import re
# str = 'python is the best language in the world'
# res=re.match('P',str,re.I)#精确匹配,p 匹配以什么为开头,即以p开头
# print(type(res))#返回 <class 're.Match'>
# print(res.group())
# #re.I 忽略大小写
# #re.M 多行匹配
# res1=re.match('(.* )is(.* ?). * ',str,re.I)
# print(res1.group())
# print(res1.groups())
# #group(num)可以获取匹配的数据,如果有多个匹配的结果,那么会以元组的形式存取到group对象中
#
![]()
# data='a1aaa'
# names='李达','李明','小王','小李'
# parrern='李.'
# pattern='..'
# for name in names:
# res = re.match(parrern, name)
# if res:
# print(res.group())
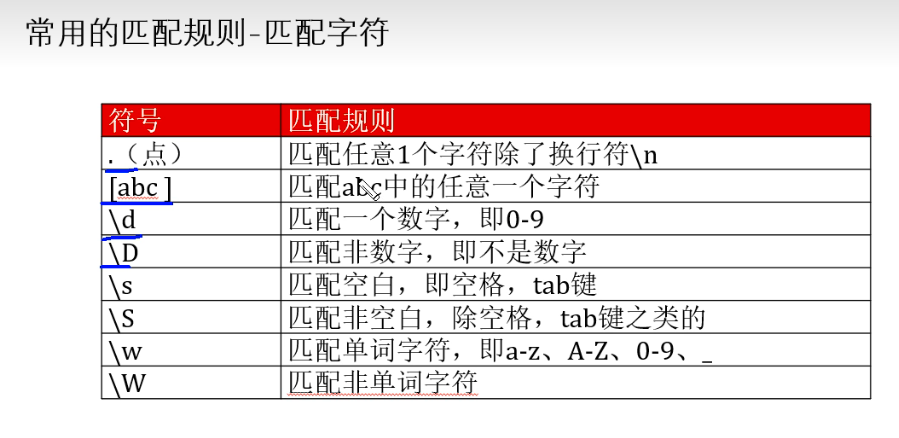
#[]的使用:匹配[]的任意一个字符
# str1='hello'
# # res=re.match('[he]',str1)
# # print(res.group())
# # pattern='[a-z]'
# # datas='a','b','g','wfa','wafafge'
# # for data in datas:
# # result=re.match(pattern,data)
# # if result:
# # print('匹配成功 %s'%result.group())
# # \d 匹配一个数字 0-9
# data='12312414'
# print(re.match('\d',data).group())
# # \D 匹配非数字
# data1='ww12312414'
# print(re.match('\D',data1).group())
![]()
res=re.match('[A-Z][a-z]*','Myt')#* 表示【a-z】可以匹配无限次
print(res.group())
#匹配符合规则:不能以数字开头,只能包含字母,数字,下划线的python变量
result=re.match('[a-zA-Z_]+','name')
print(result.group())
Myt
name
![]()
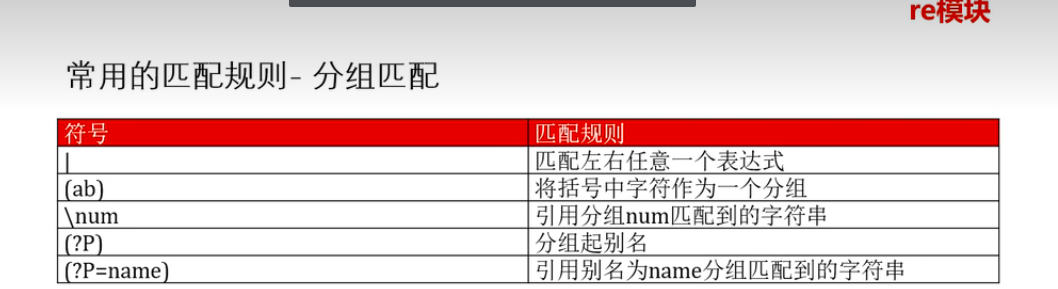
# \ 竖线,匹配左右任意一个表达式,从左往右,或的关系
import re
# string='wywsqpeng888'
# rs=re.match('(wywsqpeng|wywsqpeng888)',string)
# print(rs.group())
#结果为:wywsqpeng
# (ab)分组匹配,将括号中字符作为一个分组
#匹配电话号码 xxxx-123456789
#^ 有两种含义1:以xxx开头2:否定,取反
#[^-] 匹配不是-的字符
# res=re.match('([^-]*)-(\d*)','0355-456213987')
# print(res.group())
# print(res.group(1))
# print(res.group(2))
#\num 的使用 引用分组num匹配的字符
htmlTag='<html><h1>测试数据</h1></html>'
ress=re.match(r'<(.+)><(.+)>(.+)</\2></\1>',htmlTag)
print(ress.group(1))
print(ress.group(2))
print(ress.group(3))
#分组 别名的使用(?p<名字>)
#如何使用别名(?p=引用的名字)
data='<dir><h1>www.baidu.com</h1></div>'
res=re.match(r'<\w*><\w*>.*</\w*></\w*>',data)
print(res.group())
#compile re模块中的编译方法,可以把一个字符串编译成字节码
#优点:在使用正则表达式进行match操作时,python会将字符串转为正则表达
#式对象,而如果使用compile则只需要完成一次转换即可,以后在使用模式对
#象的话,无需重复转换
import re
# reobj=re.compile('\d{4}')
# #开始使用模式对象reobj
# rs=reobj.match('1223')
# print(rs.group())
#re.search 在全文中匹配一次,匹配到就返回
# data='我爱伟大的祖国,I love China,China is the best country'
# rs=re.search('China',data)
# print(rs)
# print(rs.group())
# print(data[19])
# print(data[20])
# <re.Match object; span=(15, 20), match='China'>
# China
# a
# ,
#re.findall() 查询字符串中某个正则表达式全部的非重复出现的情况,返回的是一个符合正则表达式的结果列表
data='华为是华人的骄傲华侨'
rs=re.findall('华.',data)
rsearch=re.search('华.',data)
print(rs)
print(rsearch)
# ['华为', '华人', '华侨']
# <re.Match object; span=(0, 2), match='华为'>
#使用compile
# reobj=re.compile('华.')
# print(reobj.search(data))
# print(reobj.findall(data))
#re.sub 实现目标的搜索和替换
#re.subn 实现目标的搜索和替换,返回被替换的次数,返回元组
# data ='python 是非常受欢迎的编程语言'
# pattern='[a-zA-Z]+'#字符集的范围,+代表前导字符模式出现1次以上
# res=re.sub(pattern,'Java',data)
# res1=re.subn(pattern,'Java',data)
# print(res)
# print(res1)
# Java 是非常受欢迎的编程语言
# ('Java 是非常受欢迎的编程语言', 1)
#re.split 实现分隔字符串
data='百度,腾讯,阿里,华为,360'
print(re.split(',',data))
# ['百度', '腾讯', '阿里', '华为', '360']
#贪婪模式
#默认的匹配规则
#在满足条件的情况下,尽可能多的去匹配
import re
rs=re.match('\d{6,9}','11122223333')
print(rs.group())
#非贪婪模式
#在满足条件的情况下,尽可能少的去匹配
rs1=re.match('\d{6,9}?','11122223333')
print(rs1.group())
#111222233
# 111222



 浙公网安备 33010602011771号
浙公网安备 33010602011771号