图
| 这个作业属于哪个班级 | 数据结构--网络2011/2012 |
| ---------- | ----------------- |
| 这个作业的地址 | DS博客作业04--图 |
| 这个作业的目标 | 学习图结构设计及相关算法 |
| 姓名 | 陈垚嘉 |
0.PTA得分截图

1.本周学习总结(6分)
1.1 图的存储结构
邻接矩阵的结构体定义:
typedef struct{
VertexType vexs[MaxVex];
EdgeType arc[MaxVex][MaxVex];
int numVertexs, numEdges;
}AdjacencyMatrix;
建图函数:
//创建邻接矩阵
void CreateAMatrix(AdjacencyMatrix* AM)
{
cout << "输入顶点数和边数:";
cin >> AM->numVertexs >> AM->numEdges;
cout << "==============================\n";
cout << "输入各个顶点:" << endl;
//邻接矩阵顶点输入
for(int i = 0; i<AM->numVertexs; i++)
{
char v;
cout << "顶点:" << i + 1;
cin >> v;
AM->vexs[i] = v;
}
//邻接矩阵初始化
for (int i = 0; i < AM->numVertexs; i++)
{
for (int j = 0; j<AM->numVertexs; j++)
{
AM->arc[i][j] = INF;
}
}
cout << "==============================\n";
//输入边的值
for (int k = 0; k<AM->numEdges; k++)
{
char i, j, w;
cout << "输入边(vi,vj)中的下标i和j和权重w:";
cin >> i >> j >> w;
AM->arc[i + Acsii][j + Acsii] = w;
AM->arc[j + Acsii][i + Acsii] = AM->arc[i + Acsii][j + Acsii];
}
}
1.1.1 邻接矩阵(不用PPT上的图)
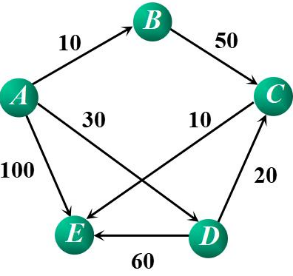
邻接矩阵:
0 10 0 30 100
0 0 50 0 0
0 0 0 0 10
0 60 20 0 60
0 0 0 0 0
1.1.2 邻接表

邻接表的结构体定义:
typedef struct EdgeNode/* 边表结点 */
{
int adjvex;/* 邻接点域,存储该顶点对应的下标 */
EdgeType weight;/* 用于存储权值,对于非网图可以不需要 */
struct EdgeNode *next; /* 链域,指向下一个邻接点 */
} EdgeNode;
typedef struct VextexNode/* 顶点表结点 */
{
VertexType data;/* 顶点域,存储顶点信息 */
EdgeNode *firstedge;/* 边表头指针 */
} VextexNode, AdjList[MAXVEX];
typedef struct
{
AdjList adjList;
int numNodes, numEdges; /* 图中当前顶点数和边数 */
} GraphAdjList;
建图函数:
void CreateALGraph(GraphAdjList *Gp)
{
int i, j, k;
EdgeNode *pe;
cout << "输入顶点数和边数(空格分隔):" << endl;
cin >> Gp->numNodes >> Gp->numEdges;
for (i = 0 ; i < Gp->numNodes; i++)
{
cout << "输入顶点信息:" << endl;
cin >> Gp->adjList[i].data;
