人工智能第三课:数据科学中的Python
我用了两天左右的时间完成了这一门课《Introduction to Python for Data Science》的学习,之前对Python有一些基础,所以在语言层面还是比较顺利的,这门课程的最大收获是让我看到了在数据科学中Python的真正威力(也理解了为什么Python这么流行),同时本次课程的交互式练习体验(Datacamp)非常棒。
这门课程主要包括了6个单元的内容,一开始介绍了Python的基本概念(常见数据类型和变量),从第二节开始讲解列表在Python中的使用,并且逐步演进,我们还学习了使用真正为Data Science准备的几个package的应用。
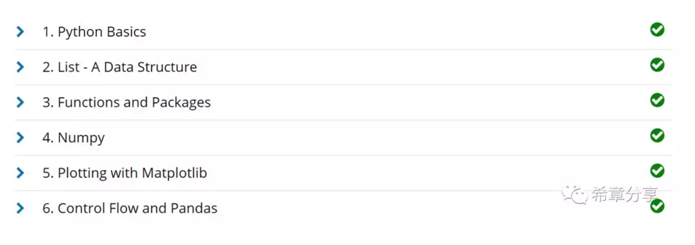
从数据科学的角度来看,Python可能真的是很适合的一个编程语言和环境。这不光是因为他本身的语法比较简单,而且目前已经有几个非常强大的包(Package)对其进行支持。
Python中的list用来表示一系列的数据,它非常灵活,甚至可以在一个列表中包含不同类型的数据,当然这样也就带来了一定的负面作用,例如性能。而numpy的array则是对list的一种改进,它进行规划化(一个array的轴上只支持同一种数据类型),并提供了更多的一些与数据科学的运算(函数)。

它自身的运算规则也跟列表有极大的区别,例如
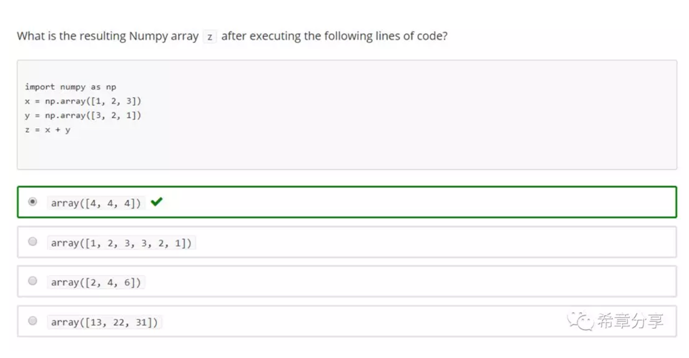
numpy库内置支持很多科学运算的函数,不需要依赖其他库

数据科学不光是对数据的处理,而且还需要对数据进行展示。目前全世界最流行的用来做数据可视化的库是matplotlib。
下图是一个最简单的例子
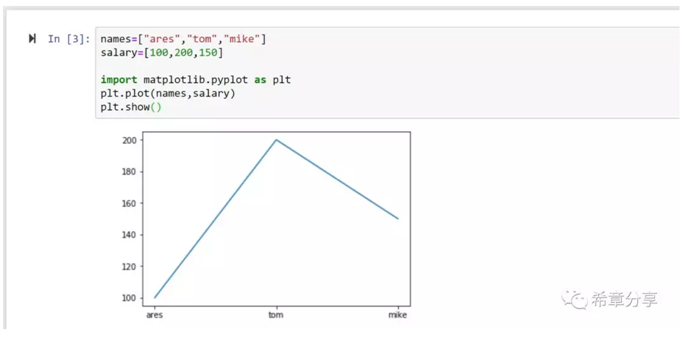
请注意,图形的数据来源既可以是List,也可以是Array,当然还可以是下面的终极解决方案DataFrame,来自pandas这个库。
numpy和matplotlib,可以很好地处理数据科学的场景。但如果数据量真的很大,则可能需要用到pandas了。

pandas提供了一个全新的dataframe的对象,它是完全为科学运算和统计而设计的,而且它自带了可视化组件库,不需要额外依赖matplotlib。
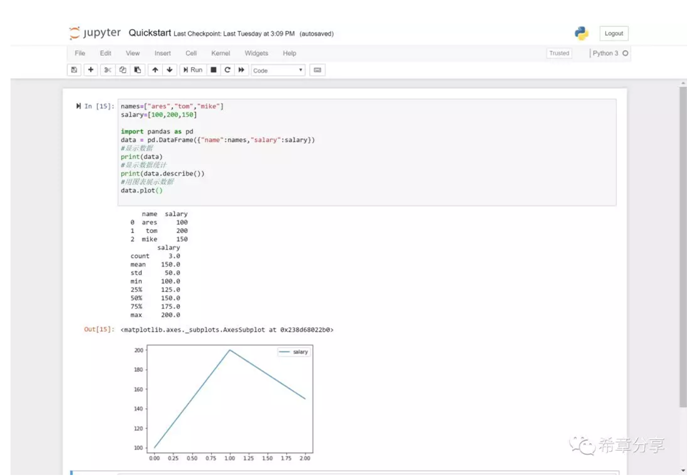
从技术上说,DataFrame很像是一个Excel表格或者数据库,它具有行和列的概念,也有索引的技术。
DataFrame还支持从外部文件(例如csv)或者网络地址加载数据,这将使得它真正具有实用的价值。
最后,我之前提到过了,本次课程给我最惊喜的一个体验是交互式练习。这是一个第三方学习平台(DataCamp)提供的,非常酷。

最后,基于Jupyter构建的notebooks.azure.com ,让我们可以在线编辑python,并且运行,形成笔记——不需要azure订阅即可使用。如果你愿意,你还可以在本地安装Jupyter。
本地安装Jupyter,请参考 https://jupyter.org/install.html

请通过 https://aka.ms/learningAI 或者扫描下面的二维码关注本系列文章《人工智能学习笔记》




 浙公网安备 33010602011771号
浙公网安备 33010602011771号