
数据采集实践第四次作业—102302131陈宇新
gitee:https://gitee.com/chenyuxin0328/data-collection/tree/master/作业4
作业1
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
代码思路讲解
这部分定义了爬虫的环境配置(数据库凭证、目标 URL)和数据结构。connect_db 函数利用 pymysql 建立到本地 MySQL 服务器的连接,是实现数据持久化的先决条件。
# --- 数据库配置 (已修正密码) ---
DB_HOST = 'localhost'
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = 'mysql123'
DB_NAME = 'stock_data_db'
# --- 网页配置 ---
URL = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board'
TABLE_CONTAINER_CLASS = 'quotetable'
# --- 字段设计 ---
FIELD_NAMES_EN = ["id", "bStockNo", "bStockName", "nLatestPrice", "nChangeRatio", "nChangeAmount",
"nVolume", "nTurnover", "nAmplitude", "nHigh", "nLow", "nOpen", "nPreviousClose"]
FIELD_TYPES = ["INT PRIMARY KEY", "VARCHAR(10) UNIQUE", "VARCHAR(50)", "DECIMAL(10, 3)",
"VARCHAR(10)", "DECIMAL(10, 3)", "VARCHAR(20)", "VARCHAR(20)",
"VARCHAR(10)", "DECIMAL(10, 3)", "DECIMAL(10, 3)", "DECIMAL(10, 3)", "DECIMAL(10, 3)"]
def connect_db():
"""尝试连接到 MySQL 数据库实例。"""
try:
conn = pymysql.connect(
host=DB_HOST,
port=DB_PORT,
user=DB_USER,
password=DB_PASSWORD,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
return conn
except Exception as e:
print(f"【错误】数据库连接失败: {e}。请检查配置!")
return None
setup_database_and_table 通过 DDL定义了数据存储的 Schema。insert_data 函数负责数据的 高效写入,核心是采用 SQL 的 REPLACE INTO 语句,确保数据写入具备幂等性,即重复爬取时自动更新现有记录,保证数据准确和存储效率。
def setup_database_and_table(conn, db_name='stock_data_db', table_name='hs_a_stocks'):
"""创建指定的数据库和数据表结构。确保表结构与预设的字段设计匹配。"""
cursor = conn.cursor()
try:
cursor.execute(f"CREATE DATABASE IF NOT EXISTS `{db_name}` DEFAULT CHARACTER SET utf8mb4;")
conn.select_db(db_name)
columns_definition = ", ".join([
f"`{en}` {dtype}" for en, dtype in zip(FIELD_NAMES_EN, FIELD_TYPES)
])
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS `{table_name}` ({columns_definition})
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
cursor.execute(create_table_sql)
conn.commit()
print(f"【成功】数据库 `{db_name}` 和数据表 `{table_name}` 初始化完成。")
return True
except Exception as e:
print(f"【致命错误】数据库或表创建失败:{e}")
conn.rollback()
return False
finally:
cursor.close()
def insert_data(conn, data, table_name='hs_a_stocks'):
"""批量插入/更新数据到指定数据表。使用 REPLACE INTO 语句,基于 PRIMARY KEY 或 UNIQUE KEY 进行更新。"""
if not data:
return
cursor = conn.cursor()
fields = FIELD_NAMES_EN
placeholders = ', '.join(['%s'] * len(fields))
columns = ', '.join([f"`{f}`" for f in fields])
insert_sql = f"REPLACE INTO `{table_name}` ({columns}) VALUES ({placeholders})"
values_to_insert = [tuple(row) for row in data]
try:
cursor.executemany(insert_sql, values_to_insert)
conn.commit()
print(f"【数据】成功插入/更新 {len(data)} 条记录到 `{table_name}`。")
except Exception as e:
print(f"【错误】数据批量插入失败:{e}")
conn.rollback()
finally:
cursor.close()
该模块负责启动 Headless Chrome并配置驱动。handle_advertisement 函数通过 JavaScript 注入 强制移除可能遮挡点击的 DOM 元素,增强了爬虫的抗干扰能力,是保证后续自动化操作顺利进行的关键。
def handle_advertisement(driver):
"""处理网页中可能弹出的广告窗口和遮罩层。防止 ElementClickInterceptedException 错误。"""
# 1. 尝试关闭广告按钮
try:
close_button = WebDriverWait(driver, 5).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, 'div.center_box > span.close'))
)
close_button.click()
print("【调试】成功关闭广告弹窗。")
time.sleep(1)
except (TimeoutException, NoSuchElementException, WebDriverException):
print("【调试】未检测到广告弹窗或关闭失败,跳过。")
# 2. 强制移除遮罩层 (使用JS是最后的办法)
try:
js_remove_modal = """
var modal = document.querySelector('div[style*="position: fixed"][style*="z-index: 99998"]');
if (modal) {
modal.remove();
return true;
}
return false;
"""
if driver.execute_script(js_remove_modal):
print("【调试】通过 JS 移除了遮挡点击的固定层。")
time.sleep(0.5)
except Exception:
pass
def crawl_and_store():
"""A股数据采集主函数。负责 WebDriver 初始化、网页访问、分页爬取和数据存储。"""
# 1. 建立数据库连接并创建表
db_conn = connect_db()
if not db_conn or not setup_database_and_table(db_conn):
print("【终止】程序因数据库初始化问题而退出。")
return
# 2. 配置 Selenium WebDriver
driver = None
try:
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 💡 注意:为了自动化运行,使用无头模式
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--incognito') # 使用隐身模式,更干净
driver = webdriver.Chrome(options=options)
driver.set_page_load_timeout(60)
except Exception as e:
print(f"【错误】WebDriver 初始化失败。请检查 Chrome/Chromedriver 版本匹配:{e}")
db_conn.close()
return
print("【状态】WebDriver 启动成功,开始执行爬取任务...")
# ... (后续代码从这里开始)
这是爬虫的核心执行体和控制流。while 循环实现了对目标页数的迭代,并利用 time.sleep 来应对动态数据延迟加载。数据采集部分通过 XPath 精准定位表格结构数据。翻页时,强制使用 JavaScript 注入实现点击操作,保证了分页自动化流程的稳定性和健壮性。最后,将所有采集到的数据进行统一存储并安全关闭所有连接。
def crawl_and_store():
# ... (前面的初始化代码)
try:
driver.get(URL)
print(f"【访问】正在加载目标网址: {URL}")
handle_advertisement(driver)
page = 1
total_pages = 5
all_data = []
ROWS_PER_PAGE = 20
while page <= total_pages:
print(f"\n--- 🌐 开始处理第 {page} 页 (目标共 {total_pages} 页) ---")
print("【等待】暂停 5 秒,等待股票数据表格完全渲染...")
