

05--网络爬虫基础知识
爬虫
什么是爬虫:
请求网站并提取数据的自动化程序。
请求:用程序模拟浏览器向服务器发送请求,获得网络资源(HTML代码)。
提取:从获取到的HTML代码中提取相关数据,可以是一张照片,一首音乐,一些手机号等等。
自动化:程序代替浏览器向服务器不停地,循环地发送请求,就可以批量地,大量地获取数据与资源。
什么的基本流程:
第一步:发起请求
通过HTTP库向目标站点发起请求,即发送一个Reques(请求)t,请求可以包含额外的headers等信息,等待服务器响应。
第二步:获取响应内容
如果服务器能正常响应,会得到一个Response,Response(响应)的内容便是所要获取的页面内容,类型可能有HTML,Json字符串,二进制数据(如图片视频)等类 型。
第三步:解析内容
得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是Json,可以直接转为Json对象解析,可能是二进制数据,可以做保存或者进一步处理。
第四步:保存数据
保存形式多样,可以存为文本,也可以保存至数据库,或者保存特定格式的文件。
Reques与Response图解:

Reques
请求方式:
主要有GET和POST两种类型,另外还有HEAD,PUT,DELETE,OPTIONS等。
GET:显示在URL里面,信息暴露在外侧,传输速度较快但是安全性较差。
POST:数据提交的时候不会显示URL里面,因此安全性较好。它的数据会被包含在From Data里面啊,常用于登录和提交的数据较敏感的时候。
请求URL:
URL全称全球统一资源定位符,如一个网页文档,一张图片,一个视频等都可以用URL唯一确定。
请求头:
包含请求时的头部信息,如User-Agent,Host,cookie等信息,相当于请求时的配置信息,如果请求时的配置信息不正确会被服务器判定为非法从而不会显示正确的页面信息。
请求体:
请求时额外携带的数据,如表单提交时的表单数据,一般GET请求方式不携带任何请求体,POST方式才会携带请求体,请求体的内容包含在Headers头部信息里面的From Data里面。
Response
响应状态:
有多种响应状态,如200代表成功,301跳转,404找不到页面,502服务器错误。
响应体:
最主要的部分,包含了请求资源的内容,如网页HTML,图片二进制数据等。
响应头:
有多种响应状态,如200代表成功,301跳转,404找不到页面,502服务器错误。
>>>import requests
>>>response = request.get('http://www.baidu.com')
>>>print(response.text)
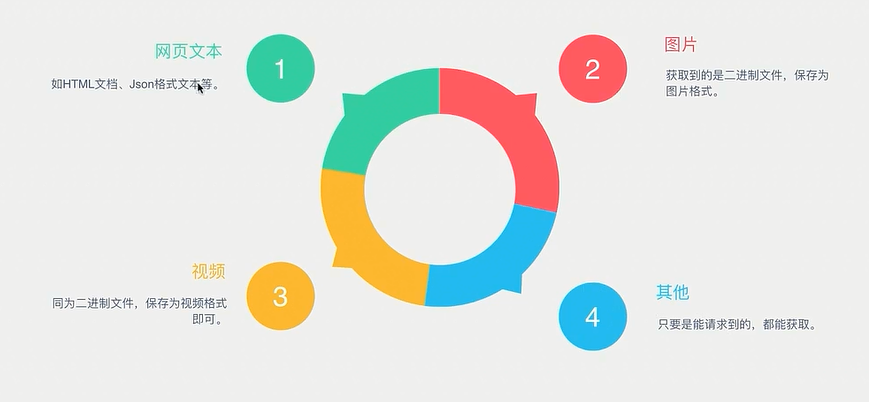
爬虫能抓取怎样的数据?
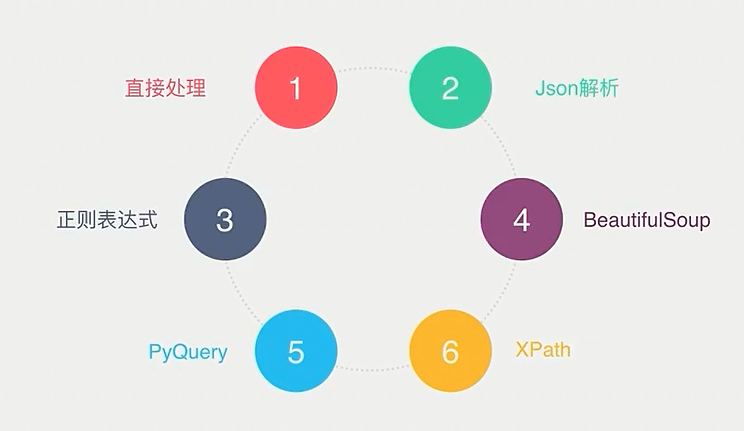
数据解析的方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号