Gp->adjList[i].firstedge = NULL;/* 将边表置为空表 */
}
for (k = 0; k < Gp->numEdges; k++)/* 建立边表 */
{
cout << "输入边(vi,vj)的顶点序号i,j(空格分隔):" << endl;
cin >> i >> j;
pe = (EdgeNode *)malloc(sizeof(EdgeNode));
pe->adjvex = j;/* 邻接序号为j */
/* 将pe的指针指向当前顶点上指向的结点 */
pe->next = Gp->adjList[i].firstedge;
Gp->adjList[i].firstedge = pe;/* 将当前顶点的指针指向pe */
pe = (EdgeNode *)malloc(sizeof(EdgeNode));
pe->adjvex = i;
pe->next = Gp->adjList[j].firstedge;
Gp->adjList[j].firstedge = pe;
}
}
1.1.3 邻接矩阵和邻接表表示图的区别
*在存储方式上:邻接矩阵用一维数组存放顶点,用二维数组存放邻接关系。而邻接表用头节点存放顶点用表结点存放邻接关系。
*从操作角度来说:邻接矩阵易于判定顶点是否邻接,查顶点的邻接点但是插入、删除顶点复杂。邻接表易于:查询某顶点的邻接点,边或弧的插入、删除但是判定顶点是否邻接,比邻接矩阵低效。
稀疏图选择邻接表比较合适,稠密图适合邻接矩阵。
如果定点数为n,边数为e
1.若采用邻接矩阵存储,时间复杂度为O(n^2);
2.若采用邻接链表存储,建立邻接表或逆邻接表时,若输入的顶点信息即为顶点的编号,则时间复杂度为O(n+e);若输入的顶点信息不是顶点的编号,需要通过查找才能得到顶点在图中的位置,则时间复杂度为O(ne);
1.2 图遍历
1.2.1 深度优先遍历
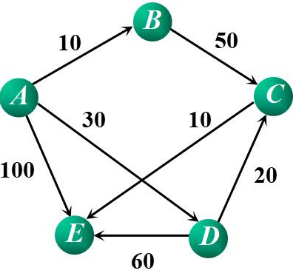
深度遍历从A开始,结果并不唯一。其中一个结果为哦A-B-C-E-D。
深度遍历代码:
int visitedDFS[MAXV] = { 0 }; //全局数组,记录是否遍历
void DFS(ListGraph* LG, int v) {
EdgeNode* p;
visitedDFS[v] = 1; //记录已访问,置 1
printf("%2d", v); //输出顶点编号
p = LG->adjList[v].firstEdge; //p 指向顶点 v 的第一个邻接点
while (p != NULL) {
if (visitedDFS[p->adjVer] == 0 && p->weight != INF) { //如果 p->adjVer 没被访问,递归访问它
DFS(LG, p->adjVer);
}
p = p->nextEdge; //p 指向顶点 v 的下一个邻接点
}
}
深度优先遍历求解哪些问题:可以解决连通域求解问题、最长路径问题等
1.2.2 广度优先遍历
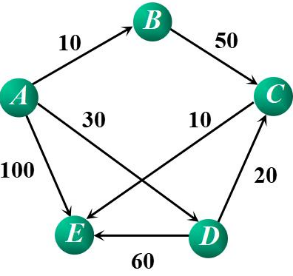
同样,广度优先遍历结果不唯一。其中从顶点A出发一个结果为:A-B-D-E-C
void BFSTraverse(AdjacencyMatrix* AM)
{
queue<int> Q;
for (int i = 0; i<AM->numVertexs; i++)
visited[i] = 0;
//InitQueue(&Q); //初始化一个空列表
for (int i = 0; i<AM->numVertexs; i++)
{
if (!visited[i])
{
visited[i] = 1;
cout << AM->vexs[i];
//EnQueue(&Q, i); //将i插入到队列的队尾
Q.push(i);
while (!Q.empty())
{
i = Q.front(); //删除队列的队头元素,并用i返回这个值
Q.pop(); //你用的时候用front取出来尽管用,等到用完了再pop。