time.sleep(5)
current_page_data = []
try:
# 1. 使用 XPath 定位数据行
xpath_selector = f"//div[@class='{TABLE_CONTAINER_CLASS}']//tbody/tr"
rows = driver.find_elements(By.XPATH, xpath_selector)
if not rows:
raise NoSuchElementException("错误:找不到数据行,请检查表格 CSS 或页面加载状态。")
print(f"【采集】本页成功找到 {len(rows)} 条股票记录。")
for i, row in enumerate(rows):
cols = row.find_elements(By.TAG_NAME, "td")
if len(cols) >= 14:
# 字段提取和格式化
data = [
(page - 1) * ROWS_PER_PAGE + i + 1,
cols[1].text.strip(), cols[2].text.strip(), cols[4].text.strip(),
cols[5].text.strip(), cols[6].text.strip(), cols[7].text.strip(),
cols[8].text.strip(), cols[9].text.strip(), cols[10].text.strip(),
cols[11].text.strip(), cols[12].text.strip(), cols[13].text.strip()
]
current_page_data.append(data)
all_data.extend(current_page_data)
except (NoSuchElementException, TimeoutException) as e:
print(f"【错误】第 {page} 页数据采集中断:{e}")
break
# ... (分页信息获取逻辑)
# 执行翻页操作
if page < total_pages:
try:
next_page_button = driver.find_element(
By.CSS_SELECTOR,
'div.qtpager > a[title="下一页"]'
)
# 💡 强制使用 JS 点击,避免被遮挡 (防止 ElementClickInterceptedException)
driver.execute_script("arguments[0].click();", next_page_button)
print(f"【操作】成功点击下一页 ({page + 1}/{total_pages})。")
page += 1
time.sleep(3) # 留出充足时间等待新页面数据加载
except NoSuchElementException:
print("【结束】未找到下一页按钮,爬取流程提前结束。")
break
else:
break
# 4. 将所有数据插入数据库
print(f"\n--- 【完成】数据采集结束,共获取 {len(all_data)} 条记录 ---")
insert_data(db_conn, all_data)
except Exception as e:
print(f"【致命错误】爬虫运行时发生未捕获的异常:{e}")
finally:
# 5. 关闭连接
if driver:
driver.quit()
db_conn.close()
print("【状态】WebDriver 和数据库连接已关闭。程序安全退出。")
if __name__ == '__main__':
