第二周 网络爬虫之提取之BeautifulSoup
学习网站:中国大学MOOC
网址:https://www.icourse163.org/
首先安装BeautifulSoup, 这个不多说了。。。
安装小测:
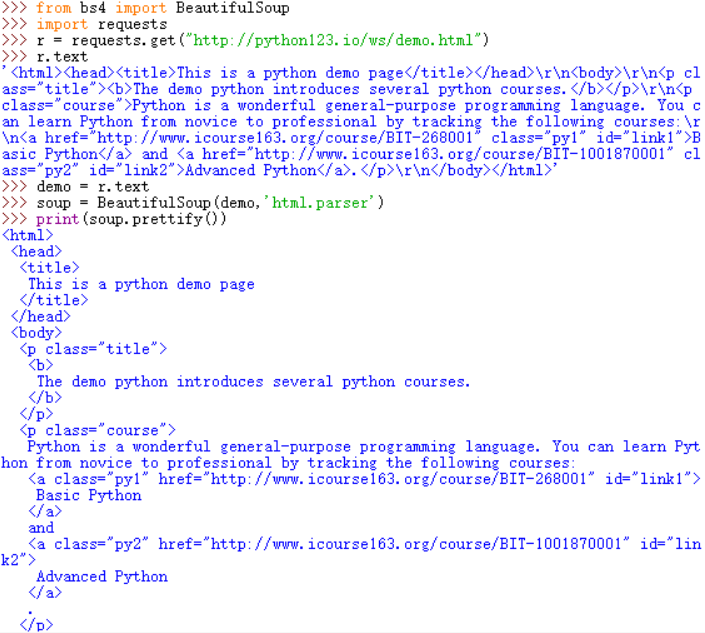
demo是老师提供的一个测试网址。

BeautifulSoup对应一个HTML/XML文档的全部内容
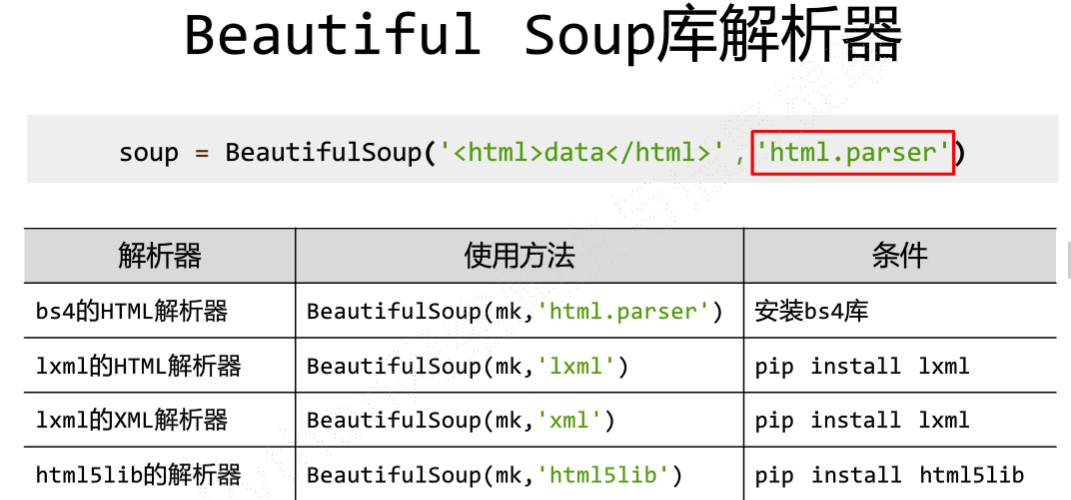
BeautifulSoup可以通过标签名访问其内容如:

每个标签都有一个名字,可通过name属性访问,也可以通过parent.name访问其父标签名:

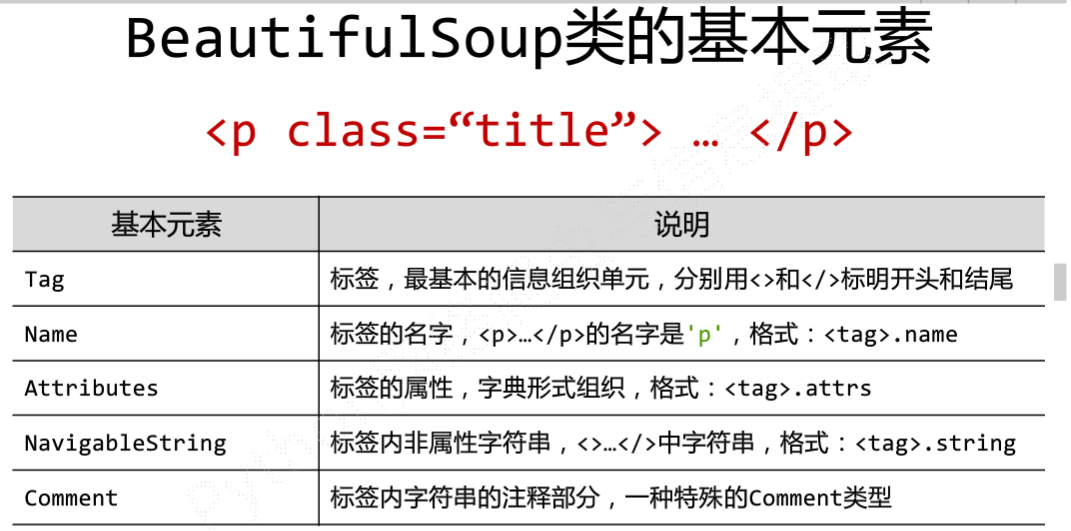
标签(Tag)的属性:attrs

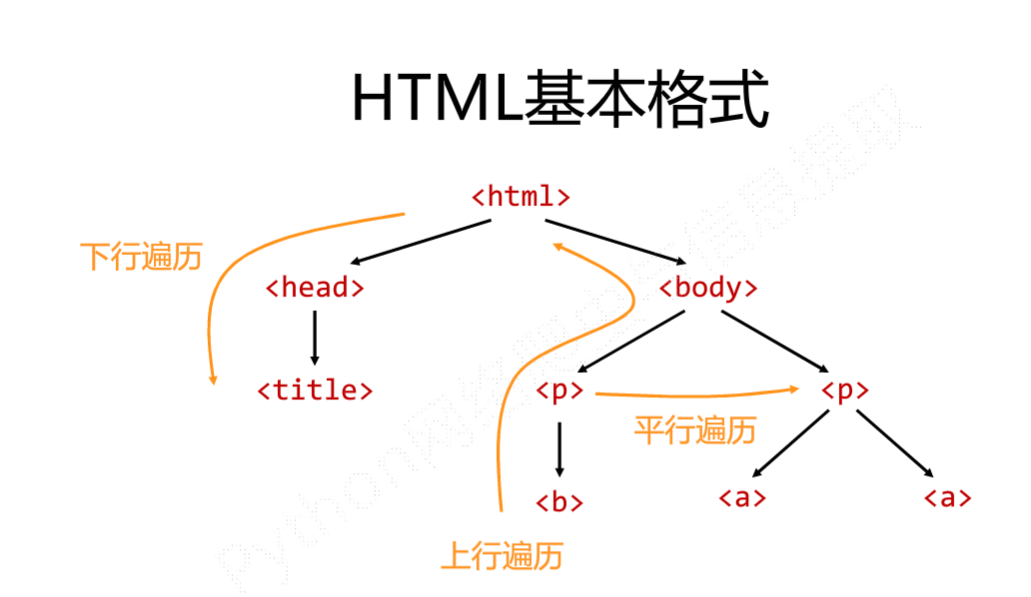
标签树的下行遍历:

标签树的上行遍历:

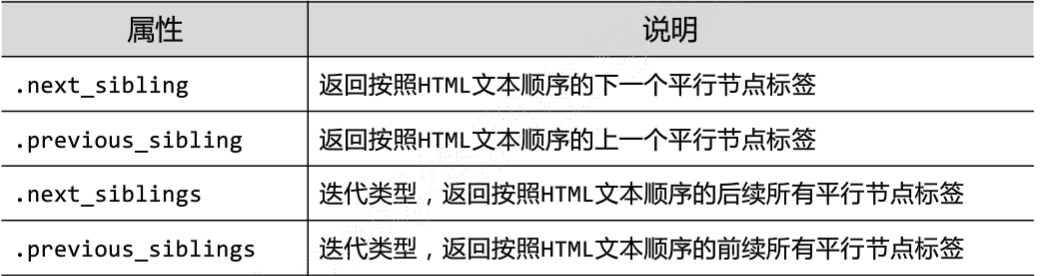
标签树的平行遍历:
bs4库的prettify()方法:
prettify可以让输出的文本更加整洁(加上了换行符)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号