//删除队列的队头元素,并用i返回这个值
//这边除了在队列中把第一个元素删掉以外
//还要把这个值返回,就像表中给的,还要根据
//返回的A来找到B和F呢
for (int j = 0; j<AM->numVertexs; j++)
{
if (!visited[j] && AM->arc[i][j] != INF)
{
visited[j] = 1;
cout << AM->vexs[j];
//EnQueue(&Q, &j);
Q.push(j); //这就相当于把B和F分步输入到队列中
}
}
}
}
}
}
广度优先遍历解决问题:最短路径问题,其思想是BFS(广度优先遍历)在一般的带权图中是不能解决最短路问题,了解BFS的都知道,BFS是根据节点到源节点之间的节点数遍历的,也就是先访问离源节点节点数最少的点。要使得BFS能计算最短路径,需要图结构满足所有的权值相等。
1.3 最小生成树
最小生成树是指由n个结点的连通图的生成树时原图的极小连通子图,并且一定包含原图中所有的节点,并且有保持图连通的最少的边。
1.3.1 Prim算法求最小生成树
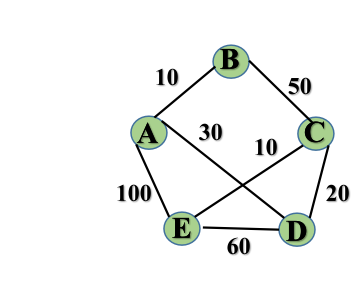
基于上述图结构求prim算法生成的最小生成树的边序列:
step1:
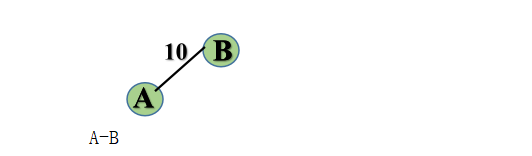
step2:
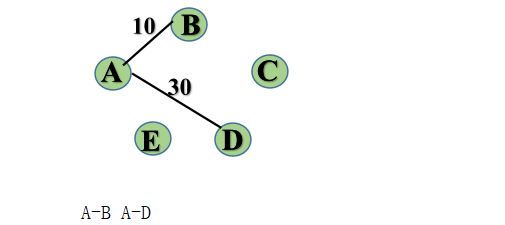
step3:
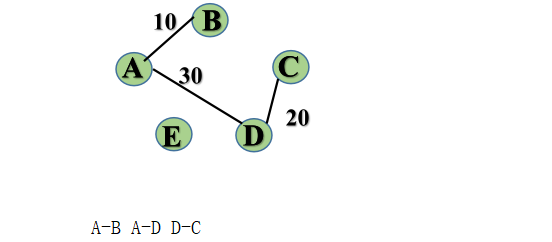
step4:
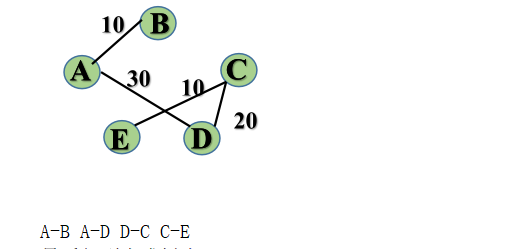
最后得到生成树为:
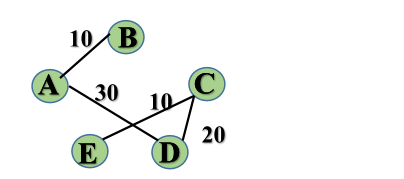
实现prim算法的两个辅助数组是什么及其作用:
为了实现Prim算法,我们需要依照思想设置一些辅助数组。
int lowcost[v] 表示以v为终点的边(u,v)的权值,v 是当前尚未选入生成树的顶点;
int nearest[v] 保存边(u,v)的另一个顶点u,u 在生成树上;
bool visited[i] 标志某个顶点当前是否已被选入在生成树上。
Prim算法代码:
void prim(int source) //起点
{
memset(lowcost,INF,sizeof(lowcost));
memset(visited,false,sizeof(visited));
visited[source] = true;
for(int i=0;i<vertex_num;i++){
lowcost[i] = matrix[source][i];
nearest[i] = source;
}
int min_cost; //最小权值
int min_cost_index; //最小权值对应的边的未在最小生成树的那一点
sum = 0;
for(int i=1;i<vertex_num;i++){ //寻找除起点以外的n-1个点
min_cost = INF;
for(int j=0;j<vertex_num;j++){
if(visited[j]==false && lowcost[j]<min_cost){
min_cost = lowcost[j];
min_cost_index = j; //定位顶点
}
}
visited[min_cost_index] = true; //将已进入最小代价生成树的结点标志位true
sum += lowcost[min_cost_index];
for(int j=0;j<vertex_num;j++){ //以找到的最小下标为起点更新lowcost数组
if(visited[j]==false && matrix[min_cost_index][j]<lowcost[j]){
lowcost[j] = matrix[min_cost_index][j];
nearest[j] = min_cost_index;
}
}
}
}
Prim算法的时间复杂度,适合什么图?