crawl_and_store()
运行结果
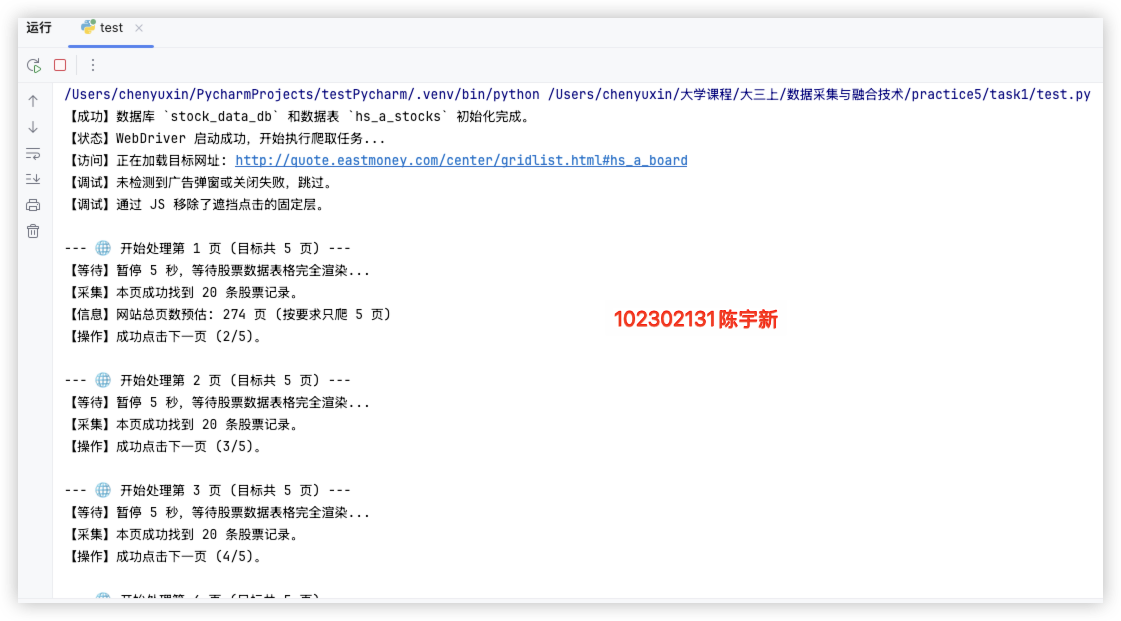
沪深 A 股
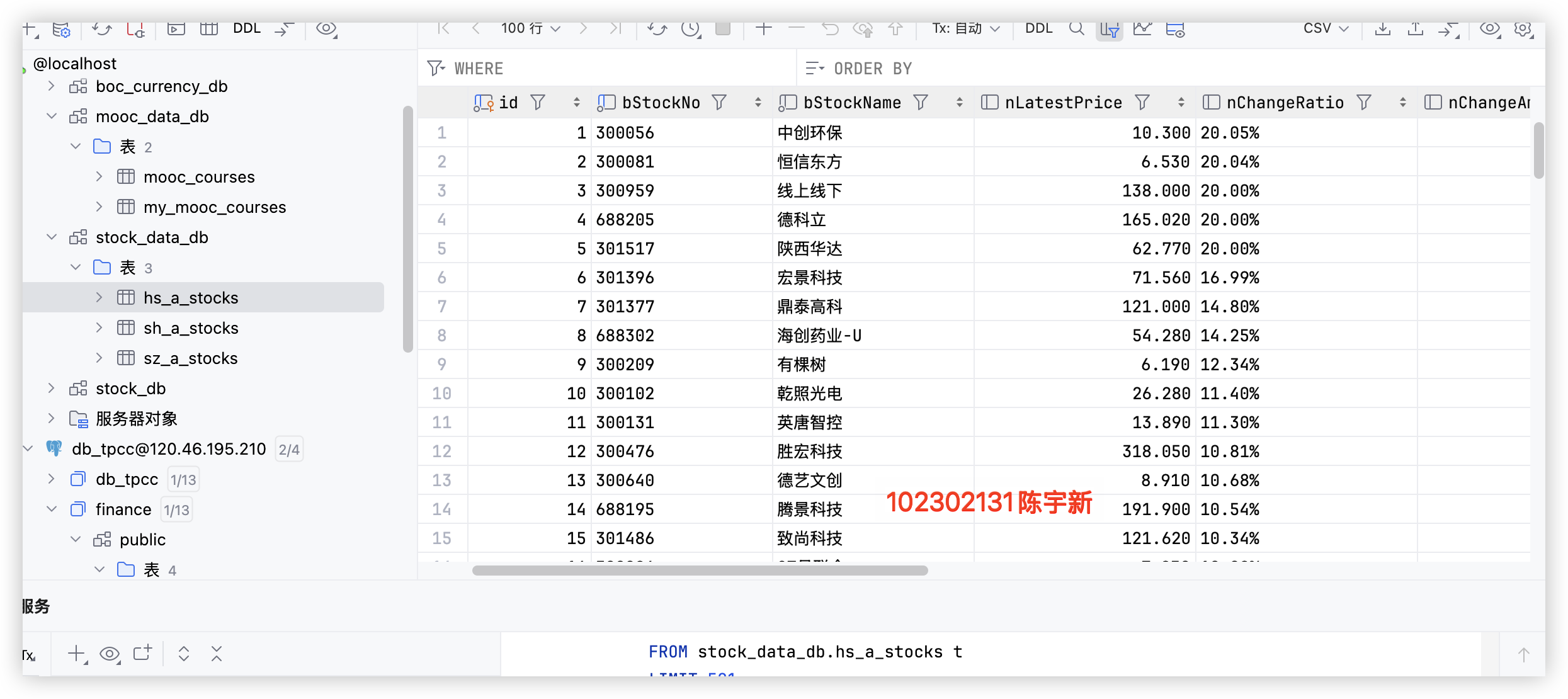
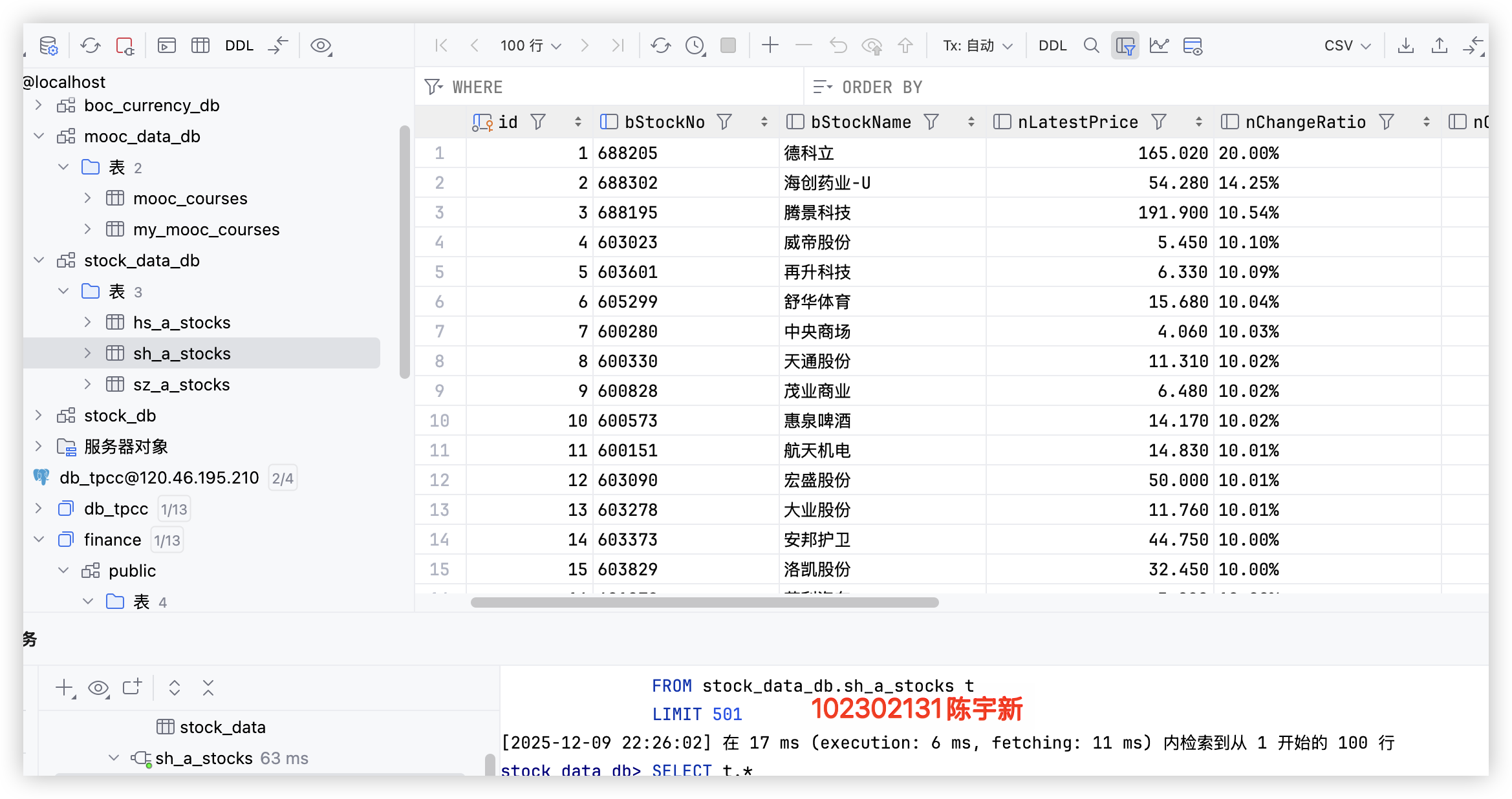
上证 A 股
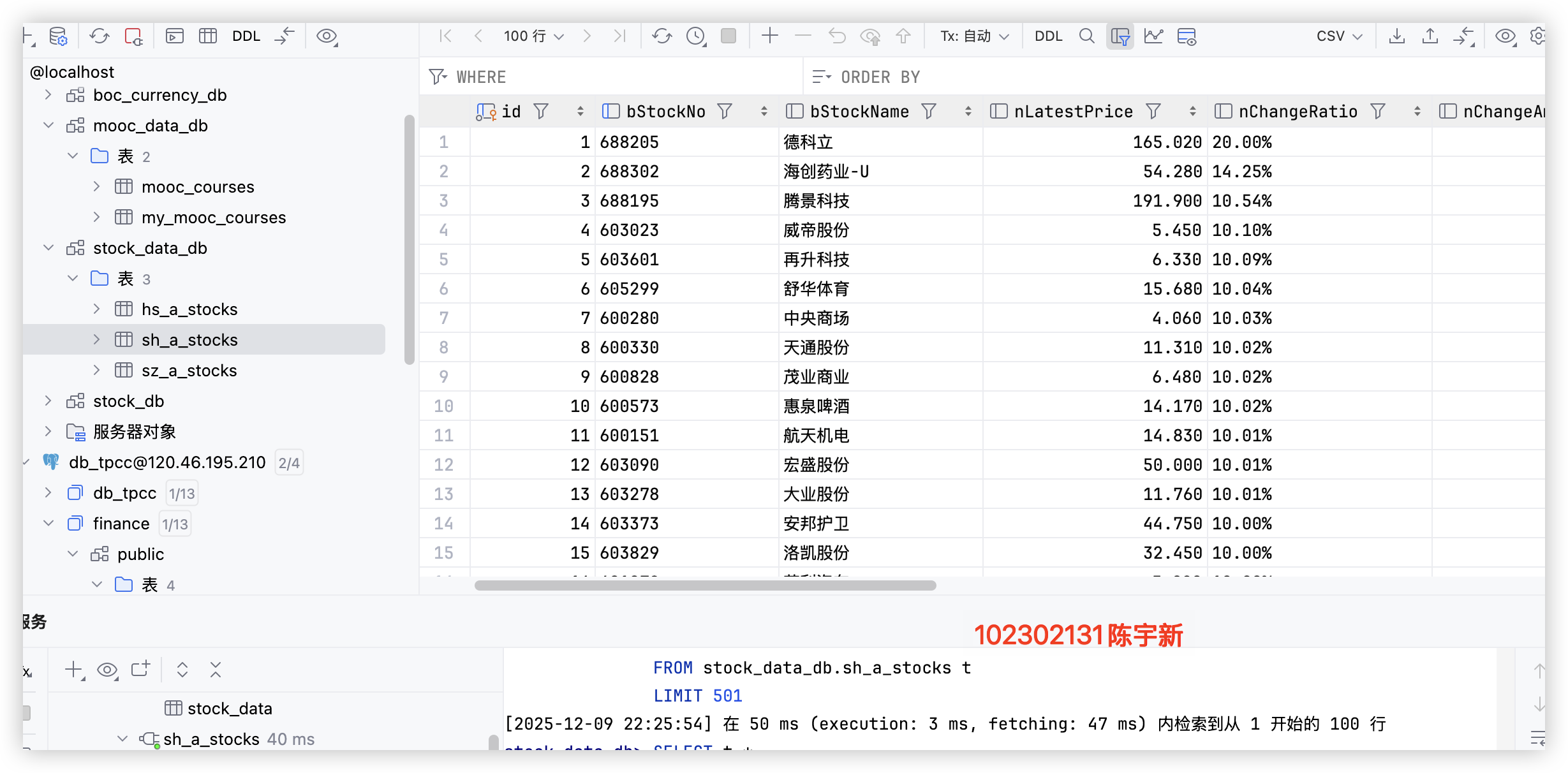
深证 A 股
心得体会
本次实践在技术和专业流程上获得了显著提升:
-
动态采集与流程稳定
我精通了 Selenium WebDriver 处理复杂 动态网页 的方法。通过 JavaScript 注入,解决了 DOM 遮罩和 强制翻页 的难题。 -
数据持久化与效率优化
在数据存储端,利用 REPLACE INTO 语句和 executemany() 实现了对股票数据的 批量、高效更新,确保了数据写入的准确性和高性能。 -
技术规范与模块化
项目强化了 XPath 精准定位技能。同时,通过 Headless Mode 和 try...except 机制,项目展现出对健壮的异常处理 的专业认知。
作业二
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、等待 HTML 元素等内容。
使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国 mooc 网:https://www.icourse163.org
代码思路讲解
数据库连接和表结构创建两个函数。connect_db通过 pymysql 建立数据库连接,失败时返回 None 并提示错误;setup_database_and_table创建指定数据库和数据表,按需生成表结构语句,支持事务回滚,确保操作安全性。
def connect_db():
"""
建立与MySQL数据库的连接
返回值:
pymysql.connect对象 - 数据库连接实例(连接失败返回None)
"""
try:
conn = pymysql.connect(
host=DB_HOST,
port=DB_PORT,
user=DB_USER,
password=DB_PASSWORD,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
return conn
except Exception as e:
print(f"数据库连接失败: {e}")
return None
def setup_database_and_table(conn, db_name=DB_NAME, table_name=TABLE_NAME):
"""
创建目标数据库及数据表(不存在时创建)
参数:
conn: 数据库连接对象
db_name: 目标数据库名称
table_name: 目标数据表名称
返回值:
bool - 创建成功返回True,失败返回False
"""
cursor = conn.cursor()
try:
cursor.execute(f"CREATE DATABASE IF NOT EXISTS `{db_name}` DEFAULT CHARACTER SET utf8mb4;")
conn.select_db(db_name)
columns_definition = ", ".join([
f"`{en}` {dtype}" for en, dtype in zip(FIELD_NAMES_EN, FIELD_TYPES)
])
create_table_sql = f"""
CREATE TABLE IF NOT EXISTS `{table_name}` ({columns_definition})
