
YOLO11深度学习 - helloworld
依赖库
YOLO 只需要前两个库即可。
其它库在图片分析过程中经常被用到,有兴趣的可以继续学习一下。
# YOLO 系列目标检测模型的官方库,支持训练、推理和部署。
pip3 install ultralytics
# 图像标注工具,最好做成独立项目,很容易出现兼容问题,实在装不上可以找现成的 windows 应用(这是一个标注工具,与业务代码无关)
pip3 install labelImg
# 计算机视觉领域的核心库,提供图像/视频处理算法。
pip3 install opencv-python
# Python 科学计算的基础库,专注于多维数组操作和数学运算。
pip3 install numpy
# 图表绘制工具,类似于 echarts,用做数据展示
pip3 install matplotlib
# 基于 Tesseract OCR 引擎的 Python 封装,实现图像文字识别。
pip3 install pytesseract
# hyperlpr 已停止更新且兼容性差,优先使用 PaddleOCR 或 EasyOCR。
pip3 install hyperlpr
# 车牌识别,使用的时候,会下载一些依赖,下载速度极慢
pip3 install easyocr
YOLO
YOLO官网:https://docs.ultralytics.com/zh/
1. 安装依赖:
pip install ultralytics
2. 下载 yolo11n.pt 文件
这个是预训练的 Detect 模型,以此为基础开始训练,训练的成果也会保存在 .pt 文件中。
我用的是办公本,只能选择 yolo11n.pt,实际使用需要根据机器性能进行挑选:YOLO11n、YOLO11s、YOLO11m、YOLO11l、YOLO11x
3. 制作训练用的素材
训练 yolo11 模型,首先需要准备一些素材,素材的专有名词为 “训练集”。
启动 labelImg 工具,打开图片,圈画(标注)出要识别的区域,给区域命名;
然后点击保存,会产生一份.txt 文件,第一次保存,还会生成一份 classes.txt。
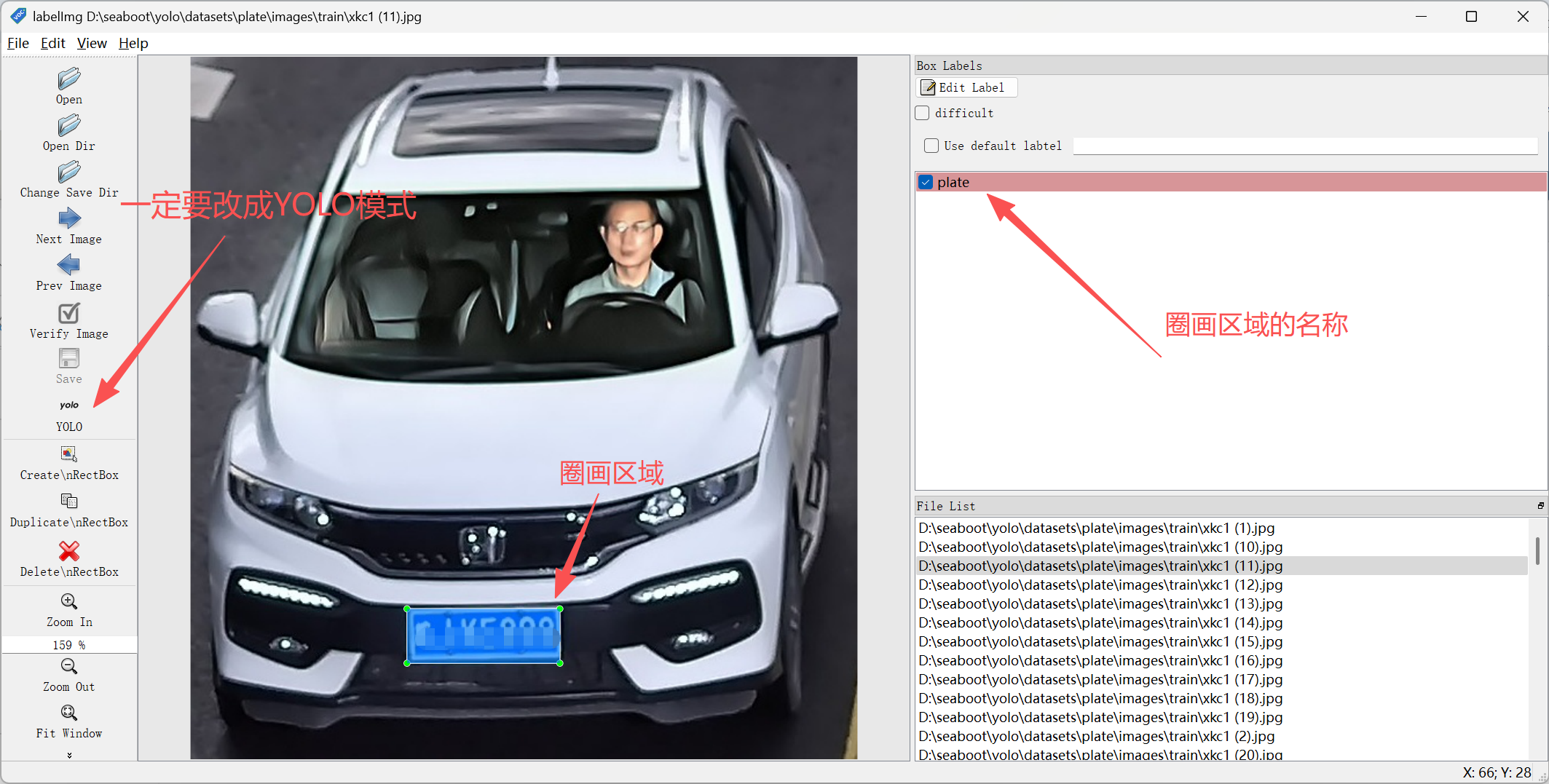
以车牌识别为例:要准备一堆的车辆照片,然后把车牌用矩形框圈起来,之后保存一下。
标注好图片之后,按下面这种结构,新建一下文件夹。
datasets/coco8/
├── images/
│ ├── train/ # 训练集图片
│ └── val/ # 验证集图片
└── labels/
├── train/ # 训练集标签(.txt)
└── val/ # 验证集标签(.txt)
把图片放到 image/train 中,把 txt 文件放到 labels/train 中;
将 train 目录的文件,分一部分到 val 文件夹(一般取 20%,先不深究比例)。
分出来的部分,称之为测试集,主要用于评估模型性能。
3.1 测试用的素材 coco8.zip
coco8 是官方提供的一个测试素材,如果网络允许,可以下载下来测试使用。
注意:coco8 就是一个用于测试的 demo,不要用到真实的模型训练中。
https://ultralytics.com/assets/coco8.zip