Prim算法的时间复杂度为O(V2),不依赖于E,因此它适用于求解边稠密的图的最小生成树。
13.2 Kruskal算法求解最小生成树
基于上述图结构求Kruskal算法生成的最小生成树边序列
step1:
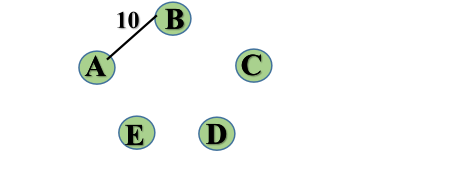
step2:

step3:
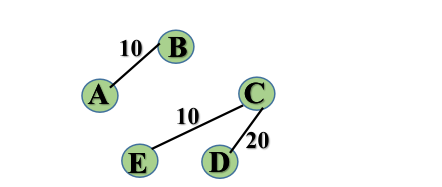
step4:
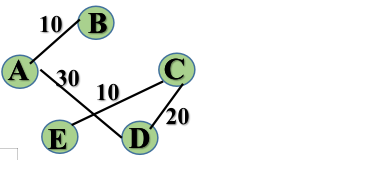
实现Kruskal算法的辅助数据结构是什么?其作用是?
Kruskal算法用到的数据结构有:
1、边顶点与权值存储结构(即图是由连接某一条边的两个顶点,以及这条边的权值来进行存储)
2、并查集:并查集就是一个用双亲表示法所表示的森林,我们可以利用这个结构来查找某一个顶点的双亲,进而找到根结点。这样,我们就能判断某两个顶点是否同源,在图中的表现就是加上这条边后会不会形成环。如果形成环,就不是简单图。并查集以顶点为基准,有几个顶点,就有几项。
分析Kruskal算法的时间复杂度,使用什么图结果,为什么
克鲁斯卡尔算法,从边的角度求网的最小生成树,时间复杂度为O(eloge)。和普里姆算法恰恰相反,更适合于求边稀疏的网的最小生成树。因为克鲁斯卡尔算法主要针对边展开,边数少时效率会很高,所以对于稀疏图有优势。
1.4 短路径
1.4.1 Dijkstra算法求解最短路径
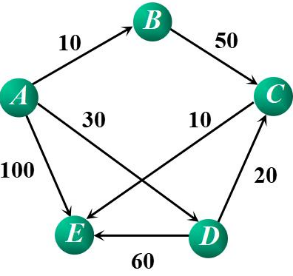
从顶点A开始
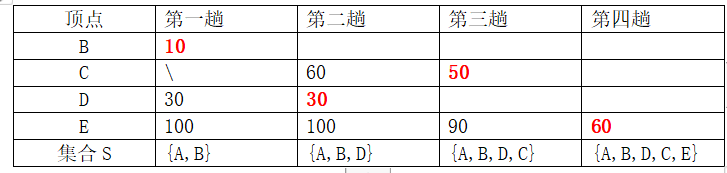
Dijkstra算法如何解决贪心算法无法求解最用问题?展示算法中的解决代码。
求解过程:
1、对于一个有向带权图<V,E>,将N中顶点点分成两组:
第一组S:已求出的最短路径的终点的集合。(初始时,只包含源点V0)
第二组V-S:尚未求出的最短路径的顶点集合。(初始时为,V-{V0})
2、算法按将各顶点与V0同最短路径长度递增的次序,逐个将集合V-S中的顶点,加入到集合S中去。
3、在这个过程中,总能保持从V0到集合S中各顶点的路径长度时始终不大于到集合V-S中各顶点的路径长度。
代码:
void ShortestPath_Dijkstra(AMGraph G, int V0){
//step1 n个顶点依次初始化
int n =G.vexnum;
for(int v=0;v<n;v++){
S[v] = false;
D[v] = G.arcs[V0][v];
if(D[v]<MaxInt){
Path[v] = V0;
} else {
Path[v] = -1;
}
}
//step2 将源点V0划入已确定集合S中
S[V0] = true;
D[V0] = 0; // 源点V0到源点V0的最短路径长度必然为0
//step3 贪心算法策略:
// 3.1 循环遍历所有结点:
// 3.2 先确定当前最短路径的终点v;
// 3.3 然后,将v划入已确定集合S中;
// 3.4 最后,以利用结点v更新所有尚未确定的结点的最短路径
int v;
int min;
D[G.vexnum] = MaxInt;
for(int i=1;i<n;i++){//3.1循环遍历所有结点 (即 求从源点V0到图中每一顶点(共计n-1个顶点)的最短路径)
//3.2 确定当前最短路径的终点v;
min = MaxInt;
for(int w=0;w<n;w++){
if(S[w]==false && D[w]<min){//比本轮循环中,已知的最短路径还短 【易错/易漏】 S[w]==false : 必须满足当前结点 Vw 属于尚未确定的结点
v = w;
min = D[w];
}
}
//3.3 然后,将v划入已确定集合S中;
S[v] = true;
//3.4 最后,以利用结点v更新所有尚未确定的结点的最短路径
for(int w=0;w<n;w++){
//↓更新Vw结点的最短路径长度为 D[v] + G.arcs[v][w]