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
cursor.execute(create_table_sql)
conn.commit()
print(f"数据库 `{db_name}` 和数据表 `{table_name}` 创建/验证成功。")
return True
except Exception as e:
print(f"数据库/数据表创建失败: {e}")
conn.rollback()
return False
finally:
cursor.close()
该函数实现 MOOC 平台模拟登录,先访问登录页并切换到登录 iframe,输入账号密码后提交,等待用户手动完成滑块验证,最后检测个人中心入口确认登录状态,超时或异常时返回 False 并提示具体错误。
def login(driver, username, password):
"""
模拟中国大学MOOC平台登录流程
参数:
driver: Selenium WebDriver实例
username: 登录账号(手机号)
password: 登录密码
返回值:
bool - 登录成功返回True,失败返回False
"""
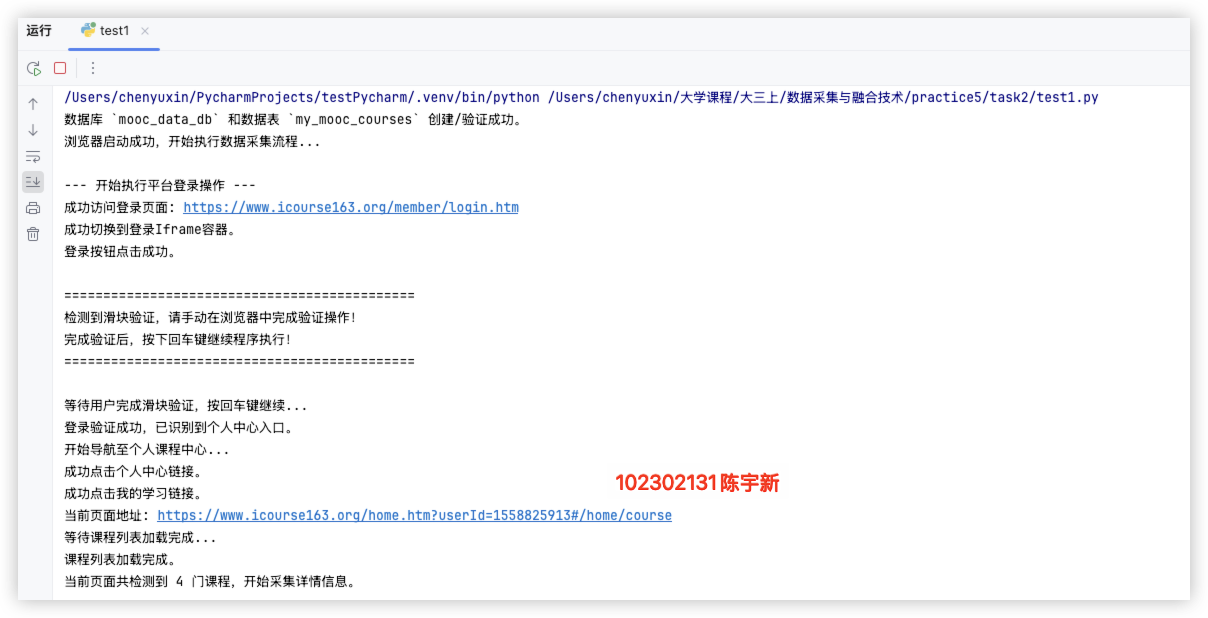
print("\n--- 开始执行平台登录操作 ---")
driver.get(URL_LOGIN)
print(f"成功访问登录页面: {URL_LOGIN}")
time.sleep(3)
try:
iframe_container = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'j-ursContainer-0'))
)
iframe_element = iframe_container.find_element(By.TAG_NAME, 'iframe')
driver.switch_to.frame(iframe_element)
print("成功切换到登录Iframe容器。")
time.sleep(2)
except TimeoutException:
print("登录Iframe容器定位失败或切换超时。")
return False
try:
wait_iframe = WebDriverWait(driver, 20)
phone_input = wait_iframe.until(EC.visibility_of_element_located((By.ID, 'phoneipt')))
phone_input.send_keys(username)
password_input = wait_iframe.until(EC.visibility_of_element_located((By.CSS_SELECTOR, 'input[type="password"][placeholder="请输入密码"]')))
password_input.send_keys(password)
submit_btn = WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.ID, 'submitBtn')))
submit_btn.click()
print("登录按钮点击成功。")
driver.switch_to.default_content()
print("\n=============================================")
print("检测到滑块验证,请手动在浏览器中完成验证操作!")