4. 准备 yaml 配置文件
新建一个 .yaml 文件,基本格式如下,
下面的配置值,是针对 coco8 填写的,根据实际情况修改 path(根目录)、train(训练集)、val(测试集) 等字段;
names 对应于 labelimg 中圈画区域的命名。
path: coco8 # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes
names:
0: car
可以在 ultralytics 库中找到 coco8.yaml 原文件
如果使用 PyCharm 开发工具,ultralytics-8.3.181,可以尝试在这个目录获取:venv/Lib/site-packages/ultralytics/cfg/datasets/coco8.yaml
5. 编码:
from ultralytics import YOLO
# Load a pre-trained YOLO model (you can choose n, s, m, l, or x versions)
model = YOLO("yolo11n.pt")
# Start training on your custom dataset
model.train(data="coco8.yaml", epochs=100, imgsz=640)
# 如果没有 GPU,就修改参数使用 CPU
model.train(data="coco8.yaml", epochs=100, imgsz=640, device='cpu')
将准备好的 yolo11n.pt、coco8.yaml、datasets 全部放到工程根目录,开始运行脚本
默认情况下,训练产生的 best.pt 文件,会放到工程根目录的 runs/detect/train/weights 文件夹下。
使用模型
案例:使用训练好的模型,在 a.jpg 图片中抓取相似的区域,在弹窗中展示。
如果你的需求是车牌识别,后续的步骤,就是截取车牌,然后将车牌照片,交给 OCR 库进行识别。
import os
import cv2
from ultralytics import YOLO
# 使用训练好的模型
model = YOLO('runs/detect/train4/weights/best.pt')
def showBox():
"""
展示监测区域的图片
:return:
"""
img = cv2.imread("a.jpg")
results = model(img)
# 遍历每个检测到的目标
for box in results[0].boxes.xyxy: # xyxy格式的边界框
x1, y1, x2, y2 = map(int, box.tolist()) # 转换为整数坐标
# 截取目标区域(注意OpenCV的坐标格式是[y:y+h, x:x+w])
cropped_region = img[y1:y2, x1:x2]
# 展开弹窗展示截取的区域
cv2.imshow("Cropped Object", cropped_region)
showBox()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号