

UE4.27, 揣摩源码, 序列化 (一) FArrayReader, FArrayWriter
1. 从ArrayReader.h和ArrayWriter.h开始
1.1. SVO
为了减少误解,介绍一下SVO
这里的read和write的主词都是array,宾语都是memory
所以前者是从内存读出array,后者是将array写入内存
1.2. 关键继承关系
FArrayReader ,FArrayWriter
class FArrayReader final : public FMemoryArchive, public TArray<uint8>
typedef FBufferArchive FArrayWriter;// 别名而已
class FBufferArchive : public FMemoryWriter, public TArray<uint8>
class FMemoryWriter : public FMemoryArchive
FMemoryArchive
class FMemoryArchive : public FArchive
class FArchive : private FArchiveState
1.3. ArIsLoading, ArIsSaving
archive在设计上,接口同时负责了 读出对象/写入内存 的 序列化/反序列化
具体派生类根据它的具体功能来设置这两个布尔量,并将接口重写为功能方向上二选一的具体版本
其他调用者,在使用archive派生类完成序列化操作的过程中,也会将该ar的两个布尔变量纳入分支控制的检查
实际代码形如下列结构(Ar是某个具体派生对象,父类是farchive)
if (Ar.IsLoading()){/*...*/}
else if(Ar.IsSaving()){/*...*/}
<<操作符的重载实现,其内部也有这种IsLoading判断,籍此来同时满足写入读出的需要
1.4. 应用不同特化类时的分支控制
在阅读了上述继承关系的类的构造后不难发现,在我们考察范围里,真正特化到具体功能了、需要设置该关键布尔量的类分别是FArrayReader FMemoryWriter
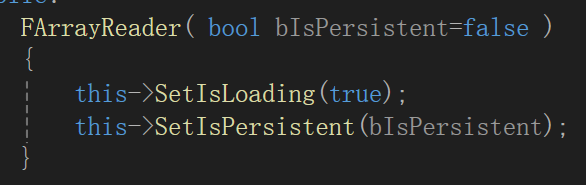
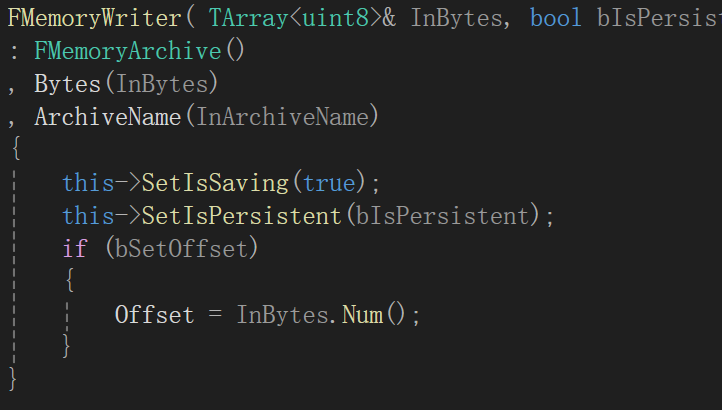
他们分别将序列化函数Serialize(void* Data, int64 Num或Count)重写为如下样式
ps: 此处只贴出关键代码的区别,也就是memcpy的调用区别
FArrayReader (Offset是为了确定已经对源地址读出了多少个字节)

FMemoryWriter (Bytes 是 FMemoryWriter构造函数 的第一个参数TArray<uint8>& InBytes)

所以我们可以理解为何对于几乎同样的调用,可以分为序列化或者反序列化两种实际效果
如array里对serialize的调用,参数几乎一样,但是进入不同分支的Ar将不可避免的是两种派生类,正如上述的关键布尔量的讨论
if (Ar.IsLoading()){
// ... //
Ar.Serialize(GetData(), NewArrayNum * SerializedElementSize);}
else if (Ar.IsSaving()){
// ... //
Ar.Serialize(GetData(), ArrayCount * SerializedElementSize);}
Data形参总是传入该数组的地址头,
对于读取任务,它被放在memcpy的dest端,接收 某ar对象 的tarray<uint8>的内存,
对于写入任务,它被放在memcpy的src端,它的内存被写进 某ar对象 的tarray<uint8>的内存(这个ar对象的tarray<uint8>在构造该ar的时候传递引用参数获得)
(事实上这个写入任务和之后的BitReader也只能写进某个TArray里,与我原本设想的指定硬地址序列化不同 ,仍然是序列化到一个内存对象,实际写入磁盘,
还需要另外的函数,比如这样调用 FFileHelper::SaveArrayToFile(ar,*path))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号