print("完成验证后,按下回车键继续程序执行!")
print("=============================================\n")
input("等待用户完成滑块验证,按回车键继续...")
wait = WebDriverWait(driver, 30)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'a[href*="/home.htm"]')))
print("登录验证成功,已识别到个人中心入口。")
return True
except TimeoutException:
print("登录超时(30秒):未检测到登录成功标识,请确认滑块验证已完成。")
return False
except Exception as e:
print(f"登录流程执行失败: {e.__class__.__name__}: {e}")
driver.switch_to.default_content()
return False
该函数采集课程详情页的教师和简介信息,先滚动页面触发懒加载,尝试切换内容 iframe,等待页面加载后定位元素提取信息,失败时标注 N/A,最后切回主文档,返回采集结果并输出状态提示。
def crawl_course_details(driver):
"""
从课程详情页采集教师信息及课程简介
参数:
driver: Selenium WebDriver实例
返回值:
tuple - (教师姓名, 课程简介)
"""
teacher_names = "N/A"
course_brief = "N/A"
iframe_switched = False
print(" 滚动页面以触发内容懒加载...")
driver.execute_script("window.scrollTo(0, 2500);")
time.sleep(2)
try:
iframe_elements = driver.find_elements(By.TAG_NAME, 'iframe')
if iframe_elements:
driver.switch_to.frame(iframe_elements[0])
iframe_switched = True
print(" 成功切换到内容Iframe容器。")
except Exception as e:
