

BAT机器学习面试1000题系列(21-30题)
BAT机器学习面试1000题系列(21-30题)
21.请大致对比下plsa和LDA的区别
pLSA中,主题分布和词分布确定后,以一定的概率(
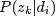
、
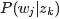
)分别选取具体的主题和词项,生成好文档。而后根据生成好的文档反推其主题分布、词分布时,最终用EM算法(极大似然估计思想)求解出了两个未知但固定的参数的值:
(由
转换而来)和
(由
转换而来)。
文档d产生主题z的概率,主题z产生单词w的概率都是两个固定的值。
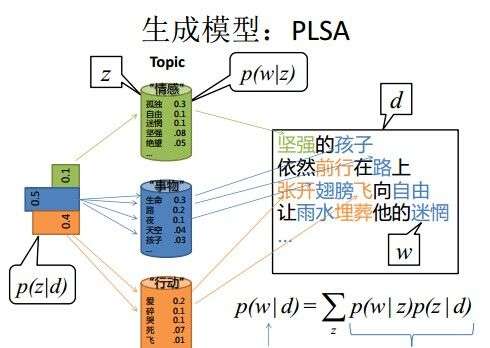
举个文档d产生主题z的例子。给定一篇文档d,主题分布是一定的,比如{ P(zi|d), i = 1,2,3 }可能就是{0.4,0.5,0.1},表示z1、z2、z3,这3个主题被文档d选中的概率都是个固定的值:P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,如下图所示(图截取自沈博PPT上):
但在贝叶斯框架下的LDA中,我们不再认为主题分布(各个主题在文档中出现的概率分布)和词分布(各个词语在某个主题下出现的概率分布)是唯一确定的(而是随机变量),而是有很多种可能。但一篇文档总得对应一个主题分布和一个词分布吧,怎么办呢?LDA为它们弄了两个Dirichlet先验参数,这个Dirichlet先验为某篇文档随机抽取出某个主题分布和词分布。
文档d产生主题z(准确的说,其实是Dirichlet先验为文档d生成主题分布Θ,然后根据主题分布Θ产生主题z)的概率,主题z产生单词w的概率都不再是某两个确定的值,而是随机变量。
还是再次举下文档d具体产生主题z的例子。给定一篇文档d,现在有多个主题z1、z2、z3,它们的主题分布{ P(zi|d), i = 1,2,3 }可能是{0.4,0.5,0.1},也可能是{0.2,0.2,0.6},即这些主题被d选中的概率都不再认为是确定的值,可能是P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,也有可能是P(z1|d) = 0.2、P(z2|d) = 0.2、P(z3|d) = 0.6等等,而主题分布到底是哪个取值集合我们不确定(为什么?这就是贝叶斯派的核心思想,把未知参数当作是随机变量,不再认为是某一个确定的值),但其先验分布是dirichlet 分布,所以可以从无穷多个主题分布中按照dirichlet 先验随机抽取出某个主题分布出来。如下图所示(图截取自沈博PPT上):

换言之,LDA在pLSA的基础上给这两参数(

、

)加了两个先验分布的参数(贝叶斯化):一个主题分布的先验分布Dirichlet分布
,和一个词语分布的先验分布Dirichlet分布
。
综上,LDA真的只是pLSA的贝叶斯版本,文档生成后,两者都要根据文档去推断其主题分布和词语分布,只是用的参数推断方法不同,在pLSA中用极大似然估计的思想去推断两未知的固定参数,而LDA则把这两参数弄成随机变量,且加入dirichlet先验。
更多请参见:http://blog.csdn.net/v_july_v/article/details/41209515
22.请简要说说EM算法
@tornadomeet,本题解析来源:http://www.cnblogs.com/tornadomeet/p/3395593.html
有时候因为样本的产生和隐含变量有关(隐含变量是不能观察的),而求模型的参数时一般采用最大似然估计,由于含有了隐含变量,所以对似然函数参数求导是求不出来的,这时可以采用EM算法来求模型的参数的(对应模型参数个数可能有多个),EM算法一般分为2步:
E步:选取一组参数,求出在该参数下隐含变量的条件概率值;
M步:结合E步求出的隐含变量条件概率,求出似然函数下界函数(本质上是某个期望函数)的最大值。
重复上面2步直至收敛。
公式如下所示:

M步公式中下界函数的推导过程:

EM算法一个常见的例子就是GMM模型,每个样本都有可能由k个高斯产生,只不过由每个高斯产生的概率不同而已,因此每个样本都有对应的高斯分布(k个中的某一个),此时的隐含变量就是每个样本对应的某个高斯分布。
GMM的E步公式如下(计算每个样本对应每个高斯的概率):

更具体的计算公式为:

M步公式如下(计算每个高斯的比重,均值,方差这3个参数):

23.KNN中的K如何选取的? 关于什么是KNN,可以查看此文:http://blog.csdn.net/v_july_v/article/details/8203674。KNN中的K值选取对K近邻算法的结果会产生重大影响。如李航博士的一书「统计学习方法」上所说:
1.如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
2.如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
3.K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的累,模型过于简单,忽略了训练实例中大量有用信息。
在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。
24.防止过拟合的方法
过拟合的原因是算法的学习能力过强;一些假设条件(如样本独立同分布)可能是不成立的;训练样本过少不能对整个空间进行分布估计。
处理方法有:
- a.早停止:如在训练中多次迭代后发现模型性能没有显著提高就停止训练
- b.数据集扩增:原有数据增加、原有数据加随机噪声、重采样
- c.正则化
- d.交叉验证
- e.特征选择/特征降维
25.机器学习中,为何要经常对数据做归一化
@zhanlijun,本题解析来源:http://www.cnblogs.com/LBSer/p/4440590.html
机器学习模型被互联网行业广泛应用,如排序(参见http://www.cnblogs.com/LBSer/p/4439542.html)、推荐、反作弊、定位(参见http://www.cnblogs.com/LBSer/p/4020370.html)等。一般做机器学习应用的时候大部分时间是花费在特征处理上,其中很关键的一步就是对特征数据进行归一化,为什么要归一化呢?很多同学并未搞清楚,维基百科给出的解释:1)归一化后加快了梯度下降求最优解的速度;2)归一化有可能提高精度。下面再简单扩展解释下这两点。
1) 归一化为什么能提高梯度下降法求解最优解的速度?
斯坦福机器学习视频做了很好的解释:https://class.coursera.org/ml-003/lecture/21
如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;
而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。

2) 归一化有可能提高精度
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
3) 归一化的类型
a. 线性归一化

这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min。
b. 标准差标准化
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:

其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
c.非线性归一化
经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等。
26.谈谈深度学习中的归一化问题

