
高并发场景优化解决思路
随着公司业务的增长,用户的增加,导致对服务器的请求增加。2019年双十一13.52亿订单量,微信的日活可以达到十个亿,当请求量过大导致:
对服务器来说,那么就是请求太多,来不及处理
对客户端来讲,等待时间过长,或者是出现错误
怎样去尽可能多的处理请求?
性能的概念:响应时间和并发性
优化:前端优化和后端优化
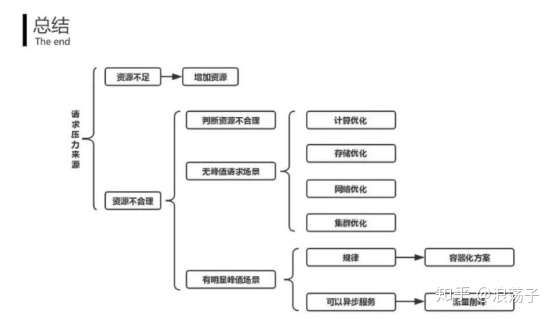
资源不足:
增加资源,选择多核cpu的服务器
合适使用多任务(多进程、多线程、多协程),充分利用cpu
网络优化:
硬件-升级网卡
DNS域名解析-更换域名服务器,提升解析速度
峰值优化(外卖网站、票务平台):
容器技术(Docker),多机集群
定时扩容
比如说外卖网站,每天我知道到了中午就会有一个小高峰,每天中午都会有个小高峰,我就可以去运用这种容器技术,或者多机集群的方式,来进行一个定时的扩容,每天到了中午的时候,比如这里到了预测到达的这个高峰之前,我就可以在这个点提前的对它进行扩容,让这个整体的一个服务能力有一个提升,然后能够很好地去处理这样一个峰值情况。然后渡过了高峰之后,比如在这个地方,然后对这样的一些容器进行销毁,可以去节约资源
https://www.cnblogs.com/angelyan/p/10439475.html
1.HTML页面静态化
2.图片服务器分离(可以用fastdfs轻量级的分布式文件存储系统)
3.使用缓存(用redis)Flask-Cache缓存
4.异步操作----->同步会阻塞
5.数据库和存储介质优化
6.多线程
7.主从配置、集群负载均衡(配置nigix服务器) nginx + uWSGI 提高 Django的并发性
8.镜像
9.CDN加速技术(内容分发网络) 把静态资源放到别人服务器上
10.精灵图,是一种网页图片应用处理技术。主要是指将网页中需要的零星的小图片集成到一个大的图片中:减少对浏览器的请求次数,避免网页的延迟 ;方便小图标的统一管理
11.前后端的代码、时间复杂度优化
数据库优化
可以从表设计、表查询、数据库服务器部署等方面考虑。
1、创建数据表时把固定长度的放在前面
2、将固定数据放入内存: 例如:choice字段 (django中有用到,数字1、2、3…… 对应相应内容)
3、char 和 varchar 的区别(char可变, varchar不可变 )
4、索引(索引只适合查询操作频繁而不常修改的表)、联合索引遵循最左前缀(从最左侧开始检索)
5、避免使用 select *
6、读写分离、集群
- 实现:两台服务器同步数据
- 利用数据库的主从分离:主,用于增加、删除、更新;从,用于查询;
7、分库
- 当数据库中的表太多,将某些表分到不同的数据库,例如:1W张表时
- 代价:连表查询
8、分表
- 水平分表:将某些列拆分到另外一张表,例如:博客+博客详情
- 垂直分表:将某些历史信息分到另外一张表中,例如:支付宝账单
9、加缓存
- 利用redis、memcache (常用数据放到缓存里,提高取数据速度)
10、如果只想获取一条数据
- select xxx from tb where name='alex' limit 1;
使用主从配置的好处:
① 提供服务可用性
② 读写分离,负载均衡。通过增加从服务器来提高数据库的性能,在主服务器上执行写入和更新,在从服务器上向外提供读功能,可以动态地调整从服务器的数量,从而调整整个数据库的性能。
③ 主从同步,将数据备份提高数据安全。复制是异步进行的,所以从服务器不需要一直连接着主服务器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号