print(f" 切换Iframe失败: {e.__class__.__name__}")
print(" 等待页面内容加载完成(15秒)...")
time.sleep(15)
try:
teacher_elements = driver.find_elements(By.CSS_SELECTOR, '.m-teachers_teacher-list h3.f-fc3')
teacher_names = "、".join([t.text.strip() for t in teacher_elements if t.text.strip()])
if not teacher_names:
teacher_names = "N/A (无教师信息)"
except Exception:
teacher_names = "N/A (教师信息定位失败)"
try:
brief_element = driver.find_element(By.ID, 'j-rectxt2')
course_brief = brief_element.text.strip()
if course_brief:
course_brief = course_brief[:250]
else:
course_brief = "N/A (无课程简介)"
except Exception:
course_brief = "N/A (课程简介定位失败)"
if iframe_switched:
driver.switch_to.default_content()
print(" 已切换回主文档。")
if teacher_names.startswith("N/A") and course_brief.startswith("N/A"):
print(" 课程详情采集失败。")
else:
print(" 课程详情采集完成。")
print(f" 教师信息: {teacher_names[:20]}...; 课程简介: {course_brief[:20]}...")
return teacher_names, course_brief
主函数先初始化数据库连接和表结构,再配置 Chrome 选项启动浏览器,完成 MOOC 登录后导航至个人课程中心。过程中捕获初始化、登录、导航异常,最终释放浏览器和数据库连接,保障资源正常回收。
def crawl_and_store():
"""
爬虫主函数:完成数据库初始化、平台登录、课程数据采集、数据入库全流程