//cout<<"S["<<w<<"]:"<<S[w]<<"D["<<v<<"]"<<D[v]<<"G.arcs["<<v<<"]["<<w<<"]"<<"D["<<w<<"]"<<D[w]<<endl;
if(S[w]==false && (D[v] + G.arcs[v][w] < D[w])){//【易错/易漏】 S[w]==false : 必须满足当前结点 Vw 属于尚未确定的结点
D[w] = D[v] + G.arcs[v][w];
Path[w] = v; // 更新 结点Vw的前驱为 v
}
}
v = G.vexnum;
}
}
Dijkstra算法的时间复杂,适用什么图结构,为什么
Dijkstra 时间复杂度:O(n^3),Dijkstra算法适用于求图中两节点之间最短路径,适用于边的长度均不为负数的有向图,它计算从一个起始顶点到其他所有顶点的最短路径的长度。因为他的求解过程可以求出初始节点到各个节点的最短路径长度。
1.4.2 Floyd算法求解最短路径
Floyd算法解决什么问题:
Floyd算法可以解决多源最短路径问题。
Floyd算法需要哪些辅助数据结构:
数组: D[MVNum][MVNum]; // 记录顶点Vi和Vj之间的最短路径长度
数组 Path[MVNum][MVNum]; // 最短路径上顶点Vj的前一顶点的序号
优点:容易理解,可以算出任意两个节点之间的最短距离,代码编写简单
比较:
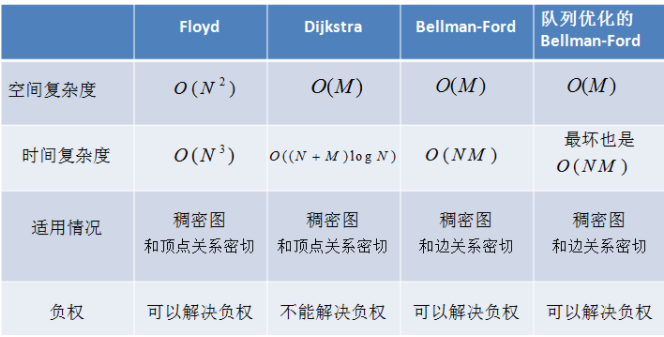
1.5 拓扑排序
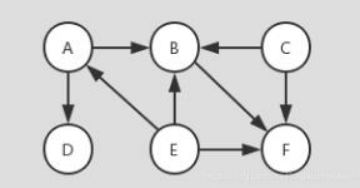
拓扑排序结果并不唯一,如上图的拓扑排序有:C-E-A-B-F;E-A-C-B-F;E-C-A-B-F等。
代码:
void TopLogicalSort(Graphlnk<T, E> &G) {
int i, w, v;
int n; // 顶点数
int *count = new int[DefaultVertices]; // 入度数组
int top = -1;
// 清零
for(i = 0; i< DefaultVertices; i++)
count[i] = 0;
// 输入顶点和边
G.inputGraph(count);
n = G.numberOfVertices(); // 获取图的顶点数
for(i = 0; i < n; i++) { // 检查网络所有顶点
if(count[i] == 0) { // 入度为0的顶点进栈
count[i] = top;
top = i;
}
}
// 进行拓扑排序,输出n个顶点
for(i = 0; i < n; i++) {
if(top == -1) { // 空栈
cout << "网络中有回路!" << endl;
return;
} else {
v = top;
top = count[top];
cout << G.getValue(v) << " "; // 输出入度为0的顶点
w = G.getFirstNeighbor(v); // 邻接顶点
while(w != -1) { // 扫描出边表
if(--count[w] == 0) { // 邻接顶点入度减1,如果入度为0则进栈
count[w] = top;
top = w;
}
w = G.getNextNeighbor(v, w); // 兄弟结点(取顶点v的邻接顶点w的下一邻接顶点)
}
}
}
cout << endl;
}
边的定义:
template <class T, class E>
struct Edge { // 边结点的定义
int dest; // 边的另一顶点位置
Edge<T, E> *link; // 下一条边链指针
};
顶点的定义:
struct Vertex { // 顶点的定义
T data; // 顶点的名字
Edge<T, E> *adj; // 边链表的头指针
};
伪代码:
定义一个int型顶点数 n 存储顶点的个数
定义一个int型数组count存储入度
for(顶点个数未遍历完)
初始化入度为零;
for(所有结点未遍历完){
if(入度为零){
顶点v进栈;
