

为了更好的使用Aperture组件,我们需要熟悉他的整体流程以及相关API接口
下面是关于Aperture组件的通用结构,文章翻译自 http://sourceforge.net/apps/trac/aperture/wiki/GeneralStructure
本人翻译得不伦不类,因为本人的汉语和英语都乏功底,翻译正文如下:
Aperture由许多API完成不同类型的服务,例如,文本和元数据提取,抓取在数据源中的数据或识别文件的MIME类型。参与实施和管理这些服务通常按特定的编码方式
在实施和管理等服务所涉及的代码通常是在一个特定的方式组织。一旦你知道这种结构是如何工作的,你会更好地在Aperture能够迅速找到自己的方式。下图显示了这些组件是如何一起工作的一个典型应用: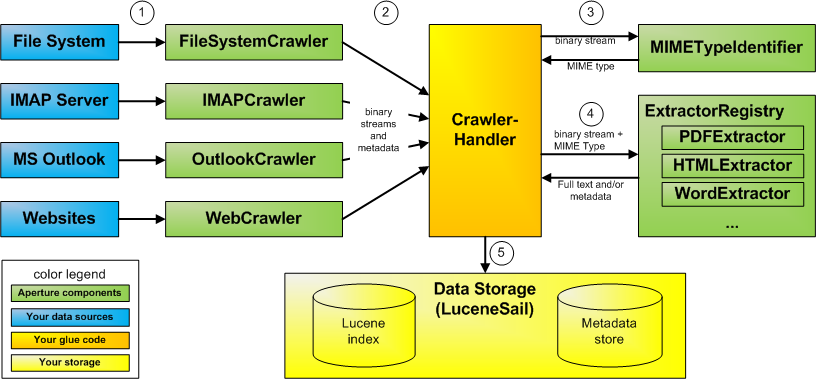
Aperture上运行现有的数据源,支持多种类型的数据源(如文件系统或者IMAP服务器),其他的可以很容易地添加。对于这些类型的数据源,Aperture提供了一种crawler,它从数据源读取数据并将其转换为一个标准化的格式RDF。一个最基本的层面上的RDF是一种数据结构,存储各种资源的信息,类似于Java的HashSet方式,但更多的可能性。资源可以相互联结成一个网络。此外,RDF提供了每一条数据的特殊含义,允许它被所有的RDF应用程序使用,为了充分利用Aperture,它们是你应该熟悉RDF应用,。本教程其余部分假定您熟悉至少像graph的基本概念, triple, URI, literal 等。请参阅RDF主页的更多细节和进一步阅读。
一旦数据由crawler转换,它被传递到crawler handler。crawler handler是在你的应用程序中使用Aperture你要写的,作为Aperture用户,现在决定怎样处理这些数据。
当crawler找到一个文件(如HTML文件),你可以使用Aperture从该文件提取元数据提取和全文。要做到这一点,你需要采取以下步骤。
使用MimeTypeIdentifier来检测文件的MIME类型
当你有MIME类型(例如,text/html),你可以用它来获得适当的Extractor。Aperture为您提供各种Extractor,这些对象都可以从二进制文件中提取元数据。对于HTML文件,HtmlExtractor的做这项工作。Aperture知道如何找到合适的Extractor,使用的是ExtractorRegistry。
让Extractor从二进制流中提取元数据
最后,你把所有的文件的元数据,你可以为你的应用程序做任何你需要的事情。你可以存储在RDF数据库,或提供文本给搜索引擎(或借助LuceneSail同时两者都做)。您可以使用Lucene的,MySQL和文件或任何其它存储。这一切都取决于你的想象力。
API
Services
Aperture架构是基于服务的。这使得它非常适合在其他面向服务中应用。主要服务项目有:
Crawlers
Extractors
Data Accessors
Mime type identifiers
Link extractors
每个服务中心是一个API,通常是Java接口,其执行所体现的服务的方法。例如,Extractor接口定义一个访问特定的MIME类型的文件的InputStream进行全文和元数据提取的提取方法。如HtmlExtractor为HTML文档具体的实施实现服务。
Factories