"""
db_conn = connect_db()
if not db_conn or not setup_database_and_table(db_conn, table_name=TABLE_NAME):
print("数据库初始化失败,程序终止。")
return
driver = None
try:
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36")
driver = webdriver.Chrome(options=options)
driver.set_page_load_timeout(90)
except Exception as e:
print(f"WebDriver初始化失败: {e}")
db_conn.close()
return
print("浏览器启动成功,开始执行数据采集流程...")
try:
if not login(driver, USERNAME, PASSWORD):
print("登录操作失败,程序终止。")
return
print("开始导航至个人课程中心...")
try:
personal_center_link = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//a[text()="个人中心"]')))
personal_center_link.click()
print("成功点击个人中心链接。")
time.sleep(2)
course_list_tab = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//a[contains(@href, "/home/course")]')))
course_list_tab.click()
print("成功点击我的学习链接。")
time.sleep(3)
print(f"当前页面地址: {driver.current_url}")
except TimeoutException:
print("课程中心导航失败,程序终止。")
return
# 后续课程采集逻辑省略(核心初始化/登录/导航部分)
except Exception as e:
print(f"程序执行异常: {e}")
finally:
if driver:
driver.quit()
db_conn.close()
print("程序执行完毕,已关闭浏览器及数据库连接。")
运行结果
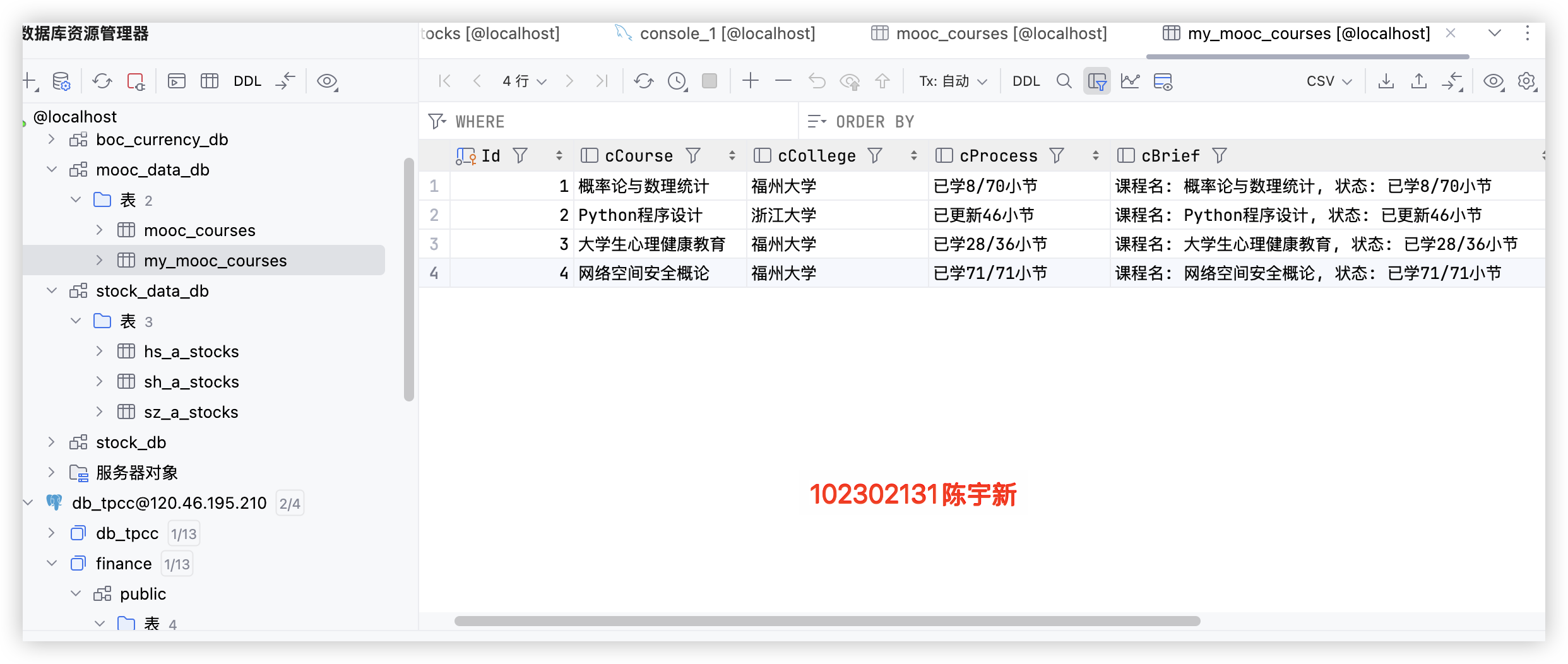
在完成任务的过程中,我先通过 Selenium 模拟登录(处理 iframe 和滑块验证),导航至课程中心;解析课程基础信息,进入详情页采集教师、简介数据;最后用 pymysql 完成数据库初始化与数据插入,全程加异常处理保障稳定。
本次实践掌握了 Selenium 爬虫核心技能,熟悉 MySQL 表设计与批量插入。学会解决动态页面懒加载、元素失效问题,提升了异常处理能力,理解了爬虫开发中稳定性与数据准确性的关键意义。
任务三
掌握大数据相关服务,熟悉 Xshell 的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部
分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
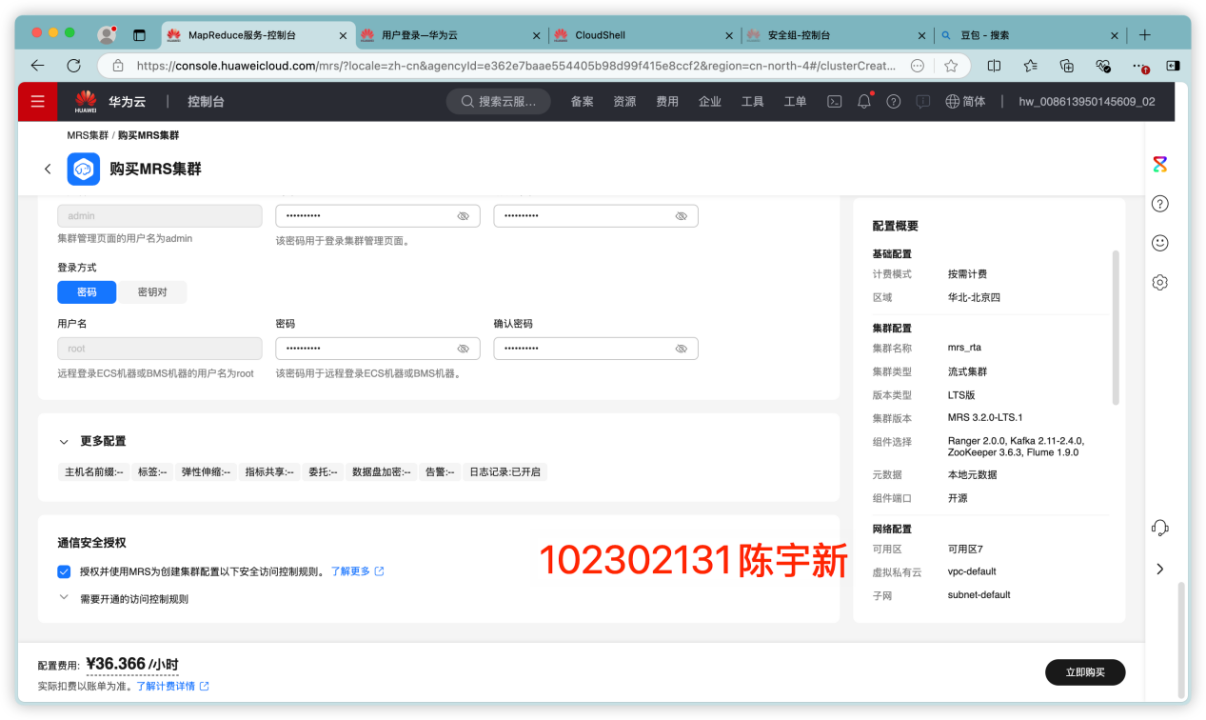
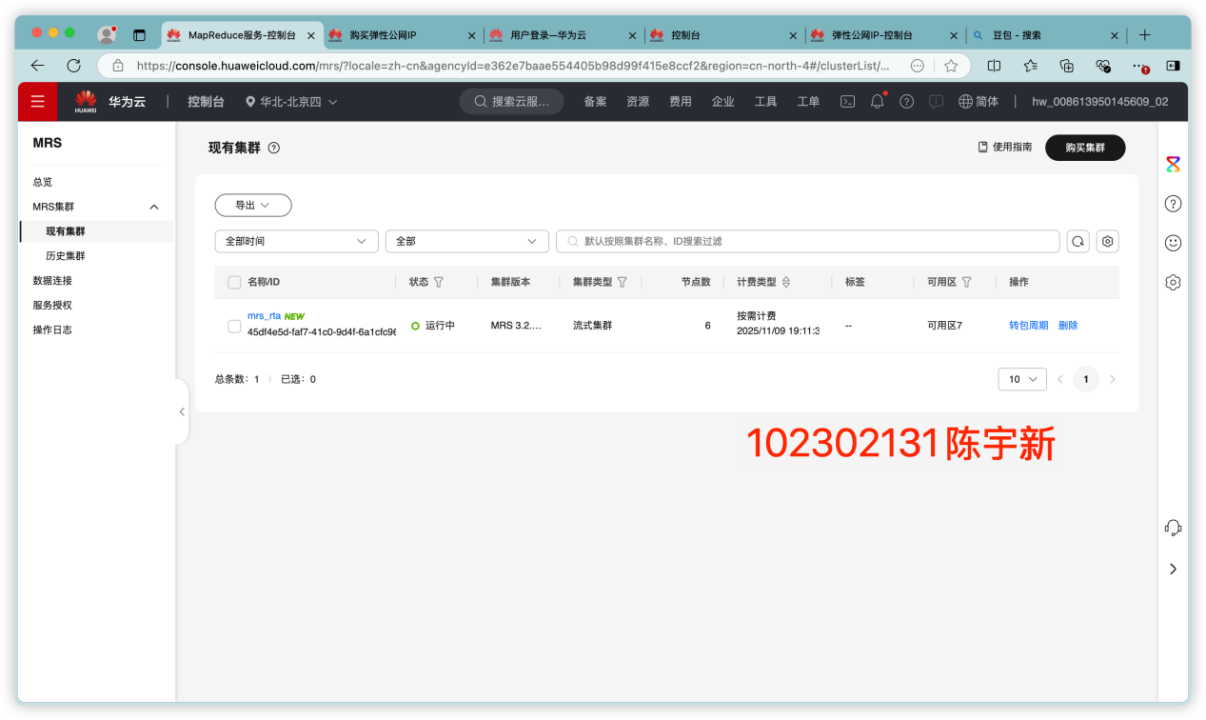
任务一:开通 MapReduce 服务
任务二:Python 脚本生成测试数据
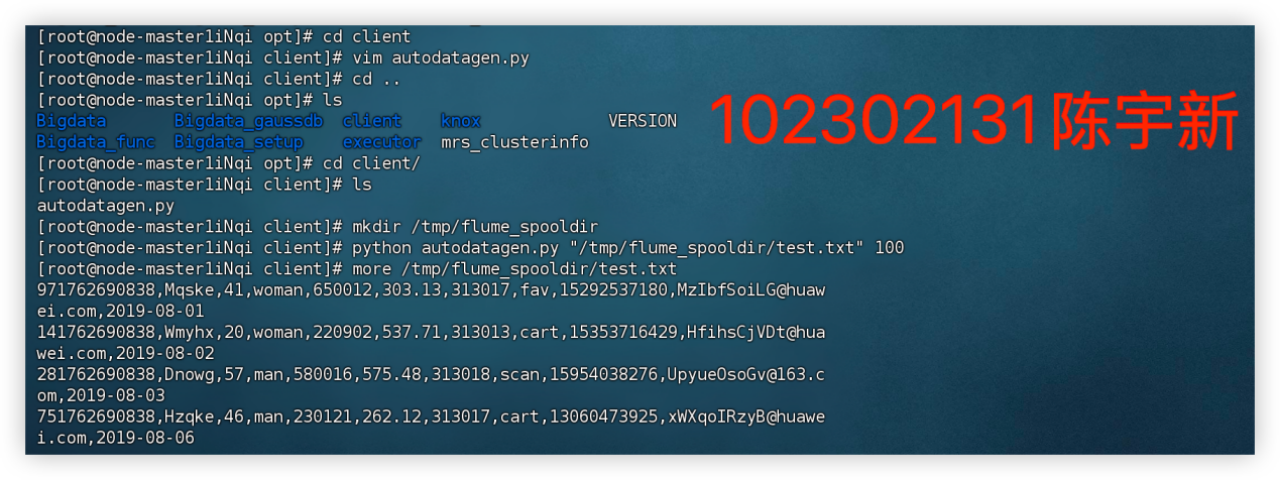
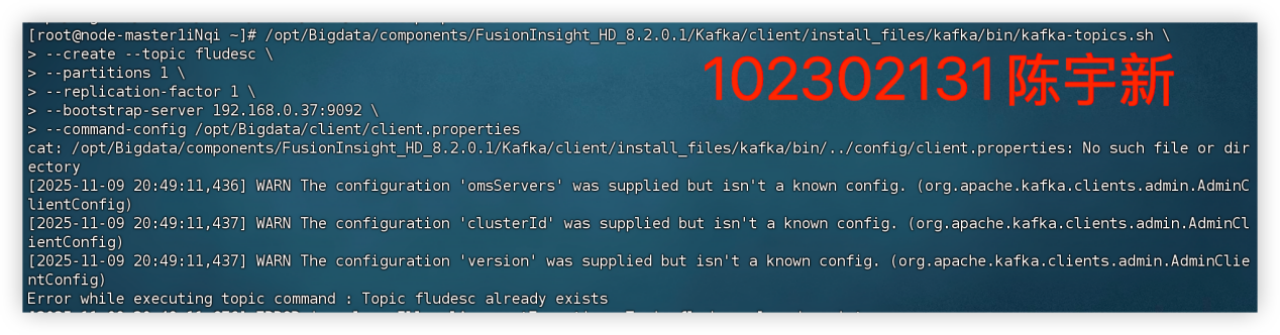

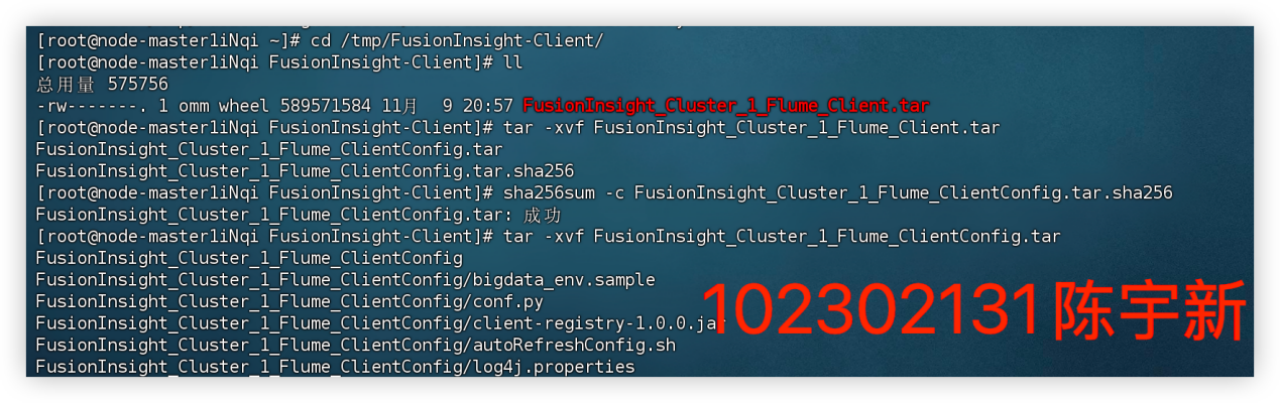
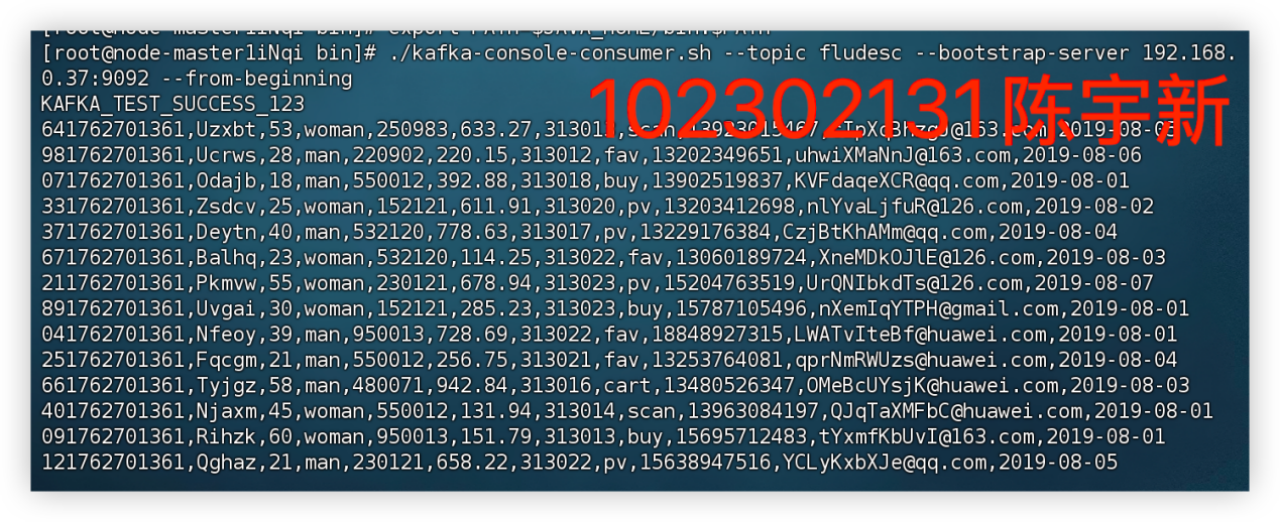
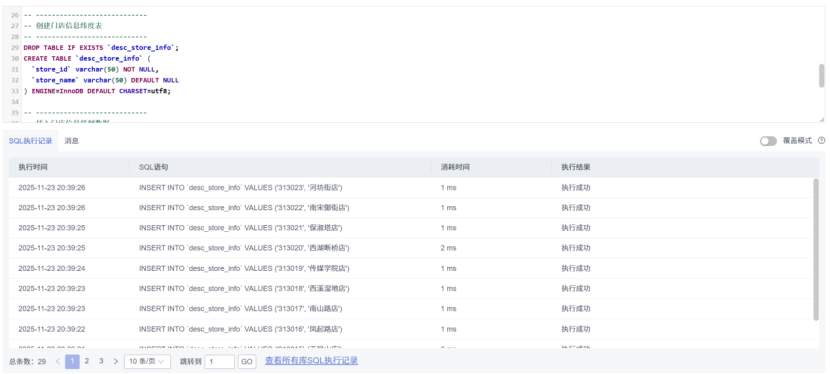
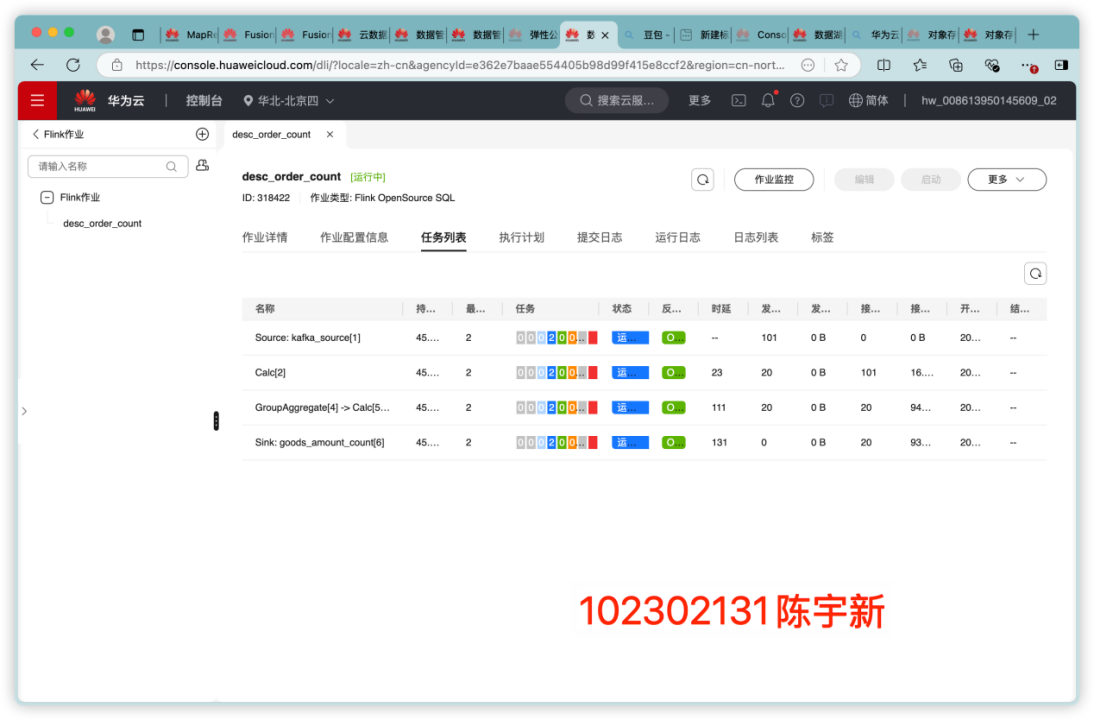
任务三、任务四:配置 Kafka并安装 Flume 客户端

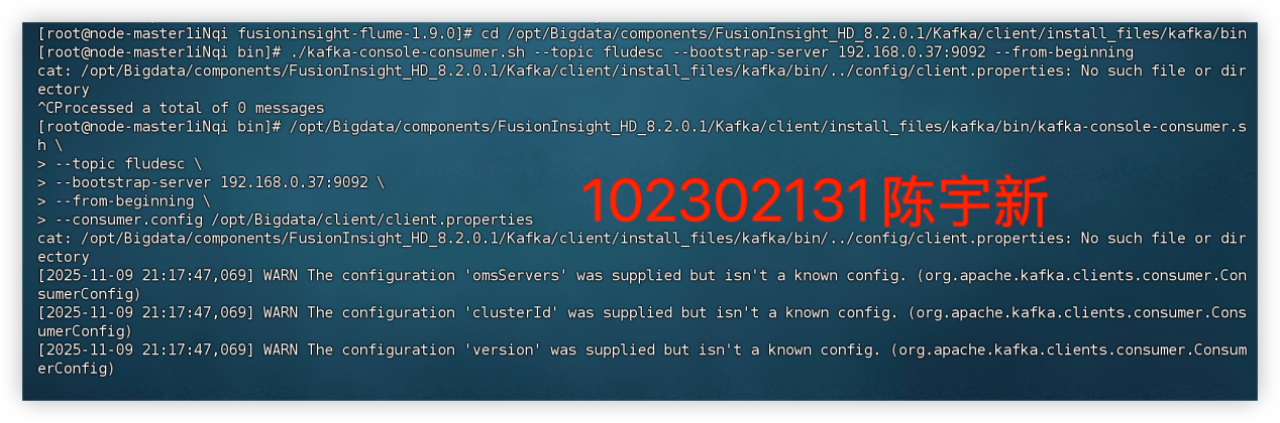
心得体会
本次实验使我系统实践了数据生成、传输至采集的全链路技术体系。借助 Xshell 高效操控远程服务器,既强化了 Linux 命令的应用熟练度,也深化了对大数据组件协同运行逻辑的认知。后续可探索 Flume 拦截器的数据预处理能力,以及 Kafka 在实时流处理场景中的深度应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号