}
}
for(遍历拓扑排序中所有顶点){
if(空栈){
图中有回路;
}else{
取栈顶元素;
While(当前存在顶点){
If(入度为零)
出栈;
}
取邻接顶点;
}
}
如何用拓扑排序代码检查一个有向图是否有环路:
如果能够用拓扑排序完成对图中所有节点的排序的话,就说明这个图中没有环。
而如果不能完成,则说明有环。
1.6 关键路径
什么叫AOE-网:
有向图中,用顶点表示活动,用有向边表示活动之间开始的先后顺序,则称这种有向图为AOV(Activity On Vertex)网络;AOV网络可以反应任务完成的先后顺序(拓扑排序)。
在AOV网的边上加上权值表示完成该活动所需的时间,则称这样的AOV网为AOE(Activity On Edge)网
什么是关键路径:关键活动:
完成整个工程所需的时间等于从源点到汇点的最长路径长度,即该路径中所有活动的持续时间之和最大。这条路径称为关键路径(critical path)。关键路径上所有活动都是关键活动。所谓关键活动(critical activity),是不按期完成会影响整个工程进度的活动。只要找到关键活动,就可以找到关键路径。
2.PTA实验作业(4分)
2.1 六度空间(2分)
2.1.1 伪代码(贴代码,本题0分)
传入G[MAXVEX][MAXVEX]为图G的邻接矩阵
队列初始化;
For(j=0;j<=Nv;j++) do
Visited[j]=0;//初始所有节点未访问
End for
Visited[i]=1;
i入队
While(队列不为空)
{
出队;
For(j=1;j<=Nv;j++) do
if(顶点未被访问)do
Visited[j]=1;//访问
入队;
End if
End fo
If(temp==last)do
level++;
Last = tail;
cnt++;
j++;
End do
If(当前访问第六层)do
break;
End do
}
返回 cnt;
2.1.2 提交列表

2.1.3 本题知识点
邻接表的建图和广度遍历BFS
使用node和lastnode两个变量来记录每一层次结束的最后结点,从而使level在一层遍历结束后增加
使用level记录遍历层次来控制广度遍历所遍历的层次,在达到规定距离时退出循环,得到距离内结点个数
2.2 村村通或通信网络设计或旅游规划(2分)
传入图G的邻接矩阵
for (i = 1; i <= n; i++) do//对链接矩阵初始化
for (j = 1; j <= n; j++) do
G[i][j] = 999999;
end for
end for
输入图的各条边的权值;
for (i = 1; i <= n; i++) do//将和源点所有相通的点对应边的权值复制给数组cost[i]
cost[i] = G[1][i];
end do
for (t = 1; t < n; t++) do
min = 999999;//初始化最小值
for (i = 1; i <= n; i++) do
if (如果不是源点到自身并且权值小于最小值) do
min = cost[i];//重新赋值最小值
End if
End for
if (k != 0) do
sum = sum + cost[k];//全职求和
for (j = 1; j <= n; j++) do
if (G[k][j] < cost[j]) do
cost[j] = G[k][j];
End if
End for
End if
End for
for (i = 1; i <= n; i++) { //遍历所有路径
if (cost[i] != 0) { //如果未被访问
flag = 1;
break;
}
}
if (flag == 1) do
cout<<"-1";
End if
else
cout<<sum;
return 0;
伪代码为思路总结,不是简单翻译代码。
2.2.2 提交列表

2.2.3 本题知识点
这道题根本是考察求最小生成树的算法,可以用Prim或者Kruskal算法解决

 浙公网安备 33010602011771号
浙公网安备 33010602011771号