试中排名第一。
6. Conclusion
我们提出了HITNet,这是一个实时的端到端架构,用于精确的立体匹配。我们提出了一种快速的初始化步骤,能够非常有效地使用学习特征来计算高分辨率匹配。然后使用传播和融合步骤来融合这些瓦片初始化。使用倾斜的支撑窗学习描述符提供了额外的准确性。我们介绍了多个常用基准测试的最新精确度。我们算法的一个局限性是需要在具有地面真实深度的数据集上进行训练。为了在未来解决这个问题,我们计划研究自我监督方法和自我蒸馏方法,以进一步提高精度并减少所需的训练数据量。我们实验的一个限制是不同的数据集是单独训练的,并且使用略有不同的模型体系结构。为了在未来解决这个问题,需要一个与强大的愿景挑战要求相一致的单一实验。
------------
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号