详情参见此视频:http://www.julyedu.com/video/play/69/686
27.哪些机器学习算法不需要做归一化处理? 概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、rf。而像adaboost、svm、lr、KNN、KMeans之类的最优化问题就需要归一化。
@管博士:我理解归一化和标准化主要是为了使计算更方便 比如两个变量的量纲不同 可能一个的数值远大于另一个那么他们同时作为变量的时候 可能会造成数值计算的问题,比如说求矩阵的逆可能很不精确 或者梯度下降法的收敛比较困难,还有如果需要计算欧式距离的话可能 量纲也需要调整 所以我估计lr 和 knn 保准话一下应该有好处。至于其他的算法 我也觉得如果变量量纲差距很大的话 先标准化一下会有好处。
@寒小阳:一般我习惯说树形模型,这里说的概率模型可能是差不多的意思。
28.对于树形结构为什么不需要归一化? 数值缩放,不影响分裂点位置。因为第一步都是按照特征值进行排序的,排序的顺序不变,那么所属的分支以及分裂点就不会有不同。对于线性模型,比如说LR,我有两个特征,一个是(0,1)的,一个是(0,10000)的,这样运用梯度下降时候,损失等高线是一个椭圆的形状,这样我想迭代到最优点,就需要很多次迭代,但是如果进行了归一化,那么等高线就是圆形的,那么SGD就会往原点迭代,需要的迭代次数较少。
另外,注意树模型是不能进行梯度下降的,因为树模型是阶跃的,阶跃点是不可导的,并且求导没意义,所以树模型(回归树)寻找最优点事通过寻找最优分裂点完成的。
29.数据归一化(或者标准化,注意归一化和标准化不同)的原因 @我愛大泡泡,来源:http://blog.csdn.net/woaidapaopao/article/details/77806273
要强调:能不归一化最好不归一化,之所以进行数据归一化是因为各维度的量纲不相同。而且需要看情况进行归一化。
有些模型在各维度进行了不均匀的伸缩后,最优解与原来不等价(如SVM)需要归一化。
有些模型伸缩有与原来等价,如:LR则不用归一化,但是实际中往往通过迭代求解模型参数,如果目标函数太扁(想象一下很扁的高斯模型)迭代算法会发生不收敛的情况,所以最坏进行数据归一化。
补充:其实本质是由于loss函数不同造成的,SVM用了欧拉距离,如果一个特征很大就会把其他的维度dominated。而LR可以通过权重调整使得损失函数不变。
30.请简要说说一个完整机器学习项目的流程 @寒小阳、龙心尘
1 抽象成数学问题
明确问题是进行机器学习的第一步。机器学习的训练过程通常都是一件非常耗时的事情,胡乱尝试时间成本是非常高的。
这里的抽象成数学问题,指的我们明确我们可以获得什么样的数据,目标是一个分类还是回归或者是聚类的问题,如果都不是的话,如果划归为其中的某类问题。
2 获取数据
数据决定了机器学习结果的上限,而算法只是尽可能逼近这个上限。
数据要有代表性,否则必然会过拟合。
而且对于分类问题,数据偏斜不能过于严重,不同类别的数据数量不要有数个数量级的差距。
而且还要对数据的量级有一个评估,多少个样本,多少个特征,可以估算出其对内存的消耗程度,判断训练过程中内存是否能够放得下。如果放不下就得考虑改进算法或者使用一些降维的技巧了。如果数据量实在太大,那就要考虑分布式了。
3 特征预处理与特征选择
良好的数据要能够提取出良好的特征才能真正发挥效力。
特征预处理、数据清洗是很关键的步骤,往往能够使得算法的效果和性能得到显著提高。归一化、离散化、因子化、缺失值处理、去除共线性等,数据挖掘过程中很多时间就花在它们上面。这些工作简单可复制,收益稳定可预期,是机器学习的基础必备步骤。
筛选出显著特征、摒弃非显著特征,需要机器学习工程师反复理解业务。这对很多结果有决定性的影响。特征选择好了,非常简单的算法也能得出良好、稳定的结果。这需要运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。
4 训练模型与调优
直到这一步才用到我们上面说的算法进行训练。现在很多算法都能够封装成黑盒供人使用。但是真正考验水平的是调整这些算法的(超)参数,使得结果变得更加优良。这需要我们对算法的原理有深入的理解。理解越深入,就越能发现问题的症结,提出良好的调优方案。
5 模型诊断
如何确定模型调优的方向与思路呢?这就需要对模型进行诊断的技术。
过拟合、欠拟合 判断是模型诊断中至关重要的一步。常见的方法如交叉验证,绘制学习曲线等。过拟合的基本调优思路是增加数据量,降低模型复杂度。欠拟合的基本调优思路是提高特征数量和质量,增加模型复杂度。
误差分析 也是机器学习至关重要的步骤。通过观察误差样本,全面分析误差产生误差的原因:是参数的问题还是算法选择的问题,是特征的问题还是数据本身的问题……
诊断后的模型需要进行调优,调优后的新模型需要重新进行诊断,这是一个反复迭代不断逼近的过程,需要不断地尝试, 进而达到最优状态。
6 模型融合
一般来说,模型融合后都能使得效果有一定提升。而且效果很好。
工程上,主要提升算法准确度的方法是分别在模型的前端(特征清洗和预处理,不同的采样模式)与后端(模型融合)上下功夫。因为他们比较标准可复制,效果比较稳定。而直接调参的工作不会很多,毕竟大量数据训练起来太慢了,而且效果难以保证。
7 上线运行
这一部分内容主要跟工程实现的相关性比较大。工程上是结果导向,模型在线上运行的效果直接决定模型的成败。 不单纯包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性是否可接受。
这些工作流程主要是工程实践上总结出的一些经验。并不是每个项目都包含完整的一个流程。这里的部分只是一个指导性的说明,只有大家自己多实践,多积累项目经验,才会有自己更深刻的认识。
故,基于此,七月在线每一期ML算法班都特此增加特征工程、模型调优等相关课。比如,这里有个公开课视频http://www.julyedu.com/video/play/18/186
推荐阅读
百面机器学习之经典算法
1. 逻辑回归 Q1. 逻辑回归相比于线性回归,有何异同? 不同之处:1. 逻辑回归处理的是分类问题,线性回归处理的是回归问题, 这是两者的最本质的区别。 2. 逻辑回归的因变量是离散的,而线…

Hulu机器学习问题与解答系列 | 二十八:概率图模型

BAT机器学习面试1000题系列(11-20题)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号
还没有评论