

第一周-单元1-Requests库入门-2-Requests库的get()方法
2.Requests库的get()方法
get()方法的完整格式:
r = requests.get(url,params=None,**kwargs)
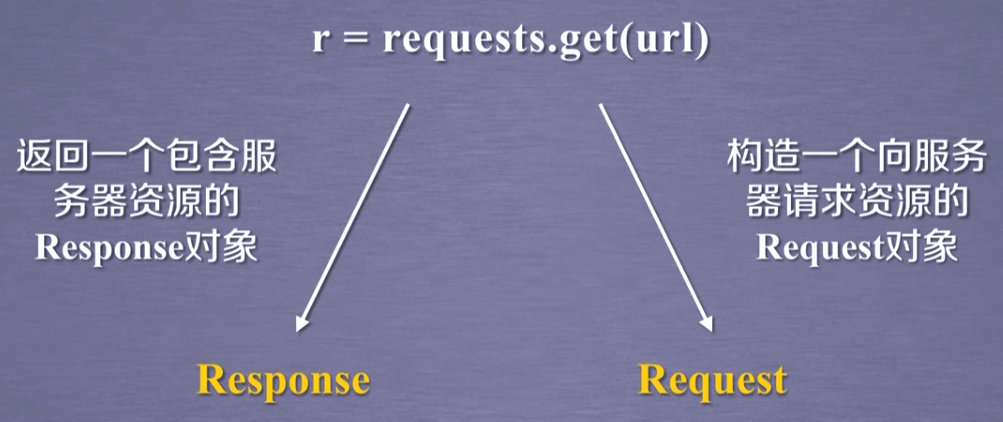
获取网页资源的最简单代码:r = requests.get(url),通过get方法构造一个向服务器请求资源的Request对象,返回一个包含服务器资源的Response对象,用变量r表示,如下图所示。
2.1 Requests库的Response对象
Response对象——重中之重,包含爬虫返回的全部内容
例:
import requests
r = requests.get("http://www.baidu.com")
print(r.status_code) #查看状态码,返回值是200则访问成功
type(r) #检测r的类型
r.headers #返回页面的头部信息Response对象包含服务器返回的所有信息,同时也含有我们向服务器请求的Request信息。
Response对象的属性
| 属性 | 说明 |
| r.status_code | HTTP请求的返回状态,200表示连接成功,404(只要不是200)表示失败 |
| r.text | HTTP响应内容的字符串形式,即url对应的页面内容 |
| r.encoding | 从HTTP的header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
2.2 使用get()方法的基本流程:
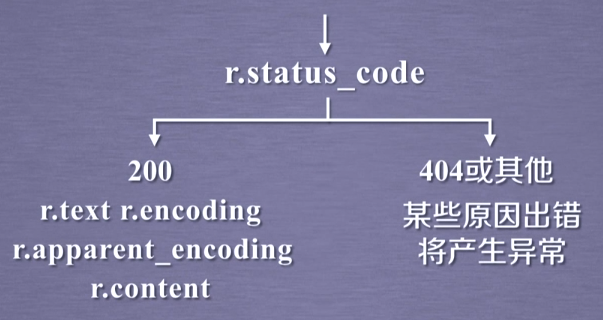
1)用r.status_code检查返回的response对象的状态。
2)如果是200,则用r.text、r.encoding、r.apparent_encoding、r.content进一步解析资源。如果不是200,则说明产生此次访问异常。
2.3 理解Response的编码
编码的意义:使人类可以用有效的解析方式读取网络上的资源
r.encoding和r.apparent_encoding的区别:
r.encoding从HTTP的header中的charset字段获得编码方式,但并不是所有的服务器都对其编码方式有要求,即header中有可能不存在charset。所以当header中不存在charset时,则认为编码方式为ISO-8859-1。
r.apparent_encoding从网页内容而不是头部获取编码方式,原则上更准确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号