每个服务API通常伴随着factory的API,如ExtractorFactory。每个API的实现,都应该有一个factory实现。factory的目的是双重的:
它应该能够返回特定的服务实现的功能,让你选择某一特定任务的最佳的实现。。
它应该能够返回一个服务API的实例,丰富这些功能。
例如,ExtractorFactory定义了一个getSupportedMimeTypes方法,返回由一个特定的Extractor 实现支持的MIME类型集合。此外,它定义了一个get方法返回准备使用Extractor实例。ExtractorFactory不指定是否返回一个新的或共享的实例,这由实现者决定。HtmlExtractorFactory 的getSupportedMimeTypes方法返回一组包含“text/html”和其他已知的类似于HTML的MIME类型,每个get()方法调用,并返回一个新的HtmlExtractor。
实现时,你应该注意factory的实现尽可能轻量级。服务实现所需的任何高成本的初始化操作应该发生在get操作或一些其他类型的lazy方式。
Registries
为了跟踪所有可用的实现服务,注册表被使用。例如,ExtractorRegistry作为所有已知ExtractorFactories的容器。当被问及支持特定的MIME类型的所有工厂,你会得到一个其支持的MIME类型包含指定的MIME类型的所有ExtractorFactories集合。然后,您可以使用额外措施,以选择最好的一个,或者干脆用第一个。
此服务工厂注册方法灵感来自OSGi,它是一个建立面向组件的Java应用程序的平台。它使新工厂将在运行时添加。(在OSGi可以在单独的束通过捆绑的新工厂和注册他们为服务启动。此功能也可以在“正常”的桌面应用程序的探讨。)当在注册表中注册一个新的工厂 - 任何使用该注册表的应用程序现在可以开始使用这个新的工厂。这就是为什么工厂应尽可能轻量,因为它们可能会在应用程序启动时被实例化。
对于'正常'的java应用程序,而不是基于OSGi的默认注册表的实现也是可用的。例如,DefaultExtractorRegistry包含了在Aperture中每一个可用的ExtractorFactory的一个实例。当你想使用不同的设置,例如,因为你有自己的一套实现,您可以:
创建一个ExtractorRegistryImpl实例(extractorregistryimpl的defaultextractorregistry超类,不会自动填充本身),并将其手动填充它与ExtractorFactories,
向DefaultExtractorRegistry添加额外的的工厂,或
检查DefaultExtractorRegistry用于得到ExtractorFactory类的名称的xml文件,并设置自己的配置。
下面的图片显示的API概述了他们的依赖关系Extractor 的例子: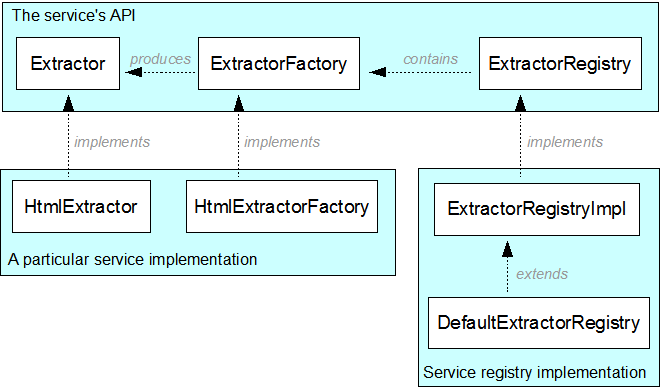
---------------------------------------------------------------------------
本系列WEB数据挖掘系本人原创
作者 博客园 刺猬的温驯
本文链接 http://www.cnblogs.com/chenying99/archive/2013/06/12/3133067.html
本文版权归作者所有,未经作者同意,严禁转载及用作商业传播,否则将追究法律责任。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号